Ultra-M元件管理器集群中的高可用性恢复- vEPC
下载选项
非歧视性语言
此产品的文档集力求使用非歧视性语言。在本文档集中,非歧视性语言是指不隐含针对年龄、残障、性别、种族身份、族群身份、性取向、社会经济地位和交叉性的歧视的语言。由于产品软件的用户界面中使用的硬编码语言、基于 RFP 文档使用的语言或引用的第三方产品使用的语言,文档中可能无法确保完全使用非歧视性语言。 深入了解思科如何使用包容性语言。
关于此翻译
思科采用人工翻译与机器翻译相结合的方式将此文档翻译成不同语言,希望全球的用户都能通过各自的语言得到支持性的内容。 请注意:即使是最好的机器翻译,其准确度也不及专业翻译人员的水平。 Cisco Systems, Inc. 对于翻译的准确性不承担任何责任,并建议您总是参考英文原始文档(已提供链接)。
简介
本文档介绍在托管StarOS虚拟网络功能(VNF)的Ultra-M设置的元素管理器(EM)群集中恢复高可用性(HA)所需的步骤。
背景信息
Ultra-M是经过预先封装和验证的虚拟化移动数据包核心解决方案,旨在简化VNF的部署。Ultra-M解决方案包括上述虚拟机(VM)类型:
- 自动IT
- 自动部署
- 超自动化服务(UAS)
- 元素管理器(EM)
- 弹性服务控制器(ESC)
- 控制功能(CF)
- 会话功能(SF)
Ultra-M的高级架构和涉及的组件如下图所示:
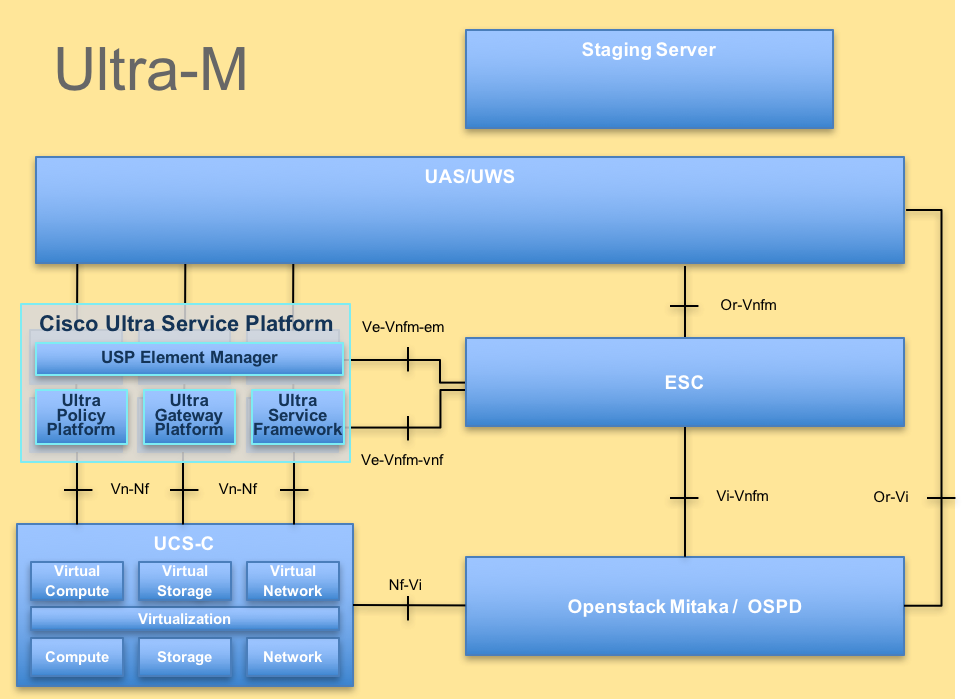 UltraM体系结构
UltraM体系结构
本文档面向熟悉Cisco Ultra-M平台的思科人员。
注意:在定义本文档中的过程时需要考虑Ultra M 5.1.x版本。
缩写
| HA | 高可用性 |
| VNF | 虚拟网络功能 |
| CF | 控制功能 |
| 旧金山 | 服务功能 |
| ESC | 弹性服务控制器 |
| MOP | 程序方法 |
| OSD | 对象存储磁盘 |
| HDD | 硬盘驱动器 |
| SSD | 固态硬盘 |
| VIM | 虚拟基础设施管理器 |
| VM | 虚拟机 |
| EM | 元素管理器 |
| UAS | 超自动化服务 |
| UUID | 通用唯一标识符 |
MoP的工作流程
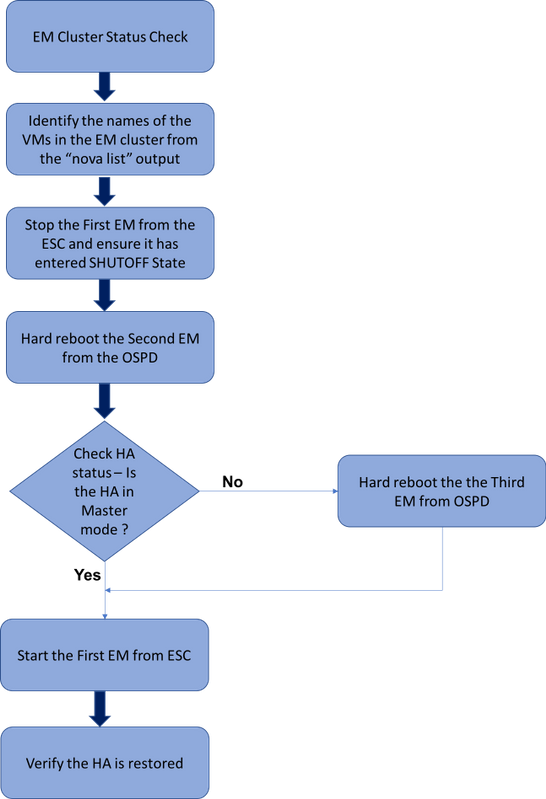 EM HA恢复过程的高级工作流
EM HA恢复过程的高级工作流
检查集群状态
登录到活动EM并检查高可用性状态。有两种情况:
1. HA模式为none:
ubuntu@vnfd1deploymentem-0:~$ ncs_cli -u admin -C
admin@scm# show ncs-state ha
ncs-state ha mode none
admin@scm# show ems
%no entries found%
2. EM集群只有一个节点(EM集群包含3台虚拟机):
ubuntu@vnfd1deploymentem-0:~$ ncs_cli -u admin -C
admin@scm# show ncs-state ha
ncs-state ha mode master
ncs-state ha node-id 2-1528893823
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
----------------------
2 up down down
在这两种情况下,HA状态都可以通过下一节中提到的步骤来恢复。
HA恢复过程
从nova列表中确定属于集群的EM的VM名称。EM集群中将包含三台虚拟机。
[stack@director ~]$ nova list | grep vnfd1
| e75ae5ee-2236-4ffd-a0d4-054ec246d506 | vnfd1-deployment_c1_0_13d5f181-0bd3-43e4-be2d-ada02636d870 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.22; DI-INTERNAL2=192.168.2.17; DI-INTERNAL1=192.168.1.14; tmo-autovnf2-uas-management=172.18.181.23 |
