Introdução
Este documento descreve como configurar o Splunk para analisar logs de tráfego DNS de um bucket de S3 gerenciado pela Cisco.
Overview
O Splunk é uma ferramenta para análise de log. Ele fornece uma interface eficiente para analisar grandes blocos de dados, como os logs fornecidos pelo Cisco Umbrella para o tráfego DNS. Este artigo descreve como:
- Configure o balde S3 gerenciado pela Cisco em seu painel.
- Verifique se os pré-requisitos da AWS Command Line Interface (AWS CLI) foram atendidos.
- Crie um trabalho cron para recuperar arquivos do bucket e armazená-los localmente no servidor.
- Configurar o Splunk para ler a partir de um diretório local.
Pré-requisitos
Crie um trabalho Cron no servidor Splunk
-
Crie um script de shell chamado pull-umbrella-logs.sh com o conteúdo fornecido, que seja executado em um trabalho cron agendado:
s3://cisco-managed-/1_2xxxxxxxxxxxxxxxxxa120c73a7c51fa6c61a4b6/dnslogs/ ).
-
Salve o script de shell e defina a permissão de execução. O script deve pertencer à raiz.
$ chmod u+x pull-umbrella-logs.sh
-
Execute o pull-umbrella-logs.sh script manualmente para confirmar se o processo de sincronização está funcionando. O preenchimento completo não é necessário; esta etapa confirma que as credenciais e a lógica do script estão corretas.
-
Adicione esta linha ao crontab do servidor Splunk:
*/5 * * * * root root /path/to/pull-umbrella-logs.sh &2>1 >/var/log/pull-umbrella-logs.txt
Não se esqueça de editar a linha para usar o caminho correto para o script. Isso executa uma sincronização a cada cinco minutos. O diretório de armazenamento S3 é atualizado a cada 10 minutos e os dados permanecem no armazenamento S3 por 30 dias. Isso mantém os dois em sincronia.
Configurar o 'Splunk' para ler a partir de um diretório local
- Em Splunk, navegue para Settings > Data Inputs > Files & Directories e selecione New.
 360002731126
360002731126
 360002731146
360002731146
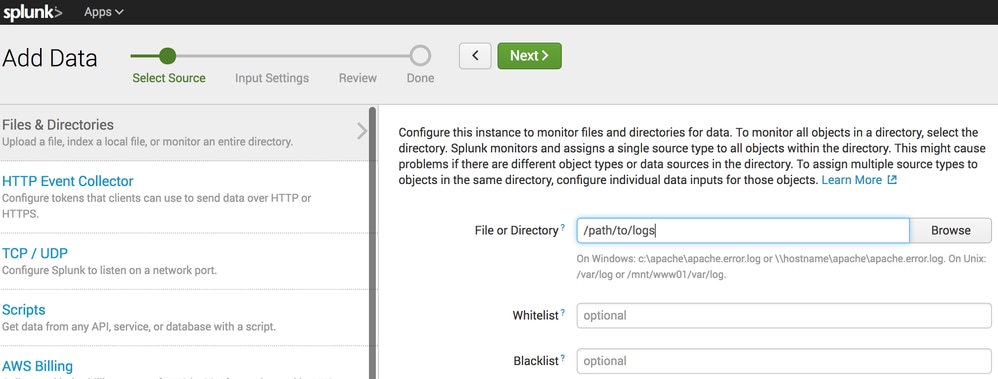
- No campo File or Diretory, especifique o diretório local onde a sincronização do S3 coloca os arquivos.
 360002731106
360002731106
- Clique em Avançar e conclua o assistente usando as configurações padrão.
Quando houver dados no diretório local e o Splunk estiver configurado, os dados poderão ser consultados e relatados no Splunk.

 Feedback
Feedback