Einleitung
In diesem Dokument werden die neuen Speicherfunktionen der UCS-Server der M7- und M8-Generation sowie die erforderlichen Schritte zum Verständnis und zur Fehlerbehebung bei Speicherfehlern beschrieben.
Voraussetzungen
Anforderungen
Cisco empfiehlt, dass Sie über Kenntnisse in folgenden Bereichen verfügen.
- Grundlegende Informationen zum UCS
- Grundlegendes Verständnis der Speicherarchitektur
Verwendete Komponenten
Die Informationen in diesem Dokument basierend auf folgenden Software- und Hardware-Versionen:
- UCS-Server M7 und M8
- UCS-Manager
- Cisco Integrated Management Controller (CIMC)
- Cisco Intersight Managed Mode (IMM)
Die Informationen in diesem Dokument beziehen sich auf Geräte in einer speziell eingerichteten Testumgebung. Alle Geräte, die in diesem Dokument benutzt wurden, begannen mit einer gelöschten (Nichterfüllungs) Konfiguration. Wenn Ihr Netzwerk in Betrieb ist, stellen Sie sicher, dass Sie die möglichen Auswirkungen aller Befehle kennen.
Hintergrundinformationen
Übersicht über Speicherfehler
Speicherfehler gehören zu den häufigsten Fehlertypen auf modernen Servern. Fehler werden häufig erkannt, wenn versucht wird, einen Speicherort zu lesen, und der gelesene Wert nicht mit dem zuletzt geschriebenen Wert übereinstimmt.
Speicherfehler können weich oder hart sein. Einige Fehler können korrigiert werden, aber mehrere gleichzeitig auftretende Soft- oder Hard-Fehler bei einem einzelnen Speicherzugriff können nicht korrigiert werden.
Cisco UCS M7/M8-Speicher-RAS-Funktionen
Die Cisco UCS M7 und M8 Server verfügen über zuverlässige RAS-Funktionen, wie hier im Detail beschrieben. Dadurch werden die Auswirkungen von Speicherfehlern auf die Leistung und die Systemverfügbarkeit minimiert.
ECC auf Systemebene
Alle Cisco UCS M7-Server verwenden Speichermodule mit ECC-Codes, mit denen auf einen x4-DRAM-Chip beschränkte Fehler korrigiert und mögliche Doppelbitfehler in bis zu zwei Geräten erkannt werden können. Dies wird jetzt als System-Level-ECC bezeichnet, wie bei Servern älterer Generationen
.
Virtual Lock-Step (VLS)/Adaptive Double Device Data Correction (ADDC)-Ersatzschaltung
ADDDC Sparing kann zwei aufeinander folgende DRAM-Fehler korrigieren, wenn sie sich in derselben Region befinden. Diese Funktion verfolgt korrigierbare Fehler und ordnet fehlerhafte Bits dynamisch durch Ersatzkopien ("Sparing") von Inhalten in eine "Buddy"-Cache-Zeile zu. Dieser Mechanismus kann korrigierbare Fehler mindern, die bei unbehandelter Behandlung nicht korrigierbar werden können. Diese Funktion verwendet Virtual LockStep (VLS), um Cache-Line-Buddy-Paare innerhalb desselben Speicherkanals entweder auf der DRAM-Bankebene mit Bank-VLS oder auf der DRAM-Geräteebene mit Rank-VLS zuzuweisen.
.
On-die ECC
On-Die ECC ist eine neue Funktion in DDR5. Diese Funktion ist standardmäßig aktiviert. Alle Einzelbitfehler (Hard und Soft) werden durch DRAM korrigiert, bevor Daten an den Host übertragen werden. Diese korrigierten Daten werden jedoch nicht in DRAM zurückgeschrieben. Error Check and Scrub (ECS) ist die Funktion, die zum Scrubben und Korrigieren von Einzelbitfehlern im Speicher verwendet wird.
Error Check and Scrub (ECS)
ECS überprüft die DRAM-Chips regelmäßig (alle 24 Stunden) auf Fehler im Hintergrund, korrigiert diese, indem Daten in das Array zurückgeschrieben werden und eine Zählung der beim Scrub gefundenen Fehler bereitgestellt wird. Diese Funktion ist standardmäßig aktiviert.
Reparatur nach der Verpackung (PPR)
Bei der Reparatur nach dem Packen werden Ersatzzeilen verwendet, um eine fehlerhafte Zelle oder Zeile in einem DRAM-Gerät zu ersetzen.
Es gibt drei Typen: Soft PPR (rekonfigurierbar), Hard PPR (permanent) und Runtime PPR.
- Cisco UCS M7 Server mit Intel CPUs unterstützen "harte" PPR. Dies ist eine permanente Reparatur und wird während des Neustarts basierend auf den während der vorherigen Laufzeit gesammelten Fehlerdaten durchgeführt oder wenn während EMT Zeilenfehler auftreten.
