Isolamento Ultra-M e substituição de disco com falha do cluster de armazenamento/Ceph - vEPC
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introdução
Este documento descreve as etapas necessárias para executar a fim de isolar e substituir o disco OSD do cluster Ceph/Storage hospedado em Object Storage Disk (OSD)-Compute em uma configuração Ultra-M.
Informações de Apoio
O Ultra-M é uma solução de núcleo de pacotes móveis virtualizados, validada e predefinida, projetada para simplificar a implantação de VNFs. O OpenStack é o Virtualized Infrastructure Manager (VIM) para Ultra-M e consiste nos seguintes tipos de nó:
- Computação
- OSD - Computação
- Controlador
- Plataforma OpenStack - Diretor (OSPD)
A arquitetura avançada do Ultra-M e os componentes envolvidos são descritos nesta imagem:
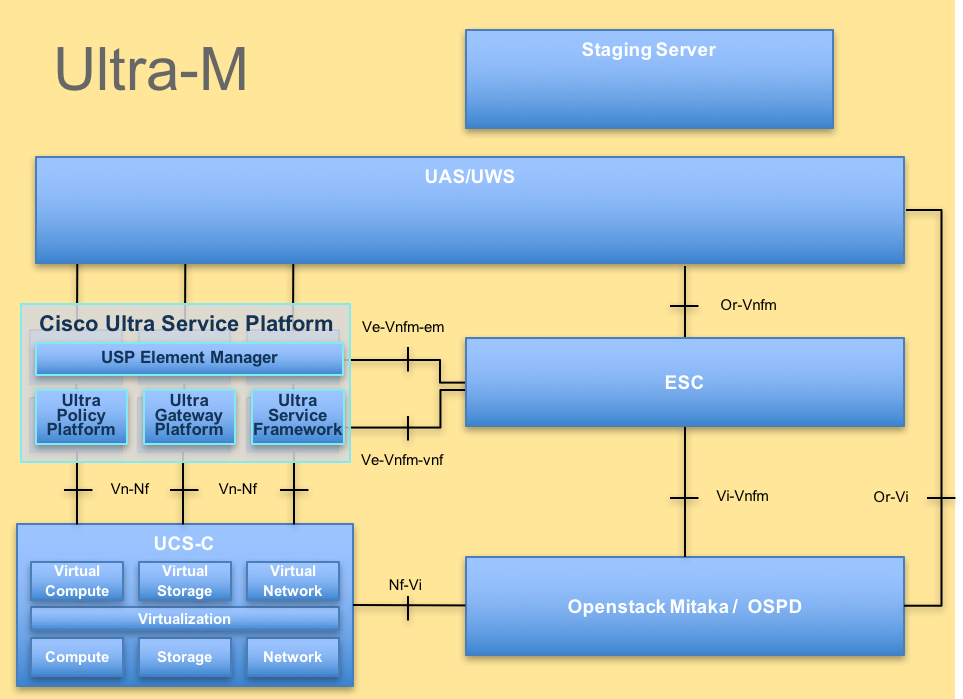 Arquitetura UltraMEste documento destina-se ao pessoal da Cisco que está familiarizado com a plataforma Cisco Ultra-M e detalha as etapas necessárias a serem executadas no nível do OpenStack no momento da substituição do servidor OSPD.
Arquitetura UltraMEste documento destina-se ao pessoal da Cisco que está familiarizado com a plataforma Cisco Ultra-M e detalha as etapas necessárias a serem executadas no nível do OpenStack no momento da substituição do servidor OSPD.
Note: A versão Ultra M 5.1.x é considerada para definir os procedimentos neste documento.
Abreviaturas
| VNF | Função de rede virtual |
| CF | Função de controle |
| SF | Função de serviço |
| ESC | Controlador de serviço elástico |
| MOP | Método de Procedimento |
| OSD | Discos de Armazenamento de Objetos |
| HDD | Unidade de disco rígido |
| SSD | Unidade de estado sólido |
| VIM | Gerente de infraestrutura virtual |
| VM | Máquina virtual |
| EM | Gerenciador de Elementos |
| UAS | Ultra Automation Services |
| UUID | Identificador Exclusivo Universal |
Fluxo de trabalho do MoP

Verificações de Integridade de Pré-requisito
1. Use o comando Ceph-disk list para entender o mapeamento do OSD para o Diário e identificar o disco a ser isolado e substituído.
