從Ceph/Storage Cluster - vEPC隔離和替換故障磁碟
下載選項
無偏見用語
本產品的文件集力求使用無偏見用語。針對本文件集的目的,無偏見係定義為未根據年齡、身心障礙、性別、種族身分、民族身分、性別傾向、社會經濟地位及交織性表示歧視的用語。由於本產品軟體使用者介面中硬式編碼的語言、根據 RFP 文件使用的語言,或引用第三方產品的語言,因此本文件中可能會出現例外狀況。深入瞭解思科如何使用包容性用語。
關於此翻譯
思科已使用電腦和人工技術翻譯本文件,讓全世界的使用者能夠以自己的語言理解支援內容。請注意,即使是最佳機器翻譯,也不如專業譯者翻譯的內容準確。Cisco Systems, Inc. 對這些翻譯的準確度概不負責,並建議一律查看原始英文文件(提供連結)。
簡介
本文檔介紹了在Ultra-M設定中將OSD磁碟從託管在對象儲存磁碟(OSD)-Compute上的Ceph/Storage群集隔離和更換這些磁碟所需的步驟。
背景資訊
Ultra-M是經過預打包和驗證的虛擬化移動資料包核心解決方案,旨在簡化VNF的部署。 OpenStack是適用於Ultra-M的虛擬化基礎架構管理器(VIM),包含以下節點型別:
- 計算
- OSD — 計算
- 控制器
- OpenStack平台 — 導向器(OSPD)
Ultra-M的高級體系結構及涉及的元件如下圖所示:
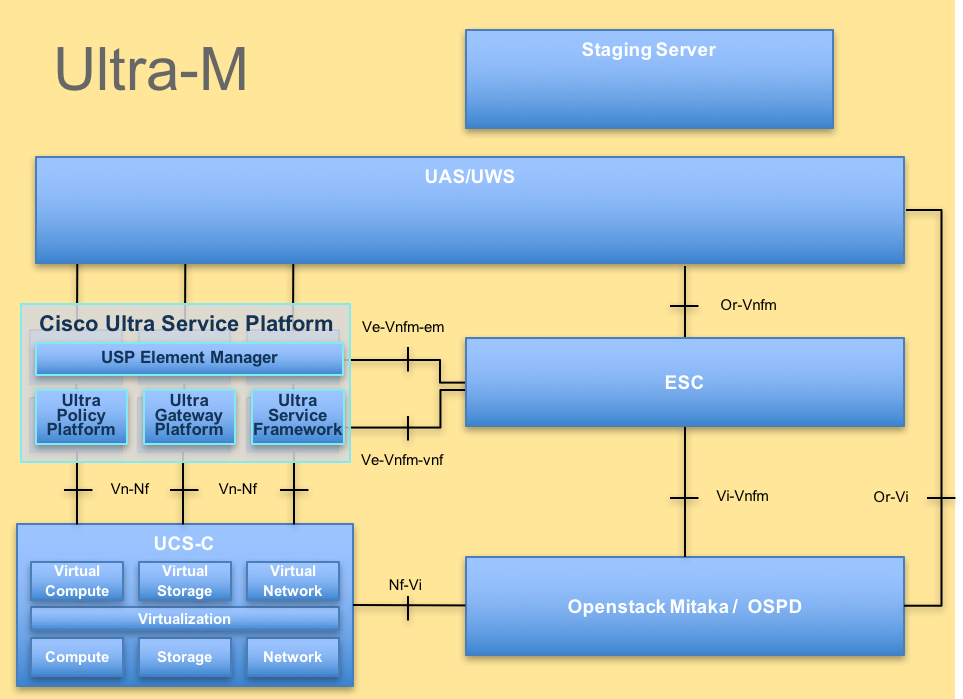 UltraM體系結構本文檔面向熟悉Cisco Ultra-M平台的思科人員,詳細說明了更換OSPD伺服器時在OpenStack級別上需要執行的步驟。
UltraM體系結構本文檔面向熟悉Cisco Ultra-M平台的思科人員,詳細說明了更換OSPD伺服器時在OpenStack級別上需要執行的步驟。
附註:Ultra M 5.1.x版本用於定義本文檔中的過程。
縮寫
| VNF | 虛擬網路功能 |
| CF | 控制功能 |
| SF | 服務功能 |
| ESC | 彈性服務控制器 |
| 澳門幣 | 程式方法 |
| OSD | 對象儲存磁碟 |
| HDD | 硬碟驅動器 |
| 固態硬碟 | 固態驅動器 |
| VIM | 虛擬基礎架構管理員 |
| 虛擬機器 | 虛擬機器 |
| EM | 元素管理器 |
| UAS | Ultra自動化服務 |
| UUID | 通用唯一ID識別符號 |
MoP的工作流程

先決條件運行狀況檢查
1.使用Ceph-disk list命令可瞭解OSD到Journal的對映,並確定要隔離和替換的磁碟。
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph-disk list
/dev/sda :
/dev/sda1 other, iso9660
/dev/sda2 other, xfs, mounted on /
/dev/sdb :
/dev/sdb1 ceph journal, for /dev/sdc1
/dev/sdb3 ceph journal, for /dev/sdd1
/dev/sdb2 ceph journal, for /dev/sde1
/dev/sdb4 ceph journal, for /dev/sdf1
/dev/sdc :
/dev/sdc1 ceph data, active, cluster ceph, osd.1, journal /dev/sdb1
/dev/sdd :
/dev/sdd1 ceph data, active, cluster ceph, osd.7, journal /dev/sdb3
/dev/sde :
/dev/sde1 ceph data, active, cluster ceph, osd.4, journal /dev/sdb2
/dev/sdf :
/dev/sdf1 ceph data, active, cluster ceph, osd.10, journal /dev/sdb4
