Ersatz für OSD-Compute UCS 240M4 - vEPC
Download-Optionen
-
ePub (1.3 MB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
Einleitung
In diesem Dokument werden die Schritte beschrieben, die erforderlich sind, um einen fehlerhaften OSD-Compute-Server (Object Storage Disk) in einem Ultra-M-Setup auszutauschen, das StarOS Virtual Network Functions (VNFs) hostet.
Hintergrundinformationen
Ultra-M ist eine vorkonfigurierte und validierte virtualisierte Mobile Packet Core-Lösung, die die Bereitstellung von VNFs vereinfacht. OpenStack ist der Virtualized Infrastructure Manager (VIM) für Ultra-M und besteht aus den folgenden Knotentypen:
- Computing
- OSD = Computing
- Controller
- OpenStack-Plattform - Director (OSPD)
Die High-Level-Architektur von Ultra-M und die beteiligten Komponenten sind in diesem Bild dargestellt:
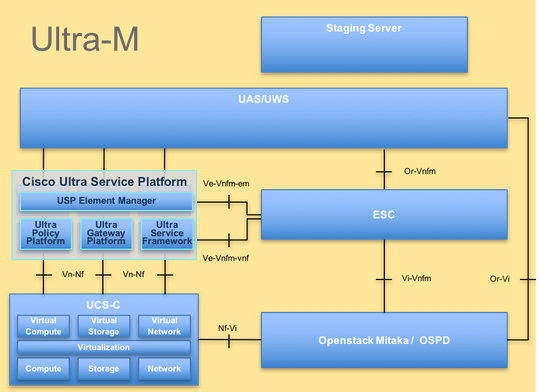
Dieses Dokument richtet sich an Cisco Mitarbeiter, die mit der Cisco Ultra-M-Plattform vertraut sind. Es beschreibt die Schritte, die auf der OpenStack- und StarOS VNF-Ebene zum Zeitpunkt des Ersatzes des Compute-Servers durchgeführt werden müssen.
Anmerkung: Die Ultra M 5.1.x-Version wird bei der Definition der in diesem Dokument beschriebenen Verfahren berücksichtigt.
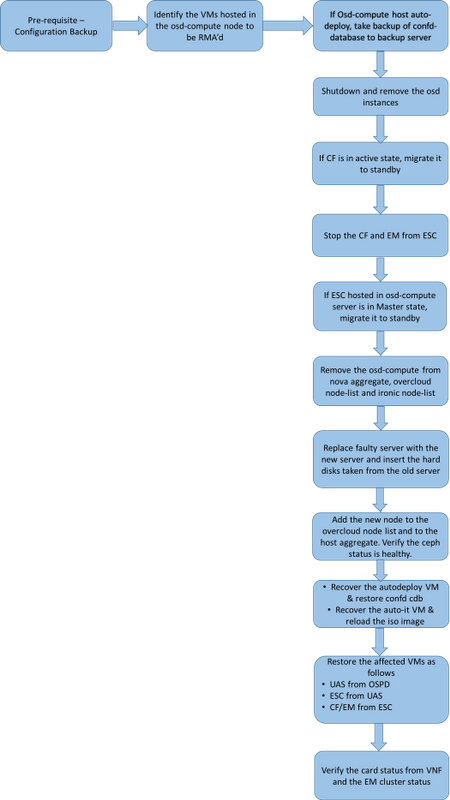
Workflow des MoP
Abkürzungen
| VNF | Virtuelle Netzwerkfunktion |
| KF | Kontrollfunktion |
| SF | Dienstfunktion |
| WSA | Elastischer Service-Controller |
| MOPP | Verfahrensweise |
| OSD | Objektspeicherplatten |
| Festplatte | Festplattenlaufwerk |
| SSD | Solid-State-Laufwerk |
| VIM | Manager für virtuelle Infrastruktur |
| VM | Virtuelles System |
| EM | Element-Manager |
| USA | Ultra-Automatisierungsservices |
| UUID | Universeller eindeutiger IDentifier |
Voraussetzungen
Backup-OSPD
Bevor Sie einen OSD-Compute-Knoten ersetzen, ist es wichtig, den aktuellen Status Ihrer Red Hat OpenStack Platform-Umgebung zu überprüfen. Es wird empfohlen, den aktuellen Status zu überprüfen, um Komplikationen zu vermeiden, wenn der Compute-Ersetzungsvorgang aktiviert ist. Dies kann durch diesen Austausch erreicht werden.
Im Falle einer Wiederherstellung empfiehlt Cisco, eine Sicherung der OSPD-Datenbank mit den folgenden Schritten durchzuführen:
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
Dieser Prozess stellt sicher, dass ein Knoten ersetzt werden kann, ohne die Verfügbarkeit von Instanzen zu beeinträchtigen. Außerdem wird empfohlen, die StarOS-Konfiguration zu sichern, insbesondere wenn der zu ersetzende Knoten "Berechnen" den virtuellen Rechner mit CF hostet.
Identifizieren der im OSD-Rechenknoten gehosteten VMs
Identifizieren Sie die VMs, die auf dem Compute-Server gehostet werden. Es gibt zwei Möglichkeiten:
Der OSD-Compute-Server enthält eine Kombination aus VMs (EM/UAS/Auto-Deploy/Auto-IT):
[stack@director ~]$ nova list --field name,host | grep osd-compute-0
| c6144778-9afd-4946-8453-78c817368f18 | AUTO-DEPLOY-VNF2-uas-0 | pod1-osd-compute-0.localdomain |
| 2d051522-bce2-4809-8d63-0c0e17f251dc | AUTO-IT-VNF2-uas-0 | pod1-osd-compute-0.localdomain |
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-osd-compute-0.localdomain |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-osd-compute-0.localdomain |
Der Compute-Server enthält eine Kombination aus CF/ESC/EM/UAS VMs:
[stack@director ~]$ nova list --field name,host | grep osd-compute-1
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain |
Anmerkung: In der hier gezeigten Ausgabe entspricht die erste Spalte der UUID, die zweite Spalte ist der VM-Name und die dritte Spalte ist der Hostname, in dem die VM vorhanden ist. Die Parameter aus dieser Ausgabe werden in den nachfolgenden Abschnitten verwendet.
Prüfen Sie, ob Ceph über die verfügbare Kapazität verfügt, damit ein einziger OSD-Server entfernt werden kann:
[root@pod1-osd-compute-1 ~]# sudo ceph df
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
13393G 11804G 1589G 11.87
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
rbd 0 0 0 3876G 0
metrics 1 4157M 0.10 3876G 215385
images 2 6731M 0.17 3876G 897
backups 3 0 0 3876G 0
volumes 4 399G 9.34 3876G 102373
vms 5 122G 3.06 3876G 31863
Überprüfen Sie, ob der Status von ceph osd tree auf dem OSD-Compute-Server aktiv ist:
[heat-admin@pod1-osd-compute-1 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 4.35999 host pod1-osd-compute-2
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-1
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
Ceph-Prozesse sind auf dem OSD-Compute-Server aktiv:
[root@pod1-osd-compute-1 ~]# systemctl list-units *ceph*
UNIT LOAD ACTIVE SUB DESCRIPTION
var-lib-ceph-osd-ceph\x2d11.mount loaded active mounted /var/lib/ceph/osd/ceph-11
var-lib-ceph-osd-ceph\x2d2.mount loaded active mounted /var/lib/ceph/osd/ceph-2
var-lib-ceph-osd-ceph\x2d5.mount loaded active mounted /var/lib/ceph/osd/ceph-5
var-lib-ceph-osd-ceph\x2d8.mount loaded active mounted /var/lib/ceph/osd/ceph-8
ceph-osd@11.service loaded active running Ceph object storage daemon
ceph-osd@2.service loaded active running Ceph object storage daemon
ceph-osd@5.service loaded active running Ceph object storage daemon
ceph-osd@8.service loaded active running Ceph object storage daemon
system-ceph\x2ddisk.slice loaded active active system-ceph\x2ddisk.slice
system-ceph\x2dosd.slice loaded active active system-ceph\x2dosd.slice
ceph-mon.target loaded active active ceph target allowing to start/stop all ceph-mon@.service instances at once
ceph-osd.target loaded active active ceph target allowing to start/stop all ceph-osd@.service instances at once
ceph-radosgw.target loaded active active ceph target allowing to start/stop all ceph-radosgw@.service instances at once
ceph.target loaded active active ceph target allowing to start/stop all ceph*@.service instances at once
Deaktivieren und stoppen Sie jede Ceph-Instanz, entfernen Sie jede Instanz aus dem OSD, und heben Sie die Bereitstellung des Verzeichnisses auf. Für jede Ceph-Instanz wiederholen:
[root@pod1-osd-compute-1 ~]# systemctl disable ceph-osd@11
[root@pod1-osd-compute-1 ~]# systemctl stop ceph-osd@11
[root@pod1-osd-compute-1 ~]# ceph osd out 11
marked out osd.11.
