Diese Liste enthält die vorkonfigurierten CallManager-Warnungen.
- StartThrottlingCallListBLFSubscriptions
- AnrufversuchBlockiertDurchRichtlinie
- AnrufverarbeitungKnotenCPUpegging
- CARIDSEngineKritisch
- CARIDSEngineFehler
- CARSchedulerJobFehlgeschlagen
- CDRAgentSendFileFailed
- CDRFileZustellungFehler
- CDRHochwasserzeichenÜberschritten
- CDRMaximumDiskSpaceÜberschreitet
- CodeGelb
- DBChangeNotifyFailure
- DBReplikationsfehler
- DBReplicationTableOutSync
- DDRBlockPrevention
- DDRDeigen
- EMCCFailInLocalCluster
- EMCCFailInRemoteCluster
- ÜbermäßigeSprachqualitätBerichte
- IMEDibutedCacheInaktiv
- IMEOberkontingent
- IMEQualityAlert
- UnzureichendeFallbackIdentifiers
- IMEServiceStatus
- UngültigeAnmeldeinformationen
- NiedrigeTFTPServerHeartbeatRate
- MalwareCallTrace
- MedienlisteErschöpft
- MgcpDCannelOutOfService
- AnzahlRegistrierteGeräteÜberschreitet
- AnzahlRegistrierteGatewaysReduziert
- AnzahlRegistrierteGatewaysErhöht
- AnzahlRegistrierteMediengeräteReduziert
- AnzahlRegistrierteMediengeräteErhöhte
- AnzahlGelöschteRegistrierteTelefone
- RoutenlisteErschöpft
- SDLLinkOutOfService
- TCPSetupToIMEFail
- TLSConnectionZuIMEFail
- BenutzerEingabeFehler
NiedrigerVerfügbarerVirtuellerSpeicher und geringerSwapPartitionVerfügbarerFestplattenspeicher
Linux-Server neigen dazu, die Auslastung des virtuellen Speichers über einen bestimmten Zeitraum nicht zu löschen. Es hat sich gezeigt, dass sich diese Alarme summieren.
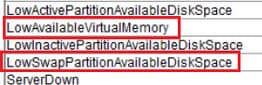
Linux funktioniert ein wenig anders als ein Betriebssystem.
Sobald Speicher einem Prozess zugewiesen wurde, wird er vom Prozessor nicht mehr wiederverwendet, es sei denn, ein anderer Prozess fordert mehr Speicher als den verfügbaren Speicher an.
Dies verursacht einen hohen virtuellen Arbeitsspeicher.
Eine Anforderung einer Erhöhung der Alarmschwelle bei den höheren Versionen des Call Managers ist im Defekt dokumentiert; https://bst.cloudapps.cisco.com/bugsearch/bug/CSCuq75767/?reffering_site=dumpcr
Bei Swap-Partitionen zeigt diese Warnung an, dass die Swap-Partition nur wenig freien Speicherplatz hat und vom System stark genutzt wird. Die Swap-Partition wird normalerweise verwendet, um die physische RAM-Kapazität bei Bedarf zu erweitern. Unter normalen Bedingungen, wenn RAM genug ist, sollte swap nicht zu viel verwendet werden.
Außerdem können diese RTMT-Warnungen auslösen, die durch eine Zusammenstellung temporärer Dateien verursacht werden. Ein Neustart des Servers wird empfohlen, um unnötige temporäre Dateien zu löschen.
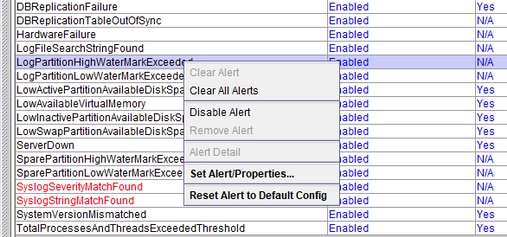
LogPartitionHighWaterMarkExceeded und LogPartitionLowWaterMarkExceeded
Wenn show status auf der CLI eines CUCM-Servers ausgeführt wird, wird ein Wert angezeigt, der den belegten und freien Prozentsatz der Protokollierungspartition im CUCM-Speicherplatz angibt. Diese Werte werden auch als gemeinsame Partition bezeichnet und geben den Speicherplatz an, der von den Protokollen/Ablaufverfolgungen und den CDR-Dateien auf dem Server belegt wird. Diese Werte sind zwar harmlos, können jedoch aufgrund von zu wenig Speicherplatz im Laufe der Zeit zu Problemen bei der Installation/Aktualisierung führen. Diese Warnungen dienen dem Administrator als Warnung, die Protokolle zu löschen, die sich im Laufe der Zeit im Cluster/Server angesammelt haben könnten.
