簡介
本文說明如何使用資料匹配排除來減少資料丟失防護(DLP)資料分類中的誤報。
概觀
通過資料匹配排除,您可以排除特定的匹配資料,這有助於微調DLP資料分類並顯著減少誤報。此功能可讓您從DLP掃描中排除已知的非敏感資料或不相關的匹配項,從而提供更精確的資料保護。
資料匹配排除如何最小化誤報
當關鍵字或模式匹配非敏感資料時,內建識別符號和自定義識別符號可能會生成誤報。舉例來說:
- 基於編號的識別符號:
美國社會保險號(SSN)等識別符號可能與其他9位數字相匹配,例如內部帳戶ID。排除已知帳戶ID可降低這些誤報。
- 基於文本的識別符號:
使用符合HIPAA的資料分類的醫療保健客戶可以在非患者情景(如「癌症捐獻組織」)中檢測術語「癌症」。 您可以排除特定術語來防止此類虛假警報。
使用「資料匹配排除」,您可以指定術語或正規表示式模式,確保這些模式上的匹配不會觸發資料違規事件。這樣可以精確控制DLP警報。
如何使用資料匹配排除項
-
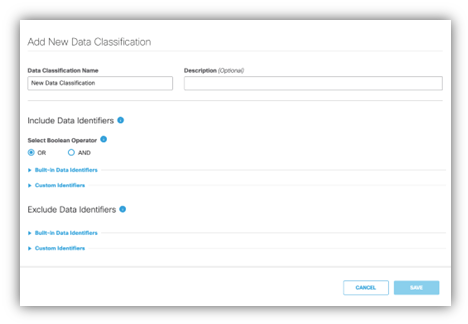
在Umbrella控制面板中,轉到Data Classificationpage頁面。
-
在排除資料標識符部分,選擇要排除的自定義識別符號或內建識別符號。
-
輸入要排除的特定術語或正規表示式模式。
- 排除項僅適用於特定的匹配內容,而不適用於整個文檔。
- 例如,如果排除「癌症捐獻組織」,則只有該術語不包括在違規範圍內,而文檔的其餘部分仍被掃描。
-
如果同一資料識別符號被包括在同一分類中並被排除,則該排除將具有優先權。
相關資源
請參閱Umbrella文檔以獲得逐步指導:建立資料分類。
 意見
意見