Cisco WAN and Application Optimization Solution Guide
Bias-Free Language
The documentation set for this product strives to use bias-free language. For the purposes of this documentation set, bias-free is defined as language that does not imply discrimination based on age, disability, gender, racial identity, ethnic identity, sexual orientation, socioeconomic status, and intersectionality. Exceptions may be present in the documentation due to language that is hardcoded in the user interfaces of the product software, language used based on RFP documentation, or language that is used by a referenced third-party product. Learn more about how Cisco is using Inclusive Language.
- Updated:
- June 9, 2008
Chapter: Network Management
- 8.1 Centralized Monitoring, Reporting, and Troubleshooting
- 8.2 NetQoS Performance Center: Network-Wide Monitoring and Reporting
- 8.3 NetQoS ReporterAnalyzer: Analyzing Link Traffic using NetFlow
- 8.4 NetQoS NetVoyant: Monitoring Device Performance and IP SLA
- 8.5 NAM: Granular Monitoring and Troubleshooting
- 8.6 Monitoring and Profiling Network and Application Usage
- 8.7 Granular Live and History Reporting
- 8.8 Configuration Management
Network Management
The Cisco WAN and application optimization solution provides a powerful set of WAN optimization features. To translate these features into verifiable user benefits, effective network management tools are required.
This chapter describes important network management features of the WAN and application optimization solution.
Instead of a general discussion on network management covering a wide range of management functions (for example, network planning and security), the focus here is specifically on traffic and performance monitoring, with a brief overview of configuration management. These functions are immediately relevant to the WAN and application optimization solution deployment and operation.
8.1 Centralized Monitoring, Reporting, and Troubleshooting
Adequate monitoring, reporting, and troubleshooting are essential elements of successful WAN optimization initiatives. The value of these features transcends functional teams, providing technology and business managers with the information needed to enhance productivity, enabling IT and network architecture groups to improve infrastructure design; and reduce time spent solving problems.
For the WAN and application optimization solution, the core monitoring features help the user to:
1. ![]() Profile traffic patterns and resource bottleneck loads, enabling the user to prioritize links and protocols to be optimized
Profile traffic patterns and resource bottleneck loads, enabling the user to prioritize links and protocols to be optimized
2. ![]() Baseline performance metrics for applications (for example, transaction times) and for resources (for example, link and server CPU/memory utilization) before WAN optimization
Baseline performance metrics for applications (for example, transaction times) and for resources (for example, link and server CPU/memory utilization) before WAN optimization
3. ![]() Assess the effectiveness of each successive WAN optimization initiative
Assess the effectiveness of each successive WAN optimization initiative
4. ![]() Troubleshoot problems that occur during and after the successive WAN optimization initiatives
Troubleshoot problems that occur during and after the successive WAN optimization initiatives
8.1.1 Monitoring Challenges and Solutions
WAN optimization devices present new challenges for developers of network monitoring products. Any WAN optimization device has at least some potential to disrupt network traffic monitoring to varying degrees.
For example, optimization device pairs can employ Layer 3 (L3) tunneling architectures and LAN-WAN segmentation. Most WAN optimization devices do not preserve original IP addresses and TCP port information for optimized user-to-server connections. Such changes can cause many conventional monitoring techniques to generate obscure or unintelligible traffic profile data.
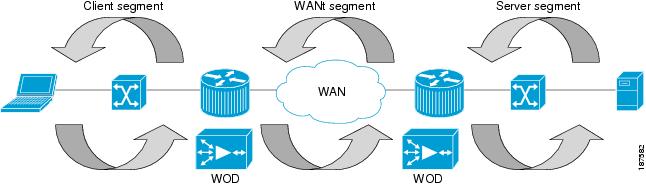
Optimization devices can disrupt performance measurements. Leading WAN optimization devices rely on TCP proxy to manage connections locally at each appliance, as shown in Figure 8-1. Each WAN optimization device acknowledges received TCP transmissions before actually sending data across the network. This behavior can skew response time analysis.
For example, application response time monitors may report the near-immediate acknowledgment of data that has not yet been transmitted, received, and acknowledged over the WAN, causing incorrect reporting of response times. Numerous network monitoring techniques can fail to accurately report performance metrics in this environment.
Figure 8-1 TCP Proxy Architecture Used in Typical WAN Optimization Devices
Fortunately, Cisco WAN optimization technologies are architected to help overcome the transparency issues found in competing products. For example, Cisco Wide Area Application Services (WAAS):
•![]() Preserves client and server IP addresses and TCP port numbers
Preserves client and server IP addresses and TCP port numbers
•![]() Exposes performance metrics for optimized traffic using FlowAgent technology on the WAAS Wide-Area Application Engine (WAE) appliance and NME network modules
Exposes performance metrics for optimized traffic using FlowAgent technology on the WAAS Wide-Area Application Engine (WAE) appliance and NME network modules
•![]() Does not mask detailed NetFlow traffic records.
Does not mask detailed NetFlow traffic records.
When deployed with NetQoS and Cisco monitoring products specifically designed for use in Cisco WAN optimized environments, users benefit from end-to-end and tier-to-tier visibility of application performance, more accurate reporting of traffic traversing the network, and detailed device performance metrics.
8.2 NetQoS Performance Center: Network-Wide Monitoring and Reporting
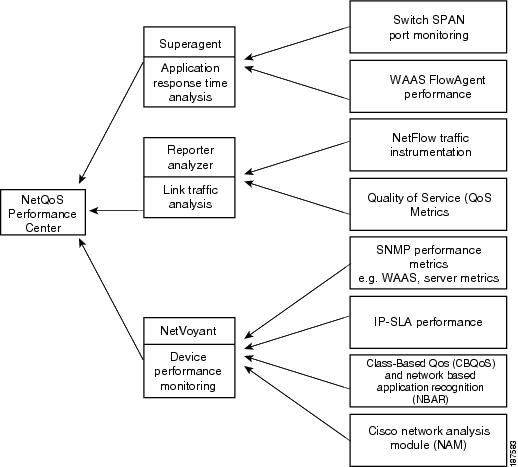
Today's best-of-breed network performance management products draw from multiple data sources to expedite problem resolution and improve infrastructure planning. The NetQoS Performance Center suite of management modules presents a rich set of analytical data using a single interface. NetQoS Performance Center derives this data from passive monitors and Cisco monitoring instrumentation that is already present in network and data center devices. See Chapter 4, "Cisco Monitoring Instrumentation" and Figure 8-2.