[root@pod1-osd-compute-1 ~]# ceph osd crush remove osd.11
removed item id 11 name 'osd.11' from crush map
[root@pod1-osd-compute-1 ~]# ceph auth del osd.11
updated
[root@pod1-osd-compute-1 ~]# ceph osd rm 11
removed osd.11
[root@pod1-osd-compute-1 ~]# umount /var/lib/ceph.osd/ceph-11
[root@pod1-osd-compute-1 ~]# rm -rf /var/lib/ceph.osd/ceph-11
Oder
Das Clean.sh-Skript kann verwendet werden, um diese Aufgabe auszuführen:
[heat-admin@pod1-osd-compute-0 ~]$ sudo ls /var/lib/ceph/osd
ceph-11 ceph-3 ceph-6 ceph-8
[heat-admin@pod1-osd-compute-0 ~]$ /bin/sh clean.sh
[heat-admin@pod1-osd-compute-0 ~]$ cat clean.sh
#!/bin/sh
set -x
CEPH=`sudo ls /var/lib/ceph/osd`
for c in $CEPH
do
i=`echo $c |cut -d'-' -f2`
sudo systemctl disable ceph-osd@$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo systemctl stop ceph-osd@$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph osd out $i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph osd crush remove osd.$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph auth del osd.$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph osd rm $i || (echo "error rc:$?"; exit 1)
sleep 2
sudo umount /var/lib/ceph/osd/$c || (echo "error rc:$?"; exit 1)
sleep 2
sudo rm -rf /var/lib/ceph/osd/$c || (echo "error rc:$?"; exit 1)
sleep 2
done
sudo ceph osd tree
Nachdem alle OSD-Prozesse migriert/gelöscht wurden, kann der Knoten aus der Overcloud entfernt werden.
Hinweis: Wenn Ceph entfernt wird, wechselt VNF HD RAID in den Status "Degraded" (Heruntergestuft), aber die HD-Festplatte muss weiterhin zugänglich sein.
Sicheres Ausschalten
Fall 1: OSD-Rechenknoten-Hosts CF/ESC/EM/US
CF-Karte in Standby-Status migrieren
Melden Sie sich bei StarOS VNF an, und identifizieren Sie die Karte, die dem virtuellen Rechner für CF entspricht. Verwenden Sie die UUID der CF VM, die im Abschnitt Identifizieren Sie die VMs, die im OSD-Rechenknoten gehostet werden, und suchen Sie die Karte, die der UUID entspricht.
[local]VNF2# show card hardware
Tuesday might 08 16:49:42 UTC 2018
<snip>
Card 2:
Card Type : Control Function Virtual Card
CPU Packages : 8 [#0, #1, #2, #3, #4, #5, #6, #7]
CPU Nodes : 1
CPU Cores/Threads : 8
Memory : 16384M (qvpc-di-large)
UUID/Serial Number : F9C0763A-4A4F-4BBD-AF51-BC7545774BE2
<snip>
Überprüfen Sie den Status der Karte:
[local]VNF2# show card table
Tuesday might 08 16:52:53 UTC 2018
Slot Card Type Oper State SPOF Attach
----------- -------------------------------------- ------------- ---- ------
1: CFC Control Function Virtual Card Standby -
2: CFC Control Function Virtual Card Active No
3: FC 4-Port Service Function Virtual Card Active No
4: FC 4-Port Service Function Virtual Card Active No
5: FC 4-Port Service Function Virtual Card Active No
6: FC 4-Port Service Function Virtual Card Active No
7: FC 4-Port Service Function Virtual Card Active No
8: FC 4-Port Service Function Virtual Card Active No
9: FC 4-Port Service Function Virtual Card Active No
10: FC 4-Port Service Function Virtual Card Standby -
Wenn sich die Karte im aktiven Zustand befindet, versetzen Sie sie in den Standby-Zustand:
[local]VNF2# card migrate from 2 to 1
Herunterfahren von CF und EM VM aus ESC
Melden Sie sich beim ESC-Knoten an, der der VNF entspricht, und überprüfen Sie den Status der VMs:
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
<state>VM_ALIVE_STATE</state>
<snip>
Stoppen Sie die CF- und EM-VM einzeln mit dem VM-Namen. VM-Name angegeben aus Abschnitt Identifizieren Sie die VMs, die im OSD-Rechenknoten gehostet werden.
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea
Nach dem Beenden müssen die VMs in den SHUTOFF-Zustand übergehen:
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_SHUTOFF_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
VM_SHUTOFF_STATE
<snip>
ESC in Standby-Modus migrieren
Melden Sie sich beim ESC an, der im Rechenknoten gehostet ist, und überprüfen Sie, ob er sich im Master-Status befindet. Falls ja, ESC in den Standby-Modus schalten:
[admin@VNF2-esc-esc-0 esc-cli]$ escadm status
0 ESC status=0 ESC Master Healthy
[admin@VNF2-esc-esc-0 ~]$ sudo service keepalived stop
Stopping keepalived: [ OK ]
[admin@VNF2-esc-esc-0 ~]$ escadm status
1 ESC status=0 In SWITCHING_TO_STOP state. Please check status after a while.
[admin@VNF2-esc-esc-0 ~]$ sudo reboot
Broadcast message from admin@vnf1-esc-esc-0.novalocal
(/dev/pts/0) at 13:32 ...
The system is going down for reboot NOW!
OSD-Rechenknoten aus Nova Aggregate-Liste entfernen
Listen Sie die Nova-Aggregate auf, und identifizieren Sie das Aggregat, das dem Compute-Server entspricht, der auf der von ihm gehosteten VNF basiert. Normalerweise hat er das Format <VNFNAME>-EM-MGMT<X> und <VNFNAME>-CF-MGMT<X>:
[stack@director ~]$ nova aggregate-list
+----+-------------------+-------------------+
| Id | Name | Availability Zone |
+----+-------------------+-------------------+
| 29 | POD1-AUTOIT | mgmt |
| 57 | VNF1-SERVICE1 | - |
| 60 | VNF1-EM-MGMT1 | - |
| 63 | VNF1-CF-MGMT1 | - |
| 66 | VNF2-CF-MGMT2 | - |
| 69 | VNF2-EM-MGMT2 | - |
| 72 | VNF2-SERVICE2 | - |
| 75 | VNF3-CF-MGMT3 | - |
| 78 | VNF3-EM-MGMT3 | - |
| 81 | VNF3-SERVICE3 | - |
+----+-------------------+-------------------+
In diesem Fall gehört der OSD-Compute-Server zu VNF2. Die entsprechenden Aggregate wären also VNF2-CF-MGMT2 und VNF2-EM-MGMT2.
Entfernen Sie den OSD-Compute-Knoten aus dem angegebenen Aggregat:
nova aggregate-remove-host
[stack@director ~]$ nova aggregate-remove-host VNF2-CF-MGMT2 pod1-osd-compute-0.localdomain
[stack@director ~]$ nova aggregate-remove-host VNF2-EM-MGMT2 pod1-osd-compute-0.localdomain
[stack@director ~]$ nova aggregate-remove-host POD1-AUTOIT pod1-osd-compute-0.localdomain
Überprüfen Sie, ob der OSD-Compute-Knoten aus den Aggregaten entfernt wurde. Stellen Sie nun sicher, dass der Host nicht unter den Aggregaten aufgeführt ist:
nova aggregate-show
[stack@director ~]$ nova aggregate-show VNF2-CF-MGMT2
[stack@director ~]$ nova aggregate-show VNF2-EM-MGMT2
[stack@director ~]$ nova aggregate-show POD1-AUTOIT
Fall 2: OSD-Compute-Node-Hosts mit automatischer Bereitstellung/Auto-IT/EM/US
Backup des CDB für die automatische Bereitstellung
Sichern Sie regelmäßig oder nach jeder Aktivierung/Deaktivierung die autodeploy config cdb-Daten, und speichern Sie die Datei auf einem Backup-Server.Auto-Deploy ist nicht redundant und wenn diese Daten verloren gehen, wird es schwierig sein, die Bereitstellung zu deaktivieren.
