- Cisco Industrial Ethernet 4000、4010、および 5000 スイッチ ソフトウェア コンフィギュレーション ガイド
- Contents
- はじめに
- 設定の概要
- コマンドライン インターフェイスの使用
- インターフェイスの設定
- スイッチ アラームの設定
- スイッチ セットアップの設定
- Cisco IOS Configuration Engine の設定
- スイッチ クラスタの設定
- スイッチ管理の実行
- PTP の設定
- PROFINET の設定
- CIP の設定
- SDM テンプレートの設定
- スイッチ ベース認証の設定
- IEEE 802.1x ポートベース認証の設定
- MACsec
- Web ベース認証の設定
- SmartPort マクロの設定
- SGACL モニタモードおよび SGACL ロギングの設定
- SGT 交換プロトコル over TCP(SXP)およびレイヤ 3 トランスポートの設定
- VLAN の設定
- VTP の設定
- 音声 VLAN の設定
- STP の設定
- MSTP の設定
- オプションのスパニングツリー機能の設定
- Resilient Ethernet Protocol の設定
- FlexLink および MAC アドレス テーブル移動更新の設定
- DHCP の設定
- ダイナミック ARP インスペクション(DAI)の設定
- IP ソース ガードの設定
- IGMP スヌーピングおよび MVR の設定
- ポート単位のトラフィック制御の設定
- SPAN および RSPAN の設定
- LLDP、LLDP-MED、およびワイヤード ロケーション サービスの設定
- レイヤ 2 NAT の設定
- CDP の設定
- UDLD の設定
- RMON の設定
- システム メッセージ ロギングの設定
- SNMP の設定
- ACL によるネットワーク セキュリティの設定
- QoS の設定
- スタティック IP ユニキャスト ルーティングの設定
- IPv6 ホスト機能の設定
- リンク ステート トラッキングの設定
- IP マルチキャスト ルーティングの設定
- MSDP の設定
- IPv6 MLD スヌーピングの設定
- HSRP および VRRP の設定
- IPv6 ACL の設定
- Embedded Event Manager の設定
- IP ユニキャスト ルーティングの設定
- IPv6 ユニキャスト ルーティングの設定
- ユニキャストの概要
- Cisco IOS IP SLA 動作の設定
- Dying Gasp
- 拡張オブジェクト トラッキングの設定
- MODBUS TCP の設定
- イーサネット CFM
- Cisco IOS ファイル システム、コンフィギュレーション ファイル、およびソフトウェア イメージの操作
- EtherChannel の設定
- トラブルシューティング
- SD カードの使用
Cisco Industrial Ethernet 4000、4010、および 5000 スイッチ ソフトウェア コンフィギュレーション ガイド
偏向のない言語
この製品のマニュアルセットは、偏向のない言語を使用するように配慮されています。このマニュアルセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザーインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブランゲージに対する取り組みの詳細は、こちらをご覧ください。
翻訳について
このドキュメントは、米国シスコ発行ドキュメントの参考和訳です。リンク情報につきましては、日本語版掲載時点で、英語版にアップデートがあり、リンク先のページが移動/変更されている場合がありますことをご了承ください。あくまでも参考和訳となりますので、正式な内容については米国サイトのドキュメントを参照ください。
- Updated:
- 2020年8月20日木曜日
章のタイトル: IP ユニキャスト ルーティングの設定
- IP ルーティングに関する情報
- 前提条件
- 注意事項と制約事項
- IP アドレス指定の設定
- IPv4 ユニキャスト ルーティングのイネーブル化
- RIP の設定
- OSPF の設定
- EIGRP の設定
- BGP の設定
- ISO CLNS ルーティングの設定
- BFD の設定
IP ユニキャスト ルーティングの設定
この章では、シスコの産業用イーサネットスイッチ(以降、スイッチと呼びます)で IP バージョン 4 (IPv4) ユニキャストルーティングを設定する方法について説明します。
注: ダイナミック ルーティング プロトコルは、IP サービスフィーチャセットを実行しているスイッチでのみサポートされています。スタティックルーティングは、Lan Base フィーチャセットでサポートされています。
IPv4 ユニキャスト設定の詳細、およびこの章で使用するコマンドの構文および使用方法については、関連資料に記載されているマニュアルを参照してください。
■![]() 前提条件
前提条件
■![]() 関連資料
関連資料
IP ルーティングに関する情報
IP ネットワークで、各サブネットワークは 1 つの VLAN に対応しています。ただし、異なる VLAN 内のネットワーク デバイスが相互に通信するには、VLAN 間でトラフィックをルーティング(VLAN 間ルーティング)するレイヤ 3 デバイス(ルータ)が必要です。VLAN 間ルーティングでは、適切な宛先 VLAN にトラフィックをルーティングするため、1 つまたは複数のルータを設定します。
図 99に基本的なルーティング トポロジを示します。スイッチ A は VLAN 10 内、スイッチ B は VLAN 20 内にあります。ルータには各 VLAN のインターフェイスが備わっています。
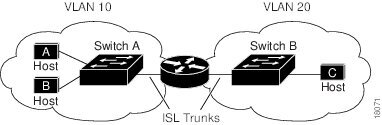
VLAN 10 内のホスト A が VLAN 10 内のホスト B と通信する場合、ホスト A はホスト B 宛にアドレス指定されたパケットを送信します。スイッチ A はパケットをルータに送信せず、ホスト B に直接転送します。
ホスト A から VLAN 20 内のホスト C にパケットを送信する場合、スイッチ A はパケットをルータに転送し、ルータは VLAN 10 インターフェイスでトラフィックを受信します。ルータはルーティング テーブルを調べて正しい発信インターフェイスを判別し、VLAN 20 インターフェイスを経由してパケットをスイッチ B に送信します。スイッチ B はパケットを受信し、ホスト C に転送します。
ルーティング タイプ
ルータおよびレイヤ 3 スイッチは、次の方法でパケットをルーティングできます。
■![]() デフォルト ルーティングを使用する(ルータにとって宛先が不明なトラフィックをデフォルトの出口または宛先に送信する)
デフォルト ルーティングを使用する(ルータにとって宛先が不明なトラフィックをデフォルトの出口または宛先に送信する)
■![]() 事前にプログラミングされているトラフィックのスタティック ルートの使用
事前にプログラミングされているトラフィックのスタティック ルートの使用
スタティック ユニキャスト ルーティングの場合、パケットは事前に設定されたポートから単一のパスを通り、ネットワークの内部または外部に転送されます。スタティック ルーティングはネットワークの変更には自動的に対応しないため、パケットが宛先に到達しないことがあります。
ルータでは、トラフィックを転送する最適ルートを動的に計算するため、ダイナミック ルーティング プロトコルが使用されます。スイッチによってサポートされるルーティング プロトコルには、ルーティング情報プロトコル(RIP)、ボーダー ゲートウェイ プロトコル(BGP)、Open Shortest Path First(OSPF)プロトコル、Enhanced IGRP(EIGRP)、Intermediate System-to-Intermediate System(IS-IS)、および双方向フォワーディング検出(BFD)があります。
前提条件
■![]() ダイナミック ルーティング プロトコルを使用するには、IP サービスライセンスが必要です。
ダイナミック ルーティング プロトコルを使用するには、IP サービスライセンスが必要です。
■![]() VLAN インターフェイスをサポートするために、スイッチで VLAN を作成および設定し、レイヤ 2 インターフェイスに VLAN メンバーシップを割り当てます。
VLAN インターフェイスをサポートするために、スイッチで VLAN を作成および設定し、レイヤ 2 インターフェイスに VLAN メンバーシップを割り当てます。
■![]() デフォルトでは、IPv4 ルーティングはスイッチ上でディセーブルとなっています。ルーティングを行う前に、IPv4 ルーティングをイネーブルにする必要があります。IPv4 ユニキャスト ルーティングのイネーブル化を参照してください。
デフォルトでは、IPv4 ルーティングはスイッチ上でディセーブルとなっています。ルーティングを行う前に、IPv4 ルーティングをイネーブルにする必要があります。IPv4 ユニキャスト ルーティングのイネーブル化を参照してください。
■![]() 特に EIGRP を使用する場合は、ルーティング プロトコル コマンドを設定する前に、インターフェイスで BFD インターバル パラメータを設定することを推奨します。BFD の詳細については、BFD の設定を参照してください。
特に EIGRP を使用する場合は、ルーティング プロトコル コマンドを設定する前に、インターフェイスで BFD インターバル パラメータを設定することを推奨します。BFD の詳細については、BFD の設定を参照してください。
注意事項と制約事項
■![]() 以下の手順では、次に示すレイヤ 3 インターフェイスの 1 つを指定する必要があります。
以下の手順では、次に示すレイヤ 3 インターフェイスの 1 つを指定する必要があります。
–![]() ルーテッドポート: no switchport インターフェイス コンフィギュレーション コマンドを使用し、レイヤ 3 ポートとして設定された物理ポートです。
ルーテッドポート: no switchport インターフェイス コンフィギュレーション コマンドを使用し、レイヤ 3 ポートとして設定された物理ポートです。
–![]() スイッチ仮想インターフェイス(SVI): interface vlan vlan_id グローバル コンフィギュレーション コマンドによって作成された VLAN インターフェイス。デフォルトではレイヤ 3 インターフェイスです。
スイッチ仮想インターフェイス(SVI): interface vlan vlan_id グローバル コンフィギュレーション コマンドによって作成された VLAN インターフェイス。デフォルトではレイヤ 3 インターフェイスです。
–![]() レイヤ 3 モードの Etherchannel ポートチャネル: interface port-channel port- channel-number グローバル コンフィギュレーション コマンドを使用し、イーサネット インターフェイスをチャネルグループにバインドして作成されたポートチャネル論理インターフェイスです。
レイヤ 3 モードの Etherchannel ポートチャネル: interface port-channel port- channel-number グローバル コンフィギュレーション コマンドを使用し、イーサネット インターフェイスをチャネルグループにバインドして作成されたポートチャネル論理インターフェイスです。
■![]() スイッチは、ユニキャスト ルーテッド トラフィックのトンネル インターフェイスをサポートしません。
スイッチは、ユニキャスト ルーテッド トラフィックのトンネル インターフェイスをサポートしません。
■![]() ルーティングが発生するすべてのレイヤ 3 インターフェイスに、IP アドレスを割り当てる必要があります。ネットワーク インターフェイスへの IP アドレスの割り当てを参照してください。
ルーティングが発生するすべてのレイヤ 3 インターフェイスに、IP アドレスを割り当てる必要があります。ネットワーク インターフェイスへの IP アドレスの割り当てを参照してください。
■![]() スイッチは、各ルーテッド ポートおよび SVI に割り当てられた IP アドレスを持つことができます。ソフトウェアに、設定できるルーテッド ポートおよび SVI の個数制限はありません。ただし、ハードウェアによって制限されるため、設定できるルーテッド ポートおよび SVI の個数と、実装されている機能の組み合わせによっては、CPU 利用率が影響を受けることがあります。
スイッチは、各ルーテッド ポートおよび SVI に割り当てられた IP アドレスを持つことができます。ソフトウェアに、設定できるルーテッド ポートおよび SVI の個数制限はありません。ただし、ハードウェアによって制限されるため、設定できるルーテッド ポートおよび SVI の個数と、実装されている機能の組み合わせによっては、CPU 利用率が影響を受けることがあります。
IPv4 ルーティングをサポートするには、 sdm prefer default グローバル コンフィギュレーション コマンドを使用して Switch Database Management(sdm)機能を設定し、リソースのバランスをとるようにします。SDM テンプレートの詳細については、関連資料に記載されているコマンドリファレンスの sdm prefer コマンドを参照してください。
ルーティングを設定する手順
IPv4 ルーティングを設定するための主な手順は次のとおりです。
■![]() スイッチ上で IPv4 ルーティングをイネーブルにします。
スイッチ上で IPv4 ルーティングをイネーブルにします。
■![]() レイヤ 3 インターフェイスに IPv4 アドレスを割り当てます。
レイヤ 3 インターフェイスに IPv4 アドレスを割り当てます。
IP アドレス指定の設定
IP ルーティングでは、レイヤ 3 ネットワーク インターフェイスに IP アドレスを割り当てて、そのインターフェイスをイネーブルにし、IP を使用するインターフェイスを介してホストと通信できるようにする必要があります。ここでは、さまざまな IP アドレス指定機能の設定方法について説明します。IP アドレスをインターフェイスに割り当てる手順は必須ですが、その他の手順は任意です。
■![]() ネットワーク インターフェイスへの IP アドレスの割り当て
ネットワーク インターフェイスへの IP アドレスの割り当て
■![]() IP ルーティングがディセーブルの場合のルーティング支援機能
IP ルーティングがディセーブルの場合のルーティング支援機能
アドレス指定のデフォルト設定
|
|
|
|---|---|
ヘルパー アドレスが定義されているか、またはユーザ データグラム プロトコル(UDP)フラッディングが設定されている場合、デフォルト ポートでは UDP 転送がイネーブルとなります |
|
ネットワーク インターフェイスへの IP アドレスの割り当て
IP アドレスは IP パケットの送信先を特定します。インターフェイスには、1 つのプライマリ IP アドレスを設定できます。マスクで、IP アドレス中のネットワーク番号を示すビットが識別できます。マスクを使用してネットワークをサブネット化する場合、そのマスクをサブネット マスクと呼びます。
はじめる前に
手順の詳細
例
サブネットゼロのイネーブル化
サブネットゼロをイネーブルにすると、サブネット 0 のサブネットを設定してルーティングする機能が提供されます。
すべてが 1 のサブネット(131.108.255.0)は使用可能です。また、IP アドレス用にサブネット スペース全体が必要な場合は、サブネット ゼロの使用をイネーブルにできます(ただし推奨できません)。
はじめる前に
サブネット アドレスがゼロであるサブネットを作成しないでください。同じアドレスを持つネットワークおよびサブネットがある場合に問題が発生することがあります。たとえば、ネットワーク 131.108.0.0 のサブネットが 255.255.255.0 の場合、サブネット ゼロは 131.108.0.0 と記述され、ネットワーク アドレスと同じとなってしまいます。
手順の詳細
|
|
|
|
|---|---|---|
デフォルトに戻して、サブネット ゼロの使用をディセーブルにするには、 no ip subnet-zero グローバル コンフィギュレーション コマンドを使用します。
例
クラスレス ルーティング
ルーティングを行うように設定されたスイッチで、クラスレス ルーティング動作はデフォルトでイネーブルとなっています。クラスレス ルーティングがイネーブルの場合、デフォルト ルートがないネットワークのサブネット宛てパケットをルータが受信すると、ルータは最適なスーパーネット ルートにパケットを転送します。スーパーネットは、単一の大規模アドレス空間をシミュレートするために使用されるクラス C アドレス空間の連続ブロックで構成されています。スーパーネットは、クラス B アドレス空間の急速な枯渇を回避するために設計されました。
図 100では、クラスレス ルーティングがイネーブルとなっています。ホストがパケットを 128.20.4.1 に送信すると、ルータはパケットを廃棄せずに、最適なスーパーネット ルートに転送します。クラスレス ルーティングがディセーブルの場合、デフォルト ルートがないネットワークのサブネット宛てパケットを受信したルータは、パケットを廃棄します。
図 100 IP クラスレス ルーティングがイネーブルの場合
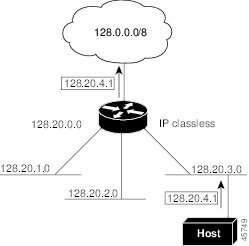
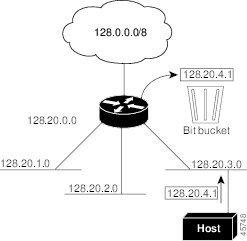
図 101では、ネットワーク 128.20.0.0 のルータはサブネット 128.20.1.0、128.20.2.0、128.20.3.0 に接続されています。ホストがパケットを 128.20.4.1 に送信した場合、ネットワークのデフォルト ルートが存在しないため、ルータはパケットを廃棄します。
図 101 IP クラスレス ルーティングがディセーブルの場合
認識されないサブネット宛てのパケットが最適なスーパーネット ルートに転送されないようにするには、クラスレス ルーティング動作をディセーブルにします。
はじめる前に
「IP ルーティングに関する情報」を確認してください。
手順の詳細
|
|
|
|
|---|---|---|
デフォルトに戻して、デフォルトルートがないネットワークのサブネット宛てパケットが最適なスーパーネットルートに転送されるようにするには、 ip classless グローバル コンフィギュレーション コマンドを使用します。
例
アドレス解決方法の設定
インターフェイス固有の IP 処理方法を制御するには、アドレス解決を行います。IP を使用するデバイスには、ローカル セグメントまたは LAN 上のデバイスを一意に定義するローカル アドレス(MAC アドレス)と、デバイスが属するネットワークを特定するネットワーク アドレスがあります。ソフトウェアがイーサネット上のデバイスと通信するには、デバイスの MAC アドレスを学習する必要があります。IP アドレスから MAC アドレスを学習するプロセスを、アドレス解決と呼びます。 MAC アドレスから IP アドレスを学習するプロセスを、 逆アドレス解決 と呼びます。
■![]() ARP:IP アドレスを MAC アドレスと関連付けるために使用されます。ARP は IP アドレスを入力と解釈し、対応する MAC アドレスを学習します。次に、IP アドレス/MAC アドレス アソシエーションを ARP キャッシュにストアし、すぐに取り出せるようにします。その後、IP データグラムがリンク層フレームにカプセル化され、ネットワークを通じて送信されます。イーサネット以外の IEEE 802 ネットワークにおける IP データグラムのカプセル化、および ARP 要求や応答については、サブネットワーク アクセス プロトコル(SNAP)で規定されています。
ARP:IP アドレスを MAC アドレスと関連付けるために使用されます。ARP は IP アドレスを入力と解釈し、対応する MAC アドレスを学習します。次に、IP アドレス/MAC アドレス アソシエーションを ARP キャッシュにストアし、すぐに取り出せるようにします。その後、IP データグラムがリンク層フレームにカプセル化され、ネットワークを通じて送信されます。イーサネット以外の IEEE 802 ネットワークにおける IP データグラムのカプセル化、および ARP 要求や応答については、サブネットワーク アクセス プロトコル(SNAP)で規定されています。
■![]() プロキシ ARP:ルーティング テーブルを持たないホストで、他のネットワークまたはサブネット上のホストの MAC アドレスを学習できるようにします。スイッチ(ルータ)が送信元と異なるインターフェイス上のホストに宛てた ARP 要求を受信した場合、そのルータに他のインターフェイスを経由してそのホストに至るすべてのルートが格納されていれば、ルータは自身のローカル データ リンク アドレスを示すプロキシ ARP パケットを生成します。ARP 要求を送信したホストはルータにパケットを送信し、ルータはパケットを目的のホストに転送します。
プロキシ ARP:ルーティング テーブルを持たないホストで、他のネットワークまたはサブネット上のホストの MAC アドレスを学習できるようにします。スイッチ(ルータ)が送信元と異なるインターフェイス上のホストに宛てた ARP 要求を受信した場合、そのルータに他のインターフェイスを経由してそのホストに至るすべてのルートが格納されていれば、ルータは自身のローカル データ リンク アドレスを示すプロキシ ARP パケットを生成します。ARP 要求を送信したホストはルータにパケットを送信し、ルータはパケットを目的のホストに転送します。
スイッチでは、ARP と同様の機能(ローカル MAC アドレスでなく IP アドレスを要求する点を除く)を持つ Reverse Address Resolution Protocol(RARP)を使用することもできます。RARP を使用するには、ルータ インターフェイスと同じネットワーク セグメント上に RARP サーバを設置する必要があります。サーバを識別するには、 ip rarp-server address インターフェイス コンフィギュレーション コマンドを使用します。
RARP の詳細については、『 IP Addressing: ARP Configuration Guide, Cisco IOS Release 15M&T 』を参照してください。
スタティック ARP キャッシュの定義
ARP および他のアドレス解決プロトコルを使用すると、IP アドレスと MAC アドレス間をダイナミックにマッピングできます。ほとんどのホストではダイナミック アドレス解決がサポートされているため、通常の場合、スタティック ARP キャッシュ エントリを指定する必要はありません。スタティック ARP キャッシュ エントリを定義する必要がある場合は、グローバルに定義できます。グローバルに定義すると、IP アドレスを MAC アドレスに変換するために使用される永続的なエントリを、ARP キャッシュに確保できます。また、指定された IP アドレスがスイッチに属する場合と同じ方法で、スイッチが ARP 要求に応答するように指定することもできます。ARP エントリを永続的なエントリにしない場合は、ARP エントリのタイムアウト期間を指定できます。
はじめる前に
「アドレス解決方法の設定」を確認してください。
手順の詳細
ARP キャッシュからエントリを削除するには、 no arp ip-address hardware-address type グローバル コンフィギュレーション コマンドを使用します。ARP キャッシュから非スタティックエントリをすべて削除するには、 clear arp-cache 特権 EXEC コマンドを使用します。
例
ARP のカプセル化の設定
IP インターフェイスでは、イーサネット ARP カプセル化( arpa キーワードで表される)がデフォルトでイネーブルに設定されています。ネットワークの必要性に応じて、カプセル化方法を SNAP に変更できます。
はじめる前に
この手順で指定するカプセル化の種類は、スタティック ARP キャッシュの定義で指定されたカプセル化の種類と一致している必要があります。
手順の詳細
|
|
|
|
|---|---|---|
必要に応じて、インターフェイスをイネーブルにします。デフォルトでは、UNI と ENI はディセーブルに、NNI はイネーブルに設定されています。 |
||
カプセル化タイプをディセーブルにするには、 no arp arpa または no arp snap インターフェイス コンフィギュレーション コマンドを使用します。
例
プロキシ ARP のイネーブル化
デフォルトでは、プロキシ ARP が使用されます。ホストが他のネットワークまたはサブネット上のホストの MAC アドレスを学習できるようにするためです。ディセーブルになっているプロキシ ARP をイネーブルにするには、次の手順を実行します。
はじめる前に
「アドレス解決方法の設定」を確認してください。
手順の詳細
|
|
|
|
|---|---|---|
必要に応じて、インターフェイスをイネーブルにします。デフォルトでは、UNI と ENI はディセーブルに、NNI はイネーブルに設定されています。 |
||
インターフェイスでプロキシ ARP をディセーブルにするには、 no ip proxy-arp インターフェイス コンフィギュレーション コマンドを使用します。
例
IP ルーティングがディセーブルの場合のルーティング支援機能
次のメカニズムを使用することで、スイッチは IP ルーティングがイネーブルでない場合、別のネットワークへのルートを学習できます。
プロキシ ARP
プロキシ ARP は、他のルートを学習する場合の最も一般的な方法です。プロキシ ARP を使用すると、ルーティング情報を持たないイーサネットホストと、他のネットワークまたはサブネット上のホストとの通信が可能になります。このホストでは、すべてのホストが同じローカルイーサネット上にあり、ARP を使用して MAC アドレスを学習すると想定されています。送信元と異なるネットワーク上にあるホストに宛てた ARP 要求を受信したスイッチは、そのホストへの最適なルートがあるかどうかを調べます。最適なルートがある場合、スイッチはスイッチ自身のイーサネット MAC アドレスが格納された ARP 応答パケットを送信します。要求の送信元ホストはパケットをスイッチに送信し、スイッチは目的のホストにパケットを転送します。プロキシ ARP は、すべてのネットワークをローカルな場合と同様に処理し、IP アドレスごとに ARP 処理を実行します。
プロキシ ARP は、デフォルトでイネーブルに設定されています。ディセーブルになった後にイネーブルにするには、プロキシ ARP のイネーブル化を参照してください。プロキシ ARP は、他のルータでサポートされているかぎり有効です。
デフォルト ゲートウェイ
ルートを特定するもう 1 つの方法は、デフォルト ルータ、つまりデフォルト ゲートウェイを定義する方法です。ローカルでないすべてのパケットはこのルータに送信されます。このルータは適切なルーティングを行う、またはインターネット制御メッセージ プロトコル(ICMP)リダイレクト メッセージを返信するという方法で、ホストが使用するローカル ルータを定義します。スイッチはリダイレクト メッセージをキャッシュに格納し、各パケットをできるだけ効率的に転送します。この方法には、デフォルト ルータがダウンした場合、または使用できなくなった場合に、検出が不可能となる制限があります。
手順の詳細
|
|
|
|
|---|---|---|
この機能をディセーブルにするには、 no ip default-gateway グローバル コンフィギュレーション コマンドを使用します。
例
ICMP Router Discovery Protocol(IRDP)
ルータ ディスカバリを使用すると、スイッチは IRDP を使用し、他のネットワークへのルートを動的に学習します。ホストは IRDP を使用し、ルータを特定します。クライアントとして動作しているスイッチは、ルータ ディスカバリ パケットを生成します。ホストとして動作しているスイッチは、ルータ ディスカバリ パケットを受信します。スイッチはルーティング情報プロトコル(RIP)ルーティングのアップデートを受信し、この情報を使用してルータの場所を推測することもできます。実際のところ、ルーティング デバイスによって送信されたルーティング テーブルは、スイッチにストアされません。どのシステムがデータを送信しているのかが記録されるだけです。IRDP を使用する利点は、プライオリティと、パケットが受信されなくなってからデバイスがダウンしていると見なされるまでの期間の両方をルータごとに指定できることです。
検出された各デバイスは、デフォルト ルータの候補となります。現在のデフォルト ルータがダウンしたと宣言された場合、または再送信が多すぎて TCP 接続がタイムアウトになりつつある場合、プライオリティが上位のルータが検出されると、最も高いプライオリティを持つ新しいルータが選択されます。
インターフェイスで IRDP ルーティングを行う場合は、インターフェイスで IRDP 処理をイネーブルにしてください。IRDP 処理をイネーブルにすると、デフォルトのパラメータが適用されます。これらのパラメータを変更することもできます。
はじめる前に
■![]() ip irdp multicast コマンドを使用すると、IRDP パケットをマルチキャストとして送信するサンマイクロシステムズ社の Solaris との互換性を維持できます。実装機能の中には、これらのマルチキャストを受信できないものも多くあります。このコマンドを使用する前に、エンドホストがこの機能に対応していることを確認してください。
ip irdp multicast コマンドを使用すると、IRDP パケットをマルチキャストとして送信するサンマイクロシステムズ社の Solaris との互換性を維持できます。実装機能の中には、これらのマルチキャストを受信できないものも多くあります。このコマンドを使用する前に、エンドホストがこの機能に対応していることを確認してください。
■![]() maxadvertinterval 値を変更すると、 holdtime 値および minadvertinterval 値も変更されます。最初に maxadvertinterval 値を変更し、次に holdtime 値または minadvertinterval 値のいずれかを手動で変更することが重要です。
maxadvertinterval 値を変更すると、 holdtime 値および minadvertinterval 値も変更されます。最初に maxadvertinterval 値を変更し、次に holdtime 値または minadvertinterval 値のいずれかを手動で変更することが重要です。