The Cisco WAN and application optimization solution incorporates NetQoS Performance Center to deliver powerful and integrated WAN traffic and performance monitoring. Refer to the following URL for more information about NetQos:
http://www.netqos.com/Cisco_wan_optimization/index.html
The NetQoS Performance Center provides flexible views and reporting to help effectively manage networks, applications, and devices. From this intuitive, Web-based network performance monitoring, the network operator can drill into detailed information provided by the following NetQoS product modules:
•![]() NetQoS SuperAgent for end-to-end performance monitoring
NetQoS SuperAgent for end-to-end performance monitoring
•![]() NetQoS ReporterAnalyzer for traffic analysis
NetQoS ReporterAnalyzer for traffic analysis
•![]() NetQoS NetVoyant for device performance management
NetQoS NetVoyant for device performance management
The NetQoS Performance Center also facilitates integration with third-party products - making it possible, for example, to publish summary views of infrastructure performance in business portals such as Microsoft SharePoint.
Figure 8-2 NetQoS Products
The NetQoS Performance Center enables users to view performance metrics from multiple data sources to facilitate troubleshooting, capacity planning, and management reporting. For example, correlating a slowdown in application access times with emerging congestion helps detect and correct the problem.
In this case, NetQoS SuperAgent reported the slowdown in application access times, which were detected through changes in application response times derived from FlowAgent instrumentation in WAE devices. This was correlated with emerging congestion caused by database replication traffic at peak office work times, which NetQoS ReporterAnalyzer reported. (ReporterAnalyzer takes metrics from IOS NetFlow-enabled routers and switches.)
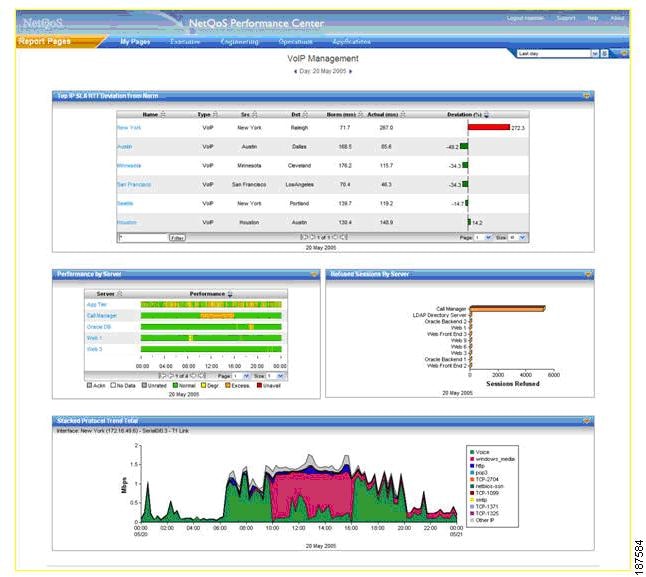
NetQoS Performance Center provides role-based views of performance data. Users having different responsibilities, or working in different geographies, can view data in ways that are tailored to their needs. Figure 8-3 illustrates role-based views.
Consider the example of separate application teams where each team is responsible for monitoring the performance of a different set of applications. When appropriately configured, NetQoS Performance Center can present tailored reports that deliver performance information only for the applications relevant to each team.
Figure 8-3 NetQoS Performance Center
8.2.1 NetQoS SuperAgent: Measuring Application Response Times
NetQoS SuperAgent is a passive application response time (ART) monitoring and reporting module that is installed in the data center. Through continuous performance analysis of TCP/IP applications, SuperAgent calculates performance baselines for applications, servers, and network links, and alerts the user when performance degrades beyond a preconfigured threshold or an automatically learned baseline. Operations staff can then isolate performance issues to the specific IT resource responsible for degraded performance.
The SuperAgent product monitors all the TCP application packets from the network into the data center and out again providing a way to measure Network round trip time (RTT), server response time (SRT), data transfer time (DTT), and much more. The SuperAgent product separates response time into application, network, and server delay components, enabling the customer to detect network performance bottlenecks rapidly to help protect application performance.
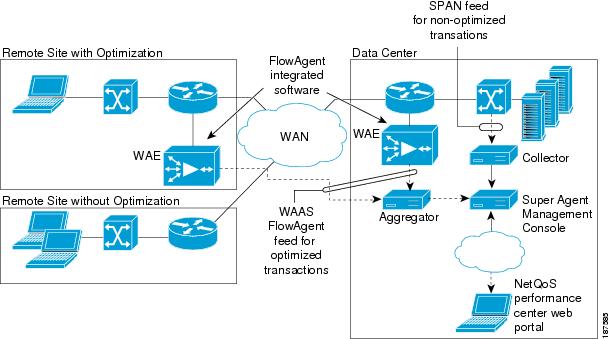
The SuperAgent product comprises at least one collection device and a management console. A collection device gathers relevant data from network devices and forwards the data to the SuperAgent Management Console. SuperAgent uses two types of collection devices: the SuperAgent Collector and the SuperAgent Aggregator. The SuperAgent Collector collects data from regular switches using a SPAN mechanism. The SuperAgent Aggregator collects data from an embedded agent (called a flow agent) residing in WAAS WAEs.
Integrating SuperAgent Aggregator and WAAS FlowAgent enables more accurate reporting of response times on optimized traffic where WAAS is deployed. Figure 8-4 shows a typical SuperAgent deployment comprising a SuperAgent Aggregator, a SuperAgent Collector, and a SuperAgent Management Console for long-term data storage and reporting. SuperAgent monitors end-to-end application delivery in optimized WAAS and nonoptimized environments. Users can quickly install and configure SuperAgent to monitor very large environments, making SuperAgent a practical choice for complex datacenters and networks.