Melden Sie sich beim Verzeichnis "Auto-Deploy VM" und "backup config cdb" an:
ubuntu@auto-deploy-iso-2007-uas-0:~$sudo -i
root@auto-deploy-iso-2007-uas-0:~#service uas-confd stop
uas-confd stop/waiting
root@auto-deploy-iso-2007-uas-0:~# cd /opt/cisco/usp/uas/confd-6.3.1/var/confd
root@auto-deploy-iso-2007-uas-0:/opt/cisco/usp/uas/confd-6.3.1/var/confd#tar cvf autodeploy_cdb_backup.tar cdb/
cdb/
cdb/O.cdb
cdb/C.cdb
cdb/aaa_init.xml
cdb/A.cdb
root@auto-deploy-iso-2007-uas-0:~# service uas-confd start
uas-confd start/running, process 13852
Anmerkung: Kopieren Sie autodeploy_cdb_backup.tar auf den Sicherungsserver.
Backup system.cfg von Auto-IT
Sichern Sie die Datei system.cfg auf den Backup-Server:
Auto-it = 10.1.1.2
Backup server = 10.2.2.2
[stack@director ~]$ ssh ubuntu@10.1.1.2
ubuntu@10.1.1.2's password:
Welcome to Ubuntu 14.04.3 LTS (GNU/Linux 3.13.0-76-generic x86_64)
* Documentation: https://help.ubuntu.com/
System information as of Wed Jun 13 16:21:34 UTC 2018
System load: 0.02 Processes: 87
Usage of /: 15.1% of 78.71GB Users logged in: 0
Memory usage: 13% IP address for eth0: 172.16.182.4
Swap usage: 0%
Graph this data and manage this system at:
https://landscape.canonical.com/
Get cloud support with Ubuntu Advantage Cloud Guest:
http://www.ubuntu.com/business/services/cloud
Cisco Ultra Services Platform (USP)
Build Date: Wed Feb 14 12:58:22 EST 2018
Description: UAS build assemble-uas#1891
sha1: bf02ced
ubuntu@auto-it-vnf-uas-0:~$ scp -r /opt/cisco/usp/uploads/system.cfg root@10.2.2.2:/home/stack
root@10.2.2.2's password:
system.cfg 100% 565 0.6KB/s 00:00
ubuntu@auto-it-vnf-uas-0:~$
Hinweis: Die für ein ordnungsgemäßes Herunterfahren von EM/UAS auf OSD-Compute-0 auszuführenden Verfahren sind in beiden Fällen identisch. Siehe Fall 1 für dasselbe.
OSD-Rechenknoten-Löschung
Die in diesem Abschnitt beschriebenen Schritte sind unabhängig von den im Rechenknoten gehosteten VMs üblich.
OSD-Rechenknoten aus der Serviceliste löschen
Löschen Sie den Compute-Dienst aus der Dienstliste:
[stack@director ~]$ source corerc
[stack@director ~]$ openstack compute service list | grep osd-compute-0
| 404 | nova-compute | pod1-osd-compute-0.localdomain | nova | enabled | up | 2018-05-08T18:40:56.000000 |
openstack compute service delete
[stack@director ~]$ openstack compute service delete 404
Neutronenagenten löschen
Löschen Sie den alten zugeordneten Neutronenagenten und den offenen vSwitch-Agenten für den Compute-Server:
[stack@director ~]$ openstack network agent list | grep osd-compute-0
| c3ee92ba-aa23-480c-ac81-d3d8d01dcc03 | Open vSwitch agent | pod1-osd-compute-0.localdomain | None | False | UP | neutron-openvswitch-agent |
| ec19cb01-abbb-4773-8397-8739d9b0a349 | NIC Switch agent | pod1-osd-compute-0.localdomain | None | False | UP | neutron-sriov-nic-agent |
openstack network agent delete
[stack@director ~]$ openstack network agent delete c3ee92ba-aa23-480c-ac81-d3d8d01dcc03
[stack@director ~]$ openstack network agent delete ec19cb01-abbb-4773-8397-8739d9b0a349
Aus der Nova- und Ironic-Datenbank löschen
Löschen Sie einen Knoten aus der Nova-Liste und der ironischen Datenbank, und überprüfen Sie ihn:
[stack@director ~]$ source stackrc
[stack@al01-pod1-ospd ~]$ nova list | grep osd-compute-0
| c2cfa4d6-9c88-4ba0-9970-857d1a18d02c | pod1-osd-compute-0 | ACTIVE | - | Running | ctlplane=192.200.0.114 |
[stack@al01-pod1-ospd ~]$ nova delete c2cfa4d6-9c88-4ba0-9970-857d1a18d02c
nova show| grep hypervisor
[stack@director ~]$ nova show pod1-osd-compute-0 | grep hypervisor
| OS-EXT-SRV-ATTR:hypervisor_hostname | 4ab21917-32fa-43a6-9260-02538b5c7a5a
ironic node-delete
[stack@director ~]$ ironic node-delete 4ab21917-32fa-43a6-9260-02538b5c7a5a
[stack@director ~]$ ironic node-list (node delete must not be listed now)
Aus Overcloud löschen
Erstellen Sie eine Skriptdatei mit dem Namen delete_node.sh mit dem angezeigten Inhalt. Stellen Sie sicher, dass die angegebenen Vorlagen mit den Vorlagen übereinstimmen, die im für die Stapelbereitstellung verwendeten Skript deploy.sh verwendet werden:
delete_node.sh
openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack
[stack@director ~]$ source stackrc
[stack@director ~]$ /bin/sh delete_node.sh
+ openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack pod1 49ac5f22-469e-4b84-badc-031083db0533
Deleting the following nodes from stack pod1:
- 49ac5f22-469e-4b84-badc-031083db0533
Started Mistral Workflow. Execution ID: 4ab4508a-c1d5-4e48-9b95-ad9a5baa20ae
real 0m52.078s
user 0m0.383s
sys 0m0.086s
Warten Sie auf den OpenStack-Stapelvorgang, um in den Zustand COMPLETE zu wechseln:
[stack@director ~]$ openstack stack list
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| ID | Stack Name | Stack Status | Creation Time | Updated Time |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod1 | UPDATE_COMPLETE | 2018-05-08T21:30:06Z | 2018-05-08T20:42:48Z |
+--------------------------------------+------------+-----------------+----------------------+----------------------
Installieren des neuen Rechenknotens
- Die Schritte zur Installation eines neuen UCS C240 M4 Servers und die ersten Einrichtungsschritte können wie folgt beschrieben werden:
Cisco UCS C240 M4 Serverinstallations- und Serviceleitfaden
- Legen Sie nach der Installation des Servers die Festplatten als alten Server in die entsprechenden Steckplätze ein.
- Melden Sie sich mit der CIMC-IP beim Server an.
- Führen Sie ein BIOS-Upgrade durch, wenn die Firmware nicht der zuvor verwendeten empfohlenen Version entspricht. Die Schritte für das BIOS-Upgrade sind hier aufgeführt:
BIOS-Upgrade-Leitfaden für Cisco UCS Rackmount-Server der C-Serie
- Überprüfen Sie den Status der physischen Laufwerke. Es muss sich um nicht eingestellte Ware handeln.
- Erstellen einer virtuellen Festplatte aus physischen Festplatten mit RAID-Level 1
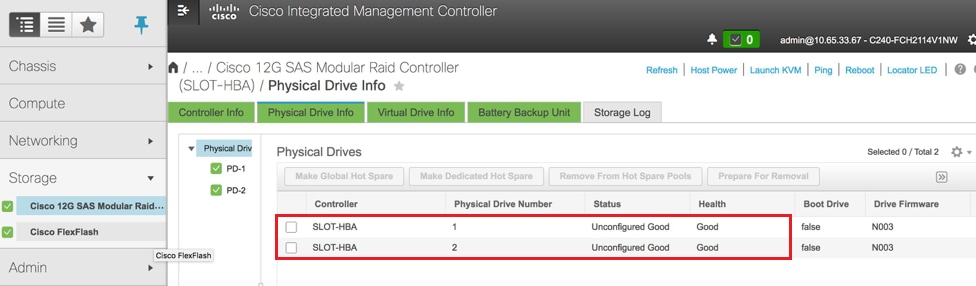 Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Informationen zu physischen Laufwerken
Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Informationen zu physischen Laufwerken
Anmerkung: Dieses Bild dient nur zur Veranschaulichung. In OSD-Compute CIMC werden sieben physische Laufwerke in den Steckplätzen (1, 2, 3, 7, 8, 9, 10) im Status "Nicht konfiguriert gut" angezeigt, da keine virtuellen Laufwerke daraus erstellt werden.
