Introdução
Este documento descreve os novos recursos de memória introduzidos nos servidores de geração UCS M7 e M8 e as etapas para compreender e solucionar problemas de erros de memória
Pré-requisitos
Requisitos
A Cisco recomenda que você tenha conhecimento destes tópicos.
- Entendimento básico do UCS.
- Entendimento básico da arquitetura de memória.
Componentes Utilizados
As informações neste documento são baseadas nestas versões de software e hardware:
- Servidores da família UCS M7 e M8
- UCS Manager
- Controlador de gerenciamento integrado da Cisco (CIMC)
- Modo gerenciado Cisco Intersight (IMM)
As informações neste documento foram criadas a partir de dispositivos em um ambiente de laboratório específico. Todos os dispositivos utilizados neste documento foram iniciados com uma configuração (padrão) inicial. Se a rede estiver ativa, certifique-se de que você entenda o impacto potencial de qualquer comando.
Informações de Apoio
Visão geral dos erros de memória
Os erros de memória estão entre os tipos mais comuns de erros em servidores modernos. Os erros são frequentemente descobertos quando é feita uma tentativa de ler um local de memória e o valor lido não corresponde ao valor gravado pela última vez.
Os erros de memória podem ser suaves ou difíceis. Alguns erros são corrigíveis, mas vários erros de software ou hardware simultâneos em um único acesso à memória podem ser incorrigíveis.
Recursos de memória RAS Cisco UCS M7/M8
Os servidores Cisco UCS M7 e M8 têm um conjunto robusto de recursos RAS, conforme detalhado aqui. Eles minimizam o impacto dos erros de memória no desempenho e no tempo de atividade do sistema.
ECC no nível do sistema
Todos os servidores Cisco UCS M7 usam módulos de memória com códigos ECC que podem corrigir qualquer erro confinado a um único chip DRAM x4 e detectar qualquer erro de bit duplo em até dois dispositivos. Isso agora é conhecido como ECC no nível do sistema, como nos servidores de geração mais antiga
.
Reserva de Virtual Lock-Step (VLS) / Adaptive Double Device Data Correction (ADDDC)
O sobressalente ADDC pode corrigir duas falhas sucessivas de DRAM se elas residirem na mesma região. Esse recurso rastreia erros corrigíveis e mapeia dinamicamente bits com falha copiando ("sobressalentes") o conteúdo em uma linha de cache "amigo". Esse mecanismo pode mitigar erros corrigíveis que, se não tratados, podem se tornar incorrigíveis. Esse recurso usa o VLS (virtual lockstep) para atribuir pares de colegas da linha do cache dentro do mesmo canal de memória no nível do banco da DRAM, usando VLS de banco, ou no nível do dispositivo da DRAM, usando VLS de classificação.
.
ECC no chip
O ECC no chip é um novo recurso no DDR5. Esse recurso é ativado por padrão. Todos os erros de bit único (hardware e software) são corrigidos pela DRAM antes que os dados sejam transmitidos ao host. No entanto, esses dados corrigidos não são gravados na DRAM. O ECS (Error Check and Scrub) é o recurso usado para depurar e corrigir erros de bit único na memória.
Verificação e Limpeza de Erros (ECS)
O ECS verifica se há erros em segundo plano, depurando cada DRAM morre periodicamente (a cada 24 horas), corrigindo-os gravando os dados de volta no array e fornecendo uma contagem dos erros encontrados durante a depuração. Este recurso é ativado por padrão.
PPR (Post Package Repair, Reparo pós-pacote)
O reparo pós-pacote é um recurso em que linhas sobressalentes são usadas para substituir uma célula ou linha inválida em um dispositivo DRAM.
Há três tipos:PPR suave(reconfigurável),PPR difícil(permanente), ePPR de tempo de execução.
- Os servidores Cisco UCS M7 com CPUs Intel suportam PPR "rígido". Esse é um reparo permanente e é realizado durante a reinicialização com base nos dados de erro coletados durante o tempo de execução anterior ou se forem encontrados erros de linha durante EMT.
- Os reparos normalmente ocorrem durante reinicializações quentes/frias ou ciclos CA.
- No UCS M8, há suporte para os três tipos de PPR, o PPR rígido é habilitado por padrão, enquanto o PPR de tempo de execução é desabilitado.
- O PPR em tempo de execução permite que os reparos ocorram durante a operação do sistema sem afetar o tempo de atividade.
