فشل محرك أقراص ثابتة أحادي طراز Ultra-M UCS 240M4 - إجراء التبديل دون إيقاف التشغيل - تقنية vEPC
خيارات التنزيل
-
ePub (265.0 KB)
العرض في تطبيقات مختلفة على iPhone أو iPad أو نظام تشغيل Android أو قارئ Sony أو نظام التشغيل Windows Phone
لغة خالية من التحيز
تسعى مجموعة الوثائق لهذا المنتج جاهدة لاستخدام لغة خالية من التحيز. لأغراض مجموعة الوثائق هذه، يتم تعريف "خالية من التحيز" على أنها لغة لا تعني التمييز على أساس العمر، والإعاقة، والجنس، والهوية العرقية، والهوية الإثنية، والتوجه الجنسي، والحالة الاجتماعية والاقتصادية، والتمييز متعدد الجوانب. قد تكون الاستثناءات موجودة في الوثائق بسبب اللغة التي يتم تشفيرها بشكل ثابت في واجهات المستخدم الخاصة ببرنامج المنتج، أو اللغة المستخدمة بناءً على وثائق RFP، أو اللغة التي يستخدمها منتج الجهة الخارجية المُشار إليه. تعرّف على المزيد حول كيفية استخدام Cisco للغة الشاملة.
حول هذه الترجمة
ترجمت Cisco هذا المستند باستخدام مجموعة من التقنيات الآلية والبشرية لتقديم محتوى دعم للمستخدمين في جميع أنحاء العالم بلغتهم الخاصة. يُرجى ملاحظة أن أفضل ترجمة آلية لن تكون دقيقة كما هو الحال مع الترجمة الاحترافية التي يقدمها مترجم محترف. تخلي Cisco Systems مسئوليتها عن دقة هذه الترجمات وتُوصي بالرجوع دائمًا إلى المستند الإنجليزي الأصلي (الرابط متوفر).
المحتويات
المقدمة
يصف هذا المستند الخطوات المطلوبة لاستبدال محرك الأقراص الثابتة (HDD) المعيب الموجود في الخادم بإعداد Ultra-M يستضيف وظائف الشبكة الظاهرية (VNFs) لنظام التشغيل StarOS.
معلومات أساسية
Ultra-M هو حل مركزي لحزم البيانات المحمولة تم تجميعه مسبقا والتحقق من صحته افتراضيا تم تصميمه لتبسيط عملية نشر شبكات VNF. OpenStack هو مدير البنية الأساسية الظاهرية (VIM) ل Ultra-M ويتكون من أنواع العقد التالية:
- حوسبة
- قرص تخزين الكائنات - الحوسبة (OSD - الحوسبة)
