Überwachung und Fehlerbehebung bei der hohen CPU-Belastung von Cisco Unified Communications Manager 6.0 mit dem Real Time Monitoring Tool (RTMT)
Inhalt
Einleitung
Dieses Dokument enthält Schritte zur Unterstützung bei der Überwachung und Fehlerbehebung im Zusammenhang mit der hohen Prozessorauslastung in Cisco Unified Communications Manager 6.0 mit RTMT.
Voraussetzungen
Anforderungen
Cisco empfiehlt, dass Sie über Kenntnisse in diesem Thema verfügen:
-
Cisco Unified Communications Manager
Verwendete Komponenten
Die in diesem Dokument enthaltenen Informationen basieren auf folgenden Tagesordnungspunkten:
-
Identifikation von Prozessen, die die meisten CPUs verwenden
-
Identifizierung des für die Festplatten-E/A verantwortlichen Prozesses
-
Code Gelb, aber Gesamtauslastung der CPU beträgt nur 25 % - Warum?
Die in diesem Dokument enthaltenen Informationen basieren auf Cisco Unified Communications Manager 6.0.
Die Informationen in diesem Dokument beziehen sich auf Geräte in einer speziell eingerichteten Testumgebung. Alle Geräte, die in diesem Dokument benutzt wurden, begannen mit einer gelöschten (Nichterfüllungs) Konfiguration. Wenn Ihr Netz Live ist, überprüfen Sie, ob Sie die mögliche Auswirkung jedes möglichen Befehls verstehen.
Konventionen
Weitere Informationen zu Dokumentkonventionen finden Sie unter Cisco Technical Tips Conventions (Technische Tipps von Cisco zu Konventionen).
Systemzeit, Benutzerzeit, IOWait, Soft IRQ und IRQ
Die Verwendung von RTMT zur Isolierung potenzieller CPU-Probleme kann sich als sehr nützlicher Schritt bei der Fehlerbehebung erweisen.
Diese Begriffe stellen die Nutzung von RTMT-CPU- und Speicher-Seitenberichten dar:
-
%System: Der prozentuale Anteil der CPU-Auslastung, der bei der Ausführung auf Systemebene aufgetreten ist (Kernel).
-
%Benutzer: Der Prozentsatz der CPU-Auslastung, der bei der Ausführung auf Benutzerebene aufgetreten ist (Anwendung).
-
%IOWait: Die prozentuale Zeit, die die CPU im Leerlauf war, während sie auf eine ausstehende Festplatten-E/A-Anforderung wartete
-
%SoftIRQ: die prozentuale Zeit, die der Prozessor eine verzögerte IRQ-Verarbeitung durchführt (z. B. Verarbeitung von Netzwerkpaketen)
-
%IRQ die prozentuale Zeit, die der Prozessor die Interrupt-Anforderung ausführt, die Geräten für Interrupt zugewiesen ist, oder ein Signal an den Computer sendet, wenn die Verarbeitung abgeschlossen ist
CPU-Pegging-Warnungen
CPUPegging/CallProcessNodeCPUPegging-Warnungen überwachen die CPU-Auslastung auf der Grundlage konfigurierter Grenzwerte:
Hinweis: %CPU wird berechnet als %system + %user + %nice + %iowait + %softirq + %irq
Warnmeldungen umfassen Folgendes:
-
%system, %user, %nice, %iowait, %softirq und %irq
-
Der Prozess, der die meisten CPUs verwendet
-
Die Prozesse, die auf den unterbrechungsfreien Festplattenspeicher warten
CPU-Pegging-Warnungen können in RTMT aufgrund einer höheren CPU-Auslastung als der Wasserzeichenpegel ausgelöst werden. Da CDR beim Laden eine CPU-intensive Anwendung ist, überprüfen Sie, ob Sie die Warnungen im gleichen Zeitraum erhalten, in dem der CDR für die Ausführung von Berichten konfiguriert ist. In diesem Fall müssen Sie die Schwellenwerte für RTMT erhöhen. Weitere Informationen zu RTMT-Warnungen finden Sie unter Warnungen.
Identifikation von Prozessen, die die meisten CPUs verwenden
Wenn %system und/oder %user hoch genug ist, um eine CPUpegging-Warnung zu generieren, überprüfen Sie die Warnmeldung, um festzustellen, welche Prozesse die meiste CPU verwenden.
Hinweis: Rufen Sie die Seite "RTMT-Prozess" auf, und sortieren Sie nach %CPU, um die Prozesse mit hoher CPU zu identifizieren.