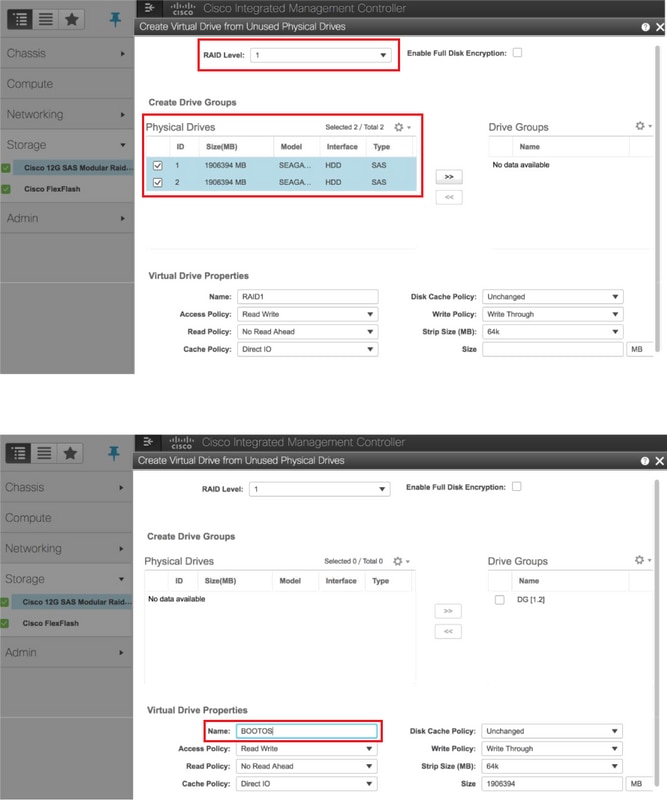 Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Controller-Informationen > Virtuelles Laufwerk aus nicht verwendeten physischen Laufwerken erstellen
Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Controller-Informationen > Virtuelles Laufwerk aus nicht verwendeten physischen Laufwerken erstellen
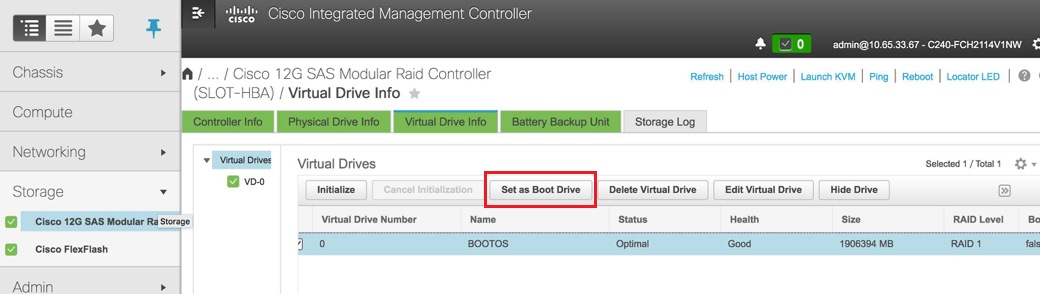 Wählen Sie das VD aus, und konfigurieren Sie "Als Boot-Laufwerk festlegen".
Wählen Sie das VD aus, und konfigurieren Sie "Als Boot-Laufwerk festlegen".
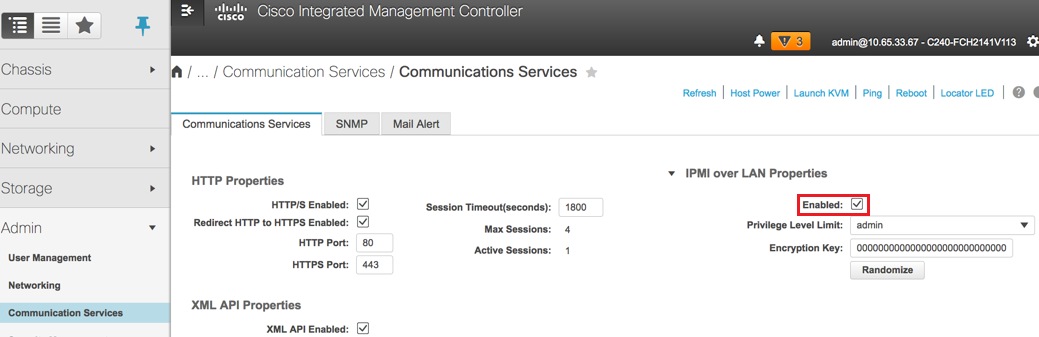 IPMI über LAN aktivieren: Admin > Kommunikationsdienste > Kommunikationsdienste
IPMI über LAN aktivieren: Admin > Kommunikationsdienste > Kommunikationsdienste
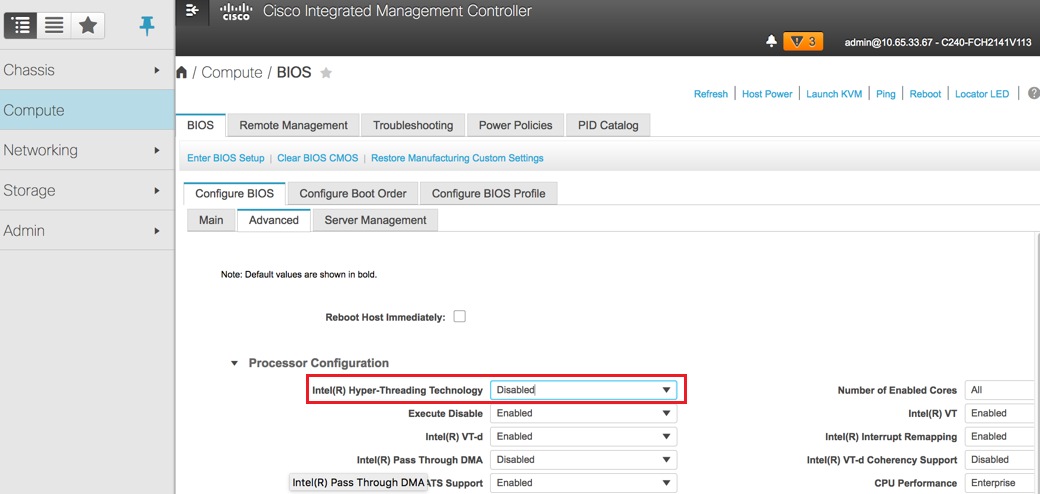 Hyperthreading deaktivieren: Computing > BIOS > BIOS konfigurieren > Erweitert > Prozessorkonfiguration
Hyperthreading deaktivieren: Computing > BIOS > BIOS konfigurieren > Erweitert > Prozessorkonfiguration
- Ähnlich wie BOOTOS VD, das mit den physischen Laufwerken 1 und 2 erstellt wurde, vier weitere virtuelle Laufwerke als
JOURNAL > Von physischem Laufwerk Nummer 3
OSD1 > Von physischem Laufwerk Nummer 7
OSD2 > Von physischem Laufwerk Nummer 8
OSD3 > Von physischem Laufwerk Nummer 9
OSD4 > Von physischem Laufwerk Nummer 10 - Am Ende müssen die physischen und virtuellen Laufwerke den im Image gezeigten ähneln:
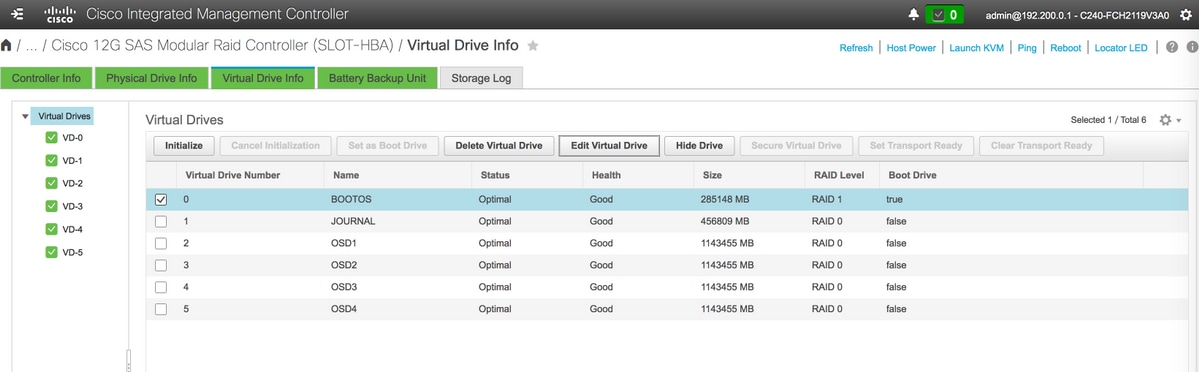 Virtuelle Laufwerke
Virtuelle Laufwerke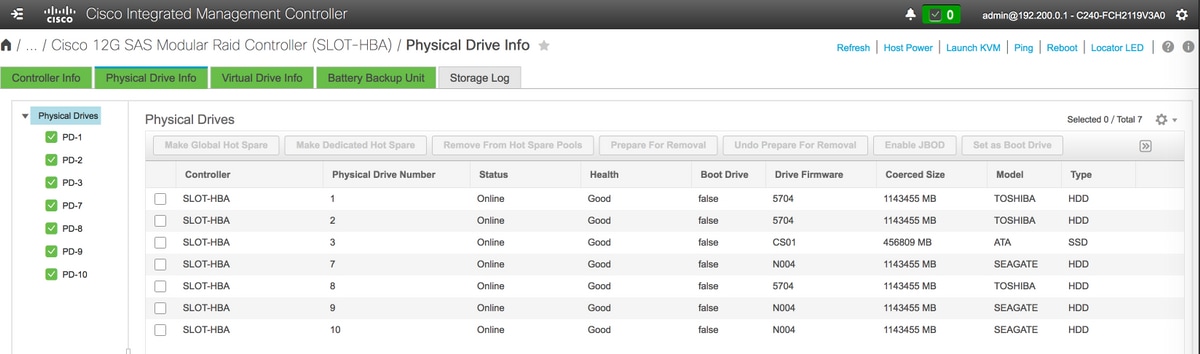 Physische Laufwerke
Physische Laufwerke
Anmerkung: Die hier abgebildete Abbildung und die in diesem Abschnitt erwähnten Konfigurationsschritte beziehen sich auf die Firmware-Version 3.0(3e), und es können geringfügige Abweichungen auftreten, wenn Sie mit anderen Versionen arbeiten.