2.在繼續已識別的OSD磁碟隔離之前,請驗證Ceph運行狀況和OSD樹對映。
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e709: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v941813: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 11922 GB / 13393 GB avail
704 active+clean
client io 58580 B/s wr, 0 op/s rd, 7 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 0 host pod1-osd-compute-1
-4 4.35999 host pod1-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
從群集中隔離和刪除有故障的OSD磁碟
1.禁用並停止OSD進程。
[heat-admin@pod1-osd-compute-3 ~]$ sudo systemctl disable ceph-osd@7
[heat-admin@pod1-osd-compute-3 ~]$ sudo systemctl stop ceph-osd@7
2.標出OSD。
[heat-admin@pod1-osd-compute-3 ~]$ sudo su
[root@pod1-osd-compute-3 heat-admin]# ceph osd set noout
set noout
[root@pod1-osd-compute-3 heat-admin]# ceph osd set norebalance
set norebalance
[root@pod1-osd-compute-3 heat-admin]# ceph osd out 7
marked out osd.7.
附註:等待資料重新平衡完成,所有PG都返回到「活動+清除」狀態以避免問題。
3.確認OSD是否已標出,並等待Ceph重新平衡繼續進行。
[root@pod1-osd-compute-3 heat-admin]# watch -n1 ceph -s
95 active+undersized+degraded+remapped+wait_backfill
28 active+recovery_wait+degraded
2 active+undersized+degraded+remapped+backfilling
1 active+recovering+degraded
2 active+undersized+degraded+remapped+backfilling
1 active+recovering+degraded
2 active+undersized+degraded+remapped+backfilling
67 active+undersized+degraded+remapped+wait_backfill
3 active+undersized+degraded+remapped+backfilling
24 active+undersized+degraded+remapped+wait_backfill
22 active+undersized+degraded+remapped+wait_backfill
1 active+undersized+degraded+remapped+backfilling
8 active+undersized+degraded+remapped+wait_backfill
4.刪除OSD的身份驗證金鑰。
[root@pod1-osd-compute-3 heat-admin]# ceph auth del osd.7