- Reparaturen werden in der Regel bei Warm-/Kaltrückstellungen oder Wechselstromzyklen durchgeführt.
- Auf dem UCS M8 unterstützen alle drei PPR-Typen. Hard PPR ist standardmäßig aktiviert, Runtime PPR ist deaktiviert.
- Runtime PPR ermöglicht Reparaturen während des Systembetriebs ohne Auswirkungen auf die Betriebszeit.
- Wenn sowohl Hard- als auch Runtime-PPR aktiviert sind, werden alle PPR-Funktionen genutzt. Wenn Hard PPR deaktiviert ist, Runtime PPR jedoch aktiviert ist, wird standardmäßig Soft PPR verwendet.
- PPR ist eng mit korrigierbaren Fehlern verknüpft, und jeder korrigierbare Fehler generiert einen SEL-Datensatz, wenn PPR aktiviert ist.
PMIC (Power Management Integrated Circuit)
Der PMIC eines DIMMs ist ein wichtiges Merkmal von DDR5-Speichermodulen. Durch diese Integration wird die Energieverwaltungsfunktion vom Motherboard auf das Speichermodul selbst verschoben, was einige wesentliche Vorteile mit sich bringt.
Für DDR5-Speicher ist die PMIC-Fehlerbehandlung aktiviert.
- PMIC-Fehler generieren CELL-Datensätze sowohl während der Laufzeit als auch nach dem Start.
- Wenn während des Speichertrainings ein PMIC-Fehler in einem Speicherkanal erkannt wird, wird der betroffene DIMM abgebildet, und das System startet weiter mit reduziertem Speicher
Protokollanalyse
Dateien zum Einchecken im technischen Support
UCSM_X_TechSupport > sam_techsupportinfo liefert Informationen über DIMM und Speicher-Array.
Technischer Support für Chassis/Server
CIMCX_TechSupport\tmp\CICMX_TechSupport.txt -> Allgemeine technische Support-Informationen zu Server X.
CIMCX_TechSupport\obfl\obfl-log -> OBFL-Protokolle liefern fortlaufende Protokolle über Status und Start von Server X.
CIMCX_TechSupport\var\log\sel -> SEL-Protokolle für Server X.
Navigieren Sie auf Basis der Plattform/Version zu den Dateien im technischen Support-Paket.
RAS -Für ECS (Error Check and Scrub) CE-Fehlerortusw., die während der Laufzeit auf jedem Scrub gesammelt werden
/nv/etc/BIOS/bt/DDR5_CISCO_ECS
AMT wird beim nächsten Start automatisch ausgeführt, wenn CE- und UCE-Fehler auf DIMMs auftreten
nv/etc/BIOS/bt/MrcOut.
AMT_TEST_MUSTER:
ADV_MT_SAMSUNG
AMT_ERGEBNIS: BESTANDEN.
PMIC-Fehler: /nv/etc/DIMM-PMIC.txt
M8 Server enthält :-
nv/etc/BIOS/bt >MrcOut
Diese Dateien liefern Informationen über den Speicher aus der BIOS-Ebene.
Dort können Informationen wieder mit DIMM-Zustandsberichtstabellen querreferenziert werden.
Beispiel vom AMD-Server:-
nv/etc/BIOS/bt >MrcOut
Es enthält:
- BIOS-Version, Erstellungsdatum und -zeit
- PSP-Firmwareversionen
- DIMM Präsenz und Status (zeigt an, dass DIMM vorhanden ist oder nicht)
- DIMM-Konfigurationsdetails:
2025/08/14 13:44:34
BIOS ID : C245M8.4.3.6b.0 Built 04/28/2025 14:15:22
=====================
PSP Firmware Versions
=====================
ABL Version: 100E8012
PSP: 0.29.0.9B
PFMW (SMU): 4.71.126.0
SEV: 1.1.37.28
PHY: 0.1.38.0
MPIO: 1.0.2D.C4
TF MPDMA: 0.47.3.0
PM MPDMA: 0.47.46.0
GMI: AB.1.27.0
RIB: 2.0.8.39
SEC: D.E.90.71
PMU: 0.0.90.4E
EMCR: 0.0.E0.4E
uCode B1: 0xA101154
DIMM Status:
|=======================|
| Memory | DIMM Status |
| Channel | |
|=======================|
| P1_A | 01 |
| P1_B | 01 |
| P1_C | 01 |
| P1_D | 01 |
| P1_E | 01 |
| P1_F | 00 |
| P1_G | 01 |
| P1_H | 01 |
| P1_I | 01 |
| P1_J | 01 |
| P1_K | 01 |
| P1_L | 00 |
| P2_A | 01 |
| P2_B | 01 |
| P2_C | 01 |
| P2_D | 01 |
| P2_E | 01 |
| P2_F | 00 |
| P2_G | 01 |
| P2_H | 01 |
| P2_I | 01 |
| P2_J | 01 |
| P2_K | 01 |
| P2_L | 00 |
|=======================|
DIMM Configuration:
=================================================
MbistTest = Disabled
MbistAggressor = Disabled
MbistPerBitSlaveDieReport = Enabled
DramTempControlledRefreshEn = Disabled
UserTimingMode = Disabled
UserTimingValue = Disabled
MemBusFreqLimit = Disabled
EnablePowerDown = Disabled
DramDoubleRefreshRate = Disabled
PmuTrainMode = 0x0000
EccSymbolSize = 0x0000
UEccRetry = Disabled
IgnoreSpdChecksum = Disabled
EnableBankGroupSwapAlt = Disabled
EnableBankGroupSwap = Disabled
DdrRouteBalancedTee = Disabled
OdtsCmdThrotEn = Disabled
OdtsCmdThrotCyc = Disabled
=================================================
Enhanced Memory Context Restore : APOB_SAVED
2025/08/14 13:44:34
MCA-Ausgangsdateibestand:-
Diese Datei enthält Informationen über MCA-Register aller Banken .