| 33c779d2-e271-47af-8ad5-6a982c79ba62 | vnfd1-deployment_c4_0_9dd6e15b-8f72-43e7-94c0-924191d99555 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.13; DI-INTERNAL2=192.168.2.14; DI-INTERNAL1=192.168.1.4; tmo-autovnf2-uas-management=172.18.181.21 |
| 65344d53-de09-4b0b-89a6-85d5cfdb3a55 | vnfd1-deployment_s2_0_b2cbf15a-3107-45c7-8edf-1afc5b787132 | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.4, 192.168.10.9; SERVICE-NETWORK2=192.168.20.17, 192.168.20.6; tmo-autovnf2-uas-orchestration=172.18.180.12; DI-INTERNAL2=192.168.2.6; DI-INTERNAL1=192.168.1.12 |
| e1a6762d-4e84-4a86-a1b1-84772b3368dc | vnfd1-deployment_s3_0_882cf1ed-fe7a-47a7-b833-dd3e284b3038 | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.22, 192.168.10.14; SERVICE-NETWORK2=192.168.20.5, 192.168.20.14; tmo-autovnf2-uas-orchestration=172.18.180.14; DI-INTERNAL2=192.168.2.7; DI-INTERNAL1=192.168.1.5 |
| b283d43c-6e0c-42e8-87d4-a3af15a61a83 | vnfd1-deployment_s5_0_672bbb00-34f2-46e7-a756-52907e1d3b3d | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.21, 192.168.10.24; SERVICE-NETWORK2=192.168.20.21, 192.168.20.24; tmo-autovnf2-uas-orchestration=172.18.180.20; DI-INTERNAL2=192.168.2.13; DI-INTERNAL1=192.168.1.16 |
| 637547ad-094e-4132-8613-b4d8502ec385 | vnfd1-deployment_s6_0_23cc139b-a7ca-45fb-b005-733c98ccc299 | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.13, 192.168.10.19; SERVICE-NETWORK2=192.168.20.9, 192.168.20.22; tmo-autovnf2-uas-orchestration=172.18.180.16; DI-INTERNAL2=192.168.2.19; DI-INTERNAL1=192.168.1.21 |
| 4169438f-6a24-4357-ad39-2a35671d29e1 | vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.6; tmo-autovnf2-uas-management=172.18.181.8 |
| 30431294-c3bb-43e6-9bb3-6b377aefbc3d | vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.7; tmo-autovnf2-uas-management=172.18.181.9 |