- ضابط
- النظام الأساسي OpenStack - المدير (OSPD)
تم توضيح البنية المعمارية عالية المستوى لتقنية Ultra-M والمكونات المعنية في هذه الصورة:
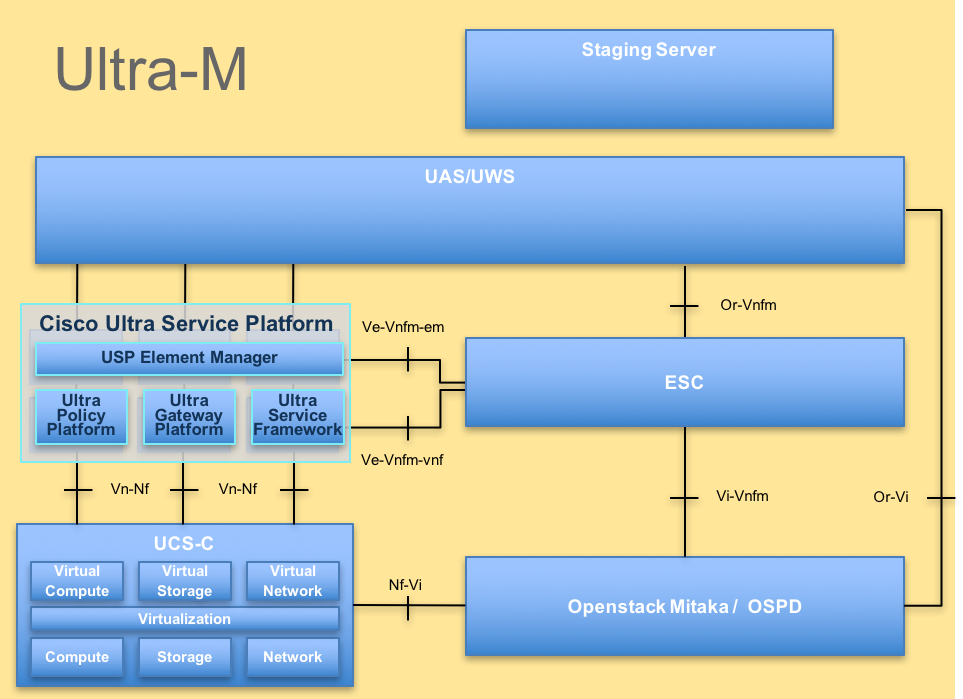 بنية UltraMهذا المستند مخصص لأفراد Cisco المطلعين على نظام Cisco Ultra-M الأساسي وهو يفصل الخطوات المطلوبة ليتم تنفيذها على مستوى OpenStack في وقت إستبدال خادم OSPD.
بنية UltraMهذا المستند مخصص لأفراد Cisco المطلعين على نظام Cisco Ultra-M الأساسي وهو يفصل الخطوات المطلوبة ليتم تنفيذها على مستوى OpenStack في وقت إستبدال خادم OSPD.
ملاحظة: يتم النظر في الإصدار Ultra M 5.1.x لتحديد الإجراءات الواردة في هذا المستند.
المختصرات
| VNF | وظيفة الشبكة الظاهرية |
| سي إف | دالة التحكم |
| SF | وظيفة الخدمة |
| ESC | وحدة التحكم المرنة في الخدمة |
| ممسحة | طريقة إجرائية |
| OSD | أقراص تخزين الكائنات |
| محرك الأقراص الثابتة | محرك الأقراص الثابتة |
| محرك أقراص مزود بذاكرة مصنوعة من مكونات صلبة | محرك أقراص في الحالة الصلبة |
| فيم | مدير البنية الأساسية الظاهرية |
| VM | جهاز ظاهري |
| إم | مدير العناصر |
| UAS | خدمات أتمتة Ultra |
| uID | المعرف الفريد العالمي |
سير عمل مذكرة التفاهم
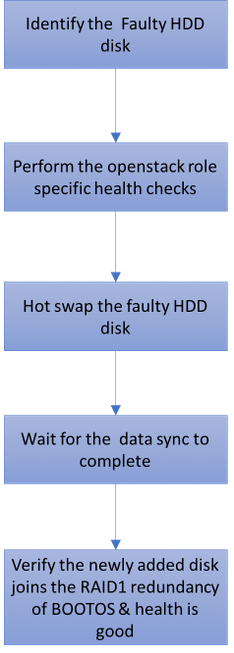
فشل محرك أقراص ثابتة واحد
1. سيتم تزويد كل خادم Baremetal بمحركي أقراص ثابتة للعمل كقرص بدء تشغيل في تهيئة RAID 1. في حالة تعطل محرك أقراص ثابتة واحد، ونظرا لوجود تكرار من المستوى RAID 1، يمكن تبديل محرك الأقراص الثابتة المعيب دون إيقاف التشغيل.
2. يمكن الرجوع إلى إجراء إستبدال مكون معيب على خادم UCS C240 M4 من: إستبدال مكونات الخادم.
3. في حالة تعطل محرك أقراص ثابتة واحد، سيتم تبديل محرك الأقراص الثابتة المعيب فقط دون إيقاف التشغيل، ومن ثم لا يلزم إجراء ترقية نظام الإدخال والإخراج الأساسي (BIOS) بعد إستبدال الأقراص الجديدة.
