This document describes the steps required in order to replace both of the faulty HDD drives in the server in an Ultra-M setup. This procedure applies to an OpenStack environment with the use of the NEWTON version where ESC does not manage Cisco Prime Access Registrar (CPAR) and CPAR is installed directly on the VM deployed on OpenStack.
Contributed by Karthikeyan Dachanamoorthy and Harshita Bhardwaj, Cisco Advanced Services.
Background Information
Ultra-M is a pre-packaged and validated virtualized mobile packet core solution designed to simplify the deployment of VNFs. OpenStack is the Virtualized Infrastructure Manager (VIM) for Ultra-M and consists of these node types:
- Compute
- Object Storage Disk - Compute (OSD - Compute)
- Controller
- OpenStack Platform - Director (OSPD)
The high-level architecture of Ultra-M and the components involved are depicted in this image:
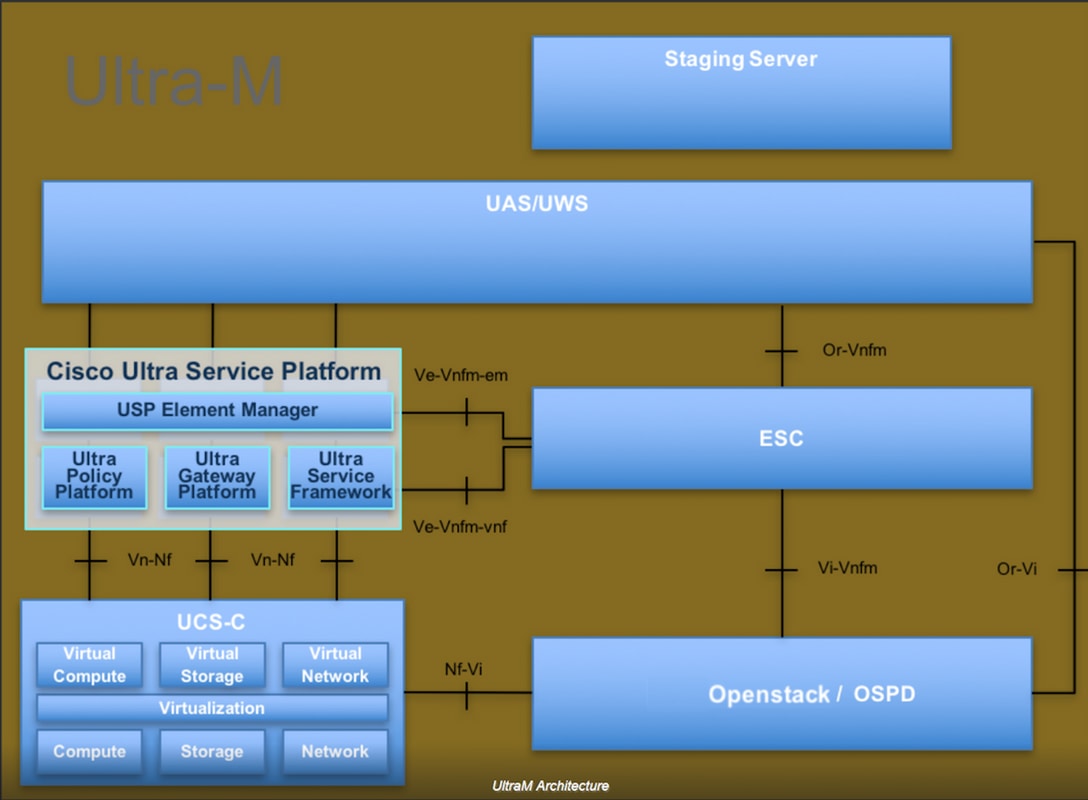
This document is intended for the Cisco personnel who are familiar with Cisco Ultra-M platform and it details the steps required to be carried out at OpenStack and Redhat OS.
Note: Ultra M 5.1.x release is considered in order to define the procedures in this document.
Abbreviations
| MOP |
Method of Procedure |
| OSD |
Object Storage Disks
|
| OSPD |
OpenStack Platform Director
|
| HDD |
Hard Disk Drive |
| SSD |
Solid State Drive |
| VIM |
Virtual Infrastructure Manager |
| VM |
Virtual Machine |
| EM |
Element Manager |
| UAS |
Ultra Automation Services |
| UUID |
Universally Unique Identifier |
Both HDDs Failure
Each bare-metal server will be provisioned with two HDD drives in order to act as BOOT DISK in Raid 1 configuration. In case of single HDD failure, since there is RAID 1 level redundancy, the faulty HDD drive can be hot swapped. However, when both the HDD drives fail, the server will be down and you will lose the access to the server. In order to restore the access to the server and the services, it is required to replace both the HDDs drives and add the server to overcloud stack that already exists.
The procedure to replace a faulty component on UCS C240 M4 server can be referred from: Replacing the Server Components.
In case of both HDDs failure, replace only these two faulty HDDs in the same UCS 240M4 server, hence BIOS upgrade procedure is not required after you replace the new disks.
In OpenStack based Ultra-M solution, UCS 240M4 bare-metal server can take up one of these roles: Compute, OSD-Compute, Controller and OSPD. The steps required in order to handle both HDD failures in each of these server roles are mentioned in these sections.
Note: In scenarios where both HDD disks are healthy but some other hardware is faulty in UCS 240M4 server, replace the UCS 240M4 with new hardware but re-use the same HDD drives. However, in this case, only the HDD drives are faulty, so you can re-use the same UCS 240M4 and replace the faulty HDD drives with new HDD drives.
Both HDDs Failure on Compute Server
If the failure of both HDD drives is observed in UCS 240M4 that acts as a Compute node, follow the replacement procedure as given in .
Both HDDs Failure on Controller Server
If the failure of both HDD drives is observed in UCS 240M4 that acts as a Controller node, follow the replacement procedure as given in . Since the controller server that observes both HDDs failure will be not reachable via Secure Shell (SSH), you can log in another Controller node in order to perform the graceful shutdown procedure listed in the previously mentioned link.
Both HDDs Failure on OSD-Compute Server
If the failure of both HDD drives is observed in UCS 240M4 that acts as an OSD-Compute node, follow the replacement procedure as given in . In the procedure mentioned here, Ceph storage graceful shutdown cannot be performed as both the failures result in unreachability of the server. Therefore, ignore these steps.
Both HDDs Failure on OSPD Server
If the failure of both HDD drives is observed in UCS 240M4 that acts as an OSPD node, follow the replacement procedure as given in . In this case, the previously stored OSPD backup is needed for restoration after HDD disk replacement, else it will be like complete stack re-deployment.
Refer to this .
 Feedback
Feedback