Cisco Prime Central 2.1 HA Guide
Bias-Free Language
The documentation set for this product strives to use bias-free language. For the purposes of this documentation set, bias-free is defined as language that does not imply discrimination based on age, disability, gender, racial identity, ethnic identity, sexual orientation, socioeconomic status, and intersectionality. Exceptions may be present in the documentation due to language that is hardcoded in the user interfaces of the product software, language used based on RFP documentation, or language that is used by a referenced third-party product. Learn more about how Cisco is using Inclusive Language.
- Updated:
- July 28, 2017
Chapter: Geographical Disaster Recovery
- Introduction
- Preparing Your Network for Geographical Disaster Recovery
- Configuring Prime Central for Geographical Disaster Recovery
- Configuring Prime Central Fault Management for Geographical Disaster Recovery
- Fault Management for Disaster Recovery Synchronization Failure
- Configuring Monitoring Frequency and Email Notifications
- Checking the Status of Disaster Recovery Node
- Initiating Switchover
- Initiating Failover
- Initiating Failback
- Integrating Applications with the Standby Server
- Upgrading to Prime Central 2.1 and Prime Central Fault Management 2.1 in a Geographical Disaster Recovery
- Upgrading RHEL Operating System
- Geographical Disaster Recovery Implementation:Best Practices and Troubleshooting Information
Setting Up Geographical Disaster Recovery
Introduction
There may be times where Prime Central or the Cisco Prime applications integrated with Prime Central go down. To help minimize the amount of downtime for these applications, you can implement geographical disaster recovery in your network. Let’s begin with an overview of the geographical disaster recovery process and a definition of three of its key components.
After completing the procedures detailed later in this section, Prime Central and integrated Cisco Prime applications reside on both a primary and standby server. When one or more of these applications go down on the primary server, you receive a system-generated email notifying you of the problem. To deal with the problem, you would first initiate switchover to the standby server. Switchover is the manual switch from one server to a redundant or standby server. By initiating a switchover, you can continue to manage and monitor your network while you figure out what’s wrong with the primary server. You can also initiate switchover if you need to perform routine maintenance on the primary server, such as upgrading hardware or installing patches. If you resolve the problem, you switch back to the primary server and that’s that. However, if all of your attempts to bring the primary server back into a working state fail and it has become completely unreachable, you would then initiate failover. Failover is essentially the same operation as switchover, the difference being that failover indicates a major problem with the primary server that will require some time to resolve. By initiating failover, the standby server effectively becomes the new primary server and takes over all network management and monitoring tasks. Before you initiate failover for a server, make sure that you’ve done everything possible to bring that server back into operation because switching to the standby server could bring about other problems. Finally, when the server previously acting as the primary server is up and running again, you would then initiate failback, which is the process that reinstates that server as the primary server.
In this section, the following topics are covered:
- How to prepare your network for geographical disaster recovery
- How to configure monitoring frequency and email notifications
- How to initiate switchover, failover, and failback
- How to integrate Cisco Prime applications with the standby server
- Best practices for geographical disaster recovery implementation, as well as troubleshooting information
Preparing Your Network for Geographical Disaster Recovery
To prepare your network for geographical disaster recovery, you will need to configure the following:
- Prime Central
- Prime Central Fault Management
- Application and database replication monitors, which keep tabs on the:
–![]() The current status of the database
The current status of the database
–![]() Database replication between the primary and standby nodes
Database replication between the primary and standby nodes
Typically, the Prime Central portal, integration layer, and database are located on the same server. You can also choose to place these components on multiple servers. If you want the integration layer to reside on its own server, you will need to complete the following procedures twice—once on the portal server and once on the integration layer server.

Note ●![]() If your environment contains multiple integration layer servers, you will need to complete these procedures for each of those servers.
If your environment contains multiple integration layer servers, you will need to complete these procedures for each of those servers.
Configuring Prime Central for Geographical Disaster Recovery
You can configure Prime Central for Geographical disaster recovery in a Primary and standby server setup.
Step 1![]() Install Prime Central 2.1 onto the server that will act as the primary server.
Install Prime Central 2.1 onto the server that will act as the primary server.
During installation, in the Embedded DB Information window, make sure that:
It is critical that you enable backups on the Oracle database. Geographical disaster recovery setup will fail unless you do so.
See “Installing Prime Central” in the Cisco Prime Central 2.1 Quick Start Guide for detailed installation instructions.
Step 2![]() Set up Prime Central for geographical disaster recovery on the server that will act as the standby server.
Set up Prime Central for geographical disaster recovery on the server that will act as the standby server.
a.![]() Copy and unzip disaster_recovery_v2.1.zip into a folder on the standby server.
Copy and unzip disaster_recovery_v2.1.zip into a folder on the standby server.
