Anwenderbericht zu CNC-Upgrades
Inhalt
Einleitung
In diesem Dokument wird ein Anwenderbericht über eine komplexe und umfassende Migration eines kabelgebundenen Wireless-Netzwerks von Cisco CNC 4.1 zu 7.1 per lift-and-shift beschrieben.
Zusammenfassung
Dieses Whitepaper stellt eine detaillierte Fallstudie zur Migration eines großen kabelgebundenen Netzwerks von Cisco Crosswork Network Controller (CNC) Version 4.1 auf Version 7.1 vor. Aufgrund des Fehlens eines Upgrademechanismus war für die Umstellung eine vollständige Lift-and-Shift-Bereitstellung erforderlich, die eine erhebliche Komplexität in den Bereichen Architektur, Betrieb und Integration für mehr als 2.000 Netzwerkgeräte und mehrere voneinander abhängige Systeme mit sich brachte. In der Studie werden die Herausforderungen in mehreren Bereichen untersucht.
Ein Hauptergebnis zeigt, wie wichtig die Automatisierung ist, um Skalierbarkeit, Genauigkeit und betriebliche Determinismus zu gewährleisten, insbesondere bei Workflows mit hohem Volumen. Die Ergebnisse zeigen außerdem, dass die Produktionsumgebungen erheblich von den kontrollierten Laborbedingungen abweichen. Dies erfordert eine adaptive Fehlerbehebung, eine iterative Validierung und einen anhaltenden Austausch mit den Technikerteams des TAC und der Geschäftsbereiche. Diese Arbeit liefert praktische Einblicke, validierte Methoden und empfohlene Best Practices, die als Referenzentwurf für künftige CNC-Upgrades und umfangreiche Veränderungen der Orchestrierungsplattform dienen.
Hintergrund
Die rasante Verbreitung von 5G-Netzwerken, die schnelle Einführung vernetzter Geräte und die Digitalisierung von Unternehmens- und Verbraucherumgebungen haben zu einem erheblichen Anstieg des Datenverkehrsvolumens und der Vielfalt der Dienste geführt, die sicher und zuverlässig skaliert bereitgestellt werden müssen. Die Communications Service Provider (CSP) betreiben heute hochdynamische Netzwerke, in denen traditionelle, isolierte Tools oft die Komplexität erhöhen, das Anwendererlebnis beeinträchtigen und die Betriebskosten erhöhen.
Um wettbewerbsfähig zu bleiben, führen Netzbetreiber zunehmend modernisierte Betriebsmodelle ein, die auf Automatisierung, Virtualisierung, SDN-Prinzipien und analysegestützten, selbstoptimierenden Netzwerken basieren.
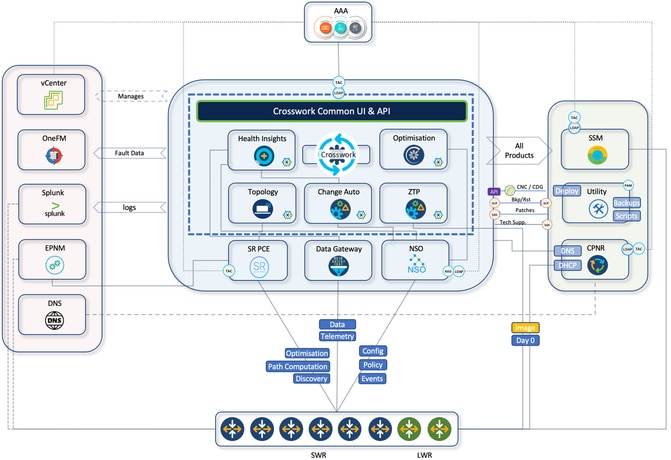
Der Cisco Crosswork Network Controller (CNC) unterstützt diese Transformation durch die Vereinfachung betrieblicher Workflows, die Senkung der Gesamtbetriebskosten und die absichtsbasierte Automatisierung in heterogenen Transportnetzwerken. CNC bietet eine einheitliche Plattform für die Servicebereitstellung, die Überwachung des Netzwerkzustands und die Echtzeit-Optimierung und bietet Betreibern eine zentrale Oberfläche für das proaktive und effiziente Management großer IP-Netzwerke.
Die zugrunde liegende Crosswork-Infrastruktur bietet ein ausfallsicheres, skalierbares Cluster-Framework, auf dem alle CNC-Anwendungen ausgeführt werden. Für CNC 7.1 umfasst dies Module wie Optimization Engine, Active Topology, Change Automation, Health Insights, Element Management Functions (EMF), Service Health und Crosswork Workflow Manager (CWM), die jeweils zur End-to-End-Orchestrierung und -Absicherung beitragen.
Die Aufrüstung von CNC bringt jedoch einzigartige Herausforderungen mit sich. CNC bietet keine Unterstützung für Upgrades vor Ort, sodass eine vollständige Lift-and-Shift-Bereitstellung erforderlich ist, bei der die neue Umgebung parallel zur bestehenden erstellt wird und alle Daten und Services auf die neue Version migriert werden. Diese Fallstudie untersucht ein umfassendes Upgrade von CNC 4.1 auf CNC 7.1 für einen großen australischen Service-Aggregator, der Backbone-Services für alle anderen Service Provider bereitstellt.
Die Migration war besonders komplex, da mehrere benutzerdefinierte Leitfäden zur Änderungsautomatisierung, benutzerdefinierte Integritätskennzahlen, L2/L3-VPN-Service-Abstimmungsanforderungen und ein sicheres ZTP erforderlich waren.
Der große Versionssprung führte zu zusätzlicher Unsicherheit angesichts interner Änderungen der Architektur und des Verhaltens, die es schwierig machten vorherzusagen, wie sich bestehende Anwendungsfälle in der neuen Version verhalten würden. Dies erforderte eine umfassende Validierung und Abstimmung aller Anwendungsfälle.
Es wurde eine umfangreiche Planung in die Ermittlung der optimalen Ressourcenzuweisung investiert, einschließlich der Anzahl der Hybrid-/Arbeitsknotenpunkte, der CDG-Verteilung und der PCE-Bedarfsbestimmung, sowie in die Frage, ob Ihr vorhandener Ressourcenbedarf erhalten werden kann.
Die anfängliche Bereitstellung und Validierung von CNC 7.1 wurde in einem internen CALO-Labor durchgeführt. Das Labor bietet eine sichere Umgebung für Experimente, die Feinabstimmung von Konfigurationen und die Vertrauensbildung. Anschließend erfolgte die Bereitstellung in der internen Testumgebung, die die Produktion genau spiegelt. Die letzte Phase umfasste die Bereitstellung von CNC 7.1 in der Produktion, die Anwendung von Konfigurationsänderungen auf Geräteebene und die Durchführung einer schrittweisen Migration aller Geräte und zugehörigen Services auf den neuen Controller.
Produktionsnetzwerk
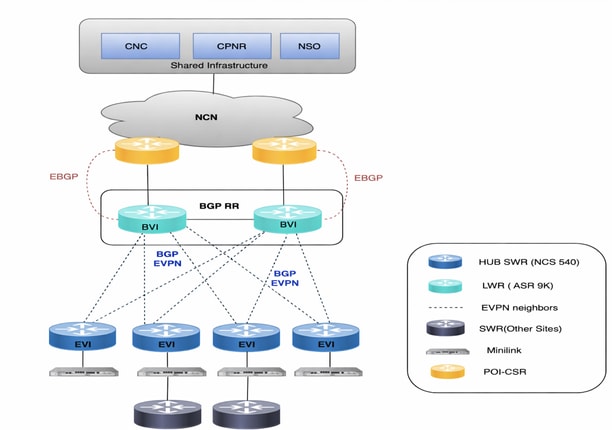
Das Air-Gap Produktionsnetzwerk ist über weite Teile Australiens verteilt. Mit mehr als 2.000 Geräten, von NCS bis hin zu ASR9Ks, verwaltete CNC alle diese Geräte, indem eine Live-Topologieansicht bereitgestellt wurde. Bei ca. 2.000 Geräten handelte es sich um NCS540-Geräte, die lokal als SWR (Small Wireless Router) mit IOS-XR 24.3.2 und 30 bekannt sind. Bei diesen Geräten handelte es sich um ASR-9Ks (Version 7.5.2), die lokal als LWRs (Large Wireless Router) bezeichnet werden.
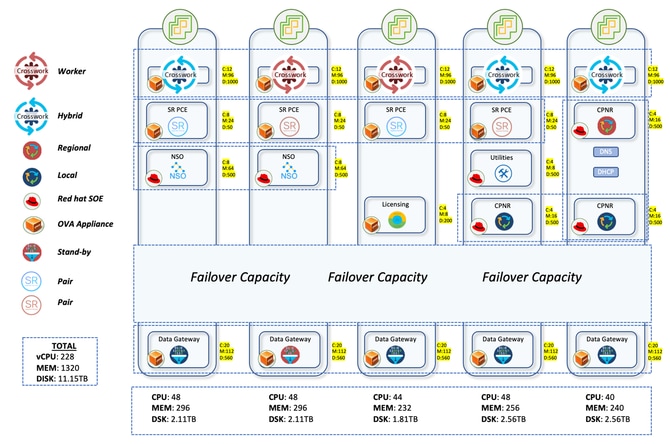
Das Crosswork-Setup bestand aus 3 Hybridknoten und 2 Workerknoten. Es gab insgesamt 5 CDGs für die Geräte, von denen 4 aktiv und 1 der Standby-Knoten waren. Dies bot nur begrenzten Schutz, da der Pool nur über ein Standby-CDG verfügte. Angesichts Ihrer Anforderungen wurde dies jedoch genehmigt. Da sich alle virtuellen Systeme in einem Rechenzentrum befinden, war die Entscheidung für nur ein Standby-Gerät einfacher.
Die CDG ist die Komponente, die die Datenerfassung von Geräten über verschiedene Protokolle wie SNMP, CLI und GNMI verwaltet. Die von CDG gesammelten Daten werden über die interne Kafka dem Crosswork ausgesetzt. Ein an Crosswork integriertes Gerät muss an ein CDG angeschlossen werden, damit sich das Daten-Gateway mit dem Gerät verbinden und die Gerätedaten abrufen kann.
Auch über die Geräteverteilung für die CDGs wurde intensiv nachgedacht. Bei der früheren Bereitstellung wurden die Geräte nach dem Zufallsprinzip auf die CDGs verteilt. Dies führte zu einer sehr schiefen Verteilung, wobei einige CDGs mehr Geräte transportierten, während es 1-2 CDGs mit sehr weniger Geräten gab. Dies führte zu einem übermäßigen Verbrauch und zu einer übermäßigen Belastung einiger CDGs, während andere unzureichend ausgestattet waren.
Bei diesem Upgrade ging es darum, jeweils 700 SWRs an die 4 aktiven CDGs zu verteilen. 2100 SWRs kamen in den ersten drei CDGs zusammen. LWRs, die sehr schwer an der Schnittstellenfront waren, waren alle für die vierte CDG reserviert. Obwohl es sich um eine sehr kleine Zahl mit einer Zahl von 30 handelte, stellte diese Zuweisung sicher, dass selbst wenn mehr Sammlungen von diesen Geräten durchgeführt würden, die CDG nicht stark belastet würde. Auch das nachträgliche Onboarding von SWRs würde an die 4. CDG gehen. Dadurch wurde eine gleichmäßige Verteilung in den ersten drei CDGs mit mehr Platz in der 4. zur Aufnahme neuer Geräte gewährleistet.
SR-PCE wurde in zwei Paaren bereitgestellt, d. h. vier VMs wurden auf verschiedenen Host-Systemen verteilt. Ein Paar verwaltet sieben POI-Standorte, das andere die verbleibenden acht POI-Standorte. Die Topologieaktualisierungen auf der CNC-Benutzeroberfläche erfolgen über SR-PCE. Er erfasst die Netzwerktopologie über BGP-LS-Peering mit anderen LWR-Routern. Diese Komponente wird auch in allen Fallbeispielen der Datenverkehrstechnik eingesetzt, bei denen der Controller den Datenverkehr über verschiedene Pfade leitet.
Um alle Anwendungsfälle für die Servicebereitstellung und die Gerätekonfiguration zu verarbeiten, muss der NSO in Verbindung mit der CNC verwendet werden. Für das Produktionsnetzwerk wurden zwei NSOs der Version 6.4.1.1 bereitgestellt, die im Hochverfügbarkeitsmodus im Tandem arbeiten. SR-PCE (Segment Routing Path Computation Element) ist die erforderliche Komponente für die Bereitstellung der Topologie-Updates für CNC und für die Verarbeitung der Echtzeit-Fallstudien aus dem Bereich Traffic Engineering. Hier wurden vier SR-PCEs mit Version 25.2.1 bereitgestellt, wobei jedes PCE mit zwei verschiedenen LWRs verbunden war.
Migrationsworkflow von CNC 4.1 auf CNC 7.1
Für die CNC-Bereitstellung war es die bevorzugte Wahl, mit der Docker-basierten Lösung fortzufahren. Da der Kunde jedoch die Einrichtung des Dockers am Standort nicht genehmigte, gab es keine andere Möglichkeit, als die manuelle Bereitstellung mit vCenter fortzusetzen. Die Bereitstellung dauert im Vergleich zur skriptbasierten Version länger, da in der vCenter-GUI Eingaben mehrmals vorgenommen werden müssen.