手順の詳細
IRDP ルーティングをディセーブルにするには、 no ip irdp インターフェイス コンフィギュレーション コマンドを使用します。
例
ブロードキャスト パケットの処理方法の設定
IP インターフェイス アドレスを設定したあとで、ルーティングをイネーブルにしたり、1 つまたは複数のルーティング プロトコルを設定したり、ネットワーク ブロードキャストへのスイッチの応答方法を設定したりできます。ブロードキャストは、物理ネットワーク上のすべてのホスト宛てのデータ パケットです。2 種類のブロードキャストがサポートされています。
■![]() ダイレクト ブロードキャスト パケット:特定のネットワークまたは一連のネットワークに送信されます。ダイレクト ブロードキャスト アドレスには、ネットワークまたはサブネット フィールドが含まれます。
ダイレクト ブロードキャスト パケット:特定のネットワークまたは一連のネットワークに送信されます。ダイレクト ブロードキャスト アドレスには、ネットワークまたはサブネット フィールドが含まれます。
■![]() フラッディング ブロードキャスト パケット:すべてのネットワークに送信されます。
フラッディング ブロードキャスト パケット:すべてのネットワークに送信されます。
注: storm-control インターフェイス コンフィギュレーション コマンドを使用して、トラフィック抑制レベルを設定し、レイヤ 2 インターフェイスでブロードキャスト、ユニキャスト、マルチキャストトラフィックを制限することもできます。
ルータはローカル ケーブルまでの範囲を制限して、ブロードキャスト ストームを防ぎます。ブリッジ(インテリジェントなブリッジを含む)はレイヤ 2 デバイスであるため、ブロードキャストはすべてのネットワーク セグメントに転送され、ブロードキャスト ストームを伝播します。ブロードキャスト ストーム問題を解決する最善の方法は、ネットワーク上で単一のブロードキャスト アドレス方式を使用することです。最新の IP 実装機能ではほとんどの場合、アドレスをブロードキャスト アドレスとして使用するように設定できます。スイッチでは、ブロードキャスト メッセージの転送用として複数のアドレス指定スキームがサポートされています。
ダイレクト ブロードキャストから物理ブロードキャストへの変換のイネーブル化
サービス拒絶攻撃からルータを極力保護するため、デフォルトでは、IP ダイレクト ブロードキャストは転送されず廃棄されます。ブロードキャストが物理(MAC レイヤ)ブロードキャストになるインターフェイスでは、IP ダイレクト ブロードキャストの転送をイネーブルにできます。 ip forward-protocol グローバル コンフィギュレーション コマンドを使用し、設定されたプロトコルだけを転送できます。
はじめる前に
転送するブロードキャストを制御するアクセス リストを指定できます。アクセス リストで許可されている IP パケットに限り、指定ブロードキャストから物理ブロードキャストに変換できるようになります。
手順の詳細
ダイレクト ブロードキャストから物理ブロードキャストへの変換をディセーブルにするには、 no ip directed-broadcast インターフェイス コンフィギュレーション コマンドを使用します。プロトコルまたはポートを削除するには、 no ip forward-protocol グローバル コンフィギュレーション コマンドを使用します。
例
次に、イーサネット インターフェイス 0 上で IP ダイレクト ブロードキャストの転送をイネーブルにする例を示します。ポート番号を指定せずに udp キーワードを使用する ip forward-protocol コマンドは、デフォルトポートでの UDP パケットの転送を可能にします。
UDP ブロードキャスト パケットおよびプロトコルの転送
ユーザ データグラム プロトコル(UDP)は、2 つのエンド システム間でオーバーヘッドの少ないコネクションレス型セッションを実現する IP ホストツーホスト レイヤ プロトコルです。UDP では、受信したデータグラムの確認応答は行われません。場合に応じてネットワーク ホストは UDP ブロードキャストを使用し、アドレス、コンフィギュレーション、名前に関する情報を検索します。このようなホストが、サーバを含まないネットワーク セグメント上にある場合、通常 UDP ブロードキャストは転送されません。ルータ上では、特定のクラスのブロードキャストがヘルパー アドレスへ転送されるように、インターフェイスを設定できます。インターフェイスごとに、複数のヘルパー アドレスを使用できます。
UDP 宛先ポートを指定すると、転送される UDP サービスを制御できます。複数の UDP プロトコルを指定することもできます。旧式のディスクレス Sun ワークステーションおよびネットワーク セキュリティ プロトコル SDNS で使用される Network Disk(ND)プロトコルも指定できます。
ヘルパー アドレスがインターフェイスに定義されている場合、デフォルトでは UDP と ND の両方の転送がイネーブルになっています。
UDP ブロードキャストの転送を設定するときに UDP ポートを指定しないと、ルータは BOOTP フォワーディング エージェントとして動作するように設定されます。BOOTP パケットは Dynamic Host Configuration Protocol(DHCP)情報を伝達します。
はじめる前に
UDP ポートを指定しない場合にデフォルトで転送されるポートのリストについては、『 Cisco IOS IP Application Services Command Reference 』の ip forward-protocol インターフェイス コンフィギュレーション コマンドの説明を参照してください。
手順の詳細
|
|
|
|
|---|---|---|
必要に応じて、インターフェイスをイネーブルにします。デフォルトでは、UNI と ENI はディセーブルに、NNI はイネーブルに設定されています。 |
||
特定アドレスへのブロードキャスト パケットの転送をディセーブルにするには、 no ip helper-address インターフェイス コンフィギュレーション コマンドを使用します。プロトコルまたはポートを削除するには、 no ip forward-protocol グローバル コンフィギュレーション コマンドを使用します。
例
次の例では、ヘルパーアドレスを定義し、ip forward-protocol コマンドを使用します。ポート番号を指定せずに udp キーワードを使用すると、デフォルトポートでの UDP パケットの転送を可能にします。
IP ブロードキャスト アドレスの確立
最も一般的な(デフォルトの)IP ブロードキャスト アドレスは、すべて 1 で構成されているアドレス(255.255.255.255)です。ただし、任意の形式の IP ブロードキャスト アドレスを生成するようにスイッチを設定することもできます。
手順の詳細
|
|
|
|
|---|---|---|
必要に応じて、インターフェイスをイネーブルにします。デフォルトでは、UNI と ENI はディセーブルに、NNI はイネーブルに設定されています。 |
||
デフォルトの IP ブロードキャスト アドレスに戻すには、 no ip broadcast-address インターフェイス コンフィギュレーション コマンドを使用します。
例
次の例では、IP ブロードキャスト アドレス 0.0.0.0 を指定する方法を示します。
IP ブロードキャストのフラッディング
IP ブロードキャストをインターネットワーク全体に、制御可能な方法でフラッディングできるようにするには、ブリッジング STP で作成されたデータベースを使用します。この機能を使用すると、ループを回避することもできます。この機能を使用できるようにするには、フラッディングが行われるインターフェイスごとにブリッジングを設定する必要があります。ブリッジングが設定されていないインターフェイスでは、ブロードキャストを受信できますが、受信したブロードキャストは転送できません。また同じルータのある別のインターフェイス上で受信されたブロードキャストが、そのインターフェイスを介して送信されることもありません。
IP ヘルパー アドレスのメカニズムを使用して単一のネットワーク アドレスに転送されるパケットを、フラッディングできます。各ネットワーク セグメントには、パケットのコピーが 1 つだけ送信されます。
フラッディングを行う場合、パケットは次の条件を満たす必要があります(これらの条件は、IP ヘルパー アドレスを使用してパケットを転送するときの条件と同じです)。
■![]() パケットは MAC レベルのブロードキャストでなければなりません。
パケットは MAC レベルのブロードキャストでなければなりません。
■![]() パケットは IP レベルのブロードキャストでなければなりません。
パケットは IP レベルのブロードキャストでなければなりません。
■![]() パケットは Trivial File Transfer Protocol(TFTP)、ドメイン ネーム システム(DNS)、Time、NetBIOS、ND、または BOOTP パケット、または ip forward-protocol udp グローバル コンフィギュレーション コマンドで指定された UDP でなければなりません。
パケットは Trivial File Transfer Protocol(TFTP)、ドメイン ネーム システム(DNS)、Time、NetBIOS、ND、または BOOTP パケット、または ip forward-protocol udp グローバル コンフィギュレーション コマンドで指定された UDP でなければなりません。
■![]() Time To Live(TTL)値が 2 以上であること。
Time To Live(TTL)値が 2 以上であること。
フラッディングされた UDP データグラムには、出力インターフェイスで ip broadcast-address インターフェイス コンフィギュレーション コマンドによって指定された宛先アドレスが表示されます。宛先アドレスは、任意のアドレスに設定できるため、データグラムがネットワーク上を伝播していくのに伴って変更されることもあります。送信元アドレスは変更されません。TTL 値が減ります。
フラッディングされた UDP データグラムがインターフェイスから送信されると(場合によっては宛先アドレスが変更される)、データグラムは通常の IP 出力ルーチンに渡されます。このため、出力インターフェイスにアクセス リストがある場合、データグラムはその影響を受けます。
はじめる前に
手順の詳細
|
|
|
|
|---|---|---|
IP ブロードキャストのフラッディングをディセーブルにするには、 no ip forward-protocol spanning-tree グローバル コンフィギュレーション コマンドを使用します。
例
次の例では、インターネットワークを介して IP ブロードキャストを制御された方法でフラッディングすることを許可します。
STP ベースの UDP フラッディングの高速化
スイッチでは、パケットの大部分がハードウェアで転送され、スイッチの CPU を経由しません。CPU に送信されるパケットの場合は、ターボフラッディングを使用し、スパニングツリーベースの UDP フラッディングを約 4 ~ 5 倍高速化します。この機能は、ARP カプセル化用に設定されたイーサネット インターフェイスでサポートされています。
はじめる前に
IP ブロードキャストのフラッディングの説明に従って、IP ブロードキャストのフラッディングをイネーブルにします。
手順の詳細
|
|
|
|
|---|---|---|
この機能をディセーブルにするには、 no ip forward-protocol turbo-flood グローバル コンフィギュレーション コマンドを使用します。
例
次に、スパニングツリー アルゴリズムを使用して UDP パケットのフラッディングを高速化する例を示します。
IP アドレスのモニタリングおよびメンテナンス
特定のキャッシュ、テーブル、またはデータベースの内容が無効になっている場合、または無効である可能性がある場合は、 clear 特権 EXEC コマンドを使用し、すべての内容を削除できます。
|
|
|
|---|---|
IP ルーティング テーブル、キャッシュ、データベースの内容、ノードへの到達可能性、ネットワーク内のパケットのルーティング パスなど、特定の統計情報を表示できます。
|
|
|
|---|---|
デフォルトのドメイン名、検索サービスの方式、サーバ ホスト名、およびキャッシュに格納されているホスト名とアドレスのリストを表示します。 |
|
IPv4 ユニキャスト ルーティングのイネーブル化
デフォルトで、スイッチはレイヤ 2 スイッチング モード、IP ルーティングはディセーブルとなっています。スイッチのレイヤ 3 機能を使用するには、IP ルーティングをイネーブルにする必要があります。
はじめる前に
「注意事項と制約事項」を確認してください。
手順の詳細
|
|
|
|
|---|---|---|
IP ルーティング プロトコルを指定します。このステップでは、他のコマンドを実行することもできます。たとえば、 network (RIP)ルータ コンフィギュレーション コマンドを使用し、ルーティングするネットワークを指定できます。具体的なプロトコルの詳細については、この章の後半を参照してください。 |
||
ルーティングをディセーブルにするには、 no ip routing グローバル コンフィギュレーション コマンドを使用します。
例
次に、ルーティング プロトコルとして RIP を使用し、IP ルーティングをイネーブルにする例を示します。
RIP の設定
RIP は、小規模な同種ネットワーク間で使用される Interior Gateway Protocol(IGP)です。RIP は、ブロードキャスト ユーザ データグラム プロトコル(UDP)データ パケットを使用してルーティング情報を交換するディスタンスベクトル ルーティング プロトコルです。RIP の詳細については、『 IP Routing Fundamentals 』(Cisco Press 刊)を参照してください。
スイッチは RIP を使用し、30 秒ごとにルーティング情報アップデート(アドバタイズメント)を送信します。180 秒以上を経過しても別のルータからアップデートがルータに届かない場合、該当するルータから送られたルートは使用不能としてマークされます。240 秒後もまだ更新がない場合、ルータは更新のないルータのルーティング テーブル エントリをすべて削除します。
RIP では、各ルートの値を評価するためにホップ カウントが使用されます。ホップ カウントは、ルート内で経由されるルータ数です。直接接続されているネットワークのホップ カウントは 0 です。ホップ カウントが 16 のネットワークに到達できません。このように範囲(0 ~ 15)が狭いため、RIP は大規模ネットワークには適していません。
ルータにデフォルトのネットワーク パスが設定されている場合、RIP はルータを疑似ネットワーク 0.0.0.0 にリンクするルートをアドバタイズします。0.0.0.0 は、実在するネットワークではありませんが、RIP では、デフォルトのルーティング機能を実行するためのネットワークとして扱われます。デフォルト ネットワークが RIP によって取得された場合、またはルータが最終ゲートウェイで、RIP がデフォルト メトリックによって設定されている場合、スイッチはデフォルト ネットワークをアドバタイズします。RIP は指定されたネットワーク内のインターフェイスにアップデートを送信します。インターフェイスのネットワークを指定しなければ、RIP のアップデート中にアドバタイズされません。
RIP のデフォルト設定
|
|
|
|---|---|
基本的な RIP パラメータの設定
RIP を設定するには、ネットワークに対して RIP ルーティングをイネーブルにします。他のパラメータを設定することもできます。RIP コンフィギュレーション コマンドは、ネットワーク番号を設定するまで無視されます。
はじめる前に
ご使用のネットワークに対する RIP ネットワーク戦略と計画を完成させます。たとえば、RIP バージョン 1 または RIP バージョン 2 のパケットのみを送受信するかどうか、および RIP 認証を使用するかどうかを決定する必要があります(RIP バージョン 1 は認証をサポートしていません)。
手順の詳細
RIP ルーティング プロセスをオフにするには、 no router rip グローバル コンフィギュレーション コマンドを使用します。
アクティブなルーティング プロトコル プロセスのパラメータと現在のステートを表示するには、 show ip protocols 特権 EXEC コマンドを使用します。RIP データベースのサマリー アドレス エントリを表示するには、 show ip rip database 特権 EXEC コマンドを使用します。
例
次に、イーサネット インターフェイス 1 を除く、ネットワーク 10.108.0.0 上のすべてのインターフェイスに対して RIP アップデートを送信する例を示します。ただし、この例では、ネイバー ルータ コンフィギュレーション コマンドが含まれています。このコマンドは、特定のネイバーへのルーティングアップデートの送信を許可します。1 つのネイバーにつきルーティングアップデートのコピーが 1 つ生成されます。
RIP 認証の設定
RIP バージョン 1 では、認証がサポートされていません。RIP バージョン 2 のパケットを送受信する場合は、インターフェイスで RIP 認証をイネーブルにできます。インターフェイスで使用できる一連のキーは、キー チェーンによって指定されます。キー チェーンが設定されていないと、デフォルトの場合でも認証は実行されません。認証キーの管理に記載されている作業も実行してください。
RIP 認証がイネーブルであるインターフェイスでは、プレーン テキストと MD5 という 2 つの認証モードがサポートされています。デフォルトはプレーン テキストです。
はじめる前に
基本的な RIP パラメータの設定の説明に従って、RIP を設定します。
手順の詳細
|
|
|
|
|---|---|---|
必要に応じて、インターフェイスをイネーブルにします。デフォルトでは、UNI と ENI はディセーブルに、NNI はイネーブルに設定されています。 |
||
クリア テキスト認証に戻すには、 no ip rip authentication mode インターフェイス コンフィギュレーション コマンドを使用します。認証を禁止するには、 no ip rip authentication key-chain インターフェイス コンフィギュレーション コマンドを使用します。
例
次の例では、trees という名前のキーチェーンに属する任意のキーを受け入れて送信するようにインターフェイスを設定し、MD5 認証を使用するようにインターフェイスを設定します。
スプリット ホライズンの設定
ブロードキャストタイプの IP ネットワークに接続され、ディスタンスベクトル ルーティング プロトコルを使用するルータでは、通常ルーティング ループの発生を抑えるために、スプリット ホライズン メカニズムが使用されます。スプリット ホライズンは、ルートに関する情報の発信元であるインターフェイス上の、ルータによって、その情報がアドバタイズされないようにします。この機能を使用すると、リンクが壊れている場合に複数のルータ間通信が最適化されます。
はじめる前に
ルートが適切にアドバタイズされるようアプリケーションでスプリットホライズンをディセーブルにすることが必要である場合を除いて、通常はこの機能をディセーブルにしないでください。
手順の詳細
|
|
|
|
|---|---|---|
必要に応じて、インターフェイスをイネーブルにします。デフォルトでは、UNI と ENI はディセーブルに、NNI はイネーブルに設定されています。 |
||
スプリット ホライズン メカニズムをイネーブルにするには、 ip split-horizon インターフェイス コンフィギュレーション コマンドを使用します。
例
次に、シリアルリンクでスプリットホライズンをディセーブルにする単純な例を示します。
サマリー アドレスの設定
ダイヤルアップクライアント用のネットワークアクセスサーバで、サマライズされたローカルな IP アドレスプールがアドバタイズされるように、RIP が実行されているインターフェイスを設定するには、 ip summary-address rip インターフェイス コンフィギュレーション コマンドを使用します。
注: スプリットホライズンがイネーブルの場合、自動サマリーとインターフェイス IP サマリーアドレスはともにアドバタイズされません。
はじめる前に
インターフェイスがレイヤ 2 モード(デフォルト)の場合は、 no switchport インターフェイス コンフィギュレーション コマンドを入力してから、 ip address インターフェイス コンフィギュレーション コマンドを入力する必要があります。
手順の詳細
|
|
|
|
|---|---|---|
必要に応じて、インターフェイスをイネーブルにします。デフォルトでは、UNI と ENI はディセーブルに、NNI はイネーブルに設定されています。 |
||
IP サマライズをディセーブルにするには、 no ip summary-address rip ルータ コンフィギュレーション コマンドを使用します。
例
次の例では、主要ネットは 10.0.0.0 です。自動サマリー アドレス 10.0.0.0 はサマリー アドレス 10.2.0.0 によって上書きされるため、10.2.0.0 はインターフェイス ギガビット イーサネット ポート 2 からアドバタイズされますが、10.0.0.0 はアドバタイズされません。
OSPF の設定
OSPF は IP ネットワーク専用の IGP で、IP サブネット化、および外部から取得したルーティング情報のタギングをサポートしています。OSPF を使用するとパケット認証も可能になり、パケットを送受信するときに IP マルチキャストが使用されます。
ここでは OSPF の設定方法について簡単に説明します。OSPF コマンドの詳細については、関連資料に記載されている OSPF のドキュメントを参照してください。
注: OSPF では、各メディアがブロードキャスト ネットワーク、非ブロードキャスト マルチアクセス(NBMA)ネットワーク、ポイントツーポイント ネットワークに分類されます。ブロードキャスト ネットワークと非ブロードキャスト ネットワークは、ポイントツーマルチポイント ネットワークとして設定することもできます。スイッチでは、これらすべてのネットワーク タイプがサポートされています。
シスコの実装は、次の主要機能を含む OSPF バージョン 2 仕様に準拠します。
■![]() 任意の IP ルーティング プロトコルによって取得されたルートは、別の IP ルーティング プロトコルに再配信されます。つまり、ドメイン内レベルで、OSPF は EIGRP および RIP によって取得したルートを取り込むことができます。OSPF ルートを RIP に伝達することもできます。
任意の IP ルーティング プロトコルによって取得されたルートは、別の IP ルーティング プロトコルに再配信されます。つまり、ドメイン内レベルで、OSPF は EIGRP および RIP によって取得したルートを取り込むことができます。OSPF ルートを RIP に伝達することもできます。
■![]() エリア内の隣接ルータ間でのプレーン テキスト認証および MD5 認証がサポートされています。
エリア内の隣接ルータ間でのプレーン テキスト認証および MD5 認証がサポートされています。
■![]() 設定可能なルーティング インターフェイス パラメータには、インターフェイス出力コスト、再送信インターバル、インターフェイス送信遅延、ルータ プライオリティ、ルータのデッド インターバルと hello インターバル、認証キーなどがあります。
設定可能なルーティング インターフェイス パラメータには、インターフェイス出力コスト、再送信インターバル、インターフェイス送信遅延、ルータ プライオリティ、ルータのデッド インターバルと hello インターバル、認証キーなどがあります。
■![]() RFC 1587 に基づく Not-So-Stubby-Area(NSSA)がサポートされています。
RFC 1587 に基づく Not-So-Stubby-Area(NSSA)がサポートされています。
通常、OSPF を使用するには、多くの内部ルータ、複数のエリアに接続されたエリア境界ルータ(ABR)、および自律システム境界ルータ(ASBR)間で調整する必要があります。 最小設定では、すべてのデフォルト パラメータ値、エリアに割り当てられたインターフェイスが使用され、認証は行われません。環境をカスタマイズする場合は、すべてのルータの設定を調整する必要があります。
OSPF のデフォルト設定
|
|
|
|---|---|
ディセーブル。イネーブルの場合、デフォルトのメトリック設定は 10 で、外部ルート タイプのデフォルトはタイプ 2 です。 |
|
dist1(エリア内のすべてのルート):110 |
|
NSF1 認識 |
イネーブル2。レイヤ 3 スイッチでは、ハードウェアやソフトウェアの変更中に、隣接する NSF 対応ルータからのパケットを転送し続けることができます。 |
|
2.OSPF NSF 認識は、IP サービスイメージを実行しているスイッチでは IPv4 に対してイネーブルになっています。 |
NSF 認識
OSPF NSF 認識機能は IP サービスイメージの IPv4 でサポートされています。隣接ルータが NSF 対応である場合、レイヤ 3 スイッチでは、ルータに障害(クラッシュ)が発生してプライマリ Route Processor(RP)がバックアップ RP によって引き継がれる間、または処理を中断させずにソフトウェア アップグレードを行うためにプライマリ RP を手動でリロードしている間、隣接ルータからパケットを転送し続けます。
この機能をディセーブルにできません。この機能の詳細については、『 High Availability Configuration Guide, Cisco IOS Release 15S 』の「 Configuring Nonstop Forwarding 」を参照してください。
基本的な OSPF パラメータの設定
OSPF をイネーブルにするには、OSPF ルーティング プロセスを作成し、ルーティング プロセスに関連付ける IP アドレスの範囲を指定して、この範囲に関連付けるエリア ID を割り当てる必要があります。
はじめる前に
ご使用のネットワークに対する OSPF ネットワーク戦略と計画を完成させます。たとえば、複数のエリアが必要かどうかを決定します。
手順の詳細
OSPF ルーティングプロセスを終了するには、 no router ospf process-id グローバル コンフィギュレーション コマンドを使用します。
例
次に、OSPF ルーティング プロセスを設定し、プロセス番号 109 を割り当てる例を示します。
OSPF インターフェイスの設定
ip ospf インターフェイス コンフィギュレーション コマンドを使用すると、インターフェイス固有の OSPF パラメータを変更できます。これらのパラメータを変更する必要はありませんが、一部のインターフェイス パラメータ(hello インターバル、デッド インターバル、認証キーなど)については、接続されたネットワーク内のすべてのルータで統一性を維持する必要があります。
はじめる前に
手順の詳細
例
次の例では、コスト 65 を指定し、リンクステート アドバタイズメント(LSA)の再送信間隔を 1 秒に設定します。
OSPF のネットワーク タイプの設定
OSPF はデフォルトで、さまざまなメディアを次の 3 種類のネットワーク タイプに分類します。
■![]() ブロードキャスト ネットワーク(イーサネット、トークンリング、FDDI)
ブロードキャスト ネットワーク(イーサネット、トークンリング、FDDI)
■![]() 非ブロードキャスト マルチアクセス(NBMA)ネットワーク(スイッチド マルチメガビット データ サービス(SMDS)、フレーム リレー、および X.25)
非ブロードキャスト マルチアクセス(NBMA)ネットワーク(スイッチド マルチメガビット データ サービス(SMDS)、フレーム リレー、および X.25)
■![]() ポイントツーポイント ネットワーク(High-Level Data Link Control(HDLC)、PPP)
ポイントツーポイント ネットワーク(High-Level Data Link Control(HDLC)、PPP)
また、デフォルトのメディア タイプにかかわらず、ネットワーク インターフェイスを、ブロードキャスト ネットワークまたは NBMA ネットワークに設定し、同時にポイントツーポイントまたはポイントツーマルチポイントに設定することができます。
非ブロードキャスト ネットワークの OSPF の設定
OSPF ネットワークには多数のルータが接続されている場合があるため、ネットワークには指定ルータが選択されています。ネットワークでブロードキャスト機能が設定されていない場合は、指定ルータを選択するために特別な設定パラメータが必要です。これらのパラメータは、指定ルータまたはバックアップ指定ルータとなる条件を満たすデバイス(つまり、ルータ プライオリティの値が 0 でないルータ)に対してだけ設定する必要があります。
はじめる前に
手順の詳細
ポイントツーマルチポイントの非ブロードキャスト ネットワークでは、さらに neighbor ルータ コンフィギュレーション コマンドを使用して、ネイバーを特定します。ネイバーへのコストの割り当てはオプションです。
例
次に、非ブロードキャスト ネットワーク アドレスが 192.168.3.4、プライオリティが 1、ポーリング間隔が 180 秒とするルータを宣言する例を示します。
OSPF インターフェイスのネットワーク タイプの設定
デフォルトのメディア タイプにかかわらず、ネットワーク インターフェイスを、ブロードキャスト ネットワークまたは NBMA ネットワークに設定し、同時にポイントツーポイントまたはポイントツーマルチポイントに設定することができます。
OSPF ポイントツーマルチポイント インターフェイスは、1 つまたは複数のネイバーを持つ、番号付きのポイントツーポイント インターフェイスとして定義されます。ポイントツーマルチポイント ブロードキャスト ネットワークでは、ネイバーの指定は任意です。メディアがブロードキャストをサポートしていない場合に、インターフェイスをポイントツーマルチポイントとして設定するには、 neighbor コマンドを使用して、ネイバーを特定する必要があります。
はじめる前に
手順の詳細
メディアのネットワークタイプをデフォルトに戻すには、 ip ospf network コマンドの no 形式を使用します。