(Immer wenn ein UCE-Fehler erkannt wurde)
--- START OF MCA FILE ---
Timestamp H:M:S 13:44:15 D:M:Y 14:8:2025
--- Note ---
The legacy MCA registers include:
MCA_CTL - Enables error reporting via machine check exception.
MCA_STATUS - Logs information associated with errors.
MCA_ADDR - Logs address information associated with errors. The use of AMD Secure Memory Encryption may change the information logged in the address register.
MCA_MISC0 - Logs miscellaneous information associated with errors.
The MCA Extension registers include:
MCA_CONFIG - Provide configuration capabilities for this MCA bank.
MCA_IPID - Provides information on the block associated with this MCA bank.
MCA_SYND - Logs physical location information associated with a logged error.
MCA_DESTATUS - Logs status information associated with a deferred error.
MCA_DEADDR - Logs address information associated with a deferred error.
MCA_MISC[1:4] - Provides additional threshold counters within an MCA bank.
MCA_TRANSSYND - Logs location information associated with a transparent error.
MCA_TRANSADDR - Logs address information associated with a transparent error.
LS - Load-Store Unit -> Bank 0
IF - Instruction Fetch Unit -> Bank 1
L2 - L2 Cache Unit -> Bank 2
DE - Decode Unit -> Bank 3
Empty/Unused bank -> Bank 4
EX - Execution Unit -> Bank 5
FP - Floating Point Unit -> Bank 6
L3 - L3 Cache Unit -> Bank 7 to 14
MP5 - Microprocessor5 Management Controller -> Bank 15
PB - Parameter Block -> Bank 16
PCS-GMI - GMI Controller -> Bank 17 to 18
KPX-GMI - High Speed Interface Unit(GMI) -> Bank 19 to 20
UMC - Unified Memory Controller -> Bank 21 to 22
CS - Coherent Station -> Bank 23 to 24
NBIO - NorthBridge IO Unit -> Bank 25
PCIE - PCIe Root port -> Bank 26 to 27
PIE - Power Management, Interrupts, Etc -> Bank 28
SMU - System Management Controller Unit -> Bank 29
PCS_XGMI - XGMI Controller -> Bank 30
KPX_SERDES - High Speed Interface Unit(XGMI)-> Bank 31
Empty/Unused bank -> Bank 32 to 63
Total BankNumber = 32
MC Global Capability Value = 120
MC Global Status Value = 0
MC Global Control Value = 0
Number of processor = 64
ProcNum BankNum Socket CCD CCX Core Thread MCA Bank Status MCA Bank Address MCA Configuration MCA IPID MSR VAL MCA SYND MSR VAL MC MISC0 MSR VAL MC MISC1 MSR VAL MC DESTAT MSR VAL MC DEADDR MSR VAL MC SYND1 MSR VAL MC SYND2 MSR VAL
Timestamp H:M:S 13:44:32 D:M:Y 14:8:2025
--- END OF MCA FILE ---
Beispiel für einen PMIC-Fehler in Vertriebsprotokollen:
Wenn auf dem DIMM ein Laufzeit-PMIC-Fehler auftritt, wird das SEL-Protokoll wie unten dargestellt generiert, und der Host wird deaktiviert.
- 2024-06-11 20:26:36 IST ◆Warning System Software event: Speichersensor, Speicher fehlgeschlagen (PMIC-Fehler erkannt und isoliert) wurde aktiviert, DIMM-Socket 1, Kanal A, CPU 2 aktiviert

Das fehlerhafte DIMM wird vom BIOS beim nächsten Einschalten des Hosts erkannt. Unten sehen wir SEL.

