المقدمة
يوضح هذا المستند كيفية إستخدام أداة الأداء على مضيفي NSO للتحقيق في مشاكل الأداء.
المتطلبات الأساسية
المتطلبات
توصي Cisco بأن تكون لديك معرفة بالمواضيع التالية:
- إستخدام سطر أوامر Basic Linux/Unix
- بنية نظام NSO (Network Services Orchestrator) وتشغيله
- مفاهيم التحليل والتنميط الخاصة بوحدة المعالجة المركزية
- التعرف على سير عمل أستكشاف الأخطاء وإصلاحها
المكونات المستخدمة
تستند المعلومات الواردة في هذا المستند إلى إصدارات البرامج والمكونات المادية التالية:
- نظام NSO أو التركيب المحلي على مضيف Unix/Linux المدعوم
- برامج لينوكس مثل Ubuntu أو Debian أو Fedora أو مشتقات RedHat
- أداة الأداء (أداة تحليل أداء لينوكس)
تم إنشاء المعلومات الواردة في هذا المستند من الأجهزة الموجودة في بيئة معملية خاصة. بدأت جميع الأجهزة المُستخدمة في هذا المستند بتكوين ممسوح (افتراضي). إذا كانت شبكتك قيد التشغيل، فتأكد من فهمك للتأثير المحتمل لأي أمر.
معلومات أساسية
يعد الأداء المتميز (PERF) بمثابة أداة قوية لتحليل الأداء في نظام التشغيل Linux، ويتم إستخدامه بشكل أساسي في تحديد ملامح وحدة المعالجة المركزية (CPU). يوفر هذا البرنامج رؤى لما تعمل عليه وحدة المعالجة المركزية (CPU) حاليا من خلال التقاط أحمال الوظائف ذات المستوى الأدنى وتحليلها. ويساعد ذلك على تحديد الوظائف أو العمليات التي تشغل وحدة المعالجة المركزية، كما يعد ضروريا لتحديد نقاط ضعف الأداء.
كما يمكن أن ينتج الأداء رسوما بيانية عن اللهب، وهي مخططات خاصة تمثل بصريا الأجزاء التي تستخدم أكثر وقت لوحدة المعالجة المركزية (CPU) في البرنامج. تسهل رسومات اللهب البيانية تحديد المناطق في التعليمات البرمجية التي يجب أن تحتاج إلى تحسين.
والأهم من ذلك، يتم تضمين الأداء أيضا في القائمة المرجعية الرئيسية لجمع البيانات الخاصة بالحالات التي تم إخراجها من الذاكرة (OOM) كما أوصت بذلك وحدة العمل في NSO (BU). للحصول على إرشادات أكثر تفصيلا حول أستكشاف أخطاء OOM وإصلاحها، يرجى الاتصال ب Cisco TAC.
أستكشاف أخطاء أداء NSO وإصلاحها عند إستخدام PERF
يوفر هذا القسم سير عمل شاملا لتثبيت البيانات واستخدامها وتحليلها من أداة الأداء على مضيفي NSO لاستكشاف أخطاء الأداء وإصلاحها.
تثبيت PERF
الخطوة 1: قم بتركيب الأداء على برامج لينوكس الخاصة بك. أستخدم الأمر المناسب لنظام التشغيل الخاص بك:
بالنسبة إلى Ubuntu:
apt-get update && apt-get -y install linux-tools-generic
بالنسبة إلى دبيان:
apt-get update && apt-get -y install linux-perf
لمشتقات Fedora/RedHat:
dnf install -y perf
للحصول على مزيد من المعلومات حول المحاذير المعروفة أثناء تثبيت الأداء، يرجى الاتصال بفريق Cisco TAC.
أخذ عينات البيانات
الخطوة 1: تحديد عملية NSO الرئيسية.
