简介
本文档介绍如何解决粘滞在“主用 — 主用”状态的Viptela SD-WAN路由器虚拟路由器冗余协议(VRRP)。
先决条件
要求
Cisco 建议您了解以下主题:
使用的组件
本文档中的信息基于以下软件和硬件版本:
- vEdge 2000,版本19.2.3
- MS250-48FP,版本MS 12.28
本文档中的信息都是基于特定实验室环境中的设备编写的。本文档中使用的所有设备最初均采用原始(默认)配置。如果您的网络处于活动状态,请确保您了解所有命令的潜在影响。
拓扑
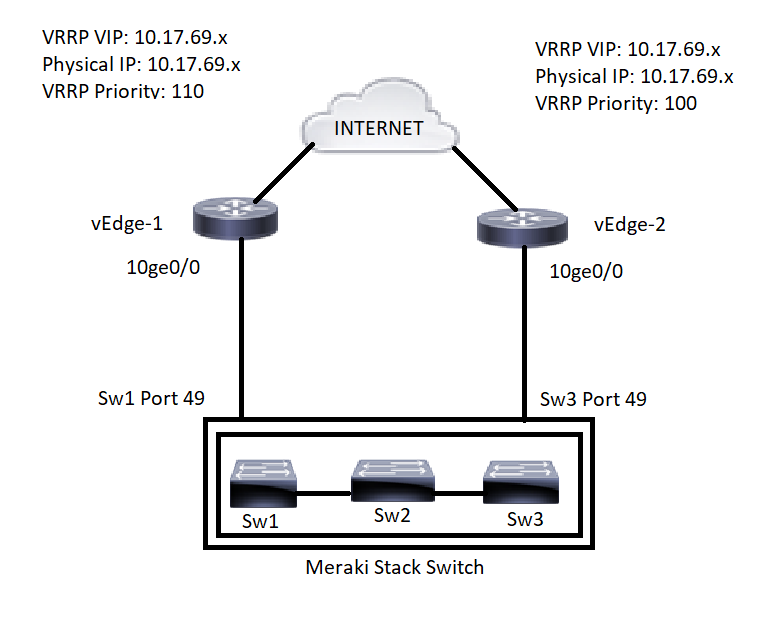
症状1. VRRP处于活动状态 — 活动状态
向下连接到Meraki堆栈交换机的两个上游网关vEdge设备都充当VRRP主。
VE1# show vrrp
MASTER PREFIX
GROUP VRRP OMP ADVERTISEMENT DOWN LIST
VPN IF NAME ID VIRTUAL IP VIRTUAL MAC PRIORITY STATE STATE TIMER TIMER LAST STATE CHANGE TIME TRACK PREFIX LIST STATE
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
11 10ge0/0.670 1 10.17.69.1 00:00:5e:00:01:01 110 master up 1 3 2021-10-12T02:16:49+00:00 Default_Route_Prefix_List resolved
VE2# show vrrp
MASTER PREFIX
GROUP VRRP OMP ADVERTISEMENT DOWN LIST
VPN IF NAME ID VIRTUAL IP VIRTUAL MAC PRIORITY STATE STATE TIMER TIMER LAST STATE CHANGE TIME TRACK PREFIX LIST STATE
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
11 10ge0/0.670 1 10.17.69.1 00:00:5e:00:01:01 100 master up 1 3 2021-10-12T02:16:40+00:00 Default_Route_Prefix_List resolved
症状2.交换机警告有错误的DNS
连接到VE2的交换机2在Meraki控制面板中收到“DNS配置错误”警报。
症状3. AP进入中继器模式
连接到交换机2的AP进入中继器模式,因为交换机不具有网关可达性。

故障排除
- 从vEdge检验VRRP行为。
从两个vEdge收集“tcpdump”并验证VRRP数据包状态。在本例中,我们注意到VRRP数据包由VE1接收和发送。但是没有收到从VE1到VE2的VRRP数据包。 但是,从VE1发送了相同的消息。因此,您可以确认网关vEdge功能没有问题。
从VE1:
10.17.69.3 > 224.0.0.18: vrrp 10.17.69.3 > 224.0.0.18: VRRPv2, Advertisement, vrid 1, prio 100, authtype none, intvl 1s, length 20, addrs: 10.17.69.1
08:57:12.744406 80:b7:09:32:e5:02 > 01:00:5e:00:00:12, ethertype IPv4 (0x0800), length 54: (tos 0xc0, ttl 255, id 6968, offset 0, flags [DF], proto VRRP (112), length 40)
10.17.69.2 > 224.0.0.18: vrrp 10.17.69.2 > 224.0.0.18: VRRPv2, Advertisement, vrid 1, prio 110, authtype none, intvl 1s, length 20, addrs: 10.17.69.1
08:57:13.708034 00:00:5e:00:01:01 > 01:00:5e:00:00:12, ethertype IPv4 (0x0800), length 56: (tos 0xc0, ttl 255, id 29924, offset 0, flags [DF], proto VRRP (112), length 40)
从VE2:
10.17.69.3 > 224.0.0.18: vrrp 10.17.69.3 > 224.0.0.18: VRRPv2, Advertisement, vrid 1, prio 100, authtype none, intvl 1s, length 20, addrs: 10.17.69.1
08:57:50.644532 80:b7:09:31:82:a2 > 01:00:5e:00:00:12, ethertype IPv4 (0x0800), length 54: (tos 0xc0, ttl 255, id 31817, offset 0, flags [DF], proto VRRP (112), length 40)
没有来自VE1(10.17.69.2)的VRRP数据包,因此VE2假定VE1已关闭并充当VRRP主。
- 验证Meraki堆栈行为。
Meraki控制面板指示AP4和AP3处于中继器模式,该中继器连接到上行链路交换机2,该交换机收到恶意DNS警报。
要确认堆栈状态,请打开Meraki TAC,因为堆栈通信消息仅对Meraki TAC可见。在验证时,发现堆叠中的主交换机和辅助交换机之间的堆叠内通信问题。
Meraki还确认此问题是由堆叠成员交换机1(主)通过堆叠成员2从VE1到VE2的VRRP数据包引起的。这是12.28代码中的一个已知问题。
解决方案
- 重新加载堆叠中的所有成员交换机(临时修复)。
- 将Meraki交换机固件升级到最新的稳定版本。
 反馈
反馈