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph-disk list
/dev/sda :
/dev/sda1 other, iso9660
/dev/sda2 other, xfs, mounted on /
/dev/sdb :
/dev/sdb1 ceph journal, for /dev/sdc1
/dev/sdb3 ceph journal, for /dev/sdd1
/dev/sdb2 ceph journal, for /dev/sde1
/dev/sdb4 ceph journal, for /dev/sdf1
/dev/sdc :
/dev/sdc1 ceph data, active, cluster ceph, osd.1, journal /dev/sdb1
/dev/sdd :
/dev/sdd1 ceph data, active, cluster ceph, osd.7, journal /dev/sdb3
/dev/sde :
/dev/sde1 ceph data, active, cluster ceph, osd.4, journal /dev/sdb2
/dev/sdf :
/dev/sdf1 ceph data, active, cluster ceph, osd.10, journal /dev/sdb4
2. Verifique a integridade do Ceph e o mapeamento da árvore OSD antes de continuar com o isolamento de disco OSD identificado.
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e709: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v941813: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 11922 GB / 13393 GB avail
704 active+clean
client io 58580 B/s wr, 0 op/s rd, 7 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 0 host pod1-osd-compute-1
-4 4.35999 host pod1-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
Isolamento e remoção de disco OSD com defeito do cluster
1. Desative e interrompa o processo OSD.
[heat-admin@pod1-osd-compute-3 ~]$ sudo systemctl disable ceph-osd@7
[heat-admin@pod1-osd-compute-3 ~]$ sudo systemctl stop ceph-osd@7
2. Desative a mensagem na tela.
[heat-admin@pod1-osd-compute-3 ~]$ sudo su
[root@pod1-osd-compute-3 heat-admin]# ceph osd set noout
set noout
[root@pod1-osd-compute-3 heat-admin]# ceph osd set norebalance
set norebalance
[root@pod1-osd-compute-3 heat-admin]# ceph osd out 7
marked out osd.7.
Note: Aguarde até que o rebalanceamento de dados seja concluído e todos os PGs voltem para ative+clean para evitar problemas.
