المقدمة
يوضح هذا المستند كيفية إستخدام إستثناءات مطابقة البيانات لتقليل الإيجابيات الخاطئة في تصنيفات بيانات منع فقدان البيانات (DLP).
نظرة عامة
تتيح لك استبعادات مطابقة البيانات إستبعاد بيانات متطابقة معينة، مما يساعدك على تحسين تصنيفات بيانات DLP وتقليل الإيجابيات الخاطئة بشكل ملحوظ. توفر هذه الميزة حماية أكثر دقة للبيانات عن طريق السماح باستبعاد البيانات المعروفة غير الحساسة أو التطابقات غير ذات الصلة من عمليات مسح DLP.
كيف تعمل البيانات المطابقة على تقليل الإيجابيات الخاطئة إلى الحد الأدنى
يمكن أن تولد المعرفات المدمجة والمخصصة إيجابيات خاطئة عندما تطابق الكلمات الأساسية أو النماذج بيانات غير حساسة. على سبيل المثال:
- المعرفات المستندة إلى الرقم:
قد تتطابق المعرفات مثل رقم الضمان الاجتماعي (SSN) في الولايات المتحدة مع أرقام أخرى من 9 أرقام، مثل معرفات الحساب الداخلي. يؤدي إستبعاد معرفات الحساب المعروفة إلى تقليل هذه الإيجابيات الخاطئة.
- المعرفات المستندة إلى النص:
وقد يكتشف عملاء الرعاية الصحية الذين يستخدمون تصنيف البيانات المتوافق مع معيار HIPAA مصطلح "السرطان" في السياقات غير المرضى، مثل "مؤسسة التبرع بالسرطان". يمكنك إستبعاد مصطلحات معينة لمنع مثل هذه التنبيهات الخاطئة.
باستخدام إستثناءات مطابقة البيانات، يمكنك تحديد المصطلحات أو أنماط regex، مما يضمن أن التطابقات على هذه لا تؤدي إلى أحداث انتهاك البيانات. وهذا يسمح بالتحكم الدقيق في تنبيهات DLP.
كيفية إستخدام إستثناءات مطابقة البيانات
-
في لوحة معلومات Umbrella، انتقل إلى صفحة تصنيف البيانات.
-
في قسم إستثناء معرفات البيانات، حدد إما معرف مخصص أو معرف مضمن لاستبعاده.
-
أدخل المصطلحات المحددة أو أنماط التعبير العادية التي تريد إستبعادها.
- تنطبق الاستبعادات فقط على المحتوى المتطابق المحدد، وليس الوثيقة بأكملها.
- على سبيل المثال، إذا استبعدت "منظمة التبرع بالسرطان"، فإن هذا المصطلح فقط هو المستبعد من المخالفات، في حين لا يزال يتم مسح بقية الوثيقة.
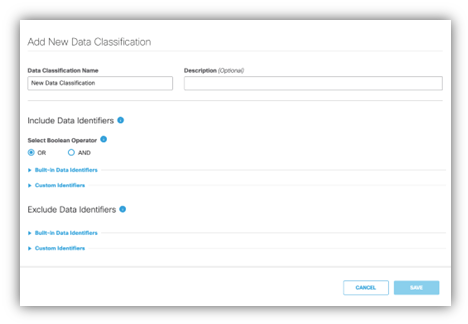
-
في حالة تضمين نفس معرف البيانات واستبعاده في نفس التصنيف، يأخذ الاستبعاد الأولوية.
الموارد ذات الصلة
ارجع إلى وثائق Umbrella للحصول على إرشادات خطوة بخطوة: إنشاء تصنيف بيانات.
 التعليقات
التعليقات