Figure 8-4 NetQoS SuperAgent Application Response Time Collection Architecture and WAAS
With a relatively small number of collection appliances (and without the installation of end user client or server based agents), SuperAgent can help the user to determine:
•![]() Historically normal performance for individual servers, applications, and network links
Historically normal performance for individual servers, applications, and network links
•![]() The specific origin of application, network, and server performance problems
The specific origin of application, network, and server performance problems
•![]() Precisely how planned and unplanned changes affect application delivery
Precisely how planned and unplanned changes affect application delivery
•![]() The impact of IT initiatives (for example, WAN and application optimization) on performance service level objectives
The impact of IT initiatives (for example, WAN and application optimization) on performance service level objectives
The SuperAgent reporting dashboard provides:
•![]() Time-based baselines by application, server, and network
Time-based baselines by application, server, and network
•![]() Response-time graphs(see the example shown in Figure 8-5) showing how server, application, and network delays affect the delivery of any configured TCP/IP application, at particular sites or for user-groups at those sites.
Response-time graphs(see the example shown in Figure 8-5) showing how server, application, and network delays affect the delivery of any configured TCP/IP application, at particular sites or for user-groups at those sites.
Figure 8-5 SuperAgent Response Time Composition Graphs
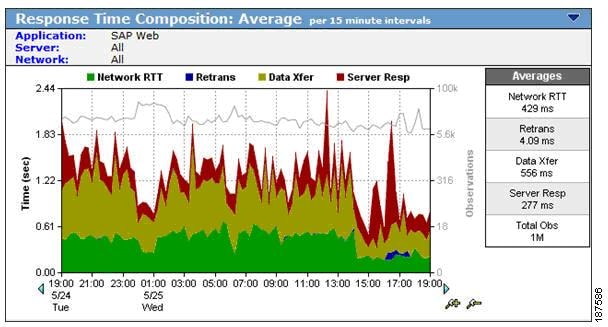
•![]() Operations views (see the example shown in Figure 8-6) showing groups of worst performing networks, servers, and applications in time-based graphs.
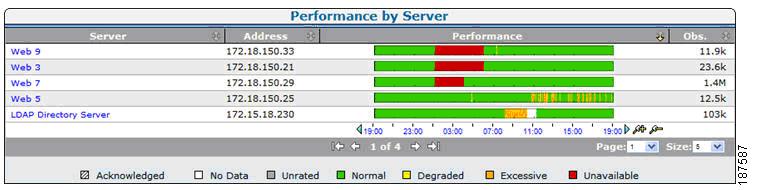
Operations views (see the example shown in Figure 8-6) showing groups of worst performing networks, servers, and applications in time-based graphs.
Figure 8-6 SuperAgent Operations View
•![]() Performance maps (see the example shown in Figure 8-7) that help compare a wide range of metrics for similar IT resources, including servers, applications, and network links, to identify performance issues and candidates for improvement.
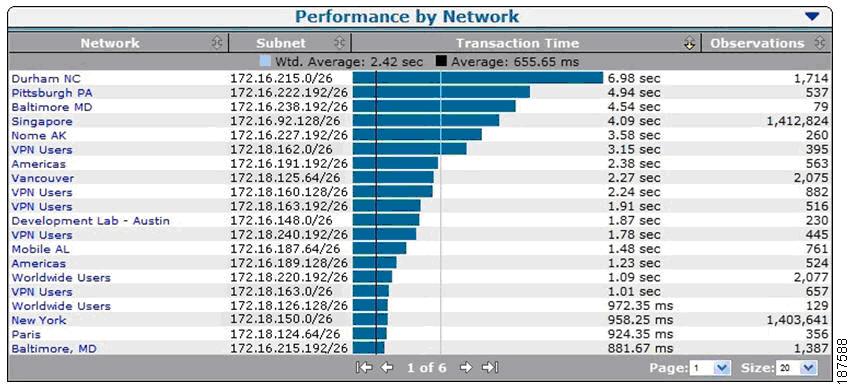
Performance maps (see the example shown in Figure 8-7) that help compare a wide range of metrics for similar IT resources, including servers, applications, and network links, to identify performance issues and candidates for improvement.
Figure 8-7 SuperAgent Performance Maps
•![]() SLA reporting (see the example shown in Figure 8-8) reports whether SLAs are met, and the causes of any deficiencies, to support service level management (SLM).
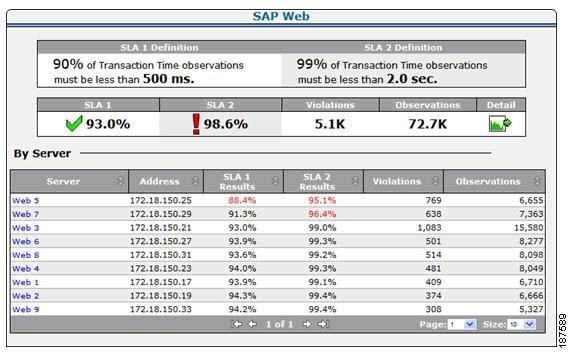
SLA reporting (see the example shown in Figure 8-8) reports whether SLAs are met, and the causes of any deficiencies, to support service level management (SLM).
Figure 8-8 SuperAgent SLA Performance Detail
8.3 NetQoS ReporterAnalyzer: Analyzing Link Traffic using NetFlow
NetQoS ReporterAnalyzer is a traffic analysis module that analyzes and reports how application traffic is affecting network performance by leveraging IOS NetFlow instrumentation present on Cisco routers and switches. It enables the user to see which applications are using bandwidth, who is using the bandwidth, and when. In a single reporting interface, ReporterAnalyzer can display trends that impact a global WAN infrastructure (for purposes of traffic policy monitoring, capacity planning and control) alongside reports of traffic anomalies (for example, malware, peer-to-peer, and unauthorized service protocols) detected from individual devices among many thousands on the network.
The ReporterAnalyzer product comprises the following components:
•![]() Harvester, which passively collects and processes data from NetFlow enabled routers.
Harvester, which passively collects and processes data from NetFlow enabled routers.
•![]() Flow Manager, which aggregates data from multiple Harvesters.
Flow Manager, which aggregates data from multiple Harvesters.
•![]() ReporterAnalyzer Console, which provides a web interface to display collected data.
ReporterAnalyzer Console, which provides a web interface to display collected data.
•![]() Data Storage Appliance (DSA), which stores data for as many as 500 interfaces, or Super DSA for up to 2500 interfaces.
Data Storage Appliance (DSA), which stores data for as many as 500 interfaces, or Super DSA for up to 2500 interfaces.
