Esta lista incluye las alertas preconfiguradas de CallManager.
- Suscripciones de BeginThrottlingCallListBLFS
- CallAttemptBlockedByPolicy
- CallProcessingNodeCpuPegging
- CARIDSEngineCritical
- CARIDSEngineFailure
- CARSchedulerJobFailed
- Error de CDRAgentSendFile
- CDRFileDeliveryFailed
- CDRHighWaterMarkExceeded
- CDRMamaximumDiskSpaceExceeded
- CódigoAmarillo
- DBChangeNotifyFailure
- DBReplicationFailure
- DBReplicationTableOutOfSync
- DDRBlockPrevention
- DDRDown
- EMCCFailInLocalCluster
- EMCCFailInRemoteCluster
- InformesCalidadVozExcesiva
- IMEDistributedCacheInactive
- IMEOverCuota
- IMEQualityAlert
- IdentificadoresDeReservaInsuficientes
- IMEServiceStatus
- Credenciales no válidas
- LowTFTPServerHeartbeatRate
- SeguimientoLlamadasMaliciosas
- ListaDeMediosAgotada
- MgcpDChannelOutOfService
- NúmeroDeDispositivosRegistradosSuperado
- NúmeroDePuertasDeEnlaceRegistradasReducidas
- NúmeroDePuertasDeEnlaceRegistradasAumentadas
- NúmeroDeDispositivosDeMediosRegistradosDisminuido
- NúmeroDeDispositivosDeMediosRegistradosAumentado
- NumberOfRegisteredPhonesDropped
- ListaRutaAgotada
- SDLLinkOutOfService
- Error de TCPSetupToIMEF
- TLSConnectionToIMEFail
- ErrorEntradaUsuario
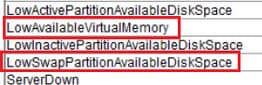
LowAvailableVirtualMemory y LowSwapPartitionAvailableDiskSpace
Los servidores Linux tienen una tendencia a ‘no borrar’ el uso de la memoria virtual durante un período de tiempo y se ha visto que se acumula y, por lo tanto, esas alertas.
Linux funciona un poco diferente como sistema operativo.
Una vez que la memoria se asigna a un proceso, el procesador no la recuperará a menos que algún otro proceso solicite más memoria que la memoria disponible.
Esto provoca una memoria virtual alta.
Una solicitud de aumento en el umbral para la alarma en las versiones superiores del administrador de llamadas se ha documentado en el defecto; https://bst.cloudapps.cisco.com/bugsearch/bug/CSCuq75767/?reffering_site=dumpcr
Para las particiones de intercambio, esta alerta indica que la partición de intercambio se queda con poco espacio disponible y es muy utilizada por el sistema. La partición de intercambio se utiliza normalmente para ampliar la capacidad física de RAM cuando es necesario. En condiciones normales, si la RAM es suficiente, el intercambio no debe usarse demasiado.
Además, estas pueden ser alertas RTMT provocadas por una acumulación de archivos temporales, se recomienda reiniciar el servidor para eliminar cualquier archivo temporal innecesario.
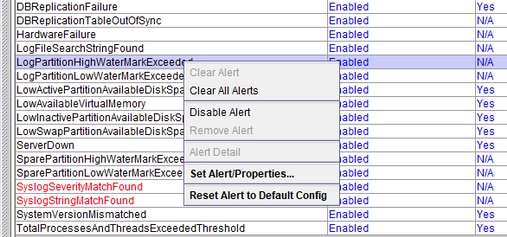
LogPartitionHighWaterMarkExceeded y LogPartitionLowWaterMarkExceeded
Al ejecutar show status en la CLI de un servidor de CUCM, se muestra un valor que especifica el porcentaje ocupado y libre de la partición de registro en el espacio de disco de CUCM. También conocidos como partición común, estos valores especifican el espacio ocupado por los registros/seguimientos y los archivos CDR en el servidor, que aunque son inofensivos, pueden causar problemas en el procedimiento de instalación/actualización debido a la falta de espacio en el tiempo. Estas alertas sirven como una advertencia al administrador para que borre los registros que podrían haberse acumulado con el tiempo en el clúster/servidor.