4. بعد إستبدال الأقراص، انتظر مزامنة البيانات بين الأقراص. قد يستغرق الأمر ساعات للاكتمال.
5. في حل يستند إلى OpenStack (Ultra-M)، يمكن لخادم UCS 240M4 Baremetal أن يضطلع بواحد من هذه الأدوار: الحوسبة، OSD-compute، وحدة التحكم، و OSPD. تكون الخطوات المطلوبة لمعالجة فشل واحد في محرك الأقراص الثابتة في كل من أدوار الخادم هذه هي نفسها ويصف هذا القسم فحوصات الصحة التي يجب إجراؤها قبل التبديل السريع للقرص.
فشل محرك أقراص ثابتة واحد في خادم الكمبيوتر
1. إذا تم ملاحظة فشل محركات الأقراص الثابتة في UCS 240M4 التي تعمل كعقدة حوسبة، فقم بإجراء فحوصات السلامة هذه قبل أن تقوم أخيرا بعملية التبديل السريع للقرص المعيب
2. التعرف على الأجهزة الافتراضية (VM) التي تعمل على هذا الخادم والتحقق من حالة الوظائف.
التعرف على الأجهزة الافتراضية المستضافة في عقدة الحوسبة:
التعرف على الأجهزة الافتراضية (VM) المستضافة على خادم الكمبيوتر والتحقق من أنها نشطة وقيد التشغيل. وقد يكون هناك إحتمالان:
1. يحتوي خادم الكمبيوتر على SF VM فقط.
[stack@director ~]$ nova list --field name,host | grep compute-10
| 49ac5f22-469e-4b84-badc-031083db0533 | VNF2-DEPLOYM_s8_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d |
pod1-compute-10.localdomain | ACTIVE|
2. يحتوي خادم الكمبيوتر على مجموعة CF/ESC/EM/UAS من الأجهزة الافتراضية.
[stack@director ~]$ nova list --field name,host | grep compute-8
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain | ACTIVE |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c2_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain | ACTIVE |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain | ACTIVE |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain | ACTIVE |
ملاحظة: في الإخراج المعروض هنا، يتوافق العمود الأول مع UUID، بينما يمثل العمود الثاني اسم VM، أما العمود الثالث فهو اسم المضيف حيث يوجد VM.
فحوصات الصحة:
1. سجل الدخول إلى StarOS VNF وحدد البطاقة التي تطابق SF أو CF VM. أستخدم المعرف الفريد (UUID) الخاص ب SF أو CF VM المحدد من القسم "التعرف على الأجهزة الافتراضية المستضافة في عقدة الحوسبة"، والتعرف على البطاقة المطابقة لمعرف المستخدم الفريد (UID).
[local]VNF2# show card hardware
Tuesday might 08 16:49:42 UTC 2018
<snip>
Card 8:
Card Type : 4-Port Service Function Virtual Card
CPU Packages : 26 [#0, #1, #2, #3, #4, #5, #6, #7, #8, #9, #10, #11, #12, #13, #14, #15, #16, #17, #18, #19, #20, #21, #22, #23, #24, #25]
CPU Nodes : 2
CPU Cores/Threads : 26
Memory : 98304M (qvpc-di-large)
UUID/Serial Number : 49AC5F22-469E-4B84-BADC-031083DB0533
<snip>
[local]VNF2# show card hardware
Tuesday might 08 16:49:42 UTC 2018
<snip>
Card 2:
Card Type : Control Function Virtual Card
CPU Packages : 8 [#0, #1, #2, #3, #4, #5, #6, #7]
CPU Nodes : 1
CPU Cores/Threads : 8
Memory : 16384M (qvpc-di-large)
UUID/Serial Number : F9C0763A-4A4F-4BBD-AF51-BC7545774BE2
<snip>
2. التحقق من حالة البطاقة.