Neuen OSD-Rechenknoten zur Overcloud hinzufügen
Die in diesem Abschnitt beschriebenen Schritte sind unabhängig von der VM, die vom Rechenknoten gehostet wird, gleich.
Hinzufügen eines Compute-Servers mit einem anderen Index.
Erstellen Sie eine Datei add_node.json, in der nur die Details des neuen Compute-Servers enthalten sind. Stellen Sie sicher, dass die Indexnummer für den neuen OSD-Compute-Server zuvor nicht verwendet wurde. Erhöhen Sie in der Regel den nächsthöheren Rechenwert.
Beispiel: Die höchste vorherige Version war OSD-Compute-0, also OSD-Compute-3 im Fall eines 2-VNF-Systems.
Anmerkung: Achten Sie auf das Format json.
[stack@director ~]$ cat add_node.json
{
"nodes":[
{
"mac":[
"<MAC_ADDRESS>"
],
"capabilities": "node:osd-compute-3,boot_option:local",
"cpu":"24",
"memory":"256000",
"disk":"3000",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"<PASSWORD>",
"pm_addr":"192.100.0.5"
}
]
}
Importieren Sie die JSON-Datei:
[stack@director ~]$ openstack baremetal import --json add_node.json
Started Mistral Workflow. Execution ID: 78f3b22c-5c11-4d08-a00f-8553b09f497d
Successfully registered node UUID 7eddfa87-6ae6-4308-b1d2-78c98689a56e
Started Mistral Workflow. Execution ID: 33a68c16-c6fd-4f2a-9df9-926545f2127e
Successfully set all nodes to available.
Führen Sie eine Knoteninspektion mit der UUID aus, die im vorherigen Schritt festgestellt wurde:
[stack@director ~]$ openstack baremetal node manage 7eddfa87-6ae6-4308-b1d2-78c98689a56e
[stack@director ~]$ ironic node-list |grep 7eddfa87
| 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | manageable | False |
[stack@director ~]$ openstack overcloud node introspect 7eddfa87-6ae6-4308-b1d2-78c98689a56e --provide
Started Mistral Workflow. Execution ID: e320298a-6562-42e3-8ba6-5ce6d8524e5c
Waiting for introspection to finish...
Successfully introspected all nodes.
Introspection completed.
Started Mistral Workflow. Execution ID: c4a90d7b-ebf2-4fcb-96bf-e3168aa69dc9
Successfully set all nodes to available.
[stack@director ~]$ ironic node-list |grep available
| 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | available | False |
Fügen Sie unter OsdComputeIPs IP-Adressen zu custom-templates/layout.yml hinzu. In diesem Fall fügen Sie beim Ersetzen von OSD-Compute-0 diese Adresse für jeden Typ am Ende der Liste hinzu:
OsdComputeIPs:
internal_api:
- 11.120.0.43
- 11.120.0.44
- 11.120.0.45
- 11.120.0.43 <<< take osd-compute-0 .43 and add here
tenant:
- 11.117.0.43
- 11.117.0.44
- 11.117.0.45
- 11.117.0.43 << and here
storage:
- 11.118.0.43
- 11.118.0.44
- 11.118.0.45
- 11.118.0.43 << and here
storage_mgmt:
- 11.119.0.43
- 11.119.0.44
- 11.119.0.45
- 11.119.0.43 << and here
Führen Sie das Skript deploy.sh aus, das zuvor zum Bereitstellen des Stacks verwendet wurde, um den neuen Rechenknoten zum Overcloud-Stack hinzuzufügen:
[stack@director ~]$ ./deploy.sh
++ openstack overcloud deploy --templates -r /home/stack/custom-templates/custom-roles.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml --stack ADN-ultram --debug --log-file overcloudDeploy_11_06_17__16_39_26.log --ntp-server 172.24.167.109 --neutron-flat-networks phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1 --neutron-network-vlan-ranges datacentre:1001:1050 --neutron-disable-tunneling --verbose --timeout 180
…
Starting new HTTP connection (1): 192.200.0.1
"POST /v2/action_executions HTTP/1.1" 201 1695
HTTP POST http://192.200.0.1:8989/v2/action_executions 201
Overcloud Endpoint: http://10.1.2.5:5000/v2.0
Overcloud Deployed
clean_up DeployOvercloud:
END return value: 0
real 38m38.971s
user 0m3.605s
sys 0m0.466s
Warten Sie, bis der Status des OpenStack-Stacks ABGESCHLOSSEN ist:
[stack@director ~]$ openstack stack list
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| ID | Stack Name | Stack Status | Creation Time | Updated Time |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod1 | UPDATE_COMPLETE | 2017-11-02T21:30:06Z | 2017-11-06T21:40:58Z |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
Stellen Sie sicher, dass sich der neue OSD-Compute-Knoten im Aktiv-Zustand befindet:
[stack@director ~]$ source stackrc
[stack@director ~]$ nova list |grep osd-compute-3
| 0f2d88cd-d2b9-4f28-b2ca-13e305ad49ea | pod1-osd-compute-3 | ACTIVE | - | Running | ctlplane=192.200.0.117 |
[stack@director ~]$ source corerc
[stack@director ~]$ openstack hypervisor list |grep osd-compute-3
| 63 | pod1-osd-compute-3.localdomain |
Melden Sie sich beim neuen OSD-Compute-Server an, und überprüfen Sie die Ceph-Prozesse. Zu Beginn wird der Status in HEALTH_WARN sein, wenn Ceph sich erholt:
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
223 pgs backfill_wait
4 pgs backfilling
41 pgs degraded
227 pgs stuck unclean
41 pgs undersized
recovery 45229/1300136 objects degraded (3.479%)
recovery 525016/1300136 objects misplaced (40.382%)
monmap e1: 3 mons at {Pod1-controller-0=11.118.0.40:6789/0,Pod1-controller-1=11.118.0.41:6789/0,Pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 Pod1-controller-0,Pod1-controller-1,Pod1-controller-2
osdmap e986: 12 osds: 12 up, 12 in; 225 remapped pgs
flags sortbitwise,require_jewel_osds
pgmap v781746: 704 pgs, 6 pools, 533 GB data, 344 kobjects
1553 GB used, 11840 GB / 13393 GB avail
45229/1300136 objects degraded (3.479%)
525016/1300136 objects misplaced (40.382%)
477 active+clean
186 active+remapped+wait_backfill
37 active+undersized+degraded+remapped+wait_backfill
4 active+undersized+degraded+remapped+backfilling
Aber nach kurzer Zeit (20 Minuten) kehrt Ceph in den Zustand HEALTH_OK zurück:
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {Pod1-controller-0=11.118.0.40:6789/0,Pod1-controller-1=11.118.0.41:6789/0,Pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 Pod1-controller-0,Pod1-controller-1,Pod1-controller-2
osdmap e1398: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v784311: 704 pgs, 6 pools, 533 GB data, 344 kobjects
1599 GB used, 11793 GB / 13393 GB avail
704 active+clean
client io 8168 kB/s wr, 0 op/s rd, 32 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 0 host pod1-osd-compute-0
-3 4.35999 host pod1-osd-compute-2
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-1
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
Einstellungen nach dem Serveraustausch
Nachdem Sie den Server zur Overcloud hinzugefügt haben, verwenden Sie den folgenden Link, um die Einstellungen zu übernehmen, die zuvor auf dem alten Server vorhanden waren:
Stellen Sie die VMs wieder her
Fall 1: OSD-Compute Node Hosting CF, ESC, EM und UAS
Ergänzung der Nova Aggregate-Liste
Fügen Sie den Knoten OSD-Compute zu den Aggregate-Hosts hinzu, und überprüfen Sie, ob der Host hinzugefügt wurde. In diesem Fall muss der OSD-Compute-Knoten sowohl dem CF- als auch dem EM-Host-Aggregat hinzugefügt werden.
