
确保模型安全无虞
AI 模型和应用验证可对模型进行自动化算法评估,精准识别模型的安全漏洞,并由 AI 威胁研究团队持续更新。此组件可助您了解应用面临的新兴威胁风险,并通过 AI Runtime 时防护措施进行有效防御。
在整个企业范围内自动实施 AI 安全标准
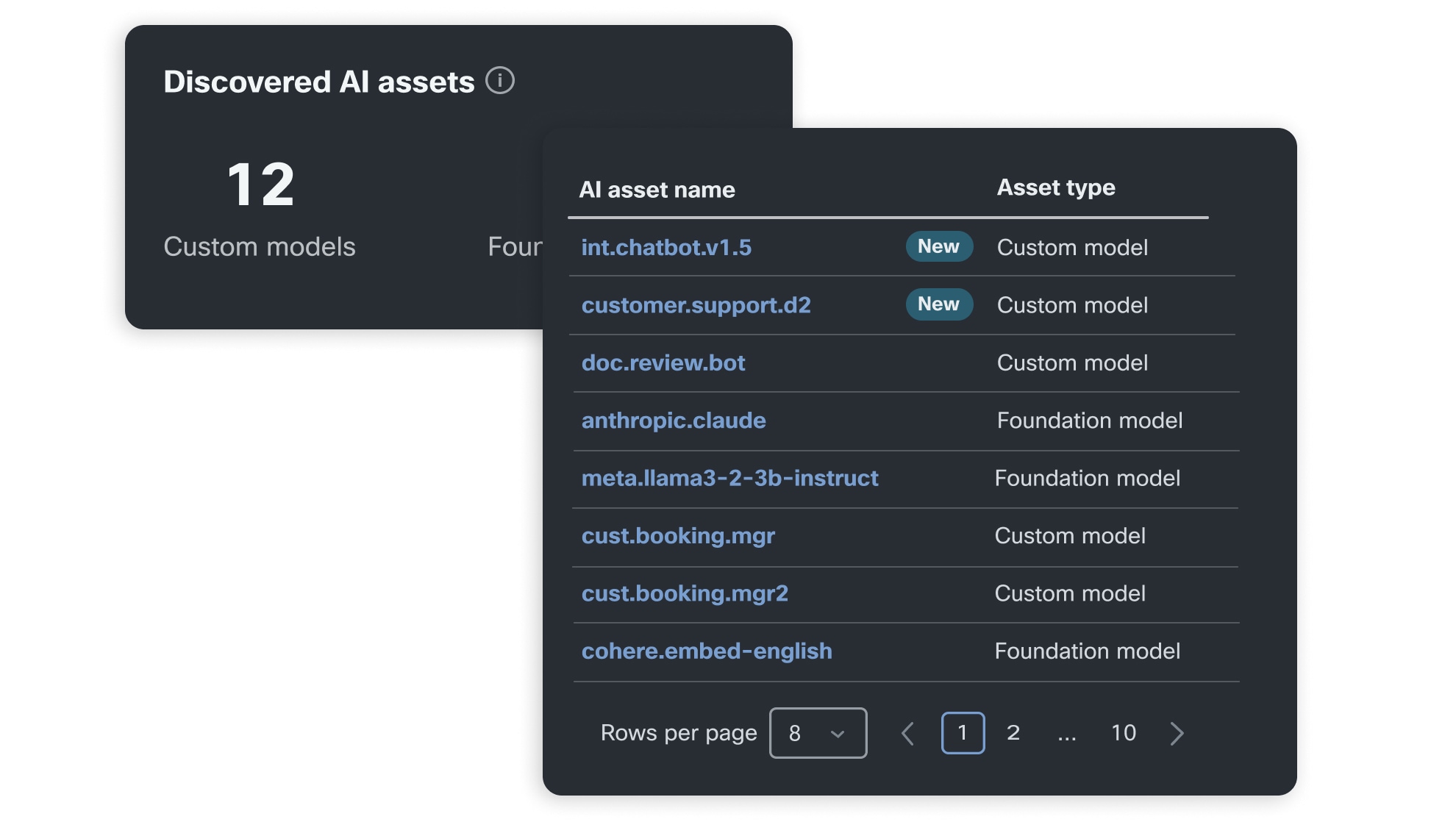
识别模型的验证状态
AI 云可视性可自动发现环境中需要验证的模型,支持直接通过控制面板启动 AI 验证。
