Monitore o desempenho do iftask e do NPU no QvPC-DI
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Introdução
Este documento descreve como monitorar o desempenho de iftask / NPU em QvPC-DI.
Ele também fornece mais informações sobre alguns conceitos-chave do iftask.
Componentes Utilizados
As informações neste documento são baseadas no QvPC-DI.
As informações neste documento foram criadas a partir de dispositivos em um ambiente de laboratório específico. Todos os dispositivos utilizados neste documento foram iniciados com uma configuração (padrão) inicial. Se a rede estiver ativa, certifique-se de que você entenda o impacto potencial de qualquer comando.
Arquitetura Iftask
iftask é um processo em QvPC-DI. Ativa a funcionalidade do Data Plane Development Kit (DPDK) na Placa Virtual de Função de Serviço (SF - Service Function Virtual Card) e na Placa Virtual de Função de Controle (CF - Control Function Virtual Card) para as portas de rede DI e as portas de serviço. O DPDK é uma maneira mais eficiente de lidar com entrada/saída em ambientes virtualizados.
Os drivers de dispositivo dos controladores de interface de rede (NICs) de alto desempenho são agora movidos para o espaço do usuário, o que evita switches de contexto caros (espaço do usuário/kernelspace).
Os drivers são executados no modo ininterrupto no espaço de usuário e os threads têm acesso direto às filas de HW/buffers de anel nesses drivers NIC.
A documentação sobre arquitetura está disponível em :
Introdução à Ultra Services Platform (USP) no Ultra Gateway Platform System Administration Guide.
Disponibilidade para diferentes versões.
A arquitetura de tarefa detalhada (para SF) é vista neste diagrama:
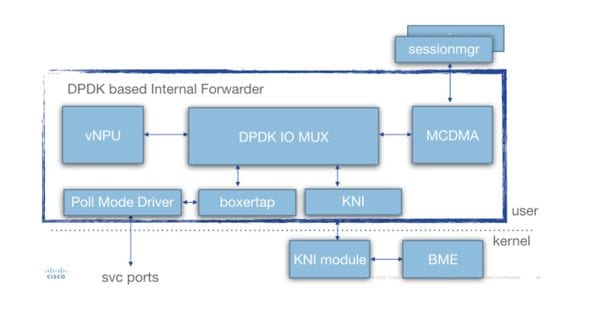
Vários componentes estão presentes:
Driver de modo de pesquisa (PMD): Essa é a função que está fazendo o polling contínuo das filas de HW das placas de rede (no caso de SR-IOV), ou dos buffers de anel de SW (no caso de interfaces do tipo virtio/vmxnet). É por isso que as CPUs associadas a esses PMDs são continuamente submetidas a pegging a 100%.
Durante a implantação, os nrs de CPUs alocados para iftask e para várias funções dentro de iftask podem ser alocados estaticamente através do arquivo param.cfg.
Botão: anexar/remover metadados staros (cabeçalho MEH) a pacotes com base na origem do pacote (ex: Di port/service port) e para onde deve ser enviado (ex: vNPU local)
IOMUX: Tem uma biblioteca BIA com todos os destinos (sessmgr's/ports/vNPU's/..). Essa função basicamente está roteando os pacotes com base em seu BIA
vNPU: -classificação/pesquisa de fluxo. Isso é comparável ao NPU nos sistemas baseados em HW (ASR5000/ASR5500).
Os fluxos no vNPU ainda são programados pelo NPUmgr (que obtém suas informações do demuxmgr/sessmgr etc.) na memória compartilhada que é acessível pelo vNPU.
-Além disso, uma API é criada para que o npumgr/sessmgr possa pesquisar o vNPU para estatísticas/configuração
MCDMA: os pacotes destinados ao sessmgr são gravados na interface MCDMA (através dos vários núcleos/threads MCDMA disponíveis). Esses pacotes são disponibilizados para o sessmgr via DMA. Isso fornece um aumento real de desempenho, pois o kernel está envolvido apenas de forma limitada. Isso é explicado com mais detalhes neste artigo.
O MCDMA também fornece recursos de lote (para lidar com muitos pacotes em uma chamada do sistema).