In this example, we will use the /root/disaster_recovery folder. When setting up geographical disaster recovery in your environment, overwrite this folder with the correct one.
b.![]() Ensure that the Prime Central database and installer binaries reside in the /root/disaster_recovery/scripts/main/installer folder. Specifically, ensure that these files are present:
Ensure that the Prime Central database and installer binaries reside in the /root/disaster_recovery/scripts/main/installer folder. Specifically, ensure that these files are present:
–![]() linuxamd64_12102_database_1of2.zip
linuxamd64_12102_database_1of2.zip
–![]() linuxamd64_12102_database_2of2.zip
linuxamd64_12102_database_2of2.zip
c.![]() Ensure that the primary server is reachable via SSH by the following means:
Ensure that the primary server is reachable via SSH by the following means:
–![]() Hostname (without domain name, if applicable)
Hostname (without domain name, if applicable)
–![]() Hostname with domain name (FQDN)
Hostname with domain name (FQDN)
d.![]() Navigate to the disaster recovery distribution package folder:
Navigate to the disaster recovery distribution package folder:
e.![]() Enter the following commands to run the setup script:
Enter the following commands to run the setup script:
f.![]() When prompted by the setup script, enter the necessary information for the primary (active) and standby server (such as IP address, hostname and root password).
When prompted by the setup script, enter the necessary information for the primary (active) and standby server (such as IP address, hostname and root password).
Note![]() In the hostname prompt, enter the FQDN. The host name of the primary server should exactly be same as the one that was used when Prime Central was being installed in it.
In the hostname prompt, enter the FQDN. The host name of the primary server should exactly be same as the one that was used when Prime Central was being installed in it.
g.![]() After Prime Central has been set up on the standby server, complete the following tasks:
After Prime Central has been set up on the standby server, complete the following tasks:
–![]() As the user primeusr, generate a Secure Shell (SSH) key for the primeusr user on both the primary and standby servers by entering the following commands:
As the user primeusr, generate a Secure Shell (SSH) key for the primeusr user on both the primary and standby servers by entering the following commands:
–![]() (On the primary server only) Share the primary server's public key with the standby server so that the dynamic creation of a SSH between the servers does not prompt for a password.
(On the primary server only) Share the primary server's public key with the standby server so that the dynamic creation of a SSH between the servers does not prompt for a password.
As the user primeusr, enter the following commands:
–![]() (On the Standby server only) Enter the following command:
(On the Standby server only) Enter the following command:
where standby-server-hostname is the hostname of the standby server.
–![]() Verify that the SSH is working and does not prompt for authentication or a password (using the FQDN hostname, non-FQDN hostname, and IP address) on both the primary and standby server.
Verify that the SSH is working and does not prompt for authentication or a password (using the FQDN hostname, non-FQDN hostname, and IP address) on both the primary and standby server.
–![]() If you are prompted to continue connecting, enter yes. (The prompt should appear only the first time you use SSH to connect to the node.)
If you are prompted to continue connecting, enter yes. (The prompt should appear only the first time you use SSH to connect to the node.)
h.![]() Integrate the relevant Cisco Prime applications, such as Prime Network and Prime Optical, with the standby server. Refer to the Integrating Applications with the Standby Server for instructions.
Integrate the relevant Cisco Prime applications, such as Prime Network and Prime Optical, with the standby server. Refer to the Integrating Applications with the Standby Server for instructions.
Note![]() Prime Central services such as, portalctl and itgctl should be running on standby server during Domain Manager integration.
Prime Central services such as, portalctl and itgctl should be running on standby server during Domain Manager integration.
Configuring Prime Central Fault Management for Geographical Disaster Recovery
You can choose to not set up Fault Management for geographical disaster recovery at this time. However, keep in mind that you may not be able to do so later.
Step 1![]() If Fault Management and Prime Central are being installed on the same machine, open /opt/primecentral/local/disaster_recovery/rsync/fm/includeSync.txt file on the primary server and comment all the lines in it. After the installation is complete, uncomment these lines.
If Fault Management and Prime Central are being installed on the same machine, open /opt/primecentral/local/disaster_recovery/rsync/fm/includeSync.txt file on the primary server and comment all the lines in it. After the installation is complete, uncomment these lines.
Note![]() The Prime Central and Fault Management installation in the Discover Recovery (DR) site may fail if step 1 is not followed because, some files in the folder “install-directory/faultmgmt” might get synced between Primary and Standby servers. For Best Practices and troubleshooting the Prime Central Installation, see Geographical Disaster Recovery Implementation: Best Practices and Troubleshooting Information.
The Prime Central and Fault Management installation in the Discover Recovery (DR) site may fail if step 1 is not followed because, some files in the folder “install-directory/faultmgmt” might get synced between Primary and Standby servers. For Best Practices and troubleshooting the Prime Central Installation, see Geographical Disaster Recovery Implementation: Best Practices and Troubleshooting Information.
Step 2![]() Install Fault Management on the Fault Management primary server.
Install Fault Management on the Fault Management primary server.