3. Confirme se o OSD está marcado e aguarde até que o rebalanceamento de Ceph continue.
[root@pod1-osd-compute-3 heat-admin]# watch -n1 ceph -s
95 active+undersized+degraded+remapped+wait_backfill
28 active+recovery_wait+degraded
2 active+undersized+degraded+remapped+backfilling
1 active+recovering+degraded
2 active+undersized+degraded+remapped+backfilling
1 active+recovering+degraded
2 active+undersized+degraded+remapped+backfilling
67 active+undersized+degraded+remapped+wait_backfill
3 active+undersized+degraded+remapped+backfilling
24 active+undersized+degraded+remapped+wait_backfill
22 active+undersized+degraded+remapped+wait_backfill
1 active+undersized+degraded+remapped+backfilling
8 active+undersized+degraded+remapped+wait_backfill
4. Remova a chave de autenticação para o OSD.
[root@pod1-osd-compute-3 heat-admin]# ceph auth del osd.7
updated
5. Confirme se as chaves para OSD.7 não estão listadas.
[root@pod1-osd-compute-3 heat-admin]# ceph auth list
installed auth entries:
osd.0
key: AQCgpB5blV9dNhAAzDN1SVdnuJyTN2f7PAdtFw==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.1
key: AQBdwyBbbuD6IBAAcvG+oQOz5vk62faOqv/CEw==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.10
key: AQCwwyBb7xvHJhAAZKPprXWT7UnvnAXBV9W2rg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.11
key: AQDxpB5b9/rGFRAAkcCEkpSN1YZVDdeW+Bho7w==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.2
key: AQCppB5btekoNBAAACoWpDz0VL9bZfyIygDpBQ==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.3
key: AQC4pB5bBaUlORAAhi3KPzetwvWhYGnerAkAsg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.4
key: AQB1wyBbvMIQLRAAXefFVnZxMX6lVtObQt9KoA==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.5
key: AQDBpB5buKHqOhAAW1Q861qoYqW6fAYHlOxsLg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.6
key: AQDQpB5b1BveFxAAfCLM3tvDUSnYneutyTmaEg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.8
key: AQDZpB5bd4nlGRAAkkzbmGPnEDAWV0dUhrhE6w==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.9
key: AQDopB5bKCZPGBAAfYtp1GLA7QIi/YxJa8O1yw==
caps: [mon] allow profile osd
caps: [osd] allow *
client.admin
key: AQDpmx5bAAAAABAA3hLK8O2tGgaAK+X2Lly5Aw==
caps: [mds] allow *
caps: [mon] allow *
caps: [osd] allow *
client.bootstrap-mds
key: AQBDpB5bjR1GJhAAB6CKKxXulve9WIiC6ZGXgA==
caps: [mon] allow profile bootstrap-mds
client.bootstrap-osd
key: AQDpmx5bAAAAABAA3hLK8O2tGgaAK+X2Lly5Aw==
caps: [mon] allow profile bootstrap-osd
client.bootstrap-rgw
key: AQBDpB5b7OWXHBAAlATmBAOX/QWW+2mLxPqlkQ==
caps: [mon] allow profile bootstrap-rgw
client.openstack
key: AQDpmx5bAAAAABAAULxfs9cYG1wkSVTjrtiaDg==
caps: [mon] allow r
caps: [osd] allow class-read object_prefix rbd_children, allow rwx pool=volumes, allow rwx pool=backups, allow rwx pool=vms, allow rwx pool=images, allow rwx pool=metrics
7. Remova o OSD do cluster.
[root@pod1-osd-compute-3 heat-admin]# ceph osd rm 7
removed osd.7
8. Desmonte o disco OSD que precisa ser substituído.
[root@pod1-osd-compute-3 heat-admin]# umount /var/lib/ceph/osd/ceph-7
9. Desative o noscrub e deep scrub.
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset noscrub
unset noscrub
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset nodeep-scrub
unset nodeep-scrub
10. Verifique a integridade do Ceph e aguarde até que a integridade esteja OK e todos os PGs voltem para ative+clean.
[root@pod1-osd-compute-3 heat-admin]# ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
28 pgs backfill_wait
4 pgs backfilling
5 pgs degraded
5 pgs recovery_wait
83 pgs stuck unclean
recovery 1697/516881 objects degraded (0.328%)
recovery 76428/516881 objects misplaced (14.786%)
noout,norebalance,sortbitwise,require_jewel_osds flag(s) set
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e877: 11 osds: 11 up, 11 in; 193 remapped pgs
flags noout,norebalance,sortbitwise,require_jewel_osds
pgmap v942974: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 10806 GB / 12277 GB avail
1697/516881 objects degraded (0.328%)
76428/516881 objects misplaced (14.786%)
511 active+clean
156 active+remapped
28 active+remapped+wait_backfill
5 active+recovery_wait+degraded+remapped
4 active+remapped+backfilling
client io 331 kB/s wr, 0 op/s rd, 56 op/s wr
Substitua o disco OSD e crie um novo DVD
1. Remova a unidade com falha e substitua-a por uma nova unidade: Guia de instalação e serviço do servidor Cisco UCS C240 M4.