nova aggregate-add-host
[stack@director ~]$ nova aggregate-add-host VNF2-CF-MGMT2 pod1-osd-compute-3.localdomain
[stack@director ~]$ nova aggregate-add-host VNF2-EM-MGMT2 pod1-osd-compute-3.localdomain
[stack@direcotr ~]$ nova aggregate-add-host POD1-AUTOIT pod1-osd-compute-3.localdomain
nova aggregate-show
[stack@director ~]$ nova aggregate-show VNF2-CF-MGMT2
[stack@director ~]$ nova aggregate-show VNF2-EM-MGMT2
[stack@director ~]$ nova aggregate-show POD1-AUTOITT
Wiederherstellung von UAS VM
Überprüfen Sie den Status der UAS VM in der Nova-Liste und löschen Sie sie:
[stack@director ~]$ nova list | grep VNF2-UAS-uas-0
| 307a704c-a17c-4cdc-8e7a-3d6e7e4332fa | VNF2-UAS-uas-0 | ACTIVE | - | Running | VNF2-UAS-uas-orchestration=172.168.11.10; VNF2-UAS-uas-management=172.168.10.3
[stack@director ~]$ nova delete VNF2-UAS-uas-0
Request to delete server VNF2-UAS-uas-0 has been accepted.
Um die autovnf-uas VM wiederherzustellen, führen Sie das uas-check-Skript aus, um den Status zu überprüfen. Sie muss einen FEHLER melden. Führen Sie dann erneut mit der Option —fix aus, um die fehlende UAS VM neu zu erstellen:
[stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts/
[stack@director scripts]$ ./uas-check.py auto-vnf VNF2-UAS
2017-12-08 12:38:05,446 - INFO: Check of AutoVNF cluster started
2017-12-08 12:38:07,925 - INFO: Instance 'vnf1-UAS-uas-0' status is 'ERROR'
2017-12-08 12:38:07,925 - INFO: Check completed, AutoVNF cluster has recoverable errors
[stack@director scripts]$ ./uas-check.py auto-vnf VNF2-UAS --fix
2017-11-22 14:01:07,215 - INFO: Check of AutoVNF cluster started
2017-11-22 14:01:09,575 - INFO: Instance VNF2-UAS-uas-0' status is 'ERROR'
2017-11-22 14:01:09,575 - INFO: Check completed, AutoVNF cluster has recoverable errors
2017-11-22 14:01:09,778 - INFO: Removing instance VNF2-UAS-uas-0'
2017-11-22 14:01:13,568 - INFO: Removed instance VNF2-UAS-uas-0'
2017-11-22 14:01:13,568 - INFO: Creating instance VNF2-UAS-uas-0' and attaching volume ‘VNF2-UAS-uas-vol-0'
2017-11-22 14:01:49,525 - INFO: Created instance ‘VNF2-UAS-uas-0'
Melden Sie sich bei autovnf-uas an. Warten Sie einige Minuten, und UAS muss in den guten Zustand zurückkehren:
VNF2-autovnf-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.17.181.101
INSTANCE IP STATE ROLE
-----------------------------------
172.17.180.6 alive CONFD-SLAVE
172.17.180.7 alive CONFD-MASTER
172.17.180.9 alive NA
Anmerkung: Wenn uas-check.py -fix fehlschlägt, müssen Sie diese Datei möglicherweise kopieren und erneut ausführen.
[stack@director ~]$ mkdir –p /opt/cisco/usp/apps/auto-it/common/uas-deploy/
[stack@director ~]$ cp /opt/cisco/usp/uas-installer/common/uas-deploy/userdata-uas.txt /opt/cisco/usp/apps/auto-it/common/uas-deploy/
Wiederherstellung der ESC VM
Überprüfen Sie den Status des ESC VM aus der Nova-Liste und löschen Sie ihn:
stack@director scripts]$ nova list |grep ESC-1
| c566efbf-1274-4588-a2d8-0682e17b0d41 | VNF2-ESC-ESC-1 | ACTIVE | - | Running | VNF2-UAS-uas-orchestration=172.168.11.14; VNF2-UAS-uas-management=172.168.10.4 |
[stack@director scripts]$ nova delete VNF2-ESC-ESC-1
Request to delete server VNF2-ESC-ESC-1 has been accepted.
Suchen Sie in AutoVNF-UAS die ESC-Bereitstellungstransaktion und im Protokoll für die Transaktion die Befehlszeile boot_vm.py, um die ESC-Instanz zu erstellen:
ubuntu@VNF2-uas-uas-0:~$ sudo -i
root@VNF2-uas-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on VNF2-uas-uas-0
VNF2-uas-uas-0#show transaction
TX ID TX TYPE DEPLOYMENT ID TIMESTAMP STATUS
-----------------------------------------------------------------------------------------------------------------------------
35eefc4a-d4a9-11e7-bb72-fa163ef8df2b vnf-deployment VNF2-DEPLOYMENT 2017-11-29T02:01:27.750692-00:00 deployment-success
73d9c540-d4a8-11e7-bb72-fa163ef8df2b vnfm-deployment VNF2-ESC 2017-11-29T01:56:02.133663-00:00 deployment-success
VNF2-uas-uas-0#show logs 73d9c540-d4a8-11e7-bb72-fa163ef8df2b | display xml
<config xmlns="http://tail-f.com/ns/config/1.0">
<logs xmlns="http://www.cisco.com/usp/nfv/usp-autovnf-oper">
<tx-id>73d9c540-d4a8-11e7-bb72-fa163ef8df2b</tx-id>
<log>2017-11-29 01:56:02,142 - VNFM Deployment RPC triggered for deployment: VNF2-ESC, deactivate: 0
2017-11-29 01:56:02,179 - Notify deployment
..