KNI: interface para pacotes que precisam ir para o kernel linux (controle DI/ARP/icmp/roteamento/...)
Fluxo De Pacote Iftask
O diagrama abaixo explica o fluxo de um pacote de plano de controle. Exemplo: Solicitação de Criação de Sessão GTPv2
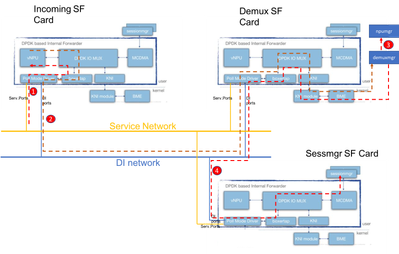
Passo 1: O pacote CSR GTPv2 entrará pela porta de serviço em qualquer um dos SFs disponíveis. Ele será colocado nas filas Rx da placa de rede da interface de serviço e coletado por um dos núcleos PMD do processo iftask. O Boxertap colocará o cabeçalho MEH e o pacote será encaminhado através do IOMux para o vNPU local para consulta de fluxo.
Como esta é uma nova sessão, o vNPU não tem fluxo específico programado para isso e terá que rotear o pacote para o demuxmgr na placa demux.
Passo 2: O vNPU altera o cabeçalho MEH (com um novo BIA para o processo demux relevante). O IOMUX sabe que precisa enviá-lo pela rede DI em direção à placa demux. Se o processo de tarefa na placa Demux manejar o pacote recebido, e o IOMux o roteará para o módulo KNI (que é a interface em direção ao kernel). Por meio do kernal, ele acabará no processo demuxmgr (egtpinmgr neste caso).
Passo 3: O Demuxmgr executará suas tarefas. Selecione um sessmgr e o programa npumgr com os fluxos para os pacotes GTPv2 subsequentes
Os vNPUs de todas as placas poderão acessar a memória compartilhada que o npumgr usa para programar esses fluxos.
Passo 4: O CSR GTPv2 é encaminhado para o sessmgr selecionado. O MEH é alterado novamente e encaminhado para fora do cartão Demux, na rede DI em direção ao cartão SF Sessmgr. O processo IOMUX nessa placa encaminhará o pacote pela interface MCDMA para o sessmgr selecionado. A partir daqui, o sessmgr tratará todo o tráfego GTPv2 para esta sessão. Uma vez negociados os TEIDs GTPU, ele programará os fluxos através do NPUmgr de modo que os pacotes GTPU subsequentes também possam ir diretamente da placa SF de entrada para a placa SF sessmgr.
vCPU's em iftask
Durante a implantação, determinada quantidade de vCPUs (virtual central processing units, unidades de processamento central virtual) é alocada estaticamente para o processo iftask. Isso reduz a quantidade de núcleos para aplicativos do espaço do usuário (sessmgr etc.), mas melhora muito o desempenho de E/S.
Essa alocação é feita por meio do parâmetro abaixo no modelo param.cfg associado a cada SF/CF durante a disponibilização:
- IFTASK_CORES (% de núcleos disponíveis a serem atribuídos a iftask)
- (IFTASK_CRYPTO_CORES - (% de núcleos disponíveis a serem atribuídos para processamento de criptografia (no caso de EPDG))
- (IFTASK_MCDMA_CORES - (para ajustar ainda mais o número de núcleos alocados para a funcionalidade MCDMA)
- Em um SF, o processo iftask distribuirá internamente seus núcleos atribuídos em:
- vCPUs PMD (Poll Mode Drivers, Drivers de modo de pesquisa) (realizando atividade tx/rx/vnpu)
- MCDMA vCPUs, fazendo a transferência de pacotes de iftask para sessmgr e vice-versa
- Em um CF, não são necessários vCPUs MCDMA, pois os SFs não hospedam processos sessmgr.