- Se a PPR de tempo de execução e a PPR de tempo de execução estiverem ativadas, todos os recursos da PPR serão utilizados. Se a PPR de hardware estiver desativada, mas a PPR de tempo de execução estiver ativada, o sistema assumirá como padrão a PPR de software.
- O PPR está intimamente ligado a erros corrigíveis e cada erro corrigível gera um registro SEL quando o PPR está habilitado.
PMIC (Power Management Integrated Circuit, Circuito integrado de gerenciamento de energia)
O PMIC em um DIMM é um recurso importante dos módulos de memória DDR5. Essa integração transfere a função de gerenciamento de energia da placa-mãe para o próprio módulo de memória, oferecendo várias vantagens significativas.
Para a memória DDR5, a manipulação de erros de PMIC está habilitada.
- Falhas de PMIC geram registros de CÉLULA durante o tempo de execução e após a inicialização.
- Durante o treinamento de memória, se uma falha de PMIC for detectada em um canal de memória, o DIMM afetado será mapeado e o sistema continuará a inicializar com uma memória reduzida
Análise de log
Arquivos para verificar no suporte técnico
UCSM_X_TechSupport > sam_techsupportinfo fornece informações sobre o DIMM e a matriz de memória.
Suporte técnico para chassi/servidor
CIMCX_TechSupport\tmp\CICMX_TechSupport.txt -> Informações genéricas de suporte técnico sobre o servidor X.
CIMCX_TechSupport\obfl\obfl-log -> Os registros OBFL fornecem registros contínuos sobre o status e a inicialização do servidor X.
CIMCX_TechSupport\var\log\sel -> registros SEL para o servidor X.
Com base na plataforma/versão, navegue até os arquivos no pacote de suporte técnico.
RAS - Para ECS (verificação e depuração de erros) Local do erro de CEetc. coletados durante o tempo de execução em cada scrubbing
/nv/etc/BIOS/bt/DDR5_CISCO_ECS
AMT Auto Executa na próxima inicialização se o erro CE & UCE for encontrado em DIMMs
nv/etc/BIOS/bt/MrcOut
AMT_TEST_PATTERN:
ADV_MT_SAMSUNG
AMT_RESULT: APROVADO.
Erro de PMIC: /nv/etc/DIMM-PMIC.txt
O servidor M8 contém:-
nv/etc/BIOS/bt >MrcOut
Esses arquivos fornecem informações sobre a memória conforme vistos no nível do BIOS.
É possível fazer novamente referência cruzada das informações com as tabelas de relatórios de estados do DIMM.
Exemplo de servidor AMD :-
nv/etc/BIOS/bt >MrcOut
Contém:
- Versão do BIOS, data e hora da compilação
- Versões de firmware PSP
- Presença e status do DIMM (indica que o DIMM está presente ou não)
- Detalhes de configuração do DIMM.
2025/08/14 13:44:34
BIOS ID : C245M8.4.3.6b.0 Built 04/28/2025 14:15:22
=====================
PSP Firmware Versions
=====================
ABL Version: 100E8012
PSP: 0.29.0.9B
PFMW (SMU): 4.71.126.0
SEV: 1.1.37.28
PHY: 0.1.38.0
MPIO: 1.0.2D.C4
TF MPDMA: 0.47.3.0
PM MPDMA: 0.47.46.0
GMI: AB.1.27.0
RIB: 2.0.8.39
SEC: D.E.90.71
PMU: 0.0.90.4E
EMCR: 0.0.E0.4E
uCode B1: 0xA101154
DIMM Status:
|=======================|
| Memory | DIMM Status |
| Channel | |
|=======================|
| P1_A | 01 |
| P1_B | 01 |
| P1_C | 01 |
| P1_D | 01 |
| P1_E | 01 |
| P1_F | 00 |
| P1_G | 01 |
| P1_H | 01 |
| P1_I | 01 |
| P1_J | 01 |
| P1_K | 01 |
| P1_L | 00 |
| P2_A | 01 |
| P2_B | 01 |
| P2_C | 01 |
| P2_D | 01 |
| P2_E | 01 |
| P2_F | 00 |
| P2_G | 01 |
| P2_H | 01 |
| P2_I | 01 |
| P2_J | 01 |
| P2_K | 01 |
| P2_L | 00 |
|=======================|
DIMM Configuration:
=================================================
MbistTest = Disabled
MbistAggressor = Disabled
MbistPerBitSlaveDieReport = Enabled
DramTempControlledRefreshEn = Disabled
UserTimingMode = Disabled
UserTimingValue = Disabled
MemBusFreqLimit = Disabled
EnablePowerDown = Disabled
DramDoubleRefreshRate = Disabled
PmuTrainMode = 0x0000
EccSymbolSize = 0x0000
UEccRetry = Disabled
IgnoreSpdChecksum = Disabled
EnableBankGroupSwapAlt = Disabled
EnableBankGroupSwap = Disabled
DdrRouteBalancedTee = Disabled
OdtsCmdThrotEn = Disabled
OdtsCmdThrotCyc = Disabled
=================================================
Enhanced Memory Context Restore : APOB_SAVED
2025/08/14 13:44:34
Inventário de arquivos de saída MCA :-
Este arquivo contém informações sobre os registros MCA de todos os bancos .