See “Installing Prime Central Fault Management” in the Cisco Prime Central 2.0 Quick Start Guide for detailed instructions.
Step 3![]() SSH to the primary Prime Central server as the user primeusr and run the list command to determine Fault Management’s instance ID value (in this example, 5).
SSH to the primary Prime Central server as the user primeusr and run the list command to determine Fault Management’s instance ID value (in this example, 5).
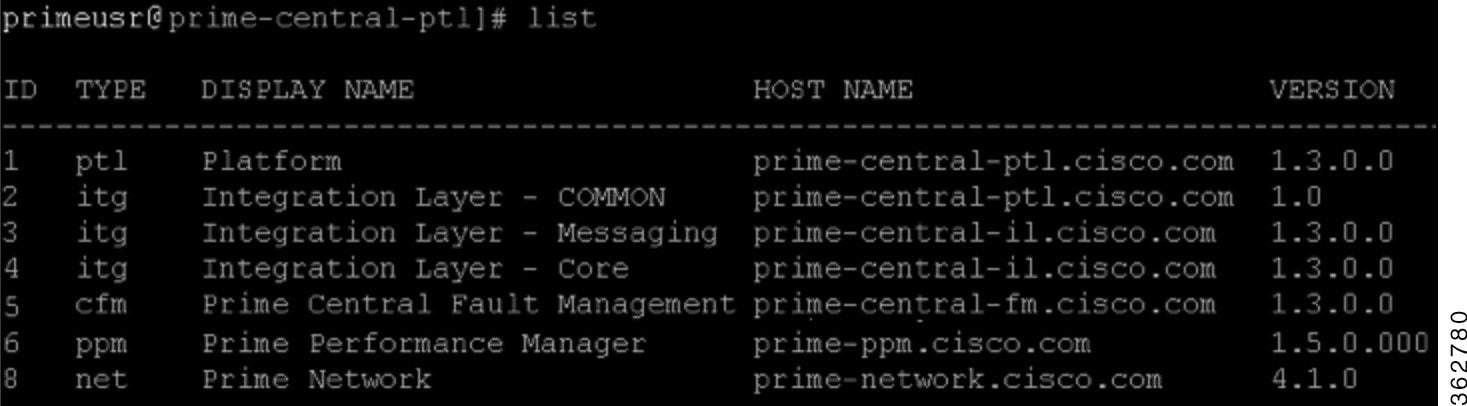
You will need this for Step 4f.
Step 4![]() On the standby Prime Central server, verify that the portal and integration layer are up and running.
On the standby Prime Central server, verify that the portal and integration layer are up and running.
Step 5![]() Set up geographical disaster recovery for Fault Management on the standby server.
Set up geographical disaster recovery for Fault Management on the standby server.
a.![]() Copy and unzip the distribution package zip file into the /root/disaster_recovery folder.
Copy and unzip the distribution package zip file into the /root/disaster_recovery folder.
b.![]() Copy FM2.1.0Build.tar.gz to the /root/disaster_recovery/scripts/main/installer folder.
Copy FM2.1.0Build.tar.gz to the /root/disaster_recovery/scripts/main/installer folder.
d.![]() Ensure that the Fault Management binary (primefm_v2.1.bin) resides in the /root/disaster_recovery/scripts/main/installer/Disk1/InstData/VM folder.
Ensure that the Fault Management binary (primefm_v2.1.bin) resides in the /root/disaster_recovery/scripts/main/installer/Disk1/InstData/VM folder.
e.![]() Enter the following commands to run the setup script:
Enter the following commands to run the setup script:
f.![]() Verify that the Fault Management component on both the primary and standby server, as well as the primary and standby Prime Central server, can be reached using their hostname.
Verify that the Fault Management component on both the primary and standby server, as well as the primary and standby Prime Central server, can be reached using their hostname.
g.![]() Enter the following command:
Enter the following command:
–![]() For regular standby installation:
For regular standby installation:
h.![]() When prompted by the setup script, enter the necessary information for the primary and standby server (such as IP address and root password).
When prompted by the setup script, enter the necessary information for the primary and standby server (such as IP address and root password).
Note![]() In the hostname prompt, enter the FQDN. The host name of the primary server should exactly be same as the one that was used when Prime Central was being installed in it.
In the hostname prompt, enter the FQDN. The host name of the primary server should exactly be same as the one that was used when Prime Central was being installed in it.
When prompted for Prime Central database details, ensure to specify the standby database IP address.
2. After Fault Management has been set up on the standby server, complete the following tasks:
–![]() As the user primeusr, generate a Secure Shell (SSH) key for the primeusr user on both the primary and standby servers by entering the following commands:
As the user primeusr, generate a Secure Shell (SSH) key for the primeusr user on both the primary and standby servers by entering the following commands:
–![]() (On the primary server only) Share the primary server's public key with the standby server so that the dynamic creation of a SSH between the servers does not prompt for a password.