Nachdem die CNC-Bereitstellung abgeschlossen war, wurden alle erforderlichen Anwendungen mit der von der BU bereitgestellten Installationsdatei für automatische Aktionen bereitgestellt, die die Anwendungen auf einmal hochlädt und aktiviert, wodurch sich die Zeit für die manuelle Ausführung verringert. Die erste Ebene wurde bereitgestellt, die die Crosswork Optimization Engine, die aktive Topologie, den Service-Status, Funktionen für das Element-Management und den Crosswork Workflow Manager umfasst. Darüber hinaus wurden die Add-on-Pakete eingerichtet, die Change Automation und Health Insight umfassen.
CWM und SH hatten keine Anwendungsfälle. Sie wurden jedoch bereitgestellt, da sie an einigen Anwendungsfällen interessiert waren, die von diesen Anwendungen in der nächsten Version angeboten werden.
Nachdem die Anwendungen eingerichtet waren, bestand der nächste Schritt darin, die Daten aus der alten CNC-Version zu migrieren. Dazu gehören in erster Linie die Berechtigungsprofile, Anbieter, Tags, benutzerdefinierte Playbooks, benutzerdefinierte KPIs, Rollen, sZTP-Gutscheine und alle anderen Daten. CNC bietet die Exportoption für alle diese Geräte, die genutzt und dann in die neue CNC importiert werden können.
Sobald diese eingerichtet sind, sollten Sie mit der Gerätemigration beginnen. Wenn bei Upgrades die neue CNC in einem neuen Subnetz im Vergleich zur älteren implementiert wird, müssen ACL-Änderungen an den Geräten vorgenommen werden, um die Erreichbarkeit mit der neuen CNC sicherzustellen. Dies ist ein zeitaufwendiger Prozess, da ein Benutzer sich manuell bei jedem Gerät anmelden und die Konfiguration ändern muss.
Nachdem diese ACL-Änderungen vorgenommen wurden, müssen die Geräte in die neue CNC importiert und an die CDGs angeschlossen werden. Wenn die Erreichbarkeit korrekt ist und die SSH- und SNMP-Anmeldeinformationen korrekt sind, werden die Geräte auf der CNC als erreichbar angezeigt und können ebenfalls an den NSO (Network Services Orchestrator) angeschlossen werden.
Auf Seiten des NSO müssen alle erforderlichen Pakete installiert und betriebsbereit sein, damit die CNC mit dem NSO kommunizieren kann und umgekehrt. Um beispielsweise die Geräte von CNC automatisch an den NSO anzubinden, ist das DLM-Funktionspaket obligatorisch. Wenn der NSO MDT-Sensorpfade auf dem Gerät konfigurieren muss, muss das TM-TC-Paket ebenfalls auf dem NSO bereitgestellt werden. Der Kern besteht darin, dass das relevante Paket je nach Anwendungsfall auf dem NSO bereitgestellt werden muss.
Anstatt die erforderlichen Pakete, insbesondere die Transport-SDN-Pakete, manuell bereitzustellen, wurde ein automatisiertes Skript für die Bereitstellung entwickelt. Mit dem Upgrade auf CNC 7.1 wurden die TSDN-Pakete aktualisiert. Diese aktualisierten Pakete sind für die Bereitstellung auf dem NSO-Server vorgesehen, um sicherzustellen, dass die L2/L3-Bereitstellung in der aktualisierten Umgebung weiterhin unterstützt wird. Das Skript automatisiert die Installation der aktualisierten TSDN-Pakete und lädt die erforderlichen Metadaten in den NSO, sodass dieser Services nach Bedarf bereitstellen kann.
Eine Instanz des Cisco Smart Software Manager (SSM)-Lizenzservers und drei Instanzen von Cisco Prime Network Registrar (CPNR) werden ebenfalls auf verschiedenen Hosts bereitgestellt.
CNC-Architektur und Integration mit anderen Komponenten
CNC bietet eine einzige Plattform für die Bereitstellung, Optimierung und Visualisierung bereitgestellter Services über eine einheitliche Benutzeroberfläche. Hier ist eine kurze Zusammenfassung der internen CNC-Komponenten, die in der CNC-Plattform-Suite und den Anwendungsfällen vorhanden sind.
- Aktive Kreuzstruktur-Topologie (Cat):
- Interne Komponentenanwendung verteilt auf CNC-VM-Knoten
- Bietet End-to-End-Echtzeit-Transparenz des abgestimmten Bestands
- Integration von Bestandsinformationen aus verschiedenen Datenquellen in ein einziges Display
- Berechnung des Transportnetzwerkpfads
- Topologieerkennung
- Crosswork Optimization Engine (COE):
- Interne Komponentenanwendung verteilt auf CNC-VM-Knoten
- Netzwerkoptimierung in Echtzeit
- Topologievisualisierung in Echtzeit
- SR-TE-Visualisierungen und -Bereitstellung
- RSVP-TE-Visualisierung und -Bereitstellung
- Bandwidth-on-Demand
- Kreuzversuch (CHI):
- Interne Komponentenanwendung verteilt auf CNC-VM-Knoten
- KPI-Überwachung
- Warnungs-Dashboard
- Crosswork Change Automation (CCA):
- Interne Komponentenanwendung verteilt auf CNC-VM-Knoten
- Dev-Ops-Tool mit sofort einsatzbereiten strategischen Leitfäden
- Planen der Ausführung von Kampagnen zur gewünschten Zeit
- HI-KPIs warnen bei vorgeschlagenen Kampagnen zur Problembehebung vor Nähungen
Architekturdiagramm
Netzwerkdiagramm
CNC 4.1 → 7.1 Detaillierter Migrations-Workflow
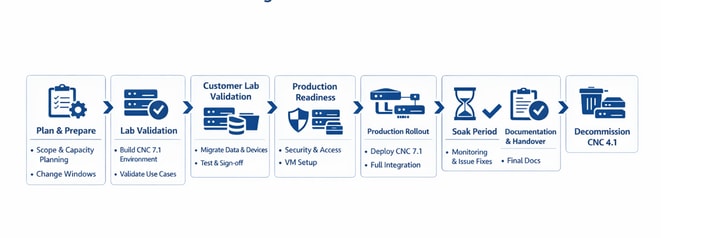
Phasenweise End-to-End-Migration von älteren CNCs 4.1 zu CNCs 7.1 (derselbe Fluss kann für jedes CNC-Upgrade unabhängig von der Version verfolgt werden)
| Planung |
› |
Labor |
› |
Kundenlabor |
› |
Produktreif |
› |
Einführung in die Produktion |
› |
Einweichzeit |
› |
Übergabe |
› |
Stilllegen |
| PHASE 1 1 Planung und Vorbereitung
|
|||||
| ▼ |
|||||
| PHASE 2 2 Interne Laborvalidierung
|
|||||
| ▼ |
|||||
| PHASE 3 3 Validierung im Kundenlabor
|
|||||
| ✓ ATP im Labor durchführen und sich abmelden lassen |
|||||
| ▼ |
|||||
| PHASE 4 4 Produktionsbereitschaft
|
|||||
| ▼ |
|||||
| PHASE 5 5 Produktionsumstellung ↻ Wiederholt alle Schritte aus Phase 3 in der Produktionsumgebung
|
|||||
| ✓ Produktionsbereitstellung |
|||||
| ▼ |
|||||
| PHASE 6 6 Einweichzeit
|
|||||
| ▼ |
|||||
| PHASE 7 7 Dokumentation und Übergabe
|
|||||
| ▼ |
|||||
| PHASE 8 8 Außerbetriebnahme älterer CNC-Geräte 4.1
|
|||||
Anwendungsfälle
L2VPN-Servicebereitstellung (EVPN-basiert)
Der L2VPN-Service bietet Layer-2-Ethernet-Konnektivität über mehrere SWRs hinweg, wobei einige Services auf LWRs verankert sind. Die aktive CNC-Topologie wird für die Servicebereitstellung verwendet, während die gesamte umgebungsspezifische Logik über benutzerdefinierte NSO-Vorlagen implementiert wird.
Die L2VPN-Bereitstellung wird als Day2-Konfigurationsaktivität behandelt und erfordert vom Betreiber bereitgestellte Serviceattribute.
Benutzerdefinierte NSO-Vorlagen
Es wurden mehrere benutzerdefinierte Vorlagen erstellt, um sie an umgebungsspezifischen Benennungskonventionen und Schnittstellenverhalten auszurichten:
- CT-l2vpn-swr-hub-and-lwr
Verarbeitet die Namensunterschiede zwischen den Hub-Seiten für Bridge-Gruppen und Bridge-Domänen auf SWR-Hubs und LWRs. - CT-l2vpn-swr-nonhub-100/101/102/105
Entfernt die ZTP-Uplink-Schnittstelle aus der Standard-EVPN-Bridge-Gruppe und der Bridge-Domäne für jede VLAN-spezifische EVI.
Diese Vorlagen gewährleisten eine konsistente EVPN-Konfiguration im gesamten Netzwerk und abstrahieren Unterschiede zwischen den Hardwareebenen.
L3-VPN-Servicebereitstellung (VRF-basiert)
Der L3-VPN-Anwendungsfall ermöglicht die Layer-3-Servicebereitstellung über mehrere SWRs als Endpunkte. Die Bereitstellung erfolgt über die aktive CNC-Topologie, wobei umgebungsspezifische Anforderungen mithilfe einer benutzerdefinierten NSO-Vorlage implementiert werden.
Wie bei L2VPN handelt es sich um eine Day-2-Konfigurationsaktion, für die Eingaben des Betreibers erforderlich sind.
Benutzerdefinierte NSO-Vorlage
- CT-l3VPN-SWR
Erfassung VRF-spezifischer Parameter (AS-Nummer, VRF-Name, Präfix-Set, Name der Routenrichtlinie, Route Distinguisher) und Erstellung der erforderlichen BGP-Import-/Exportrichtlinie, einschließlich Neuverteilung verbundener Routen mithilfe einer benutzerdefinierten Routenrichtlinie.
Traffic Engineering
Die Crosswork Optimization Engine (COE)-Anwendung der CNC-Suite hilft, den Datenverkehrsfluss im Netzwerk auf der Grundlage der gewünschten Absicht zu steuern.
Es gibt zwei Arten von Datenverkehr, für die unterschiedliche Anforderungen gelten (SLA-Kennzahlen):
- TC1-Datenverkehr - Latenzempfindliches SLA, um sicherzustellen, dass sich der Datenverkehr auf dem niedrigsten Latenzpfad befindet.
- TC4-Datenverkehr - SLA mit Mindestbandbreite, um sicherzustellen, dass für TC4-Datenverkehr immer dedizierte Bandbreite verfügbar ist
TC1-Datenverkehr (niedrigste Latenz)
Um sicherzustellen, dass der TC1-Datenverkehr stets über den Pfad mit der niedrigsten Latenz geführt wird, muss eine Segment Routing (SR)-Richtlinie auf dem Headend-SWR mit Pfadberechnungskriterien als Latenz erstellt werden.
Dies wird durch die Definition einer On Demand Next Hop (ODN)-Konfiguration auf jedem Headend-SWR für die spezifische Farbe 1001 mithilfe von CNC zur Vereinfachung der Erstellung von SR-Richtlinien erreicht.
TC4-Datenverkehr (zugesicherte Bandbreite)
Um sicherzustellen, dass der TC4-Datenverkehr immer über dedizierte Bandbreite auf den Pfad geleitet wird, muss eine SR-Richtlinie auf dem Headend-SWR erstellt werden, die Pfadberechnungskriterien als Bandbreite vorsieht.
Dies wird erreicht durch:
- Bandwidth-on-Demand (BoD)-Funktionspaket auf CNC
- Definieren der On Demand Next Hop (ODN)-Konfiguration auf jedem Headend-SWR für die spezifische Farbe 1004 mithilfe der CNC SR-Richtlinienerstellung mit diesen Konfigurationen
Das BoD-Funktionspaket dient zur Berechnung des Pfads für SR-Richtlinien, deren Bandbreite als Kriterium für die Pfadberechnung dient. Es verfolgt die Bandbreite, die einer Richtlinie zugewiesen wurde, und überwacht den aktuellen Pfad der Richtlinie während ihres Lebenszyklus.
Wenn der aktuelle Patch der BWOD-Richtlinie zu einem beliebigen Zeitpunkt nicht über genügend Kapazität verfügt, um die zugesicherte Bandbreite zu erfüllen, wird der BWOD-Richtlinienpfad neu berechnet und die Richtlinie auf einen neuen Pfad umgeleitet. Das Umleiten dieser BWOD-Richtlinie ist ein kontinuierlicher Prozess und erfordert keinen manuellen Eingriff.
In gewisser Weise führt BWOD die Optimierung unmittelbar für die Bandbreite durch, genau wie SR-PCE für die Latenz.
Gerätenutzung mithilfe von sZTP
In der Vergangenheit war für die Installation und den Support ein gewisses Maß an Fachwissen erforderlich, um ein neues Gerät zu installieren, zu konfigurieren und Probleme bei der Implementierung einer neuen Komponente zu beheben. Es kann auch ein langer Prozess der Vorabbereitstellung der Geräte an einem externen Standort erforderlich sein, der von vielen Mitarbeitern unterstützt wird, die an verschiedenen Teilen der Lösung arbeiten.
Bei neuen SWR-Geräten, die in Ihrer Umgebung bereitgestellt werden sollen, wird dieser Prozess der Geräteintegration mit der sicheren ZTP-Anwendung (Zero Touch Provisioning) von CNC automatisiert.