O comando 'show cloud hardware iftask' fornece mais detalhes sobre isso em sua implantação do QVPC-DI:
[local]UGP# show cloud hardware iftask Card 1: Total number of cores on VM: 8 Number of cores for PMD only: 0 Number of cores for VNPU only: 0 Number of cores for PMD and VNPU: 2 <-- CF: 2 out of 8 cores are assigned to iftask PMD/VNPU Number of cores for MCDMA: 0 <-- CF: no cores allocated to MCDMA as there is no sessmgr process on CF Number of cores for Crypto: 0 Hugepage size: 2048 kB Total hugepages: 3670016 kB NPUSHM hugepages: 0 kB CPU flags: avx sse sse2 ssse3 sse4_1 sse4_2 Poll CPU's: 1 2 KNI reschedule interval: 5 us ... Card 3: Total number of cores on VM: 8 Number of cores for PMD only: 0 Number of cores for VNPU only: 0 Number of cores for PMD and VNPU: 2 <-- SF: 2 out of 8 core are assigned to iftask PMD/VNPU
Number of cores for MCDMA: 1 <-- SF: 1 out of 8 cores is assigned to iftak MCDMA
Number of cores for Crypto: 0
Hugepage size: 2048 kB
Total hugepages: 4718592 kB
NPUSHM hugepages: 0 kB
CPU flags: avx sse sse2 ssse3 sse4_1 sse4_2
Poll CPU's: 1 2 3
KNI reschedule interval: 5 us
O comando 'show cloud configuration' fornecerá mais detalhes sobre os parâmetros usados:
[local]UGP# show cloud configuration Card 1: Config Disk Params: ------------------------- CARDSLOT=1 CPUID=0 CARDTYPE=0x40010100 DI_INTERFACE=BOND:TYPE:ixgbevf-1,TYPE:ixgbevf-2 DI_INTERFACE_VLANID=2111 VNFM_INTERFACE=MAC:fa:16:3e:23:aa:e9 VNFM_PROXY_ADDRS=172.16.180.3,172.16.180.5,172.16.180.6 MGMT_INTERFACE=MAC:fa:16:3e:87:23:9b VNFM_IPV4_ENABLE=true VNFM_IPV4_DHCP_ENABLE=true Local Params: ------------------------- CARDSLOT=1 CARDTYPE=0x40010100 CPUID=0 ... Card 3: Config Disk Params: ------------------------- CARDSLOT=3 CPUID=0 CARDTYPE=0x42030100 DI_INTERFACE=BOND:TYPE:ixgbevf-1,TYPE:ixgbevf-2 SERVICE1_INTERFACE=BOND:TYPE:ixgbevf-3,TYPE:ixgbevf-4 SERVICE2_INTERFACE=BOND:TYPE:ixgbevf-5,TYPE:ixgbevf-6 DI_INTERFACE_VLANID=2111 VNFM_INTERFACE=MAC:fa:16:3e:29:c6:b7 IFTASK_CORES=30 VNFM_IPV4_ENABLE=true VNFM_IPV4_DHCP_ENABLE=true Local Params: ------------------------- CARDSLOT=3 CARDTYPE=0x42010100 CPUID=0
Considerações do projeto:
Há uma série de fatores que devem ser considerados ao alocar vCPUs para iftask.
-vCPUs totais disponíveis para o SF versus vCPUs iftask: A configuração padrão especifica 30% dos vCPUs associados a iftask por meio do parâmetro IFTASK_CORES no arquivo param.cfg. Mas isso pode variar dependendo do aplicativo (MME vs SPGW vs ePDG) —> Para ser consultado com a engenharia.
-iftask vCPUs alocadas para PMD vs iftask vCPUs alocadas para MCDMA. Para verificar se isso está balanceado, consulte a seção iftask performance abaixo.
-iftask MCDMA vCPUs vs vCPUs restantes para todos os aplicativos. Normalmente, é bom ter uma distribuição 1/x de iftask MCDMA vCPU em relação aos vCPUs restantes para os aplicativos (sessmgr/aamgr/...).
Exemplo:
Total de núcleos 38 disponíveis para SF:
-14 atribuídos a iftask (6 PMD, 8 MCDMA)
-deixando 24 atribuídos a outros processos
O que significa que há 1 MCDMA vCPU para cada 3 vCPUs de aplicativo.
isso ajuda a garantir carga igual para cada vCPU MCDMA.
Monitorando o desempenho da tarefa if
O processo iftask pode ser monitorado de várias maneiras.