[local]VNF2# show card table
Tuesday might 08 16:52:53 UTC 2018
Slot Card Type Oper State SPOF Attach
----------- -------------------------------------- ------------- ---- ------
1: CFC Control Function Virtual Card Active No
2: CFC Control Function Virtual Card Standby -
3: FC 4-Port Service Function Virtual Card Active No
4: FC 4-Port Service Function Virtual Card Active No
5: FC 4-Port Service Function Virtual Card Active No
6: FC 4-Port Service Function Virtual Card Active No
7: FC 4-Port Service Function Virtual Card Active No
8: FC 4-Port Service Function Virtual Card Active No
9: FC 4-Port Service Function Virtual Card Active No
10: FC 4-Port Service Function Virtual Card Standby -
3. سجل الدخول إلى ESC المستضاف في عقدة الحوسبة وفحص الحالة.
[admin@VNF2-esc-esc-0 esc-cli]$ escadm status
0 ESC status=0 ESC Master Healthy
4. سجل الدخول إلى EM المستضاف في عقدة الحوسبة وفحص الحالة.
ubuntu@vnfd2deploymentem-1:~$ ncs_cli -u admin -C
admin connected from 10.225.247.142 using ssh on vnfd2deploymentem-1
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
---------------------
3 up up up
6 up up up
5. سجل الدخول إلى وحدات UAS المستضافة في عقدة الحوسبة وفحص الحالة.
ubuntu@autovnf2-uas-1:~$ sudo su
root@autovnf2-uas-1:/home/ubuntu# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on autovnf2-uas-1
autovnf2-uas-1#show uas ha
uas ha-vip 172.18.181.101
autovnf2-uas-1#
autovnf2-uas-1#
autovnf2-uas-1#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.18.181.101
INSTANCE IP STATE ROLE
-----------------------------------
172.18.180.4 alive CONFD-SLAVE
172.18.180.5 alive CONFD-MASTER
172.18.180.8 alive NA
autovnf2-uas-1#show errors
% No entries found.
6. إذا كانت عمليات التحقق من الصحة جيدة، فقم بالمتابعة مع إجراء التبديل السريع للقرص المعيب وانتظر مزامنة البيانات عندما يستغرق إتمامها ساعات. ارجع إلى إستبدال مكونات الخادم.
7. كرر إجراءات التحقق من الصحة هذه للتأكد من إستعادة حالة سلامة الأجهزة الافتراضية المستضافة على عقدة الكمبيوتر.
فشل محرك أقراص ثابتة واحد على خادم وحدة التحكم
1. في حالة ملاحظة فشل محركات الأقراص الثابتة في UCS 240M4، التي تعمل كعقدة وحدة تحكم، اتبع فحوصات السلامة قبل إجراء التبديل السريع للقرص المعيب.
2. تحقق من حالة منظم الحزم على وحدات التحكم.
3. سجل الدخول إلى أحد وحدات التحكم النشطة وفحص حالة جهاز تنظيم الحزم. يجب تشغيل كافة الخدمات على وحدات التحكم المتوفرة وتوقيفها على وحدة التحكم الفاشلة.
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-0 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Thu Jun 28 07:53:06 2018 Last change: Wed Jan 17 11:38:00 2018 by root via cibadmin on pod1-controller-0
3 nodes and 22 resources conimaged
Online: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-10.2.2.2 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.120.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
ip-11.120.0.50 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.118.0.48 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-192.200.0.102 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-0 ]
Slaves: [ pod1-controller-1 pod1-controller-2 ]
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-0
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Started pod1-controller-2
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Started pod1-controller-0
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
4. تحقق من حالة MariaDB في وحدات التحكم النشطة.
[stack@director] nova list | grep control
| 4361358a-922f-49b5-89d4-247a50722f6d | pod1-controller-0 | ACTIVE | - | Running | ctlplane=192.200.0.102 |
| d0f57f27-93a8-414f-b4d8-957de0d785fc | pod1-controller-1 | ACTIVE | - | Running | ctlplane=192.200.0.110 |
[stack@director ~]$ for i in 192.200.0.102 192.200.0.110 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_state_comment'\" ; sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_cluster_size'\""; done
*** 192.200.0.152 ***
Variable_name Value
wsrep_local_state_comment Synced
Variable_name Value
wsrep_cluster_size 2
*** 192.200.0.154 ***
Variable_name Value
wsrep_local_state_comment Synced
Variable_name Value
wsrep_cluster_size 2
5. تحقق من وجود هذه البنود لكل وحدة تحكم نشطة:
wsrep_local_state_comment: Synced
wsrep_cluster_size: 2
6. تحقق من حالة Rabbitmq في وحدات التحكم النشطة.