例
次に、ユーザの OSPF ネットワークをブロードキャスト ネットワークとして設定する例を示します。
次に、ブロードキャストを行うポイントツーマルチポイント ネットワークの例を示します。
OSPF エリア パラメータの設定
複数の OSPF エリア パラメータを設定することもできます。設定できるパラメータには、エリア、スタブ エリア、および NSSA への無許可アクセスをパスワードによって阻止する認証用パラメータがあります。スタブエリアは、外部ルートの情報が送信されないエリアです。が、代わりに、自律システム(AS)外の宛先に対するデフォルトの外部ルートが、ABR によって生成されます。NSSA ではコアからそのエリアへ向かう LSA の一部がフラッディングされませんが、再配信することによって、エリア内の AS 外部ルートをインポートできます。
経路集約は、アドバタイズされたアドレスを、他のエリアでアドバタイズされる単一のサマリー ルートに統合することです。ネットワーク番号が連続する場合は、 area range ルータ コンフィギュレーション コマンドを使用し、範囲内のすべてのネットワークを対象とするサマリー ルートをアドバタイズするように ABR を設定できます。
はじめる前に
■![]() 外部の宛先に到達するために使用可能なタイプ 7 のデフォルト ルートを設定できます。この設定により、ルータはタイプ 7 デフォルト ルートを NSSA または NSSA の ABR に生成します。
外部の宛先に到達するために使用可能なタイプ 7 のデフォルト ルートを設定できます。この設定により、ルータはタイプ 7 デフォルト ルートを NSSA または NSSA の ABR に生成します。
■![]() 同じエリア内のすべてのルータは、そのエリアが NSSA であることに合意している必要があります。合意していないと、ルータ間の通信ができません。
同じエリア内のすべてのルータは、そのエリアが NSSA であることに合意している必要があります。合意していないと、ルータ間の通信ができません。
手順の詳細
例
次に、OSPF ルーティングプロセス 201 のエリア 0 および 10.0.0.0 に対して認証を必須とする例を示します。認証キーも指定しています。
その他の OSPF パラメータの設定
ルータ コンフィギュレーション モードで、その他の OSPF パラメータを設定することもできます。
■![]() 経路集約:他のプロトコルからのルートを再配信すると(ルート マップによるルーティング情報の再配信を参照)、各ルートは外部 LSA 内で個別にアドバタイズされます。OSPF リンクステートデータベースのサイズを小さくするには、 summary-address ルータ コンフィギュレーション コマンドを使用し、指定されたネットワークアドレスおよびマスクに含まれる、再配信されたすべてのルートを単一のルータにアドバタイズします。
経路集約:他のプロトコルからのルートを再配信すると(ルート マップによるルーティング情報の再配信を参照)、各ルートは外部 LSA 内で個別にアドバタイズされます。OSPF リンクステートデータベースのサイズを小さくするには、 summary-address ルータ コンフィギュレーション コマンドを使用し、指定されたネットワークアドレスおよびマスクに含まれる、再配信されたすべてのルートを単一のルータにアドバタイズします。
■![]() 仮想リンク:OSPF では、すべてのエリアがバックボーン エリアに接続されている必要があります。バックボーンが不連続である場合に仮想リンクを確立するには、2 つの ABR を仮想リンクのエンドポイントとして設定します。設定情報には、他の仮想エンドポイント(他の ABR)の ID、および 2 つのルータに共通する非バックボーン リンク(通過エリア)などがあります。仮想リンクをスタブ エリアから設定できません。
仮想リンク:OSPF では、すべてのエリアがバックボーン エリアに接続されている必要があります。バックボーンが不連続である場合に仮想リンクを確立するには、2 つの ABR を仮想リンクのエンドポイントとして設定します。設定情報には、他の仮想エンドポイント(他の ABR)の ID、および 2 つのルータに共通する非バックボーン リンク(通過エリア)などがあります。仮想リンクをスタブ エリアから設定できません。
■![]() デフォルト ルート:OSPF ルーティング ドメイン内へのルート再配信を設定すると、ルータは自動的に自律システム境界ルータ(ASBR)になります。ASBR を設定し、強制的に OSPF ルーティング ドメインにデフォルト ルートを生成できます。
デフォルト ルート:OSPF ルーティング ドメイン内へのルート再配信を設定すると、ルータは自動的に自律システム境界ルータ(ASBR)になります。ASBR を設定し、強制的に OSPF ルーティング ドメインにデフォルト ルートを生成できます。
■![]() すべての OSPF show 特権 EXEC コマンドで使用されるドメイン ネーム サーバ(DNS)名を使用すると、ルータ ID やネイバー ID を指定して表示する場合に比べ、ルータを簡単に特定できます。
すべての OSPF show 特権 EXEC コマンドで使用されるドメイン ネーム サーバ(DNS)名を使用すると、ルータ ID やネイバー ID を指定して表示する場合に比べ、ルータを簡単に特定できます。
■![]() デフォルト メトリック:OSPF は、インターフェイスの帯域幅に従ってインターフェイスの OSPF メトリックを計算します。メトリックは、帯域幅で分割された ref-bw として計算されます。ここでの ref のデフォルト値は 10 で、帯域幅( bw )は bandwidth インターフェイス コンフィギュレーション コマンドによって指定されます。大きな帯域幅を持つ複数のリンクの場合は、大きな数値を指定し、これらのリンクのコストを区別できます。
デフォルト メトリック:OSPF は、インターフェイスの帯域幅に従ってインターフェイスの OSPF メトリックを計算します。メトリックは、帯域幅で分割された ref-bw として計算されます。ここでの ref のデフォルト値は 10 で、帯域幅( bw )は bandwidth インターフェイス コンフィギュレーション コマンドによって指定されます。大きな帯域幅を持つ複数のリンクの場合は、大きな数値を指定し、これらのリンクのコストを区別できます。
■![]() アドミニストレーティブ ディスタンスは、ルーティング情報送信元の信頼性を表す数値です。0 ~ 255 の整数を指定でき、値が大きいほど信頼性は低下します。アドミニストレーティブ ディスタンスが 255 の場合はルーティング情報の送信元をまったく信頼できないため、無視する必要があります。OSPF では、エリア内のルート(エリア内)、別のエリアへのルート(エリア間)、および再配信によって学習した別のルーティング ドメインからのルート(外部)の 3 つの異なるアドミニストレーティブ ディスタンスが使用されます。どのアドミニストレーティブ ディスタンスの値でも変更できます。
アドミニストレーティブ ディスタンスは、ルーティング情報送信元の信頼性を表す数値です。0 ~ 255 の整数を指定でき、値が大きいほど信頼性は低下します。アドミニストレーティブ ディスタンスが 255 の場合はルーティング情報の送信元をまったく信頼できないため、無視する必要があります。OSPF では、エリア内のルート(エリア内)、別のエリアへのルート(エリア間)、および再配信によって学習した別のルーティング ドメインからのルート(外部)の 3 つの異なるアドミニストレーティブ ディスタンスが使用されます。どのアドミニストレーティブ ディスタンスの値でも変更できます。
■![]() 受動インターフェイス:イーサネット上の 2 つのデバイス間のインターフェイスは 1 つのネットワーク セグメントしか表しません。このため、OSPF が送信側インターフェイスに hello パケットを送信しないようにするには、送信側デバイスを受動インターフェイスに設定する必要があります。両方のデバイスは受信側インターフェイス宛ての hello パケットを使用することで、相互の識別を可能にします。
受動インターフェイス:イーサネット上の 2 つのデバイス間のインターフェイスは 1 つのネットワーク セグメントしか表しません。このため、OSPF が送信側インターフェイスに hello パケットを送信しないようにするには、送信側デバイスを受動インターフェイスに設定する必要があります。両方のデバイスは受信側インターフェイス宛ての hello パケットを使用することで、相互の識別を可能にします。
■![]() ルート計算タイマー:OSPF がトポロジ変更を受信してから SPF 計算を開始するまでの遅延時間、および 2 つの SPF 計算の間のホールド タイムを設定できます。
ルート計算タイマー:OSPF がトポロジ変更を受信してから SPF 計算を開始するまでの遅延時間、および 2 つの SPF 計算の間のホールド タイムを設定できます。
■![]() ネイバー変更ログ:OSPF ネイバー ステートが変更されたときに Syslog メッセージを送信するようにルータを設定し、ルータの変更を詳細に表示できます。
ネイバー変更ログ:OSPF ネイバー ステートが変更されたときに Syslog メッセージを送信するようにルータを設定し、ルータの変更を詳細に表示できます。
はじめる前に
手順の詳細
|
|
|
|
|---|---|---|
(任意)1 つのサマリー ルートだけがアドバタイズされるように、再配信されたルートのアドレスおよび IP サブネット マスクを指定します。 |
||
area area-id virtual-link router-id [ hello-interval seconds ] [ retransmit-interval seconds ] [ trans ] [[ authentication-key key ] | message-digest-key keyid md5 key ]] |
(任意)仮想リンクを確立し、パラメータを設定します。パラメータ定義については OSPF インターフェイスの設定、仮想リンクのデフォルト設定については OSPF のデフォルト設定を参照してください。 |
|
default-information originate [ always ] [ metric metric-value ] [ metric-type type-value ] [ route-map map-name ] |
(任意)強制的に OSPF ルーティング ドメインにデフォルト ルートを生成するように ASBR を設定します。パラメータはすべて任意です。 |
|
distance ospf {[ inter-area dist1 ] [ inter-area dist2 ] [ external dist3 ]} |
(任意)OSPF の距離の値を変更します。各タイプのルートのデフォルト距離は 110 です。有効値は 1 ~ 255 です。 |
|
| ■ ■ |
||
特定のルータの OSPF データベースに関連する情報のリストを表示します。キーワードオプションの一部については、OSPF のモニタリングを参照してください。 |
||
例
次の例では、集約アドレス 10.1.0.0 にアドレス 10.1.1.0、10.1.2.0、10.1.3.0 などが含まれています。外部 LSA では、アドレス 10.1.0.0 だけがアドバタイズされます。
LSA グループ ペーシングの変更
OSPF LSA グループ ペーシング機能を使用すると、OSPF LSA をグループ化し、リフレッシュ、チェックサム、エージング機能の同期を取って、ルータをより効率的に使用できるようになります。デフォルトでこの機能はイネーブルとなっています。デフォルトのペーシング インターバルは 4 分間です。通常は、このパラメータを変更する必要はありません。最適なグループ ペーシング インターバルは、ルータがリフレッシュ、チェックサム、エージングを行う LSA 数に反比例します。たとえば、データベース内に約 10000 個の LSA が格納されている場合は、ペーシング インターバルを短くすると便利です。小さなデータベース(40 ~ 100 LSA)を使用する場合は、ペーシング インターバルを長くし、10 ~ 20 分に設定してください。
はじめる前に
OSPF パケット フラッディングの要件を満たす他のオプションをすべて使用した場合に限り、パケット ペーシング タイマーを変更してください。特に、ネットワーク オペレータは、デフォルトのフラッディング タイマーを変更する前に、集約、スタブ エリアの使用方法、キューの調整、およびバッファの調整を優先して行う必要があります。さらに、タイマー値を変更するガイドラインはなく、各 OSPF 配備は一意であり、ケースバイケースで考慮する必要があります。ネットワーク オペレータは、デフォルトのタイマー値を変更することで生じるリスクを念頭に置く必要があります。
手順の詳細
|
|
|
|
|---|---|---|
デフォルト値に戻すには、 no timers pacing lsa-group ルータ コンフィギュレーション コマンドを使用します。
例
次に、OSPF ルーティング プロセス 1 に対して、LSA グループ間の OSPF グループ パケット ペーシング更新が 60 秒間隔で発生するように設定する例を示します。
ループバック インターフェイスの設定
OSPF は、インターフェイスに設定されている最大の IP アドレスをルータ ID として使用します。このインターフェイスがダウンした場合、または削除された場合、OSPF プロセスは新しいルータ ID を再計算し、すべてのルーティング情報をそのルータのインターフェイスから再送信します。ループバック インターフェイスが IP アドレスによって設定されている場合、他のインターフェイスにより大きな IP アドレスがある場合でも、OSPF はこの IP アドレスをルータ ID として使用します。ループバック インターフェイスに障害は発生しないため、安定性は増大します。OSPF は他のインターフェイスよりもループバック インターフェイスを自動的に優先し、すべてのループバック インターフェイスの中で最大の IP アドレスを選択します。
はじめる前に
ループバック インターフェイスの IP アドレスは、固有である必要があり、別のインターフェイスによっては使用されません。
手順の詳細
|
|
|
|
|---|---|---|
ループバック インターフェイスをディセーブルにするには、 no interface loopback 0 グローバル コンフィギュレーション コマンドを使用します。
例
OSPF のモニタリング
IP ルーティング テーブル、キャッシュ、データベースの内容など、特定の統計情報を表示できます。
次に、OSPF 統計情報を表示するために使用する特権 EXEC コマンドの一部を示します。 show ip ospf database 特権 EXEC コマンドのオプションおよび表示されるフィールドの詳細については、『 Cisco IOS IP Routing: OSPF Command Reference 』を参照してください。
EIGRP の設定
EIGRP は IGRP のシスコ独自の拡張バージョンです。EIGRP は IGRP と同じディスタンス ベクトル アルゴリズムおよび距離情報を使用しますが、EIGRP では収束性および動作効率が大幅に改善されています。
コンバージェンス テクノロジーには、拡散更新アルゴリズム(DUAL)と呼ばれるアルゴリズムが採用されています。DUAL を使用すると、ルート計算の各段階でループが発生しなくなり、トポロジの変更に関連するすべてのデバイスを同時に同期できます。トポロジ変更の影響を受けないルータは、再計算に含まれません。
IP EIGRP を導入すると、ネットワークの幅が広がります。RIP の場合、ネットワークの最大幅は 15 ホップです。EIGRP メトリックは数千ホップをサポートするほど大きいため、ネットワークを拡張するときに問題となるのは、トランスポート レイヤのホップ カウンタだけです。IP パケットが 15 台のルータを経由し、宛先方向のネクスト ホップが EIGRP によって取得されている場合だけ、EIGRP は転送制御フィールドの値を増やします。
EIGRP には次に示す 4 つの基本コンポーネントがあります。
■![]() ネイバー探索およびネイバーの回復:直接接続されたネットワーク上の他のルータに関する情報を動的に取得するために、ルータで使用されるプロセスです。 また、ネイバーが到達不能または動作不能になっていることを検出するためにも使用されます。ネイバー探索および回復:サイズの小さい hello パケットを定期的に送信することにより実現します。ネイバーは、hello パケットを受信している限り、動作していると判断されます。動作していると判断されると、隣接ルータはルーティング情報を交換します。
ネイバー探索およびネイバーの回復:直接接続されたネットワーク上の他のルータに関する情報を動的に取得するために、ルータで使用されるプロセスです。 また、ネイバーが到達不能または動作不能になっていることを検出するためにも使用されます。ネイバー探索および回復:サイズの小さい hello パケットを定期的に送信することにより実現します。ネイバーは、hello パケットを受信している限り、動作していると判断されます。動作していると判断されると、隣接ルータはルーティング情報を交換します。
■![]() Reliable Transport Protocol :EIGRP パケットをすべてのネイバーに確実に、順序どおりに配信します。マルチキャスト パケットとユニキャスト パケットが混在した伝送もサポートされます。EIGRP パケットには確実に送信する必要があるものと、そうでないものがあります。効率化のため、信頼性は必要時にのみ提供されます。たとえば、マルチキャスト機能があるマルチアクセス ネットワークでは、すべてのネイバーそれぞれに対して hello パケットを確実に送信する必要はありません。そのため、EIGRP は、1 つのマルチキャスト hello を送信し、パケットに確認応答が必要ないという通知をそのパケットに含めます。他のタイプのパケット(アップデートなど)の場合は、確認応答(ACK パケット)を要求します。コンバージェンス時間を短縮するため、確認応答のない保留中パケットがある場合には、信頼性の高い転送によってマルチキャスト パケットが迅速に送信されます。
Reliable Transport Protocol :EIGRP パケットをすべてのネイバーに確実に、順序どおりに配信します。マルチキャスト パケットとユニキャスト パケットが混在した伝送もサポートされます。EIGRP パケットには確実に送信する必要があるものと、そうでないものがあります。効率化のため、信頼性は必要時にのみ提供されます。たとえば、マルチキャスト機能があるマルチアクセス ネットワークでは、すべてのネイバーそれぞれに対して hello パケットを確実に送信する必要はありません。そのため、EIGRP は、1 つのマルチキャスト hello を送信し、パケットに確認応答が必要ないという通知をそのパケットに含めます。他のタイプのパケット(アップデートなど)の場合は、確認応答(ACK パケット)を要求します。コンバージェンス時間を短縮するため、確認応答のない保留中パケットがある場合には、信頼性の高い転送によってマルチキャスト パケットが迅速に送信されます。
■![]() DUAL 有限状態マシン:すべてのルート計算に関する決定プロセスが処理されます。 DUAL 有限状態マシンでは、すべてのネイバーによりアドバタイズされた全ルートが追跡され、距離情報(メトリック)に基づいて、ループのない効率的なパスが選択されます。さらに DUAL は適切な後継ルータに基づいて、ルーティング テーブルに挿入するルートを選択します。後継ルータは、宛先への最小コスト パス(ルーティング ループに関連しないことが保証されている)を持つ、パケット転送に使用される隣接ルータです。
DUAL 有限状態マシン:すべてのルート計算に関する決定プロセスが処理されます。 DUAL 有限状態マシンでは、すべてのネイバーによりアドバタイズされた全ルートが追跡され、距離情報(メトリック)に基づいて、ループのない効率的なパスが選択されます。さらに DUAL は適切な後継ルータに基づいて、ルーティング テーブルに挿入するルートを選択します。後継ルータは、宛先への最小コスト パス(ルーティング ループに関連しないことが保証されている)を持つ、パケット転送に使用される隣接ルータです。
適切な後継ルータが存在しなくても、宛先にアドバタイズするネイバーが存在する場合は、再計算を行って新たな後継ルータを決定する必要があります。ルートの再計算に要する時間によって、コンバージェンス時間が変わります。トポロジが変更された場合、DUAL では、不要な再計算を省略するために、適切な後継ルータが存在するかどうかのテストが行われます。
■![]() プロトコル依存モジュール:ネットワーク層プロトコル固有のタスクを実行します。 たとえば、IP EIGRP モジュールは、IP でカプセル化された EIGRP パケットを送受信します。また、EIGRP パケットを解析したり、DUAL に受信した新しい情報を通知したりします。ルーティングの決定結果は IP ルーティング テーブルに格納されます。また EIGRP では、他の IP ルーティング プロトコルにより学習されたルートが再配布されます。
プロトコル依存モジュール:ネットワーク層プロトコル固有のタスクを実行します。 たとえば、IP EIGRP モジュールは、IP でカプセル化された EIGRP パケットを送受信します。また、EIGRP パケットを解析したり、DUAL に受信した新しい情報を通知したりします。ルーティングの決定結果は IP ルーティング テーブルに格納されます。また EIGRP では、他の IP ルーティング プロトコルにより学習されたルートが再配布されます。
EIGRP のデフォルト設定
|
|
|
|---|---|
デフォルト メトリックなしで再配信できるのは、接続されたルートおよびインターフェイスのスタティック ルートだけです。デフォルト メトリックは次のとおりです。 ■ ■ |
|
NSF3 認識 |
イネーブル4。レイヤ 3 スイッチでは、ハードウェアやソフトウェアの変更中に、隣接する NSF 対応ルータからのパケットを転送し続けることができます。 |
|
4.EIGRP NSF 認識は、IP サービスイメージを実行しているスイッチでは IPv4 に対してイネーブルになっています。 |
EIGRP ルーティング プロセスを作成するには、EIGRP をイネーブルにし、ネットワークを関連付ける必要があります。EIGRP は指定されたネットワーク内のインターフェイスにアップデートを送信します。インターフェイス ネットワークを指定しないと、どの EIGRP アップデートでもアドバタイズされません。
NSF 認識
EIGRP NSF 認識機能は IP サービス イメージの IPv4 でサポートされています。隣接ルータが NSF 対応である場合、レイヤ 3 スイッチでは、ルータに障害が発生してプライマリ RP がバックアップ RP によって引き継がれる間、または処理を中断させずにソフトウェア アップグレードを行うためにプライマリ RP を手動でリロードしている間、隣接ルータからパケットを転送し続けます。
この機能をディセーブルにできません。この機能の詳細については、『 High Availability Configuration Guide, Cisco IOS Release 15S 』の「 Configuring Nonstop Forwarding 」を参照してください。
基本的な EIGRP パラメータの設定
はじめる前に
手順の詳細
例
次に、EIGRP 自律システム 1 を設定し、ネットワーク 172.16.0.0 および 192.168.0.0 を通じてネイバーを確立する例を示します。
EIGRP インターフェイスの設定
はじめる前に
基本的な EIGRP パラメータの設定の説明に従って、EIGRP をイネーブルにします。
手順の詳細
例
次に、EIGRP で、自律システム 209 の 56-kbps シリアル リンクを最大 75%(42 kbps)使用できるようにする例を示します。
EIGRP ルート認証の設定
EIGRP ルート認証を行うと、EIGRP ルーティング プロトコルからのルーティング アップデートに関する MD5 認証が可能になり、承認されていない送信元から無許可または問題のあるルーティング メッセージを受け取ることがなくなります。
はじめる前に
基本的な EIGRP パラメータの設定の説明に従って、EIGRP をイネーブルにします。
手順の詳細
例
次の例では、認証をアドレスファミリ自律システム 1 に適用するよう EIGRP を設定して、SITE1 という名前のキーチェーンを識別しています。
EIGRP スタブ ルーティングの設定
EIGRP スタブ ルーティング機能は、エンド ユーザの近くにルーテッド トラフィックを移動することでリソースの利用率を低減させます。EIGRP スタブ ルーティングを使用するネットワークでは、ユーザに対する IP トラフィックの唯一の許容ルートは、EIGRP スタブ ルーティングを設定しているスイッチ経由です。スイッチは、ユーザ インターフェイスとして設定されているインターフェイスまたは他のデバイスに接続されているインターフェイスにルーテッド トラフィックを送信します。
EIGRP スタブ ルーティングを使用しているときは、EIGRP を使用してスイッチだけをスタブとして設定するように、分散ルータおよびリモート ルータを設定する必要があります。指定したルートだけがスイッチから伝播されます。スイッチは、サマリー、接続ルート、およびルーティング アップデートに対するすべてのクエリーに応答します。
注: EIGRP スタブルーティングでは、ルーティングテーブルからネットワークのその他のスイッチに、接続ルートまたはサマリールートだけがアドバタイズされます。スイッチは アクセス レイヤで EIGRP スタブ ルーティングを使用することにより、ほかのタイプのルーティング アドバタイズメントの必要性を排除しています。マルチ VRF CE と EIGRP スタブ ルーティングを同時に設定しようとすると、設定は許可されません。
スタブ ルータの状態を通知するパケットを受信した隣接ルータは、ルートについてはスタブ ルータに照会しません。また、スタブ ピアを持つルータは、そのピアについては照会しません。スタブ ルータは、ディストリビューション ルータを使用して適切なアップデートをすべてのピアに送信します。
図 102では、スイッチ B が EIGRP スタブ ルータとして設定されています。スイッチ A および C は残りの WAN に接続されています。スイッチ B は、接続ルート、スタティック ルート、再配信ルート、およびサマリー ルートをスイッチ A と C にアドバタイズします。スイッチ B は、スイッチ A から学習したルートをアドバタイズしません(逆の場合も同様です)。
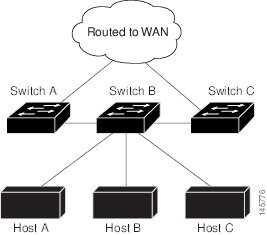
EIGRP スタブルーティングの詳細については、『 IP Routing: EIGRP Configuration Guide, Cisco IOS Release 15M&T 』を参照してください。
はじめる前に
手順の詳細
特権 EXEC コマンド show ip eigrp neighbor detail を分散ルータから入力し、設定を確認します。
例
次に、接続および集約ルートをアドバタイズするスタブとしてルータを設定するために eigrp stub コマンドが使用する例を示します。
EIGRP のモニタリングおよびメンテナンス
ネイバー テーブルからネイバーを削除できます。さらに、各種 EIGRP ルーティング統計情報を表示することもできます。
|
|
|
|---|---|
show ip eigrp topology [ autonomous-system-number ] | [[ ip-address ] mask ]] |
|
BGP の設定
BGP は、外部ゲートウェイ プロトコル(EGP)です。自律システム間で、ループの発生しないルーティング情報交換を行うためのドメイン間ルーティング システムを設定する際に使用します。自律システムは、同じ管理下で動作して RIP や OSPF などの Interior Gateway Protocol(IGP)を境界内で実行し、Exterior Gateway Protocol(EGP)を使用して相互接続されるルータで構成されます。BGP バージョン 4 は、インターネット内でドメイン間ルーティングを行うための標準 EGP です。
BGP の設定とコマンドの詳細については、関連資料に記載されている BGP のドキュメントを参照してください。
同じ自律システム(AS)に属し、BGP アップデートを交換するルータは内部 BGP(IBGP)を実行し、異なる自律システムに属し、BGP アップデートを交換するルータは外部 BGP(EBGP)を実行します。 大部分のコンフィギュレーション コマンドは、EBGP と IBGP で同じですが、ルーティング アップデートが自律システム間で交換されるか(EBGP)、または AS 内で交換されるか(IBGP)という点で異なります。図 103に、EBGP と IBGP の両方が稼働するネットワークを示します。
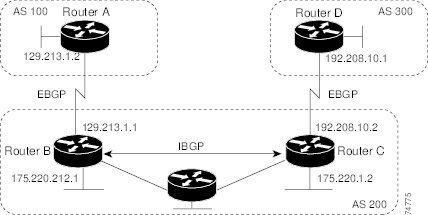
外部 AS と情報を交換する前に、BGP は AS 内のルータ間で内部 BGP ピアリングを定義し、IGRP や OSPF など AS 内で稼働する IGP に BGP ルーティング情報を再配信して、AS 内のネットワークに到達することを確認します。
BGP ルーティングプロセスを実行するルータは、通常 BGP スピーカーと呼ばれます。BGP はトランスポート プロトコルとして伝送制御プロトコル(TCP)を使用します(特にポート 179)。ルーティング情報を交換するため相互に TCP 接続された 2 つの BGP スピーカーを、ピアまたはネイバーと呼びます。図 103では、ルータ A と B が BGP ピアで、ルータ B と C、ルータ C と D も同様です。ルーティング情報は、宛先ネットワークへの完全パスを示す一連の AS 番号です。BGP はこの情報を使用し、ループのない自律システム マップを作成します。
■![]() ルータ A および B では EBGP が、ルータ B および C では IBGP が稼働しています。EBGP ピアは直接接続されていますが、IBGP ピアは直接接続されていないことに注意してください。IGP が稼働し、2 つのネイバーが相互に到達するかぎり、IBGP ピアを直接接続する必要はありません。
ルータ A および B では EBGP が、ルータ B および C では IBGP が稼働しています。EBGP ピアは直接接続されていますが、IBGP ピアは直接接続されていないことに注意してください。IGP が稼働し、2 つのネイバーが相互に到達するかぎり、IBGP ピアを直接接続する必要はありません。