LogPartitionLowWaterMarkExceeded: Esta alerta se genera cuando el espacio relleno alcanza los valores de umbral configurados para la alerta. Esta alerta sirve como indicador de comprobación previa para el uso del disco.
LogPartitionHighWaterMarkExceeded: Esta alerta se genera cuando el espacio relleno alcanza los valores de umbral configurados para la alerta. Una vez que se genera la alerta, el servidor comienza a purgar automáticamente los registros más antiguos para reducir el espacio al valor menor que el umbral HighWaterMark.
Se recomienda purgar los registros manualmente tan pronto como se reciba la alerta LogPartitionLowWaterMarkExceeded.
Los pasos para hacerlo son:
Paso 1. Inicie RTMT.
Paso 2. Seleccione Alert Central y, a continuación, realice estas tareas:
Seleccione LogPartitionHighWaterMarkExceeded, anote su valor y cambie su valor de umbral al 60%.
Seleccione LogPartitionLowWaterMarkExceeded, anote su valor y cambie su valor de umbral al 50%.
El sondeo se realiza cada 5 minutos, por lo que debe esperar entre 5 y 10 minutos y, a continuación, comprobar que el espacio en disco necesario está disponible. Si desea liberar más espacio en disco en la partición común, vuelva a cambiar los valores de los subprocesos LogPartitionHighWaterMarkExceeded y LogPartitionLowWaterMarkExceeded por valores inferiores (por ejemplo, 30% y 20%).
Dale de 15 a 20 minutos para despejar el espacio en la partición común. Puede monitorear la disminución en el uso del disco con el comando show status de CLI.
Eso haría caer la partición común.
CpuPegging
La alerta de trazabilidad de CPU supervisa el uso de la CPU en función del umbral configurado.
Cuando se recibe la alerta de vinculación de CPU, el proceso que ocupa la CPU más alta puede ser ocupado por ir a la sección Sistema de la izquierda, es decir, Proceso.
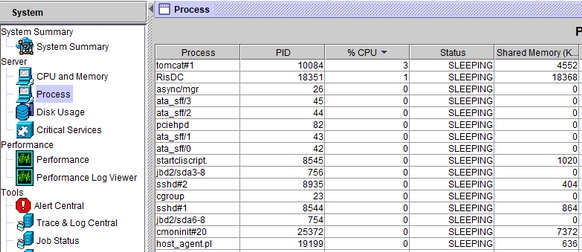
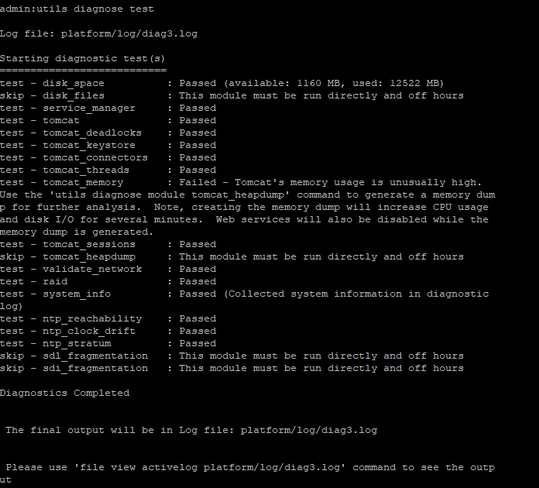
A partir de la CLI del servidor en cuestión, estos resultados proporcionarán cierta información.
- prueba de diagnóstico de utils
- show process load cpu sorted
- show status
- lista activa de núcleo de utils
Se recomienda observar si el pico de la CPU ocurre en un momento específico o aleatoriamente. Si ocurre aleatoriamente, entonces los seguimientos detallados de CUCM requeridos, así como los registros perfmon de RisDC, verifican lo que está desencadenando el pico en la CPU. Si las alertas se producen a una hora específica del día, podría deberse a alguna actividad programada, como la copia de seguridad del sistema de recuperación ante desastres (DRS), la carga de CDR, etc.
Además, sobre la base de la información acerca de qué proceso ocupa la mayor parte de la CPU, se toman registros específicos para una investigación adicional. Por ejemplo, si el culpable es Tomcat, se necesitan los registros relacionados con Tomcat.
 Comentarios
Comentarios