(On the primary server only) Share the primary server's public key with the standby server so that the dynamic creation of a SSH between the servers does not prompt for a password.
As the user primeusr, enter the following commands:
–![]() (On the Standby server only) Enter the following command:
(On the Standby server only) Enter the following command:
where standby-server-hostname is the hostname of the standby server.
–![]() Verify that the SSH is working and does not prompt for authentication or a password (using both the hostname and IP address).
Verify that the SSH is working and does not prompt for authentication or a password (using both the hostname and IP address).
–![]() If you are prompted to continue connecting, enter yes. (The prompt should appear only the first time you use SSH to connect to the server).
If you are prompted to continue connecting, enter yes. (The prompt should appear only the first time you use SSH to connect to the server).
–![]() Make sure all the lines in /opt/primecentral/local/disaster_recovery/rsync/fm/includeSync.txt file, on the primary server, are uncommented (which were commented during Step 1).
Make sure all the lines in /opt/primecentral/local/disaster_recovery/rsync/fm/includeSync.txt file, on the primary server, are uncommented (which were commented during Step 1).
i.![]() Configure Fault Management to send 3GPP alarm notifications to Northbound Interface for both primary and standby server:
Configure Fault Management to send 3GPP alarm notifications to Northbound Interface for both primary and standby server:
j.![]() Restart the Prime Central Fault Management:
Restart the Prime Central Fault Management:
Note![]() If centraladmin user’s password is changed, run Step j with the new password.
If centraladmin user’s password is changed, run Step j with the new password.
Fault Management for Disaster Recovery Synchronization Failure
This feature helps the user to get an alarm/notification if sync fails between the primary and the standby node.
If database synchronization fails, an alarm is sent to the user notifying the database sync failure along with the possible reason for failure. See Figure 3-1.
Figure 3-1 Database Synchronization Failure Alarm

If file synchronization fails, an alarm is sent to the user notifying the same.
Below is the list of alarms supported for Disaster Recovery Sync Failure:
Note![]() File Sync and DB Sync alarms are ADMC (Automatic Delivery Manual Clear).
File Sync and DB Sync alarms are ADMC (Automatic Delivery Manual Clear).
Configuring Monitoring Frequency and Email Notifications
Even though the values you configure while completing this procedure are automatically synchronized between the primary and standby servers, we recommend that you verify this has taken place. Note that the first time you initiate file synchronization, it can take 5 to 10 minutes for the process to start.
Step 1![]() Configure the monitoring frequency value.
Configure the monitoring frequency value.
By default, this value is set to 5 minutes for application, file synchronization, and data replication monitoring. If you want to keep this as is, proceed to Step 2. If you want to set another value, do the following:
a.![]() Log into the primary server as the root user.
Log into the primary server as the root user.
b.![]() Enter the following commands:
Enter the following commands:
c.![]() Open primeusr-home-directory/local/cron/app_mon/conf/frequency_conf and set the desired monitoring frequency value (in minutes) for the following parameters:
Open primeusr-home-directory/local/cron/app_mon/conf/frequency_conf and set the desired monitoring frequency value (in minutes) for the following parameters:
–![]() RSYNC_FREQUENCY (file synchronization)
RSYNC_FREQUENCY (file synchronization)
–![]() DBMON_FREQUENCY (data replication)
DBMON_FREQUENCY (data replication)
d.![]() Enter the following commands:
Enter the following commands:
Step 2![]() Open primeusr-home-directory/local/disaster_recovery/scripts/cron/app_mon/conf/email_config and specify the users that will be notified via email whenever an event occurs, as well as the email address from which these messages will be sent.
Open primeusr-home-directory/local/disaster_recovery/scripts/cron/app_mon/conf/email_config and specify the users that will be notified via email whenever an event occurs, as well as the email address from which these messages will be sent.
A sample email_config file looks like this:
EMAIL_IDS=email_id1@example.com email_id2@example.com (recipients of application monitoring messages)
DB_ EMAIL_IDS=email_id1@example.com email_id2@example.com (recipients of database monitoring messages)
SENDER_EMAIL=source@example.com (sender of application monitoring messages)
DB_SENDER_EMAIL=source@example.com (sender of database monitoring messages)
- The Application Monitor uses the sendmail email client. Verify that sendmail has been properly configured to send notification emails.
- Ensure that each recipient’s email address is separated by a space.
- You can specify an email alias, provided that it is a valid email address.
- Only one sender email address can be configured at any given time.
- After setup, check your email client’s junk folder for any failover-related messages. If necessary, set similar messages as being safe to read.
- If the primary server, standby server, or VM belongs to a lab where DNS configuration is not available, open /etc/hosts and add the following entry:
Checking the Status of Disaster Recovery Node
To check the status of the disaster recovery node, follow the below steps.
Step 1![]() As the root user, log into the Primary server.