Der ZTP-Workflow wird beim erstmaligen Hochfahren des Geräts ausgelöst und lädt das geplante Plattform-Image sowie die Erstkonfiguration herunter, die ohne manuellen Eingriff angewendet werden müssen.
Zur weiteren Orchestrierung wird das Gerät automatisch in die CNC integriert.
Dieses Diagramm zeigt den Workflow des sicheren ZTP-Prozesses beim Einschalten des Geräts:
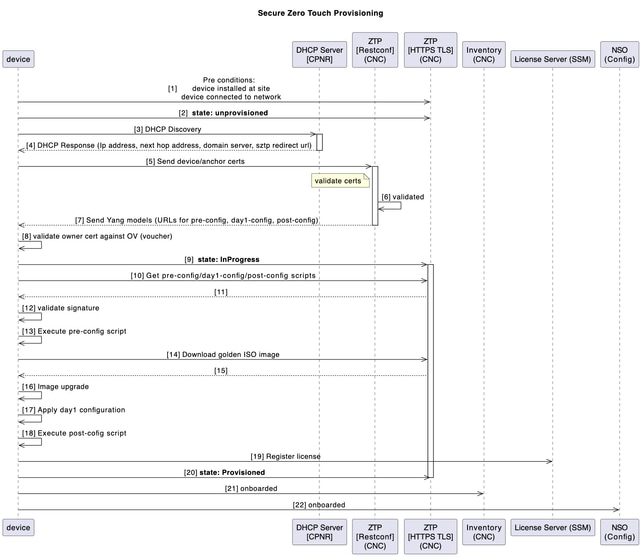
Post-ZTP-Orchestrierung (automatisierungsgesteuert)
Eine Python-Automatisierung auf dem Utility-Host orchestriert und überprüft den End-to-End-Prozess mithilfe einer strukturierten Excel-Eingabe (pro Kette):
- Generiert und lädt Day-1- und Post-Config-Artefakte in CNC hoch.
- Erstellt CPNR-Reservierungen (an serielle SWR-Einträge gebundene DHCP-Einträge).
- Fügt EPNM Geräte hinzu (für Transparenz/Sicherheit).
- Post-ZTP Housekeeping in CNC:
- Weist CDGs SWRs zu (Telemetrieziel)
- Wird an Gerätegruppen und Tags angehängt
- Aktualisiert Längen-/Breitengrad für Topologievisualisierung
- BNM-KPI-Profil zur Aktivierung von Telemetrie-Streaming
Verarbeitung von Bandwidth Notification Message (BNM) in CNC
Der SWR kann BNM vom am gleichen Standort befindlichen MiniLink-Switch empfangen, der der Bandbreite der WAN-Ports entspricht. Diese Benachrichtigungsmeldungen sind standardbasierte CFM-Meldungen, die die aktuell ausgeführte aufgezeichnete Bandbreite (RBW) und die maximal konfigurierte Bandbreite (auch als nominale Bandbreite (NBW) bezeichnet) umfassen.
Die aktuelle Bandbreite ist die tatsächliche Bandbreite der Mikrowellen-WAN-Verbindung, basierend auf den aggregierten Bandbreiten der einzelnen Mikrowellen-Verbindungen und deren QAM-Pegel. Die nominale Bandbreite ist die konfigurierte maximal mögliche WAN-Bandbreite, basierend auf den aggregierten Bandbreiten der maximal konfigurierten QAM für jede der einzelnen Mikrowellenverbindungen.
Die Bandbreitenoptimierung wird auf der Grundlage des folgenden Szenarios durchgeführt:
Temporäre (flüchtige) Änderungen
- Bei einer kurzfristigen Verschlechterung oder einem Ausfall des Netzwerks/der Verbindung, das/die auf SWR lokalisiert ist (z. B. aufgrund eines ungünstigen Wetterereignisses, das zu einem Schwund der Mikrowellenfunkstrecke und einer Reduzierung der verfügbaren Bandbreite aufgrund von Änderungen in Modulationsschemata führt), erfolgt eine Traffic Shaping-Korrektur an der lokalen SWR an der betroffenen Netzwerkschnittstelle.
- Auf diese Weise wird sichergestellt, dass über den betroffenen Übertragungspfad nur minimale Paketverluste auftreten.
Wenn eine SWR-Funktion mit BNM KPI in CNC im Rahmen von Post-sZTP-Aktivitäten aktiviert wurde, überträgt CNC Telemetriekonfigurationen in die SWR-Funktion.
BNM-MDT
modellgestützte Telemetrie
destination-group <DGName>
vrf VRF-OMSWR-<Ortsvorwahl>1
address-family ipv4 <CDG IPv4Address> Port 9010
Kodierung selbstbeschreibend-gpb
Protokoll-TCP
!
!
sensor-group <Gruppenname>
sensor-path Cisco-IOS-XR-ethernet-cfm-oper:cfm/nodes/node/bandwidth-notifications/bandwidth-notification
!
CNC verarbeitet diese über Telemetrie empfangenen BNM-Nachrichten und ergreift ggf. Korrekturmaßnahmen. Hier sind die 2 Komponenten, die in CNC beteiligt sind:
- Health Insight (HI): Die CNC-Anwendung erfasst BNM-Benachrichtigungen über einen benutzerdefinierten Leistungsindikator, der den spezifischen Sensorpfad für BNM-Meldungen überwacht. Health Insight kann Warnmeldungen ausgeben, falls Bandbreitenänderungen erforderlich sind.
- Änderungsautomatisierung (CA): Die CNC-Anwendung dient zum Reagieren auf BNM-Streaming-Nachrichten, die HI-Warnungen verursacht haben. Es wurden 2 benutzerdefinierte Leitfäden bereitgestellt, um diese Änderungen an der betroffenen Schnittstelle vorzunehmen:
- Einstellen des QoS-Shapers auf die neue RBW
- Festlegen der Schnittstellenkapazität auf einen neuen RBW-Wert
Ein benutzerdefiniertes Python-Skript wird entwickelt, um eine benutzerdefinierte Logik auszuführen und die CA-Playbooks automatisch auszuführen, wenn HI-Kennzahlen überschritten werden.
Das Skript zum Auslösen des strategischen Leitfadens basiert auf diesem Algorithmus:
In dieser Tabelle werden die benutzerdefinierten Warnstufen erläutert, die bei einem Grad der Bandbreitennutzung festgelegt wurden:
Gemeldete Bandbreite = RBW
Nennbandbreite = NBW
| Wert für Warnintervalle |
Benachrichtigungsebene |
| (RBW/NBW)*100 >=70 |
Info |
| (RBW/NBW)*100 <70 und >60 |
Warnung |
| (RBW/NBW) x 100 <=60 |
Critical (Kritisch) |
Dieser Sensorpfad wird von CNC überwacht:
Cisco-IOS-XR-Ethernet-cfm-oper:cfm/nodes/node/bandwidth-notifications/bandwidth-notification
In CNC wird ein benutzerdefinierter KPI erstellt, um den BNM-Sensorpfad zu überwachen. Dieser KPI wird einem KPI-Profil hinzugefügt, das mit einem Rhythmus von 120 Sekunden und Warnschwellenwerten konfiguriert wurde. Wenn SWRs an dieses Profil angehängt werden, wird die erforderliche Telemetriekonfiguration automatisch über den NSO an die Geräte übertragen.
Nach der Aktivierung streamen Geräte RBW-/NBW-Daten zu den zugewiesenen CDGs im konfigurierten Intervall. Health Insight (HI) berechnet das RBW÷NBW-Verhältnis und löst Warnungen aus, wenn Schwellenwerte überschritten werden. können diese Ereignisse in HI und über Grafana-Dashboards überwachen.
Ein Warnungsanbieter in CNC leitet diese Warnungen an den Hybridknoten weiter, der die Python-Automatisierung hostet. Das Skript analysiert Details zu Geräten/Schnittstellen/RBW/NBW und löst die entsprechenden strategischen Leitfäden zur Änderungsautomatisierung aus: Shaper-Anpassung, Bandbreitenaktualisierung oder beides basierend auf der definierten Entscheidungslogik.
Im Workflow werden die folgenden beiden strategischen Leitfäden verwendet:
1. Strategischer Leitfaden zum Ändern des Shaper-Werts
2. Strategischer Leitfaden zum Ändern der Schnittstellenbandbreite
Wie bereits erwähnt, spinnt das Skript einen Webserver an, der als Provider für die Kommunikation mit CNC über die REST-API fungiert. Alle Antworten, die wir für eine POST-Anfrage erhalten, werden hier erfasst. Die Warnungen werden in JSON erfasst und dann in ein Wörterbuch konvertiert, um die erforderlichen Parameter zu ermitteln.
Standardisierung des Day-2-Netzwerkbetriebs durch benutzerdefinierte Strategiedokumente zur Automatisierung
Die strategischen Leitfäden zur benutzerdefinierten Änderungsautomatisierung wurden entwickelt, um wichtige Day-2-Prozesse im gesamten Netzwerklebenszyklus zu optimieren und zu standardisieren. Dazu gehören die Paket-Ether-Bereitstellung, Updates der Beschreibung der Management-Schnittstelle, CFM-Reihenschaltung, nahtlose Erweiterung der Verbindungskapazität, eNodeB-Außerbetriebnahme und effizientes Mini-Link-Onboarding. Durch die Integration von Best Practices für den Betrieb in wiederverwendbare Workflows verbessern diese strategischen Leitfäden die Ausführungskonsistenz erheblich, minimieren das Risiko menschlicher Fehler und verringern die Abhängigkeit von manuellen Eingriffen. Im Zusammenhang mit einem Cisco CNC-Upgrade spielt dieses Automatisierungsframework eine entscheidende Rolle bei der Beschleunigung der betrieblichen Umstellung, der Gewährleistung der Servicekontinuität und der Bereitstellung skalierbarer, wiederholbarer Prozesse, die auf die Ziele moderner Netzwerktransformation abgestimmt sind.
Kontinuierliche TACACS+-Integration in Cisco CNC 7.1-Upgrade
Im Rahmen des Upgrades von Cisco CNC 4.1 auf 7.1 wurde die vorhandene TACACS+-Integration sorgfältig beibehalten, um die Kontinuität der zentralisierten Authentifizierung und Autorisierung sicherzustellen. Beim Upgrade wurde die TACACS+-Konfiguration in Cisco CNC 7.1 validiert und repliziert, wobei die bestehenden Sicherheitsrichtlinien und rollenbasierten Zugriffskontrollmechanismen (RBAC) eingehalten wurden.
CNC- und CDG-Syslog-Weiterleitung an Splunk
Eine Syslog-Weiterleitung wird eingerichtet, um die Alarme/Ereignisse/Syslogs an einen Splunk-Server weiterzuleiten. Hierzu wurde die vorkonfigurierte Funktion von CNC zum Einrichten des Syslog-Servers verwendet.
Alarmmeldung an OneFM weiterleiten
CNC-Alarme werden auch an ein Northbound-System wie OneFM weitergeleitet, das die verbindungsorientierte CNC-Restconf-API nutzt:
curl -L --request GET \
--url https://{server_ip}:30603/crosswork/notification/restconf/streams/v2/alarm.json \
--header 'Accept: application/txt'). This API must be used over a websocket connection config.Automatisierung täglicher CNC-Backups
Ein automatisiertes Skript nutzt die CNC-Sicherungs-API, um die vollständige Sicherung von CNC durchzuführen und die Sicherungsdatei auf dem Host des Dienstprogramms zu speichern. Dieser Vorgang wird täglich durchgeführt.
Herausforderungen
Großer Sprung in Kreuzworträtsel Version
Das Upgrade von Cross Work 4.4 auf 7.1 bedeutete eher einen deutlichen Versionssprung als ein routinemäßiges inkrementelles Update. Bei diesem großen Sprung wurden zahlreiche neue Funktionen für verschiedene Anwendungen eingeführt, zusammen mit grundlegenden Verbesserungen und Änderungen an der Architektur. Aus diesem Grund war das CNC-Upgrade nicht nur ein einfacher Versionsaustausch, sondern es erforderte eine gründliche Validierung, um die Kompatibilität, Stabilität und ordnungsgemäße Funktion aller integrierten Komponenten sicherzustellen. Die erweiterten Funktionen und die zugrunde liegenden Verbesserungen bedeuteten, dass vorhandene Workflows, Konfigurationen und Integrationen sorgfältig geprüft werden mussten, sodass umfassende Tests und Validierungen für den Erfolg des Upgrades entscheidend waren.
Kein Upgrade vor Ort
CNC unterstützt kein Upgrade-Modell vor Ort. Stattdessen müssen Upgrades nach einem lift-and-shift-Ansatz erfolgen, bei dem die bestehende Bereitstellung erhalten bleibt und mit der Zielversion eine komplett neue Umgebung von Grund auf neu erstellt wird. Nach der Installation des neuen Systems müssen Konfigurationen, Daten und Integrationen sorgfältig migriert und validiert werden, bevor die alte Umgebung außer Betrieb genommen werden kann.
Dieser Ansatz bringt eine Reihe betrieblicher Herausforderungen mit sich:
- Parallele Umgebungen: Die alte und die neue CNC-Umgebung müssen gleichzeitig ausgeführt werden, bis die Migration und Validierung abgeschlossen sind.
- Druck auf Hardware-Ressourcen: Wenn zwei vollständige Umgebungen parallel betrieben werden, steigt der Bedarf an Computing-, Storage- und Netzwerkressourcen, was die verfügbare Infrastruktur belasten kann.