■![]() AS 内のすべての BGP スピーカーは、相互にピア関係を確立する必要があります。つまり、AS 内の BGP スピーカーは、論理的な完全メッシュ型に接続する必要があります。BGP4 は、論理的な完全メッシュに関する要求を軽減する 2 つの技術(連合およびルートリフレクタ)を提供します。
AS 内のすべての BGP スピーカーは、相互にピア関係を確立する必要があります。つまり、AS 内の BGP スピーカーは、論理的な完全メッシュ型に接続する必要があります。BGP4 は、論理的な完全メッシュに関する要求を軽減する 2 つの技術(連合およびルートリフレクタ)を提供します。
■![]() AS 200 は AS 100 および AS 300 の中継 AS です。つまり、AS 200 は AS 100 と AS 300 間でパケットを転送するために使用されます。
AS 200 は AS 100 および AS 300 の中継 AS です。つまり、AS 200 は AS 100 と AS 300 間でパケットを転送するために使用されます。
BGP ピアは完全な BGP ルーティング テーブルを最初に交換し、差分更新だけを送信します。BGP ピアはキープアライブ メッセージ(接続が有効であることを確認)、および通知メッセージ(エラーまたは特殊条件に応答)を交換することもできます。
BGP の場合、各ルートはネットワーク番号、情報が通過した自律システムのリスト(自律システムパス)、および他のパス属性リストで構成されます。BGP システムの主な機能は、AS パスのリストに関する情報など、ネットワークの到達可能性情報を他の BGP システムと交換することです。この情報は、AS が接続されているかどうかを判別したり、ルーティング ループをプルーニングしたり、AS レベル ポリシー判断を行うために使用できます。
Cisco IOS が稼働しているルータまたはスイッチが IBGP ルートを選択または使用するのは、ネクストホップ ルータで使用可能なルートがあり、IGP から同期信号を受信している(IGP 同期がディセーブルの場合は除く)場合です。複数のルートが使用可能な場合、BGP は属性値に基づいてパスを選択します。BGP 属性の詳細については、BGP 判断属性の設定を参照してください。
BGP バージョン 4 ではクラスレスドメイン間ルーティング(CIDR)がサポートされているため、集約ルートを作成してスーパーネットを構築し、ルーティングテーブルのサイズを削減できます。CIDR は、BGP 内部のネットワーク クラスの概念をエミュレートし、IP プレフィックスのアドバタイズをサポートします。
BGP のデフォルト設定
|
|
|
|---|---|
■ |
|
ループバック インターフェイスに IP アドレスが設定されている場合は、ループバック インターフェイスの IP アドレス、またはルータの物理インターフェイスに対して設定された最大の IP アドレス |
|
■ |
|
■ ■ |
|
■ |
|
NSF5 認識 |
ディセーブル6。レイヤ 3 スイッチでは、ハードウェアやソフトウェアの変更中に、隣接する NSF 対応ルータからのパケットを転送し続けることができます。 |
|
6.BGP NSF 認識は、グレースフルリスタートをイネーブルすることにより、IP サービスイメージを稼働しているスイッチの IPv4 に対してイネーブルにできます。 |
NSF 認識
BGP NSF 認識機能は IP サービス イメージの IPv4 でサポートされています。BGP ルーティングでこの機能をイネーブルにするには、グレースフル リスタートをイネーブルにする必要があります。隣接ルータが NSF 対応で、この機能がイネーブルである場合、レイヤ 3 スイッチでは、ルータに障害が発生してプライマリ RP がバックアップ RP によって引き継がれる間、または処理を中断させずにソフトウェア アップグレードを行うためにプライマリ RP を手動でリロードしている間、隣接ルータからパケットを転送し続けます。詳細については、『 IP Routing: BGP Configuration Guide, Cisco IOS Release 15M&T 』を参照してください。
BGP ルーティングのイネーブル化
BGP ルーティングをイネーブルにするには、BGP ルーティング プロセスを確立し、ローカル ネットワークを定義します。BGP はネイバーとの関係を完全に認識する必要があるため、BGP ネイバーも指定する必要があります。
BGP は、内部および外部の 2 種類のネイバーをサポートします。内部ネイバーは同じ AS 内に、外部ネイバーは異なる AS 内にあります。通常の場合、外部ネイバーは相互に隣接し、1 つのサブネットを共有しますが、内部ネイバーは同じ AS 内の任意の場所に存在します。
スイッチではプライベート AS 番号を使用できます。プライベート AS 番号は通常サービス プロバイダーによって割り当てられ、ルートが外部ネイバーにアドバタイズされないシステムに設定されます。プライベート AS 番号の範囲は 64512 ~ 65535 です。AS パスからプライベート AS 番号を削除するように外部ネイバーを設定するには、 neighbor remove-private-as ルータ コンフィギュレーション コマンドを使用します。この結果、外部ネイバーにアップデートを渡すとき、AS パス内にプライベート AS 番号が含まれている場合は、これらの番号が削除されます。
AS が別の AS から受け取ったトラフィックをさらに別の AS に渡す場合は、アドバタイズ対象のルートに矛盾がないことが重要です。BGP によりルートがアドバタイズされてから、ネットワーク内のすべてのルータが IGP を通してルートを学習した場合、AS は一部のルータがルーティングできなかったトラフィックを受信することがあります。このような事態を避けるため、BGP は IGP が AS に情報を伝播し、BGP が IGP と同期化されるまで、待機する必要があります。同期化は、デフォルトでイネーブルに設定されています。AS が特定の AS から別の AS にトラフィックを渡さない場合、または自律システム内のすべてのルータで BGP が稼働している場合は、同期化をディセーブルにし、IGP 内で伝送されるルート数を少なくして、BGP がより短時間で収束するようにします。
はじめる前に
BGP を設定する前にネットワーク設計およびそれを経由するトラフィックのフロー方法を知っておく必要があります。必要なネットワーク要件を収集します。これには次のものが含まれている必要があります。
手順の詳細
BGP AS を削除するには、 no router bgp autonomous-system グローバル コンフィギュレーション コマンドを使用します。BGP テーブルからネットワークを削除するには、 no network network-number ルータ コンフィギュレーション コマンドを使用します。ネイバーを削除するには、 no neighbor { ip-address | peer-group-name } remote-as number ルータ コンフィギュレーション コマンドを使用します。ネイバーにアップデート内のプライベート AS 番号を追加するには、 no neighbor { ip-address | peer-group-name } remove-private-as ルータ コンフィギュレーション コマンドを使用します。同期化を再度イネーブルにするには、 synchronization ルータ コンフィギュレーション コマンドを使用します。
例
次に、図 103に示されたルータ上で BGP を設定する例を示します。
BGP ピアが稼働していることを確認するには、show ip bgp neighbors 特権 EXEC コマンドを使用します。次に、ルータ A にこのコマンドを実行した場合の出力例を示します。
state = established 以外の情報が出力された場合、ピアは稼働していません。リモート ルータ ID は、ルータ(または最大のループバック インターフェイス)上の最大の IP アドレスです。テーブルが新規情報でアップデートされるたびに、テーブルのバージョン番号は増加します。継続的にテーブル バージョン番号が増加している場合は、ルートがフラッピングし、ルーティング アップデートが絶えず発生しています。
外部プロトコルの場合、 network ルータ コンフィギュレーション コマンドから IP ネットワークへの参照によって制御されるのは、アドバタイズされるネットワークだけです。これは、 network コマンドを使用してアップデートの送信先を指定する IGP(EIGRP など)と対照的です。
ルーティング ポリシー変更の管理
ピアのルーティング ポリシーには、インバウンドまたはアウトバウンド ルーティング テーブル アップデートに影響する可能性があるすべての設定が含まれます。BGP ネイバーとして定義された 2 台のルータは、BGP 接続を形成し、ルーティング情報を交換します。このあとで BGP フィルタ、重量、距離、バージョン、またはタイマーを変更する場合、または同様の設定変更を行う場合は、BGP セッションをリセットし、設定の変更を有効にする必要があります。
リセットには、ハードリセットとソフトリセットの 2 種類があります。両方の BGP ピアでソフト ルート リフレッシュ機能がサポートされている場合、スイッチでは事前に設定を行うことなくソフト リセットを使用できます。ソフト ルート リフレッシュ機能は、ピアによって TCP セッションが確立されたときに送信される OPEN メッセージによりアドバタイズされます。ソフト リセットを使用すると、BGP ルータ間でルート リフレッシュ要求およびルーティング情報を動的に交換したり、それぞれのアウトバウンド ルーティング テーブルをあとで再アドバタイズできます。
■![]() ソフトリセットによってネイバーからインバウンドアップデートが生成された場合、このリセットはダイナミック インバウンド ソフト リセットといいます。
ソフトリセットによってネイバーからインバウンドアップデートが生成された場合、このリセットはダイナミック インバウンド ソフト リセットといいます。
■![]() ソフトリセットによってネイバーに一連のアップデートが送信された場合、このリセットはアウトバウンド ソフト リセットといいます。
ソフトリセットによってネイバーに一連のアップデートが送信された場合、このリセットはアウトバウンド ソフト リセットといいます。
ソフト インバウンド リセットが発生すると、新規インバウンド ポリシーが有効になります。ソフト アウトバウンド リセットが発生すると、BGP セッションがリセットされずに、新規ローカル アウトバウンド ポリシーが有効になります。アウトバウンド ポリシーのリセット中に新しい一連のアップデートが送信されると、新規インバウンド ポリシーも有効になる場合があります。
|
|
|
|
|---|---|---|
はじめる前に
BGP ルーティングのイネーブル化の説明に従って、BGP ルーティングをイネーブルにします。
手順の詳細
例
次の例では、自律システム番号 35700 のすべてのルータとのセッションに対してアウトバウンド ソフト リセットが開始されます。
BGP 判断属性の設定
BGP スピーカーが複数の自律システムから受信したアップデートが、同じ宛先に対して異なるパスを示している場合、BGP スピーカーはその宛先に到達する最適パスを 1 つ選択する必要があります。この判断は、アップデートに格納されている属性値、および BGP で設定可能な他の要因に基づいて行われます。選択されたパスは BGP ルーティング テーブルに格納され、ネイバーに伝播されます。
BGP ピアはネイバー AS からプレフィックスに対する 2 つの EBGP パスを学習するとき、最適パスを選択して IP ルーティング テーブルに挿入します。BGP マルチパス サポートがイネーブルの場合、同じネイバー自律システムから複数の EBGP パスを学習すると、IP ルーティング テーブルには複数のパスが格納されます。その後、パケット スイッチング中に、複数のパス間でパケット単位または宛先単位のロード バランシングが実行されます。maximum-paths maximum-paths ルータ コンフィギュレーション コマンドは、許可されるパス数を制御します。
これらの要因により、BGP が最適パスを選択するために属性を評価する順序が決まります。
1.![]() パスで指定されているネクスト ホップが到達不能な場合、この更新はドロップされます。BGP ネクスト ホップ属性(ソフトウェアによって自動判別される)は、宛先に到達するために使用されるネクスト ホップの IP アドレスです。EBGP の場合、通常このアドレスは neighbor remote-as router ルータ コンフィギュレーション コマンドで指定されたネイバーの IP アドレスです。ネクストホップの処理をディセーブルにするには、ルートマップまたは neighbor next-hop-self ルータ コンフィギュレーション コマンドを使用します。
パスで指定されているネクスト ホップが到達不能な場合、この更新はドロップされます。BGP ネクスト ホップ属性(ソフトウェアによって自動判別される)は、宛先に到達するために使用されるネクスト ホップの IP アドレスです。EBGP の場合、通常このアドレスは neighbor remote-as router ルータ コンフィギュレーション コマンドで指定されたネイバーの IP アドレスです。ネクストホップの処理をディセーブルにするには、ルートマップまたは neighbor next-hop-self ルータ コンフィギュレーション コマンドを使用します。
2.![]() 最大の重みのパスを推奨します(シスコ独自のパラメータ)。ウェイト属性はルータにローカルであるため、ルーティング アップデートで伝播されません。デフォルトでは、ルータ送信元のパスに関するウェイト属性は 32768 で、それ以外のパスのウェイト属性は 0 です。重みを設定するには、アクセス リスト、ルート マップ、または neighbor weight ルータ コンフィギュレーション コマンドを使用します。
最大の重みのパスを推奨します(シスコ独自のパラメータ)。ウェイト属性はルータにローカルであるため、ルーティング アップデートで伝播されません。デフォルトでは、ルータ送信元のパスに関するウェイト属性は 32768 で、それ以外のパスのウェイト属性は 0 です。重みを設定するには、アクセス リスト、ルート マップ、または neighbor weight ルータ コンフィギュレーション コマンドを使用します。
3.![]() ローカル プリファレンス値が最大のルートを推奨します。ローカル プリファレンスはルーティング アップデートに含まれ、同じ AS 内のルータ間で交換されます。ローカル初期設定属性のデフォルト値は 100 です。ローカル プリファレンスを設定するには、 bgp default local-preference ルータ コンフィギュレーション コマンドまたはルート マップを使用します。
ローカル プリファレンス値が最大のルートを推奨します。ローカル プリファレンスはルーティング アップデートに含まれ、同じ AS 内のルータ間で交換されます。ローカル初期設定属性のデフォルト値は 100 です。ローカル プリファレンスを設定するには、 bgp default local-preference ルータ コンフィギュレーション コマンドまたはルート マップを使用します。
4.![]() ローカル ルータ上で稼働する BGP から送信されたルートを推奨します。
ローカル ルータ上で稼働する BGP から送信されたルートを推奨します。
6.![]() 送信元タイプが最小のルートを推奨します。内部ルートまたは IGP は、EGP によって学習されたルートよりも小さく、EGP で学習されたルートは、未知の送信元のルートまたは別の方法で学習されたルートよりも小さくなります。
送信元タイプが最小のルートを推奨します。内部ルートまたは IGP は、EGP によって学習されたルートよりも小さく、EGP で学習されたルートは、未知の送信元のルートまたは別の方法で学習されたルートよりも小さくなります。
7.![]() 想定されるすべてのルートについてネイバー AS が同じである場合は、MED メトリック属性が最小のルートを優先します。MED を設定するには、ルート マップまたは default-metric ルータ コンフィギュレーション コマンドを使用します。IBGP ピアに送信されるアップデートには、MED が含まれます。
想定されるすべてのルートについてネイバー AS が同じである場合は、MED メトリック属性が最小のルートを優先します。MED を設定するには、ルート マップまたは default-metric ルータ コンフィギュレーション コマンドを使用します。IBGP ピアに送信されるアップデートには、MED が含まれます。
8.![]() 内部(IBGP)パスより、外部(EBGP)パスを推奨します。
内部(IBGP)パスより、外部(EBGP)パスを推奨します。
9.![]() 最も近い IGP ネイバー(最小の IGP メトリック)を通って到達できるルートを推奨します。ルータは、AS 内の最短の内部パス(BGP のネクストホップへの最短パス)を使用し、宛先に到達するためです。
最も近い IGP ネイバー(最小の IGP メトリック)を通って到達できるルートを推奨します。ルータは、AS 内の最短の内部パス(BGP のネクストホップへの最短パス)を使用し、宛先に到達するためです。
10.![]() 次の条件にすべて該当する場合は、このパスのルートを IP ルーティング テーブルに挿入してください。
次の条件にすべて該当する場合は、このパスのルートを IP ルーティング テーブルに挿入してください。
11.![]() マルチパスがイネーブルでない場合は、BGP ルータ ID の IP アドレスが最小であるルートを推奨します。通常、ルータ ID はルータ上の最大の IP アドレスまたはループバック(仮想)アドレスですが、実装に依存することがあります。
マルチパスがイネーブルでない場合は、BGP ルータ ID の IP アドレスが最小であるルートを推奨します。通常、ルータ ID はルータ上の最大の IP アドレスまたはループバック(仮想)アドレスですが、実装に依存することがあります。
はじめる前に
BGP ルーティングのイネーブル化の説明に従って、BGP ルーティングをイネーブルにします。
手順の詳細
例
次に、10.108.1.1 向けのすべてのアップデートに対し、このルータをネクスト ホップとしてアドバタイズするように設定する例を示します。
次の例では、受信したパスが属する自律システムに関係なくパスの選択肢から MED を比較するように、ローカル BGP ルーティング プロセスを設定しています。
ルート マップによる BGP フィルタリングの設定
BGP 内でルート マップを使用すると、ルーティング情報を制御、変更したり、ルーティング ドメイン間でルートを再配布する条件を定義したりできます。ルートマップの詳細については、ルート マップによるルーティング情報の再配信を参照してください。各ルートマップには、ルートマップを識別する名前(マップタグ)およびオプションのシーケンス番号が付いています。
はじめる前に
BGP ルーティングのイネーブル化の説明に従って、BGP ルーティングをイネーブルにします。
手順の詳細
ルートマップを削除するには、 no route-map map-tag コマンドを使用します。ネクストホップ処理を再びイネーブルにするには、 no set ip next-hop ip-address コマンドを使用します。
例
次の例では、rmap という名前のインバウンドルートマップがネクストホップを設定します。
ネイバーによる BGP フィルタリングの設定
BGP アドバタイズメントをフィルタリングするには、 as-path access-list グローバル コンフィギュレーション コマンドや neighbor filter-list ルータ コンフィギュレーション コマンドなどの AS パス フィルタを使用します。 neighbor distribute-list ルータ コンフィギュレーション コマンドとアクセス リストを併用することもできます。distribute-list フィルタはネットワーク番号に適用されます。 distribute-list コマンドの詳細については、ルーティング アップデートのアドバタイズおよび処理の制御を参照してください。
ネイバー単位でルート マップを使用すると、アップデートをフィルタリングしたり、さまざまな属性を変更したりできます。ルート マップは、インバウンド アップデートまたはアウトバウンド アップデートのいずれかに適用できます。ルート マップを渡すルートだけが、アップデート内で送信または許可されます。着信および発信の両方のアップデートで、AS パス、コミュニティ、およびネットワーク番号に基づくマッチングがサポートされています。AS パスのマッチングには match as-path access-list ルートマップコマンド、コミュニティに基づくマッチングには match community-list ルートマップコマンド、ネットワークに基づくマッチングには ip access-list グローバル コンフィギュレーション コマンドが必要です。
はじめる前に
BGP ルーティングのイネーブル化の説明に従って、BGP ルーティングをイネーブルにします。
手順の詳細
ネイバーからアクセスリストを削除するには、 no neighbor distribute-list コマンドを使用します。ネイバーからルートマップを削除するには、 no neighbor route-map map-tag ルータ コンフィギュレーション コマンドを使用します。
例
次のルータ コンフィギュレーション モードの例では、リスト 39 をネイバー 172.16.4.1 からの着信アドバタイズメントに適用しています。リスト 39 は、ネットワーク 10.109.0.0 のアドバタイズメントを許可します。
アクセスリストによる BGP フィルタリングの設定
BGP 自律システム パスに基づいて着信および発信の両方のアップデートにアクセス リスト フィルタを指定して、フィルタリングすることもできます。各フィルタは、正規表現を使用するアクセス リストです。(正規表現の作成方法の詳細については、『 Using Regular Expressions in BGP 』を参照してください。)この方法を使用するには、自律システムパスのアクセスリストを定義し、特定のネイバーに対して送受信されるアップデートに適用します。
はじめる前に
BGP ルーティングのイネーブル化の説明に従って、BGP ルーティングをイネーブルにします。
手順の詳細
例
次の例では、自律システムパスアクセスリスト(番号 500)を定義し、自律システム 65535 から、またはこの自律システムを経由して、10.20.2.2 ネイバーにパスをアドバタイズしないようにルータを設定しています。
BGP フィルタリング用のプレフィックス リストの設定
neighbor distribute-list ルータ コンフィギュレーション コマンドを含む多数の BGP ルート フィルタリング コマンドでは、アクセス リストの代わりにプレフィックス リストを使用できます。プレフィックス リストによるフィルタリングでは、アクセス リストの照合の場合と同様に、プレフィックス リストに記載されたプレフィックスとルートのプレフィックスが照合されます。一致すると、一致したルートが使用されます。プレフィックスが許可されるか、または拒否されるかは、次に示すルールに基づいて決定されます。
■![]() 空のプレフィックス リストはすべてのプレフィックスを許可します。
空のプレフィックス リストはすべてのプレフィックスを許可します。
■![]() 特定のプレフィックスがプレフィックス リストのどのエントリとも一致しなかった場合、実質的に拒否されたものと見なされます。
特定のプレフィックスがプレフィックス リストのどのエントリとも一致しなかった場合、実質的に拒否されたものと見なされます。
■![]() 指定されたプレフィックスと一致するエントリがプレフィックス リスト内に複数存在する場合は、シーケンス番号が最小であるプレフィックス リスト エントリが識別されます。
指定されたプレフィックスと一致するエントリがプレフィックス リスト内に複数存在する場合は、シーケンス番号が最小であるプレフィックス リスト エントリが識別されます。
デフォルトでは、シーケンス番号は自動生成され、5 ずつ増分します。シーケンス番号の自動生成をディセーブルにした場合は、エントリごとにシーケンス番号を指定する必要があります。シーケンス番号を指定する場合の増分値に制限はありません。増分値が 1 の場合は、このリストに追加エントリを挿入できません。増分値が大きい場合は、値がなくなることがあります。
コンフィギュレーション エントリを削除する場合は、シーケンス番号を指定する必要はありません。 show コマンドの出力には、シーケンス番号が含まれます。
はじめる前に
BGP ルーティングのイネーブル化の説明に従って、BGP ルーティングをイネーブルにします。
手順の詳細
プレフィックスリストまたはそのエントリをすべて削除する場合は、 no ip prefix-list list-name グローバル コンフィギュレーション コマンドを使用します。プレフィックスリストから特定のエントリを削除する場合は、 no ip prefix-list seq seq-value グローバル コンフィギュレーション コマンドを使用します。シーケンス番号の自動生成をディセーブルにするには no ip prefix-list sequence number コマンドを、自動生成を再びイネーブルにするには ip prefix-list sequence number コマンドを使用します。プレフィックス リスト エントリのヒット数テーブルをクリアするには、 clear ip prefix-list 特権 EXEC コマンドを使用します。
例
次の例では、プレフィックス リストがデフォルト ルート 0.0.0.0/0 を拒否するように設定されています。
次の例では、プレフィックス リストが 172.16.1.0/24 サブネットからのトラフィックを許可するように設定されています。
次の例では、プレフィックス リストが 24 ビット以下のマスク長を持つ 10.0.0.0/8 ネットワークからのルートを許可するように設定されています。
次の例では、プレフィックス リストが 25 ビット以上のマスク長を持つ 10.0.0.0/8 ネットワークからのルートを拒否するように設定されています。
次の例では、マスク長が 8 ~ 24 ビットの任意のネットワークからのルートを許可するようにプレフィックス リストが設定されています。
次の例では、プレフィックス リストが 10.0.0.0/8 ネットワークからの任意のマスク長を持つルートを拒否するように設定されています。
BGP コミュニティ フィルタリングの設定
BGP コミュニティ フィルタリングは、COMMUNITIES 属性の値に基づいてルーティング情報の配信を制御する BGP の方法の 1 つです。コミュニティは、共通するいくつかの属性を共有する宛先のグループです。各宛先は複数のコミュニティに属します。AS 管理者は、宛先が属するコミュニティを定義できます。デフォルトでは、すべての宛先が一般的なインターネット コミュニティに属します。コミュニティは、過渡的でグローバルなオプションの属性である、COMMUNITIES 属性(1 ~ 4294967200 の数値)によって識別されます。事前に定義された既知のコミュニティの一部を、次に示します。
■![]() internet :このルートをインターネット コミュニティにアドバタイズします。すべてのルータが所属します。
internet :このルートをインターネット コミュニティにアドバタイズします。すべてのルータが所属します。
■![]() no-export :EBGP ピアにこのルートをアドバタイズしません。
no-export :EBGP ピアにこのルートをアドバタイズしません。
■![]() no-advertise :どのピア(内部または外部)にもこのルートをアドバタイズしません。
no-advertise :どのピア(内部または外部)にもこのルートをアドバタイズしません。
■![]() local-as : ローカルな AS 外部のピアにこのルートをアドバタイズしません。
local-as : ローカルな AS 外部のピアにこのルートをアドバタイズしません。
コミュニティに基づき、他のネイバーに許可、送信、配信するルーティング情報を制御できます。BGP スピーカーは、ルートを学習、アドバタイズ、または再配信するときに、ルートのコミュニティを設定、追加、または変更します。ルートを集約すると、作成された集約内の COMMUNITIES 属性に、すべての初期ルートの全コミュニティが含まれます。
コミュニティ リストを使用すると、ルート マップの match 句で使用されるコミュニティ グループを作成できます。さらに、アクセス リストの場合と同様、一連のコミュニティ リストを作成することもできます。ステートメントは一致が見つかるまでチェックされ、1 つのステートメントが満たされると、テストは終了します。
コミュニティに基づいて COMMUNITIES 属性および match 句を設定するには、ルート マップによるルーティング情報の再配信に記載されている match community-list および set community ルート マップ コンフィギュレーション コマンドを参照してください。
デフォルトでは、COMMUNITIES 属性はネイバーに送信されません。COMMUNITIES 属性が特定の IP アドレスのネイバーに送信されるように指定するには、 neighbor send-community ルータ コンフィギュレーション コマンドを使用します。
はじめる前に
BGP ルーティングのイネーブル化の説明に従って、BGP ルーティングをイネーブルにします。
手順の詳細
例
次の例では、標準コミュニティ リストが、自律システム 50000 のネットワーク 10 からのルートを許可するように設定されます。
次に示すルータ コンフィギュレーション モードの例では、ルータが自律システム 109 に属していて、IP アドレス 172.16.70.23 のネイバーにコミュニティ属性を送信するように設定します。
次の例では、32 ビットの数値のコミュニティ形式を使用するルータを、AA:NN 形式を使用するようにアップグレードしています。
次の出力例は、bgp-community new-format コマンドがイネーブルになっている場合に BGP コミュニティ番号がどのように表示されるかを示しています。
BGP ネイバーおよびピア グループの設定
