StarOS VNF的Ceph中断影响分析
下载选项
非歧视性语言
此产品的文档集力求使用非歧视性语言。在本文档集中,非歧视性语言是指不隐含针对年龄、残障、性别、种族身份、族群身份、性取向、社会经济地位和交叉性的歧视的语言。由于产品软件的用户界面中使用的硬编码语言、基于 RFP 文档使用的语言或引用的第三方产品使用的语言,文档中可能无法确保完全使用非歧视性语言。 深入了解思科如何使用包容性语言。
关于此翻译
思科采用人工翻译与机器翻译相结合的方式将此文档翻译成不同语言,希望全球的用户都能通过各自的语言得到支持性的内容。 请注意:即使是最好的机器翻译,其准确度也不及专业翻译人员的水平。 Cisco Systems, Inc. 对于翻译的准确性不承担任何责任,并建议您总是参考英文原始文档(已提供链接)。
目录
简介
本文档介绍在思科虚拟化基础设施管理器(VIM)上运行的StarOS VNF在Ceph存储服务受损时受到的影响,以及可以采取哪些措施来减轻影响。其解释假设思科VIM用作基础设施,但相同的理论可应用于任何Openstack环境。
先决条件
要求
Cisco 建议您了解以下主题:
- 思科StarOS
- 思科VIM
- OpenStack
- 西普
使用的组件
本文档中的信息基于以下软件和硬件版本:
- StarOS:21.16.c9
- 思科VIM:3.2.2(Openstack Queens)
本文档中的信息都是基于特定实验室环境中的设备编写的。本文档中使用的所有设备最初均采用原始(默认)配置。如果您的网络处于活动状态,请确保您了解所有命令的潜在影响。
缩写
| 思科VIM | 思科虚拟化基础设施管理器 |
| VNF | 虚拟网络功能 |
| 倒置OSD | Ceph对象存储守护程序 |
| StarOS | 思科移动分组核心解决方案的操作系统 |
思科VIM中的Ceph
此图片摘自《思科VIM管理员指南》。思科VIM使用Ceph作为存储后端。
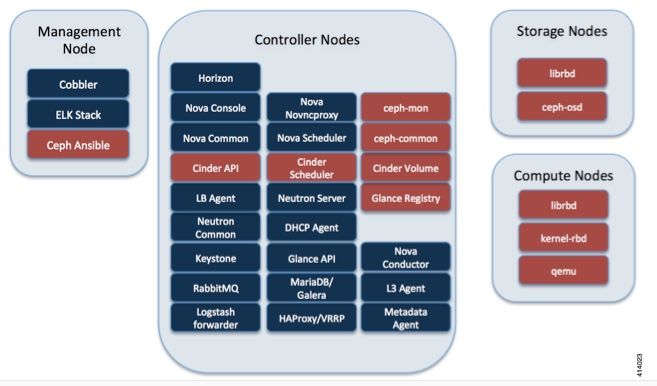
Ceph支持块和对象存储,因此用于存储可连接到VM的VM映像和卷。依赖存储后端的多个OpenStack服务包括:
- 概览(OpenStack映像服务) — 使用Ceph存储映像。
- Cinder(OpenStack存储服务) — 使用Ceph创建可连接到虚拟机的卷。
- Nova(OpenStack计算服务) — 使用Ceph连接到Cinder创建的卷。
在许多情况下,在Ceph中为StarOS VNF创建/flash和/hd-raid卷,如下例所示。
openstack volume create --image `glance image-list | grep up-image | awk '{print $2}'` --size 16 --type LUKS up1-flash-boot
openstack volume create --size 20 --type LUKS up1-hd-raid
Ceph监控机制的基础
以下是Ceph文档中有关监控的说明:
每个Ceph OSD守护程序以小于每6秒的随机间隔检查其他Ceph OSD守护程序的心跳。如果相邻Ceph OSD守护程序在20秒宽限期内未显示心跳,则Ceph OSD守护程序可能会考虑关闭相邻Ceph OSD守护程序,并将其报告回Ceph监控器,后者会更新Ceph集群映射。默认情况下,来自不同主机的两个Ceph OSD守护程序必须向Ceph监控器报告另一个Ceph OSD守护程序关闭,然后Ceph监控器才确认报告的Ceph OSD守护程序关闭。
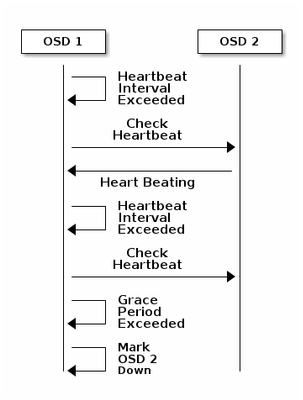
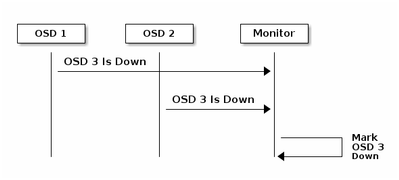
因此,通常需要大约20秒来检测OSD关闭,并且Ceph集群映射更新,只有在此VNF可以使用新OSD之后。在此期间,磁盘会被阻止I/O。
阻塞I/O对StarOS VNF的影响