- Erweiterte Validierung: Alle migrierten Daten, Konfigurationen, Richtlinien und Integrationen müssen in der neuen Version überprüft werden, um sicherzustellen, dass sie genau wie erwartet funktionieren.
- Komplexität der Datenmigration: Die Übertragung von Verlaufsdaten, Anwendungskonfigurationen und Betriebseinstellungen erfordert eine sorgfältige Planung, um Inkonsistenzen oder Datenverluste zu vermeiden.
- Verspätete Stilllegung: Das ältere System und die zugehörigen virtuellen Systeme können erst gelöscht werden, wenn sich die neue Bereitstellung als stabil erwiesen hat. Dadurch werden die Ressourcennutzung und der betriebliche Aufwand verlängert.
- Operative Koordinierung: Die Teams müssen während der Übergangsphase die Synchronisierung zwischen beiden Umgebungen verwalten, um Abweichungen von der Konfiguration oder Betriebsunterbrechungen zu vermeiden.
- Automatisierungskonflikte mit geschlossenem Regelkreis: CNC unterstützt Closed-Loop-Automatisierungsfälle, die dynamisch Aktionen basierend auf Echtzeit-Netzwerkbedingungen auslösen. Wenn während der Umstellung sowohl der alte als auch der neue Controller aktiv sind, besteht die Gefahr, dass dieselbe Automatisierungslogik von beiden Controllern ausgeführt wird, was zu doppelten Konfigurationsänderungen oder in Konflikt stehenden Aktionen im Netzwerk führen kann. Dies erfordert eine sorgfältige Kontrolle der Automatisierungsrichtlinien während des Migrationsfensters.
- Ältere Betriebsdaten, wie z. B. Alarme, Ereignisse, Fehlerprotokolle und Audit-Informationen, werden aufgrund des Fehlens nativer Exportfunktionen nicht in die neue Umgebung migriert. Daher sind diese Verlaufsdaten im aktualisierten System nicht verfügbar und müssen nach der Migration als nicht wiederherstellbar behandelt werden.
Aufgrund dieser Faktoren macht das Lift-and-Shift-Modell CNC-Upgrades ressourcenintensiver und betrieblich komplexer im Vergleich zu einem standardmäßigen Vor-Ort-Upgrade.
Bereitstellungstoleranzen ohne Rollback-Optionen
Bestimmte Fehler in der Konfiguration für die Bereitstellung und nach der Bereitstellung in CNC können nicht behoben werden und erfordern eine vollständige Entfernung und erneute Bereitstellung des Clusters. Beispielsweise hat ein falscher FQDN, der für das VIP der Crosswork-Daten konfiguriert wurde und für den sZTP-Anwendungsfall erforderlich ist, sZTP funktionsunfähig gemacht. Da dieser Wert nach der Bereitstellung nicht korrigiert werden kann, war eine vollständige Neubereitstellung erforderlich.
Ebenso konnte eine falsche Konfiguration der Anmeldeinformationen zum Überschreiben von Geräten in der Änderungsautomatisierung nach der Bereitstellung nicht behoben werden, was zu einer erneuten Clustererstellung führte. Andere Fehler, wie falsch konfigurierte Gateway-IPs oder Subnetzdefinitionen, können ebenfalls nicht behoben werden.
Diese Szenarien zeigen, wie wichtig es ist, alle unveränderlichen Parameter bei der Erstbereitstellung zu validieren. Sorgfältige Planung und Verifizierung von Eingaben sind unerlässlich, um kostspielige Nachbearbeitung und Auswirkungen auf den Zeitplan zu vermeiden.
Einschränkungen bei der Diagnosevalidierung nach der Bereitstellung
CNC bietet ein Diagnosedienstprogramm zur Bewertung von Zustandsparametern auf VM-Ebene wie Festplattenlese-/Schreiblatenz, IOPS, Synchronisierungslatenz, Netzwerkschnittstellengeschwindigkeit und CPU-Taktfrequenz. Das Dienstprogramm meldet die gemessenen Werte anhand der erwarteten Schwellenwerte und markiert jede Überprüfung als erfolgreich oder fehlerhaft. Diese Diagnosen können jedoch erst nach der Bereitstellung des Clusters durchgeführt werden, sodass vor der Bereitstellung kein Mechanismus zur Überprüfung der Infrastrukturbereitschaft verbleibt.
Während der Installation wird das Flag "Ignore Diagnostic Checks" (Diagnoseprüfungen ignorieren) standardmäßig auf false gesetzt. In der Praxis wird das Installationsprogramm angehalten, wenn eine einzelne Überprüfung fehlschlägt, sodass die Bereitstellung nicht fortgesetzt werden kann. Daher müssen Außendiensttechniker diese Markierung aktivieren und die Diagnose vollständig umgehen, da selbst in Umgebungen der Produktionsklasse eine oder mehrere Überprüfungen häufig nicht durchgeführt werden. Dies führt zu einem betrieblichen Dilemma: Die Teams müssen sich zwischen einer strengen Validierung, die die Bereitstellung blockiert, und einem weiteren Vorgehen entscheiden, ohne sicherzustellen, dass die zugrunde liegende Infrastruktur die empfohlenen Performance-Benchmarks erfüllt.
Änderung des benutzerdefinierten KPI-Erstellungsverfahrens für HI
In Health Insight 4.1 stützte sich die benutzerdefinierte KPI-Erstellung auf die Tick-Skriptlogik, in der KPI-Definitionen und Verarbeitungslogik mithilfe von Skripts im Tick-Framework implementiert wurden. In Version 7.1 wurde dieser Ansatz jedoch durch ein dateibasiertes Tracker-Framework zur Definition und Verwaltung von KPIs ersetzt.
Aufgrund dieser Architekturänderung konnten die vorhandenen benutzerdefinierten KPIs nicht direkt wiederverwendet werden. Daher mussten sie entsprechend dem neuen Tracker-Dateiformat überarbeitet werden. Dies erforderte einen erheblichen Zeit- und Arbeitsaufwand, um:
- Verständnis des neuen Rahmens: Das Team musste die Struktur, Syntax und das Betriebsverhalten des in Version 7.1 eingeführten dateibasierten KPI-Definitionsmodells für Tracker untersuchen.
- Vorhandene Logik neu gestalten: Die zuvor in Tick-Skripten implementierte Logik musste übersetzt und in das Tracker-Dateiformat angepasst werden.
- BNM-KPIs neu erstellen: Die BNM-KPI musste mithilfe des neuen Frameworks neu erstellt werden, um sicherzustellen, dass sie die gleichen Ergebnisse und Erkenntnisse wie zuvor liefert.
- KPI-Genauigkeit überprüfen: Eine umfassende Validierung war erforderlich, um sicherzustellen, dass die neuen Implementierungen im Vergleich zur Vorgängerversion konsistente und korrekte Kennzahlen generierten.
- Test und Abstimmung: Das neue Modell erforderte außerdem Leistungs- und Verhaltenstests unter realen Netzwerkbedingungen, denen gegebenenfalls Anpassungen folgten.
- Mangelnder Support: Einige Funktionen, die früher mit Tick-Skript funktionierten, wurden bei der neuen Tracker-Dateiimplementierung nicht mehr unterstützt. Also mussten einige Kompromisse eingegangen werden.
Durch diese Änderung des KPI-Erstellungsmechanismus wurde der Aufwand während des Upgrades erheblich erhöht, da sowohl ein neues System erlernt als auch die vorhandene benutzerdefinierte Überwachungslogik neu implementiert werden musste, um die Kontinuität der betrieblichen Erkenntnisse sicherzustellen.
API-Timeout in BNM-Playbooks - Trigger-Skript
Die BNM-Playbooks werden durch ein benutzerdefiniertes Skript ausgelöst, das mit CNC-APIs interagiert. Während des Upgrade- und Validierungsprozesses wurden verschiedene Probleme im Zusammenhang mit der API-Authentifizierung und der Antwortbehandlung identifiziert und behoben.
Das CNC-API-Token hat eine Gültigkeit von 8 Stunden, aber das ursprüngliche Skript enthielt keine ordnungsgemäße Logik, um das Token nach Ablauf zu aktualisieren. Obwohl die KPI-Warnungen in CNC 4.4 richtig funktionierten, wurde die Ausführung des Skripts zum Auslösen des strategischen Leitfadens nach Ablauf des Tokens beendet. Dieses Problem blieb lange unbemerkt, sodass das Automatisierungsskript seit mehr als einem Jahr nicht mehr zuverlässig ausgeführt wurde. Das Problem wurde erst während der Migrations- und Validierungsaktivitäten in CNC 7.1 sichtbar.
Aus diesem Grund waren mehrere Verbesserungen und Verbesserungen erforderlich:
- Tokenaktualisierungslogik: Die richtige Logik wurde implementiert, um das Ablaufdatum des Tokens zu erkennen und das API-Token automatisch zu aktualisieren, sodass eine unterbrechungsfreie Ausführung des Skripts gewährleistet ist.
- API-Antwortänderungen: Unterschiede zwischen den CNC-Versionen verursachten zusätzliche Probleme. In CNC 4.1 enthielt eine abgelaufene Tokenantwort in der Regel die Meldung "abgelaufen", während in CNC 7.1 die Antwort "Schlüssel nicht autorisiert" zurückgibt. Die Skriptlogik musste aktualisiert werden, um die neuen Antwortmuster in 7.1 richtig zu interpretieren.
- Globale Tokenbehandlung: Zuvor wurden Token in Funktionen gespeichert und lokal verwendet. Dadurch wurden Szenarien erstellt, in denen das Token beim Eingeben einer Funktion gültig war, aber vor nachfolgenden API-Aufrufen abgelaufen ist. Die Implementierung wurde dahingehend geändert, dass sie die globale Tokenbehandlung verwendet, um Konsistenz und korrekte Aktualisierungen für alle Funktionen zu gewährleisten.
- Verbesserte Fehlerbehandlung: In einigen Fällen lieferte die API zur "Überprüfung der Synchronisierung" des NSO Antworten, die unvollständig waren oder sich von der erwarteten Struktur unterschieden. Dies verursachte KeyError-Ausnahmen, die die Skriptausführung anhielten. Zusätzliche Ausnahmebehandlung und Validierungslogik wurden eingeführt, sodass das Skript auch dann ausgeführt werden kann, wenn unerwartete API-Antworten empfangen werden.
- Verbesserte Skriptstabilität: Es wurden zusätzliche Sicherheitsmechanismen und Prüfungen hinzugefügt, um sicherzustellen, dass API-Fehler, vorübergehende Antwortprobleme oder Tokenaktualisierungsereignisse nicht dazu führen, dass das Skript unerwartet beendet wird.
Durch diese Verbesserungen wurden nicht nur die während des Upgrades aufgedeckten Probleme gelöst, sondern auch die Zuverlässigkeit, Ausfallsicherheit und Wartungsfreundlichkeit des BNM-Frameworks für die Leitfaden-Automatisierung deutlich verbessert.
Design-Änderung für BNM-Verarbeitung und strategischen Leitfaden
Die BNM-Automatisierungslogik ist ereignisgesteuert und beruht auf Warnmeldungen, die von Kennzahlen in der Health Insight-Anwendung in CNC generiert werden. Der allgemeine Workflow funktioniert wie folgt:
- CNC liest die NB- (nominale Bandbreite) und RBW-Werte (reale Bandbreite) vom Gerät.
- Anhand dieser Werte wird das Bandbreitenverhältnis (BW%) berechnet.
- Der Health Insight-KPI wertet dieses Verhältnis anhand vordefinierter Warnschwellenwerte aus.
- Wenn eine Warnung generiert wird, erkennt das Skript zum Auslösen des BNM-strategischen Leitfadens die Warnung und führt die entsprechenden korrigierenden strategischen Leitfäden aus.
Beschränkung im ursprünglichen Warnmeldungsdesign
Folgende Warnschwellenwerte wurden konfiguriert:
- BW% < 60 → Kritisch
- 60 ≤ BW% ≤ 70 → Warnung
- Bandbreite % > 90 → Info
Dieses Design hat sich bei der Erkennung von Bandbreitenbeeinträchtigungen bewährt, jedoch bei Szenarien zur Bandbreitenwiederherstellung eine funktionelle Lücke geschaffen. Für den 70-90 %-Bereich wurde keine Warnstufe definiert.
Dies führte zu diesem Verhalten:
- Wenn die Bandbreitenauslastung auf unter 70 % sinkt, wird eine kritische oder eine Warnung generiert, die strategische Leitfäden auslöst, mit denen die Shaper- und Bandbreitenwerte angepasst werden.
- Als sich die Bandbreite jedoch erholte und der Bandbreitenbedarf um mehr als 70 % anstieg, gab der KPI keine Warnung aus, da der Wert in das 70-90 %-Band fiel, mit dem keine Warnstufe verbunden war.
- Da das BNM-Automatisierungsskript zur Auslösung von Aktionen vollständig von der Alarmgenerierung abhängig ist, hatte es keine Möglichkeit, aktualisierte NBW/RBW-Werte zu lesen oder Wiederherstellungsaktionen zu initiieren.
- Die Bandbreitenwiederherstellung erfolgte daher nicht automatisch, obwohl ausreichend Bandbreite verfügbar geworden war. Auch im ursprünglichen Design gab es keine Restaurierungslogik.
Diese Einschränkung wurde im Produktionsnetzwerk sichtbar, wo Verbindungen, die zuvor eine Bandbreitenreduzierung durchlaufen hatten, auch nach Verbesserung der Bedingungen in einem eingeschränkten Zustand blieben.