Ein Fehler wird wie unten gezeigt ausgelöst.

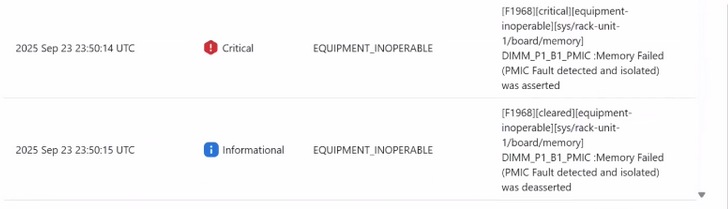
Fehlerbehebung bei RAS-Fehlern
Im Allgemeinen werden diese Fehler im UCS Manager als RAS-Ereignis angezeigt.
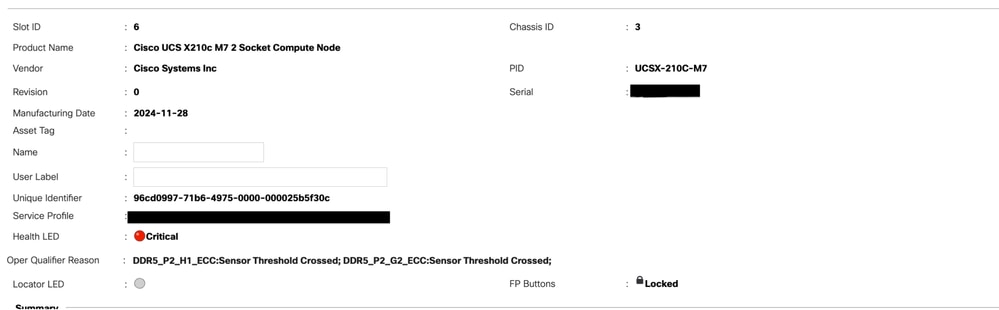
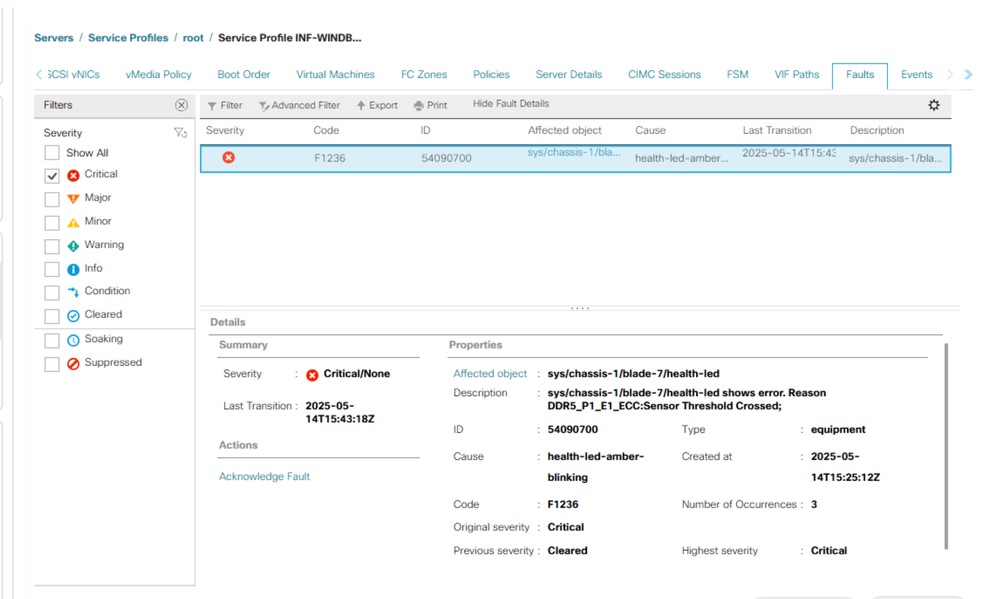
UCSM CLI-Befehle zum Zurücksetzen aller Speicherfehlerindikatoren:
UCS-A# Scope Server x/y
UCS-A/Chassis/Server # Reset-All-Memory-Errors
UCS-A/Chassis/Server* # Commit
So löschen Sie die SPD-Daten:
Server ausschalten
Führen Sie dann die folgenden Befehle in der UCSM CLI aus:
UCS-A# connect cimc x/y
UCS-A/Chassis/Server # Reset-All-Memory-Errors
UCS-A/Chassis/Server* # Commit
Wichtige Fehler
1. Cisco Bug-ID CSCwo62396
2. Cisco Bug-ID CSCwq33148
3. Cisco Bug-ID CSCwh73760
 Feedback
Feedback