有用的HyperFlex一般知识
下载选项
非歧视性语言
此产品的文档集力求使用非歧视性语言。在本文档集中,非歧视性语言是指不隐含针对年龄、残障、性别、种族身份、族群身份、性取向、社会经济地位和交叉性的歧视的语言。由于产品软件的用户界面中使用的硬编码语言、基于 RFP 文档使用的语言或引用的第三方产品使用的语言,文档中可能无法确保完全使用非歧视性语言。 深入了解思科如何使用包容性语言。
关于此翻译
思科采用人工翻译与机器翻译相结合的方式将此文档翻译成不同语言,希望全球的用户都能通过各自的语言得到支持性的内容。 请注意:即使是最好的机器翻译,其准确度也不及专业翻译人员的水平。 Cisco Systems, Inc. 对于翻译的准确性不承担任何责任,并建议您总是参考英文原始文档(已提供链接)。
目录
简介
本文档介绍管理员应掌握的有关Cisco HyperFlex(HX)的一般知识。
常用首字母缩略词
SCVM =存储控制器虚拟机
VMNIC =虚拟机网络接口卡(V)
VNIC =虚拟网络接口卡卡
SED =自我加密驱动器
VM =虚拟机
HX = HyperFlex
HyperFlex VMware VMNIC订购
VMNIC位置已在HX版本3.5及更高版本中修改。
3.5之前版本订购
在版本3.5之前,VNIC是根据VNIC编号分配的。
| VNIC | 虚拟交换机(vSwitch) |
| VNIC 0和VNIC 1 | vSwitch-hx-inband-mgmt |
| VNIC 2和VNIC 3 | vSwitch-hx-storage-data |
| VNIC 4和VNIC 5 | vSwitch-hx-vm-network |
| VNIC 6和VNIC 7 | vMotion |
3.5后订购
在版本3.5及更高版本中,VNIC根据介质访问控制(MAC)地址分配。因此,没有特定的分配顺序。
如果执行从3.5以上版本到3.5或更高版本的升级,则维护VMNIC订购。
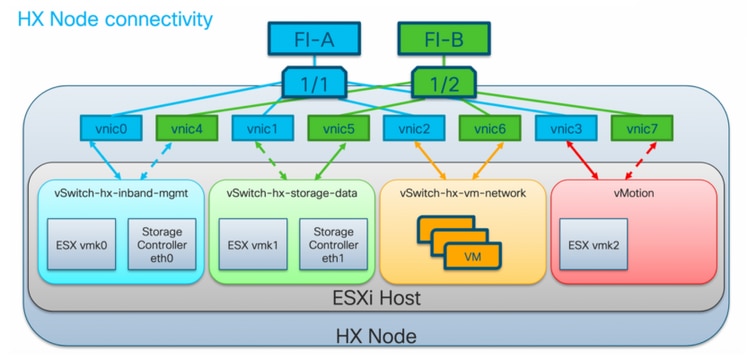
注意:对于HX Hyper-V,这将不适用,因为Hyper-V使用一致的设备命名(CDN)。
融合节点与计算节点上的SCVM
SCVM位于融合节点和计算节点上,两者之间有差异。
融合节点
CPU资源预留
由于SCVM提供Cisco HX分布式数据平台的关键功能,因此HyperFlex安装程序将为控制器VM配置CPU资源预留。此保留确保控制器VM在访客VM占用ESXi虚拟机监控程序主机的物理CPU资源严重的情况下具有最低级别的中央处理单元(CPU)资源。这是软保证,这意味着在大多数情况下,SCVM不使用保留的所有CPU资源,因此允许访客VM使用它们。下表详细列出存储控制器VM的CPU资源预留:
| vCPU数量 | 股份 | 预订 | 限制 |
| 8 | 低 | 10800 MHZ | 无限 |
内存资源预留
由于SCVM提供Cisco HX分布式数据平台的关键功能,因此HyperFlex安装程序将为控制器VM配置内存资源预留。此保留可确保控制器虚拟机在ESXi虚拟机监控程序主机的物理内存资源被访客虚拟机大量消耗的情况下具有最低级别的内存资源。下表详细列出存储控制器VM的内存资源预留:
| 服务器型号 | 访客内存量 | 保留所有访客内存 |
| HX 220c-M5SX HXAF 220c-M5SX HX 220c-M4S HXAF220c-M4S |
48 GB | Yes |
| HX 240c-M5SX HXAF 240c-M5SX HX240c-M4SX HXAF240c-M4SX |
72 GB | Yes |
| HX240c-M5L | 78 GB | Yes |
计算节点
仅计算节点具有轻量SCVM。它仅配置1个1024MHz和512 MB内存预留的vCPU。
拥有计算节点的目的主要是维护vCluster分布式资源调度程序™(DRS)设置,以确保DRS不会将用户虚拟机移回融合节点。
不正常的群集方案
HX集群在以下情况下可能不正常。
情形 1:节点关闭
当节点关闭时,集群将进入不正常状态。在集群升级期间或服务器进入维护模式时,节点应关闭。
root@SpringpathController:~# stcli cluster storage-summary --detail
<snip>
current ensemble size:3
# of caching failures before cluster shuts down:2
minimum cache copies remaining:2
minimum data copies available for some user data:2
current healing status:rebuilding/healing is needed, but not in progress yet. warning: insufficient node or space resources may prevent healing. storage node 10.197.252.99is either down or initializing disks.