Consolidar lista de comandos show:
show subscribers data-rate show npumgr dinet utilization pps show npumgr dinet utilization pps show cloud monitor di-network summary show cloud hardware iftask show cloud configuration show iftask stats summary show port utilization table show npu utilization table show npumgr utilization information show processes cpu
O comando #show cpu info verbose não fornecerá informações sobre os núcleos iftask. Eles sempre serão listados com 100% de utilização.
No exemplo abaixo, o núcleo 1,2,3 está associado a iftask e está listado em 100% de utilização, isso é esperado.
Card 3, CPU 0:
Status : Standby, Kernel Running, Tasks Running
Load Average : 3.12, 3.12, 3.13 (3.95 max)
Total Memory : 16384M
Kernel Uptime : 4D 21H 56M
Last Reading:
CPU Usage All : 1.9% user, 0.3% sys, 0.0% io, 0.0% irq, 97.8% idle
Core 0 : 5.8% user, 0.2% sys, 0.0% io, 0.0% irq, 94.0% idle
Core 1 : Not Averaged (Poll CPU)
Core 2 : Not Averaged (Poll CPU)
Core 3 : Not Averaged (Poll CPU)
Core 4 : 2.2% user, 0.2% sys, 0.0% io, 0.0% irq, 97.6% idle
Core 5 : 0.8% user, 0.5% sys, 0.0% io, 0.0% irq, 98.7% idle
Core 6 : 0.4% user, 0.5% sys, 0.0% io, 0.0% irq, 99.1% idle
Core 7 : 0.1% user, 0.3% sys, 0.0% io, 0.0% irq, 99.6% idle
Poll CPUs : 3 (1, 2, 3)
Core 1 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Core 2 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Core 3 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Processes / Tasks : 143 processes / 16 tasks
Network mcdmaN : 0.002 kpps rx, 0.001 mbps rx, 0.002 kpps tx, 0.001 mbps tx
File Usage : 1504 open files, 1627405 available
Memory Usage : 7687M 46.9% used
Memory Details:
Static : 330M kernel, 144M image
System : 10M tmp, 0M buffers, 54M kcache, 79M cache
Process/Task : 6963M (120M small, 684M huge, 6158M other)
Other : 104M shared data
Free : 8696M free
Usable : 5810M usable (8696M free, 0M reclaimable, 2885M reserved by tasks)O comando #show tabela de utilização da npu fornecerá um bom resumo da utilização de cada núcleo associado ao processo iftask (em cada placa).
Note: O importante aqui é identificar se alguns núcleos são consistentemente mais utilizados que outros núcleos.
[local]UGP# show npu utilization table
-------iftask-------
lcore now 5min 15min
-------- ------ ------ ------
01/0/1 0% 0% 0%
01/0/2 0% 0% 0%
02/0/1 0% 0% 0%
02/0/2 2% 1% 0%
03/0/1 0% 0% 0%
03/0/2 0% 0% 0%
03/0/3 0% 0% 0%
04/0/1 0% 0% 0%
04/0/2 0% 0% 0%
04/0/3 0% 0% 0%
05/0/1 0% 0% 0%
05/0/2 0% 0% 0%
05/0/3 0% 0% 0%Comando #show npumgr usage information (comando oculto)
Esse comando fornece mais informações sobre cada núcleo de iftask e o que está consumindo CPU nesses núcleos.
Note: Os núcleos PMD estão tendo sua CPU consumida em PortRX, PortTX, KNI, Cipher. Os núcleos MCDMA estão tendo sua CPU consumida pelo MCDMA.
Os núcleos PMD e MCDMA devem ter uma carga razoavelmente uniforme.
Se não for o caso, poderá ser necessário algum ajuste (alocando mais/menos núcleos de MDMA, por exemplo).