通常、BGP ネイバーの多くは同じアップデート ポリシー(同じアウトバウンド ルート マップ、配信リスト、フィルタ リスト、アップデート送信元など)を使用して設定されます。アップデート ポリシーが同じネイバーをピア グループにまとめると設定が簡単になり、アップデートの効率が高まります。多数のピアを設定した場合は、この方法を推奨します。
BGP ピア グループを設定するには、ピア グループを作成し、そこにオプションを割り当てて、ピア グループ メンバーとしてネイバーを追加します。ピア グループを設定するには、 neighbor ルータ コンフィギュレーション コマンドを使用します。デフォルトでは、ピア グループ メンバーは remote-as(設定されている場合)、version、update-source、out-route-map、out-filter-list、out-dist-list、minimum-advertisement-interval、next-hop-self など、ピア グループの設定オプションをすべて継承します。すべてのピア グループ メンバーは、ピア グループに対する変更を継承します。また、アウトバウンド アップデートに影響しないオプションを無効にするように、メンバーを設定することもできます。
各ネイバーに設定オプションを割り当てるには、ネイバーの IP アドレスを使用し、次に示すルータ コンフィギュレーション コマンドのいずれかを指定します。ピア グループにオプションを割り当てるには、ピア グループ名を使用し、いずれかのコマンドを指定します。 neighbor shutdown ルータ コンフィギュレーション コマンドを使用すると、すべての設定情報を削除せずに、BGP ピアまたはピア グループをディセーブルにできます。
はじめる前に
BGP ルーティングのイネーブル化の説明に従って、BGP ルーティングをイネーブルにします。
手順の詳細
既存の BGP ネイバーまたはネイバーピアグループをディセーブルにするには、 neighbor shutdown ルータ コンフィギュレーション コマンドを使用します。ディセーブル化されている既存のネイバーまたはネイバーピアグループをイネーブルにするには、 no neighbor shutdown ルータ コンフィギュレーション コマンドを使用します。
例
次に、ピアグループを設定し、そのピアグループの BGP ルーティングアップデートの最小送信間隔を 10 秒に設定する例を示します。
集約アドレスの設定
クラスレスドメイン間ルーティング(CIDR)を使用すると、集約ルート(またはスーパーネット)を作成して、ルーティングテーブルのサイズを最小化できます。 BGP 内に集約ルートを設定するには、集約ルートを BGP に再配信するか、または BGP ルーティング テーブル内に集約エントリを作成します。BGP テーブル内に特定のエントリがさらに 1 つまたは複数存在する場合は、BGP テーブルに集約アドレスが追加されます。
はじめる前に
BGP ルーティングのイネーブル化の説明に従って、BGP ルーティングをイネーブルにします。
手順の詳細
集約エントリを削除するには、 no aggregate-address address mask ルータ コンフィギュレーション コマンドを使用します。オプションをデフォルト値に戻すには、キーワードを指定してコマンドを使用します。
例
次に、集約 BGP アドレスがルータ コンフィギュレーション モードで作成される例を示します。このルートにアドバタイズされるパスは、集約中のすべてのパス内に含まれるすべての要素で構成される AS_SET になります。
次に、MAP-ONE というルート マップが作成され、AS-path アクセス リストで一致する例を示します。このルートにアドバタイズされるパスは、ルート マップで照合されるパスに含まれる要素で構成される AS_SET になります。
ルーティング ドメイン連合の設定
IBGP メッシュを削減する方法の 1 つは、自律システムを複数のサブ自律システムに分割して、単一の自律システムとして認識される単一の連合にグループ化することです。各自律システムは内部で完全にメッシュ化されていて、同じコンフェデレーション内の他の自律システムとの間には数本の接続があります。異なる自律システム内にあるピアでは EBGP セッションが使用されますが、ルーティング情報は IBGP ピアと同様な方法で交換されます。具体的には、ネクスト ホップ、MED、およびローカル プリファレンス情報は維持されます。すべての自律システムで単一の IGP を使用できます。
はじめる前に
BGP ルーティングのイネーブル化の説明に従って、BGP ルーティングをイネーブルにします。
手順の詳細
|
|
|
|
|---|---|---|
bgp confederation peers autonomous-system [ autonomous-system ...] |
||
例
次の例では、ルーティングドメインは自律システム 50001、50002、50003、50004、50005、および 50006 に分割され、コンフェデレーション ID 50007 によって識別されます。ネイバー 10.2.3.4 は、ルーティング ドメイン コンフェデレーションの内部にあるピアです。ネイバー 10.4.5.6 は、ルーティング ドメイン コンフェデレーションの外部にあるピアです。外部ピアとルーティングドメインに対して、このコンフェデレーションは番号 50007 の単一自律システムであると示されます。
BGP ルート リフレクタの設定
BGP では、すべての IBGP スピーカーを完全メッシュ構造にする必要があります。外部ネイバーからルートを受信したルータは、そのルートをすべての内部ネイバーにアドバタイズする必要があります。ルーティング情報のループを防ぐには、すべての IBGP スピーカーを接続する必要があります。内部ネイバーは、内部ネイバーから学習されたルートを他の内部ネイバーに送信しません。
ルート リフレクタを使用すると、学習されたルートをネイバーに渡す場合に他の方法が使用されるため、すべての IBGP スピーカーを完全メッシュ構造にする必要はありません。IBGP ピアをルートリフレクタに設定すると、その IBGP ピアは IBGP によって学習されたルートを一連の IBGP ネイバーに送信するようになります。ルートリフレクタの内部ピアには、クライアントピアと非クライアントピア(AS 内の他のすべてのルータ)の 2 つのグループがあります。ルート リフレクタは、これらの 2 つのグループ間でルートを反映させます。ルート リフレクタおよびそのクライアント ピアは、 クラスタ を形成します。非クライアント ピアは相互に完全メッシュ構造にする必要がありますが、クライアント ピアはその必要はありません。クラスタ内のクライアントは、そのクラスタ外の IBGP スピーカーと通信しません。
アドバタイズされたルートを受信したルート リフレクタは、ネイバーに応じて、次のいずれかのアクションを実行します。
■![]() 外部 BGP スピーカーからのルートをすべてのクライアントおよび非クライアント ピアにアドバタイズします。
外部 BGP スピーカーからのルートをすべてのクライアントおよび非クライアント ピアにアドバタイズします。
■![]() 非クライアント ピアからのルートをすべてのクライアントにアドバタイズします。
非クライアント ピアからのルートをすべてのクライアントにアドバタイズします。
■![]() クライアントからのルートをすべてのクライアントおよび非クライアント ピアにアドバタイズします。したがって、クライアントを完全メッシュ構造にする必要はありません。
クライアントからのルートをすべてのクライアントおよび非クライアント ピアにアドバタイズします。したがって、クライアントを完全メッシュ構造にする必要はありません。
通常、クライアントのクラスタにはルート リフレクタが 1 つあり、クラスタはルート リフレクタのルータ ID で識別されます。冗長性を高めて、シングル ポイントでの障害を回避するには、クラスタに複数のルート リフレクタを設定する必要があります。このように設定した場合は、ルート リフレクタが同じクラスタ内のルート リフレクタからのアップデートを認識できるように、クラスタ内のすべてのルート リフレクタに同じクラスタ ID(4 バイト)を設定する必要があります。クラスタを処理するすべてのルート リフレクタは完全メッシュ構造にし、一連の同一なクライアント ピアおよび非クライアント ピアを設定する必要があります。
はじめる前に
BGP ルーティングのイネーブル化の説明に従って、BGP ルーティングをイネーブルにします。
手順の詳細
例
次のルータ コンフィギュレーション モードの例では、ローカルルータはルートリフレクタです。これは、学習した IBGP ルートを 172.16.70.24 のネイバーに渡します。
ルート ダンプニングの設定
ルート フラップ ダンプニングを使用すると、インターネットワーク全体におけるフラッピング ルートの伝播を最小限に抑制できます。ルートの状態が使用可能、使用不可能、使用可能、使用不可能という具合に、繰り返し変化する場合、ルートはフラッピングと見なされます。ルートダンプニングがイネーブルの場合は、フラッピングしているルートにペナルティ値が割り当てられます。ルートの累積ペナルティが、設定された制限値に到達すると、ルートが稼働している場合であっても、BGP はルートのアドバタイズメントを抑制します。再使用限度は、ペナルティと比較される設定可能な値です。ペナルティが再使用限度より小さくなると、起動中の抑制されたルートのアドバタイズメントが再開されます。
IBGP によって取得されたルートには、ダンプニングが適用されません。このポリシーにより、IBGP ピアのペナルティが AS 外部のルートよりも大きくなることはありません。
はじめる前に
BGP ルーティングのイネーブル化の説明に従って、BGP ルーティングをイネーブルにします。
手順の詳細
フラップダンプニングをディセーブルにするには、キーワードを指定しないで no bgp dampening ルータ コンフィギュレーション コマンドを使用します。ダンプニング係数をデフォルト値に戻すには、値を指定して no bgp dampening ルータ コンフィギュレーション コマンドを使用します。
例
次の例では、BLUE という名前のルートマップを使用してフィルタリングされたプレフィックスに BGP ダンプニングが適用されます。
BGP のモニタリングおよびメンテナンス
特定のキャッシュ、テーブル、またはデータベースのすべての内容を削除できます。この作業は、特定の構造の内容が無効になる場合、または無効である疑いがある場合に必要となります。
BGP ルーティング テーブル、キャッシュ、データベースの内容など、特定の統計情報を表示できます。さらに、リソースの利用率を取得したり、ネットワーク問題を解決するための情報を使用することもできます。さらに、ノードの到達可能性に関する情報を表示し、デバイスのパケットが経由するネットワーク内のルーティング パスを検出することもできます。
また、 bgp log-neighbor changes ルータ コンフィギュレーション コマンドを使用し、BGP ネイバーをリセット、起動、またはダウンさせるときに生成されるメッセージのロギングをイネーブルにすることもできます。
ISO CLNS ルーティングの設定
国際標準化機構(ISO)コネクションレス型ネットワーク サービス(CLNS)プロトコルとは、オープン システム インターコネクション(OSI)モデルのネットワーク層の標準の 1 つです。ISO ネットワーク アーキテクチャ内のアドレスは、ネットワーク サービス アクセス ポイント(NSAP)アドレスおよび Network Entity Titles(NETs)と呼ばれます。OSI ネットワークの各ノードには、1 つ以上の NETs が含まれます。さらに、各ノードには、多数の NSAP アドレスが含まれます。
スイッチ上で、 clns routing グローバル コンフィギュレーション コマンドを使用してコネクションレス型ルーティングをイネーブルにすると、スイッチはルーティング関連の機能を果たさず、転送の決定だけを行います。ダイナミック ルーティングには、ルーティング プロトコルもイネーブルにする必要があります。スイッチは、ISO CLNS ネットワークの Intermediate System-to-Intermediate System(IS-IS)ダイナミック ルーティング プロトコルをサポートします。このルーティングプロトコルは、エリアの概念をサポートします。1 つのエリア内部では、すべてのルータがすべてのシステム ID に到達する方法を認識しています。エリア間では、ルータは適切なエリアに到達する方法を認識しています。IS-IS は、ステーションルーティング(1 つのエリア内)およびエリアルーティング(エリア間)という 2 つのレベルのルーティングをサポートします。
ISO IGRP と IS-IS NSAP アドレス方式の主な違いは、エリア アドレスの定義にあります。両方ともレベル 1 ルーティング(1 つのエリア内)にはシステム ID を使用します。ただし、エリア ルーティングに関してアドレスが指定される方法が異なります。ISO IGRP NSAP アドレスには、ドメイン、エリア、およびシステム ID という 3 つの異なるフィールドが含まれます。IS-IS アドレスには、単一の連続的エリアフィールド(ドメインフィールドおよびエリアフィールドから成る)とシステム ID という 2 つのフィールドが含まれます。
ISO CLNS の詳細については、関連資料に記載されている ISO CLNS のドキュメントを参照してください。
IS-IS ダイナミック ルーティングの設定
IS-IS は、ISO のダイナミック ルーティング プロトコルです。IS-IS をイネーブルにするには、IS-IS ルーティング プロセスを作成したうえで、それをネットワークではなく、特定のインターフェイスに割り当てる必要があります。マルチエリア IS-IS コンフィギュレーション構文を使用することで、レイヤ 3 スイッチまたはルータごとに複数の IS-IS ルーティング プロトコルを指定できます。その後、IS-IS ルーティング プロセスのインスタンスごとにパラメータを設定します。
小規模の IS-IS ネットワークは、ネットワーク内にすべてのルータが含まれる単一のエリアとして構築されます。ネットワークの規模が大きくなるに従って、このネットワークは、すべてのエリアに属する、接続されたすべてのレベル 2 ルータのセットから構成されるバックボーン エリア内に再編成され、その後、このネットワークはローカル エリアに接続されます。ローカル エリア内部では、すべてのルータがすべてのシステム ID に到達する方法を認識しています。エリア間では、ルータはバックボーンへの到達方法を認識しており、バックボーン ルータは他のエリアに到達する方法を認識しています。
ルータは、ローカル エリア内でルーティングを実行するために、レベル 1 の隣接関係を確立します(ステーション ルーティング)。ルータは、レベル 1 のエリア間でルーティングを実行するために、レベル 2 の隣接関係を確立します(エリア ルーティング)。
1 つの Cisco ルータは、最大 29 エリアのルーティングに参加でき、バックボーンでレベル 2 ルーティングを実行できます。一般に、ルーティング プロセスごとに 1 つのエリアに対応します。デフォルトでは、ルーティング プロセスの最初のインスタンスが、レベル 1 および レベル 2 両方のルーティングを実行するように設定されます。追加のルーティング インスタンスを設定できます。このインスタンスは、自動的にレベル 1 エリアとして扱われます。IS-IS ルーティング プロセスの各インスタンスごとに個別にパラメータを設定する必要があります。
IS-IS マルチエリア ルーティングでは、シスコの各装置に対して最大 29 個の レベル 1 エリアを定義できますが、レベル 2 ルーティングを実行するプロセスは 1 つだけ設定できます。レベル 2 ルーティングが任意のプロセス上に設定されている場合、追加のプロセスは、すべて自動的にレベル 1 に設定されます。同時に、このプロセスがレベル 1 ルーティングを実行するように設定することもできます。ルータ インスタンスにレベル 2 ルーティングが必要でない場合は、 is-type グローバル コンフィギュレーション コマンドを使用してレベル 2 の機能を削除します。別のルータ インスタンスをレベル 2 ルータとして設定する場合にも is-type コマンドを使用します。
ここでは、IS-IS ルーティングの設定方法を簡単に説明します。IS-IS の詳細については、関連資料に記載されている IS-IS のドキュメントを参照してください。
IS-IS のデフォルト設定
|
|
|
|---|---|
従来型の IS-IS:ルータは、レベル 1(ステーション)とレベル 2(エリア) 両方のルータとして機能します。 マルチエリア IS-IS:IS-IS ルーティング プロセスの最初のインスタンスが レベル 1-2 ルータです。残りのインスタンスは、レベル 1 ルータです。 |
|
NSF7 認識 |
イネーブル8。レイヤ 3 スイッチでは、ハードウェアやソフトウェアの変更中に、隣接する NSF 対応ルータからのパケットを転送し続けることができます。 |
ディセーブル。イネーブルの際に引数が入力されない場合、過負荷ビットがただちに設定され、 no set-overload-bit コマンドが入力されるまで設定されたままになります。 |
|
|
8.IS-IS NSF 認識は、IP サービスイメージを実行しているスイッチでは IPv4 に対してイネーブルになっています。 |
NSF 認識
統合 IS-IS NSF 認識機能は IP サービスイメージの IPv4 でサポートされています。この機能により、NSF を認識する顧客宅内装置(CPE)ルータが、NFS 対応ルータによるパケットのノンストップ転送を実現します。ローカル ルータでは、必ずしも NSF を実行している必要はありませんが、このルータが NSF を認識していると、スイッチオーバー プロセス時にルーティング データベースの整合性と精度、および隣接 NSF 対応ルータ上のリンクステート データベースが保持されます。
この機能は、自動的にイネーブルにされ、設定は必要ありません。この機能の詳細については、『 High Availability Configuration Guide, Cisco IOS Release 15S 』の「 Configuring Nonstop Forwarding 」を参照してください。
IS-IS ルーティングのイネーブル化
IS-IS をイネーブルにするには、各ルーティング プロセスに名前と NET を指定します。その後、インターフェイス上で IS-IS ルーティングをイネーブルにし、ルーティング プロセスの各インスタンスに対してエリアを指定します。
はじめる前に
IS-IS を設定する前にネットワーク設計およびそれを経由するトラフィックのフロー方法を知っておく必要があります。エリアを定義し、デバイスのアドレッシング計画を準備し(NET の定義を含む)、統合 IS-IS を実行するインターフェイスを決定します。検証を容易にするため、デバイスを設定する前に、隣接関係テーブルに含まれると予想されるネイバーを示す、隣接関係のマトリックスを準備する必要があります。
手順の詳細
IS-IS ルーティングをディセーブルにするには、 no router isis area-tag ルータ コンフィギュレーション コマンドを使用します。
例
次に、従来型の IS-IS を IP ルーティング プロトコルとして実行するために 3 つのルータを設定する方法を示します。従来型の IS-IS では、すべてのルータはレベル 1 およびレベル 2 のルータとして機能します(デフォルト)。
IS-IS グローバル パラメータの設定
設定可能ないくつかのオプションの IS-IS グローバル パラメータを次に示します。
■![]() ルート マップによって制御されるデフォルト ルートを設定することで、デフォルト ルートを IS-IS ルーティング ドメイン内に強制的に設定できます。ルート マップで設定可能な、その他のフィルタリング オプションも指定できます。
ルート マップによって制御されるデフォルト ルートを設定することで、デフォルト ルートを IS-IS ルーティング ドメイン内に強制的に設定できます。ルート マップで設定可能な、その他のフィルタリング オプションも指定できます。
■![]() 内部チェックサム エラーとともに受信された IS-IS LSP を無視したり、破損した LSP を消去するようにルータを設定できます。これにより、LSP の発信側は、LSP を再生成します。
内部チェックサム エラーとともに受信された IS-IS LSP を無視したり、破損した LSP を消去するようにルータを設定できます。これにより、LSP の発信側は、LSP を再生成します。
■![]() サマリー アドレスを使用して、ルーティング テーブル内に表示される集約アドレスを作成できます(経路集約)。他のルーティング プロトコルから学習したルートも集約できます。サマリーをアドバタイズするのに使用されるメトリックは、すべての個別ルートにおける最小のメトリックです。
サマリー アドレスを使用して、ルーティング テーブル内に表示される集約アドレスを作成できます(経路集約)。他のルーティング プロトコルから学習したルートも集約できます。サマリーをアドバタイズするのに使用されるメトリックは、すべての個別ルートにおける最小のメトリックです。
■![]() LSP リフレッシュ インターバルおよび LSP がリフレッシュなしでルータ データベース内にとどまることができる最大時間を設定できます。
LSP リフレッシュ インターバルおよび LSP がリフレッシュなしでルータ データベース内にとどまることができる最大時間を設定できます。
■![]() LSP 生成に対するスロットリング タイマー、最短パス優先計算、および部分ルート計算を設定できます。
LSP 生成に対するスロットリング タイマー、最短パス優先計算、および部分ルート計算を設定できます。
■![]() IS-IS 隣接関係がステートを変更(アップまたはダウン)する際に、スイッチがログ メッセージを生成するように設定できます。
IS-IS 隣接関係がステートを変更(アップまたはダウン)する際に、スイッチがログ メッセージを生成するように設定できます。
■![]() ネットワーク内のリンクが、1500 バイト未満の最大伝送単位(MTU)サイズの場合、それでもルーティングが行われるように LSP MTU の値を低くできます。
ネットワーク内のリンクが、1500 バイト未満の最大伝送単位(MTU)サイズの場合、それでもルーティングが行われるように LSP MTU の値を低くできます。
■![]() パーティション回避ルータ コンフィギュレーション コマンドは、レベル 1-2 境界ルータ、隣接レベル 1 ルータ、およびエンド ホスト間で完全な接続が失われた場合に、エリアがパーティション化されるのを防ぎます。
パーティション回避ルータ コンフィギュレーション コマンドは、レベル 1-2 境界ルータ、隣接レベル 1 ルータ、およびエンド ホスト間で完全な接続が失われた場合に、エリアがパーティション化されるのを防ぎます。
はじめる前に
IS-IS ルーティングのイネーブル化の説明に従って、IS-IS ルーティングをイネーブルにします。
手順の詳細
デフォルトルート生成をディセーブルにするには、 no default-information originate ルータ コンフィギュレーション コマンドを使用します。 no area-password または no domain-password ルータ コンフィギュレーション コマンドを使用して、パスワードをディセーブルにします。LSP MTU 設定をディセーブルにするには、 no lsp mtu ルータ コンフィギュレーション コマンドを使用します。サマリーアドレス指定、LSP リフレッシュインターバル、LSP ライフタイム、LSP タイマー、SFP タイマー、および PRC タイマーをデフォルト状態に戻すには、コマンドの no 形式を使用します。 no partition avoidance ルータ コンフィギュレーション コマンドを使用して、出力形式をディセーブルにします。
例
IS-IS インターフェイス パラメータの設定
任意で、特定のインターフェイス固有の IS-IS パラメータを、付加されている他のルータとは別に設定できます。ただし、一部の値(乗数およびタイム インターバルなど)をデフォルトから変更する場合、複数のルータおよびインターフェイス上でもこれを変更する必要があります。ほとんどのインターフェイス パラメータは、レベル 1、レベル 2、またはその両方で設定できます。
次に、設定可能なインターフェイス レベル パラメータの一部を示します。
■![]() インターフェイスのデフォルト メトリック:Quality of Service(QoS)ルーティングが実行されない場合に、IS-IS メトリックの値として使用され、割り当てられます。
インターフェイスのデフォルト メトリック:Quality of Service(QoS)ルーティングが実行されない場合に、IS-IS メトリックの値として使用され、割り当てられます。
■![]() hello インターバル(インターフェイスから送信される hello パケットの間隔)またはデフォルトの hello パケット乗数:インターフェイス上で使用されて、IS-IS hello パケットで送信されるホールド タイムを決定します。ホールド タイムは、ネイバーがダウンしていると宣言するまでに、別の hello パケットを待機する時間を決定します。これにより、障害リンクまたはネイバーが検出される速さも決定し、ルートを再計算できるようになります。hello パケットが頻繁に失われ、IS-IS 隣接に無用な障害が発生する場合は、hello 乗数を変更してください。hello 乗数を大きくし、それに対応して hello インターバルを小さくすると、リンク障害を検出するのに必要な時間を増やすことなく、hello プロトコルの信頼性を高めることができます。
hello インターバル(インターフェイスから送信される hello パケットの間隔)またはデフォルトの hello パケット乗数:インターフェイス上で使用されて、IS-IS hello パケットで送信されるホールド タイムを決定します。ホールド タイムは、ネイバーがダウンしていると宣言するまでに、別の hello パケットを待機する時間を決定します。これにより、障害リンクまたはネイバーが検出される速さも決定し、ルートを再計算できるようになります。hello パケットが頻繁に失われ、IS-IS 隣接に無用な障害が発生する場合は、hello 乗数を変更してください。hello 乗数を大きくし、それに対応して hello インターバルを小さくすると、リンク障害を検出するのに必要な時間を増やすことなく、hello プロトコルの信頼性を高めることができます。
–![]() Complete Sequence Number PDU(CSNP)インターバルCSNP は、指定ルータにより送信され、データベースの同期を維持します。
Complete Sequence Number PDU(CSNP)インターバルCSNP は、指定ルータにより送信され、データベースの同期を維持します。
–![]() 再送信インターバルこれは、ポイントツーポイント リンクの IS-IS LSP の再送信間隔です。
再送信インターバルこれは、ポイントツーポイント リンクの IS-IS LSP の再送信間隔です。
–![]() IS-IS LSP 再送信スロットル インターバルこれは、IS-IS LSP がポイントツーポイントリンクで再送信される最大レート(パケット間のミリ秒数)です。このインターバルは、同じ LSP が連続する再送信間隔である再送信インターバルとは異なります。
IS-IS LSP 再送信スロットル インターバルこれは、IS-IS LSP がポイントツーポイントリンクで再送信される最大レート(パケット間のミリ秒数)です。このインターバルは、同じ LSP が連続する再送信間隔である再送信インターバルとは異なります。
■![]() 指定ルータの選択プライオリティ:マルチアクセス ネットワークで必要な隣接数を削減し、その代わりに、ルーティング プロトコル トラフィックの量およびトポロジ データベースのサイズを削減できます。
指定ルータの選択プライオリティ:マルチアクセス ネットワークで必要な隣接数を削減し、その代わりに、ルーティング プロトコル トラフィックの量およびトポロジ データベースのサイズを削減できます。
はじめる前に
IS-IS ルーティングのイネーブル化の説明に従って、IS-IS ルーティングをイネーブルにします。
手順の詳細
例
次の area1 という名前の IS-IS ルーティング プロセスの設定例では、IS-IS インターフェイスに対するグローバル デフォルト メトリックに 111 を設定しています。
IS-IS のモニタリングおよびメンテナンス
CLNS キャッシュのすべての内容または特定のネイバーまたはルートの情報を削除できます。ルーティング テーブル、キャッシュ、およびデータベースの内容など、特定の CLNS または IS-IS の統計情報を表示できます。また、特定のインターフェイス、フィルタ、またはネイバーに関する情報も表示できます。
|
|
|
|---|---|
BFD の設定
双方向フォワーディング検出(BFD)プロトコルは、さまざまなメディア タイプ、カプセル化、トポロジ、およびルーティング プロトコルの転送パス障害を迅速に検出します。2 つのシステム間で転送されるデータ プロトコルの上位でユニキャスト、ポイントツーポイント モードで動作し、直接接続されたネイバー間の IPv4 接続を追跡します。BFD パケットは UDP パケット内に 3784 ~ 3785 の宛先ポート番号でカプセル化されます。
EIGRP、IS-IS、および OSPF の配置では、BFD に最も近い代替方法は、修正された障害検出メカニズムの使用です。EIGRP、IS-IS、および OSPF タイマーを短縮すると障害検出レートを 1 ~ 2 秒にすることができますが、BFD は障害検出を 1 秒未満にすることができます。BFD はタイマーの短縮よりも CPU の負担が少なく、特定のルーティング プロトコルに限定されないため、複数のルーティング プロトコルでの汎用の一貫した障害検出メカニズムとして使用できます。
BFD セッションを作成するには、両方のシステム(BFD ピア)で BFD を設定する必要があります。BFD ピアのインターフェイスおよびルーティング プロトコル レベルで BFD をイネーブルにすると、BFD セッションが作成されます。BFD タイマーがネゴシエーションされ、BFD ピアはネゴシエーションされた間隔で制御パケットを相互に送信します。ネイバーが直接接続されていない場合、BFD ネイバー登録は拒否されます。
図 104に、OSPF と BFD を実行する 2 台のルータがある単純なネットワークを示します。OSPF がネイバーを検出すると(1)、BFD プロセスに対してネイバー OSPF ルータとの BFD ネイバー セッションを開始するように要求し(2)、BFD ネイバー セッションを確立します(3)。