updated
5.確認未列出OSD.7的金鑰。
[root@pod1-osd-compute-3 heat-admin]# ceph auth list
installed auth entries:
osd.0
key: AQCgpB5blV9dNhAAzDN1SVdnuJyTN2f7PAdtFw==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.1
key: AQBdwyBbbuD6IBAAcvG+oQOz5vk62faOqv/CEw==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.10
key: AQCwwyBb7xvHJhAAZKPprXWT7UnvnAXBV9W2rg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.11
key: AQDxpB5b9/rGFRAAkcCEkpSN1YZVDdeW+Bho7w==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.2
key: AQCppB5btekoNBAAACoWpDz0VL9bZfyIygDpBQ==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.3
key: AQC4pB5bBaUlORAAhi3KPzetwvWhYGnerAkAsg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.4
key: AQB1wyBbvMIQLRAAXefFVnZxMX6lVtObQt9KoA==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.5
key: AQDBpB5buKHqOhAAW1Q861qoYqW6fAYHlOxsLg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.6
key: AQDQpB5b1BveFxAAfCLM3tvDUSnYneutyTmaEg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.8
key: AQDZpB5bd4nlGRAAkkzbmGPnEDAWV0dUhrhE6w==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.9
key: AQDopB5bKCZPGBAAfYtp1GLA7QIi/YxJa8O1yw==
caps: [mon] allow profile osd
caps: [osd] allow *
client.admin
key: AQDpmx5bAAAAABAA3hLK8O2tGgaAK+X2Lly5Aw==
caps: [mds] allow *
caps: [mon] allow *
caps: [osd] allow *
client.bootstrap-mds
key: AQBDpB5bjR1GJhAAB6CKKxXulve9WIiC6ZGXgA==
caps: [mon] allow profile bootstrap-mds
client.bootstrap-osd
key: AQDpmx5bAAAAABAA3hLK8O2tGgaAK+X2Lly5Aw==
caps: [mon] allow profile bootstrap-osd
client.bootstrap-rgw
key: AQBDpB5b7OWXHBAAlATmBAOX/QWW+2mLxPqlkQ==
caps: [mon] allow profile bootstrap-rgw
client.openstack