In a typical ReporterAnalyzer implementation, as shown in Figure 8-9, a Harvester collects raw NetFlow data from configured routers, switches, and other NetFlow compliant devices, processes the data for collection by Flow Manager, and creates local archives for detailed flow analysis and reporting.
Figure 8-9 ReporterAnalyzer Link Traffic Analysis Architecture
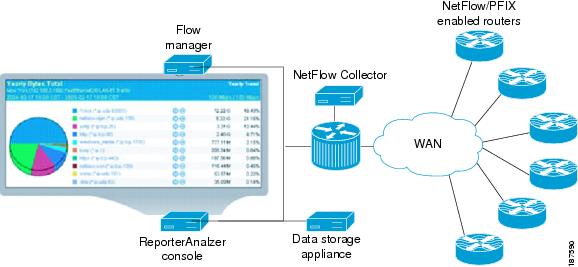
After enabling networking devices to export NetFlow data, and deploying a few Harvester NetFlow collection devices, ReporterAnalyzer users can:
•![]() Identify interfaces, hosts, and applications that generate the most traffic or are most utilized
Identify interfaces, hosts, and applications that generate the most traffic or are most utilized
•![]() View baselines for protocol and flow data
View baselines for protocol and flow data
•![]() Identify network traffic that exceeds specified thresholds
Identify network traffic that exceeds specified thresholds
•![]() View real-time alerts and reports
View real-time alerts and reports
•![]() Help pinpoint the cause of a network problem by reporting on, and drilling into, all traffic flows
Help pinpoint the cause of a network problem by reporting on, and drilling into, all traffic flows
•![]() Identify bandwidth requirements for network applications and users
Identify bandwidth requirements for network applications and users
•![]() Design and run reports based on user-selected criteria
Design and run reports based on user-selected criteria
The ReporterAnalyzer user interface provides views and analytics to support network troubleshooting, forensics, policy monitoring, capacity planning, and management reporting.
ReporterAnalyzer provides the following views.
•![]() An enterprise overview page displays a summary of interfaces that exceed configured utilization thresholds and the top interfaces, protocols, and hosts for the entire network during the preceding 24 hours.
An enterprise overview page displays a summary of interfaces that exceed configured utilization thresholds and the top interfaces, protocols, and hosts for the entire network during the preceding 24 hours.
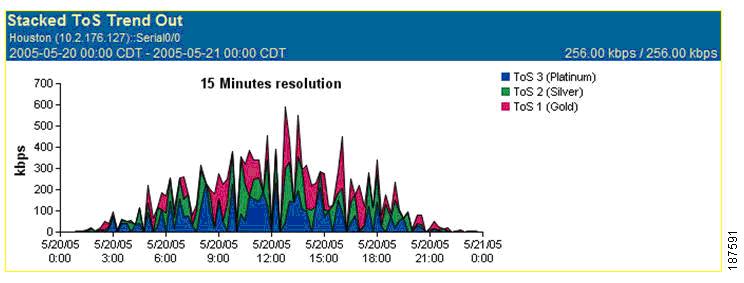
•![]() Interface views show summary information, protocols, hosts, conversations, type of service (ToS), as shown in Figure 8-10, growth reports, baselines, and other data.
Interface views show summary information, protocols, hosts, conversations, type of service (ToS), as shown in Figure 8-10, growth reports, baselines, and other data.
Figure 8-10 ReporterAnalyzer Stacked Trend Plot Showing ToS Distribution on a Link
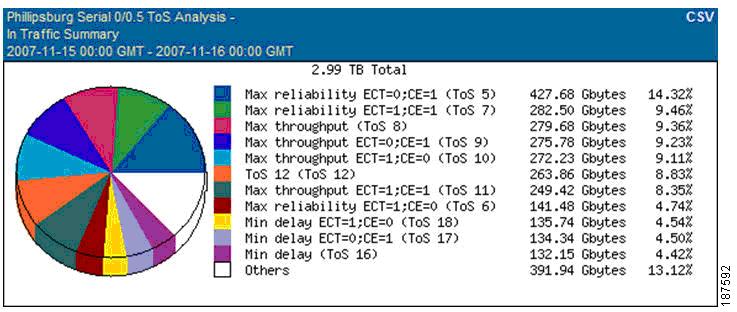
•![]() Custom reports (see the example shown in Figure 8-11), which use a wizard to create interface, protocol, ToS, host, conversation, and combination reports for any timeframe, and that can be run at any designated time.
Custom reports (see the example shown in Figure 8-11), which use a wizard to create interface, protocol, ToS, host, conversation, and combination reports for any timeframe, and that can be run at any designated time.
Figure 8-11 ReporterAnalyzer Custom Report
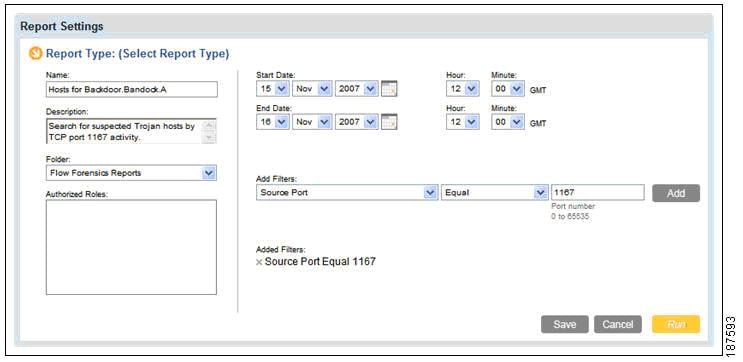
•![]() Flow forensics reports, which use a wizard (see the example shown in Figure 8-12) to create reports that analyze raw NetFlow data to provide insight into any protocol, host, and conversation on the network.
Flow forensics reports, which use a wizard (see the example shown in Figure 8-12) to create reports that analyze raw NetFlow data to provide insight into any protocol, host, and conversation on the network.
Figure 8-12 ReporterAnalyzer Flow Forensics Wizard
•![]() Analysis reports, which use a wizard to compare collected data to an established threshold, and can be run on a schedule, or at any specified time.
Analysis reports, which use a wizard to compare collected data to an established threshold, and can be run on a schedule, or at any specified time.