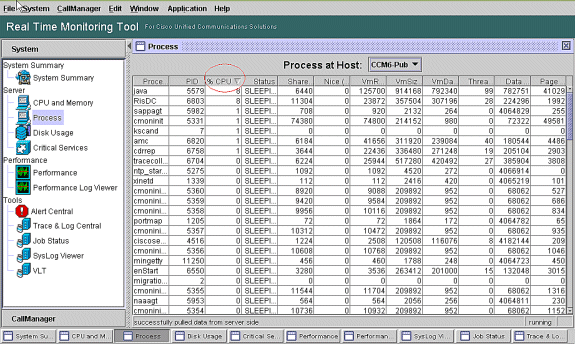
Hinweis: Für die Postmortem-Analyse verfolgt das RIS-Fehlerbehebungs-PerfMon-Protokoll den Prozess %CPU-Auslastung und verfolgt auf Systemebene.
Hoher IoE-Wert
Hoch %IOWait zeigt hohe Festplatten-E/A-Aktivitäten an. Bedenken Sie Folgendes:
-
IOWait ist auf einen starken Speicheraustausch zurückzuführen.
Überprüfen Sie die %CPU Time for Swap Partition (CPU-Zeit für Auslagerungspartition), um festzustellen, ob ein hoher Grad an Speicherauslagerungsaktivität vorliegt. Da Muster über mindestens 2G RAM verfügt, ist ein hoher Speicheraustausch wahrscheinlich auf ein Speicherleck zurückzuführen.
-
IOWait ist auf DB-Aktivität zurückzuführen.
Die DB ist in erster Linie die einzige, die auf die aktive Partition zugreift. Wenn %CPU-Zeit für aktive Partition hoch ist, gibt es wahrscheinlich eine Menge DB-Aktivität.
Hoher IOWait aufgrund gemeinsamer Partition
Die gemeinsame (oder Protokoll-)Partition ist der Speicherort, in dem Ablaufverfolgungs- und Protokolldateien gespeichert werden.
Hinweis: Überprüfen Sie Folgendes:
-
Trace & Log Central (Ablaufverfolgung und Protokollzentrale): Gibt es Aktivitäten zur Ablaufverfolgungssammlung? Wenn die Anrufverarbeitung beeinträchtigt ist (d. h. CodeYellow), passen Sie den Zeitplan für die Ablaufverfolgungssammlung an. Wenn Sie die Zip-Option verwenden, deaktivieren Sie diese ebenfalls.
-
Trace-Einstellung - Auf der Detailed-Ebene generiert CallManager eine ganze Menge Trace. Wenn sich ein hoher %IOWait und/oder CCM im CodeYellow-Status befindet und die CallManager-Dienstablaufverfolgungseinstellung auf Detailed festgelegt ist, ändern Sie den Wert in "Error".
Identifizierung des für die Festplatten-E/A verantwortlichen Prozesses
Es gibt keine direkte Möglichkeit, die Nutzung von %IOWait pro Prozess zu ermitteln. Derzeit ist der beste Weg, um die Prozesse warten auf der Festplatte zu überprüfen.
Wenn %IOWait hoch genug ist, um eine CPUpegging-Warnung auszulösen, überprüfen Sie die Warnmeldung, um die Prozesse zu ermitteln, die auf Festplatten-E/A warten.
-
Rufen Sie die Seite "RTMT-Prozess" auf, und sortieren Sie nach Status. Überprüfen Sie, ob sich die Vorgänge im Ruhezustand der unterbrechungsfreien Festplatte befinden. Der von TLC für die geplante Sammlung verwendete SFTP-Prozess befindet sich im Ruhezustand der unterbrechungsfreien Festplatte.
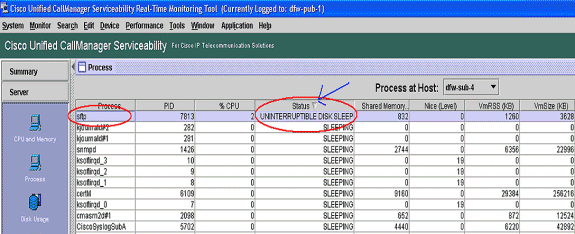
Hinweis: Die RIS Troubleshooting PerfMon Log-Datei kann heruntergeladen werden, um den Prozessstatus für längere Zeiträume zu überprüfen.

-
Gehen Sie im Echtzeit-Überwachungstool zu System > Tools > Trace > Trace & Log Central.