Auswirkungen der KPI-Framework-Änderung
Das Problem wurde durch die in CNC 7.1 eingeführte Rahmenänderung noch verschärft. In Health Insight 4.1 unterstützte die Tick-basierte KPI-Implementierung bis zu fünf Warnstufen, was eine feinere Kontrolle der Schwellenbänder ermöglichte und die Implementierung der Wiederherstellungslogik erleichterte.
In CNC 7.1 unterstützt das auf Tracker-Dateien basierende KPI-Framework jedoch nur drei Warnstufen, was die Flexibilität bei der Definition mehrerer Wiederherstellungsschwellenwerte verringert und eine Umgestaltung der Warnlogik erforderlich macht, damit diese in diese Einschränkungen passen.
Übermäßiges Auslösen aus strategischen Leitfäden
Ein weiteres Problem, das in der ursprünglichen Implementierung genannt wurde, war die extrem hohe Häufigkeit von Hinrichtungen nach strategischen Leitfäden. Die Automatisierungslogik enthielt keine Haltezeit oder kein Stabilisierungsfenster. Sobald CNC einen Wert vom Gerät gelesen hat, der die Alarmbedingung erfüllt:
- Der Alarm wurde sofort ausgelöst.
- Das Automatisierungsskript löste sofort die Korrekturleitfäden aus.
Da sich die Telemetriedaten in Live-Netzwerken häufig ändern, wurden stündlich Hunderte von strategischen Leitfäden ausgelöst, was sowohl im Hinblick auf die Netzwerkstabilität als auch die Anwendungsleistung nicht optimal war.
Überarbeitete Automatisierungslogik
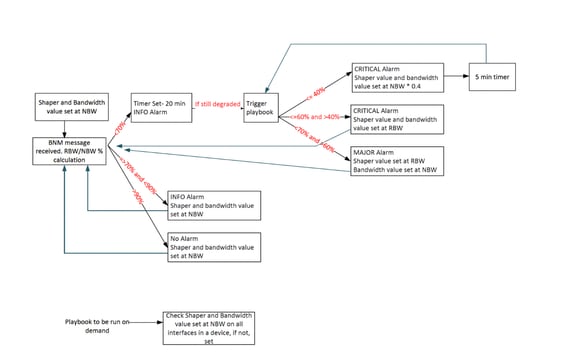
Um diese Einschränkungen zu umgehen, wurde das BNM-Automatisierungsdesign mit verschiedenen Verbesserungen überarbeitet:
- Überarbeitete Warnungsschwellenwertlogik: Um sicherzustellen, dass das Wiederherstellungsband innerhalb der drei Warnstufen erfasst wurde, wurde die Logik so geändert, dass BW% größer als 70% jetzt als Warnung auf INFO-Ebene behandelt wird. Damit wurde der frühere Ansatz ersetzt, bei dem nur Werte über 90% als INFO klassifiziert wurden. Dadurch wurde sichergestellt, dass das Wiederherstellungsband von 70-90 % aktiv überwacht wird, sodass Wiederherstellungsleitfäden ausgelöst werden können, wenn sich die Bandbreitenbedingungen verbessern.
- Einführung der Haltezeit: Es wurde ein Haltezeitmechanismus von 20 Minuten eingeführt, um sicherzustellen, dass die Bandbreitenbedingungen vor dem Auslösen der strategischen Leitfäden für einen bestimmten Zeitraum stabil bleiben. Dadurch wird verhindert, dass die Automatisierung auf kurzfristige Schwankungen reagiert.
- Kontrollierte Playbook-Ausführung: Mit der überarbeiteten Logik und der Haltezeit reduzierte sich die Häufigkeit von Programmausführungen drastisch und vermeidete unnötige Automatisierungsaktionen.
- Booster-Mechanismus für schwere Degradierung: Bei schweren Bandbreitenverlusten wurde ein Booster-Ansatz eingeführt. In solchen Szenarien passen die Automatisierung den Traffic Shaper und die Bandbreitenzuweisung proaktiv an 40 % der NBW an und ermöglichen so eine schnellere Wiederherstellung nach Überlastung.
- Verbesserte Stabilität der Automatisierung: Der überarbeitete Workflow stellt sicher, dass Bandbreitenreduktions- und Bandbreitenwiederherstellungsszenarien effektiv verarbeitet werden, selbst wenn die Einschränkungen des tracker-basierten KPI-Frameworks beachtet werden.
Ergebnis
Durch diese Designänderungen und die früheren Verbesserungen bei der API-Handhabung, der Tokenverwaltung und der Skriptstabilität wird das BNM-Automatisierungs-Framework jetzt auf eine wesentlich stabilere, effizientere und vorhersehbarere Weise betrieben. Das System kann korrekt auf Überlastungen und Wiederherstellungsbedingungen reagieren, übermäßige Ausgaben des strategischen Leitfadens vermeiden und eine zuverlässige Optimierung der Netzwerkbandbreite sicherstellen.
Unterdrückung von Gerätewarnungen
In CNC 4.1 wurden Alarme über eine RESTCONF-API an ein Northbound-System namens OneFM weitergeleitet. Da der CNC 4.1-Stack keine EMF-Funktionalität enthielt, wurden auf der Plattform nur Alarme auf Systemebene generiert. Diese Alarme wurden Upstream weitergeleitet, ohne dass die Kategorisierung von Alarmen zu ihrer Komplexität führte.
Mit dem Einsatz von CNC 7.1 wurde die EMF-Anwendung eingeführt, die das Alarmmodell erheblich erweitert. Die Alarme wurden nun in drei Kategorien eingeteilt:
- Systemwarnungen - in Bezug auf die CNC-Plattform und den Anwendungszustand
- Netzwerkwarnungen - in Bezug auf Netzwerkdienstbedingungen
- Gerätewarnungen - werden direkt von Netzwerkgeräten generiert und über CNC weitergeleitet
Es gab jedoch bereits ein EPNM, das für die Erfassung und Verwaltung von Alarmen auf Geräteebene zuständig war. Wenn die CNC diese Alarme auch an OneFM weiterleitete, wurden doppelte Alarme von beiden Systemen empfangen. Die Anforderung lautete daher, Alarme von Geräten bei der CNC-Bearbeitung auszuschließen und gleichzeitig System- und Netzwerk-Alarme weiterzuleiten.
Die größte Herausforderung bestand in der Einschränkung der Northbound-API von RESTCONF für die Weiterleitung von Alarmen an OneFM. Das Filtern von Alarmen nach Alarmkategorie wurde nicht unterstützt. Wäre eine solche Filterung verfügbar gewesen, wäre die Lösung einfach: Schließen Sie Gerätewarnungen einfach auf API-Ebene aus, bevor Sie sie an das Northbound-System weiterleiten.
Mehrere mögliche Lösungen wurden bewertet und diskutiert:
- Stoppen von Gerätefallen an der Quelle: Verhindern Sie, dass Geräte Traps an CNC senden.
- Filterung von Alarmen im Northbound-System (OneFM): CNC kann alle Alarme senden, aber Gerätealarme innerhalb von OneFM filtern.
- Filterung in CNC vor der Weiterleitung von Alarmen.
Das Beenden von Traps auf Geräteebene wurde nicht als praktikabel erachtet, da CNC auf diese Traps angewiesen ist, um Geräteereignisse zu erkennen und die Betriebsbereitschaft der Netzwerkbedingungen aufrechtzuerhalten. Das Deaktivieren von Traps würde die Fähigkeit von CNC, auf Netzwerkprobleme zu reagieren, erheblich einschränken.
Die letztendlich implementierte Lösung nutzte eine integrierte CNC-Funktion namens "Device Alarm Suppression" (Unterdrückung von Gerätealarmen). Mit dieser Funktion können Administratoren bestimmte Arten von Gerätewarnungen auf Basis von Gerätegruppen unterdrücken und so verhindern, dass diese verarbeitet oder an weitere Upstream-Geräte weitergeleitet werden.
Durch die Konfiguration von Richtlinien zur Unterdrückung von Gerätewarnungen konnte das System folgende Ziele erreichen:
- Unterdrückung von gerätegenerierten Alarmen in CNC.
- Fahren Sie mit der Verarbeitung und Weiterleitung von System- und Netzwerkalarmen fort.
- Verhindern, dass doppelte Gerätewarnungen das OneFM-System erreichen.
Dieser Ansatz bot eine saubere und skalierbare Lösung, ohne dass die Fähigkeit von CNC beeinträchtigt wurde, Traps von Geräten zu empfangen. Dadurch wurde der Alarmfluss zu OneFM gestrafft, sodass nur relevante System- und Netzwerk-Alarme weitergeleitet wurden, ohne dass es zu einer Duplizierung mit dem EPNM-Gerätemanagement kam.
Out-of-Band-Änderungen
In der bestehenden Konfiguration verließ sich das Betriebsteam häufig auf direkte CLI-basierte Skripts, um Konfigurationsaktualisierungen auf Netzwerkgeräte zu pushen, insbesondere für Aufgaben wie ACL-Änderungen und Debugaktivitäten. Dieser Ansatz war zwar kurzfristig effektiv, führte jedoch zu Konfigurationsabweichungen, da Änderungen, die außerhalb des NSO vorgenommen wurden, im System nicht nachverfolgt wurden. Dies führte zu Inkonsistenzen zwischen dem beabsichtigten (modellierten) Zustand und den tatsächlichen Gerätekonfigurationen, die zu Ausfällen und betrieblichen Ineffizienzen führten.
L2/L3-VPN-Abstimmung
Aufgrund von Out-of-Band-Konfigurationsänderungen: hatte das Netzwerkteam die VPN-bezogene Konfiguration auf Geräten außerhalb von CNC/NSO und des TSDN-Workflows aktualisiert. Daher stimmte der im NSO gespeicherte Status (aus der Ära CNC 4.1) nicht immer mit dem Status auf den Geräten überein.
Diese Diskrepanzen verursachten mehrere Abstimmungsfehler und Inkonsistenzen. In mehreren Fällen enthielt der NSO VPN-Servicedaten, die auf den Geräten nicht mehr vorhanden waren (oder die nicht vom NSO übernommen wurden). Um den NSO mit dem Netzwerk abzustimmen, mussten VPN-Diensteinträge entfernt werden, die nur im NSO und nicht auf den Geräten vorhanden waren. Außerdem mussten andere durch Out-of-Band-Änderungen verursachte Diskrepanzen korrigiert werden.
Auswirkungen planen
Um diese Probleme zu lösen, waren etwa zwei weitere Wochen über den ursprünglichen Abstimmungsplan hinaus erforderlich. Die Zeit, die zusätzlich für die Identifizierung von Diskrepanzen, die Überprüfung des Gerätestatus und die sichere Bereinigung oder Korrektur von NSO CDB-Daten aufgewendet wurde, wurde aufgewendet.
Beobachtungen
- Konfigurationsberechtigung: Out-of-Band-Änderungen an VPN- (oder anderen TSDN-verwalteten) Konfigurationen führen zu Abweichungen zwischen dem NSO und dem Netzwerk und erschweren den Abgleich.
- Vor der Migration: Eine klare Baseline zwischen NC/NSO-Managed und reinem Gerätezustand vor der Migration hätte die Erkennung und Behebung von Diskrepanzen vereinfacht.
- Automatisierung und Konvertierung: Payload-Konvertierungsskripte und benutzerspezifische Anpassungen waren wichtig, um Format- und Modellunterschiede zwischen 4.1 und 7.1 konsistent zu handhaben.
Empfehlungen für ähnliche Upgrades
- Erzwingen Sie einen Änderungsstopp für VPN- (und andere TSDN-verwaltete) Services während des Abgleichfensters, mit Ausnahmen nur über einen kontrollierten Prozess.
- Führen Sie vor dem Abgleich einen Audit durch, bei dem die NSO-CDB mit der Gerätekonfiguration verglichen wird, um Abweichungen zu quantifizieren und aufzulisten, bevor Sie mit dem Abgleich beginnen.
- Dokumentieren und sozialisieren Sie, dass VPN-Änderungen nach dem Upgrade über CNC/NSO TSDN erfolgen müssen, um zu verhindern, dass es erneut zu Out-of-Band-Verschiebungen kommt.
- Konvertierungs- und Abstimmungsskripte zur Wiederverwendung bei zukünftigen Upgrades oder zur Fehlerbehebung aufbewahren.
CNC-Sicherungsfehler aufgrund von Abhängigkeiten im Wartungsmodus
Der CNC-Sicherungsmechanismus erfordert, dass die Plattform in den Wartungsmodus versetzt wird, bevor ein Sicherungsvorgang initiiert werden kann. Die Sicherungs-API erzwingt diese Voraussetzung. Wenn die CNC nicht in den Wartungsmodus wechselt, wird der Sicherungsvorgang automatisch abgebrochen.
In der Praxis schlug der Einstieg in den Wartungsmodus häufig aufgrund laufender Systemaktivitäten fehl, darunter:
- Aktive Change Automation-Leitfäden (MOPP)
- Laufende sZTP-Workflows
- DLM-Dienstvorgänge
- KPI-Profilbefestigung oder Ablöseaktivitäten
- On-Demand-Showtech-Kollektionen
- Orchestrierungsaufgaben im Hintergrund
Das Vorhandensein solcher Aktivitäten verhindert, dass CNC in den Wartungsmodus wechselt, wodurch der Sicherungsvorgang vor der Ausführung fehlschlägt.