2. Verifique o login no CIMC do OSD-Compute e verifique o slot onde o OSD é substituído e mostrado com boa saúde.
3. Crie uma unidade virtual para um novo HDD, ele deve ser um HDD novo sem metadados.
4. Verifique se o disco recém-adicionado está no estado Não confirmado.
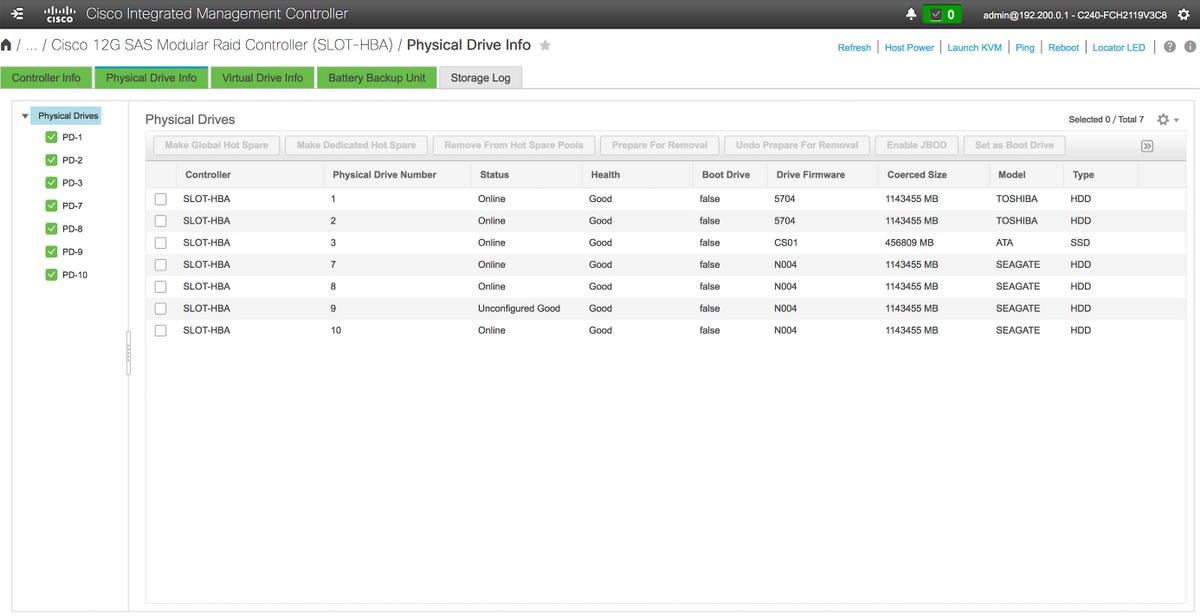 Armazenamento > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Informações da unidade física
Armazenamento > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Informações da unidade física
5. Selecione a opção Create Virtual Drive from Unused Physical Drives para criar o DVD.
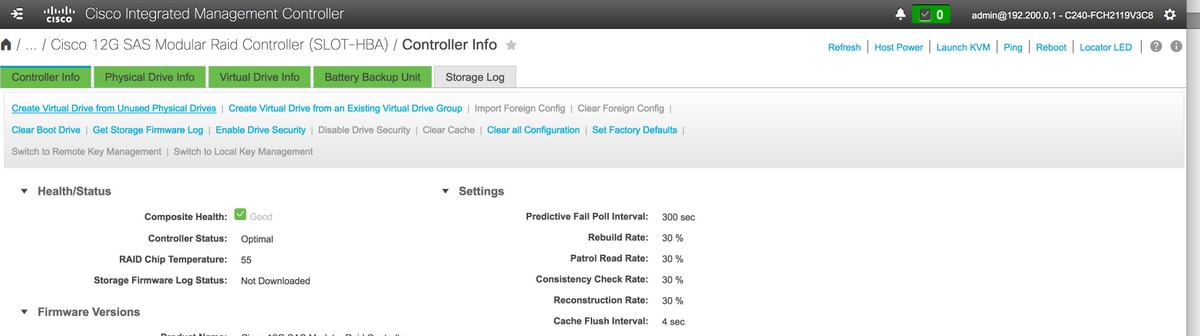 Armazenamento > Cisco 12G SAS Modular Raid Controller (SLOT-HBA)
Armazenamento > Cisco 12G SAS Modular Raid Controller (SLOT-HBA)
6. Use Physical Drive 9 para criar um novo VD e nomeie-o como OSD3.