minimum metadata copies available for cluster metadata:2
# of unavailable nodes:1
# of nodes failure tolerable for cluster to be available:0
health state reason:storage cluster is unhealthy. storage node 10.197.252.99 is unavailable.
# of node failures before cluster shuts down:2
# of node failures before cluster goes into readonly:2
# of persistent devices failures tolerable for cluster to be available:1
# of node failures before cluster goes to enospace warn trying to move the existing data:na
# of persistent devices failures before cluster shuts down:2
# of persistent devices failures before cluster goes into readonly:2
# of caching failures before cluster goes into readonly:na
# of caching devices failures tolerable for cluster to be available:1
resiliencyInfo:
messages:
----------------------------------------
Storage cluster is unhealthy.
----------------------------------------
Storage node 10.197.252.99 is unavailable.
----------------------------------------
state: 2
nodeFailuresTolerable: 0
cachingDeviceFailuresTolerable: 1
persistentDeviceFailuresTolerable: 1
zoneResInfoList: None
spaceStatus: normal
totalCapacity: 3.0T
totalSavings: 5.17%
usedCapacity: 45.9G
zkHealth: online
clusterAccessPolicy: lenient
dataReplicationCompliance: non_compliant
dataReplicationFactor: 3
方案 2:磁盘关闭
当磁盘不可用时,群集将进入不正常状态。当数据分发到其他磁盘时,该条件应该清除。
root@SpringpathController:~# stcli cluster storage-summary --detail
<snip>
current ensemble size:3
# of caching failures before cluster shuts down:2
minimum cache copies remaining:2
minimum data copies available for some user data:2
current healing status:rebuilding/healing is needed, but not in progress yet. warning: insufficient node or space resources may prevent healing. storage node is either down or initializing disks.
minimum metadata copies available for cluster metadata:2
# of unavailable nodes:1
# of nodes failure tolerable for cluster to be available:0
health state reason:storage cluster is unhealthy. persistent device disk [5000c5007e113d8b:0000000000000000] on node 10.197.252.99 is unavailable.
# of node failures before cluster shuts down:2
# of node failures before cluster goes into readonly:2
# of persistent devices failures tolerable for cluster to be available:1
# of node failures before cluster goes to enospace warn trying to move the existing data:na
# of persistent devices failures before cluster shuts down:2
# of persistent devices failures before cluster goes into readonly:2
# of caching failures before cluster goes into readonly:na
# of caching devices failures tolerable for cluster to be available:1
resiliencyInfo:
messages:
----------------------------------------
Storage cluster is unhealthy.
----------------------------------------
Persistent Device Disk [5000c5007e113d8b:0000000000000000] on node 10.197.252.99 is unavailable.