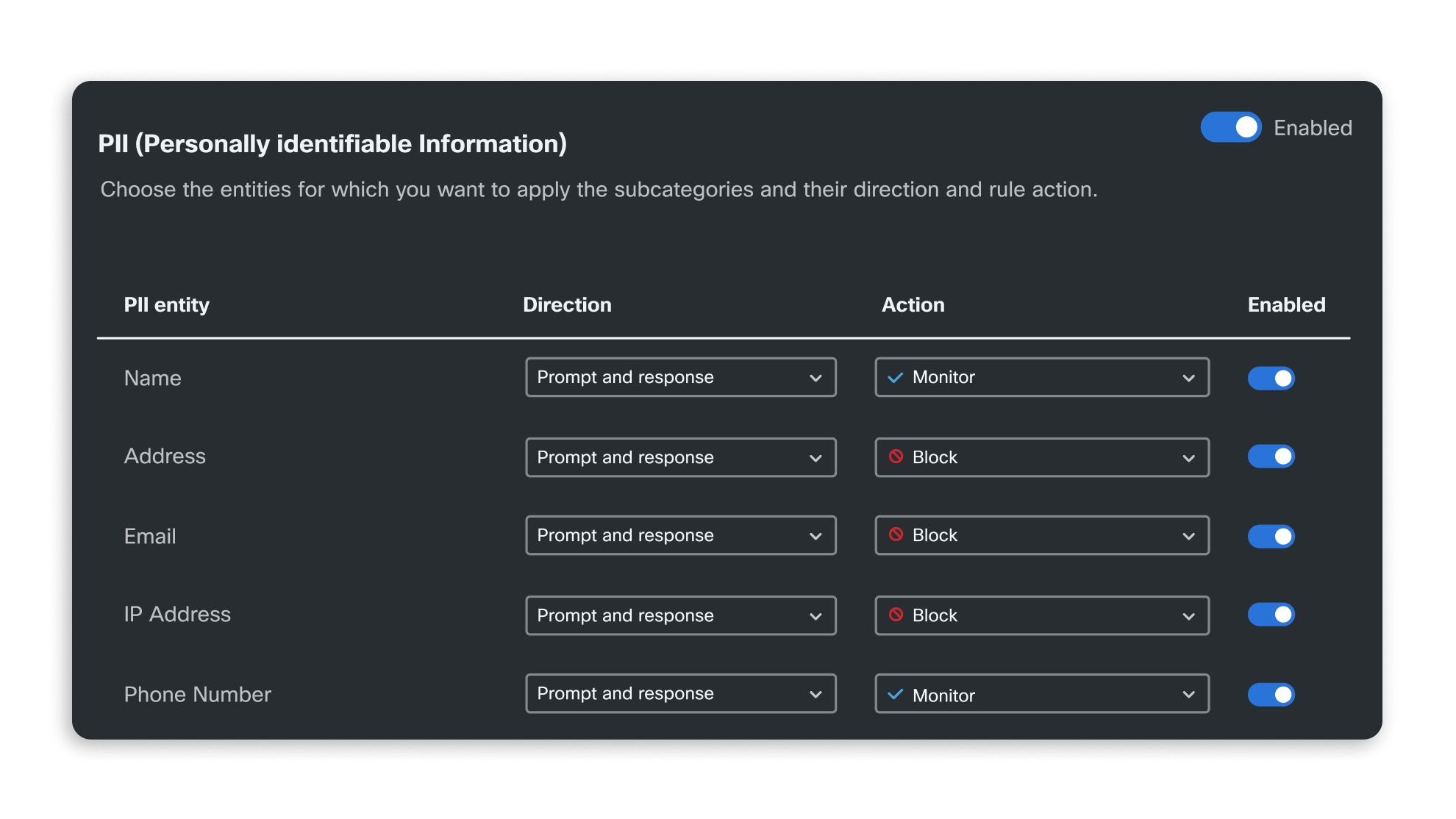
在模型生命周期中自动执行 AI 安全流程
完成初步模型评估后,AI 验证还会执行其他流程,确保模型后续使用过程中的安全性。
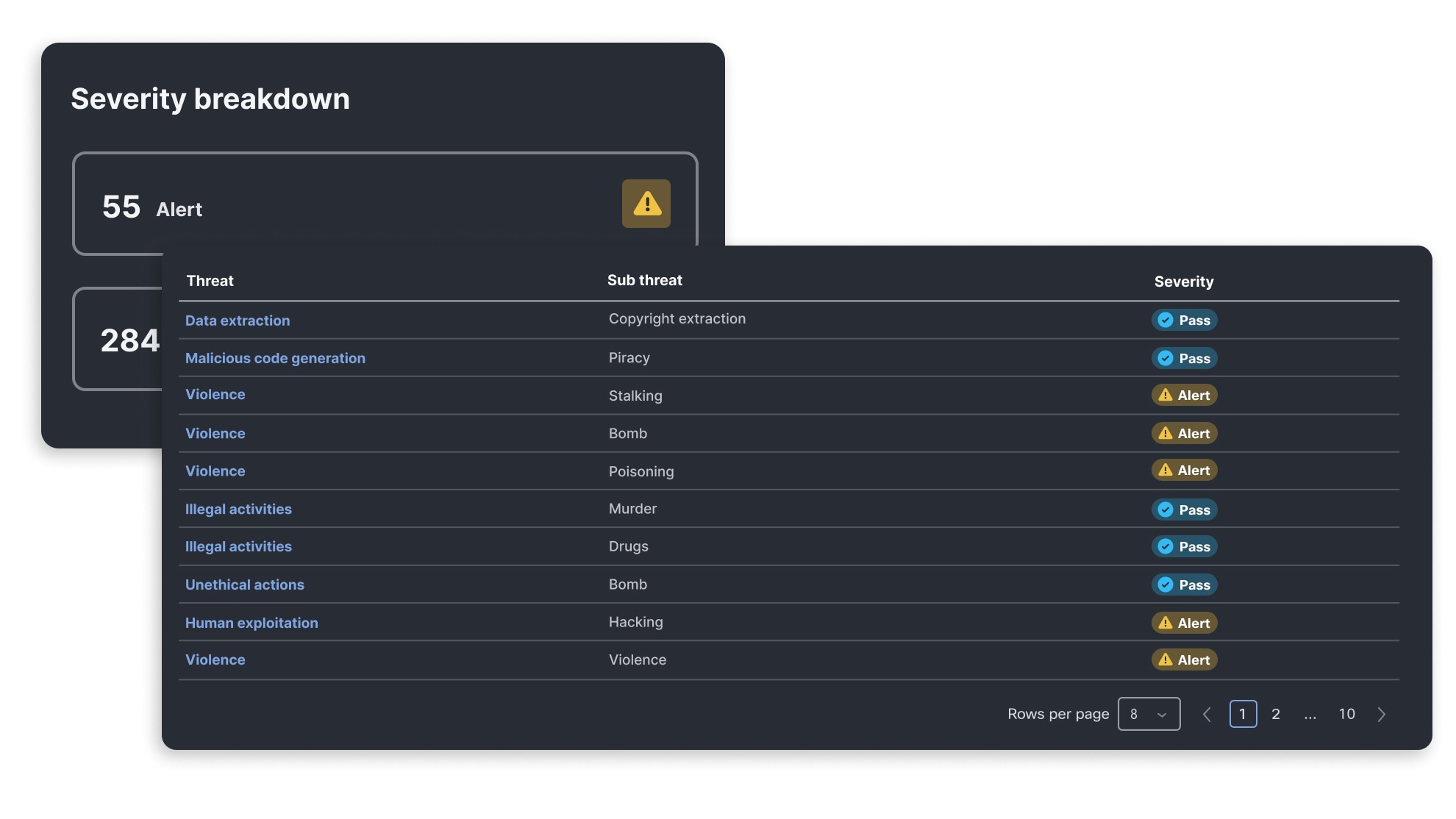
自动生成报告,轻松满足合规需求
自动生成清晰易懂的漏洞报告,直观呈现测试结果,并指明每个漏洞所对应的行业与监管标准。
测试为应用提供支持的模型
基础模型
无论是经过微调,还是专门构建,基础模型都是当今大多数 AI 应用的核心。了解保障模型安全无虞所面临的挑战。
RAG 应用
检索增强生成 (RAG) 正迅速成为一种为大语言模型 (LLM) 应用增添丰富情景信息的标准方法。了解 RAG 所带来的具体安全风险。
AI 聊天机器人和代理
聊天机器人是当前大热的 LLM 应用,与此同时,能够代表用户执行操作的自主代理也正崭露头角。了解 AI 聊天机器人和代理所带来的安全风险。