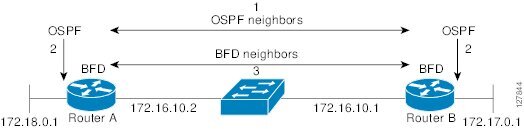
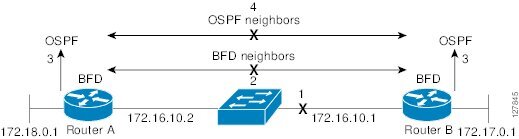
図 105に、ネットワーク(1)で障害が発生した場合を示します。OSPF ネイバーとの BFD ネイバー セッションは閉じられます(2)。BFD は BFD ネイバーが到達不可能になったことを OSPF プロセスに通知し、OSPF プロセスは OSPF ネイバー関係を切断します(4)。代替パスが使用可能な場合、ルータはそのパスでコンバージェンスを開始します。
BFD クライアントは、ネイバーを BFD に登録するルーティング プロトコルです。スイッチは、IS-IS、OSPF v1 および v2、BGP、EIGRP、およびホット スタンバイ ルータ プロトコル(HSRP)クライアントをサポートします。1 つの BFD セッションを複数のクライアント プロトコルに対して使用できます。たとえば、ネットワークで同じピアへの同じリンクで OSPF および EIGRP が実行されている場合、作成する必要がある BFD セッションは 1 つだけであり、情報は両方のルーティング プロトコルで共有されます。
スイッチは、BFD バージョン 0 およびバージョン 1 をサポートします。BFD ネイバーは自動的にバージョンをネゴシエーションし、プロトコルは常に上位のバージョンで実行されます。デフォルトのバージョンはバージョン 1 です。
デフォルトでは、BFD ネイバーは、転送障害を検出するために制御パケットとエコー パケットの両方を交換します。スイッチでは、設定された BFD イータバル(50 ~ 999 ミリ秒)でエコー パケットが送信されます。また制御パケットは、BFD のスロータイマー レート(1000 ~ 3000 ミリ秒)で送信されます。
障害レート検出は BFD エコー モードの方が速く、このモードは BFD セッションを設定するとデフォルトでイネーブルになります。このモードでは、スイッチは BFD ソフトウェア レイヤからパケットを送信し、BFD ネイバーは高速スイッチング レイヤによってエコー パケットに応答します。エコー パケットは BFD ネイバーのソフトウェア レイヤに到達しませんが、障害検出用の転送パスによって反映されます。各 BFD インターフェイスが BFD エコーパケットを送信するレートを設定するには、 bfd interval インターフェイス コンフィギュレーション コマンドを入力します。
帯域幅の使用量を削減するために、 no bfd echo インターフェイス コンフィギュレーション コマンドを入力して、エコーパケットの送信をディセーブルにすることができます。エコー モードがディセーブルの場合、フォワーディングの障害検出には制御パケットが使用されます。制御パケットは、設定されたスロータイマー レートで交換されます。そのため、障害検出に要する時間が長くなる場合があります。スロータイマーレートの設定は、 bfd slow-timer グローバル コンフィギュレーション コマンドで行います。設定できる範囲は 1000 ~ 3000 ミリ秒で、デフォルトは 1000 ミリ秒です。
エコー処理は、BFD ネイバーの設定とは独立したスイッチ インターフェイスで、イネーブルとディセーブルを切り替えられます。エコー モードをディセーブルにしても、インターフェイスからのエコー パケット送信がディセーブルになるだけです。エコー パケットを受信する高速スイッチング レイヤでは常に、エコー パケットが送信者へ返送されます。
スイッチで BFD を実行するには、基本的な BFD インターバル パラメータを BFD インターフェイスで設定し、スイッチでルーティングをイネーブルにし、BFD 用に 1 つまたは複数のルーティング プロトコル クライアントをイネーブルにする必要があります。また、参加するスイッチでシスコ エクスプレス フォワーディング(CEF)がイネーブル(デフォルト)であることを確認する必要もあります。
設定およびコマンドの詳細については、関連資料に記載されている BFD のドキュメントを参照してください。
■![]() インターフェイスでの BFD セッション パラメータの設定
インターフェイスでの BFD セッション パラメータの設定
■![]() BFD ルーティング プロトコル クライアントのイネーブル化
BFD ルーティング プロトコル クライアントのイネーブル化
デフォルトの BFD の設定
■![]() BFD セッションは設定されていません。すべてのインターフェイスで BFD はディセーブルです。
BFD セッションは設定されていません。すべてのインターフェイスで BFD はディセーブルです。
■![]() 設定する場合、BFD バージョン 1 がデフォルトですが、バージョンはスイッチによってネゴシエーションされます。バージョン 0 もサポートされます。
設定する場合、BFD バージョン 1 がデフォルトですが、バージョンはスイッチによってネゴシエーションされます。バージョン 0 もサポートされます。
BFD のデフォルト設定に関する注意事項
スイッチで同時に使用できる BFD セッションの数は 最大で 28 です。
スイッチで BFD を実行するには、次の作業を行います。
■![]() BFD セッションを実行する各インターフェイスで、基本的な BFD インターバル パラメータを設定します。
BFD セッションを実行する各インターフェイスで、基本的な BFD インターバル パラメータを設定します。
■![]() スイッチ上でルーティングをイネーブルに設定します。ルーティングをイネーブルにしなくても BFD を設定できますが、スイッチおよび BFD インターフェイスでルーティングがイネーブルにならないかぎり、BFD セッションはアクティブになりません。
スイッチ上でルーティングをイネーブルに設定します。ルーティングをイネーブルにしなくても BFD を設定できますが、スイッチおよび BFD インターフェイスでルーティングがイネーブルにならないかぎり、BFD セッションはアクティブになりません。
■![]() BFD 用に 1 つまたは複数のルーティング プロトコル クライアントをイネーブルにします。使用しているルーティング プロトコルの高速コンバージェンスを実装する必要があります。
BFD 用に 1 つまたは複数のルーティング プロトコル クライアントをイネーブルにします。使用しているルーティング プロトコルの高速コンバージェンスを実装する必要があります。
注: 特に EIGRP を使用する場合は、ルーティング プロトコル コマンドを設定する前に、インターフェイスで BFD インターバルパラメータを設定することを推奨します。
IP ルーティングと同様に、参加するスイッチで CEF がイネーブル(デフォルト)であることを確認します。
BFD は、ルーティング インターフェイスとして設定されている物理インターフェイスでサポートされます。レイヤ 2 インターフェイス、疑似回線、スタティック ルート、SVI インターフェイス、およびポート チャネルではサポートされていません。
BFD インターフェイス コマンドをレイヤ 2 ポートで設定できますが、レイヤ 3 インターフェイスとして設定され(no switchport)、IP アドレスが割り当てられないかぎり、BFD セッションはインターフェイスで動作しません。
HSRP BFD では、スタンバイ BFD はデフォルトですべてのインターフェイスでグローバルにイネーブルです。これを 1 つのインターフェイスでディセーブルにする場合は、グローバルにディセーブルにして再度イネーブルにする必要があります。これにより、BFD セッションはアクティブになります。
BFD エコーモード(デフォルト)を使用する場合、BFD インターフェイスで no ip redirects インターフェイス コンフィギュレーション コマンドを入力して、ICMP リダイレクトメッセージの送信をディセーブルにする必要があります。
インターフェイスでの BFD セッション パラメータの設定
インターフェイスで BFD セッションを開始する前に、インターフェイスをレイヤ 3 モードにし、ベースライン BFD パラメータを設定する必要があります。
注: レイヤ 2 インターフェイスで BFD を設定できますが、両方のインターフェイスがレイヤ 3 モードになり、スイッチでルーティングがイネーブルになるまで、BFD セッションを開始できません。
はじめる前に
BFD のデフォルト設定に関する注意事項を参照してください。
手順の詳細
BFD パラメータ設定を削除するには、 no bfd interval インターフェイス コンフィギュレーション コマンドを入力します。
BFD ルーティング プロトコル クライアントのイネーブル化
インターフェイスで BFD パラメータを設定したあと、1 つまたは複数のルーティング プロトコルの BFD セッションを開始できます。スイッチで ip routing グローバル コンフィギュレーション コマンドを入力して、最初にルーティングをイネーブルにする必要があります。ルーティング プロトコルに応じて、インターフェイスで BFD セッションを開始する方法は複数ある場合があります。
OSPF の BFD の設定
OSPF の BFD セッションを開始する場合、参加するすべてのデバイスで OSPF が稼働している必要があります。OSPF の BFD サポートをイネーブルにするには、すべての OSPF インターフェイスでグローバルにイネーブルにするか、1 つまたは複数のインターフェイスでイネーブルにします。
OSPF の BFD のグローバルな設定
はじめる前に
■![]() インターフェイスでの BFD セッション パラメータの設定の説明に従って、BFD パラメータを設定します。
インターフェイスでの BFD セッション パラメータの設定の説明に従って、BFD パラメータを設定します。
■![]() OSPF の設定の説明に従って、OSPF を設定します。
OSPF の設定の説明に従って、OSPF を設定します。
手順の詳細
すべてのインターフェイスで OSPF BFD をディセーブルにするには、 no bfd all-interfaces ルータ コンフィギュレーション コマンドを入力します。特定のインターフェイスでディセーブルにするには、そのインターフェイス上で no ip osfp bfd または ip ospf bfd disable インターフェイス コンフィギュレーション コマンドを入力します。
1 つまたは少数のインターフェイスだけで OSPF BFD を実行する場合は、グローバルにイネーブルにしないで、それらのインターフェイス上で ip ospf bfd インターフェイス コンフィギュレーション コマンドを入力できます。次の手順を参照してください。
例
次に、すべての OSPF インターフェイスで OSPF の BFD をイネーブルにする例を示します。
インターフェイスでの OSPF の BFD の設定
はじめる前に
■![]() インターフェイスでの BFD セッション パラメータの設定の説明に従って、インターフェイスに BFD パラメータを設定します。
インターフェイスでの BFD セッション パラメータの設定の説明に従って、インターフェイスに BFD パラメータを設定します。
■![]() OSPF の設定の説明に従って、OSPF を設定します。
OSPF の設定の説明に従って、OSPF を設定します。
手順の詳細
|
|
|
|
|---|---|---|
指定された OSPF インターフェイス上で BFD をイネーブルにします。BFD セッションを実行するすべての OSPF インターフェイス上で、ステップ 3 および 4 を繰り返します。 |
||
インターフェイスで OSPF BFD をディセーブルにするには、インターフェイス上で no ip osfp bfd または ip ospf bfd disable インターフェイス コンフィギュレーション コマンドを入力します。
例
次に、単一のインターフェイスで OSPF の BFD をイネーブルにする例を示します。
IS-IS の BFD の設定
IS-IS の BFD セッションを開始する場合、BFD に参加するすべてのデバイスで IS-IS が稼働している必要があります。OSPF の BFD サポートをイネーブルにするには、すべての OSPF インターフェイスでグローバルにイネーブルにするか、1 つまたは複数のインターフェイスでイネーブルにします。
IS-IS の BFD のグローバルな設定
はじめる前に
■![]() インターフェイスでの BFD セッション パラメータの設定の説明に従って、インターフェイスに BFD パラメータを設定します。
インターフェイスでの BFD セッション パラメータの設定の説明に従って、インターフェイスに BFD パラメータを設定します。
■![]() IS-IS ダイナミック ルーティングの設定の説明に従って、IS-IS を設定します。
IS-IS ダイナミック ルーティングの設定の説明に従って、IS-IS を設定します。
手順の詳細
すべてのインターフェイスで IS-IS BFD をディセーブルにするには、 no bfd all-interfaces ルータ コンフィギュレーション コマンドを入力します。指定されたインターフェイスでディセーブルにするには、インターフェイス上で no isis bfd または isis bfd disable インターフェイス コンフィギュレーション コマンドを入力します。
少数のインターフェイスだけで IS-IS BFD を実行する場合は、グローバルにイネーブルにしないで、それらのインターフェイス上で isis bfd インターフェイス コンフィギュレーション コマンドを入力できます。次の手順を参照してください。
注: IS-IS BFD はレイヤ 3 インターフェイスだけで動作しますが、レイヤ 2 またはレイヤ 3 モードのインターフェイスで設定できます。イネーブルにすると、次のメッセージが表示されます。
%ISIS BFD is reverting to router mode configuration, and remains disabled.
例
次に、高速コンバージェンスを設定し、すべての IS-IS インターフェイスで IS-IS の BFD をイネーブルにする例を示します。
インターフェイスでの IS-IS の BFD の設定
はじめる前に
■![]() インターフェイスでの BFD セッション パラメータの設定の説明に従って、インターフェイスに BFD パラメータを設定します。
インターフェイスでの BFD セッション パラメータの設定の説明に従って、インターフェイスに BFD パラメータを設定します。
■![]() IS-IS ダイナミック ルーティングの設定の説明に従って、IS-IS を設定します。
IS-IS ダイナミック ルーティングの設定の説明に従って、IS-IS を設定します。
手順の詳細
|
|
|
|
|---|---|---|
指定された IS-IS インターフェイス上で BFD をイネーブルにします。BFD セッションを実行するすべての IS-IS インターフェイス上で、ステップ 3 および 4 を繰り返します。 |
||
インターフェイスで IS-IS BFD をディセーブルにするには、インターフェイス上で no isis bfd または isis bfd disable インターフェイス コンフィギュレーション コマンドを入力します。
例
次に、単一のインターフェイスで IS-IS の BFD をイネーブルにする例を示します。
BGP の BFD の設定
BGP の BFD セッションを開始する場合、参加するすべてのデバイスで BGP が稼働している必要があります。BGP の BFD をイネーブルにする BFD ネイバーの IP アドレスを入力します。
はじめる前に
■![]() インターフェイスでの BFD セッション パラメータの設定の説明に従って、インターフェイスに BFD パラメータを設定します。
インターフェイスでの BFD セッション パラメータの設定の説明に従って、インターフェイスに BFD パラメータを設定します。
■![]() BGP の設定の説明に従って、BGP を設定します。
BGP の設定の説明に従って、BGP を設定します。
手順の詳細
|
|
|
|
|---|---|---|
BGP BFD をディセーブルにするには、 no neighbor ip-address fall-over bfd ルータ コンフィギュレーション コマンドを入力します。
EIGRP の BFD の設定
EIGRP の BFD セッションを開始する場合、参加するすべてのデバイスで EIGRP が稼働している必要があります。EIGRP の BFD サポートをイネーブルにするには、すべての EIGRP インターフェイスでグローバルにイネーブルにするか、1 つまたは複数のインターフェイスでイネーブルにします。
はじめる前に
■![]() インターフェイスでの BFD セッション パラメータの設定の説明に従って、インターフェイスに BFD パラメータを設定します。
インターフェイスでの BFD セッション パラメータの設定の説明に従って、インターフェイスに BFD パラメータを設定します。
■![]() EIGRP の設定の説明に従って、EIGRP を設定します。
EIGRP の設定の説明に従って、EIGRP を設定します。
手順の詳細
すべてのインターフェイスで EIGRP BFD をディセーブルにするには、 no bfd all-interfaces ルータ コンフィギュレーション コマンドを入力します。1 つのインターフェイスでディセーブルにするには、 no bfd interface interface-id ルータ コンフィギュレーション コマンドを入力します。
HSRP の BFD の設定
HSRP は BFD をデフォルトでサポートしており、すべてのインターフェイスでグローバルにイネーブルです。HSRP のサポートを手動でディセーブルにした場合は、インターフェイスまたはグローバル コンフィギュレーション モードで再度イネーブルにすることができます。
はじめる前に
■![]() インターフェイスでの BFD セッション パラメータの設定の説明に従って、インターフェイスに BFD パラメータを設定します。
インターフェイスでの BFD セッション パラメータの設定の説明に従って、インターフェイスに BFD パラメータを設定します。
手順の詳細
|
|
|
|
|---|---|---|
BFD セッションのインターフェイスを指定し、インターフェイス コンフィギュレーション モードを開始します。BFD は物理インターフェイスだけでサポートされます。 |
||
すべてのインターフェイスで HSRP による BFD のサポートをディセーブルにするには、 no standby bfd all-interfaces グローバル コンフィギュレーション コマンドを入力します。1 つのインターフェイスでディセーブルにするには、 no standby bfd インターフェイス コンフィギュレーション コマンドを入力します。
注: no standby bfd インターフェイス コンフィギュレーション コマンドを入力して 1 つのインターフェイスでスタンバイ BFD をディセーブルにする場合、他のインターフェイスで BFD セッションをアクティブにするには、 no standby bfd all-interfaces グローバル コンフィギュレーション コマンドおよび standby bfd all-interfaces グローバル コンフィギュレーション コマンドを続けて入力して、グローバルにディセーブルにして再度イネーブルにする必要があります。
例
次に、スイッチで HSRP BFD ピアリングが無効になっている場合に、そのピアリングを再度イネーブルにする例を示します。
BFD エコー モードのディセーブル化
BFD セッションを設定すると、BFD インターフェイスで BFD エコー モードはデフォルトでイネーブルになります。インターフェイス上でエコー モードをディセーブルにすると、そのインターフェイスでは、エコー パケットは送信されず、ネイバーから受信したエコー パケットに限り返送されます。エコー モードがディセーブルの場合、フォワーディングの障害検出には制御パケットが使用されます。BFD 制御パケットの送信頻度を低くする場合は、スロー タイマーを設定します。
はじめる前に
インターフェイスでの BFD セッション パラメータの設定の説明に従って、インターフェイスに BFD パラメータを設定します。
手順の詳細
|
|
|
|
|---|---|---|
インターフェイスで BFD エコー モードをディセーブルにします。デフォルトではイネーブルですが、BFD ネイバーで個別にディセーブルにすることができます。 |
||
(任意)BFD のスロータイマーの値を設定します。指定できる範囲は 1000 ~ 30000 ミリ秒です。デフォルトは 1000 ミリ秒です。 |
||
スイッチ上でエコーモードをディセーブルにしたあと、再度イネーブルにするには、 bfd echo グローバル コンフィギュレーション モードを使用します。
例
次に、BFD ネイバー間でエコーモードをディセーブルにする例を示します。
Multi-VRF CE の設定
バーチャル プライベート ネットワーク(VPN)は、ISP バックボーン ネットワーク上でお客様にセキュアな帯域幅共有を提供します。VPN は、共通ルーティング テーブルを共有するサイトの集合です。カスタマー サイトは、1 つまたは複数のインターフェイスでサービス プロバイダー ネットワークに接続され、サービス プロバイダーは、VRF テーブルと呼ばれる VPN ルーティング テーブルと各インターフェイスを関連付けます。
スイッチは、カスタマー エッジ(CE)デバイスの複数の VRF(マルチ VRF)インスタンスをサポートしています(マルチ VRF CE)。サービスプロバイダーは、Multi-VRF CE により、重複する IP アドレスで複数の VPN をサポートできます。
注: スイッチでは、VPN のサポートのためにマルチプロトコル ラベル スイッチング(MPLS)が使用されません。MPLS VRF の詳細については、『 MPLS: Layer 3 VPNs Configuration Guide, Cisco IOS Release 15M&T 』を参照してください。
Multi-VRF CE に関する情報
マルチ VRF CE は、サービス プロバイダーが複数の VPN をサポートし、VPN 間で IP アドレスを重複して使用できるようにする機能です。Multi-VRF CE は入力インターフェイスを使用して、さまざまな VPN のルートを区別し、1 つまたは複数のレイヤ 3 インターフェイスと各 VRF を関連付けて仮想パケット転送テーブルを形成します。VRF 内のインターフェイスは、イーサネット ポートのように物理的なもの、または VLAN SVI のように論理的なものにもできますが、複数の VRF に属すことはできません。
注: Multi-VRF CE インターフェイスは、レイヤ 3 インターフェイスである必要があります。
■![]() お客様は、CE デバイスにより、1 つまたは複数のプロバイダー エッジ(PE)ルータへのデータ リンクを介してサービス プロバイダー ネットワークにアクセスできます。CE デバイスは、サイトのローカル ルートをルータにアドバタイズし、リモート VPN ルートをそこから取得します。Cisco Connected Grid スイッチは、CE にすることができます。
お客様は、CE デバイスにより、1 つまたは複数のプロバイダー エッジ(PE)ルータへのデータ リンクを介してサービス プロバイダー ネットワークにアクセスできます。CE デバイスは、サイトのローカル ルートをルータにアドバタイズし、リモート VPN ルートをそこから取得します。Cisco Connected Grid スイッチは、CE にすることができます。
■![]() PE ルータは、スタティック ルーティング、または BGP、RIPv2、OSPF、EIGRP などのルーティング プロトコルを使用して、CE デバイスとルーティング情報を交換します。PE では、直接接続している VPN の VPN ルートだけを維持すればよく、すべてのサービス プロバイダー VPN ルートを維持する必要はありません。各 PE ルータは、直接接続しているサイトごとに VRF を維持します。すべてのサイトが同じ VPN に存在する場合は、PE ルータの複数のインターフェイスを 1 つの VRF に関連付けることができます。各 VPN は、指定された VRF にマッピングされます。PE ルータは、ローカル VPN ルートを CE から学習したあとで、IBGP を使用して別の PE ルータと VPN ルーティング情報を交換します。
PE ルータは、スタティック ルーティング、または BGP、RIPv2、OSPF、EIGRP などのルーティング プロトコルを使用して、CE デバイスとルーティング情報を交換します。PE では、直接接続している VPN の VPN ルートだけを維持すればよく、すべてのサービス プロバイダー VPN ルートを維持する必要はありません。各 PE ルータは、直接接続しているサイトごとに VRF を維持します。すべてのサイトが同じ VPN に存在する場合は、PE ルータの複数のインターフェイスを 1 つの VRF に関連付けることができます。各 VPN は、指定された VRF にマッピングされます。PE ルータは、ローカル VPN ルートを CE から学習したあとで、IBGP を使用して別の PE ルータと VPN ルーティング情報を交換します。
■![]() CE デバイスに接続していないサービス プロバイダー ネットワークのルータは、プロバイダー ルータやコア ルータになります。
CE デバイスに接続していないサービス プロバイダー ネットワークのルータは、プロバイダー ルータやコア ルータになります。
Multi-VRF CE では、複数のお客様が 1 つの CE を共有でき、CE と PE の間で 1 つの物理リンクだけが使用されます。共有 CE は、お客様ごとに別々の VRF テーブルを維持し、独自のルーティング テーブルに基づいて、お客様ごとにパケットをスイッチングまたはルーティングします。Multi-VRF CE は、制限付きの PE 機能を CE デバイスに拡張して、別々の VRF テーブルを維持し、VPN のプライバシーおよびセキュリティをブランチ オフィスに拡張します。
図 106は、Cisco Connected Grid スイッチを使用した複数の仮想 CE による構成を示したものです。このシナリオは、中小企業など、VPN サービスの帯域幅要件の低いお客様に適しています。このような場合、Cisco Connected Grid スイッチでは Multi-VRF CE のサポートが必要です。Multi-VRF CE はレイヤ 3 機能なので、VRF のそれぞれのインターフェイスはレイヤ 3 インターフェイスである必要があります。
CE スイッチは、レイヤ 3 インターフェイスを VRF に追加するコマンドを受信すると、Multi-VRF CE 関連のデータ構造で VLAN ID と Policy Label(PL)の間に適切なマッピングを設定し、VLAN ID と PL を VLAN データベースに追加します。
Multi-VRF CE を設定すると、レイヤ 3 フォワーディング テーブルは、次の 2 つのセクションに概念的に分割されます。
■![]() Multi-VRF CE ルーティング セクションには、さまざまな VPN からのルートが含まれます。
Multi-VRF CE ルーティング セクションには、さまざまな VPN からのルートが含まれます。
■![]() グローバル ルーティング セクションには、インターネットなど、VPN 以外のネットワークへのルートが含まれます。
グローバル ルーティング セクションには、インターネットなど、VPN 以外のネットワークへのルートが含まれます。
さまざまな VRF の VLAN ID はさまざまな PL にマッピングされ、処理中に VRF を区別するために使用されます。レイヤ 3 転送テーブルのマルチ VRF CE セクションにルートが見つからない場合は、グローバル ルーティング セクションを使用して転送パスが判別されます。レイヤ 3 設定機能では、学習した新しい VPN ルートごとに、入力ポートの VLAN ID を使用して PL を取得し、Multi-VRF CE ルーティング セクションに PL および新しいルートを挿入します。ルーテッド ポートからパケットを受信した場合は、ポート内部 VLAN ID 番号が使用されます。SVI からパケットを受信した場合は、VLAN 番号が使用されます。
Multi-VRF CE 対応ネットワークのパケット転送処理は次のとおりです。
■![]() スイッチは、VPN からパケットを受信すると、入力 PL 番号に基づいてルーティング テーブルを検索します。ルートが見つかると、スイッチはパケットを PE に転送します。
スイッチは、VPN からパケットを受信すると、入力 PL 番号に基づいてルーティング テーブルを検索します。ルートが見つかると、スイッチはパケットを PE に転送します。
■![]() 入力 PE は、CE からパケットを受信すると、VRF 検索を実行します。ルートが見つかると、ルータは対応する MPLS ラベルをパケットに追加し、MPLS ネットワークに送信します。
入力 PE は、CE からパケットを受信すると、VRF 検索を実行します。ルートが見つかると、ルータは対応する MPLS ラベルをパケットに追加し、MPLS ネットワークに送信します。
■![]() 出力 PE は、ネットワークからパケットを受信すると、ラベルを除去してそのラベルを使用し、正しい VPN ルーティング テーブルを識別します。次に、通常のルート検索を実行します。ルートが見つかると、パケットを正しい隣接デバイスに転送します。
出力 PE は、ネットワークからパケットを受信すると、ラベルを除去してそのラベルを使用し、正しい VPN ルーティング テーブルを識別します。次に、通常のルート検索を実行します。ルートが見つかると、パケットを正しい隣接デバイスに転送します。
■![]() CE は、出力 PE からパケットを受信すると、入力 PL を使用して正しい VPN ルーティング テーブルを検索します。ルートが見つかると、パケットを VPN 内で転送します。
CE は、出力 PE からパケットを受信すると、入力 PL を使用して正しい VPN ルーティング テーブルを検索します。ルートが見つかると、パケットを VPN 内で転送します。
VRF を設定するには、VRF テーブルを作成し、VRF に関連するレイヤ 3 インターフェイスを指定します。次に、VPN、および CE と PE 間でルーティング プロトコルを設定します。プロバイダーのバックボーンで VPN ルーティング情報を配信する場合は、BGP が優先ルーティング プロトコルです。Multi-VRF CE ネットワークには、次の 3 つの主要コンポーネントがあります。