******** show npumgr utilization information 3/0/0 *******
5-Sec Avg: lcore01| lcore02| lcore03| lcore04| lcore05| lcore06| lcore07| lcore08| lcore09| lcore10| lcore11| lcore12| lcore13| lcore14| lcore15| lcore16|
Idle: 31%| 37%| 32%| 35%| 41%| 48%| 47%| 38%| 57%| 56%| 55%| 56%| 46%| 56%| 54%| 52%|
PortRX: 28%| 26%| 27%| 26%| 0%| 0%| 0%| 0%| 12%| 14%| 11%| 11%| 0%| 0%| 0%| 0%|
PortTX: 5%| 5%| 6%| 5%| 8%| 8%| 8%| 14%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
KniRX: 6%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
Kni: 1%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
McdmaRX: 0%| 0%| 0%| 0%| 34%| 29%| 29%| 32%| 0%| 0%| 0%| 0%| 35%| 28%| 28%| 28%|
Mcdma: 0%| 0%| 0%| 0%| 11%| 7%| 4%| 6%| 0%| 0%| 0%| 0%| 14%| 7%| 7%| 7%|
Vnpu: 28%| 29%| 28%| 32%| 0%| 0%| 0%| 0%| 30%| 28%| 33%| 28%| 0%| 0%| 0%| 0%|
McdmaFlush: 0%| 0%| 0%| 0%| 6%| 8%| 12%| 10%| 0%| 0%| 0%| 0%| 6%| 10%| 11%| 14%|
Cipher: 1%| 2%| 6%| 2%| 0%| 0%| 0%| 0%| 1%| 2%| 1%| 5%| 0%| 0%| 0%| 0%|
rx kbits/sec: 728563| 736103| 647535| 626595| 811362| 698724| 717147| 799281| 617199| 595268| 623670| 633132| 819270| 672732| 790849| 719498|
rx frames/sec: 94409| 95586| 91107| 84997| 109526| 97466| 98557| 107690| 81122| 82076| 86959| 87960| 114114| 96198| 108108| 100259|
tx kbits/sec: 715038| 722181| 634227| 614221| 827124| 712740| 731329| 814782| 605373| 583318| 611001| 620328| 835692| 686575| 806395| 733924|
tx frames/sec: 94310| 95491| 90969| 84896| 109526| 97466| 98557| 107690| 81002| 81986| 86858| 87859| 114114| 96198| 108108| 100259|
5-Min Avg: ...
15-Min Avg: ...mais explicações:
A CPU é contabilizada da seguinte forma para um pacote que entra no processo iftask através da porta de serviço ou porta DI.
A pesquisa de Vnpu é a parte que mais consome CPU.
Se após a pesquisa de Vnpu:
- o pacote é enviado para o núcleo MCDMA, o tempo de CPU será considerado no McdmaRx do núcleo MCDMA relevante.
- o pacote é enviado para outro núcleo de iftask, o tempo de CPU será considerado na Vnpu
- o pacote é enviado no mesmo núcleo de iftask, o tempo de CPU será considerado em PortRx
-o pacote é enviado para fora no mesmo núcleo de iftask, o tempo de CPU será considerado em KniRx
O PortRx também inclui uma sobrecarga geral significativa para retirar pacotes das filas de recebimento e enviá-los/enfileirá-los para onde eles precisam ir
Comandos #show npumgr dinet usage pps, #show npumgr dinet usage bbps e #show tabela de utilização de porta
Eles fornecem informações sobre a carga nas portas DI e nas portas de serviços.
O desempenho real depende da alocação de NICs/CPUs e CPUs para iftask.
[local]UGP# show npumgr dinet utilization pps
------ Average DINet Port Utilization (in kpps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/0 Virtual Ethernet 0 0 0 0 0 0
2/0 Virtual Ethernet 0 0 0 0 0 0
3/0 Virtual Ethernet 0 0 0 0 0 0
4/0 Virtual Ethernet 0 0 0 0 0 0
5/0 Virtual Ethernet 0 0 0 0 0 0
[local]UGP# show npumgr dinet utilization bps
------ Average DINet Port Utilization (in mbps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/0 Virtual Ethernet 1 1 1 1 1 1
2/0 Virtual Ethernet 1 0 1 0 1 0
3/0 Virtual Ethernet 0 0 0 0 0 0
4/0 Virtual Ethernet 0 0 0 0 0 0
5/0 Virtual Ethernet 0 0 0 0 0 0
[local]UGP# show port utilization table
------ Average Port Utilization (in mbps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/1 Virtual Ethernet 0 0 0 0 0 0
2/1 Virtual Ethernet 0 0 0 0 0 0
3/10 Virtual Ethernet 0 0 0 0 0 0
3/11 Virtual Ethernet 0 0 0 0 0 0
4/10 Virtual Ethernet 0 0 0 0 0 0
4/11 Virtual Ethernet 0 0 0 0 0 0
5/10 Virtual Ethernet 0 0 0 0 0 0
5/11 Virtual Ethernet 0 0 0 0 0 0Comando #show cloud monitor di-network summary
Esse comando monitora a integridade da rede DI. As placas estão enviando batimentos cardíacos entre si, e a perda é monitorada. Em um sistema saudável, nenhuma perda é relatada.