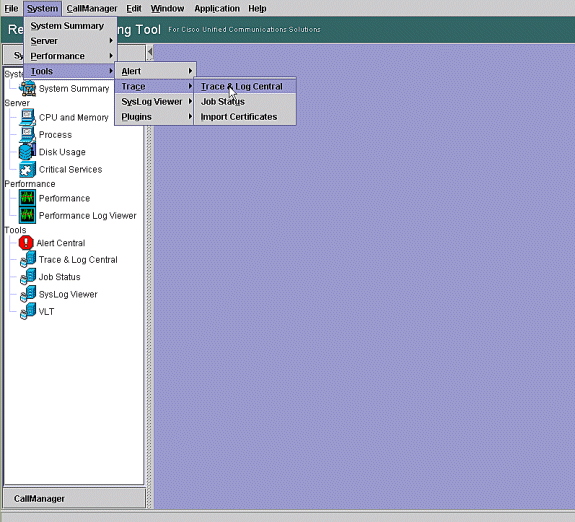
-
Doppelklicken Sie auf Dateien sammeln, und wählen Sie Weiter aus.
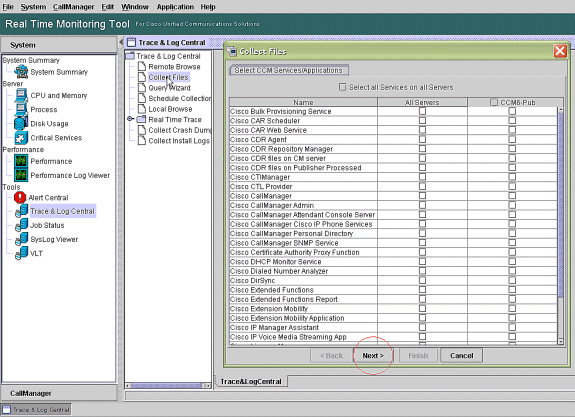
-
Wählen Sie Cisco RIS Data Collector PerfMonLog aus, und wählen Sie Weiter aus.
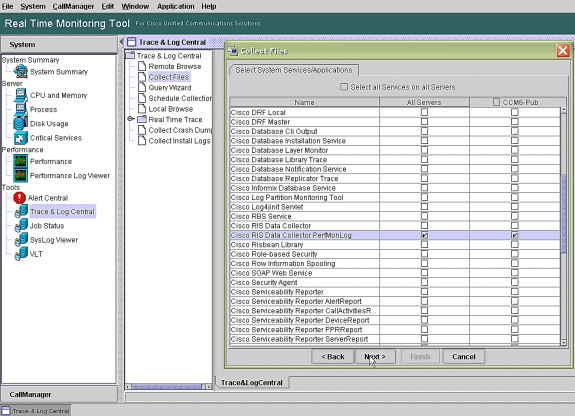
-
Konfigurieren Sie im Feld Collection Time (Erfassungszeit) die Zeit, die erforderlich ist, um Protokolldateien für den betreffenden Zeitraum anzuzeigen. Navigieren Sie im Feld Download File Options (Dateioptionen herunterladen) zu Ihrem Downloadpfad (einem Speicherort, von dem aus Sie den Windows-Leistungsmonitor starten können, um die Protokolldatei anzuzeigen), wählen Sie Zip Files (Zip-Dateien) und dann Finish (Fertig stellen).
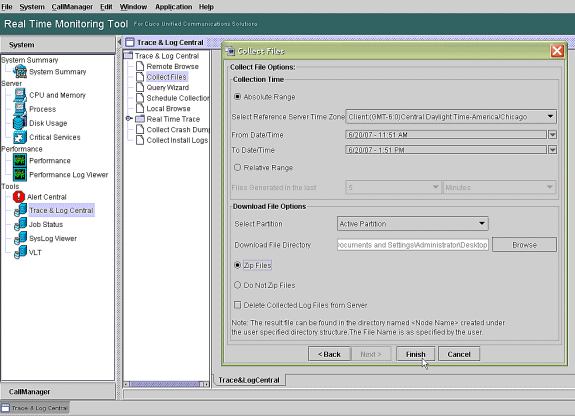
-
Beachten Sie den Status und den Downloadpfad zum Sammeln von Dateien. Hier sollten keine Fehler gemeldet werden.