■![]() VPN ルート ターゲット コミュニティ:VPN コミュニティのその他すべてのメンバのリスト。VPN コミュニティ メンバーごとに VPN ルート ターゲットを設定する必要があります。
VPN ルート ターゲット コミュニティ:VPN コミュニティのその他すべてのメンバのリスト。VPN コミュニティ メンバーごとに VPN ルート ターゲットを設定する必要があります。
■![]() VPN コミュニティ PE ルータのマルチプロトコル BGP ピアリング:VPN コミュニティのすべてのメンバーに VRF 到達可能性情報を伝播します。VPN コミュニティのすべての PE ルータで BGP ピアリングを設定する必要があります。
VPN コミュニティ PE ルータのマルチプロトコル BGP ピアリング:VPN コミュニティのすべてのメンバーに VRF 到達可能性情報を伝播します。VPN コミュニティのすべての PE ルータで BGP ピアリングを設定する必要があります。
■![]() VPN 転送:VPN サービス プロバイダー ネットワークを介し、全 VPN コミュニティ メンバー間で、全トラフィックを伝送します。
VPN 転送:VPN サービス プロバイダー ネットワークを介し、全 VPN コミュニティ メンバー間で、全トラフィックを伝送します。
マルチ VRF CE のデフォルト設定
|
|
|
|---|---|
Multi-VRF CE の設定時の注意事項
ネットワークに VRF を設定する場合は、次の内容に注意してください。
■![]() Multi-VRF CE を含むスイッチは複数のお客様によって共有され、各お客様には独自のルーティング テーブルがあります。
Multi-VRF CE を含むスイッチは複数のお客様によって共有され、各お客様には独自のルーティング テーブルがあります。
■![]() お客様は別々の VRF テーブルを使用するので、同じ IP アドレスを再利用できます。別々の VPN では IP アドレスの重複が許可されます。
お客様は別々の VRF テーブルを使用するので、同じ IP アドレスを再利用できます。別々の VPN では IP アドレスの重複が許可されます。
■![]() Multi-VRF CE では、複数のお客様が、PE と CE の間で同じ物理リンクを共有できます。複数の VLAN を持つトランク ポートでは、パケットがお客様間で分離されます。それぞれのお客様には独自の VLAN があります。
Multi-VRF CE では、複数のお客様が、PE と CE の間で同じ物理リンクを共有できます。複数の VLAN を持つトランク ポートでは、パケットがお客様間で分離されます。それぞれのお客様には独自の VLAN があります。
■![]() Multi-VRF CE ではサポートされない MPLS-VRF 機能があります。ラベル交換、LDP 隣接関係、ラベル付きパケットはサポートされません。
Multi-VRF CE ではサポートされない MPLS-VRF 機能があります。ラベル交換、LDP 隣接関係、ラベル付きパケットはサポートされません。
■![]() PE ルータの場合、Multi-VRF CE の使用と複数の CE の使用に違いはありません。図 106では、複数の仮想レイヤ 3 インターフェイスが Multi-VRF CE デバイスに接続されています。
PE ルータの場合、Multi-VRF CE の使用と複数の CE の使用に違いはありません。図 106では、複数の仮想レイヤ 3 インターフェイスが Multi-VRF CE デバイスに接続されています。
■![]() スイッチでは、物理ポートか VLAN SVI、またはその両方の組み合わせを使用して、VRF を設定できます。SVI は、アクセス ポートまたはトランク ポートで接続できます。
スイッチでは、物理ポートか VLAN SVI、またはその両方の組み合わせを使用して、VRF を設定できます。SVI は、アクセス ポートまたはトランク ポートで接続できます。
■![]() お客様は、別のお客様と重複しないかぎり、複数の VLAN を使用できます。お客様の VLAN は、スイッチに保存されている適切なルーティング テーブルの識別に使用される特定のルーティング テーブル ID にマッピングされます。
お客様は、別のお客様と重複しないかぎり、複数の VLAN を使用できます。お客様の VLAN は、スイッチに保存されている適切なルーティング テーブルの識別に使用される特定のルーティング テーブル ID にマッピングされます。
■![]() スイッチは、1 つのグローバル ネットワークおよび最大 26 の VRF をサポートします。
スイッチは、1 つのグローバル ネットワークおよび最大 26 の VRF をサポートします。
■![]() CE と PE の間では、ほとんどのルーティング プロトコル(BGP、OSPF、RIP、EIGRP およびスタティック ルーティング)を使用できます。ただし、次の理由から External BGP(EBGP)を使用することを推奨します。
CE と PE の間では、ほとんどのルーティング プロトコル(BGP、OSPF、RIP、EIGRP およびスタティック ルーティング)を使用できます。ただし、次の理由から External BGP(EBGP)を使用することを推奨します。
–![]() BGP では、複数の CE とのやり取りに複数のアルゴリズムを必要としません。
BGP では、複数の CE とのやり取りに複数のアルゴリズムを必要としません。
–![]() BGP は、さまざまな管理者によって稼働するシステム間でルーティング情報を渡すように設計されています。
BGP は、さまざまな管理者によって稼働するシステム間でルーティング情報を渡すように設計されています。
–![]() BGP では、ルートの属性を CE に簡単に渡すことができます。
BGP では、ルートの属性を CE に簡単に渡すことができます。
■![]() Multi-VRF CE は、パケットのスイッチング レートに影響しません。
Multi-VRF CE は、パケットのスイッチング レートに影響しません。
■![]() VRF を設定しない場合は、最大 105 のポリシーを設定できます。
VRF を設定しない場合は、最大 105 のポリシーを設定できます。
■![]() VRF を 1 つでも設定した場合、設定できるポリシーの数は 41 となります。
VRF を 1 つでも設定した場合、設定できるポリシーの数は 41 となります。
■![]() 設定されているポリシーの数が 41 を超えている場合は、VRF を設定できません。
設定されているポリシーの数が 41 を超えている場合は、VRF を設定できません。
■![]() VRF とプライベート VLAN は相互に排他的です。プライベート VLAN では VRF をイネーブルにできません。同様に、VLAN インターフェイスで VRF が設定されている VLAN では、プライベート VLAN をイネーブルにはできません。
VRF とプライベート VLAN は相互に排他的です。プライベート VLAN では VRF をイネーブルにできません。同様に、VLAN インターフェイスで VRF が設定されている VLAN では、プライベート VLAN をイネーブルにはできません。
■![]() VRF とポリシーベース ルーティング(PBR)は、スイッチ インターフェイス上で相互に排他的です。PBR がインターフェイスで有効になっているときは、VRF を有効にはできません。VRF がインターフェイスでイネーブルになっている場合、PBR をイネーブルにはできません。
VRF とポリシーベース ルーティング(PBR)は、スイッチ インターフェイス上で相互に排他的です。PBR がインターフェイスで有効になっているときは、VRF を有効にはできません。VRF がインターフェイスでイネーブルになっている場合、PBR をイネーブルにはできません。
VRF の設定
はじめる前に
Multi-VRF CE の設定時の注意事項を参照してください。
手順の詳細
VRF とそのすべてのインターフェイスを削除するには、 no ip vrf vrf-name グローバル コンフィギュレーション コマンドを使用します。VRF からあるインターフェイスを削除するには、 no ip vrf forwarding インターフェイス コンフィギュレーション コマンドを使用します。
例
次に、VPN1 という名前の VRF インスタンスにルートマップをインポートする例を示します。
VRF 認識サービスの設定
IP サービスはグローバル インターフェイスに設定可能で、グローバル ルーティング インスタンスで稼働します。IP サービスは複数のルーティング インスタンス上で稼働するように拡張されます。これが、VRF 認識です。システム内の任意の設定済み VRF であればいずれも、VRF 認識サービス用に指定できます。
VRF 認識サービスは、プラットフォームから独立したモジュールに実装されています。VRF とは、Cisco IOS 内の複数のルーティング インスタンスを意味します。各プラットフォームには、サポートする VRF 数に関して独自の制限があります。
■![]() ユーザは、ユーザ指定の VRF 内のホストに ping を実行できます。
ユーザは、ユーザ指定の VRF 内のホストに ping を実行できます。
ARP のユーザ インターフェイス
VRF を ARP キャッシュに追加するには、グローバル コンフィギュレーション モードで arp コマンドを使用します。
はじめる前に
VRF の設定の説明に従って、VRF を設定します。
手順の詳細
|
|
|
|
arp vrf vrf-name hardware-address encap-type [ interface-type ] [alias] |
||
例
ping のユーザ インターフェイス
設定されている VRF が動作しているかどうかを確認するには、ping VRF コマンドを使用します。
プロバイダーエッジ(PE)ルータからカスタマーエッジ(CE)ルータへ、または PE ルータから PE ルータへ ping を実行しようとすると、通常、標準の ping コマンドは機能しません。ping vrf コマンドを使用すると、CE ルータの LAN インターフェイスの IP アドレスに対して ping を実行できます。
PE ルータを使用している場合は、「例」のセクションに示すように、特定の VRF(VPN)名を必ず指定してください。
すべての必要な情報がコマンドラインで指定されていない場合、システムは ping の対話式ダイアログ(拡張モード)を開始します。
はじめる前に
VRF の設定の説明に従って、VRF を設定します。
手順の詳細
|
|
|
|
|---|---|---|
例
次の例では、ドメイン 209.165.201.1 のターゲットホストに対し、「CustomerA」 VPN 接続のコンテキストで ping を実行します(IP/ICMP を使用)。
SNMP のユーザ インターフェイス
はじめる前に
VRF の設定の説明に従って、VRF を設定します。
手順の詳細
例
次に、SNMP エンジン ID を指定し、172.16.20.3 にあるリモートデバイスとの SNMP 通信のための VRF 名 traps-vrf を設定する例を示します。
次の例は、コミュニティ ストリング public を使用して、trap-vrf という名前の VRF 上ですべての SNMP 通知を example.com に送信する方法を示しています。
HSRP のユーザ インターフェイス
VRF の Hot Standby Router Protocol(HSRP)サポートにより、HSRP 仮想 IP アドレスが、確実に適切な IP ルーティングテーブルに追加されます。
はじめる前に
VRF の設定の説明に従って、VRF を設定します。
手順の詳細
|
|
|
|
|---|---|---|
例
Syslog のユーザ インターフェイス
はじめる前に
VRF の設定の説明に従って、VRF を設定します。
手順の詳細
|
|
|
|
|---|---|---|
例
次の例では、syslog サーバホストに接続する VRF を指定します。
traceroute のユーザ インターフェイス
はじめる前に
VRF の設定の説明に従って、VRF を設定します。
手順の詳細
|
|
|
|
|---|---|---|
例
次の例では、vrf キーワードを指定した traceroute コマンドの出力を表示しています。出力には、着信 VRF の名前/タグと発信 VRF の名前/タグが含まれます。
FTP および TFTP のユーザインターフェイス
FTP と TFTP は VRF 認識です。これは、VRF インスタンス内のインターフェイス間でファイル転送がサポートされていることを意味します。VRF を FTP または TFTP 接続の送信元として指定するには、ip ftp source-interface コマンドを使用して設定したのと同じインターフェイスに VRF が関連付けられている必要があります。この設定では、FTP は指定された VRF テーブルでファイル転送の宛先 IP アドレスを検索します。指定された送信元インターフェイスが動作していない場合、Cisco IOS ソフトウェアは、宛先に最も近いインターフェイスのアドレスを送信元アドレスとして選択します。
|
|
|
|
|---|---|---|
TFTP 接続の送信元 IP アドレスとしてインターフェイスの IP アドレスを指定するには、ip tftp source-interface show モードコマンドを使用します。デフォルトに戻るには、no 形式のコマンドを使用します。
|
|
|
|
|---|---|---|
例
次に、vpn1 という名前の VRF テーブルを使用して、FTP パケットの転送先の宛先 IP アドレスを検索するようにスイッチを設定する例を示します。
VRF 認識 RADIUS のユーザ インターフェイス
VRF 認識 RADIUS を設定するには、まず RADIUS サーバ上で AAA をイネーブルにする必要があります。スイッチで ip vrf forwarding vrf-name サーバグループ コンフィギュレーション コマンドと ip radius source-interface グローバル コンフィギュレーション コマンドがサポートされます。
VPN ルーティング セッションの設定
VPN 内のルーティングは、サポートされている任意のルーティング プロトコル(RIP、OSPF、EIGRP、BGP)、またはスタティック ルーティングで設定できます。ここで説明する設定は OSPF のものですが、その他のプロトコルでも手順は同じです。
注: VRF インスタンス内で EIGRP ルーティングプロセスが実行されるように設定するには、 autonomous-system autonomous-system-number アドレスファミリ コンフィギュレーション モード コマンドを入力して、自律システム番号を設定する必要があります。
はじめる前に
VRF の設定の説明に従って、VRF を設定します。
手順の詳細
|
|
|
|
|---|---|---|
OSPF ルーティングをイネーブルにして VPN 転送テーブルを指定し、ルータ コンフィギュレーション モードを開始します。 |
||
no router ospf process-id vrf vrf-name グローバル コンフィギュレーション コマンドを使用して、VPN 転送テーブルと OSPF ルーティングプロセスの関連付けを解除します。
例
次の例は、router ospf コマンドを使用して、first、second、および third という名前の各 VRF に、OSPF VRF プロセスを設定する、基本的な OSPF 設定を示しています。
BGP PE/CE ルーティング セッションの設定
はじめる前に
■![]() ご使用のネットワークに対する BGP ネットワーク戦略と計画を完成させます。
ご使用のネットワークに対する BGP ネットワーク戦略と計画を完成させます。
■![]() OSPF の設定の説明に従って、OSPF を設定します。
OSPF の設定の説明に従って、OSPF を設定します。
■![]() VRF の設定の説明に従って、VRF を設定します。
VRF の設定の説明に従って、VRF を設定します。
手順の詳細
|
|
|
|
|---|---|---|
その他の BGP ルータに AS 番号を渡す BGP ルーティング プロセスを設定し、ルータ コンフィギュレーション モードを開始します。 |
||
no router bgp autonomous-system-number グローバル コンフィギュレーション コマンドを使用して、BGP ルーティングプロセスを削除します。ルーティング特性を削除するには、コマンドにキーワードを指定してこのコマンドを使用します。
例
次に、CE から PE へのルーティング用に BGP を設定する例を示します。
Multi-VRF CE ステータスの表示
Multi-VRF CE の設定とステータスに関する情報を表示するには、次の特権 EXEC コマンドを使用します。
|
|
|
|---|---|
show ip route vrf vrf-name [ connected ] [ protocol [ as-number ]] [ list ] [ mobile ] [ odr ] [ profile ] [ static ] [ summary ] [ supernets-only ] |
|
プロトコル独立機能の設定
ここでは、IP ルーティング プロトコルに依存しない機能の設定方法について説明します。この章に記載された IP ルーティングプロトコルに依存しないコマンドの詳細については、『 Cisco IOS IP Routing: Protocol-Independent Command Reference 』を参照してください。
CEF の設定
Cisco Express Forwarding(CEF)は、ネットワークパフォーマンスを最適化するために使用されるレイヤ 3 IP スイッチング技術です。CEF には高度な IP 検索および転送アルゴリズムが実装されているため、レイヤ 3 スイッチングのパフォーマンスを最大化できます。高速スイッチング ルート キャッシュよりも CPU にかかる負担が少ないため、CEF はより多くの CPU 処理能力をパケット転送に割り当てることができます。動的なネットワークでは、ルーティングの変更によって、高速スイッチング キャッシュ エントリが頻繁に無効になります。高速スイッチング キャッシュ エントリが無効になると、トラフィックがルート キャッシュによって高速スイッチングされずに、ルーティング テーブルによってプロセス スイッチングされることがあります。CEF は転送情報ベース(FIB)検索テーブルを使用して、宛先ベースの IP パケット スイッチングを実行します。
CEF の 2 つの主要な構成要素は、分散 FIB と分散隣接関係テーブルです。
■![]() FIB はルーティング テーブルや情報ベースと同様、IP ルーティング テーブルに転送情報のミラー イメージが保持されます。ネットワーク内でルーティングまたはトポロジが変更されると、IP ルーティング テーブルがアップデートされ、これらの変更が FIB に反映されます。FIB には、IP ルーティング テーブル内の情報に基づいて、ネクストホップのアドレス情報が保持されます。FIB にはルーティング テーブル内の既知のルートがすべて格納されているため、CEF はルート キャッシュをメンテナンスする必要がなく、トラフィックのスイッチングがより効率化され、トラフィック パターンの影響も受けません。
FIB はルーティング テーブルや情報ベースと同様、IP ルーティング テーブルに転送情報のミラー イメージが保持されます。ネットワーク内でルーティングまたはトポロジが変更されると、IP ルーティング テーブルがアップデートされ、これらの変更が FIB に反映されます。FIB には、IP ルーティング テーブル内の情報に基づいて、ネクストホップのアドレス情報が保持されます。FIB にはルーティング テーブル内の既知のルートがすべて格納されているため、CEF はルート キャッシュをメンテナンスする必要がなく、トラフィックのスイッチングがより効率化され、トラフィック パターンの影響も受けません。
■![]() リンク層上でネットワーク内のノードが 1 ホップで相互に到達可能な場合、これらのノードは隣接関係にあると見なされます。CEF は隣接テーブルを使用し、レイヤ 2 アドレッシング情報を付加します。隣接テーブルには、すべての FIB エントリに対する、レイヤ 2 のネクストホップのアドレスが保持されます。
リンク層上でネットワーク内のノードが 1 ホップで相互に到達可能な場合、これらのノードは隣接関係にあると見なされます。CEF は隣接テーブルを使用し、レイヤ 2 アドレッシング情報を付加します。隣接テーブルには、すべての FIB エントリに対する、レイヤ 2 のネクストホップのアドレスが保持されます。
スイッチは、ギガビット速度の回線レート IP トラフィックを達成するため特定用途向け IC(ASIC)を使用しているので、CEF 転送はソフトウェア転送パス(CPU により転送されるトラフィック)にだけ適用されます。
デフォルトで、CEF はグローバルなイネーブルに設定されています。何らかの理由でこれがディセーブルになった場合は、 ip cef グローバル コンフィギュレーション コマンドを使用し、再度イネーブルに設定できます。
デフォルト設定では、すべてのレイヤ 3 インターフェイスで CEF がイネーブルです。 no ip route-cache cef インターフェイス コンフィギュレーション コマンドを入力すると、ソフトウェアが転送するトラフィックに対して CEF がディセーブルになります。このコマンドは、ハードウェア転送パスには影響しません。CEF をディセーブルにして debug ip packet detail 特権 EXEC コマンドを使用すると、ソフトウェア転送トラフィックをデバッグするのに便利です。ソフトウェア転送パス用のインターフェイスで CEF をイネーブルにするには、 ip route-cache cef インターフェイス コンフィギュレーション コマンドを使用します。
注意: CLI には、インターフェイス上で CEF をディセーブルにする no ip route-cache cef インターフェイス コンフィギュレーション コマンドが表示されますが、デバッグ以外の目的では、インターフェイス上で CEF をディセーブルにしないようにしてください。
はじめる前に
■![]() Cisco Express Forwarding には、スイッチで有効になっている Cisco Express Forwarding と IP ルーティングが含まれているソフトウェアイメージが必要です。
Cisco Express Forwarding には、スイッチで有効になっている Cisco Express Forwarding と IP ルーティングが含まれているソフトウェアイメージが必要です。
■![]() シスコ エクスプレス フォワーディングをイネーブルにしてから、log キーワードを使用するアクセス リストを作成した場合、アクセス リストと一致するパケットは、シスコ エクスプレス フォワーディングで交換されたものではありません。これらはプロセス交換されたものです。ロギングにより、シスコ エクスプレス フォワーディングがディセーブルになります。
シスコ エクスプレス フォワーディングをイネーブルにしてから、log キーワードを使用するアクセス リストを作成した場合、アクセス リストと一致するパケットは、シスコ エクスプレス フォワーディングで交換されたものではありません。これらはプロセス交換されたものです。ロギングにより、シスコ エクスプレス フォワーディングがディセーブルになります。
手順の詳細
|
|
|
|
|---|---|---|
必要に応じて、インターフェイスをイネーブルにします。デフォルトでは、UNI と ENI はディセーブルに、NNI はイネーブルに設定されています。 |
||
例
等コスト ルーティング パスの個数の設定
同じネットワークへ向かう同じメトリックのルートが複数ルータに格納されている場合、これらのルートは等価コストを保有していると見なされます。ルーティングテーブルに複数の等コストルートが含まれる場合は、これらをパラレルパスと呼ぶこともあります。 ネットワークへの等コスト パスがルータに複数格納されている場合、ルータはこれらを同時に使用できます。パラレル パスを使用すると、パスに障害が発生した場合に冗長性を確保できます。また、使用可能なパスにパケットの負荷を分散し、使用可能な帯域幅を有効利用することもできます。
等コスト ルートはルータによって自動的に取得、設定されますが、ルーティング テーブルの IP ルーティング プロトコルでサポートされるパラレル パスの最大数は制御可能です。
手順の詳細
|
|
|
|
|---|---|---|
プロトコル ルーティング テーブルのパラレル パスの最大数を設定します。指定できる範囲は 1 ~ 8 です。ほとんどの IP ルーティング プロトコルでデフォルトは 4 ですが、BGP の場合は 1 つだけです。 |
||
例
OSPF ルーティングプロセスで、1 つの宛先に最大 16 のパスを許容する例を示します。
スタティック ユニキャスト ルートの設定
スタティック ユニキャスト ルートは、特定のパスを通過して送信元と宛先間でパケットを送受信するユーザ定義のルートです。ルータが特定の宛先へのルートを構築できない場合、スタティック ルートは重要で、到達不能なすべてのパケットが送信される最終ゲートウェイを指定する場合に有効です。
ユーザによって削除されるまで、スタティック ルートはスイッチに保持されます。ただし、アドミニストレーティブ ディスタンスの値を割り当て、スタティック ルートをダイナミック ルーティング情報で上書きできます。各ダイナミック ルーティング プロトコルには、デフォルトのアドミニストレーティブ ディスタンスが設定されています(表 2 を参照)。ダイナミック ルーティング プロトコルの情報でスタティック ルートを上書きする場合は、スタティック ルートのアドミニストレーティブ ディスタンスがダイナミック プロトコルのアドミニストレーティブ ディスタンスよりも大きな値になるように設定します。
|
|
|
|---|---|
インターフェイスを指し示すスタティック ルートは、RIP、IGRP、およびその他のダイナミック ルーティング プロトコルを通してアドバタイズされます。 redistribute スタティック ルータ コンフィギュレーション コマンドが、これらのルーティング プロトコルに対して指定されているかどうかは関係ありません。これらのスタティック ルートがアドバタイズされるのは、インターフェイスを指し示すスタティック ルートが接続された結果、静的な性質を失ったとルーティング テーブルで見なされるためです。ただし、network コマンドで定義されたネットワーク以外のインターフェイスに対してスタティック ルートを定義する場合は、ダイナミック ルーティング プロトコルに redistribute スタティック コマンドを指定しないかぎり、ルートはアドバタイズされません。
インターフェイスがダウンすると、ダウンしたインターフェイスを経由するすべてのスタティック ルートが IP ルーティング テーブルから削除されます。転送ルータのアドレスとして指定されたアドレスへ向かう有効なネクスト ホップがスタティック ルート内に見つからない場合は、IP ルーティング テーブルからそのスタティック ルートも削除されます。
手順の詳細
|
|
|
|
|---|---|---|
スタティック ルートを削除するには、 no ip route prefix mask { address | interface } グローバル コンフィギュレーション コマンドを使用します。
例
次の例は、110 のアドミニストレーティブ ディスタンスを選択する方法を示しています。この場合、アドミニストレーティブ ディスタンスが 110 未満のダイナミック情報を入手できなければ、ネットワーク 10.0.0.0 のパケットが 172.31.3.4 にあるルータに転送されます。
デフォルトのルートおよびネットワークの指定
ルータは、他のすべてのネットワークへのルートを学習できません。完全なルーティング機能を実現するには、一部のルータをスマート ルータとして使用し、それ以外のルータのデフォルト ルートをスマート ルータ宛てに指定します(スマート ルータにはインターネットワーク全体のルーティング テーブルに関する情報が格納されます)。これらのデフォルトルートは動的に学習できますが、ルータごとに設定することもできます。ほとんどのダイナミックな内部ルーティング プロトコルには、スマート ルータを使用してデフォルト情報を動的に生成し、他のルータに転送するメカニズムがあります。
指定されたデフォルト ネットワークに直接接続されたインターフェイスがルータに存在する場合は、そのデバイス上で動作するダイナミック ルーティング プロトコルによってデフォルト ルートが生成されます。RIP の場合は、疑似ネットワーク 0.0.0.0 がアドバタイズされます。
ネットワークのデフォルトを生成しているルータには、そのルータ自身のデフォルト ルートも指定する必要があります。ルータが自身のデフォルト ルートを生成する方法の 1 つは、適切なデバイスを経由してネットワーク 0.0.0.0 に至るスタティック ルートを指定することです。
ダイナミック ルーティング プロトコルによってデフォルト情報を送信するときは、特に設定する必要はありません。ルーティング テーブルは定期的にスキャンされ、デフォルト ルートとして最適なデフォルト ネットワークが選択されます。IGRP ネットワークでは、システムのデフォルト ネットワークの候補が複数存在する場合もあります。Cisco ルータでは、デフォルト ルートまたは最終ゲートウェイを設定するため、アドミニストレーティブ ディスタンスおよびメトリック情報を使用します。
ダイナミックなデフォルト情報がシステムに送信されない場合は、 ip default-network グローバル コンフィギュレーション コマンドを使用し、デフォルト ルートの候補を指定します。このネットワークが任意の送信元のルーティング テーブルに格納されている場合は、デフォルト ルートの候補としてフラグ付けされます。ルータにデフォルト ネットワークのインターフェイスが存在しなくても、そこへのパスが格納されている場合、そのネットワークは 1 つの候補と見なされ、最適なデフォルト パスへのゲートウェイが最終ゲートウェイになります。
はじめる前に
ip default-network コマンドは、クラスフルコマンドです。これが有効なのは、ラストリゾートゲートウェイを計算するための候補ルートとして設定するネットワークのネットワークマスクが、ルーティング情報ベース(RIB)のネットワークマスクと一致する場合のみです。