[local]UGP# show cloud monitor di-network summary Card 3 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 4 Good 0.00% 0.00% 5 Good 0.00% 0.00% Card 4 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 3 Good 0.00% 0.00% 5 Good 0.00% 0.00% Card 5 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 3 Good 0.00% 0.00% 4 Good 0.00% 0.00%
Comando #show iftask stats summary
Com cargas de NPU mais altas, talvez seja possível que o tráfego esteja sendo descartado.
Para avaliar isso, o comando #show iftask stats summary pode ser usado.
Note: DESCARTES pode ser diferente de zero, todos os outros contadores devem permanecer como 0.
[local]VPC# show iftask stats summary Thursday January 18 16:01:29 IST 2018 ----------------------------------------------------------------------------------------------- Counter SF3 SF4 SF5 SF6 SF7 SF8 SF9 SF10 SF11 SF12 ___TOTAL___ ------------------------------------------------------------------------------------------------ svc_rx 32491861127 16545600654 37041906441 37466889835 32762859630 34931554543 38861410897 16025531220 33566817747 32823851780 312518283874 svc_tx 46024774071 14811663244 40316226774 39926898585 40803541378 48718868048 35252698559 1738016438 4249156512 40356388348 312198231957 di_rx 42307187425 14637310721 40072487209 39584697117 41150445596 44534022642 31867253533 1731310419 4401095653 40711142205 300996952520 di_tx 28420090751 16267050562 36423298668 36758561246 32731606974 30366650898 35201117980 16009902791 33536789041 32815316570 298530385481 __ALL_DROPS__ 1932492 252 17742 790473 11228 627018 844812 60402 0 460830 4745249 svc_tx_drops 0 0 0 0 0 0 0 0 0 0 0 di_rx_drops 0 1 0 0 49 113 579 30200 0 4888 35830 di_tx_drops 0 0 0 0 0 0 0 0 0 0 0 sw_rss_enq_drops 0 0 0 0 0 0 0 0 0 0 0 kni_thread_drops 0 0 0 0 0 0 0 0 0 0 0 kni_drops 0 1 0 0 0 0 124 30200 0 0 30325 mcdma_drops 0 0 0 168 80 194535 758500 0 0 11628 964911 mux_deliver_hop_drops 0 0 0 0 0 0 0 0 0 1019 1019 mux_deliver_drops 0 0 0 0 0 0 0 0 0 0 0 mux_xmit_failure_drops 0 3 0 0 0 0 7 2 0 0 12 mc_dma_thread_enq_drops 0 0 0 0 49 113 580 0 0 3457 4199 sw_tx_egress_enq_drops 1904329 0 0 787971 9004 429214 85022 0 0 429810 3645350 cpeth0_drops 0 0 0 0 0 0 0 0 0 0 0 mcdma_summary_drops 28163 247 17742 2334 2046 3043 0 0 0 10028 63603 fragmentation_err 0 0 0 0 0 0 0 0 0 0 0 reassembly_err 0 0 0 0 0 0 0 0 0 0 0 reassembly_ring_enq_err 0 0 0 0 0 0 0 0 0 0 0 __DISCARDS__ 20331090 9051092 23736055 23882896 23807520 24231716 24116576 8944291 22309474 20135799 20135799
SW-RSS e HW-RSS
O RSS é um recurso capaz de distribuir o tráfego de entrada proveniente de uma placa de rede através de vários processadores DPDK. Geralmente, a placa de rede suporta RSS em HW, permitindo que ele distribua tráfego em vários núcleos de iftask.