----------------------------------------
state: 2
nodeFailuresTolerable: 0
cachingDeviceFailuresTolerable: 1
persistentDeviceFailuresTolerable: 1
zoneResInfoList: None
spaceStatus: normal
totalCapacity: 3.0T
totalSavings: 8.82%
usedCapacity: 45.9G
zkHealth: online
clusterAccessPolicy: lenient
dataReplicationCompliance: non_compliant
dataReplicationFactor: 3
情形 3:节点和磁盘均未关闭
当节点和磁盘都未关闭时,群集可能进入不正常状态。如果正在重建,则会发生此情况。
root@SpringpathController:~# stcli cluster storage-summary --detail
<snip>
resiliencyDetails:
current ensemble size:5
# of caching failures before cluster shuts down:3
minimum cache copies remaining:3
minimum data copies available for some user data:2
current healing status:rebuilding is in progress, 98% completed. minimum metadata copies available for cluster metadata:2
time remaining before current healing operation finishes:7 hr(s), 15 min(s), and 34 sec(s)
# of unavailable nodes:0
# of nodes failure tolerable for cluster to be available:1
health state reason:storage cluster is unhealthy.
# of node failures before cluster shuts down:2
# of node failures before cluster goes into readonly:2
# of persistent devices failures tolerable for cluster to be available:1
# of node failures before cluster goes to enospace warn trying to move the existing data:na
# of persistent devices failures before cluster shuts down:2
# of persistent devices failures before cluster goes into readonly:2
# of caching failures before cluster goes into readonly:na
# of caching devices failures tolerable for cluster to be available:2
resiliencyInfo:
messages:
Storage cluster is unhealthy.
state: 2
nodeFailuresTolerable: 1
cachingDeviceFailuresTolerable: 2
persistentDeviceFailuresTolerable: 1
zoneResInfoList: None
spaceStatus: normal
totalCapacity: 225.0T
totalSavings: 42.93%
usedCapacity: 67.7T
clusterAccessPolicy: lenient
dataReplicationCompliance: non_compliant
dataReplicationFactor: 3
如何使用命令行界面(CLI)检查SED集群
如果无法访问HX连接,则CLI可用于检查集群是否为SED。
# Check if the cluster is SED capable
root@SpringpathController:~# cat /etc/springpath/sed_capability.conf sed_capable_cluster=False
# Check if the cluster is SED enabled root@SpringpathController:~# cat /etc/springpath/sed.conf sed_encryption_state=unknown
root@SpringpathController:~# /usr/share/springpath/storfs-appliance/sed-client.sh -l WWN,Slot,Supported,Enabled,Locked,Vendor,Model,Serial,Size 5002538c40a42d38,1,0,0,0,Samsung,SAMSUNG_MZ7LM240HMHQ-00003,S3LKNX0K406548,228936 5000c50030278d83,25,1,1,0,MICRON,S650DC-800FIPS,ZAZ15QDM0000822150Z3,763097 500a07511d38cd36,2,1,1,0,MICRON,Micron_5100_MTFDDAK960TCB_SED,17261D38CD36,915715 500a07511d38efbe,4,1,1,0,MICRON,Micron_5100_MTFDDAK960TCB_SED,17261D38EFBE,915715 500a07511d38f350,7,1,1,0,MICRON,Micron_5100_MTFDDAK960TCB_SED,17261D38F350,915715 500a07511d38eaa6,3,1,1,0,MICRON,Micron_5100_MTFDDAK960TCB_SED,17261D38EAA6,915715 500a07511d38ce80,6,1,1,0,MICRON,Micron_5100_MTFDDAK960TCB_SED,17261D38CE80,915715 500a07511d38e4fc,5,1,1,0,MICRON,Micron_5100_MTFDDAK960TCB_SED,17261D38E4FC,915715
HX维护模式与ESXi维护模式
当需要在属于HX集群的服务器上执行维护活动时,应使用HX维护模式,而不是ESXi维护模式。使用HX维护模式时,SCVM正常关闭,而使用ESXi维护模式时,SCVM突然关闭。
当节点处于维护模式时,将视其为关闭,即1个节点故障。
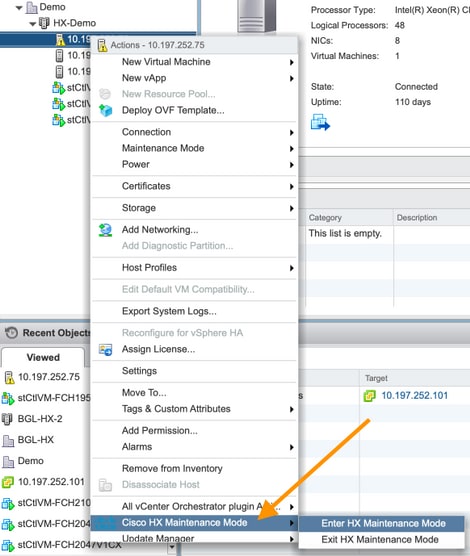
在将另一个节点移至维护模式之前,请确保集群显示正常。
root@SpringpathController:~# stcli cluster storage-summary --detail
<snip>
current ensemble size:3
# of caching failures before cluster shuts down:3
minimum cache copies remaining:3
minimum data copies available for some user data:3
minimum metadata copies available for cluster metadata:3
# of unavailable nodes:0
# of nodes failure tolerable for cluster to be available:1
health state reason:storage cluster is healthy.