أستخدم الأمر التالي لتحديد موقع عملية NCS.smp):
ps -ef | grep ncs\.smp
مثال الإخراج:
root 120829 1 16 13:23 ? 00:11:08 /opt/ncs/current/lib/ncs/erts/bin/ncs.smp -K true -P 277140 -- -root /opt/ncs/current/lib/ncs -progname ncs -- -home / -- -cd /var/opt/ncs -pa /opt/ncs/current/lib/ncs/patches -boot ncs -ncs true -delayed-detach -noshell -noinput -yaws embedded true -kernel gethost_poolsize 16 -stacktrace_depth 24 -shutdown_time 30000 -ssl_dist_optfile /var/opt/ncs/state/ssl_dist_optfile -delayed-heart -conffile /etc/ncs/ncs.conf -max_fds 65535 -- -detached-fd 4
root 121424 120604 0 14:30 pts/0 00:00:00 grep --color=auto ncs.smp
الخطوة 2: بدلا من ذلك، يجب أن تستخدم معرف العملية الرئيسية ل Java المرتبط ب NSO، خاصة إذا كان التركيز على عمليات Java. التشغيل:
ps -ef | grep NcsJVMLauncher
مثال الإخراج:
root 120903 120833 6 13:32 ? 00:03:40 java -classpath :/opt/ncs/current/java/jar/* -Dhost=127.0.0.1 -Dport=4569 -Djvm.restart.enabled=false -Djvm.restart.errCount=3 -Djvm.restart.duration=60 -Djava.security.egd=file:/dev/./urandom -Dfile.encoding=UTF-8 -Dorg.apache.logging.log4j.simplelog.StatusLogger.level=OFF com.tailf.ncs.NcsJVMLauncher
root 121435 120604 0 14:33 pts/0 00:00:00 grep --color=auto NcsJVMLauncher
الخطوة 3: قم بتنفيذ حالة الاختبار أو حالة الاستخدام ذات المشكلات للتحقق من صحة سيناريو الأداء.
الخطوة 4: في نافذة طرفية مختلفة، قم بتشغيل الأداء مقابل معرفات العملية (PIDs) ذات الصلة. أستخدم تنسيق الأمر التالي، مستبدلا XX و YY و ZZ بالمعرفات التي تم الحصول عليها أعلاه:
perf record -F 100 -g -p XX,YY,ZZ
على سبيل المثال، لتوصيف النظام بالكامل وتجميع الرسومات البيانية للاستدعاءات عند سرعة 99 هرتز لبطاقات PID معينة:
perf record -a -g -F 99 -p 120829,120903
مثال الإخراج:
Warning:
PID/TID switch overriding SYSTEM
أوصاف الخيارات:
- -أ: جميع وحدات المعالجة المركزية؛ مجموعة على مستوى النظام من جميع وحدات المعالجة المركزية (بشكل افتراضي إذا لم يتم تحديد هدف).
- -g: التقاط رسومات بيانية لاتصالات (مسارات المكدس). يحدد مكان إستدعاء الوظائف.
- -واو: تواتر أخذ العينات بهرتز. الترددات الأعلى تزيد الدقة لكنها تضيف مصروفات.
- -p: تحديد معرف (معرفات) العملية.
الخطوة 5: عندما تنتهي من تجميع العينات، توقف عن الأداء باستخدام Ctrl+C:
^C
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.646 MB perf.data (4365 samples) ]
يمكنك الآن رؤية ملف perf.data في الدليل الحالي.
الخطوة 6: إنشاء تقرير ملخص باستخدام هذا الأمر:
perf report -n --stdio > perf_report.txt
أوصاف الخيارات:
- -ن: إظهار الرموز بدون تجميع (عرض مسطح).
- —ستوديو: فرض الإخراج على المخرج القياسي (محطة طرفية).
عند هذه النقطة، يجب حفظ كلا الملفين (perf.data وperf_report.txt) ومشاركتهما مع جهة اتصال الدعم الخاصة بك قبل الانتقال إلى مزيد من التحليل.
إذا نجح الالتقاط، يعرض perf_report.txt بنية شبيهة بالشجرة تمثل رسما بيانيا للمكالمات الهرمية. تساعدك النسب المئوية على تحديد النقاط الفعالة حيث يتم قضاء معظم وقت وحدة المعالجة المركزية.
مثال مقتطف:
# Children Self Samples Command Shared Object Symbol
# ........ ........ ............ ............... .................... ...................................................................