[heat-admin@pod1-controller-0 ~]$ sudo rabbitmqctl cluster_status
Cluster status of node 'rabbit@pod1-controller-0' ...
[{nodes,[{disc,['rabbit@pod1-controller-0','rabbit@pod1-controller-1',
'rabbit@pod1-controller-2']}]},
{running_nodes,['rabbit@pod1-controller-2',
'rabbit@pod1-controller-1',
'rabbit@pod1-controller-0']},
{cluster_name,<<"rabbit@pod1-controller-0.localdomain">>},
{partitions,[]},
{alarms,[{'rabbit@pod1-controller-2',[]},
{'rabbit@pod1-controller-1',[]},
{'rabbit@pod1-controller-0',[]}]}]
7. إذا كانت عمليات التحقق من الصحة جيدة، فقم بالمتابعة مع إجراء التبديل السريع للقرص المعيب وانتظر مزامنة البيانات عندما يستغرق إتمامها ساعات. ارجع إلى إستبدال مكونات الخادم.
8. كرر إجراءات التحقق من الصحة هذه للتأكد من إستعادة الحالة الصحية لوحدة التحكم.
فشل محرك أقراص ثابتة واحد على خادم حوسبة OSD
إذا تم ملاحظة فشل محركات الأقراص الثابتة في UCS 240M4 التي تعمل كعقدة SN OSD-Compute، فقم بإجراء فحوصات السلامة هذه قبل إجراء عملية التبديل السريع للقرص المعيب.
التعرف على الأجهزة الافتراضية المستضافة في عقدة OSD-Compute:
التعرف على الأجهزة الافتراضية (VM) المستضافة على خادم الحوسبة. وقد يكون هناك إحتمالان:
1. يحتوي خادم OSD-Compute على مجموعة EM/UAS/Auto-Deployment/Auto-IT من VMs.
[stack@director ~]$ nova list --field name,host | grep osd-compute-0
| c6144778-9afd-4946-8453-78c817368f18 | AUTO-DEPLOY-VNF2-uas-0 | pod1-osd-compute-0.localdomain | ACTIVE |
| 2d051522-bce2-4809-8d63-0c0e17f251dc | AUTO-IT-VNF2-uas-0 | pod1-osd-compute-0.localdomain | ACTIVE |
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-osd-compute-0.localdomain | ACTIVE |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-osd-compute-0.localdomain | ACTIVE |
2. يحتوي خادم الكمبيوتر على مجموعة CF/ESC/EM/UAS من الأجهزة الافتراضية.
[stack@director ~]$ nova list --field name,host | grep osd-compute-1
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain | ACTIVE |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain | ACTIVE |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain | ACTIVE |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain | ACTIVE |
ملاحظة: في الإخراج المعروض هنا، يتوافق العمود الأول مع UUID، بينما يمثل العمود الثاني اسم VM، أما العمود الثالث فهو اسم المضيف حيث يوجد VM.
3. تكون عمليات CEPH نشطة على خادم OSD-Compute.