# of node failures before cluster shuts down:3
# of node failures before cluster goes into readonly:3
# of persistent devices failures tolerable for cluster to be available:2
# of node failures before cluster goes to enospace warn trying to move the existing data:na
# of persistent devices failures before cluster shuts down:3
# of persistent devices failures before cluster goes into readonly:3
# of caching failures before cluster goes into readonly:na
# of caching devices failures tolerable for cluster to be available:2
resiliencyInfo:
messages:
Storage cluster is healthy.
state: 1
nodeFailuresTolerable: 1
cachingDeviceFailuresTolerable: 2
<snip>
常见问题
Cisco HyperFlex M4和M5服务器上的SCVM安装在哪里?
Cisco Hyperflex M4和M5服务器之间的SCVM位置不同。下表列出了SCVM的位置,并提供了其他有用信息。
| 思科HX服务器 | ESXi | SCVM sda |
缓存固态驱动器(SSD) | 管理SSD sdb1和sdb2 |
| HX 220 M4 | 安全数字(SD卡) | SD卡上3.5G | 插槽 2 | 插槽 1 |
| HX 240 M4 | SD卡 | 在PCH控制的SSD上(esxi控制此) | 插槽 1 | 在PCH控制的SSD上 |
| HX 220 M5 | M.2驱动器 | M.2驱动器 | 插槽 2 | 插槽 1 |
| HX 240 M5 | M.2驱动器 | M.2驱动器 | 后插槽SSD | 插槽 1 |
群集可以容忍多少个故障节点?
群集可以容忍的故障数取决于复制因子和访问策略。
具有5个或更多节点的群集
当复制因子(RF)为3且访问策略设置为Ensignate时,如果2个节点失败,集群将仍处于读/写状态。如果3个节点发生故障,则集群将关闭。
| 复制因子 | 访问策略 | 失败节点数 | ||
| 读/写 | 只读 | shutdown | ||
| 3 | 宽大 | 2 | — | 3 |
| 3 | 严格 | 1 | 2 | 3 |
| 2 | 宽大 | 1 | — | 2 |
| 2 | 严格 | — | 1 | 2 |
具有3和4节点的群集
当RF为3且访问策略设置为Esignate或Strict时,如果单个节点发生故障,集群仍处于读/写状态。如果2个节点发生故障,集群将关闭。
| 复制因子 | 访问策略 | 失败节点数 | ||
| 读/写 | 只读 | shutdown | ||
| 3 | 宽大或严格 | 1 | — | 2 |
| 2 | 宽大 | 1 | — | 2 |
| 2 | 严格 | — | 1 | 2 |
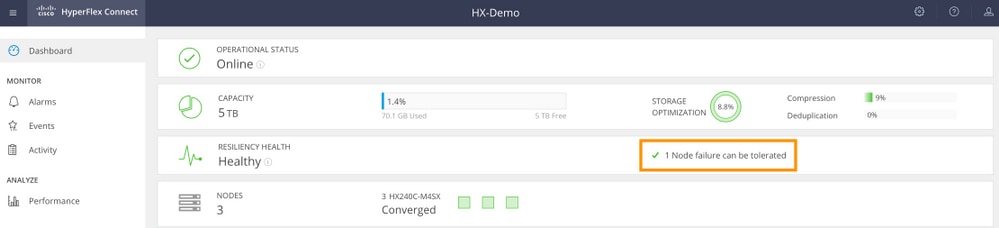
3节点集群(RF:3,访问策略:宽大)
图形用户界面(GUI)示例
CLI示例
root@SpringpathController:~# stcli cluster storage-summary --detail
<snip>
current ensemble size:3
# of caching failures before cluster shuts down:3
minimum cache copies remaining:3
minimum data copies available for some user data:3
minimum metadata copies available for cluster metadata:3
# of unavailable nodes:0
# of nodes failure tolerable for cluster to be available:1
health state reason:storage cluster is healthy.
