Traditionally, VLANs have been the standard method for providing network segmentation in campus networks. VLANs use loop prevention
techniques such as Spanning Tree Protocol (STP), which impose restrictions on network design and resiliency. Further, because
there is a limitation with the number of VLANs that can be used to address layer 2 segments (4094 VLANs), VLANs are a limiting
factor for IT departments and cloud providers who build large and complex campus networks.
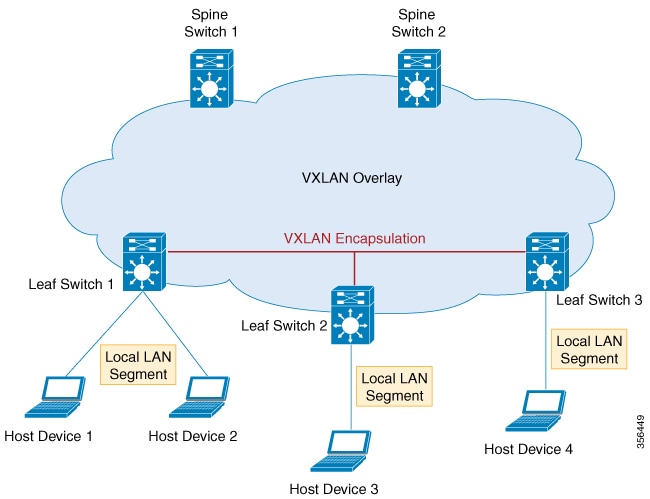
VXLAN is designed to overcome the inherent limitations of VLANs and STP. It is a proposed IETF standard [RFC 7348] to provide
the same Ethernet Layer 2 network services as VLANs do, but with greater flexibility. Functionally, it is a MAC-in- UDP encapsulation
protocol that runs as a virtual overlay on an existing Layer 3 network.
However, VXLAN by itself does not provide for optimal switching and routing in a network, because the “flood and learn” mechanism
it uses, limits its scalability (for a host to be reachable, the host’s information is flooded across the network). A VXLAN
overlay, requires:
-
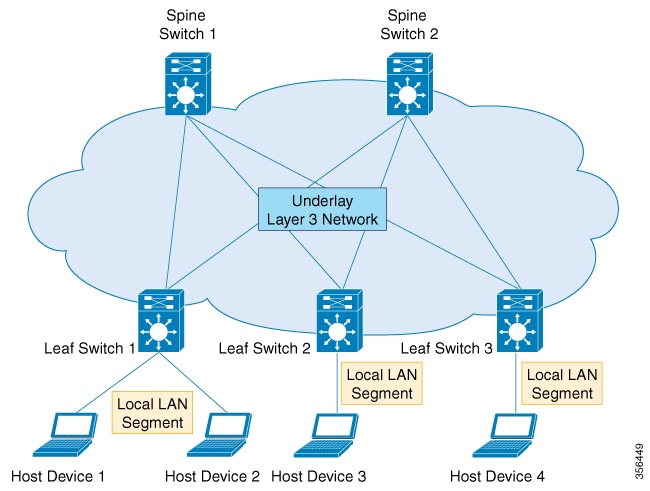
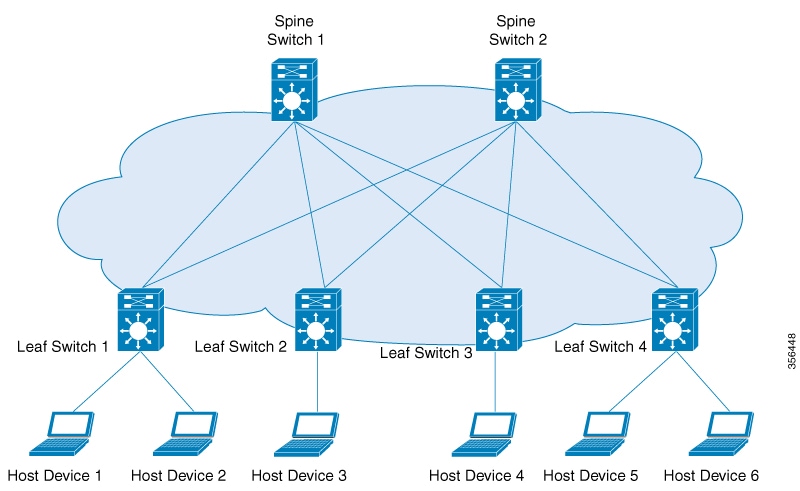
An underlying transport network that performs data plane forwarding, for unicast communication between end points connected
to the fabric.
-
A control plane that is capable of distributing Layer 2 and Layer 3 host reachability information across the network.
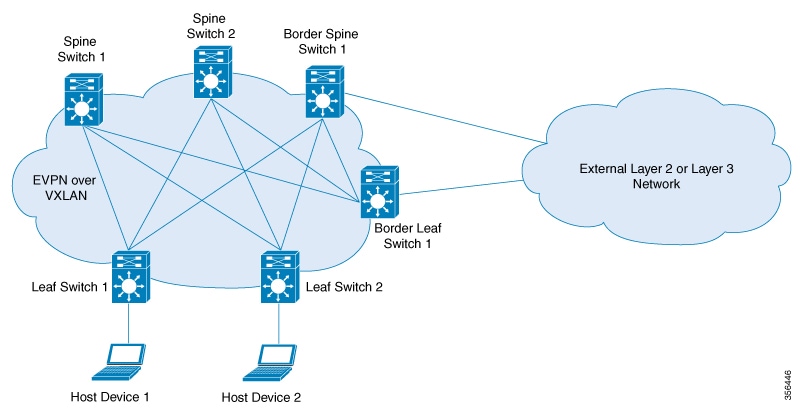
To meet these additional requirements, Internet drafts submitted by the bess workgroup (draft-ietf-bess-evpn-overlay-12), propose MP-BGP, which features Network Layer Reachability Information (NLRI), to carry both Layer 2 MAC and Layer 3 IP
information at the same time. With MAC and IP information available together for forwarding decisions, routing and switching
within a network is optimised. This also minimizes the use of the conventional flood and learn mechanism, which limits the
VXLAN fabric’s ability to scale. The extension that allows BGP to transport Layer 2 MAC and Layer 3 IP information is EVPN.
 Feedback
Feedback