As the root user, log into the Primary server.
Step 2![]() Enter the following commands:
Enter the following commands:
Note![]() By default, the primeusr home directory is /opt/primecentral. You can specify another directory, if necessary.
By default, the primeusr home directory is /opt/primecentral. You can specify another directory, if necessary.
Initiating Switchover
To initiate the Switchover process for Prime Central and Fault Management servers, follow the below steps.
Step 1![]() As the root user, log into the standby server.
As the root user, log into the standby server.
Step 2![]() Enter the following commands:
Enter the following commands:
Note![]() By default, the primeusr home directory is /opt/primecentral. You can specify another directory, if necessary.
By default, the primeusr home directory is /opt/primecentral. You can specify another directory, if necessary.
Note![]() To make crosslaunch work on upgrade setup, de-register and register the Prime Network after Prime Central and Prime Network switchover.
To make crosslaunch work on upgrade setup, de-register and register the Prime Network after Prime Central and Prime Network switchover.
Initiating Failover
To initiate the Failover process for Prime Central and Fault Management servers, follow the below steps.
Step 1![]() As the root user, log into the standby server.
As the root user, log into the standby server.
Step 2![]() Enter the following commands:
Enter the following commands:
Note![]() By default, the primeusr home directory is /opt/primecentral. You can specify another directory, if necessary. Also, External Oracle Database configuration is supported only in standalone configuration and this External Oracle Database configuration is not supported with Prime Central DR configuration.
By default, the primeusr home directory is /opt/primecentral. You can specify another directory, if necessary. Also, External Oracle Database configuration is supported only in standalone configuration and this External Oracle Database configuration is not supported with Prime Central DR configuration.
Note![]() After failover, if “DR sync failed. Database is not a logical standy” alarm appears in the alarm browser, ignore it and clear the alarm manually.
After failover, if “DR sync failed. Database is not a logical standy” alarm appears in the alarm browser, ignore it and clear the alarm manually.
Initiating Failback
When a server that was previously brought into failover is operational again, and all of the geographical disaster recovery installation data present before the server failed (which includes the entire database and all of the files in the primeusr home directory) has been fully restored, it is ready for failback. Complete the following procedure on that server to reinstate it as the primary server.
Step 1![]() If the server’s data is totally erased, you first need to complete the procedure described in Configuring Prime Central for Geographical Disaster Recovery and Configuring Prime Central Fault Management for Geographical Disaster Recovery. For Prime Central, after you enter./pc_standby_setup.sh command, the installer detects that you are reinstalling Prime Central on the server you are reinstating as the primary server. When prompted, enter Y to proceed with the installation.
If the server’s data is totally erased, you first need to complete the procedure described in Configuring Prime Central for Geographical Disaster Recovery and Configuring Prime Central Fault Management for Geographical Disaster Recovery. For Prime Central, after you enter./pc_standby_setup.sh command, the installer detects that you are reinstalling Prime Central on the server you are reinstating as the primary server. When prompted, enter Y to proceed with the installation.
Step 2![]() As the root user, log into the server you want to reinstate as the primary server.
As the root user, log into the server you want to reinstate as the primary server.
Step 3![]() Enter the following commands:
Enter the following commands:
Note![]() After failback, if Domain Manager is down in suite-monitoring or if cross-launch fails, de-register and register the respective Domain Manager.
After failback, if Domain Manager is down in suite-monitoring or if cross-launch fails, de-register and register the respective Domain Manager.
Integrating Applications with the Standby Server
Complete the following procedure to integrate applications such as Prime Network and Prime Optical with the standby server.
Step 1![]() Determine the instance ID of the application on the primary server you want to integrate. To do so, run the list command as the user primeusr.
Determine the instance ID of the application on the primary server you want to integrate. To do so, run the list command as the user primeusr.
Say you want to integrate Prime Network. In the following example, Prime Network’s instance ID value is 8.
Step 2![]() Enter one of the following commands, depending on whether you want to specify the necessary values when prompted by the script (in Interactive mode) or all at once (in Non-interactive mode):
Enter one of the following commands, depending on whether you want to specify the necessary values when prompted by the script (in Interactive mode) or all at once (in Non-interactive mode):
–![]() server is the IP address of the standby Prime Central database server
server is the IP address of the standby Prime Central database server
–![]() db-service-name is the standby Prime Central database service name (for an embedded Oracle database, the default is primedb)
db-service-name is the standby Prime Central database service name (for an embedded Oracle database, the default is primedb)
–![]() db-user is the username of the standby Prime Central database user
db-user is the username of the standby Prime Central database user
–![]() db-password is the password of the standby Prime Central database user
db-password is the password of the standby Prime Central database user
–![]() port is the port number of the standby Prime Central database port
port is the port number of the standby Prime Central database port
–![]() dm_id is the instance ID value you obtained in Step 1.
dm_id is the instance ID value you obtained in Step 1.