2017-11-29 01:57:30,385 - Creating VNFM 'VNF2-ESC-ESC-1' with [python //opt/cisco/vnf-staging/bootvm.py VNF2-ESC-ESC-1 --flavor VNF2-ESC-ESC-flavor --image 3fe6b197-961b-4651-af22-dfd910436689 --net VNF2-UAS-uas-management --gateway_ip 172.168.10.1 --net VNF2-UAS-uas-orchestration --os_auth_url http://10.1.2.5:5000/v2.0 --os_tenant_name core --os_username ****** --os_password ****** --bs_os_auth_url http://10.1.2.5:5000/v2.0 --bs_os_tenant_name core --bs_os_username ****** --bs_os_password ****** --esc_ui_startup false --esc_params_file /tmp/esc_params.cfg --encrypt_key ****** --user_pass ****** --user_confd_pass ****** --kad_vif eth0 --kad_vip 172.168.10.7 --ipaddr 172.168.10.6 dhcp --ha_node_list 172.168.10.3 172.168.10.6 --file root:0755:/opt/cisco/esc/esc-scripts/esc_volume_em_staging.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_volume_em_staging.sh --file root:0755:/opt/cisco/esc/esc-scripts/esc_vpc_chassis_id.py:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_vpc_chassis_id.py --file root:0755:/opt/cisco/esc/esc-scripts/esc-vpc-di-internal-keys.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc-vpc-di-internal-keys.sh
Speichern Sie die Zeile boot_vm.py in einer Shell-Skriptdatei (esc.sh) und aktualisieren Sie alle Zeilen mit dem Benutzernamen ***** und dem Kennwort ***** mit den richtigen Informationen (in der Regel core/<PASSWORD>). Sie müssen auch die Option -encrypt_key entfernen. Für user_pass und user_config_pass müssen Sie das Format username verwenden: Kennwort (Beispiel: admin:<PASSWORT>).
Suchen Sie die URL, um bootvm.py von running-config abzuhalten, und rufen Sie die Datei bootvm.py an die VM autovnf-uas ab. In diesem Fall ist 10.1.2.3 die IP-Adresse der virtuellen Auto-IT-Maschine:
root@VNF2-uas-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on VNF2-uas-uas-0
VNF2-uas-uas-0#show running-config autovnf-vnfm:vnfm
…
configs bootvm
value http:// 10.1.2.3:80/bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
!
root@VNF2-uas-uas-0:~# wget http://10.1.2.3:80/bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
--2017-12-01 20:25:52-- http://10.1.2.3 /bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
Connecting to 10.1.2.3:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 127771 (125K) [text/x-python]
Saving to: ‘bootvm-2_3_2_155.py’
100%[=====================================================================================>] 127,771 --.-K/s in 0.001s
2017-12-01 20:25:52 (173 MB/s) - ‘bootvm-2_3_2_155.py’ saved [127771/127771]
Erstellen Sie eine Datei /tmp/esc_params.cfg:
root@VNF2-uas-uas-0:~# echo "openstack.endpoint=publicURL" > /tmp/esc_params.cfg
Führen Sie das Shell-Skript aus, um ESC vom UAS-Knoten bereitzustellen:
root@VNF2-uas-uas-0:~# /bin/sh esc.sh
+ python ./bootvm.py VNF2-ESC-ESC-1 --flavor VNF2-ESC-ESC-flavor --image 3fe6b197-961b-4651-af22-dfd910436689
--net VNF2-UAS-uas-management --gateway_ip 172.168.10.1 --net VNF2-UAS-uas-orchestration --os_auth_url
http://10.1.2.5:5000/v2.0 --os_tenant_name core --os_username core --os_password <PASSWORD> --bs_os_auth_url
http://10.1.2.5:5000/v2.0 --bs_os_tenant_name core --bs_os_username core --bs_os_password <PASSWORD>
--esc_ui_startup false --esc_params_file /tmp/esc_params.cfg --user_pass admin:<PASSWORD> --user_confd_pass
admin:<PASSWORD> --kad_vif eth0 --kad_vip 172.168.10.7 --ipaddr 172.168.10.6 dhcp --ha_node_list 172.168.10.3
172.168.10.6 --file root:0755:/opt/cisco/esc/esc-scripts/esc_volume_em_staging.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_volume_em_staging.sh
--file root:0755:/opt/cisco/esc/esc-scripts/esc_vpc_chassis_id.py:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_vpc_chassis_id.py
--file root:0755:/opt/cisco/esc/esc-scripts/esc-vpc-di-internal-keys.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc-vpc-di-internal-keys.sh
Melden Sie sich bei der neuen ESC an, und überprüfen Sie den Backup-Status:
ubuntu@VNF2-uas-uas-0:~$ ssh admin@172.168.11.14
…
####################################################################
# ESC on VNF2-esc-esc-1.novalocal is in BACKUP state.
####################################################################
[admin@VNF2-esc-esc-1 ~]$ escadm status
0 ESC status=0 ESC Backup Healthy
[admin@VNF2-esc-esc-1 ~]$ health.sh
============== ESC HA (BACKUP) ===================================================
ESC HEALTH PASSED
Wiederherstellen von CF- und EM-VMs aus ESC
Überprüfen Sie den Status der CF und EM VMs aus der Nova-Liste. Sie müssen den Status "ERROR" aufweisen:
[stack@director ~]$ source corerc
[stack@director ~]$ nova list --field name,host,status |grep -i err
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | None | ERROR|
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 |None | ERROR
Melden Sie sich beim ESC-Master an, und führen Sie recovery-vm-action für jedes betroffene EM- und CF-VM aus. Sei geduldig! ESC würde die Recovery-Aktion planen, und es kann sein, dass es für ein paar Minuten nicht passiert. Überwachen Sie die Datei yangesc.log:
sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO
[admin@VNF2-esc-esc-0 ~]$ sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO VNF2-DEPLOYMENT-_VNF2-D_0_a6843886-77b4-4f38-b941-74eb527113a8
[sudo] password for admin:
Recovery VM Action
/opt/cisco/esc/confd/bin/netconf-console --port=830 --host=127.0.0.1 --user=admin --privKeyFile=/root/.ssh/confd_id_dsa --privKeyType=dsa --rpc=/tmp/esc_nc_cli.ZpRCGiieuW
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="1">
<ok/>
</rpc-reply>
[admin@VNF2-esc-esc-0 ~]$ tail -f /var/log/esc/yangesc.log
…
14:59:50,112 07-Nov-2017 WARN Type: VM_RECOVERY_COMPLETE
14:59:50,112 07-Nov-2017 WARN Status: SUCCESS
14:59:50,112 07-Nov-2017 WARN Status Code: 200
14:59:50,112 07-Nov-2017 WARN Status Msg: Recovery: Successfully recovered VM [VNF2-DEPLOYMENT-_VNF2-D_0_a6843886-77b4-4f38-b941-74eb527113a8]
Melden Sie sich bei der neuen EM an, und überprüfen Sie, ob der EM-Status aktiv ist:
ubuntu@VNF2vnfddeploymentem-1:~$ /opt/cisco/ncs/current/bin/ncs_cli -u admin -C
admin connected from 172.17.180.6 using ssh on VNF2vnfddeploymentem-1
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
---------------------
2 up up up
3 up up up
Melden Sie sich bei StarOS VNF an, und vergewissern Sie sich, dass sich die CF-Karte im Standby-Status befindet.