Betriebliche Auswirkungen
Die erforderlichen täglichen CNC-Backups für Compliance und Betriebssicherheit. Häufige Automatisierungsaktivitäten, insbesondere durch BNM ausgelöste Playbooks, führten jedoch häufig dazu, dass das System nicht in den Wartungsmodus wechseln konnte. Daher traten wiederholt Datensicherungsfehler auf, die ein erhebliches betriebliches Risiko mit sich brachten und manuelle Eingriffe erforderten.
Eindämmungsstrategie
1. Optimierung der Backup-Planung: Es wurde ein Wartungsfenster mit minimaler Systemaktivität identifiziert. Basierend auf der Datenverkehrs- und Automatisierungsanalyse wurde der Backup-Job für 05:00 Uhr (AEST) angesetzt, als Orchestrierung und die Ausführung des strategischen Leitfadens am seltensten waren.
2. Überprüfung vor der Sicherung: Vor dem Aufrufen der Sicherungs-API wurde eine automatisierte Überprüfung eingeführt:
- Das Skript fragt CNC-APIs ab, um laufende MOP-Jobs für die Änderungsautomatisierung zu erkennen.
- Wenn ein Job als Running gemeldet wird, wartet das Skript 5 Sekunden und versucht es erneut.
- Diese Schleife wird fortgesetzt, bis das System keine aktiven Jobs meldet.
- Erst wenn die Inaktivität der Umgebung bestätigt wurde, versucht das Skript, den Wartungsmodus zu aktivieren und die Sicherung auszulösen.
Auf diese Weise wurden unnötige Sicherungsversuche vermieden, während sich das System im aktiven Zustand befand.
3. Mechanismen für Wiederholungen und Ausfallsicherheit: Um vorübergehenden Systemzuständen Rechnung zu tragen, wurden zusätzliche Sicherheitsmechanismen hinzugefügt:
- Bis zu drei Wiederholungsversuche, wenn die Sicherungs-API einen Fehler zurückgibt
- Kurze Verzögerungsintervalle zwischen Wiederholungen
- Sichere Fehlerbehandlung zur Vermeidung der Skriptterminierung
Ergebnisse und Ergebnisse
Durch die kombinierte Reduzierung konnte die Zuverlässigkeit von Backups deutlich verbessert werden:
- Backup-Fehler wurden drastisch reduziert
- Nach der Implementierung wurden nur zwei Fehler beobachtet, die beide durch einen blockierten sZTP-Prozess verursacht wurden, der sich außerhalb der Kontrolle des Skripts befindet.
- Durch die Einführung von Ausführungsverzögerungen in der BNM-Playbook-Automatisierung wurden Konflikte mit dem Wartungsmodus weiter reduziert.
Syslogs werden an Splunk weitergeleitet
Das Syslog-Ziel wurde in CNC konfiguriert, um Protokolle über TLS an Splunk weiterzuleiten. Nach dem Empfang waren die Protokolle auf Splunk-Seite jedoch nicht mehr lesbar. Aufgrund dieses Problems, das von der Splunk-Umgebung ausgeht, wurde die Option ausgewählt, den UDP-Transport wiederherzustellen. Anschließend wurden die Protokolle erfolgreich verarbeitet.
Problem bei der Migration von Gerätegruppen
Der Benutzer hat zuvor 18 Gerätegruppen in CNC 4.1 erstellt. Diese Version bot jedoch keinen UI-basierten oder API-gesteuerten Mechanismus zum Exportieren oder Importieren von Gerätegruppen. Daher war für die Migration dieser Gruppen auf CNC 7.1 ein nicht standardmäßiger Ansatz erforderlich. Es wurden zwei interne CNC-APIs identifiziert: eine mit Angaben zur Gerätegruppenhierarchie und eine weitere mit Angaben zu den Geräten, die den einzelnen Hierarchieknoten zugeordnet sind. Mithilfe dieser APIs wurden alle Gerätegruppen und die zugehörigen Geräte extrahiert und als JSON-Ausgaben gespeichert. Anschließend wurde ein benutzerdefiniertes Skript entwickelt, um die Antworten zu analysieren und nur die Hostnamen der Geräte aus jeder Gruppe zu extrahieren.
CNC 7.1 führte native Import-/Exportfunktionen für Gerätegruppen ein, darunter eine CSV-basierte Importvorlage. Nach dem Extrahieren der Hostnamen aus dem Legacy-System wurde ein zweites Automatisierungsskript erstellt, um die CSV-Vorlagen im erforderlichen Format zu füllen und sicherzustellen, dass jede Gerätegruppe korrekt und unabhängig importiert werden konnte. Diese Automatisierung war unerlässlich. ohne diese wäre die Migration der Gerätegruppen auf CNC 7.1 deutlich zeitaufwendiger und betrieblich aufwändiger gewesen.
Isolierung stark bandbreitenreduzierter Geräte
Trotz der Implementierung des BNM-Anwendungsfalls für die automatische Behebung niedriger RBW/NBW-Kennzahlen blieb ein Teil der Geräte über lange Zeit in stark beeinträchtigtem Zustand. Obwohl die Shaper- und Bandbreitenanpassungsleitfäden Geräte in der Regel kurz nach Leistungsabfällen wiederherstellten, bestanden mehrere Geräte länger als eine Woche im kritischen Zustand und mussten manuell eingegriffen werden. Die Identifizierung dieser Geräte stellte jedoch eine Herausforderung dar. Die CNC-Benutzeroberfläche bietet zwar eine klare Visualisierung von Warnungen und Bandbreitenmetriken, zeigt jedoch nicht ohne Weiteres Geräte an, die sich über längere Zeiträume ausschließlich im kritischen Zustand befanden.
Um diese betriebliche Lücke zu schließen, wurde eine API-gestützte Lösung entwickelt. CNC bietet eine API, die eine Liste der wichtigsten alarmgenerierenden Geräte über konfigurierbare Zeitfenster (z. B. 7 Tage, 1 Monat) abruft. Durch das Abrufen dieser Daten und das Filtern nach Geräten, die im ausgewählten Zeitraum nur kritische Warnmeldungen erzeugt haben, konnte das Team Geräte, die manuell behoben werden mussten, schnell isolieren. Dieser automatisierte Ansatz verbesserte die Effizienz der Fehlerbehebung erheblich und reduzierte den Zeitaufwand für die Identifizierung von Fällen einer dauerhaften Verschlechterung.
Entfernen der Gerätetelemetriekonfiguration
In CNC 4.1 wurden Telemetriekonfigurationen, die vom NSO über das tcfunction-Paket übertragen wurden, automatisch angewendet, wenn ein Gerät einem Health Insight (HI)-KPI-Profil zugeordnet wurde. Diese Konfigurationen - einschließlich CDG VIP-Verweise - wurden jedoch nicht entfernt, als das KPI-Profil zu einem späteren Zeitpunkt entfernt wurde. Dementsprechend häuften die Geräte veraltete und redundante Telemetrieeinträge im Laufe der Zeit an.
Dieses Problem wurde während des Upgrades auf CNC 7.1 noch ausgeprägter. Geräte behielten häufig ältere CDG VIP-Telemetriekonfigurationen von CNC 4.1 neben den neuen Einträgen, die von CNC 7.1 generiert wurden, bei, was zu mehreren gegensätzlichen Telemetriekonfigurationen auf mehr als 2.000 Geräten führte. Es wurden Bedenken hinsichtlich der betrieblichen Auswirkungen und der Konfigurationshygiene geäußert, da nur die VIP-Konfiguration der CNC 7.1 CDG aktiv geblieben sein muss.
Zu diesem Zweck wurde ein automatisiertes Skript entwickelt, um veraltete CDG VIP-Referenzen zu identifizieren und aus der Telemetriekonfiguration der einzelnen Geräte zu entfernen. Diese Lösung beseitigte Inkonsistenzen in der Konfiguration, stellte die Übereinstimmung mit dem erwarteten 7.1-Telemetriemodell wieder her und verhinderte, dass der manuelle Bereinigungsaufwand über mehrere Tage hinweg für die gesamte große Geräteflotte angestiegen wäre.
Fehlerbehebung bei MDT-Sammlung
In CNC 7.1 basieren die meisten Health Insight (HI) KPI-Sammlungen auf modellgetriebener Telemetrie (MDT). Wenn auf einem Gerät ein KPI-Profil aktiviert ist, programmiert der NSO automatisch die erforderlichen Sensorpfade und konfiguriert das CDG VIP als Telemetrieziel. Nach Anwendung dieser Konfiguration wird ein entsprechender CDG-Erfassungsauftrag erstellt, um den Telemetriestatus des Geräts zu verfolgen.
Während der Validierung fehlten bei mehr als 100 Geräten Telemetriekonfigurationen. Die Identifizierung dieser Geräte über die CNC-Benutzeroberfläche erwies sich als unpraktisch, da die Benutzeroberfläche nur Gerätefilterung unterstützt und für eine Flotte von mehr als 2.000 Geräten nicht effizient skalierbar ist. Dies erforderte ein automatisiertes Verfahren, um festzustellen, für welche Geräte keine Telemetriekonfiguration und keine erneute Aktivierung der Leistungskennzahlen erforderlich war.
Um dies zu erreichen, wurde bei jeder Aktivierung eines KPI-Profils das BNM-Tag verwendet, das Geräten zugewiesen wurde. Zunächst wurde ein Export aller Geräte mit dem BNM-Tag generiert. Anschließend wurde ein Python-Skript für die Interaktion mit der CNC-Erfassungs-API entwickelt, das eine Paginierungslogik zum Abrufen des gesamten Satzes von Erfassungs-Jobs enthält (jeder API-Aufruf gibt maximal 100 Einträge zurück). Das Skript extrahierte Hostnamen aus den Daten des Erfassungsauftrags und verglich sie mit der exportierten, mit BNM gekennzeichneten Geräteliste.
Dieser Vergleich ergab eine Liste der Geräte, die markiert waren, aber nicht im BNM-Erfassungsauftrag aufgeführt waren. Dies deutet darauf hin, dass die MDT-Telemetriekonfiguration nicht angewendet wurde. Das KPI-Profil wurde dann auf diesen Geräten erneut aktiviert, und die Validierung bestätigte, dass alle entsprechenden Erfassungsaufträge korrekt erstellt wurden.
Durch diese Automatisierung wurde die Fehlerbehebung erheblich vereinfacht. Das Team konnte alle betroffenen Geräte innerhalb eines Tages identifizieren und beheben, was bei einer manuellen Überprüfung nicht möglich gewesen wäre.
Anpassung von HA-Verhaltensänderungen und Consensus Algorithm in NSO 6.4.1.1
Während des Upgrades von Cisco NSO 5.7.5.1 auf 6.4.1.1 im Rahmen der Umstellung auf Cisco CNC 7.1 wurde eine bemerkenswerte Änderung des HA-Verhaltens (High Availability) beobachtet, die auf die implizite Aktivierung des Consensus Algorithmus in der neueren NSO-Version zurückzuführen war. Dies war nicht das Standardverhalten in NSO 5.7.5.1, was nach dem Upgrade zu einer Änderung der Failover-Eigenschaften führte. Nach dem Ausfall des Primärknoten wechselte der Sekundärknoten in einen schreibgeschützten Zustand, wodurch verhindert wurde, dass er Bereitstellungsaktivitäten verarbeiten konnte. Ebenso wechselte der Primärknoten bei einem Ausfall des Sekundärknotens von einem aktiven Primärknoten in den Zustand "Keine", wodurch sich die Servicekontinuität änderte.
Um das erwartete HA-Verhalten in Übereinstimmung mit der vorherigen Bereitstellung wiederherzustellen, wurde der Consensus-Algorithmus in NSO 6.4.1.1 explizit deaktiviert. Durch diese Anpassung wurde sichergestellt, dass der primäre und der sekundäre Knoten während Failover-Szenarien ihre beabsichtigten Rollen wieder übernehmen konnten. Dies ermöglicht eine unterbrechungsfreie Bereitstellung und gewährleistet die Betriebsstabilität, die mit der früheren NSO-Version konsistent ist.
Verbesserungen für NSO-Versionsupgrade und Paketkompatibilität
Im Rahmen des Übergangs von Cisco CNC 4.1 zu 7.1 wurde die zugrunde liegende Cisco NSO-Version von 5.7.5.1 auf 6.4.1.1 aktualisiert. Bei diesem Versionsupgrade wurden Änderungen an XML-Vorlagenstrukturen in vorhandenen NSO-Paketen vorgenommen, die zu Fehlern in bestimmten Regressionstestfällen führten, die vom Verhalten älterer Vorlagen abhingen.
Um diese Kompatibilitätslücken zu schließen, wurden die betroffenen NSO-Paketvorlagen analysiert und aktualisiert, um sie an die überarbeiteten Schema- und Verarbeitungsanforderungen von NSO 6.4.1.1 anzupassen. Diese Erweiterungen stellten sicher, dass alle Automatisierungs-Workflows und Servicemodelle wie erwartet funktionierten, wodurch die Regressionsstabilität wiederhergestellt und die Konsistenz in der aktualisierten CNC-Umgebung aufrechterhalten wurde.
Probleme bei der Skalierung von Leistungskennzahlen
CNC bietet eine sofort einsatzbereite Benutzeroberfläche zur Aktivierung von KPI-Profilen auf Geräten. Dieser Ansatz funktioniert zwar für kleine Flotten gut, wird aber in großem Maßstab ineffizient und unzuverlässig. Bei dieser Bereitstellung waren mehr als 2.000 SWR-Geräte auf die Aktivierung von KPIs angewiesen, und die Benutzeroberfläche bot keine effektive Möglichkeit, Geräte in großen Mengen auszuwählen oder zu verarbeiten.