(Sempre que um erro UCE for detectado)
--- START OF MCA FILE ---
Timestamp H:M:S 13:44:15 D:M:Y 14:8:2025
--- Note ---
The legacy MCA registers include:
MCA_CTL - Enables error reporting via machine check exception.
MCA_STATUS - Logs information associated with errors.
MCA_ADDR - Logs address information associated with errors. The use of AMD Secure Memory Encryption may change the information logged in the address register.
MCA_MISC0 - Logs miscellaneous information associated with errors.
The MCA Extension registers include:
MCA_CONFIG - Provide configuration capabilities for this MCA bank.
MCA_IPID - Provides information on the block associated with this MCA bank.
MCA_SYND - Logs physical location information associated with a logged error.
MCA_DESTATUS - Logs status information associated with a deferred error.
MCA_DEADDR - Logs address information associated with a deferred error.
MCA_MISC[1:4] - Provides additional threshold counters within an MCA bank.
MCA_TRANSSYND - Logs location information associated with a transparent error.
MCA_TRANSADDR - Logs address information associated with a transparent error.
LS - Load-Store Unit -> Bank 0
IF - Instruction Fetch Unit -> Bank 1
L2 - L2 Cache Unit -> Bank 2
DE - Decode Unit -> Bank 3
Empty/Unused bank -> Bank 4
EX - Execution Unit -> Bank 5
FP - Floating Point Unit -> Bank 6
L3 - L3 Cache Unit -> Bank 7 to 14
MP5 - Microprocessor5 Management Controller -> Bank 15
PB - Parameter Block -> Bank 16
PCS-GMI - GMI Controller -> Bank 17 to 18
KPX-GMI - High Speed Interface Unit(GMI) -> Bank 19 to 20
UMC - Unified Memory Controller -> Bank 21 to 22
CS - Coherent Station -> Bank 23 to 24
NBIO - NorthBridge IO Unit -> Bank 25
PCIE - PCIe Root port -> Bank 26 to 27
PIE - Power Management, Interrupts, Etc -> Bank 28
SMU - System Management Controller Unit -> Bank 29
PCS_XGMI - XGMI Controller -> Bank 30
KPX_SERDES - High Speed Interface Unit(XGMI)-> Bank 31
Empty/Unused bank -> Bank 32 to 63
Total BankNumber = 32
MC Global Capability Value = 120
MC Global Status Value = 0
MC Global Control Value = 0
Number of processor = 64
ProcNum BankNum Socket CCD CCX Core Thread MCA Bank Status MCA Bank Address MCA Configuration MCA IPID MSR VAL MCA SYND MSR VAL MC MISC0 MSR VAL MC MISC1 MSR VAL MC DESTAT MSR VAL MC DEADDR MSR VAL MC SYND1 MSR VAL MC SYND2 MSR VAL
Timestamp H:M:S 13:44:32 D:M:Y 14:8:2025
--- END OF MCA FILE ---
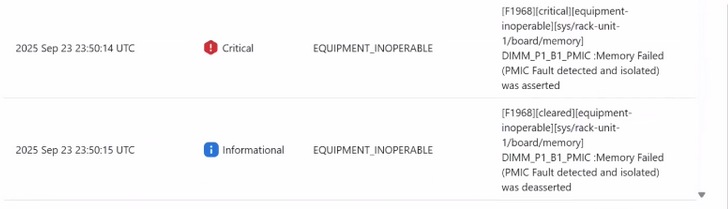
Exemplo de falha de PMIC em logs Sel :-
Sempre que houver uma falha de PMIC em tempo de execução no DIMM, o registro SEL será gerado conforme mostrado abaixo e o host será desligado.
