Runs a set of
diagnostics and displays the current state of the system. If any components are
not running, red failure messages are displayed.

Note |
RADIUS-based policy control is no longer supported in CPS 14.0.0
and later releases as 3GPP Gx Diameter interface has become the
industry-standard policy control interface.
|
Syntax
/var/qps/bin/diag/diagnostics.sh -h
Usage: /var/qps/bin/diag/diagnostics.sh [options]
This script runs checks (i.e. diagnostics) against the various access, monitoring, and configuration points of a running CPS system.
In HA/GR environments, the script always does a ping check for all VMs prior to any other checks and adds any that fail the ping test to the IGNORED_HOSTS variable. This helps reduce the possibility for script function errors.
NOTE: See /var/qps/bin/diag/diagnostics.ini to disable certain checks for the HA/GR env persistently. The use of a flag will override the diagnostics.ini value.
Examples:
/var/qps/bin/diag/diagnostics.sh -q
/var/qps/bin/diag/diagnostics.sh --basic_ports --clock_skew -v --ignored_hosts='portal01,portal02'
Options:
--basic_ports : Run basic port checks
For AIO: 80, 11211, 27017, 27749, 7070, 8080, 8090, 8182, 9091, 9092
For HA/GR: 80, 11211, 7070, 8080, 8081, 8090, 8182, 9091, 9092, and Mongo DB ports based on /etc/broadhop/mongoConfig.cfg
--clock_skew : Check clock skew between lb01 and all vms (Multi-Node Environment only)
--diskspace : Check diskspace
--get_active_alarms : Get the active alarms in the CPS
--get_replica_status : Get the status of the replica-sets present in environment. (Multi-Node Environment only)
--get_sharding_status : Get the status of the sharding information present in environment. (Multi-Node Environment only)
--get_shard_health : Get the status of the sharded database information present in environment. (Multi-Node Environment only)
--get_peer_status: Get the diameter peers present in the environemt.
--get_sharded_replica_status : Get the status of the shards present in environment. (Multi-Node Environment only)
--ha_proxy : Connect to HAProxy to check operation and performance statistics, and ports (Multi-Node Environment only)
http://lbvip01:5540/haproxy?stats
http://lbvip01:5540//haproxy-diam?stats
--help -h : Help - displays this help
--hostnames : Check hostnames are valid (no underscores, resolvable, in /etc/broadhop/servers) (AIO only)
--ignored_hosts : Ignore the comma separated list of hosts. For example --ignored_hosts='portal01,portal02'
Default is 'portal01,portal02,portallb01,portallb02' (Multi-Node Environment only)
--ping_check : Check ping status for all VM
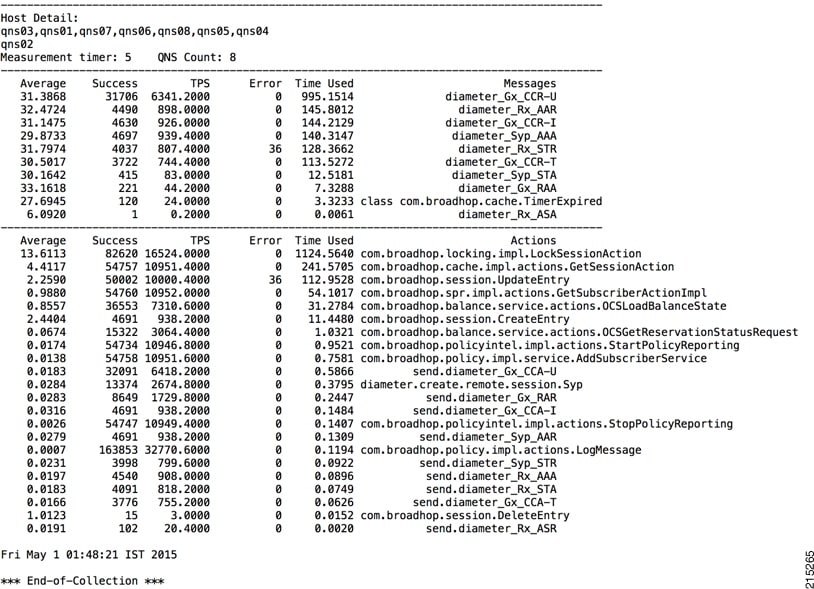
--qns_diagnostics : Retrieve diagnostics from CPS java processes
--qns_login : Check qns user passwordless login
--quiet -q : Quiet output - display only failed diagnostics
--radius : Run radius specific checks
--redis : Run redis specific checks
--svn : Check svn sync status between pcrfclient01 & pcrfclient02 (Multi-Node Environment only)
--tacacs : Check Tacacs server reachability
--swapspace : Check swap space
--verbose -v : Verbose output - display *all* diagnostics (by default, some are grouped for readability)
--virtual_ips : Ensure Virtual IP Addresses are operational (Multi-Node Environment only)
--vm_allocation : Ensure VM Memory and CPUs have been allocated according to recommendations
The test for swap memory usage must have the following criteria :
-
The test passes if the swap space used is less than 200 MB.