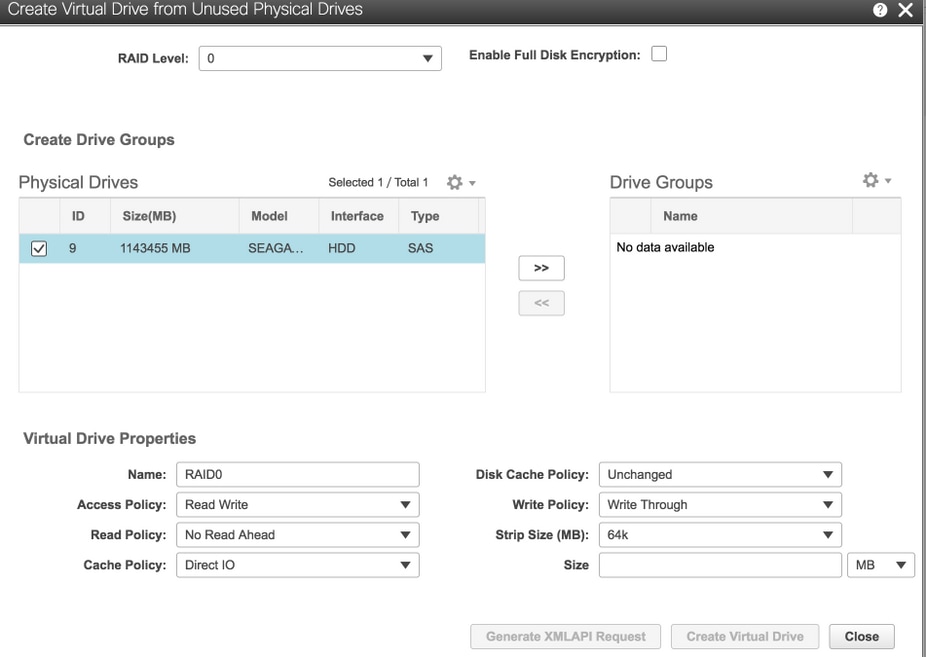 Armazenamento > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Controller Info > Create Virtual Drive from Unused Physical Drives (Informações do controlador > Criar unidade virtual a partir de unidades físicas não utilizadas)
Armazenamento > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Controller Info > Create Virtual Drive from Unused Physical Drives (Informações do controlador > Criar unidade virtual a partir de unidades físicas não utilizadas)
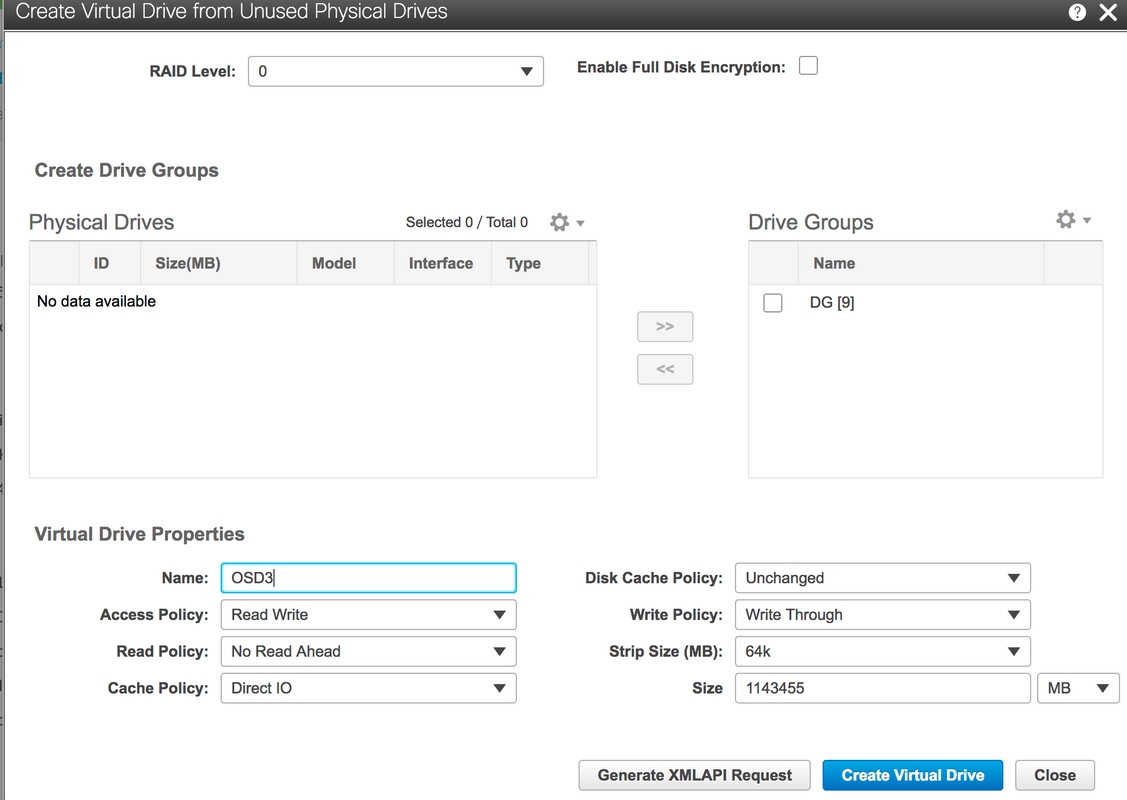 Armazenamento > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Controller Info > Create Virtual Drive from Unused Physical Drives (Informações do controlador > Criar unidade virtual a partir de unidades físicas não utilizadas)
Armazenamento > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Controller Info > Create Virtual Drive from Unused Physical Drives (Informações do controlador > Criar unidade virtual a partir de unidades físicas não utilizadas)