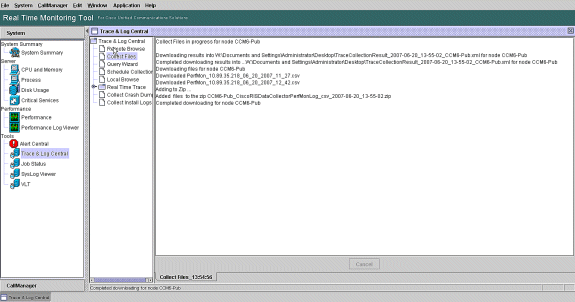
-
Zeigen Sie die Leistungsprotokolldateien mit dem Microsoft Performance Monitor-Tool an. Wählen Sie Start > Einstellungen > Systemsteuerung > Verwaltung > Leistung aus.
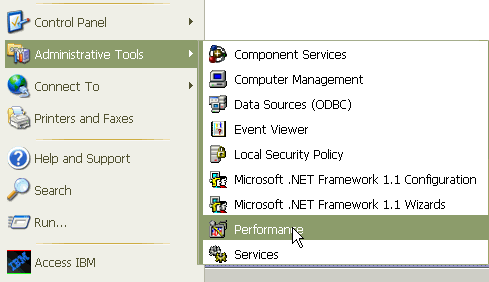
-
Klicken Sie im Anwendungsfenster mit der rechten Maustaste, und wählen Sie Eigenschaften aus.
-
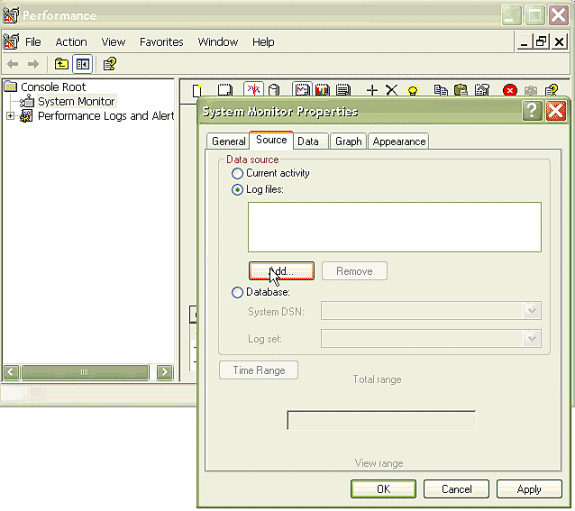
Wählen Sie im Dialogfeld Eigenschaften von Systemmonitor die Registerkarte Quelle aus. Protokolldateien auswählen: als Datenquelle, und klicken Sie auf die Schaltfläche Hinzufügen.
-
Navigieren Sie zu dem Verzeichnis, in das Sie die PerfMon Log-Datei heruntergeladen haben, und wählen Sie die perfmon csv-Datei. Die Protokolldatei enthält die folgende Namenskonvention:
PerfMon_<Knoten>_<Monat>_<Tag>_<Jahr>_<Stunde>_<Minute>.csv; Beispiel: PerfMon_10.89.35.218_6_20_2005_11_27.csv.
-
Klicken Sie auf Apply (Anwenden).
-
Klicken Sie auf die Schaltfläche Zeitbereich. Um den gewünschten Zeitraum in der PerfMon-Protokolldatei anzugeben, ziehen Sie die Leiste auf die entsprechenden Start- und Endzeiten.
-
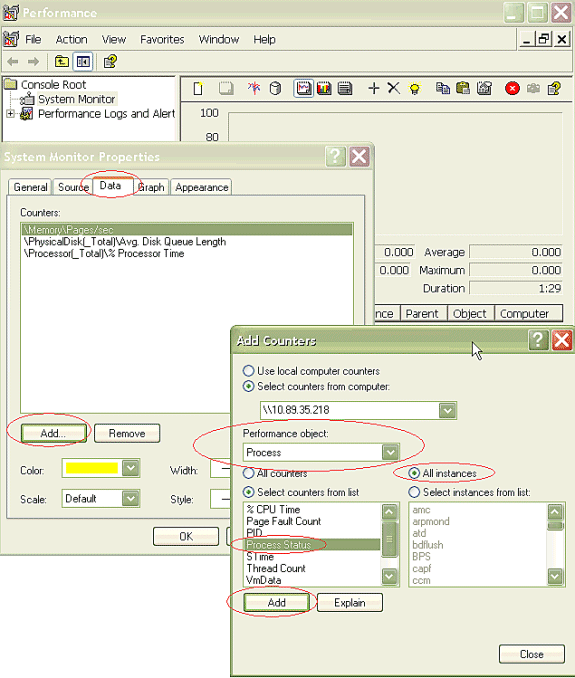
Um das Dialogfeld Indikatoren hinzufügen zu öffnen, klicken Sie auf die Registerkarte Daten und dann auf Hinzufügen. Fügen Sie Process aus dem Dropdown-Feld Leistungsobjekt hinzu. Wählen Sie Prozessstatus aus, und klicken Sie auf Alle Instanzen. Wenn Sie die Zählerauswahl abgeschlossen haben, klicken Sie auf Schließen.