O processo iftask em Staros implementou uma versão de software do rss que pode ser habilitada se:
-nic não oferece suporte a HW rss (portanto todo o tráfego tx/rx chegará em uma única CPU iftask).
-nic não tem filas tx/rx suficientes (menos filas do que as CPUs tx/rx disponíveis atribuídas a iftask). Nesse caso, o SW-RSS (abrangente) permite a distribuição adequada em todos os núcleos de tarefas disponíveis atribuídos para rx/tx.
Esse recurso funciona apenas para o tráfego que chega através de portas de serviço. O tráfego DI não é levado em conta.
Existem 3 modos de configuração:
-no iftask sw-rss - sw-rss desabilitado. O sistema depende do HW RSS.
-iftask sw-rss abrangente - usando sw rss para todo o tráfego. O SW RSS pode ser executado junto com o HW RSS. Não há necessidade de desativar o RSS de HW. Mas o SW RSS será responsável pelo balanceamento de carga real do tráfego de SERVIÇO para os núcleos de tarefas if.
-iftask sw-rss suplementar - usando sw rss apenas para o tráfego que não é suportado por hw-rss (exemplo: tráfego MPLS)
Com RSS de HW e SW, é importante entender como o tráfego é dividido em vários processadores iftask/dpdk.
RSS DE HW: o hashing depende do hardware. A seguir, está um exemplo:
[root@host]# ethtool -n enp10s0f1
4 RX rings available
Total 0 rules
[root@host] # ethtool -n enp10s0f0 rx-flow-hash udp4
UDP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA
RSS de SW: A partir do Staros 21.6, o hashing da versão SW RSS se comporta da seguinte forma:
1. In case of IPV6
we only support L3( IP src/dst ) based hashing (same as the old behaviour).
2. In case of IPV4
a. For TCP we support IP src/dst + tcp ports src/dst
b. For UDP fragmented - only IP src/dst
c. For UDP non-fragmented not gtpu ( I.e. Port !=2152) ? IP src/dst + udp port src/dst
d. For UDP non-fragmented and gtpu ( I.e. Port ==2152) - IP src/dst + udp port src/dst + gtp tunnel id
e. Any other protocol ? we default back to IP src/dst
Importante: RSS para tráfego DI criptografado:
Na ausência de SW-RSS (suplementar/abrangente), pode ser possível que todo o tráfego de DI criptografado seja dividido em um único núcleo em iftask.
Isso fará com que esse núcleo tenha uma utilização consistentemente maior do que os outros.
Desde o CSCvi06080  , isso agora pode ser atenuado por este comando de configuração:
, isso agora pode ser atenuado por este comando de configuração:
iftask di-net-encrypt-rss
Após a integração do CSCvm41257 , esta opção será padrão.
Informações mais detalhadas sobre SW RSS:
A finalidade do sw-rss é fazer o balanceamento de carga dos núcleos PMD e evitar cenários de limitação de throughput em que um núcleo PMD atinge o seu máximo quando os outros têm capacidade disponível significativa.
Todos os pacotes de entrada de porta de serviço são retirados da placa de rede e recebem encapsulamento de MEH pelo núcleo PMD atendendo à fila Rx na qual chegam.
Neste ponto, iftask não sabe para onde enviar o pacote. Os pacotes devem ser processados pelo VNPU para determinar o destino interno. Praticamente todos esses pacotes passam por IOC/consulta de fluxo quando são entregues ao VNPU. As exceções estão relacionadas a descartes por motivos como vlan não configurada/desativada ou MAC de destino inválido (há também o cenário de encaminhamento L3, mas isso é incomum).
Se sw-rss não estiver configurado, o processamento de pesquisa de fluxo/IOC do VNPU ocorre no mesmo núcleo imediatamente após o encapsulamento MEH. Se o sw-rss estiver configurado, os pacotes serão enfileirados em um núcleo para processamento de VNPU com base em um hash. A operação de pesquisa de fluxo/IOC do VNPU é a função iftask mais cara; o sw-rss permite equilibrar essa carga de trabalho em todos os núcleos PMD.
Após a pesquisa de fluxo/IOC do VNPU, o pacote é transmitido para outro SF via transmissão DINet ou enfileirado para o aplicativo local via transferência MCDMA (novamente, há exceções, mas eu não acredito que elas sejam relevantes para esta discussão).