8.4 NetQoS NetVoyant: Monitoring Device Performance and IP SLA
NetQoS NetVoyant is an appliance-based Simple Network Management Protocol (SNMP) monitoring and reporting module that helps users identify trends and potential problems early enough to potentially avoid lost productivity. NetVoyant takes advantage of the comprehensive SNMP performance data provided by Cisco devices to help IT administrators provide more consistent application delivery, optimize the network infrastructure for better application performance, and equip their staff to solve complex problems.
(SNMP) instrumentation from routers, switches, servers, frame relay circuits, logical segments, and wide area links can provide essential data for troubleshooting, capacity planning, and management reporting. Through SNMP instrumentation, Cisco products provide comprehensive device performance statistics, service level metrics, and application data. For example, Cisco WAE devices can report service statistics, configuration data, and resource consumption through SNMP.
NetVoyant monitors performance metrics from a variety of sources:
•![]() Network and datacenter devices can be polled to report CPU and memory statistics, interface utilization, availability, configuration data, and other key metrics.
Network and datacenter devices can be polled to report CPU and memory statistics, interface utilization, availability, configuration data, and other key metrics.
•![]() IP SLA agents on Cisco routers can be configured and polled to provide latency, jitter, connection tests, and other statistics between a host router and specified targets.
IP SLA agents on Cisco routers can be configured and polled to provide latency, jitter, connection tests, and other statistics between a host router and specified targets.
•![]() Network Based Application Recognition (NBAR), Remote Network Monitoring (RMON) metrics, and application response time (ART) from Cisco Network Analysis Modules (NAMs) can be polled.
Network Based Application Recognition (NBAR), Remote Network Monitoring (RMON) metrics, and application response time (ART) from Cisco Network Analysis Modules (NAMs) can be polled.
•![]() Class-based quality of service (CBQoS) management information bases (MIBs) on Cisco routers can be polled to provide utilization statistics for each class of service.
Class-based quality of service (CBQoS) management information bases (MIBs) on Cisco routers can be polled to provide utilization statistics for each class of service.
Figure 8-13 illustrates a typical NetVoyant distributed configuration. NetVoyant can be deployed on a single server or in a distributed configuration as shown.
Figure 8-13 NetVoyant Device Performance Monitoring Architecture
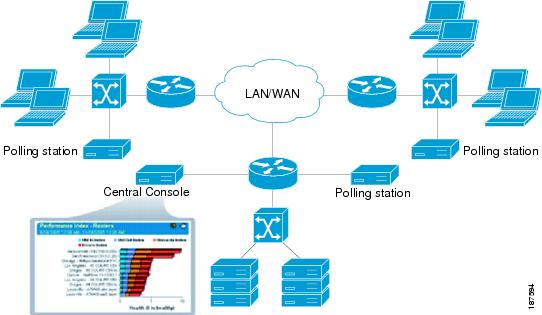
In a distributed configuration, a NetVoyant Master Console performs administration and reporting while remote Polling Stations discover and poll devices on the network. Because the volume of data collected from polling stations is much smaller than the volume of received SNMP data, on large networks it can be advantageous to place polling stations near the devices that they monitor to minimize management traffic on the WAN. During initial configuration, a wizard helps the administrator configure SNMP settings, initialize discovery processes, and determine the types of devices to monitor.
NetVoyant organizes reporting features according to user tasks:
•![]() Management reports provide comprehensive survey views of devices and network performance using scorecards and summaries by device (as shown in Figure 8-14) and network segment.
Management reports provide comprehensive survey views of devices and network performance using scorecards and summaries by device (as shown in Figure 8-14) and network segment.
Figure 8-14 NetVoyant Management Views
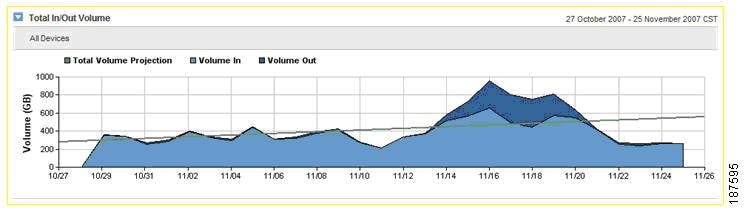
•![]() Capacity planning reports (see the example shown in Figure 8-15) support planning for device and network link upgrades and help identify the resources with the fastest growth and characteristics approaching defined thresholds.
Capacity planning reports (see the example shown in Figure 8-15) support planning for device and network link upgrades and help identify the resources with the fastest growth and characteristics approaching defined thresholds.
Figure 8-15 Figure 8-15. NetVoyant Capacity Planning
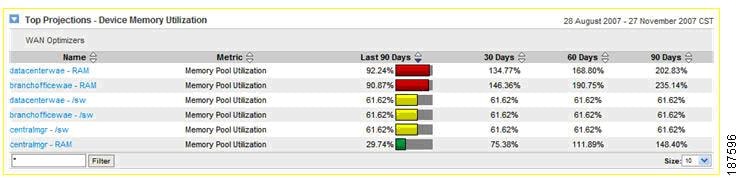
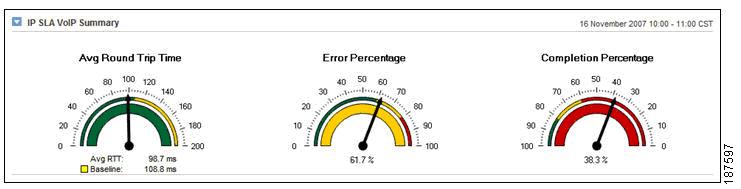
•![]() Service level reports (see the example shown in Figure 8-16) can help users to verify compliance with SLAs and to help track performance metrics with unexpected values, including data from IP SLA tests, VoIP statistics, and CBQoS reports.
Service level reports (see the example shown in Figure 8-16) can help users to verify compliance with SLAs and to help track performance metrics with unexpected values, including data from IP SLA tests, VoIP statistics, and CBQoS reports.
Figure 8-16 NetVoyant SLA Reports
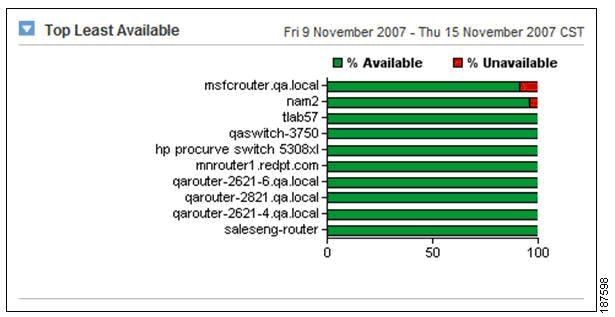
•![]() Operations reports (see the example shown in Figure 8-17) provide an operations-level view of devices on the network, with views that include the devices that are most unavailable, the interfaces that are most utilized, and events and alarms for SNMP data collection issues. In the view shown in Figure 8-17, the SNMP poller msfcrouter.qa.local was unavailable 10% of the time.