key: AQDpmx5bAAAAABAAULxfs9cYG1wkSVTjrtiaDg==
caps: [mon] allow r
caps: [osd] allow class-read object_prefix rbd_children, allow rwx pool=volumes, allow rwx pool=backups, allow rwx pool=vms, allow rwx pool=images, allow rwx pool=metrics
7.從群集中刪除OSD。
[root@pod1-osd-compute-3 heat-admin]# ceph osd rm 7
removed osd.7
8.解除安裝需要更換的OSD磁碟。
[root@pod1-osd-compute-3 heat-admin]# umount /var/lib/ceph/osd/ceph-7
9.取消設定noscrub和deepscrub。
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset noscrub
unset noscrub
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset nodeep-scrub
unset nodeep-scrub
10.驗證Ceph運行狀況,並等待health-ok和所有PG恢復活動+clean。
[root@pod1-osd-compute-3 heat-admin]# ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
28 pgs backfill_wait
4 pgs backfilling
5 pgs degraded
5 pgs recovery_wait
83 pgs stuck unclean
recovery 1697/516881 objects degraded (0.328%)
recovery 76428/516881 objects misplaced (14.786%)
noout,norebalance,sortbitwise,require_jewel_osds flag(s) set
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e877: 11 osds: 11 up, 11 in; 193 remapped pgs
flags noout,norebalance,sortbitwise,require_jewel_osds
pgmap v942974: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 10806 GB / 12277 GB avail
1697/516881 objects degraded (0.328%)
76428/516881 objects misplaced (14.786%)
511 active+clean
156 active+remapped
28 active+remapped+wait_backfill
5 active+recovery_wait+degraded+remapped
4 active+remapped+backfilling
client io 331 kB/s wr, 0 op/s rd, 56 op/s wr
更換OSD磁碟並建立新的VD
1.卸下故障驅動器並用新驅動器替換:Cisco UCS C240 M4伺服器安裝和服務指南。
2.驗證是否登入到OSD電腦的CIMC,並檢查更換OSD的插槽是否顯示良好運行狀況。
3.為新的HDD建立虛擬驅動器,它必須是沒有後設資料的新的HDD。
4.驗證新增的磁碟是否處於「未配置完好」狀態。
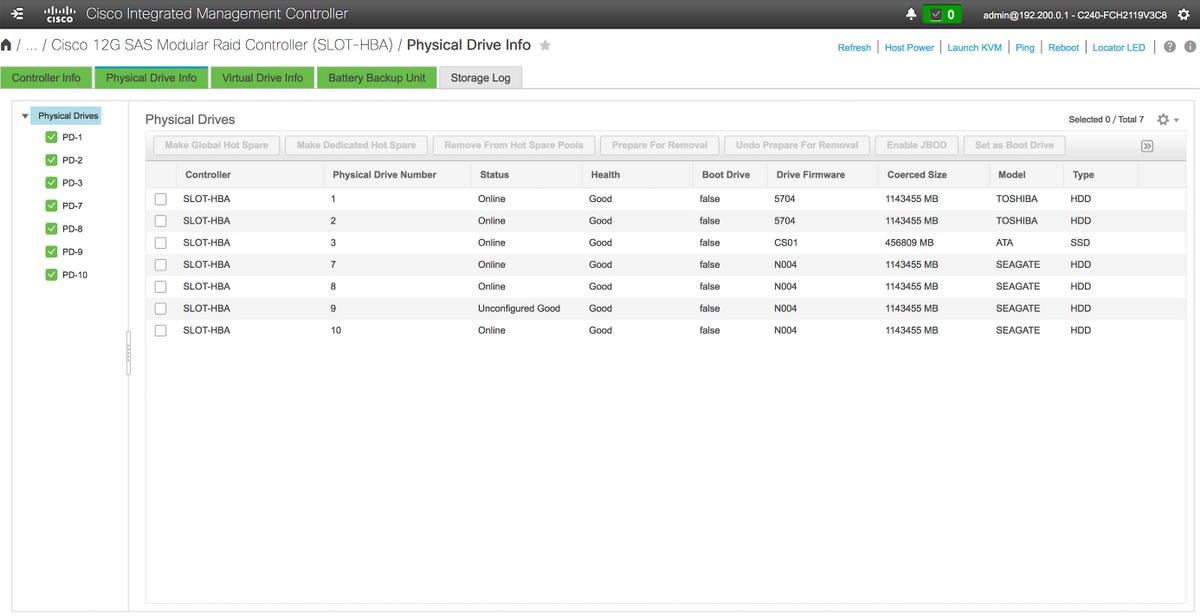 儲存> Cisco 12G SAS模組化Raid控制器(SLOT-HBA)>物理驅動器資訊