Os pacotes enviados para outro SF são diretamente enfileirados para o canal MCDMA apropriado na placa de destino após DINet Rx. Eles não exigem uma (segunda) aprovação de VNPU.
Filas TX/RX
Nos logs de iftask, podemos ver logs como:
Tue May 7 15:26:48 2019 PID:8188 APP: max rx queues supported 16 ...
Tue May 7 15:26:48 2019 PID:8188 APP: max tx queues supported 8 ...
Tue May 7 15:26:48 2019 PID:8188 APP: hw rx requested 2 ...
Tue May 7 15:26:48 2019 PID:8188 APP: hw tx requested tx 5
Isso está relacionado ao número suportado de filas rx e tx que o hardware real suporta versus o número de filas tx/rx que iftask solicita.
O que o iftask solicita está intimamente relacionado ao número de processadores alocados para o iftask.
Note: Cada motorista é diferente. Alguns hosts de consulta, alguns têm código fixo.
A contagem de hw tx request é o número de núcleos que o dpdk está usando. Normalmente, é um a mais do que o total de núcleos alocados para iftask, pois dpdk inclui o núcleo no qual o thread de controle/ipc é executado. Esse núcleo é compartilhado com boxer e agendado como uma cpu de uso geral (o segmento dpdk control/ipc não usa muita cpu).
A contagem solicitada de hw rx é geralmente o número de núcleos PMD.
Iftask aloca o mínimo (solicitado, máximo) para cada porta e os distribui pelos núcleos. O algoritmo de distribuição é um pouco complicado. O objetivo é distribuir a carga de trabalho da maneira mais uniforme possível entre todos os núcleos.
Iftask txbatch
Desde a Versão 21.9, o staros tem as seguintes opções de configuração de iftask padrão que são importantes para a criação de lotes (agregação de tráfego). Isso tem algum impacto negativo no desempenho quando o nó está sendo testado com um único (ou poucos) assinantes.
# iftask mcdmatxbatch burst size 32 # iftask mcdmatxbatch latency 200 # iftask txbatch burst size 32 # iftask txbatch latency 200
Mais explicações sobre isso estão em uma seção separada:
Bulkstats
O esquema Bulkstat é desenvolvido para desempenho QPVC-DI relacionado a iftask/dinet. Isso é útil para monitorar a dinet, as portas de serviço e a utilização da npu de uma perspectiva de desempenho/carga:
card schema iftask-dinet format EMS,IFTASKDINET,%date%,%time%,%dinet-rxpkts-curr%,%dinet-txpkts-curr%,%dinet-rxpkts-5minave%,%dinet-txpkts-5minave%,%dinet-rxpkts-15minave%,%dinet-txpkts-15minave%,%dinet-txdrops-curr%,%dinet-txdrops-5minave%,%dinet-txdrops-15minave%,%npuutil-now% file 2 port schema iftask-port format EMS,IFTASKPORT,%date%,%time%,%util-rxpkts-curr%,%util-txpkts-curr%,%util-rxpkts-5min%,%util-txpkts-5min%,%util-rxpkts-15min%,%util-txpkts-15min%,%util-txdrops-curr%,%util-txdrops-5min%,%util-txdrops-15min% file 3 card schema npu-util format EMS,NPUUTIL,%date%,%time%,%npuutil-now%,%npuutil-5minave%,%npuutil-15minave%,%npuutil-rxbytes-5secave%,%npuutil-txbytes-5secave%,%npuutil-rxbytes-5minave%,%npuutil-txbytes-5minave%,%npuutil-rxbytes-15minave%,%npuutil-txbytes-15minave%,%npuutil-rxpkts-5secave%,%npuutil-txpkts-5secave%,%npuutil-rxpkts-5minave%,%npuutil-txpkts-5minave%,%npuutil-rxpkts-15minave%,%npuutil-txpkts-15minave%
Histórico de revisões
| Revisão | Data de publicação | Comentários |
|---|---|---|
1.0 |
09-Jun-2018
|
Versão inicial |
Colaborado por engenheiros da Cisco
- Steven Loos
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)