Upgrading to Prime Central 2.1 and Prime Central Fault Management 2.1 in a Geographical Disaster Recovery
Step 1![]() Stop application monitoring, data replication monitoring and file synchronization on Primary Server.
Stop application monitoring, data replication monitoring and file synchronization on Primary Server.
a.![]() Log into the primary server as the root user.
Log into the primary server as the root user.
b.![]() Enter the following commands:
Enter the following commands:
c.![]() Log into the primary server as the user primeusr.
Log into the primary server as the user primeusr.
d.![]() Enter the following command:
Enter the following command:
Note![]() As part of Prime Central release 2.0, direct upgrade from 1.5.1 to 2.1.0, 1.5.2 to 2.1.0, 1.5.3 to 2.1.0 and 2.0.0 to 2.1.0 are supported.
As part of Prime Central release 2.0, direct upgrade from 1.5.1 to 2.1.0, 1.5.2 to 2.1.0, 1.5.3 to 2.1.0 and 2.0.0 to 2.1.0 are supported.
Step 2![]() If you are performing direct upgrade of Prime Central or Prime Central Fault Management from 1.5.3,or 1.5.2, or 1.5.1 to 2.1.0, follow the below direct upgrade steps mentioned in the Table 3-2
If you are performing direct upgrade of Prime Central or Prime Central Fault Management from 1.5.3,or 1.5.2, or 1.5.1 to 2.1.0, follow the below direct upgrade steps mentioned in the Table 3-2
Table 3-2 Direct Upgrade Steps
|
|
|
|
|
|
|
|---|---|---|---|---|---|
Step 1: Uninstall Prime Central Fault Management 2.0 from standby server |
Cisco Prime Central 2.0 Quick Start Guide for uninstalling process. |
||||
Cisco Prime Central 2.0 Quick Start Guide for uninstalling process. |
|||||
Step 3: Upgrade Prime Central 2.0 to Prime Central 2.1 on primary server |
Cisco Prime Central 2.1 Quick Start Guide for upgrading process |
||||
Step 4: Upgrade Prime Central Fault Management 2.0 to Prime Central Fault Management 2.1 on primary server |
Cisco Prime Central 2.1 Quick Start Guide for upgrading process. |
||||
Step 1: Uninstall Prime Central Fault Management 1.5.3 from standby server |
Cisco Prime Central 1.5.3 Quick Start Guide for uninstalling process. |
||||
Cisco Prime Central 1.5.3 Quick Start Guide for uninstalling process. |
|||||
Step 3: Upgrade Prime Central 1.5.3 to Prime Central 2.1 on primary server |
Cisco Prime Central 2.1 Quick Start Guide for upgrading process. |
||||
Step 4: Upgrade Prime Central Fault Management 1.5.3 to Prime Central Fault Management 2.1 on primary server |
Cisco Prime Central 2.1 Quick Start Guide for upgrading process. |
||||
Step 1: Uninstall Prime Central Fault Management 1.5.2 from standby server |
Cisco Prime Central 1.5.2 Quick Start Guide for uninstalling process. |
||||
Cisco Prime Central 1.5.2 Quick Start Guide for uninstalling process. |
|||||
Step 3: Upgrade Prime Central 1.5.2 to Prime Central 2.1 on primary server. |
Cisco Prime Central 2.1 Quick Start Guide for upgrading process. |
||||
Step 4: Upgrade Prime Central Fault Management 1.5.2 to Prime Central Fault Management 2.1 on primary server. |
Cisco Prime Central 2.1 Quick Start Guide for upgrading process. |
||||
Step 1: Uninstall Prime Central Fault Management 1.5.1 from standby server |
Cisco Prime Central 1.5.1 Quick Start Guide for uninstalling process. |
||||
Cisco Prime Central 1.5.1 Quick Start Guide for uninstalling process. |
|||||
Step 3: Upgrade Prime Central 1.5.1 to Prime Central 2.1 on primary server. |
Cisco Prime Central 1.5.1 Quick Start Guide for upgrading process. |
||||
Step 4: Upgrade Prime Central Fault Management 1.5.1 to Prime Central Fault Management 2.1 on primary server. |
Cisco Prime Central 1.5.1 Quick Start Guide for upgrading process. |
||||
Step 3![]() Perform Disaster Recovery setup of Prime Central 2.1 on standby server. Refer to Configuring Prime Central for Geographical Disaster Recovery for setup instructions.
Perform Disaster Recovery setup of Prime Central 2.1 on standby server. Refer to Configuring Prime Central for Geographical Disaster Recovery for setup instructions.
Step 4![]() Perform Disaster Recovery setup of Prime Central Fault Management 2.1 on standby server. Refer to section Configuring Prime Central Fault Management for Geographical Disaster Recovery for setup instructions.
Perform Disaster Recovery setup of Prime Central Fault Management 2.1 on standby server. Refer to section Configuring Prime Central Fault Management for Geographical Disaster Recovery for setup instructions.