儲存> Cisco 12G SAS模組化Raid控制器(SLOT-HBA)>物理驅動器資訊
5.選擇Create Virtual Drive from Unused Physical Drives選項以建立VD。
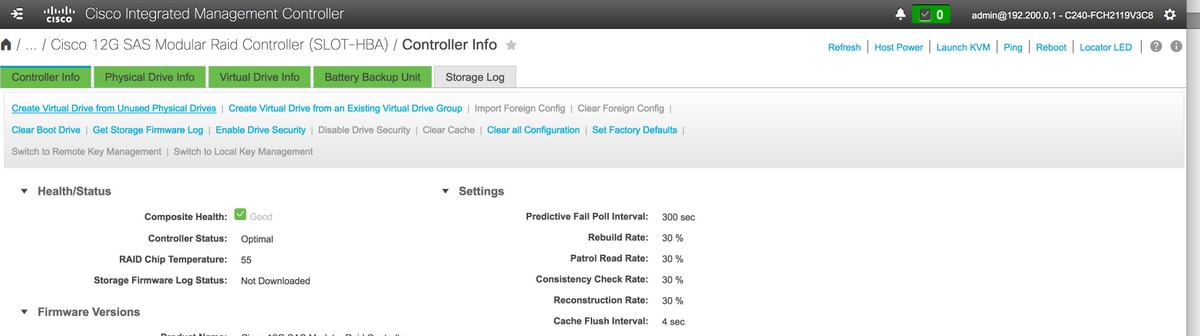 儲存> Cisco 12G SAS模組化Raid控制器(SLOT-HBA)
儲存> Cisco 12G SAS模組化Raid控制器(SLOT-HBA)
6.使用物理驅動器9建立新的VD並將其命名為OSD3。
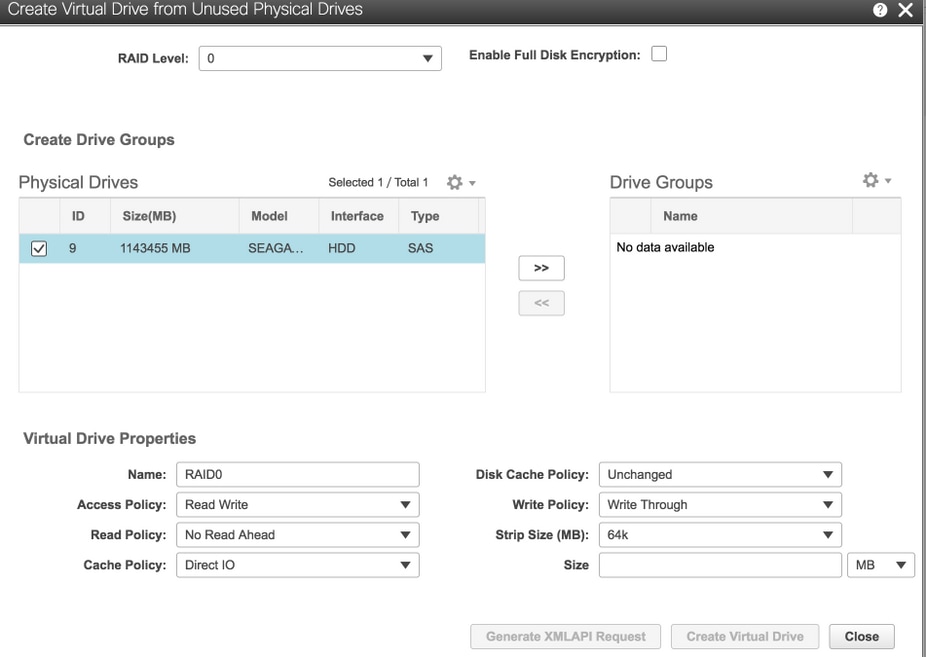 儲存> Cisco 12G SAS模組化Raid控制器(SLOT-HBA)>控制器資訊>從未使用的物理驅動器建立虛擬驅動器
儲存> Cisco 12G SAS模組化Raid控制器(SLOT-HBA)>控制器資訊>從未使用的物理驅動器建立虛擬驅動器
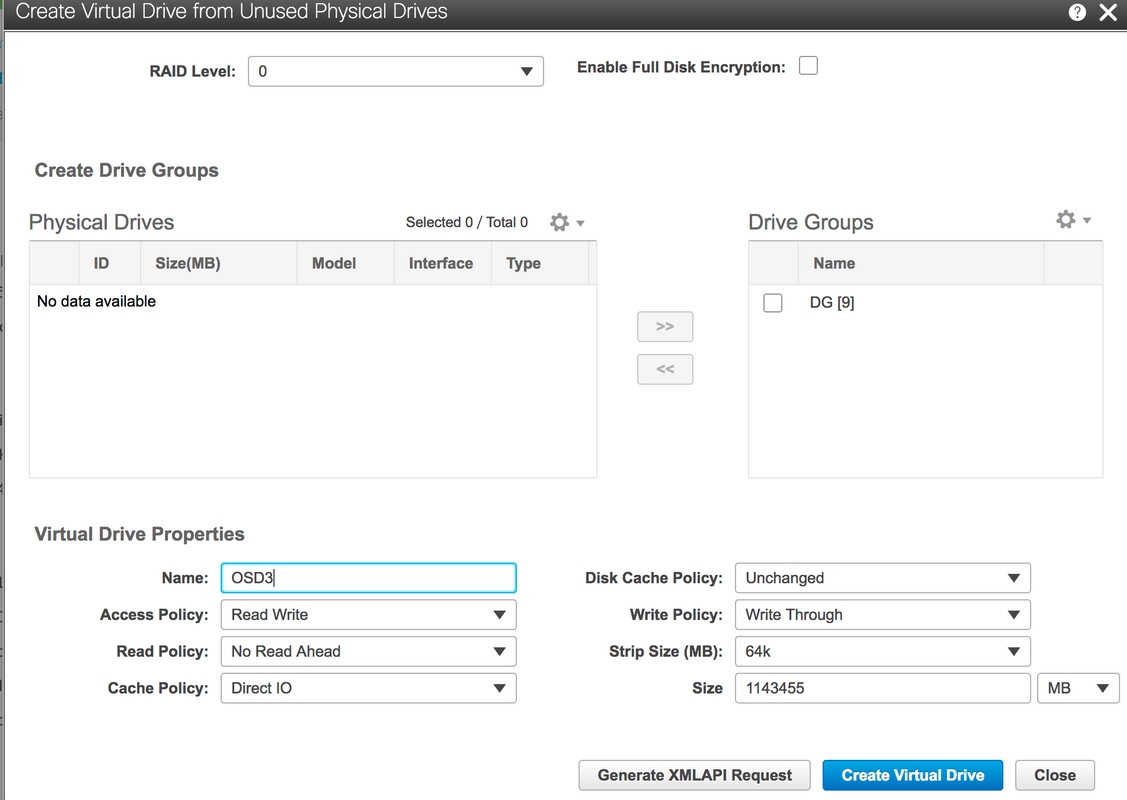 儲存> Cisco 12G SAS模組化Raid控制器(SLOT-HBA)>控制器資訊>從未使用的物理驅動器建立虛擬驅動器
儲存> Cisco 12G SAS模組化Raid控制器(SLOT-HBA)>控制器資訊>從未使用的物理驅動器建立虛擬驅動器
7.啟用IPMI over LAN: Admin > Communication Services > Communication Services。
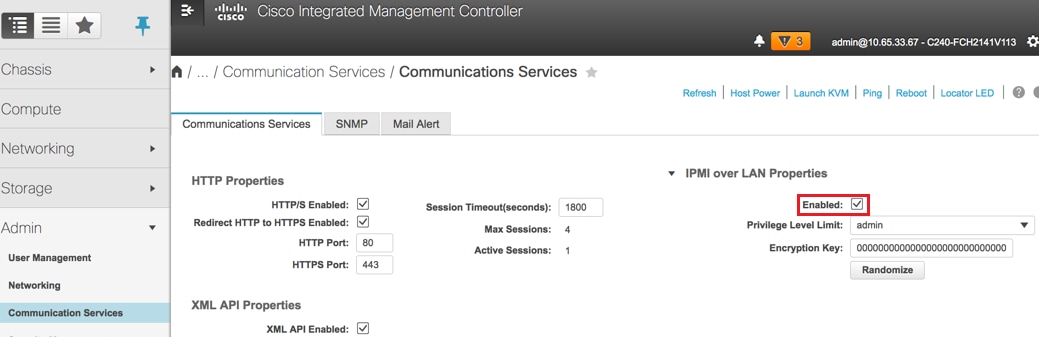 啟用IPMI over LAN:管理>通訊服務>通訊服務
啟用IPMI over LAN:管理>通訊服務>通訊服務
8.禁用超執行緒:計算> BIOS >配置BIOS >高級>處理器配置。
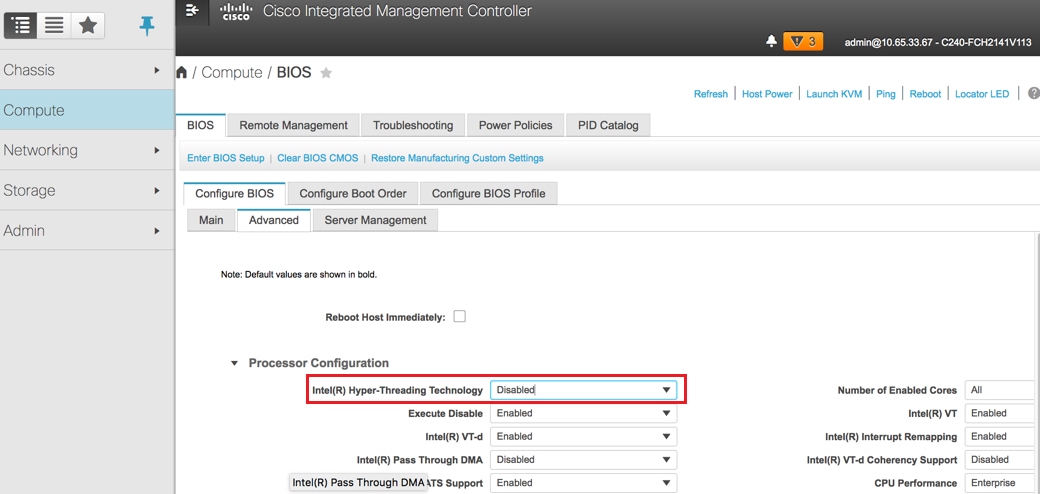 禁用超執行緒:計算> BIOS >配置BIOS >高級>處理器配置
禁用超執行緒:計算> BIOS >配置BIOS >高級>處理器配置
附註:此處顯示的影象和本節中提到的配置步驟是參考韌體版本3.0(3e),如果您使用其他版本,可能會有細微的差異。
將OSD重新新增到群集中
1.替換新磁碟後,執行partprobe以發現新裝置。
[root@pod1-osd-compute-3 heat-admin]# partprobe
[root@pod1-osd-compute-3 heat-admin]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 278.5G 0 disk
|
-sda1 8:1 0 1M 0 part
-sda2 8:2 0 278.5G 0 part /
sdb 8:16 0 446.1G 0 disk
|
-sdb1 8:17 0 107G 0 part
-sdb2 8:18 0 107G 0 part
-sdb3 8:19 0 107G 0 part
-sdb4 8:20 0 107G 0 part
sdc 8:32 0 1.1T 0 disk
|
-sdc1 8:33 0 1.1T 0 part /var/lib/ceph/osd/ceph-1
sdd 8:48 0 1.1T 0 disk
|
-sdd1 8:49 0 1.1T 0 part
sde 8:64 0 1.1T 0 disk
|
-sde1 8:65 0 1.1T 0 part /var/lib/ceph/osd/ceph-4
sdf 8:80 0 1.1T 0 disk
|
-sdf1 8:81 0 1.1T 0 part /var/lib/ceph/osd/ceph-10
2.查詢伺服器上可用的裝置。
[root@pod1-osd-compute-3 heat-admin]# fdisk -l