Zunächst wurde ein tagging-basierter Ansatz versucht: Alle SWR-Geräte erhielten ein SWR-Tag, und die Aktivierung der Kennzahlen erfolgte nicht über eine manuelle, sondern über eine Tag-Auswahl. Die Verarbeitung von mehr als 2.000 Geräten in einem einzigen Workflow führte jedoch zu erheblichen betrieblichen Herausforderungen. Der Job dauerte mehr als drei Stunden und wurde mit Hunderten von Ausfällen abgeschlossen. Obwohl alle Geräte in der Absicht enthalten waren, konnten nur ~750 die KPI-Unterstützung erfolgreich erhalten, und wiederholte Versuche führten nur zu inkrementellen Fortschritten. Dieser Ansatz erwies sich weder als skalierbar noch als reproduzierbar. Es zeigte sich, dass die Last erhebliche Probleme aufwies.
Eine zweite Herausforderung ergaben sich aus Synchronisierungsproblemen der NSO-Geräte. Viele Ausfälle deuteten darauf hin, dass der NSO nicht mit den entsprechenden Geräten synchronisiert war. Der Versuch, eine manuelle Synchronisierung durchzuführen und anschließend die Kennzahlen wieder zu aktivieren, war nicht praktikabel und hätte einen erheblichen Arbeitsaufwand für die Telefonzentrale erfordert.
Um diese Einschränkungen zu umgehen, wurde ein automatisierter, batchgesteuerter Workflow entwickelt:
- Exportieren des gesamten CNC-Bestands
- Verarbeitung von Geräten in Chargen von 50 (wird durch Abstimmung als optimale Größe erkannt).
- Triggern Sie für jeden Stapel eine automatische Synchronisierung mithilfe der Geräte-UUIDs.
- Durchführung von KPI-Aktivierung über die CNC-API
- Programmgesteuertes Überwachen des KPI-Auftragsverlaufs und Protokollieren von Fehlern.
- Verarbeiten Sie ausgefallene Geräte erneut, indem Sie die Synchronisierungs- und KPI-Aktivierungsschritte wiederholen.
- Wenn ein Stapel erfolgreich abgeschlossen wurde, fahren Sie mit den nächsten 50 Geräten fort.
Die Automatisierung umfasste auch die Möglichkeit, KPI-Profile zu deaktivieren und so ein umfassendes Lebenszyklusmanagement zu ermöglichen.
Diese Lösung bot einen optimierten, deterministischen und hochgradig skalierbaren Prozess für die Bereitstellung von Leistungskennzahlen. Manuelle Eingriffe wurden eliminiert, einheitliche Ergebnisse wurden sichergestellt und mehrere Tage des Betriebsaufwands eingespart. Die gleiche Automatisierung erwies sich als unschätzbar wertvoll, als KPI-Profile nach der BNM-Designänderung deaktiviert und wieder aktiviert werden mussten, sodass eine schnelle und fehlerfreie Neukonfiguration der gesamten 2.000 Geräte möglich war.
RESTCONF Northbound-API - auf Administratorzugriff beschränkt
Die RESTCONF-basierte Northbound-API für die Weiterleitung von Alarmen und Ereignissen von der CNC hat eine Einschränkung, dass sie nur über das Admin-Konto aufgerufen werden kann. Die Versuche, über Dienstkonten auf die API zuzugreifen, schlugen fehl, obwohl diese Konten über die erforderlichen Betriebsrollen verfügten. Als Problemumgehung musste der Benutzer die Admin-Anmeldedaten für die Alarmweiterleitung an das Northbound-System verwenden. Dies führte zu einer Betriebsbeschränkung und schränkte die Einhaltung der Zugriffsprinzipien mit den geringsten Rechten ein.
Automatisierung als strategischer Erfolgsfaktor
Angesichts des Umfangs und der Komplexität des CNC-Upgrade- und Migrationsprogramms erwies sich die manuelle Ausführung betrieblicher Aufgaben schnell als nicht nachhaltig. Aktivitäten wie die Geräteintegration, die Bereitstellung von Leistungskennzahlen, die Ausrichtung der Konfiguration, der Abgleich und die Telemetriedvalidierung umfassen Tausende von Netzwerkelementen und wiederholten Workflows, die bei einer manuellen Ausführung sehr fehleranfällig sind. Die Automatisierung war daher nicht nur für eine schnellere Ausführung, sondern auch für die Gewährleistung von Konsistenz, die Verringerung betrieblicher Risiken und die Befreiung der Teams von zeitintensiven, sich wiederholenden Aufgaben von entscheidender Bedeutung.
Durch die Systematisierung dieser Prozesse mittels skriptgesteuerter Workflows und API-gestützter Betriebsabläufe konnte das Upgrade-Programm erhebliche Effizienzsteigerungen erzielen. Die Automatisierung ermöglichte eine schnellere Aufgabenabwicklung, eine höhere Genauigkeit und vorhersehbare Ergebnisse in allen Bereichen. Die dadurch erzielten Einsparungen reduzierten nicht nur die Gesamtbereitstellungszeit, sondern ermöglichten es den Technikern auch, sich auf höherwertige Validierungs- und Designarbeiten zu konzentrieren, anstatt sich um routinemäßige Betriebsaufgaben zu kümmern.
Einige der Automatisierungsaktivitäten wurden vor dem Beginn des Upgrade-Projekts identifiziert, während andere sich weiterentwickelten, wenn Probleme auftraten. Es gab auch einige, die durch die Probleme, die im Laufe des Projekts entwickelt wurden, notwendig waren.
Diese Tabelle zeigt die Bereiche, in denen die Automatisierung erhebliche Auswirkungen auf das gesamte Programm hatte.
| Aufgabenbeschreibung |
Manueller Aufwand (Tage) |
Automatisierungsaufwand (Tage) |
Geschätzte Einsparungen (Tage) |
| ACL-Updates (SWR/LWR)(über 2.000) |
30.0 |
2.0 |
28.0 |
| Gerätemigration und Anbindung an CDG (über 2.000) |
5 |
1.0 |
4.0 |
| BNM-KPI-Anschluss an Geräte (2.000+) |
4.0 |
1,5 (durchschn. |
2.5 |
| Service-Abstimmung |
7 |
2.5 |
4.5 |
| Migration von Gerätegruppen |
4 |
0.5 |
3.5 |
| Isolierung von Geräten mit stark eingeschränkter Bandbreite |
3 |
0.5 |
2.5 |
| MDT-Sammlung - Fehlerbehebung |
3 |
0.5 |
2.5 |
| Gesamtwerte |
56 Tage |
8,5 Tage |
47,5 Tage |
Erkenntnisse
Upgrade ist nicht einfach
CNC bietet keine Unterstützung für Upgrades vor Ort, und das Lift-and-Shift-Modell bringt eine erhebliche betriebliche Komplexität mit sich. Der Prozess darf niemals als einfach angenommen werden, insbesondere dann nicht, wenn der Versionssprung groß ist. Unerwartete Probleme tauchen bei Anwendungen, Integrationen und Workflows auf und erfordern Zeit, Analyse und sorgfältige Eindämmung. Diese Herausforderung wird durch einen großen Versionssprung noch verstärkt, der eine gründliche Planung, Validierung und stufenweise Ausführung erforderlich macht. Wir mussten viel mehr Zeit in TAC-Tickets und in die Fehlerbehebung investieren. Da wir dafür keine Pufferzeit hatten, wurde es eine Herausforderung.
CX muss das Heavy Lifting machen
Erwarten Sie erhebliche CX-Anstrengungen bei der Bereitstellung, Integration, Migration und End-to-End-Validierung von Anwendungsfällen. Gehen Sie nicht davon aus, dass sich die Workflows, die mit der alten Version getestet wurden, mit denen der neuen Version identisch verhalten.- Es wären eine Menge Fehlerbehebungs- und Analyseprozesse erforderlich, damit die Dinge funktionieren.
Automatisierungs-Toolkit ist ein Muss
Der Upgrade-Prozess hat gezeigt, dass die Automatisierung kein optionaler Komfort ist, sondern eine grundlegende Anforderung für große CNC-Bereitstellungen. Wir haben die Automatisierung für die erforderlichen Kandidaten frühzeitig geplant, können jedoch niemals davon ausgehen, dass dies ausreichen wird. In der Mitte des Projekts konnten Probleme in Anwendungsfällen identifiziert werden, in denen die Automatisierung definitiv einen Mehrwert bieten würde, wie in den vorherigen Abschnitten gezeigt wurde.
Vermeidung von Konflikten mit zwei Controllern während der Migration
Während des Upgrades muss sichergestellt werden, dass sowohl die alte als auch die neue CNC-Umgebung nicht gleichzeitig aktiv sind. Obwohl eine kurze Einweichphase für die Validierung erforderlich ist, führt eine deutliche Verlängerung, wie bei diesem Projekt über 2 Monate geschehen, zu Betriebsrisiken. Da beide CNCs über 15-20 Tage aktiv waren, führten Automatisierungsfunktionen mit geschlossenem Regelkreis wie Bandwidth-on-Demand zu inkonsistenten und widersprüchlichen Aktionen im gesamten Netzwerk, da die Automatisierungslogik von zwei Controllern gleichzeitig ausgeführt wurde.
Eine wichtige Lehre ist die Einführung klarer Sicherheitsvorkehrungen während der Migration. Maßnahmen wie die administrative Deaktivierung von Geräten in der alten CNC, die Unterbrechung von Automatisierungsworkflows oder die Beschränkung von Telemetrie-Abonnements hätten diese Konflikte verhindert. Bei zukünftigen Upgrades muss eine strikte Controller-Isolierung vorgesehen werden, um Interferenzen mit zwei Controllern zu vermeiden und ein vorhersehbares Netzwerkverhalten sicherzustellen.
MOPP sind nicht sakrosankt
Obwohl Verfahrensmethodendokumente (Method of Procedure, MOPP) für jeden Bereitstellungs-, Integrations- und Anwendungsfall erstellt werden, ist es unrealistisch anzunehmen, dass ein MOPP, der unter Laborbedingungen validiert wird, sich in der Produktion identisch verhält. In der Produktionsumgebung traten immer wieder Abweichungen auf, von denen einige geringfügig und einige signifikant waren, sodass Lücken deutlich wurden, die bei kontrollierten Tests nicht sichtbar waren. Reale Netzwerke, veraltetes Verhalten, externe Abhängigkeiten und Live-Datenverkehrsbedingungen führen Variablen ein, die Laborsimulationen nicht immer replizieren können.
Die wichtigste Erkenntnis besteht darin, dass die Teams bei der Einführung der Produktionsumgebung auf unerwartete Verhaltensweisen, Randbedingungen und neue Erkenntnisse vertrauen müssen. Flexibilität, schnelle Fehlerbehebung und die Bereitschaft zur sofortigen Anpassung von Prozessen sind für eine erfolgreiche und skalierbare Durchführung unerlässlich.
Wirksamkeit der TAC-Fälle
Probleme nach der Produktion sind unvermeidlich, und während die erste Fehlerbehebung durch das Bereitstellungsteam wertvoll ist, kann der ausschließliche Einsatz von internen Bemühungen zu unnötigen Verzögerungen führen. Es ist ratsam, parallel ein TAC-Ticket als Sicherheitsnetz zu öffnen, insbesondere für produktbezogene Probleme oder komplexe Verhaltensweisen, die nicht sofort diagnostizierbar sind. TAC-Untersuchungen erfordern häufig Zeit, und eine Verzögerung der Fallerstellung um mehrere Tage kann zu erheblichen Verlusten an Projektimpulsen führen. Durch eine frühzeitige Kontaktaufnahme mit dem TAC wird sichergestellt, dass Experten bei Bedarf zur Verfügung stehen, die Ursachenermittlung beschleunigt wird und vermeidbare Zeitplanabweichungen vermieden werden.
Arbeiten Sie mit der CNC-Geschäftseinheit zusammen, um effektiven Wissenssupport zu erhalten
Starke Unterstützung durch den Geschäftsbereich CNC ist bei jedem CNC-Projekt sehr wertvoll. Häufig benötigen Benutzer detaillierte Produkteinblicke und -klärungen, die ihnen allein vom Bereitstellungsteam nicht sofort zur Verfügung stehen. Die Verfügbarkeit eines Geschäftsbereichskontakts während des gesamten Projekts beschleunigt die Problembehebung, erhöht die technische Genauigkeit und stärkt das Vertrauen und die Beziehung zwischen den Benutzern.
Best Practices für CNC-Upgrades
Planung einer optimierten Upgrade-Strategie
CNC bietet keine Unterstützung für Upgrades vor Ort, sodass parallele Bereitstellungen unvermeidlich sind. Behandeln Sie die neue Umgebung als Neuinstallation, und weisen Sie eine ausreichende Rechen-, Speicher- und Verwaltungskapazität zu, um zwei Umgebungen gleichzeitig auszuführen. Planen Sie Validierungsphasen, die Migrationssequenzierung und Umstellungsaktivitäten rechtzeitig im Voraus.
Eine strenge Validierung vor der Bereitstellung ist insbesondere für nicht veränderliche Parameter unerlässlich.