7. Habilitar IPMI sobre LAN: Admin > Serviços de Comunicação > Serviços de Comunicação.
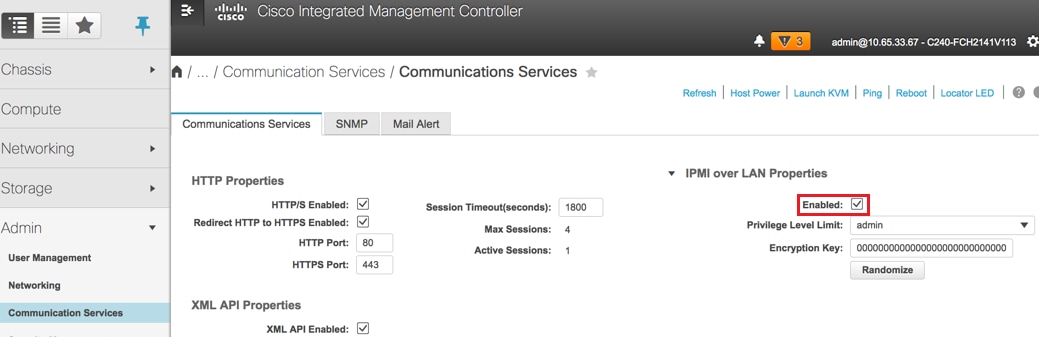 Habilitar IPMI sobre LAN: Admin > Serviços de Comunicação > Serviços de Comunicação
Habilitar IPMI sobre LAN: Admin > Serviços de Comunicação > Serviços de Comunicação
8. Desative o hyperthreading: Computação > BIOS > Conimage BIOS > Avançado > Configuração do processador.
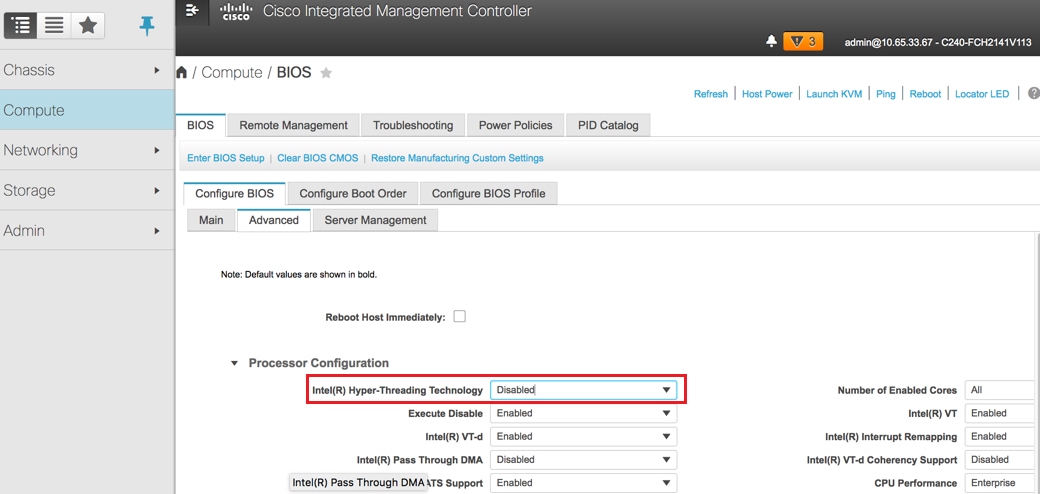 Desabilitar hiperthreading: Computação > BIOS > Configurar BIOS > Avançado > Configuração do processador
Desabilitar hiperthreading: Computação > BIOS > Configurar BIOS > Avançado > Configuração do processador
Note: A imagem mostrada aqui e as etapas de configuração mencionadas nesta seção dizem respeito à versão 3.0(3e) do firmware e pode haver pequenas variações se você trabalhar em outras versões.