たとえば、ip default-network 10.0.0.0 を設定すると、ルーティングプロトコルによって考慮されるマスクは、クラス A ネットワークであるため 10.0.0.0/8 になります。ラストリゾートゲートウェイは、RIB に 10.0.0.0/8 ルートが含まれている場合にのみ設定されます。
ip default-network コマンドを使用する必要がある場合は、ネットワーククラスのメジャーマスクと一致するネットワークルートが RIB に含まれていることを確認します。
手順の詳細
|
|
|
|
|---|---|---|
ルートを削除するには、 no ip default-network network number グローバル コンフィギュレーション コマンドを使用します。
例
次に、ネットワーク 10.0.0.0 へのスタティックルートをスタティック デフォルト ルートとして定義する例を示します。
ルート マップによるルーティング情報の再配信
スイッチでは複数のルーティング プロトコルを同時に実行し、ルーティング プロトコル間で情報を再配信できます。ルーティング プロトコル間での情報の再配信は、サポートされているすべての IP ベース ルーティング プロトコルに適用されます。
2 つのドメイン間で拡張パケット フィルタまたはルート マップを定義することにより、ルーティング ドメイン間でルートの再配信を条件付きで制御することもできます。 match および set ルート マップ コンフィギュレーション コマンドは、ルート マップの条件部を定義します。 match コマンドは、条件が一致する必要があることを指定しています。 set コマンドは、ルーティング アップデートが match コマンドで定義した条件を満たす場合に行われる処理を指定します。再配信はプロトコルに依存しない機能ですが、 match および set ルート マップ コンフィギュレーション コマンドの一部は特定のプロトコル固有のものです。
route-map コマンドのあとに、 match コマンドおよび set コマンドをそれぞれ 1 つまたは複数指定します。 match コマンドを指定しない場合は、すべて一致すると見なされます。 set コマンドを指定しない場合、一致以外の処理はすべて実行されません。このため、少なくとも 1 つの match または set コマンドを指定する必要があります。
注: set ルートマップ コンフィギュレーション コマンドを使用しないルートマップは、CPU に送信されるので、CPU の使用率が高くなります。
ルートマップ ステートメントは、 permit または deny として識別することもできます。ステートメントが拒否としてマークされている場合、一致基準を満たすパケットは通常の転送チャネルを通じて送り返されます(宛先ベース ルーティング)、ステートメントが許可としてマークされている場合は、一致基準を満たすパケットに set コマンドが適用されます。一致基準を満たさないパケットは、通常のルーティング チャネルを通じて転送されます。
BGP ルート マップ continue 句を使用して、エントリが無事に一致して句が設定された後、ルート マップの追加のエントリを実行できます。 continue 句を使用すれば、同じルート マップ内で特定のポリシー コンフィギュレーションを繰り返す必要がないように、より多くのモジュラ ポリシー定義を設定および編成できます。スイッチで発信ポリシーに continue コマンドを使用できるようになりました。ルートマップの continue 句の使用の詳細については、『 IP Routing: BGP Configuration Guide, Cisco IOS Release 15M&T 』の「BGP Route-Map Continue」セクションを参照してください。
注: 次に示すステップ 3 ~ 14 はそれぞれ任意ですが、少なくとも 1 つの match ルートマップ コンフィギュレーション コマンド、および 1 つの set ルートマップ コンフィギュレーション コマンドを入力する必要があります。
はじめる前に
ルート再配布またはポリシーベースルーティングを設定する前に、ネットワーク設計とトラフィックをどのように流すのかについて理解しておく必要があります。
手順の詳細
エントリを削除するには、 no route-map map tag グローバル コンフィギュレーション コマンド、または no match や no set ルートマップ コンフィギュレーション コマンドを使用します。
例
次に、ホップカウントが 1 の Routing Information Protocol(RIP)ルートを Open Shortest Path First(OSPF)に再配布する例を示します。これらのルートは、メトリック 5、メトリックタイプ 1、およびタグ 1 の外部リンクステート アドバタイズメント(LSA)として OSPF に再配布されます。
ルート再配布の制御
ルーティング ドメイン間でルートを配信したり、ルート再配信を制御できます。この手順でのキーワードは前述の手順で定義されたキーワードと同じです。
ルーティング プロトコルのメトリックを、必ずしも別のルーティング プロトコルのメトリックに変換する必要はありません。このような場合は、メトリックを独自に設定し、再配信されたルートに割り当てます。ルーティング情報を制御せずにさまざまなルーティング プロトコル間で交換するとルーティング ループが発生し、ネットワーク動作が著しく低下することがあります。
メトリック変換の代わりに使用されるデフォルトの再配信メトリックが定義されていない場合は、ルーティング プロトコル間で自動的にメトリック変換が発生することがあります。
■![]() RIP はスタティック ルートを自動的に再配信できます。スタティック ルートにはメトリック 1(直接接続)が割り当てられます。
RIP はスタティック ルートを自動的に再配信できます。スタティック ルートにはメトリック 1(直接接続)が割り当てられます。
はじめる前に
『 Cisco IOS IP Routing: Protocol-Independent Command Reference 』で、redistribute コマンドの使用上のガイドラインとその他の例を確認してください。
手順の詳細
例
次の設定では、ネットワーク 160.89.0.0 に対して RIP で学習されたルートと、プレフィックス 49.0001.0002 の ISP-IGRP で学習されたルートが、メトリック 5 のレベル 2 リンクステート PDU に再配布されます。
ポリシーベース ルーティングの設定
PBR を使用すると、トラフィック フローに定義済みポリシーを設定できます。PBR を使用してルーティングをより細かく制御するには、ルーティング プロトコルから取得したルートの信頼度を小さくします。PBR は、次の基準に基づいて、パスを許可または拒否するルーティング ポリシーを設定したり、実装したりできます。
PBR を使用すると、等価アクセスや送信元依存ルーティング、インタラクティブ対バッチ トラフィックに基づくルーティング、専用リンクに基づくルーティングを実現できます。たとえば、在庫記録を本社に送信する場合は高帯域で高コストのリンクを短時間使用し、電子メールなど日常的に使用するアプリケーション データは低帯域で低コストのリンクで送信できます。
PBR がイネーブルの場合は、アクセス コントロール リスト(ACL)を使用してトラフィックを分類し、各トラフィックがそれぞれ異なるパスを経由するようにします。PBR は着信パケットに適用されます。PBR がイネーブルのインターフェイスで受信されたすべてのパケットは、ルート マップを通過します。ルート マップで定義された基準に基づいて、パケットは適切なネクスト ホップに転送(ルーティング)されます。
■![]() パケットがルート マップ ステートメントと一致しない場合は、すべての set 句が適用されます。
パケットがルート マップ ステートメントと一致しない場合は、すべての set 句が適用されます。
■![]() ステートメントが許可としてマークされている場合、どのルートマップ ステートメントとも一致しないパケットは通常の転送チャネルを通じて送信され、宛先ベースのルーティングが実行されます。
ステートメントが許可としてマークされている場合、どのルートマップ ステートメントとも一致しないパケットは通常の転送チャネルを通じて送信され、宛先ベースのルーティングが実行されます。
■![]() PBR では、拒否としてマークされているルートマップ ステートメントはサポートされません。
PBR では、拒否としてマークされているルートマップ ステートメントはサポートされません。
ルートマップの設定の詳細については、ルート マップによるルーティング情報の再配信を参照してください。
標準 IP ACL を使用すると、アプリケーション、プロトコル タイプ、またはエンド ステーションに基づいて一致基準を指定するように、送信元アドレスまたは拡張 IP ACL の一致基準を指定できます。一致が見つかるまで、ルート マップにこのプロセスが行われます。一致が見つからない場合、通常の宛先ベース ルーティングが行われます。match ステートメント リストの末尾には、暗黙の拒否ステートメントがあります。
match 句が満たされた場合は、set 句を使用して、パス内のネクスト ホップ ルータを識別する IP アドレスを指定できます。
PBR コマンドとキーワードの詳細については、『 IP Routing: Protocol-Independent Configuration Guide, Cisco IOS Release 15M&T 』を参照してください。
PBR 設定時の注意事項
■![]() マルチキャスト トラフィックには、ポリシーによるルーティングが行われません。PBR が適用されるのはユニキャスト トラフィックだけです。
マルチキャスト トラフィックには、ポリシーによるルーティングが行われません。PBR が適用されるのはユニキャスト トラフィックだけです。
■![]() ルーテッド ポートまたは SVI 上で、PBR を有効にできます。
ルーテッド ポートまたは SVI 上で、PBR を有効にできます。
■![]() PBR には、 route-map deny ステートメントはサポートされません。
PBR には、 route-map deny ステートメントはサポートされません。
■![]() レイヤ 3 モードの EtherChannel ポート チャネルにはポリシー ルート マップを適用できますが、EtherChannel のメンバーである物理インターフェイスには適用できません。適用しようとすると、コマンドが拒否されます。ポリシー ルート マップが適用されている物理インターフェイスは、EtherChannel のメンバーになることができません。
レイヤ 3 モードの EtherChannel ポート チャネルにはポリシー ルート マップを適用できますが、EtherChannel のメンバーである物理インターフェイスには適用できません。適用しようとすると、コマンドが拒否されます。ポリシー ルート マップが適用されている物理インターフェイスは、EtherChannel のメンバーになることができません。
■![]() スイッチには最大 246 個の IP ポリシー ルート マップを定義できます。
スイッチには最大 246 個の IP ポリシー ルート マップを定義できます。
■![]() スイッチには、PBR 用として最大 512 個のアクセス コントロール エントリ(ACE)を定義できます。
スイッチには、PBR 用として最大 512 個のアクセス コントロール エントリ(ACE)を定義できます。
■![]() ルート マップに一致基準を設定する場合は、次の注意事項に従ってください。
ルート マップに一致基準を設定する場合は、次の注意事項に従ってください。
–![]() ローカル アドレス宛てのパケットを許可する ACL と照合させないでください。PBR はこれらのパケットを転送しますが、ping や Telnet 障害またはルート プロトコル フラッピングが発生する可能性があります。
ローカル アドレス宛てのパケットを許可する ACL と照合させないでください。PBR はこれらのパケットを転送しますが、ping や Telnet 障害またはルート プロトコル フラッピングが発生する可能性があります。
–![]() 拒否 ACE を含む ACL と照合させないでください。拒否 ACE と一致するパケットが CPU に送られるため、CPU の利用率が高くなる可能性があります。
拒否 ACE を含む ACL と照合させないでください。拒否 ACE と一致するパケットが CPU に送られるため、CPU の利用率が高くなる可能性があります。
■![]() PBR を使用するには、 sdm prefer default グローバル コンフィギュレーション コマンドを使用して、デフォルトテンプレートをイネーブルにしておく必要があります。PBR では、レイヤ 2 テンプレートは使用できません。
PBR を使用するには、 sdm prefer default グローバル コンフィギュレーション コマンドを使用して、デフォルトテンプレートをイネーブルにしておく必要があります。PBR では、レイヤ 2 テンプレートは使用できません。
■![]() VRF と PBR は、スイッチ インターフェイス上で相互に排他的です。PBR がインターフェイスで有効になっているときは、VRF を有効にはできません。VRF がインターフェイスでイネーブルになっている場合、PBR をイネーブルにはできません。
VRF と PBR は、スイッチ インターフェイス上で相互に排他的です。PBR がインターフェイスで有効になっているときは、VRF を有効にはできません。VRF がインターフェイスでイネーブルになっている場合、PBR をイネーブルにはできません。
■![]() PBR で使用される 3 値連想メモリ(TCAM)エントリ数は、ルート マップ自体、使用される ACL、ACL およびルート マップ エントリの順序によって異なります。
PBR で使用される 3 値連想メモリ(TCAM)エントリ数は、ルート マップ自体、使用される ACL、ACL およびルート マップ エントリの順序によって異なります。
■![]() パケット長、IP precedence および ToS、set interface、set default next hop、または set default interface に基づく PBR は、サポートされていません。有効な set アクションがないか、または set アクションが Don't Fragment に設定されているポリシーマップは、サポートされていません。
パケット長、IP precedence および ToS、set interface、set default next hop、または set default interface に基づく PBR は、サポートされていません。有効な set アクションがないか、または set アクションが Don't Fragment に設定されているポリシーマップは、サポートされていません。
PBR のイネーブル化
デフォルトでは、PBR はスイッチ上で無効です。PBR をイネーブルにするには、一致基準およびすべての match 句と一致した場合の動作を指定するルート マップを作成する必要があります。次に、特定のインターフェイスでそのルート マップ用の PBR を有効にします。指定したインターフェイスに着信したパケットのうち、match 句と一致したものはすべて PBR の対象になります。
PBR は、スイッチの速度低下を引き起こさない速度で、高速転送したり実装したりできます。高速スイッチングされた PBR では、ほとんどの match および set コマンドを使用できます。PBR の高速スイッチングをイネーブルにするには、事前に PBR をイネーブルにする必要があります。PBR の高速スイッチングは、デフォルトでディセーブルです。
スイッチで生成されたパケットまたはローカル パケットは、通常どおりにポリシー ルーティングされません。スイッチ上でローカル PBR をグローバルに有効にすると、そのスイッチから送信されたすべてのパケットがローカル PBR の影響を受けます。ローカル PBR は、デフォルトで無効に設定されています。
はじめる前に
PBR 設定時の注意事項を参照してください。
手順の詳細
エントリを削除するには、 no route-map map-tag グローバル コンフィギュレーション コマンド、または no match または no set ルートマップ コンフィギュレーション コマンドを使用します。インターフェイス上で PBR をディセーブルにするには、 no ip policy route-map map-tag インターフェイス コンフィギュレーション コマンドを使用します。PBR の高速スイッチングをディセーブルにするには、 no ip route-cache policy インターフェイス コンフィギュレーション コマンドを使用します。スイッチから送信されるパケットに対して PBR をディセーブルにするには、 ip local policy route-map map-tag グローバル コンフィギュレーション コマンドを使用します。
例
次に、宛先 IP アドレス 172.21.16.18 のパケットを IP アドレス 172.30.3.20 のルータに送信する例を示します。
ルーティング情報のフィルタリング
受動インターフェイスの設定
ローカル ネットワーク上の他のルータが動的にルートを取得しないようにするには、 passive-interface ルータ コンフィギュレーション コマンドを使用し、ルーティング アップデート メッセージがルータ インターフェイスから送信されないようにします。OSPF プロトコルでこのコマンドを使用すると、パッシブに指定したインターフェイス アドレスが OSPF ドメインのスタブ ネットワークとして表示されます。OSPF ルーティング情報は、指定されたルータ インターフェイスから送受信されません。
多数のインターフェイスが存在するネットワークで、インターフェイスを手動でパッシブに設定する作業を回避するには、 passive-interface default ルータ コンフィギュレーション コマンドを使用し、すべてのインターフェイスをデフォルトでパッシブになるように設定します。このあとで、隣接関係が必要なインターフェイスを手動で設定します。
はじめる前に
ルーティング情報をフィルタリングする前にネットワーク設計およびそれを経由するトラフィックのフロー方法を知っておく必要があります。
手順の詳細
|
|
|
|
|---|---|---|
(任意)ルーティング プロセス用のネットワーク リストを指定します。 network-address は IP アドレスです。 |
||
パッシブとしてイネーブルにしたインターフェイスを確認するには、 show ip ospf interface などのネットワーク モニタリング用特権 EXEC コマンドを使用します。アクティブとしてイネーブルにしたインターフェイスを確認するには、 show ip interface 特権 EXEC コマンドを使用します。
ルーティングアップデートの送信を再度イネーブルにするには、 no passive-interface interface-id ルータ コンフィギュレーション コマンドを使用します。
例
次に、イーサネット インターフェイス 1 を除く、ネットワーク 10.108.0.0 上のすべてのインターフェイスに対して EIGRP アップデートを送信する例を示します。
次の例では、すべてのインターフェイスをパッシブに設定してから、インターフェイス ethernet0 をアクティブにする方法を示します。
ルーティング アップデートのアドバタイズおよび処理の制御
アクセスコントロールリストと distribute-list ルータ コンフィギュレーション コマンドを組み合わせて使用すると、ルーティングアップデート中にルートのアドバタイズを抑制し、他のルータが 1 つまたは複数のルートを取得しないようにできます。この機能を OSPF で使用した場合は外部ルートにだけ適用されるため、インターフェイス名を指定できません。
distribute-list ルータ コンフィギュレーション コマンドを使用し、着信したアップデートのリストのうち特定のルートを処理しないようにすることもできます。(OSPF にこの機能は適用されません)。
はじめる前に
手順の詳細
フィルタを変更またはキャンセルするには、 no distribute-list in ルータ コンフィギュレーション コマンドを使用します。アップデート中のネットワーク アドバタイズメントの抑制をキャンセルするには、 no distribute-list out ルータ コンフィギュレーション コマンドを使用します。
例
次の例では、プレフィックス リストと配布リストを定義して、ネットワーク 10.1.1.0/24、ネットワーク 192.168.1.0、およびネットワーク 10.108.0.0 からのトラフィックだけを受け入れるように BGP ルーティング プロセスを設定しています。着信ルート リフレッシュが開始され、配布リストがアクティブ化されます。
ルーティング情報の送信元のフィルタリング
一部のルーティング情報が他の情報よりも正確な場合があるため、フィルタリングを使用して、さまざまな送信元から送られる情報にプライオリティを設定できます。アドミニストレーティブ ディスタンスは、ルータやルータのグループなど、ルーティング情報送信元の信頼性を表す数値です。 大規模ネットワークでは、他のルーティング プロトコルよりも信頼できるルーティング プロトコルが存在する場合があります。アドミニストレーティブ ディスタンスの値を指定すると、ルータはルーティング情報の送信元をインテリジェントに区別できるようになります。常にルーティング プロトコルのアドミニストレーティブ ディスタンスが最短(値が最小)であるルートが選択されます。
はじめる前に
■![]() 常に、具体性が最低のネットワークから最高のネットワークの順になるようにアドミニストレーティブ ディスタンスを設定します。
常に、具体性が最低のネットワークから最高のネットワークの順になるようにアドミニストレーティブ ディスタンスを設定します。
■![]() 『 Cisco IOS IP Routing: Protocol-Independent Command Reference 』の distance コマンドの使用上の注意事項とその他の例を確認してください。
『 Cisco IOS IP Routing: Protocol-Independent Command Reference 』の distance コマンドの使用上の注意事項とその他の例を確認してください。
手順の詳細
アドミニストレーティブ ディスタンスを削除するには、 no distance ルータ コンフィギュレーション コマンドを使用します。
例
次の例では、routereigrp グローバル コンフィギュレーション コマンドで、自律システム番号 109 で EIGRP ルーティングを設定しています。network ルータ コンフィギュレーション コマンドは、ネットワーク 192.168.7.0 と 172.16.0.0 で EIGRP ルーティングを指定します。1 番目の distance コマンドでは、クラス C ネットワーク 192.168.7.0 上のすべてのルータのアドミニストレーティブ ディスタンスが 90 に設定されます。2 番目の distance コマンドでは、アドレス 172.16.1.3 のルータに 120 のアドミニストレーティブ ディスタンスが設定されます。
次の例では、設定されたディスタンスは具体性が最低のネットワークから最高のネットワークへの順になります。
認証キーの管理
キー管理を使用すると、ルーティング プロトコルで使用される認証キーを制御できます。一部のプロトコルでは、キー管理を使用できません。認証キーは EIGRP および RIP バージョン 2 で使用できます。
認証キーを管理するには、キー チェーンを定義してそのキー チェーンに属するキーを識別し、各キーの有効期間を指定します。各キーには、ローカルにストアされる独自のキー ID( key number キー チェーン コンフィギュレーション コマンドで指定)があります。キー ID、およびメッセージに関連付けられたインターフェイスの組み合わせにより、使用中の認証アルゴリズムおよび Message Digest 5(MD5)認証キーが一意に識別されます。
有効期間が指定された複数のキーを設定できます。存在する有効なキーの数にかかわらず、送信される認証パケットは 1 つだけです。最小の番号から順にキー番号が調べられ、最初に見つかった有効なキーが使用されます。キー変更中は、有効期間が重なっても問題ありません。これらの有効期間は、ルータに通知する必要があります。
はじめる前に
認証キーを管理する前に、認証をイネーブルにする必要があります。プロトコルに対して認証をイネーブルにする方法については、該当するプロトコルについての説明を参照してください。
手順の詳細
キーチェーンを削除するには、 no key chain name-of-chain グローバル コンフィギュレーション コマンドを使用します。
例
次の例では、chain1 という名前のキー チェーンが設定されます。Key1 という名前のキーは、午後 1 時 30 分から午後 3 時 30 分まで承認され、午後 2 時から午後 3 時まで送信されます。Key2 という名前のキーは、午後 2 時 30 分から午後 4 時 30 分まで承認され、午後 3 時から午後 4 時まで送信されます。この重複により、キーの移行またはルータの設定時間の不一致に対処できます。時間の違いを処理するために、前後に 30 分間の余裕が設けられています。
設定の確認
特定のキャッシュ、テーブル、またはデータベースのすべての内容を削除できます。特定の統計情報を表示することもできます。
|
|
|
|---|---|
show ip route [ address [ mask ] [ longer-prefixes ]] | [ protocol [ process-id ]] |
|
関連資料
■![]() 『Cisco IOS Master Command List, All Releases』
『Cisco IOS Master Command List, All Releases』
■![]() 『IP Addressing: ARP Configuration Guide, Cisco IOS Release 15M&T』
『IP Addressing: ARP Configuration Guide, Cisco IOS Release 15M&T』
■![]() 『Cisco IOS IP Routing: RIP Command Reference』
『Cisco IOS IP Routing: RIP Command Reference』
■![]() 『IP Routing: RIP Configuration Guide, Cisco IOS Release 15M&T』
『IP Routing: RIP Configuration Guide, Cisco IOS Release 15M&T』
■![]() 『Cisco IOS IP Routing: OSPF Command Reference』
『Cisco IOS IP Routing: OSPF Command Reference』
■![]() 『IP Routing: OSPF Configuration Guide, Cisco IOS Release 15M&T』
『IP Routing: OSPF Configuration Guide, Cisco IOS Release 15M&T』
■![]() 『Cisco IOS IP Routing: EIGRP Command Reference』
『Cisco IOS IP Routing: EIGRP Command Reference』
■![]() 『IP Routing: EIGRP Configuration Guide, Cisco IOS Release 15M&T』
『IP Routing: EIGRP Configuration Guide, Cisco IOS Release 15M&T』
■![]() 『Cisco IOS IP Routing: BGP Command Reference』
『Cisco IOS IP Routing: BGP Command Reference』
■![]() 『IP Routing: BGP Configuration Guide, Cisco IOS Release 15M&T』
『IP Routing: BGP Configuration Guide, Cisco IOS Release 15M&T』
■![]() 『Cisco IOS ISO CLNS Command Reference』
『Cisco IOS ISO CLNS Command Reference』
■![]() 『ISO CLNS Configuration Guide, Cisco IOS Release 15M&T』
『ISO CLNS Configuration Guide, Cisco IOS Release 15M&T』
■![]() 『Cisco IOS IP Routing: ISIS Command Reference』
『Cisco IOS IP Routing: ISIS Command Reference』
■![]() 『IP Routing: ISIS Configuration Guide, Cisco IOS Release 15M&T』
『IP Routing: ISIS Configuration Guide, Cisco IOS Release 15M&T』
■![]() 『High Availability Configuration Guide, Cisco IOS Release 15S』
『High Availability Configuration Guide, Cisco IOS Release 15S』
■![]() 『IP Routing: BFD Configuration Guide, Cisco IOS Release 15M&T』
『IP Routing: BFD Configuration Guide, Cisco IOS Release 15M&T』
■![]() 『Cisco IOS IP Routing: Protocol-Independent Command Reference』
『Cisco IOS IP Routing: Protocol-Independent Command Reference』
■![]() 『IP Routing: Protocol-Independent Configuration Guide, Cisco IOS Release 15M&T』
『IP Routing: Protocol-Independent Configuration Guide, Cisco IOS Release 15M&T』
 フィードバック
フィードバック