ML-basierte Dokumentklassifizierung für effizientes SvD-Policy-Management verwenden
Inhalt
Einleitung
Dieses Dokument beschreibt die Verwendung der ML-basierten Dokumentenklassifizierung (Built with Meta Llama 3) zur Vereinfachung und Verbesserung des Richtlinienmanagements zum Schutz vor Datenverlust (Data Loss Prevention, DLP).
Überblick
Die ML-Dokumentenklassifizierung verbessert die Inhaltszuordnung und vereinfacht das DLP-Richtlinienmanagement. Sie können aus vordefinierten, vorab geschulten Dokumenttypen auswählen, sodass komplexe Datenklassifizierungen nicht mehr von Grund auf auf auf Begriffen und Mustern basieren müssen.
Verwenden der ML-basierten Dokumentklassifizierung
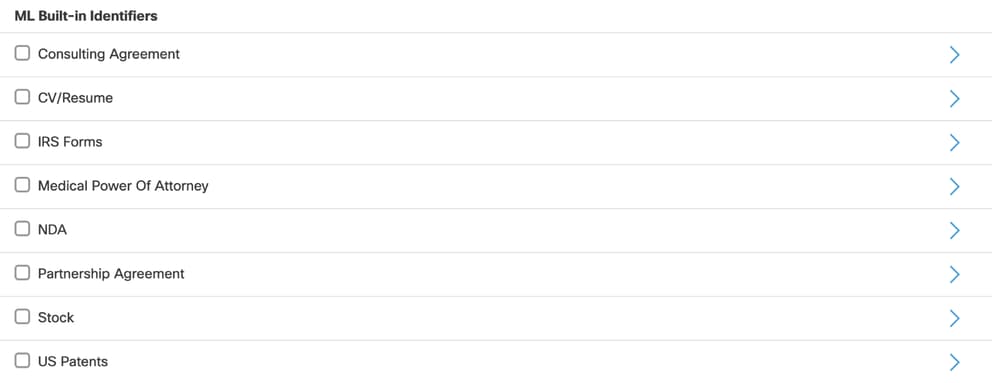
- Die ML-basierte Dokumentenklassifizierung ist als integrierter Bezeichner verfügbar, wenn Sie eine Datenklassifizierung erstellen.
- Alle unterstützten ML-basierten Bezeichner werden während der Einrichtung der Datenklassifizierung im Abschnitt ML-integrierte Bezeichner angezeigt.
 26221783199892
26221783199892
Unterstützte Dokumenttypen
Sie können die ML-basierte Klassifizierung für folgende Dokumenttypen verwenden:
- Beratungsvereinbarungen
- Lebensläufe und Lebensläufe
- IRS-Formulare
- Ärztliche Vollmacht
- Vertraulichkeitsvereinbarungen (NDA)
- Partnerschaftsabkommen
- Aktien- und US-Patente
Unterstützte Sprachen und Regionen
Die erste Version unterstützt nur Dokumente in englischer Sprache. Weitere Sprachen und Regionen sollen in Zukunft unterstützt werden.
Multimode-DLP-Unterstützung
Die ML-basierte Dokumentenklassifizierung funktioniert sowohl mit Realtime DLP als auch mit SaaS API DLP. Es ist mit allen DLP-unterstützten Dateitypen kompatibel.
Zugehörige Ressourcen
In der Secure Access- und Umbrella-Dokumentation finden Sie Hinweise zur Verwendung von ML-basierten Datenkennungen in Datenklassifizierungen und SvD-Regeln:
- Sicherer Zugriff: Integrierte Daten-IDs
- Regenschirm: Integrierte Daten-IDs
Revisionsverlauf
| Überarbeitung | Veröffentlichungsdatum | Kommentare |
|---|---|---|
2.0 |
20-Jul-2026
|
Erstveröffentlichung |
1.0 |
21-Oct-2025
|
Erstveröffentlichung |
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)