- 2024-06-11 20:26:36 IST ◆Evento de software do sistema de aviso: O sensor de memória, Memory Failed (PMIC Fault detected and protected) foi confirmado, soquete DIMM 1, canal A, CPU 2. foi confirmado

O DIMM com falha é mapeado pelo BIOS na próxima inicialização do host . Vemos o SEL abaixo

Uma falha é gerada conforme mostrado abaixo.

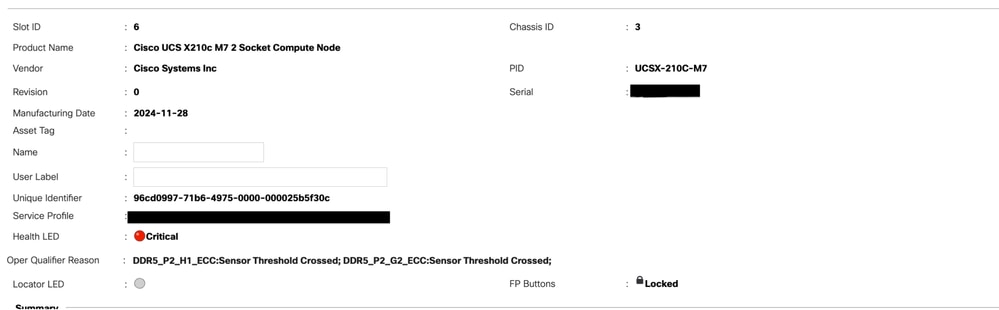
Troubleshooting de Falhas de RAS
Geralmente, você vê essas falhas no UCS Manager como um evento RAS.
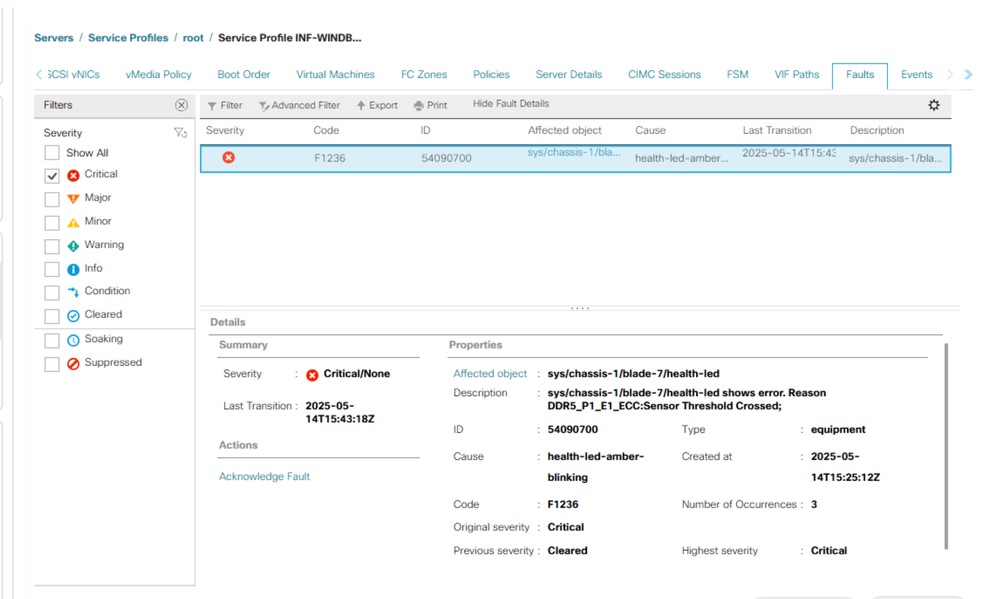
Comandos CLI do UCSM para redefinir todos os contadores de erro de memória:
UCS-A#scope server x/y
UCS-A /chassis/server # reset-all-memory-errors
UCS-A /chassi/servidor* # commit
Para limpar os dados de SPD:
Desligar o servidor
Em seguida, execute os seguintes comandos a partir da CLI do UCSM:
UCS-A# connect cimc x/y
UCS-A /chassis/server # reset-all-memory-errors
UCS-A /chassi/servidor* # commit
Erros notáveis
1. ID de bug da Cisco CSCwo62396
2. ID de bug da Cisco CSCwq33148
3. ID de bug da Cisco CSCwh73760
 Feedback
Feedback