-
The script issues a warning if the swap space used is between 200 MB and 1000 MB.
-
The status fails if the swap memory used exceeds 1000 MB.
Executable on
VMs
Cluster Manager and
OAM (pcrfclient) nodes
Example
[root@pcrfclient01 ~]# diagnostics.sh
QNS Diagnostics
Checking basic ports (80, 7070, 27017, 27717-27720, 27749, 8080, 9091)...[PASS]
Checking qns passwordless logins on all boxes...[PASS]
Validating hostnames...[PASS]
Checking disk space for all VMs...[PASS]
Checking swap space for all VMs...[PASS]
Checking for clock skew...[PASS]
Retrieving QNS diagnostics from qns01:9045...[PASS]
Retrieving QNS diagnostics from qns02:9045...[PASS]
Checking HAProxy status...[PASS]
Checking VM CPU and memory allocation for all VMs...[PASS]
Checking Virtual IPs are up...[PASS]
[root@pcrfclient01 ~]#
List of Active
Alarms
To get the list of
active alarms, execute the
diagnostics.sh --get_active_alarms command. Here is a
sample output:
#diagnostics.sh --get_active_alarms
CPS Diagnostics HA Multi-Node Environment
---------------------------
Active Application Alarm Status
---------------------------------------------------------------------------------
id=1000 sub_id=3001 event_host=lb02 status=down date=2017-11-22,
10:47:34,051+0000 msg="3001:Host: site-host-gx Realm: site-gx-client.com is down"
id=1000 sub_id=3001 event_host=lb02 status=down date=2017-11-22,
10:47:34,048+0000 msg="3001:Host: site-host-sd Realm: site-sd-client.com is down"
id=1000 sub_id=3001 event_host=lb01 status=down date=2017-11-22,
10:45:17,927+0000 msg="3001:Host: site-server Realm: site-server.com is down"
id=1000 sub_id=3001 event_host=lb02 status=down date=2017-11-22,
10:47:34,091+0000 msg="3001:Host: site-host-rx Realm: site-rx-client.com is down"
id=1000 sub_id=3002 event_host=lb02 status=down date=2017-11-22,
10:47:34,111+0000 msg="3002:Realm: site-server.com:applicationId: 7:all peers are down"
Active Component Alarm Status
---------------------------------------------------------------------------------
event_host=lb02 name=ProcessDown severity=critical facility=operatingsystem
date=2017-22-11,10:13:49,310329511,+00:00 info=corosync process is down
Attention |
-
Due to the
limitation of architecture of the CPS SNMP implementation, if the SNMP deamon
or policy server (QNS) process on pcrfclient VM restarts, there can be gap
between active alarms displayed by the
diagnostics.sh and active alarms in NMS.
-
The date
printed for application alarm status is when the alarm was seen at pcrfclient
VM. The time for the alarm at NMS is the time before the alarm is received from
Policy Director (LB) VM. So there can be a difference in the dates for the same
alarm reported in
diagnostics.sh and in NMS.
|
The following
table list the type of SNMP alarms:
Table 1. IDs - Type of
SNMP Alarms
|
Alarm ID
|
Type
|
|
1000
|
Application Alarm
|
|
7100
|
Database
Alarm
|
|
7200
|
Failover
Alarm
|
|
7300
|
Process
Alarm
|
|
7400
|
VM Alarm
|
|
7700
|
GR Alarm
|
For more information on SNMP alarms, refer to
CPS SNMP, Alarms and Clearing Procedures Guide.
Sample Output
of --get_sharding_status
-
---------------------------------------------------------------------------------
|--------------------------------------------------------------------------------------------------------------------------------|
| MONGODB SHARDING STATUS INFORMATION Date : 2017-12-20 19:02:38 |
|--------------------------------------------------------------------------------------------------------------------------------|
Shard Id Mongo DB State Backup DB Removed Session Count
1 sessionmgr01:27717/session_cache online false false 0
2 sessionmgr01:27717/session_cache_2 online false false 0
4 sessionmgr01:27717/session_cache_4 online false false 0
Rebalance Status: Rebalanced
|--------------------------------------------------------------------------------------------------------------------------------|
Shard Id Mongo DB State Backup DB Removed Session Count
1 sessionmgr01:37717/session_cache online false false 0
Rebalance Status: Rebalanced

 Feedback
Feedback