LogPartitionLowWaterMarkExceeded: Diese Warnung wird generiert, wenn der gefüllte Speicherplatz die für die Warnung konfigurierten Schwellenwerte erreicht. Diese Warnmeldung dient als Vorabprüfung der Festplattennutzung.
LogPartitionHighWaterMarkExceeded: Diese Warnung wird generiert, wenn der gefüllte Speicherplatz die für die Warnung konfigurierten Schwellenwerte erreicht. Sobald die Warnung generiert wurde, beginnt der Server, die ältesten Protokolle automatisch zu bereinigen, um den Speicherplatz auf einen Wert zu reduzieren, der unter dem HighWaterMark-Schwellenwert liegt.
Als Best Practice sollten Sie die Protokolle manuell löschen, sobald die Warnung LogPartitionLowWaterMarkExceeded eingeht.
Dies geschieht in folgenden Schritten:
Schritt 1: Starten Sie RTMT.
Schritt 2. Wählen Sie Alert Central aus, und führen Sie dann folgende Aufgaben aus:
Wählen Sie LogPartitionHighWaterMarkExceeded aus, notieren Sie den Wert, und ändern Sie den Schwellenwert auf 60 %.
Wählen Sie LogPartitionLowWaterMarkExceeded aus, notieren Sie sich den Wert, und ändern Sie den Schwellenwert auf 50 %.
Das Polling erfolgt alle 5 Minuten. Warten Sie also 5-10 Minuten, und stellen Sie dann sicher, dass der erforderliche Speicherplatz verfügbar ist. Wenn Sie mehr Speicherplatz in der gemeinsamen Partition freigeben möchten, ändern Sie die Threadwerte LogPartitionHighWaterMarkExceeded und LogPartitionLowWaterMarkExceeded erneut in niedrigere Werte (z. B. 30 % und 20 %).
Geben Sie ihm 15 bis 20 Minuten, um den Platz in der gemeinsamen Partition freizugeben. Sie können den Rückgang der Festplattennutzung mithilfe des Befehls show status aus der CLI überwachen.
Das würde die gemeinsame Partition reduzieren.
CPUpegging
CpuPegging-Warnung überwacht die CPU-Auslastung auf Basis des konfigurierten Grenzwerts.
Wenn die Warnung zum CPU-Pegging eingeht, kann der Prozess, der die höchste CPU belegt, in der Systemausgabe links, d. h. in Prozess, angezeigt werden.
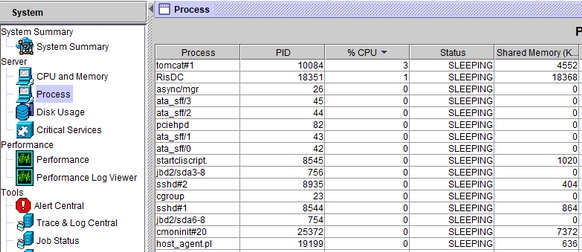
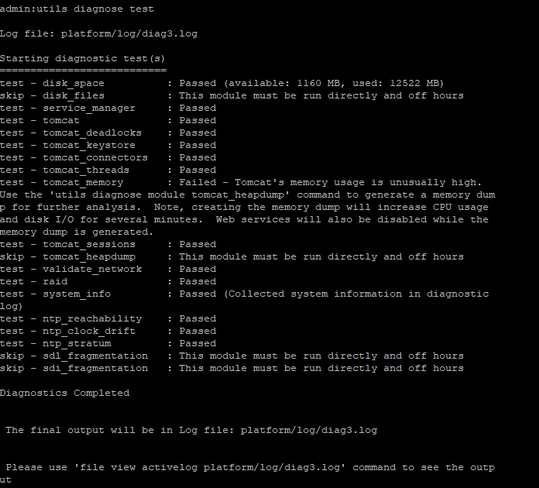
Aus der CLI des betroffenen Servers erhalten diese Ausgaben einen Einblick.
- utils diagnose test
- Prozesslade-CPU sortiert anzeigen
- Status anzeigen
- utils core active list
Es wird empfohlen, zu beobachten, ob die CPU-Spitze zu einer bestimmten Zeit oder zufällig auftritt. Tritt er zufällig auf, protokollieren die erforderlichen detaillierten CUCM-Ablaufverfolgungen sowie die RisDC-Leistungsprotokolle, um zu überprüfen, was den CPU-Spitzenwert auslöst. Wenn die Warnmeldungen zu einer bestimmten Tageszeit ausgegeben werden, kann dies auf geplante Aktivitäten wie DRS-Sicherung (Disaster Recovery System), CDR-Laden usw. zurückzuführen sein.
Anhand der Informationen darüber, welcher Prozess die meiste CPU beansprucht, werden bestimmte Protokolle zur weiteren Untersuchung herangezogen. Beispiel: Wenn der Täter Tomcat ist, werden die Tomcat-Protokolle benötigt.
 Feedback
Feedback