Disk /dev/sda: 299.0 GB, 298999349248 bytes, 583983104 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x000b5e87
Device Boot Start End Blocks Id System
/dev/sda1 2048 4095 1024 83 Linux
/dev/sda2 * 4096 583983070 291989487+ 83 Linux
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdb: 479.0 GB, 478998953984 bytes, 935544832 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 224462847 107G unknown ceph journal
2 224462848 448923647 107G unknown ceph journal
3 448923648 673384447 107G unknown ceph journal
4 673384448 897845247 107G unknown ceph journal
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdd: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdc: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sde: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdf: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
[root@pod1-osd-compute-3 heat-admin]#
3.使用Ceph-disk list標識日誌磁碟分割槽對映。
[root@pod1-osd-compute-3 heat-admin]# ceph-disk list
/dev/sda :
/dev/sda1 other, iso9660
/dev/sda2 other, xfs, mounted on /
/dev/sdb :
/dev/sdb1 ceph journal, for /dev/sdc1
/dev/sdb3 ceph journal
/dev/sdb2 ceph journal, for /dev/sde1
/dev/sdb4 ceph journal, for /dev/sdf1
/dev/sdc :
/dev/sdc1 ceph data, active, cluster ceph, osd.1, journal /dev/sdb1
/dev/sdd :
/dev/sdd1 other, xfs
/dev/sde :
/dev/sde1 ceph data, active, cluster ceph, osd.4, journal /dev/sdb2
/dev/sdf :
/dev/sdf1 ceph data, active, cluster ceph, osd.10, journal /dev/sdb4
附註:在ceph-disk list中,突出顯示的輸出sde1是sdb2的日誌分割槽。檢查Ceph-disk list的輸出並在命令中對映日誌磁碟分割槽,以準備Ceph。只要在下面運行命令OSD.7出現/進入且資料重新平衡(回填/恢復)就會啟動。
4.建立Ceph磁碟並將其新增回群集。
[root@pod1-osd-compute-3 heat-admin]# ceph-disk --setuser ceph --setgroup ceph prepare --fs-type xfs /dev/sdd /dev/sdb3