Operations reports (see the example shown in Figure 8-17) provide an operations-level view of devices on the network, with views that include the devices that are most unavailable, the interfaces that are most utilized, and events and alarms for SNMP data collection issues. In the view shown in Figure 8-17, the SNMP poller msfcrouter.qa.local was unavailable 10% of the time.
Figure 8-17 NetVoyant Operations Reports
8.5 NAM: Granular Monitoring and Troubleshooting
Network Analysis Module (NAM) is a powerful integrated network monitoring tool designed to report how users experience network services and to help network operators ensure and improve network performance.
The Cisco WAN and application optimization solution incorporates NAM to help deliver a feature-rich, granular, and interactive troubleshooting capability that can substantially reduce the time and effort needed to isolate configuration and performance problems.
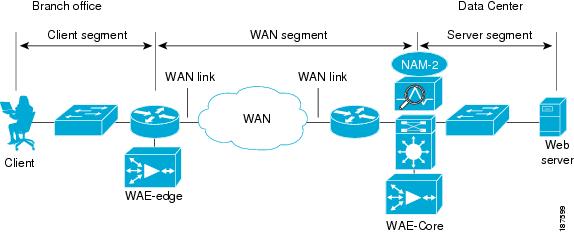
Figure 8-18 shows an example of how NAM is placed in the data center.
Figure 8-18 Example of NAM Placement in the Data Center
Cisco NAM is available as
•![]() A single blade (NAM-1 and NAM-2) for the Cisco Catalyst 6500 Series Switch or the Cisco 7600 Series Router.
A single blade (NAM-1 and NAM-2) for the Cisco Catalyst 6500 Series Switch or the Cisco 7600 Series Router.
•![]() A single network module (NM-NAM and NME-NAM) for the Cisco 2800 and 3800 Series Integrated Services Routers (ISR) and the Cisco 3700 Series Multiservice Access Routers.
A single network module (NM-NAM and NME-NAM) for the Cisco 2800 and 3800 Series Integrated Services Routers (ISR) and the Cisco 3700 Series Multiservice Access Routers.
NAM-2 is the deployment form incorporated into the current WAN and application optimization Solution architecture.
Cisco NAM combines embedded data collection and analysis features with a remotely accessible, web-based management console that delivers:
•![]() Real-time visibility for troubleshooting, with the flexibility to apply filters in real-time - this sidesteps the need to pre-configure data-sources, servers, and applications in troubleshooting contexts;
Real-time visibility for troubleshooting, with the flexibility to apply filters in real-time - this sidesteps the need to pre-configure data-sources, servers, and applications in troubleshooting contexts;
•![]() Deep information granularity, supporting drill-downs to individual conversations, with data-points collected over short time-frames;
Deep information granularity, supporting drill-downs to individual conversations, with data-points collected over short time-frames;
•![]() Short and long-term traffic and performance reports on individual conversations and hosts;
Short and long-term traffic and performance reports on individual conversations and hosts;
•![]() Performance analytics covering TCP application response time metrics, DiffServ QoS, voice and video;
Performance analytics covering TCP application response time metrics, DiffServ QoS, voice and video;
•![]() User-defined trigger-based packet capture, filters and decodes;
User-defined trigger-based packet capture, filters and decodes;
•![]() Integrated NetFlow processing for remote troubleshooting.
Integrated NetFlow processing for remote troubleshooting.
The NAM Traffic Analyzer GUI provides quick access to the configuration menus and presents easy-to-read reports.
8.6 Monitoring and Profiling Network and Application Usage
Cisco NAM can inspect packets to gather information about applications, hosts, and conversations. Application monitoring identifies each application that consumes bandwidth and how much, and detects which hosts are using which applications.
Host and conversation-pair monitoring reports bandwidth consumption per host and shows which hosts talk to each other, along with the amount of traffic each host generates. These metrics reveal usage patterns for users, and for router and switch, interface, server, and application resources.
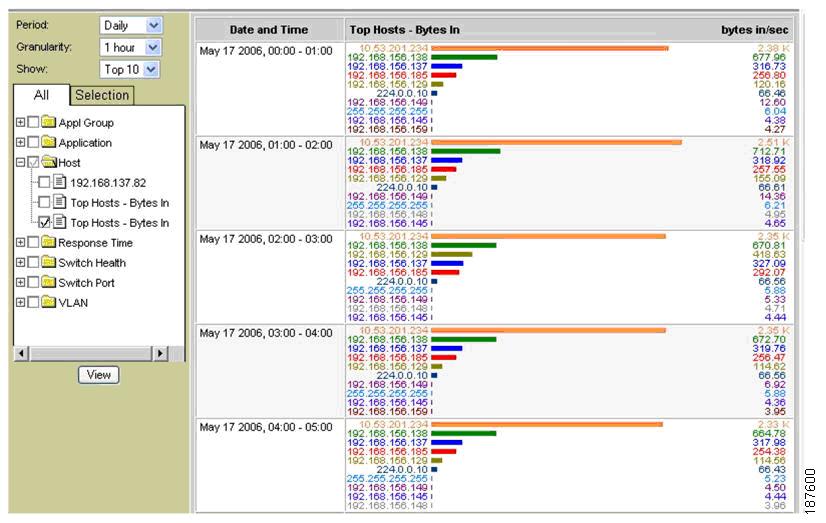
For example, Figure 8-19 shows a report identifying the top 10 hosts on the network.
Figure 8-19 Monitoring the Top 10 Hosts on the Network
8.7 Granular Live and History Reporting
The live conversation reporting capability of NAM exposes potential problems that would otherwise be masked if critical report updates occurred less frequently or within aggregated traffic data. This information helps facilitate quick identification and verification of traffic anomalies so current and impending problems can be rapidly resolved.