如果磁盘I/O被阻止超过120秒,StarOS VNF将重新启动。对于与磁盘I/O和StarOS相关的xfssyncd/md0和xfs_db进程,当它检测到这些进程上出现卡滞超过120秒时,会特意重新启动。
StarOS调试控制台日志:
[ 1080.859817] INFO: task xfssyncd/md0:25787 blocked for more than 120 seconds.
[ 1080.862844] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
[ 1080.866184] xfssyncd/md0 D ffff880c036a8290 0 25787 2 0x00000000
[ 1080.869321] ffff880aacf87d30 0000000000000046 0000000100000a9a ffff880a00000000
[ 1080.872665] ffff880aacf87fd8 ffff880c036a8000 ffff880aacf87fd8 ffff880aacf87fd8
[ 1080.876100] ffff880c036a8298 ffff880aacf87fd8 ffff880c0f2f3980 ffff880c036a8000
[ 1080.879443] Call Trace:
[ 1080.880526] [<ffffffff8123d62e>] ? xfs_trans_commit_iclog+0x28e/0x380
[ 1080.883288] [<ffffffff810297c9>] ? default_spin_lock_flags+0x9/0x10
[ 1080.886050] [<ffffffff8157fd7d>] ? _raw_spin_lock_irqsave+0x4d/0x60
[ 1080.888748] [<ffffffff812301b3>] _xfs_log_force_lsn+0x173/0x2f0
[ 1080.891375] [<ffffffff8104bae0>] ? default_wake_function+0x0/0x20
[ 1080.894010] [<ffffffff8123dc15>] _xfs_trans_commit+0x2a5/0x2b0
[ 1080.896588] [<ffffffff8121ff64>] xfs_fs_log_dummy+0x64/0x90
[ 1080.899079] [<ffffffff81253cf1>] xfs_sync_worker+0x81/0x90
[ 1080.901446] [<ffffffff81252871>] xfssyncd+0x141/0x1e0
[ 1080.903670] [<ffffffff81252730>] ? xfssyncd+0x0/0x1e0
[ 1080.905871] [<ffffffff81071d5c>] kthread+0x8c/0xa0
[ 1080.908815] [<ffffffff81003364>] kernel_thread_helper+0x4/0x10
[ 1080.911343] [<ffffffff81580805>] ? restore_args+0x0/0x30
[ 1080.913668] [<ffffffff81071cd0>] ? kthread+0x0/0xa0
[ 1080.915808] [<ffffffff81003360>] ? kernel_thread_helper+0x0/0x10
[ 1080.918411] **** xfssyncd/md0 stuck, resetting card
但是,它不限于120秒计时器,如果磁盘I/O被阻塞一段时间,甚至不到120秒,VNF可能会因各种原因重新启动。此处的输出是一个示例,显示由于磁盘I/O问题、有时连续的StarOS任务崩溃等原因导致的重新启动。它取决于活动磁盘I/O与存储问题的时间安排。
[ 2153.370758] Hangcheck: hangcheck value past margin!