prepare_device: OSD will not be hot-swappable if journal is not the same device as the osd data
Creating new GPT entries.
The operation has completed successfully.
meta-data=/dev/sdd1 isize=2048 agcount=4, agsize=73181055 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=292724219, imaxpct=5
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=142931, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
Warning: The kernel is still using the old partition table.
The new table will be used at the next reboot.
The operation has completed successfully.
#####Hint###
where - sdd is new drive added as OSD
where – sdb3 is journal disk partition number
mapping is sdc1 for sdc, sdd1 for sdd, sde1 for sde
sdf1 for sdf (and so on)
5.啟用Ceph-disks並取消設定noscrub和nodeep-scrub標志。
[root@pod1-osd-compute-3 heat-admin]# ceph-disk activate-all
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset noout
unset noout
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset norebalance
unset norebalance
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset noscrub
unset noscrub
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset nodeep-scrub
unset nodeep-scrub
6.等待重新平衡完成,並驗證Ceph和OSD樹的運行狀況良好。
[root@pod1-osd-compute-3 heat-admin]# watch -n 3 ceph -s
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e709: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v941813: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 11922 GB / 13393 GB avail
704 active+clean
client io 58580 B/s wr, 0 op/s rd, 7 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
由思科工程師貢獻
- Partheeban RajagopalCisco Advanced Services
- Padmaraj RamanoudjamCisco Advanced Services
 意見
意見