| 28ab33d5-7e08-45fe-8a27-dfb68cf50321 | vnfd1-deployment_vnfd1-_0_f63241f3-2516-4fc4-92f3-06e45054dba0 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.3; tmo-autovnf2-uas-management=172.18.181.7 |
停止其中一个EM从ESC并检查它是否已进入SHUTOFF 状态。
[admin@vnfm1-esc-0 esc-cli]$ /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli vm-action STOP vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
[admin@vnfm1-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_INERT_STATE</state>
vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
VM_SHUTOFF_STATE
<vm_name>vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>vnfd1-deployment_vnfd1-_0_f63241f3-2516-4fc4-92f3-06e45054dba0</vm_name>
<state>VM_ALIVE_STATE</state>
现在,一旦EM进入SHUTOFF状态,请从OpenStack Platform Director (OSPD)中重新启动其他EM。
[stack@director ~]$ nova reboot --hard vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a
Request to reboot server <Server: vnfd2-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a> has been accepted.
再次登录EM VIP并检查HA状态。
ubuntu@vnfd1deploymentem-0:~$ ncs_cli -u admin -C
admin@scm# show ncs-state ha
ncs-state ha mode master
ncs-state ha node-id 2-1528893823
如果HA处于“master”状态,请从ESC启动之前关闭的EM。否则,继续从OSPD重新启动下一个EM,然后再次检查HA状态。
[admin@vnfm1-esc-0 esc-cli]$ /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli vm-action START vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
[admin@vnfm1-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
VM_ALIVE_STATE
<vm_name>vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>vnfd1-deployment_vnfd1-_0_f63241f3-2516-4fc4-92f3-06e45054dba0</vm_name>
<state>VM_ALIVE_STATE</state>
从ESC启动EM后,请检查EM的HA状态。它本应该被恢复。
admin@scm# em-ha-status
ha-status MASTER
admin@scm# show ncs-state ha
ncs-state ha mode master
ncs-state ha node-id 4-1516609103
ncs-state ha connected-slave [ 2-1516609363 ]
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
---------------------
2 up up up
4 up up up
 反馈
反馈