NAM delivers granular, real-time snapshots of bandwidth usage and performance, and can be easily configured to deliver continuous history views focused on specific hosts and conversations to help isolate intermittent user or conversation problems. NAM can also collect Data for a specific period and analyzed after the event to discover when an anomaly has occurred so it can be quickly resolved.
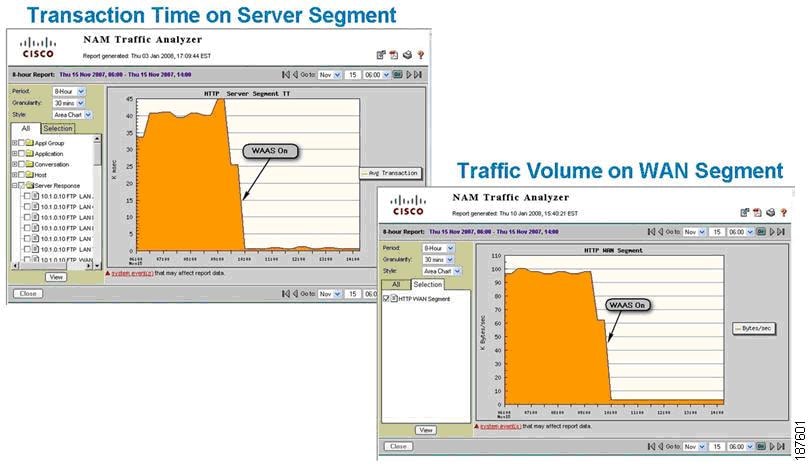
Figure 8-20 illustrates sample history reports.
Figure 8-20 History Reports for WAN and Application Optimization Validation
8.7.1 Transaction-Aware Response-Time Measurement, Monitoring, and Baselining
Cisco NAM implements newly enhanced transaction-based response-time measurement features that passively gather data on TCP-based client/server requests and acknowledgements. The response-time monitoring capability of Cisco NAM provides intelligent information about client, server, and application latency.
By giving fast, easy access to specific host and conversation response-time metrics, Cisco NAM can assist IT staff in troubleshooting application performance problems, analyzing application behavior and performing pre- and post- deployment monitoring of application optimization and acceleration services, as well as defining and tracking targeted service levels.
Figure 8-21 shows examples of granular transaction time views that could be generated to help track intermittent performance problems.
Figure 8-21 Application Response-Time Monitoring
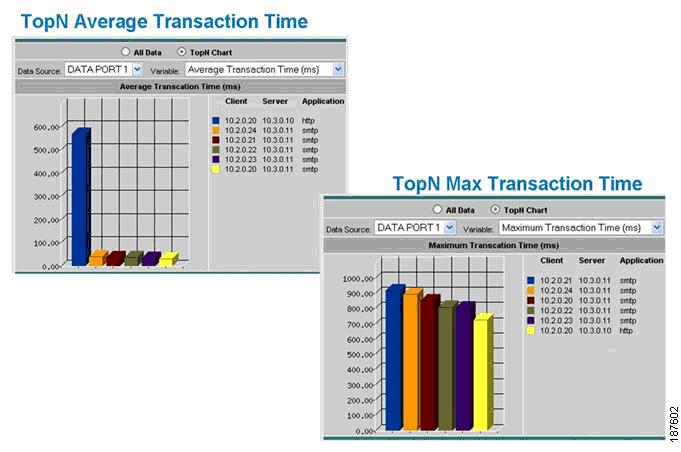
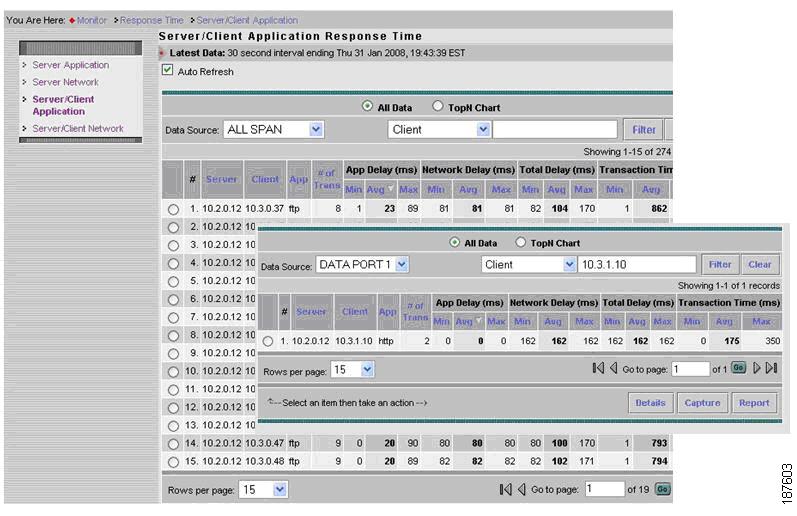
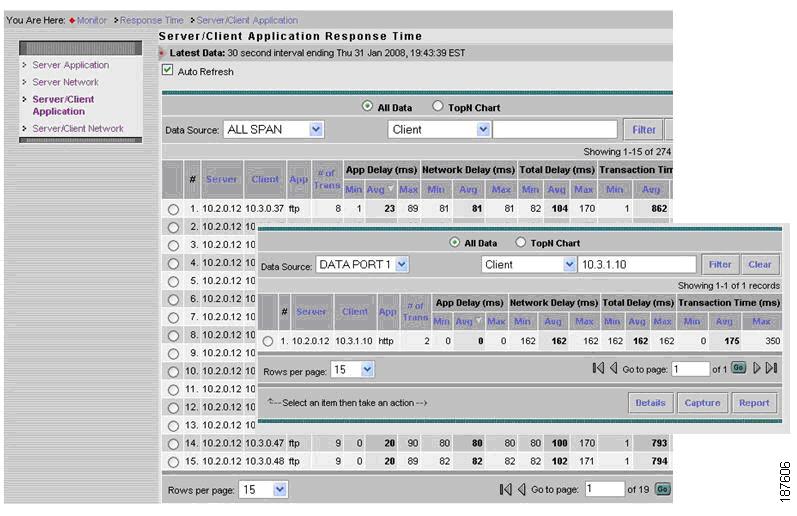
Figure 8-22 illustrates a live drill-down to an individual conversation.