Fall 2: OSD-Compute Node Hosting Auto-IT, Auto-Deployment, EM und UAS
Wiederherstellung eines virtuellen Systems mit automatischer Bereitstellung
Wenn die automatische VM-Bereitstellung von OSPD betroffen war, aber weiterhin AKTIV/Wird ausgeführt angezeigt wird, müssen Sie sie zuerst löschen. Wenn die automatische Bereitstellung nicht beeinträchtigt wurde, fahren Sie mit Recovery of Auto-it VM:
[stack@director ~]$ nova list |grep auto-deploy
| 9b55270a-2dcd-4ac1-aba3-bf041733a0c9 | auto-deploy-ISO-2007-uas-0 | ACTIVE | - | Running | mgmt=172.16.181.12, 10.1.2.7 [stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director ~]$ ./auto-deploy-booting.sh --floating-ip 10.1.2.7 --delete
Nachdem die automatische Bereitstellung gelöscht wurde, erstellen Sie sie erneut mit der gleichen floatingip-Adresse:
[stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director scripts]$ ./auto-deploy-booting.sh --floating-ip 10.1.2.7
2017-11-17 07:05:03,038 - INFO: Creating AutoDeploy deployment (1 instance(s)) on 'http://10.84.123.4:5000/v2.0' tenant 'core' user 'core', ISO 'default'
2017-11-17 07:05:03,039 - INFO: Loading image 'auto-deploy-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2' from '/opt/cisco/usp/uas-installer/images/usp-uas-1.0.1-1504.qcow2'
2017-11-17 07:05:14,603 - INFO: Loaded image 'auto-deploy-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2'
2017-11-17 07:05:15,787 - INFO: Assigned floating IP '10.1.2.7' to IP '172.16.181.7'
2017-11-17 07:05:15,788 - INFO: Creating instance 'auto-deploy-ISO-5-1-7-2007-uas-0'
2017-11-17 07:05:42,759 - INFO: Created instance 'auto-deploy-ISO-5-1-7-2007-uas-0'
2017-11-17 07:05:42,759 - INFO: Request completed, floating IP: 10.1.2.7
Kopieren Sie die Datei Autodeploy.cfg, die ISO-Datei und die Tar-Datei config_backup von Ihrem Backup-Server, um VM automatisch bereitzustellen und config cdb-Dateien aus der Tar-Datei backup wiederherzustellen:
ubuntu@auto-deploy-iso-2007-uas-0:~# sudo -i
ubuntu@auto-deploy-iso-2007-uas-0:# service uas-confd stop
uas-confd stop/waiting
root@auto-deploy-iso-2007-uas-0:# cd /opt/cisco/usp/uas/confd-6.3.1/var/confd
root@auto-deploy-iso-2007-uas-0:/opt/cisco/usp/uas/confd-6.3.1/var/confd# tar xvf /home/ubuntu/ad_cdb_backup.tar
cdb/
cdb/O.cdb
cdb/C.cdb
cdb/aaa_init.xml
cdb/A.cdb
root@auto-deploy-iso-2007-uas-0~# service uas-confd start
uas-confd start/running, process 2036
Vergewissern Sie sich, dass konfd ordnungsgemäß geladen wurde, indem Sie frühere Transaktionen überprüfen. Aktualisieren Sie die Datei autodeploy.cfg mit einem neuen OSD-Compute-Namen. Siehe Abschnitt - Abschließender Schritt: AutoDeploy-Konfiguration aktualisieren:
root@auto-deploy-iso-2007-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on auto-deploy-iso-2007-uas-0
auto-deploy-iso-2007-uas-0#show transaction
SERVICE SITE
DEPLOYMENT SITE TX AUTOVNF VNF AUTOVNF
TX ID TX TYPE ID DATE AND TIME STATUS ID ID ID ID TX ID
-------------------------------------------------------------------------------------------------------------------------------------
1512571978613 service-deployment tb5bxb 2017-12-06T14:52:59.412+00:00 deployment-success
auto-deploy-iso-2007-uas-0# exit
Wiederherstellung von Auto-IT VM
Wenn die automatische Einwahl im virtuellen System von OSPD betroffen war, aber weiterhin als AKTIV/Wird ausgeführt angezeigt wird, muss sie gelöscht werden. Wenn keine Auswirkungen auf die Automatisierung auftreten, fahren Sie mit dem nächsten virtuellen System fort:
[stack@director ~]$ nova list |grep auto-it
| 580faf80-1d8c-463b-9354-781ea0c0b352 | auto-it-vnf-ISO-2007-uas-0 | ACTIVE | - | Running | mgmt=172.16.181.3, 10.1.2.8 [stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director ~]$ ./ auto-it-vnf-staging.sh --floating-ip 10.1.2.8 --delete
Führen Sie das auto-it-vnf-Stagingskript aus, und erstellen Sie auto-it neu:
[stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director scripts]$ ./auto-it-vnf-staging.sh --floating-ip 10.1.2.8
2017-11-16 12:54:31,381 - INFO: Creating StagingServer deployment (1 instance(s)) on 'http://10.84.123.4:5000/v2.0' tenant 'core' user 'core', ISO 'default'
2017-11-16 12:54:31,382 - INFO: Loading image 'auto-it-vnf-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2' from '/opt/cisco/usp/uas-installer/images/usp-uas-1.0.1-1504.qcow2'
2017-11-16 12:54:51,961 - INFO: Loaded image 'auto-it-vnf-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2'
2017-11-16 12:54:53,217 - INFO: Assigned floating IP '10.1.2.8' to IP '172.16.181.9'
2017-11-16 12:54:53,217 - INFO: Creating instance 'auto-it-vnf-ISO-5-1-7-2007-uas-0'
2017-11-16 12:55:20,929 - INFO: Created instance 'auto-it-vnf-ISO-5-1-7-2007-uas-0'
2017-11-16 12:55:20,930 - INFO: Request completed, floating IP: 10.1.2.8
Laden Sie das ISO-Image neu. In diesem Fall ist die automatische IP-Adresse 10.1.2.8. Das Laden dauert einige Minuten:
[stack@director ~]$ cd images/5_1_7-2007/isos
[stack@director isos]$ curl -F file=@usp-5_1_7-2007.iso http://10.1.2.8:5001/isos
{
"iso-id": "5.1.7-2007"
}
to check the ISO image:
[stack@director isos]$ curl http://10.1.2.8:5001/isos
{
"isos": [
{
"iso-id": "5.1.7-2007"
}
]
}
Kopieren Sie die VNF system.cfg-Dateien aus dem OSPD Auto-Deploy-Verzeichnis in die automatische VM:
[stack@director autodeploy]$ scp system-vnf* ubuntu@10.1.2.8:.
ubuntu@10.1.2.8's password:
system-vnf1.cfg 100% 1197 1.2KB/s 00:00
system-vnf2.cfg 100% 1197 1.2KB/s 00:00
ubuntu@auto-it-vnf-iso-2007-uas-0:~$ pwd
/home/ubuntu
ubuntu@auto-it-vnf-iso-2007-uas-0:~$ ls
system-vnf1.cfg system-vnf2.cfg
Anmerkung: Die Wiederherstellungsverfahren von EM und UAS VM sind in beiden Fällen identisch. Entsprechendes finden Sie im Abschnitt Case.1.
ESC-Wiederherstellungsfehler behandeln
Falls die ESC die VM aufgrund eines unerwarteten Zustands nicht starten kann, empfiehlt Cisco, dass Sie einen ESC-Switchover durchführen, indem Sie die Master-ESC neu starten. Die Umstellung auf den ESC würde etwa eine Minute dauern. Führen Sie das Skript health.sh auf dem neuen Master-ESC aus, um zu überprüfen, ob der Status aktiv ist. Master-ESC, um die VM zu starten und den VM-Status zu korrigieren. Dieser Wiederherstellungsvorgang dauert bis zu fünf Minuten.
Sie können /var/log/esc/yangesc.log und /var/log/esc/escmanager.log überwachen. Wenn Sie nicht sehen, dass die VM nach 5-7 Minuten wiederhergestellt wird, muss der Benutzer die manuelle Wiederherstellung der betroffenen VM(s) durchführen.
Konfigurationsaktualisierung für automatische Bereitstellung
Bearbeiten Sie in AutoDeploy VM die Datei auto-deploy.cfg, und ersetzen Sie den alten OSD-Compute-Server durch den neuen. Dann laden Sie replace in config_cli. Dieser Schritt ist für eine spätere erfolgreiche Deaktivierung der Bereitstellung erforderlich.
root@auto-deploy-iso-2007-uas-0:/home/ubuntu# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on auto-deploy-iso-2007-uas-0
auto-deploy-iso-2007-uas-0#config
Entering configuration mode terminal
auto-deploy-iso-2007-uas-0(config)#load replace autodeploy.cfg
Loading. 14.63 KiB parsed in 0.42 sec (34.16 KiB/sec)
auto-deploy-iso-2007-uas-0(config)#commit
Commit complete.
auto-deploy-iso-2007-uas-0(config)#end
Starten Sie uas-config und Auto-Deploy-Dienste nach der Konfigurationsänderung neu:
root@auto-deploy-iso-2007-uas-0:~# service uas-confd restart
uas-confd stop/waiting
uas-confd start/running, process 14078
root@auto-deploy-iso-2007-uas-0:~# service uas-confd status
uas-confd start/running, process 14078
root@auto-deploy-iso-2007-uas-0:~# service autodeploy restart
autodeploy stop/waiting
autodeploy start/running, process 14017
root@auto-deploy-iso-2007-uas-0:~# service autodeploy status
autodeploy start/running, process 14017
Aktivieren von Syslogs
Um die Syslogs für den UCS-Server, OpenStack-Komponenten und die wiederhergestellten VMs zu aktivieren, befolgen Sie die Abschnitte
"Re-Enable syslog for UCS and OpenStack components" und "Enable syslog for the VNFs", siehe Link unten:
Revisionsverlauf
| Überarbeitung | Veröffentlichungsdatum | Kommentare |
|---|---|---|
1.0 |
10-Jul-2018
|
Erstveröffentlichung |
Beiträge von Cisco Ingenieuren
- Partheeban RajagopalCisco Advanced Services
- Padmaraj RamanoudjamCisco Advanced Services
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)