Adicionar o OSD de volta ao cluster
1. Depois que um novo disco for substituído, execute partprobe para descobrir o novo dispositivo.
[root@pod1-osd-compute-3 heat-admin]# partprobe
[root@pod1-osd-compute-3 heat-admin]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 278.5G 0 disk
|
-sda1 8:1 0 1M 0 part
-sda2 8:2 0 278.5G 0 part /
sdb 8:16 0 446.1G 0 disk
|
-sdb1 8:17 0 107G 0 part
-sdb2 8:18 0 107G 0 part
-sdb3 8:19 0 107G 0 part
-sdb4 8:20 0 107G 0 part
sdc 8:32 0 1.1T 0 disk
|
-sdc1 8:33 0 1.1T 0 part /var/lib/ceph/osd/ceph-1
sdd 8:48 0 1.1T 0 disk
|
-sdd1 8:49 0 1.1T 0 part
sde 8:64 0 1.1T 0 disk
|
-sde1 8:65 0 1.1T 0 part /var/lib/ceph/osd/ceph-4
sdf 8:80 0 1.1T 0 disk
|
-sdf1 8:81 0 1.1T 0 part /var/lib/ceph/osd/ceph-10
2. Localize um dispositivo disponível no servidor.
[root@pod1-osd-compute-3 heat-admin]# fdisk -l
Disk /dev/sda: 299.0 GB, 298999349248 bytes, 583983104 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x000b5e87
Device Boot Start End Blocks Id System
/dev/sda1 2048 4095 1024 83 Linux
/dev/sda2 * 4096 583983070 291989487+ 83 Linux
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdb: 479.0 GB, 478998953984 bytes, 935544832 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 224462847 107G unknown ceph journal
2 224462848 448923647 107G unknown ceph journal
3 448923648 673384447 107G unknown ceph journal
4 673384448 897845247 107G unknown ceph journal
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdd: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdc: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sde: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdf: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
[root@pod1-osd-compute-3 heat-admin]#
3. Use Ceph-disk list para identificar o mapa de partição de disco de diário.
[root@pod1-osd-compute-3 heat-admin]# ceph-disk list
/dev/sda :
/dev/sda1 other, iso9660
/dev/sda2 other, xfs, mounted on /
/dev/sdb :
/dev/sdb1 ceph journal, for /dev/sdc1
/dev/sdb3 ceph journal
/dev/sdb2 ceph journal, for /dev/sde1
/dev/sdb4 ceph journal, for /dev/sdf1
/dev/sdc :
/dev/sdc1 ceph data, active, cluster ceph, osd.1, journal /dev/sdb1
/dev/sdd :
/dev/sdd1 other, xfs
/dev/sde :
/dev/sde1 ceph data, active, cluster ceph, osd.4, journal /dev/sdb2
/dev/sdf :
/dev/sdf1 ceph data, active, cluster ceph, osd.10, journal /dev/sdb4
Note: Na lista ceph-disk, o sde1 de saída destacado é uma partição de diário para sdb2. Verifique a saída da lista Ceph-disk e mapeie a partição de disco de diário no comando para preparação de Ceph. Assim que você executar abaixo o comando OSD.7 veio/veio e rebalanceamento de dados (backfill/recuperação) será iniciado.
4. Crie o disco Ceph e adicione-o de volta ao cluster.
[root@pod1-osd-compute-3 heat-admin]# ceph-disk --setuser ceph --setgroup ceph prepare --fs-type xfs /dev/sdd /dev/sdb3
prepare_device: OSD will not be hot-swappable if journal is not the same device as the osd data
Creating new GPT entries.
The operation has completed successfully.
meta-data=/dev/sdd1 isize=2048 agcount=4, agsize=73181055 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=292724219, imaxpct=5
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=142931, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
Warning: The kernel is still using the old partition table.
The new table will be used at the next reboot.
The operation has completed successfully.
#####Hint###
where - sdd is new drive added as OSD
where – sdb3 is journal disk partition number
mapping is sdc1 for sdc, sdd1 for sdd, sde1 for sde
sdf1 for sdf (and so on)
5. Ative os discos Ceph e desconfigure os sinalizadores noscrub e nodeep-scrub.
[root@pod1-osd-compute-3 heat-admin]# ceph-disk activate-all
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset noout
unset noout
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset norebalance
unset norebalance
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset noscrub
unset noscrub
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset nodeep-scrub
unset nodeep-scrub
6. Aguarde até que o reequilíbrio seja concluído e verifique se a integridade da árvore Ceph e OSD está boa.
[root@pod1-osd-compute-3 heat-admin]# watch -n 3 ceph -s
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e709: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v941813: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 11922 GB / 13393 GB avail
704 active+clean
client io 58580 B/s wr, 0 op/s rd, 7 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
Colaborado por engenheiros da Cisco
- Partheeban RajagopalServiços avançados da Cisco
- Padmaraj RamanoudjamServiços avançados da Cisco
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)