[ 2153.396850] ata1.01: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6 frozen
[ 2153.396853] ata1.01: failed command: WRITE DMA EXT
--- skip ---
SYSLINUX 3.53 0x5d037742 EBIOS Copyright (C) 1994-2007 H. Peter Anvin
基本上,长阻塞I/O可视为StarOS VNF的一个关键问题,应尽可能减少。
长阻塞I/O场景
根据对多个客户部署和实验室测试的研究,确定了2种主要方案,可能导致Ceph的长阻塞I/O。
Laggy计时器机制
OSD之间有心跳机制,可检测OSD关闭。根据osd_heartbeat_grace值(默认为20秒),OSD被检测为失败。
在OSD状态出现波动或抖动时,宏计时器自动调整(变长)。 这可能会使osd_heartbeat_grace值更大。
正常情况下,心跳宽限为20秒
2019-01-09 16:58:01.715155 mon.ceph-XXXXX [INF] osd.2 failed (root=default,host=XXXXX) (2 reporters from different host after 20.000047 >= grace 20.000000)
但是,当一个存储节点出现多个网络抖动后,它会变得更大。
2019-01-10 16:44:15.140433 mon.ceph-XXXXX [INF] osd.2 failed (root=default,host=XXXXX) (2 reporters from different host after 256.588099 >= grace 255.682576)
因此,在上例中,需要256秒来检测OSD是否关闭。
RAID卡硬件故障
Ceph可能无法及时检测RAID卡硬件故障。RAID卡故障最终导致某种OSD挂起情况。在这种情况下,几分钟后检测到OSD关闭,足以使StarOS VNF重新启动。
当RAID卡挂起时,某些CPU核心在wa状态时占100%。
%Cpu20 : 2.6 us, 7.9 sy, 0.0 ni, 0.0 id, 89.4 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu21 : 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu22 : 31.3 us, 5.1 sy, 0.0 ni, 63.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu23 : 0.0 us, 0.0 sy, 0.0 ni, 28.1 id, 71.9 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu24 : 0.0 us, 0.0 sy, 0.0 ni, 0.0 id,100.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu25 : 0.0 us, 0.0 sy, 0.0 ni, 0.0 id,100.0 wa, 0.0 hi, 0.0 si, 0.0 st
OSD的CPU内核逐渐耗尽,OSD也逐渐下降,有时间差。
2019-01-01 17:08:05.267629 mon.ceph-XXXXX [INF] Marking osd.2 out (has been down for 602 seconds)
2019-01-01 17:09:25.296955 mon.ceph-XXXXX [INF] Marking osd.4 out (has been down for 603 seconds)
2019-01-01 17:11:10.351131 mon.ceph-XXXXX [INF] Marking osd.7 out (has been down for 604 seconds)
2019-01-01 17:16:40.426927 mon.ceph-XXXXX [INF] Marking osd.10 out (has been down for 603 seconds)
同时,在ceph.log中检测慢速请求。
2019-01-01 16:57:26.743372 mon.XXXXX [WRN] Health check failed: 1 slow requests are blocked > 32 sec. Implicated osds 2 (REQUEST_SLOW)