Upgrading RHEL Operating System
The Operating System (OS) upgrade procedure supports Prime Central 1.5.1 customers to perform upgrade of Operating System from RHEL 5.8 to 6.5 and inline upgrade from RHEL 6.5 to 6.7. For more information, refer the Cisco Prime Central RHEL Operating System Upgrade guide.
Geographical Disaster Recovery Implementation:
Best Practices and Troubleshooting Information
- During geographical disaster recovery setup, refer to the log files located in the logs folder (which resides in the same folder as the setup scripts).
- While geographical disaster recovery is taking place, refer to the logs here: primeusr-home-directory/local/disaster_recovery/logs
Problem Prerequisites check failed.
Solution Make sure the server meets all required specifications in terms of:
Problem Environment setup failed.
- Make sure you run the script as the root user.
- Verify whether the Expect Unix tool is installed. If not, check the log files in the logs folder for any errors that occurred.
Problem Oracle database standby setup failed.
Solution Make sure that database backups and archive logs are enabled on the primary server.
1.![]() Log into the primary server as the user primeusr.
Log into the primary server as the user primeusr.
2.![]() Enter the following command:
Enter the following command:
If any errors occur, please refer to the Cisco Prime Central 2.1 Quick Start Guide for more troubleshooting information.
If backups are already enabled but the Oracle database standby setup failed:
1.![]() Log into the database server as the user oracle.
Log into the database server as the user oracle.
2.![]() Enter the following command:
Enter the following command:
3.![]() Check the log file named PCoracleADG.ksh_*.log for any errors, where * refers to the latest available log file.
Check the log file named PCoracleADG.ksh_*.log for any errors, where * refers to the latest available log file.
4.![]() Once the errors have been identified and resolved, clean up the server and run the geographical disaster recovery setup process again.
Once the errors have been identified and resolved, clean up the server and run the geographical disaster recovery setup process again.
Problem Application Monitor always reports that the File Sync operation failed.
Solution Make sure that trust has been established between the primary and standby servers for the user primeusr. If you need to establish trust, perform the tasks described in Step 2g of Configuring Prime Central for Geographical Disaster Recovery.
Problem Prime Central and Fault Management failback reports that the File Sync operation failed.
Solution Make sure that trust has been established between the primary and standby servers for the user primeusr. If you need to establish trust, perform the tasks described in Step 2g of Configuring Prime Central for Geographical Disaster Recovery.
Problem Prime Central installation on the standby server failed.
- The standby server meets all prerequisites.
- You entered the right passwords when prompted by the installer.
- The server is configured for DNS configured or the /etc/hosts file has the right information.
Refer to the Cisco Prime Central 2.1 Quick Start Guide for installation troubleshooting information.
Problem Application integration on the standby server failed.
Solution Make sure that the application’s ID value specified during the integration process is valid. To check, perform the steps described in application’s integration guide.
Solution Make sure that both the primary and standby nodes can communicate via SSH without authentication (the process is described in Step 2g of Configuring Prime Central for Geographical Disaster Recovery). To view more details on the Rsync failure, navigate to primeusr-home-directory/local/disaster_recovery/logs and open app_mon.log.
Problem Information for the integration layer is not found in the standby database.
Solution Run the following commands:
Problem Oracle database restore fails on Standby (Inactive) server after performing database restore on Primary (Active) server.
Solution Run the following commands as root user on the Standby (Inactive) server:
Problem Prime Central and Fault Management installation in the Discover Recovery (DR) site failed with the following error log found in “install-directory/IBM_Tivoli_Netcool_OMNIbus_Web_GUI_Install-00.log”
Solution Perform the following steps:
1.![]() On the Primary server, comment out all the lines in the file:
On the Primary server, comment out all the lines in the file:
2.![]() On the Standby server, check if there is any left behind fault management process even after the un-installation, by using the below command:
On the Standby server, check if there is any left behind fault management process even after the un-installation, by using the below command:
Kill the process if any, by using the below command:
3.![]() Delete the faultmgmt folder.
Delete the faultmgmt folder.
Problem After initiating either switchover, failover, or failback, PC alarms from the current inactive server are present in the current active server.
Solution Ignore and manually clear the PC alarms.
Note![]() This solution is applicable only for alarms raised by PrimeCentral (ex:Csv file download failure alarms or DM down alarms) and not for the alarms coming from Domain Manager.
This solution is applicable only for alarms raised by PrimeCentral (ex:Csv file download failure alarms or DM down alarms) and not for the alarms coming from Domain Manager.
Problem How to avoid netcool imapct hang?