Zahlreiche Erfahrungen machen deutlich, wie wichtig Sorgfalt bei der Erstbereitstellung ist. Die Validierung aller wichtigen Eingaben im Vorfeld, insbesondere der unveränderlichen Konfigurationsparameter, ist wichtig, um kostspielige Umbereitstellungen und Auswirkungen auf den Zeitplan zu vermeiden. Die Verwendung von strukturierten Checklisten vor der Bereitstellung, Peer Reviews und Dry-Run-Validierungen wird daher dringend empfohlen, um das Risiko irreversibler Konfigurationsfehler zu minimieren.
Verwenden einer dedizierten Validierungsumgebung vor dem Berühren der Produktion
Durch die frühzeitige Einrichtung einer internen CALO/Test-Umgebung können Teams experimentieren, Workflows validieren, versionsspezifische Änderungen identifizieren und Vertrauen aufbauen, bevor sie die Produktion berühren. Dadurch werden Unbekannte während der endgültigen Einführung deutlich reduziert.
Evidenzbasierte Dimensionierung für verteilte Vernetzungskomponenten
Beim Design von Clustern, CDG-Distributionen und PCE-Zuweisungen müssen die Basisentscheidungen auf Gerätetypen, Schnittstellenskalierung, Topologiekomplexität und Erfassungsintensität basieren, anstatt auf einer einfachen Anzahl von Geräten. Ausgewogene Verteilungen verhindern eine Überlastung und gewährleisten eine vorhersehbare Leistung im Cluster.
Automatisierung für wiederholte, absatzstarke Arbeiten
Automatisierungsrückstände bei der Einführung von Aufgaben, die sich wiederholen, hohe Volumen haben oder betriebskritisch sind, und Investitionen, wenn eine Automatisierung erforderlich ist Validieren und verfeinern Sie zuerst Ihre Automatisierung in der SIT-Umgebung, um sicherzustellen, dass die Produktion nicht auf kurzfristige Korrekturen angewiesen ist. Skalierung erhöht die Kosten für manuelle Arbeit; Die standardisierte Automatisierung verbessert Qualität, Geschwindigkeit und Kontrolle. Die Ergebnisse können als wiederverwendbare Ressourcen (dokumentierte Schnittstellen, parametrisierte Jobs, gemeinsam genutzte Bibliotheken) gepackt werden, sodass Teams die gleiche Automatisierung für zukünftige Crosswork-Upgrades und angrenzende Projekte nutzen und so die Nacharbeit und Onboarding-Zeit reduzieren können.
Vermeidung von doppelten geschlossenen Regelkreisen bei parallelem Lauf
Nutzen Sie Closed-Loop-Automatisierung während der Koexistenz als Single-Writer-Funktion: Nur ein Orchestrierungspfad kann die Sanierung oder richtliniengesteuerte Konfiguration aktiv unterstützen. Bei der gleichzeitigen Verwendung von CLA in alten und neuen Stacks besteht die Gefahr, dass Auslöser doppelt vorhanden sind und dass unterschiedliche Absichten auftreten, wodurch der Gerätestatus destabilisiert werden kann. Planung CLA Go-Live als Meilenstein in der Spätphase nach funktionaler Validierung und definitiver Umstellung auf den neuen Controller.
Durchführung einer strukturierten Analyse der Upgrade-Auswirkungen
Wichtige Versionssprünge führen zu neuen Funktionen, während ältere veraltet oder geändert werden. Es ist äußerst wichtig, diese Veränderungen zu berücksichtigen. In vielen Fällen wird die Änderung nicht in den Versionshinweisen der aktualisierten Version dokumentiert, sondern wird angezeigt, sobald die neue Version vor Ort verfügbar ist. Durchführung strukturierter Bewertungen von
- Veraltete APIs
- Änderungen am KPI-Framework
- Unterschiede im Verhalten auf Anwendungsebene
- Abweichungen beim Konfigurationsmodell
- Warnmeldungen, Verarbeitung der Topologie und Änderungen bei der Umsetzung des strategischen Leitfadens
Testen der Kompatibilität und des Verhaltens auf der gesamten Integrationsoberfläche
CNC interagiert mit mehreren externen Systemen wie NSO, SSM, CPNR, EPNM, OneFM, Splunk und Orchestrierungs-Frameworks.
Vor der Migration:
- Kompatibilität der Version überprüfen
- Testen aller Northbound/Southbound-Integrationen
- Datenmodelle, Traps, Telemetrieflüsse bestätigen
- SSL-/RESTCONF-Authentifizierungsverhalten überprüfen
Integrationsfehler, die nach der Migration entdeckt werden, führen zu betrieblichen Engpässen.
Entwicklung einer zuverlässigen Datenexportstrategie vor der Migration
Alles vor Beginn der Migration exportieren:
- Berechtigungsprofile
- Anbieter
- Tags
- Benutzerdefinierte Leitfäden
- Benutzerdefinierte KPIs
- Rollen und rollenbasierte Zugriffskontrolle
- ZTP-Gutscheine
- Gerätegruppen
- Verlaufsservice-Metadaten
Batch Device Migration mit integrierten Validierungsgates
Bei der Migration Tausender Geräte führen Sie die Migration in kontrollierten Batches durch:
- Verschieben von Geräten in festen Kohorten (z. B. nach Region, CDG-Last oder Gerätetyp)
- Überprüfung von Telemetrie, NSO-Synchronisierungsstatus und Erreichbarkeit, bevor mit dem nächsten Batch fortgefahren wird
- Rollback des Stapels, wenn dauerhafte Anomalien auftreten
Dadurch wird eine hohe Belastung von CDG und CNC in kurzer Zeit vermieden.
Handhabung von Out-of-Band-Konfigurationsänderungen durch NSO-Integration
Zur Bewältigung von Out-of-Band-Herausforderungen im Rahmen des CNC 4.1- bis 7.1-Upgrades wurde eine strukturierte Umstellung auf NSO-gesteuerte Prozesse implementiert. Dem Betriebsteam wurde ein kontrollierter, benutzerbasierter Zugriff auf die Kommandozeile des NSO gewährt, während der direkte administrative Zugriff auf die Geräte-Kommandozeile eingeschränkt wurde, um Out-of-Band-Änderungen zu verhindern. Darüber hinaus wurden ältere CLI-Skripte systematisch in eine RESTCONF-basierte Automatisierung konvertiert, die in den NSO integriert ist. Dadurch werden Funktionen wie eine Probelauf-Validierung und ein transaktionales Rollback ermöglicht. Mit diesem Ansatz wurde sichergestellt, dass alle Konfigurationsänderungen zentral verwaltet und geprüft werden konnten und mit den Servicemodellen des NSO konsistent waren. Konfigurationsabweichungen wurden so effektiv vermieden, und die Zuverlässigkeit der Bereitstellung wurde wiederhergestellt.
Starke Betonung auf Einfrieren von Veränderungen
Während kritischer Migrationsphasen:
- Einfrieren von benutzerinitiierten Netzwerkänderungen
- Konfigurationspushvorgänge einschränken
- Synchronisierung mit Außendienst- und NOC-Teams
- Planen Sie ein Fenster für Notfallaktivitäten wie den Austausch von Geräten mit CNC/ZTP usw.
Dies reduziert Geräusche und stellt sicher, dass der Netzwerkstatus während des Upgrades stabil bleibt.
Schlussfolgerung
Die Migration von CNC 4.1 auf CNC 7.1 stellt eine wichtige Fallstudie hinsichtlich der Komplexität dar, die mit umfangreichen Upgrades der Netzwerkorchestrierungsplattform verbunden ist. Dieses Projekt zeigt, dass solche Übergänge nicht nur Versionsverbesserungen sind, sondern umfassende Transformationen über Architekturebenen, betriebliche Workflows und Automatisierungsökosysteme hinweg. Das Fehlen eines Upgrade-Pfades vor Ort erforderte eine vollständige Lift-and-Shift-Bereitstellung, die Herausforderungen paralleler Umgebungen mit sich brachte und eine sorgfältige Koordination zwischen CNC, NSO, SR-PCE, CDG und externen Systemintegrationen erforderte. Die daraus resultierende Betriebsumgebung unterstreicht die Bedeutung zuverlässiger Migrationsmethoden, umfassender Validierungszyklen und streng kontrollierter Umstellungsprozesse zur Risikominimierung in Produktionsumgebungen.
Das Upgrade zeigte außerdem, wie wichtig Automatisierung als unverzichtbare Säule für Skalierbarkeit und Genauigkeit ist. Mit mehr als 2.000 Geräten, umfangreichen Telemetriekonfigurationen, mehreren abhängigen Komponenten und dynamischen Closed-Loop-Automatisierungs-Workflows zeigte das Projekt die Einschränkungen manueller Verfahren in Umgebungen dieser Größenordnung auf. ACL-Updates, die Geräteintegration, die Bereitstellung von Leistungskennzahlen, die Telemetriesanierung und die Fehlerisolierung waren ausschlaggebend für die Entscheidungsfindung, die Reduzierung menschlicher Fehler und die Erzielung erheblicher Effizienzsteigerungen. Das Automatisierungs-Framework ermöglichte nicht nur die betriebliche Kontinuität während der Migration, sondern legte auch eine nachhaltige Grundlage für die laufende Netzwerkoptimierung.
Ebenso wichtig war die Erkenntnis, dass das Produktionsverhalten deutlich von kontrollierten Laborbedingungen abweicht. Durch Änderungen am Framework, z. B. den Übergang von der Tick-basierten KPI-Logik zu Tracker-basierten Definitionen, wurden unvorhergesehene Verhaltensänderungen eingeführt, die eine Überarbeitung, erneute Tests und iterative Verbesserung erforderten. In ähnlicher Weise machten die betrieblichen Herausforderungen im Zusammenhang mit der Closed-Loop-Automatisierung, der Zuverlässigkeit von Telemetriedaten und dem API-Verhalten deutlich, dass eine adaptive Fehlerbehebung, eine proaktive Risikobewertung und die kontinuierliche Zusammenarbeit mit den Fachexperten des TAC und der Geschäftsbereiche erforderlich sind. Diese Faktoren zeigen zusammen, dass umfangreiche Versionsänderungen sowohl technische Tiefe als auch organisatorische Vorbereitung erfordern. Es bleiben nur noch wenige offene Fragen, die voraussichtlich in der nächsten Kreuzworträtsel 7.2 gelöst werden.
Insgesamt zeigt dieses Upgrade, dass erfolgreiche großflächige CNC-Migrationen auf vier grundlegenden Säulen beruhen: eine rigorose Validierung vor der Bereitstellung, eine systematische und ausfallsichere Automatisierung, eine enge funktionsübergreifende Koordination und ein adaptiver Betriebszustand, der Abweichungen zwischen Labor- und Produktionsumgebungen voraussieht. Die bei diesem Projekt gewonnenen Erkenntnisse trugen nicht nur zu einer stabilen Bereitstellung von CNC 7.1 bei, sondern sie bieten auch eine Vorlage für künftige Übergänge, die Aufklärung über Best Practices, die Verstärkung von Architekturanleitungen und die Erweiterung des institutionellen Wissens für die Weiterentwicklung Ihres Netzwerkautomatisierungs-Ökosystems.
Glossar
| Begriff |
Definition |
| BNM |
Bandbreitenbenachrichtigung. |
| Katzenkatze |
Aktive Querschnittstopologie |
| CCA |
Automatisierung von Netzwerkänderungen |
| CDG |
Crosswork Data Gateway |
| CHI |
Crosswork Health Insight |
| CNC |
Cisco Crosswork Network Controller |
| COE |
Crosswork Optimization Engine |
| CPNR |
Cisco Prime Network Registrar |
| CWM |
Crosswork Workflow Manager |
| EMF |
Funktionen für das Element-Management |
| KPI |
Leistungskennzahl |
| Niederschrift |
Großer Wireless-Router |
| MDT |
Modellbasierte Telemetrie |
| MOPP |
Verfahrensweise |
| NBW |
Nennbandbreite |
| NSO |
Network Services Orchestrator |
| RBW |
Aufgezeichnete Bandbreite |
| SR-PCE |
Element zur Berechnung des Segmentroutingpfads |
| SSM |
Cisco Smart Software Manager |
| SWR |
Kleiner Wireless-Router |
| TAC |
Technical Assistance Center |
| TSDN |
Transport Software-Defined Networking |
| ZTP |
Zero-Touch-Bereitstellung |
| RR |
Routen-Reflektor |
| RP |
Routenprofil |
| Verbindungspunkt |
Verbindungspunkt |
| EVPN |
Virtuelles privates Ethernet-Netzwerk |
Referenzen
- Cisco Systems, Cisco Crosswork Network Controller - Versionshinweise, Version 7.1.0
- Cisco Systems, Cisco Crosswork Infrastructure 7.1 - Installationshandbuch
- Cisco Systems, Cisco Crosswork Infrastructure 7.1 - Administrationsleitfaden - Konzepte im Überblick:
- Cisco Systems, Crosswork Network Controller Traffic Engineering and Optimization Guide, Version 7.1
- Cisco Systems, Cisco Crosswork Health Insights-Benutzerhandbuch, Version 7.1
- Cisco Systems, ZTP-Bereitstellungsleitfaden (Crosswork Zero Touch Provisioning)
- Cisco Systems, Cisco NSO Transport SDN Function Pack - Installationshandbuch, Version 7.1.0
- Cisco Systems,Cisco SR-PCE Konfigurationsleitfaden
Revisionsverlauf
| Überarbeitung | Veröffentlichungsdatum | Kommentare |
|---|---|---|
2.0 |
04-May-2026
|
Erste Veröffentlichung, Formatierung, Header, Links, Grammatik, Rechtschreibung. |
1.0 |
30-Apr-2026
|
Erstveröffentlichung |
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)