# of node failures before cluster shuts down:3
# of node failures before cluster goes into readonly:3
# of persistent devices failures tolerable for cluster to be available:2
# of node failures before cluster goes to enospace warn trying to move the existing data:na
# of persistent devices failures before cluster shuts down:3
# of persistent devices failures before cluster goes into readonly:3
# of caching failures before cluster goes into readonly:na
# of caching devices failures tolerable for cluster to be available:2
resiliencyInfo:
messages:
Storage cluster is healthy.
state: 1
<snip>
clusterAccessPolicy: lenient
如果其中一个SCVM关闭,会发生什么情况?VM是否继续运行?
警告:这不是SCVM上支持的操作。这仅用于演示目的。
注意:确保一次只关闭一个SCVM。此外,在SCVM关闭之前,请确保集群运行正常。此场景仅用于证明即使SCVM关闭或不可用,VM和数据存储仍应正常运行。
VM将继续正常运行。以下是SCVM已关闭,但Datastore仍已挂载且可用的输出示例。
[root@node1:~] vim-cmd vmsvc/getallvms
Vmid Name File Guest OS Version Annotation
1 stCtlVM-F 9H [SpringpathDS-F 9H] stCtlVM-F 9H/stCtlVM-F 9H.vmx ubuntu64Guest vmx-13
[root@node1:~] vim-cmd vmsvc/power.off 1
Powering off VM:
[root@node1:~] vim-cmd vmsvc/power.getstate 1
Retrieved runtime info
Powered off
[root@node1:~] esxcfg-nas -l
Test is 10.197.252.106:Test from 3203172317343203629-5043383143428344954 mounted available
ReplSec is 10.197.252.106:ReplSec from 3203172317343203629-5043383143428344954 mounted available
New_DS is 10.197.252.106:New_DS from 3203172317343203629-5043383143428344954 mounted available
SCVM上的VMware硬件版本已更新。现在呢?
警告:这不是SCVM上支持的操作。这仅用于演示目的。
通过在Compatibility > Upgrade VM Compatibility中编辑VM设置来升级VMware硬件版本是vSphere Web客户端不是SCVM上支持的操作。SCVM将在HX Connect中报告为Offline。
root@SpringpathController0 UE:~# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 2.5G 0 disk `-sda1 8:1 0 2.5G 0 part / sdb 8:16 0 100G 0 disk |-sdb1 8:17 0 64G 0 part /var/stv `-sdb2 8:18 0 24G 0 part /var/zookeeper root@SpringpathController0 UE:~# lsscsi [2:0:0:0] disk VMware Virtual disk 2.0 /dev/sda [2:0:1:0] disk VMware Virtual disk 2.0 /dev/sdb root@SpringpathController0 UE:~# cat /var/log/springpath/diskslotmap-v2.txt 1.11.1:5002538a17221ab0:SAMSUNG:MZIES800HMHP/003:S1N2NY0J201389:EM19:SAS:SSD:763097:Inactive:/dev/sdc 1.11.2:5002538c405537e0:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 98:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sdd 1.11.3:5002538c4055383a:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 88:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sde 1.11.4:5002538c40553813:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 49:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sdf 1.11.5:5002538c4055380e:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 44:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sdg 1.11.6:5002538c40553818:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 54:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sdh 1.11.7:5002538c405537d1:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 83:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sdi 1.11.8:5002538c405537d8:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 90:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sdj 1.11.9:5002538c4055383b:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 89:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sdk 1.11.10:5002538c4055381f:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 61:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sdl 1.11.11:5002538c40553823:Samsung:SAMSUNG_MZ7LM3T8HMLP-00003:S 65:GXT51F3Q:SATA:SSD:3662830:Inactive:/dev/sdm
警告:如果意外执行了此操作,请致电思科支持部门,寻求进一步帮助。需要重新部署SCVM。
由思科工程师提供
- Mohammed Majid HussainCisco CX
- Himanshu SardanaCisco CX
- Avinash ShuklaCisco CX
 反馈
反馈