-
Tipps zum Anzeigen des Protokolls:
-
Stellen Sie die vertikale Skalierung des Diagramms auf Maximum 6 ein.
-
Konzentrieren Sie sich auf die einzelnen Prozesse, und beachten Sie den Maximalwert von 2 oder mehr.
-
Löschen von Prozessen, die sich nicht im Unterbrechungsfreien Festplattenspeicher befinden.
-
Verwenden Sie die Hervorhebungsoption.
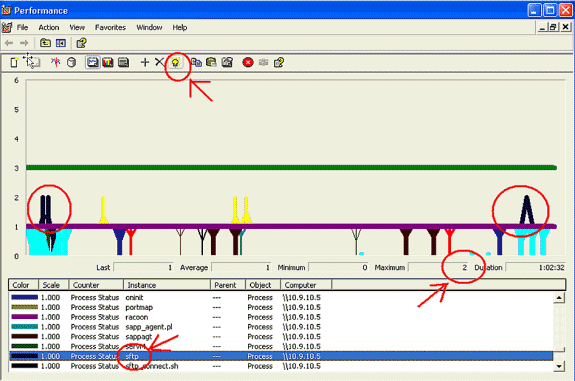
Hinweis: Prozessstatus 2 = Unterbrechungsfreier Festplattenschlaf ist verdächtig. Weitere Statusmöglichkeiten sind 0-Running, 1-Sleeping, 2-Unterbrechungsfreier Disk Sleep, 3-Zombie, 4-Traced oder gestoppt, 5-Paging, 6-Unknown
-










Code Gelb
Die Warnmeldung "Code Yellow" wird generiert, wenn der CallManager-Dienst in den Status "Code Yellow" wechselt. Weitere Informationen zum Status "Code Gelb" finden Sie unter Anrufdrosselung und Code Gelb-Status. Die CodeYellow-Warnung kann so konfiguriert werden, dass Trace-Dateien für die Fehlerbehebung heruntergeladen werden.
Der AverageExpectedDelay-Leistungsindikator stellt die aktuelle durchschnittliche erwartete Verzögerung bei der Verarbeitung eingehender Nachrichten dar. Wenn der Wert über dem Wert liegt, der im Service-Parameter "Code Yellow Entry Latency" angegeben ist, wird der CodeYellow-Alarm generiert. Dieser Leistungsindikator kann ein Schlüsselindikator für die Leistung der Anrufverarbeitung sein.
CodeYellow, aber Gesamt-CPU-Auslastung ist nur 25% - Warum?
CallManager kann aufgrund fehlender Prozessorressourcen in den CodeYellow-Zustand wechseln, wenn die Gesamt-CPU-Auslastung in einer 4-Virtual-Processor-Box nur etwa 25-35 Prozent beträgt.
Hinweis: Bei aktiviertem Hyper-Threading verfügt ein Server mit zwei physischen Prozessoren über vier virtuelle Prozessoren.
Hinweis: Ebenso ist CodeYellow auf einem Server mit zwei Prozessoren bei einer Gesamt-CPU-Auslastung von ca. 50 Prozent möglich.
Warnung: "Service Status is DOWN. Cisco Messaging-Schnittstelle."
Wenn RTMT sendet, lautet der Servicestatus "DOWN". Cisco Messaging-Schnittstelle. Warnmeldung, Sie müssen den Cisco Messaging Interface-Service deaktivieren, wenn CUCM nicht in ein Voice Messaging System eines Drittanbieters integriert ist. Wenn Sie den Cisco Messaging Interface-Dienst deaktivieren, werden weitere RTMT-Warnungen angehalten.
Zugehörige Informationen
Revisionsverlauf
| Überarbeitung | Veröffentlichungsdatum | Kommentare |
|---|---|---|
1.0 |
22-Jun-2007
|
Erstveröffentlichung |
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)