# 30.61% 0.00% 0 C2 CompilerThre libc.so.6 [.] start_thread
# ---start_thread
# thread_native_entry(Thread*)
# Thread::call_run()
# JavaThread::thread_main_inner()
# CompileBroker::compiler_thread_loop()
# --30.58%--CompileBroker::invoke_compiler_on_method(CompileTask*)
# --30.47%--C2Compiler::compile_method(ciEnv*, ciMethod*, int, bool, DirectiveSet*)
# Compile::Compile(ciEnv*, ciMethod*, int, bool, bool, bool, bool, bool, DirectiveSet*)
# |--17.57%--Compile::Code_Gen()
# | |--12.46%--PhaseChaitin::Register_Allocate()
# | | |--2.79%--PhaseChaitin::build_ifg_physical(ResourceArea*)
# | | | --1.05%--PhaseChaitin::interfere_with_live(unsigned int, IndexSet*) [clone .part.0]
# | |--1.49%--PhaseChaitin::Split(unsigned int, ResourceArea*)
# | |--1.26%--PhaseChaitin::post_allocate_copy_removal()
تفسير:
- العملية/مؤشرات الترابط: يتم تحليل مؤشر ترابط C2 CompilerThre.
- إجمالي إستخدام وحدة المعالجة المركزية: يعد هذا مؤشر الترابط مسؤولا عن 30.61٪ من وقت وحدة المعالجة المركزية (CPU).
- سير الدالة: يبدأ مؤشر الترابط ب
start_thread ويعمل المفوضون عبر عدة طبقات. يتم قضاء الجزء الأكبر من وقت وحدة المعالجة المركزية (30.47٪) في المحول البرمجي C2Compiler::compile_method، مما يشير إلى نقطة اتصال محتملة.
إنشاء مخطط لهب
الخطوة 1: قم بإنشاء نموذج أداء من جميع وحدات المعالجة المركزية (CPU) والعمليات عبر فاصل زمني محدد (على سبيل المثال، 60 ثانية):
perf record -a -g -F 99 sleep 60
مثال الإخراج:
[ perf record: Woken up 32 times to write data ]
[ perf record: Captured and wrote 10.417 MB perf.data (67204 samples) ]
الخطوة 2: انسخ ملف perf.data هذا أو قم بنقله إلى مضيف يمكنك من خلاله تنزيل مستودع قالب Flamegraph.
الخطوة 3: تحويل ملف البيانات إلى تنسيق نصي:
perf script > data.perf
الخطوة 4: قم بنسخ مستودع GitHub FlameGraph ووضع Data.perf في هذا الدليل:
cp data.perf $PWD/FlameGraph/.
الخطوة 5: طي مسارات المكدس لمعالجة Flamegraph:
cat data.perf | ./stackcollapse-perf.pl > data.perf-folded
الخطوة 6: إنشاء ملف SVG الخاص برسم اللهب البياني:
./flamegraph.pl data.perf-folded > data.svg
ملاحظة: إذا واجهت الخطأ "يتعذر تحديد موقع open.pm في @INC" على CentOS أو RHEL، قم بتثبيت وحدة Perl المطلوبة:
yum install perl-open.noarch
الخطوة 7: افتح ملف data.svg في متصفح الويب المفضل لديك لعرض الرسم البياني المشتعل.
تصفح الرسم البياني للهب
بمجرد فتح ملف الرسم البياني على المتصفح، يمكنك التفاعل معه بنقر أي مربع لتكبير تلك الدالة ومكدس إستدعائها. يمثل طول كل مربع مقدار وقت وحدة المعالجة المركزية (CPU) المستغرق في هذه الوظيفة ومكدس الاستدعاءات الخاص بها. يجعل هذا التصور من السهل تحديد النقاط الساخنة والمناطق التي تحتاج إلى تحسين.
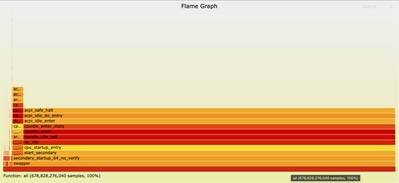
تم التكبير في ncs.smp:

معلومات ذات صلة
 التعليقات
التعليقات