Figure 8-22 Detailed Application Response Times for a Specific Server/Client
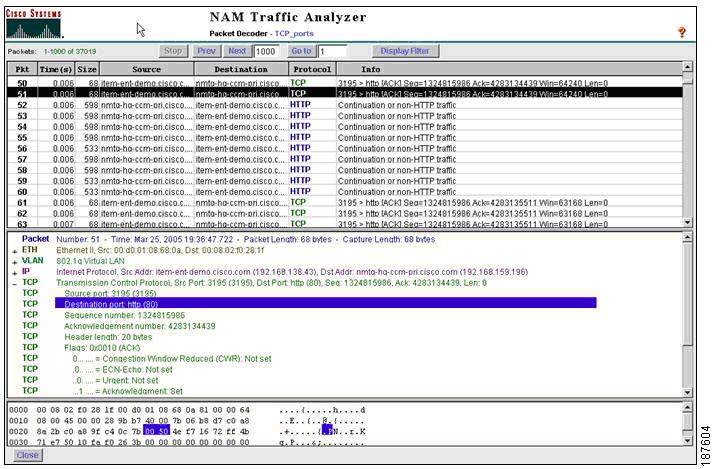
8.7.1.1 Alarms, Packet Captures and Decodes for Troubleshooting
To support isolating intermittent problems, users can set thresholds and alarms on various network parameters such as increased utilization and severe application response delays. When a potential problem is identified, the packet stream can be automatically captured and decoded to help resolve the problem.
Captures can be performed using a Web browser, and decodes can be viewed through the Traffic Analyzer GUI while data is being captured. This helps the user quickly pinpoint and resolve problems when troubleshooting. Because NAM typically uses a local Switched Port Analyzer (SPAN) configuration to perform a capture, capture traffic does not stress the operational user network.
Figure 8-23 Using NAM to Capture and Decode Packets
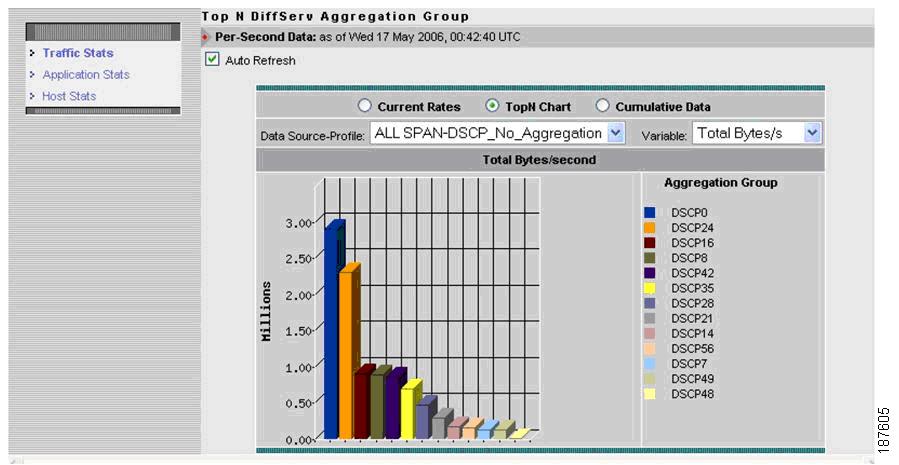
8.7.1.2 Analyzing QoS
NAM supports QoS troubleshooting, through its support of the Differentiated Services Monitoring (DSMON) MIB, which monitors traffic by differentiated services code point (DSCP) allocations defined by QoS policies.
Using its DiffServ monitoring capabilities, NAM can help identify the hosts, conversations, and applications participating in each grouping of DiffServ classes. This information can be used to validate and tune QoS allocations in detailed troubleshooting workflows, to detect incorrectly marked or unauthorized traffic, and in other troubleshooting scenarios. Figure 8-24 provides a QoS monitoring example.
Figure 8-24 QoS Monitoring Using DSMON
8.8 Configuration Management
The WAN and application optimization solution spans multiple network devices and IOS features. However, WAN optimization is only one of the powerful features delivered by those network devices and appliances. Because decisions on configuration will need to take place within a wider context, this section only briefly outlines the functions and products most central to WAN optimization deployments.
8.8.1 General Configuration Management Functions
General configuration covers the generic, network-wide configuration of devices and IOS features as the network evolves.
•![]() Inventory management helps to enables network operations to maintain a comprehensive, up-to-date record of devices and modules on the enterprise network, and to generate tailored inventory reports.
Inventory management helps to enables network operations to maintain a comprehensive, up-to-date record of devices and modules on the enterprise network, and to generate tailored inventory reports.
•![]() Image management helps supports the distribution of software images to the network devices, and the maintenance of up-to-date and consistent images with role-based access control.
Image management helps supports the distribution of software images to the network devices, and the maintenance of up-to-date and consistent images with role-based access control.
•![]() Change management supports the implementation of changes to the network inventory, configuration, and images, and reports on current and historical modifications.
Change management supports the implementation of changes to the network inventory, configuration, and images, and reports on current and historical modifications.
•![]() Network backup supports image and configuration backups and archiving.
Network backup supports image and configuration backups and archiving.
•![]() Compliance support helps enforce enterprise configuration policies, and comply with regulatory requirements such as Sarbanes-Oxley (SOX), using predefined, configurable role-based workflows and detailed policy and regulation compliance reports.
Compliance support helps enforce enterprise configuration policies, and comply with regulatory requirements such as Sarbanes-Oxley (SOX), using predefined, configurable role-based workflows and detailed policy and regulation compliance reports.
The CiscoWorks product suite is available to support the general configuration management for enterprise users. Refer towww.cisco.com for details.
8.8.2 Dedicated Configuration Management
Several products and features in the WAN and application optimization solution require dedicated configuration management to aid or enable customer the configuration of rich features on non-IOS devices, or to increase automation and user guidance for configuring complex IOS features, such as QoS.
Of these, the product most relevant to the WAN and application optimization solution is the Cisco WAAS Central Manager. WAAS Central Manager is a scalable, secure, and simple function that runs on WAE appliances. WAAS Central Manager provides a centralized configuration mechanism, along with basic WAAS deployment monitoring and reporting. WAAS Central Manager can be accessed from a Web browser, allowing secure remote management.
More information about these and other dedicated management products are available on www.cisco.com.
Figure 8-25 A View of Detailed Application Response Times for a Specific Server/Client
 Feedback
Feedback