2019-01-01 16:57:35.129229 mon.XXXXX [WRN] Health check update: 3 slow requests are blocked > 32 sec. Implicated osds 2,7,10 (REQUEST_SLOW)
2019-01-01 16:57:38.055976 osd.7 osd.7 [WRN] 1 slow requests, 1 included below; oldest blocked for > 30.216236 secs
2019-01-01 16:57:39.048591 osd.2 osd.2 [WRN] 1 slow requests, 1 included below; oldest blocked for > 30.635122 secs
-----skip-----
2019-01-01 17:06:22.124978 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 554.285311 secs
2019-01-01 17:06:25.114453 osd.4 osd.4 [WRN] 19 slow requests, 1 included below; oldest blocked for > 546.221508 secs
2019-01-01 17:06:26.125459 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 558.285789 secs
2019-01-01 17:06:27.125582 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 559.285915 secs
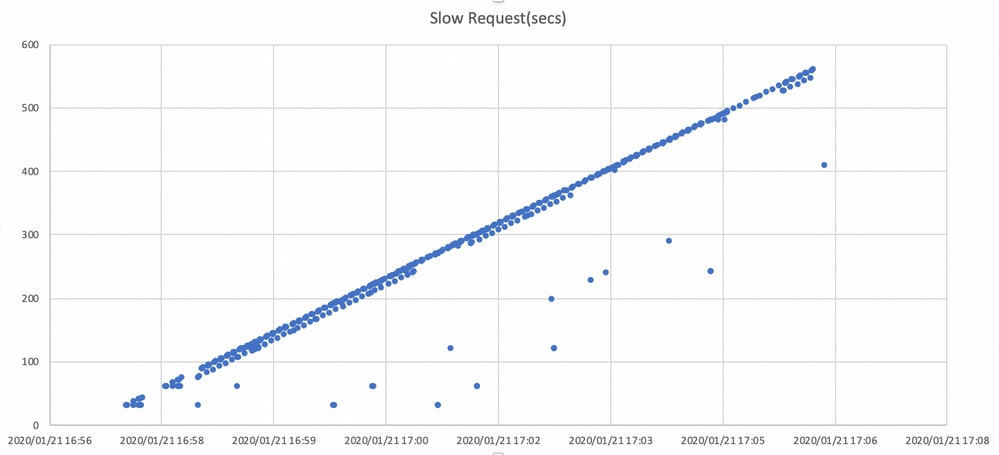
此图显示了使用时间线阻止I/O请求的时间。通过在ceph.log中绘制慢速请求日志来创建该图。它表明,阻塞时间会随着时间推移而变长。
如何降低影响?
从Ceph存储移动到本地磁盘
减轻影响的最简单方法是从Ceph存储移动到本地磁盘。StarOS使用2个磁盘(/flash和/hd-raid),可以只将/flash移动到本地磁盘,这使StarOS VNF对于Ceph问题更加稳健。使用共享存储(如Ceph)的负面是,当出现问题时,使用共享存储的所有VNF都会受到影响。通过使用本地磁盘,存储问题的影响可以最小化到仅在受影响节点上运行的VNF。而且,上一节中提到的场景仅适用于Ceph,不适用于本地磁盘。但本地磁盘的反面是,在重新部署虚拟机时,磁盘的内容(如StarOS映像、配置、核心文件、计费记录)无法保留。它也可能影响VNF自愈机制。
CEPH配置调整
从StarOS VNF的角度,建议使用以下新的Ceph参数,以尽量减少上述阻塞I/O时间。
<默认设置>
"mon_osd_adjust_heartbeat_grace": "true",
"osd_client_watch_timeout": "30",
"osd_max_markdown_count": "5",
"osd_heartbeat_grace": "20",
<新设置>
"mon_osd_adjust_heartbeat_grace": "false",
"osd_client_watch_timeout": "10",
"osd_max_markdown_count": "1",
"osd_heartbeat_grace": "10",
它包括:
- 该拉格计时器机构被禁用,无自动调整
- 心跳宽限时间缩短
- OSD立即标记为关闭(默认为过去600秒内5次)
新参数在实验室中测试,OSD关闭检测时间缩短到约10秒,最初大约30秒,默认配置为Ceph。
监控RAID卡硬件问题
对于RAID卡硬件场景,由于问题的性质,可能仍难以及时检测,因为这会造成OSD间歇性工作而I/O被阻塞的情况。此解决方案没有单一解决方案,但建议监控服务器硬件日志以查找RAID卡故障,或通过某些脚本监控ceph.log中的慢请求日志,并采取一些措施,例如主动关闭受影响的OSD。
CEPH_OSD_RESERVED_PCORES调谐
这与上述场景无关,但是如果Ceph性能因I/O操作过重而出现问题,则增加CEPH_OSD_RESEREVED_PCORES值可以使Ceph I/O性能更好。默认情况下,思科VIM上的CEPH_OSD_RESERVED_PCORES配置为2并可以增加。
由思科工程师提供
- Tomonobu OkadaCisco TAC Engineer
- Satoshi KinoshitaCisco TAC Engineer
 反馈
反馈