[root@pod1-osd-compute-1 ~]# systemctl list-units *ceph*
UNIT LOAD ACTIVE SUB DESCRIPTION
var-lib-ceph-osd-ceph\x2d11.mount loaded active mounted /var/lib/ceph/osd/ceph-11
var-lib-ceph-osd-ceph\x2d2.mount loaded active mounted /var/lib/ceph/osd/ceph-2
var-lib-ceph-osd-ceph\x2d5.mount loaded active mounted /var/lib/ceph/osd/ceph-5
var-lib-ceph-osd-ceph\x2d8.mount loaded active mounted /var/lib/ceph/osd/ceph-8
ceph-osd@11.service loaded active running Ceph object storage daemon
ceph-osd@2.service loaded active running Ceph object storage daemon
ceph-osd@5.service loaded active running Ceph object storage daemon
ceph-osd@8.service loaded active running Ceph object storage daemon
system-ceph\x2ddisk.slice loaded active active system-ceph\x2ddisk.slice
system-ceph\x2dosd.slice loaded active active system-ceph\x2dosd.slice
ceph-mon.target loaded active active ceph target allowing to start/stop all ceph-mon@.service instances at once
ceph-osd.target loaded active active ceph target allowing to start/stop all ceph-osd@.service instances at once
ceph-radosgw.target loaded active active ceph target allowing to start/stop all ceph-radosgw@.service instances at once
ceph.target loaded active active ceph target allowing to start/stop all ceph*@.service instances at once
4. تأكد من أن تعيين OSD (قرص HDD) إلى Journal (SSD) جيد.
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph-disk list
/dev/sda :
/dev/sda1 other, iso9660
/dev/sda2 other, xfs, mounted on /
/dev/sdb :
/dev/sdb1 ceph journal, for /dev/sdc1
/dev/sdb3 ceph journal, for /dev/sdd1
/dev/sdb2 ceph journal, for /dev/sde1
/dev/sdb4 ceph journal, for /dev/sdf1
/dev/sdc :
/dev/sdc1 ceph data, active, cluster ceph, osd.1, journal /dev/sdb1
/dev/sdd :
/dev/sdd1 ceph data, active, cluster ceph, osd.7, journal /dev/sdb3
/dev/sde :
/dev/sde1 ceph data, active, cluster ceph, osd.4, journal /dev/sdb2
/dev/sdf :
/dev/sdf1 ceph data, active, cluster ceph, osd.10, journal /dev/sdb4
5. تأكد من أن صحة CEPH ورسم خرائط شجرة OSD جيدان.
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e709: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v941813: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 11922 GB / 13393 GB avail
704 active+clean
client io 58580 B/s wr, 0 op/s rd, 7 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
6. إذا كانت عمليات التحقق من الصحة جيدة، فقم بالمتابعة مع إجراء التبديل السريع للقرص المعيب وانتظر مزامنة البيانات عندما يستغرق إتمامها ساعات. ارجع إلى إستبدال مكونات الخادم.
7. كرر إجراءات التحقق من الصحة هذه للتأكد من حالة صحة الأجهزة الافتراضية المستضافة على عقدة OSD-Compute التي تمت استعادتها.
فشل محرك أقراص ثابتة واحد على خادم OSPD
1. إذا تم ملاحظة فشل محركات الأقراص الثابتة في UCS 240M4، والتي تعمل كعقدة OSPD، فقم بإجراء فحوصات السلامة هذه قبل بدء عملية التبديل السريع للقرص المعيب.
2. تحقق من حالة مكدس OpenStack وقائمة العقد.
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
3. تحقق مما إذا كانت جميع خدمات UnderCloud في حالة تحميل ونشاط وتشغيل من عقدة OSP-D.
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-ovs-cleanup.service loaded active exited OpenStack Neutron Open vSwitch Cleanup Utility
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
4. إذا كانت عمليات التحقق من الصحة جيدة، فقم بالمتابعة مع إجراء التبديل السريع للقرص المعيب وانتظر مزامنة البيانات عندما يستغرق إتمامها ساعات. ارجع إلى إستبدال مكونات الخادم.
5. كرر إجراءات التحقق من الصحة هذه للتأكد من إستعادة حالة صحة عقد OSPD.
تمت المساهمة بواسطة مهندسو Cisco
- Partheeban Rajagopalخدمات Cisco المتقدمة
- Padmaraj Ramanoudjamخدمات Cisco المتقدمة
 التعليقات
التعليقاتاتصل بنا
- فتح حالة دعم

- (تتطلب عقد خدمة Cisco)