Solution Increase the heap size of netcool impact to better its performance in production environment. To increase the heap size follow the below steps:
1.![]() Enable debug logs in netcool impact
Enable debug logs in netcool impact
a.![]() Set the PolicyLogger for problem determination:
Set the PolicyLogger for problem determination:
–![]() Launch Impact GUI interface (http://FMHOST:9080/nci/main)
Launch Impact GUI interface (http://FMHOST:9080/nci/main)
–![]() Select the PolicyLogger under Service Status
Select the PolicyLogger under Service Status
Configure the following options and Save:
Pre-execution Action Module Parameters
Post-execution Action Module Parameters
–![]() Check policy Profiling enabled
Check policy Profiling enabled
Append Policy Name to log file
b.![]() Edit the $NCHOME/eWAS/properties/log4j.properties file:
Edit the $NCHOME/eWAS/properties/log4j.properties file:
log4j.appender.NETCOOL.threshold=DEBUG
log4j.category.com.micromuse=DEBUG,NETCOOL,NETCOOL-ERRORS
log4j.appender.NETCOOL.maxBackupIndex=10
log4j.appender.NETCOOL.maxFileSize=20MB
2.![]() To increase the heap size, follow the steps specified below:
To increase the heap size, follow the steps specified below:
b.![]() (optional) If the server is not running, use the following:
(optional) If the server is not running, use the following:
c.![]() Enter the following commands at the comnad prompt (wsadmin>):
Enter the following commands at the comnad prompt (wsadmin>):
–![]() wsadmin>jvm=AdminConfig.list("JavaVirtualMachine").split("\r\n") [0]
wsadmin>jvm=AdminConfig.list("JavaVirtualMachine").split("\r\n") [0]
–![]() wsadmin>AdminConfig.modify(jvm, '[[maximumHeapSize 3000]]')
wsadmin>AdminConfig.modify(jvm, '[[maximumHeapSize 3000]]')
–![]() wsadmin>attr.append([['name','Xmx'], ['value','3000']])
wsadmin>attr.append([['name','Xmx'], ['value','3000']])
–![]() wsadmin>AdminConfig.modify(jvm, [['systemProperties',[]]])
wsadmin>AdminConfig.modify(jvm, [['systemProperties',[]]])
–![]() wsadmin>AdminConfig.modify(jvm, [['systemProperties',attr]])
wsadmin>AdminConfig.modify(jvm, [['systemProperties',attr]])
3.![]() Restart the impact either with fmctl stop/start impact or use the below commands after above steps:
Restart the impact either with fmctl stop/start impact or use the below commands after above steps:
–![]() cd $NCHOME/eWAS/profiles/ImpactProfile/bin
cd $NCHOME/eWAS/profiles/ImpactProfile/bin
–![]() ./stopServer.sh server1 -username wasadmin -password netcool
./stopServer.sh server1 -username wasadmin -password netcool
–![]() ./startServer.sh server1 -username wasadmin -password netcool
./startServer.sh server1 -username wasadmin -password netcool
Problem At the time of rebuilding the standby database on a HA environment, what script should be run to recover the Primary database (primedb)?
Solution 1: If you are rebuilding the standby database on HA2 when HA1 is active, use the following script:
sh PCoracleADG.ksh [PRIMARY] [STANDBY] [DB_TO_BE_DROPPED] [SYSTEM_PASSWD] [ORACLE_BASE]
[ORACLE_USER] [ARCHIVED_LOG_LOCATION] [ORACLE_DATA_FILES_LOCATION] [REDO_LOG_LOCATION]
SYSTEM_PASSWD = "grep Embedded_SYSTEM_PASS= install/conf/.db.conf"
Note: Use the command to decrypt password if encrypted:
java -cp install/utils/encryptionUtil.jar EncodeDecode decrypt 90f8006cd6bc0dde.
ARCHIVED_LOG_LOCATION = output of ‘show parameter log_archive_dest_1;&rsquo
ORACLE_DATA_FILES_LOCATION = output of ‘select name from v$datafile;&rsquo
REDO_LOG_LOCATION = output of ‘select member from v$logfile;’
Solution 2: If you are rebuilding the standby database on HA1 when HA2 is active, use the following script:
sh PCoracleADG.ksh [PRIMARY] [STANDBY] [DB_TO_BE_DROPPED] [SYSTEM_PASSWD] [ORACLE_BASE]
[ORACLE_USER] [ARCHIVED_LOG_LOCATION] [ORACLE_DATA_FILES_LOCATION] [REDO_LOG_LOCATION]
SYSTEM_PASSWD = "grep Embedded_SYSTEM_PASS= install/conf/.db.conf"
Note: Use the command to decrypt password if encrypted:
java -cp install/utils/encryptionUtil.jar EncodeDecode decrypt 90f8006cd6bc0dde.
ARCHIVED_LOG_LOCATION = output of ‘show parameter log_archive_dest_1;&rsquo
ORACLE_DATA_FILES_LOCATION = output of ‘select name from v$datafile;&rsquo
REDO_LOG_LOCATION = output of ‘select member from v$logfile;’
 Feedback
Feedback