Recovery Procedure for Ultra-M AutoVNF Cluster Failure - vEPC
Downloadopties
Inclusief taalgebruik
De documentatie van dit product is waar mogelijk geschreven met inclusief taalgebruik. Inclusief taalgebruik wordt in deze documentatie gedefinieerd als taal die geen discriminatie op basis van leeftijd, handicap, gender, etniciteit, seksuele oriëntatie, sociaaleconomische status of combinaties hiervan weerspiegelt. In deze documentatie kunnen uitzonderingen voorkomen vanwege bewoordingen die in de gebruikersinterfaces van de productsoftware zijn gecodeerd, die op het taalgebruik in de RFP-documentatie zijn gebaseerd of die worden gebruikt in een product van een externe partij waarnaar wordt verwezen. Lees meer over hoe Cisco gebruikmaakt van inclusief taalgebruik.
Over deze vertaling
Cisco heeft dit document vertaald via een combinatie van machine- en menselijke technologie om onze gebruikers wereldwijd ondersteuningscontent te bieden in hun eigen taal. Houd er rekening mee dat zelfs de beste machinevertaling niet net zo nauwkeurig is als die van een professionele vertaler. Cisco Systems, Inc. is niet aansprakelijk voor de nauwkeurigheid van deze vertalingen en raadt aan altijd het oorspronkelijke Engelstalige document (link) te raadplegen.
Inhoud
Inleiding
In dit document worden de stappen beschreven die nodig zijn om de Ultra Automation Services (UAS) of AutoVNF Cluster-fout te herstellen in een Ultra-M-configuratie waarin StarOS Virtual Network Functions (VNF’s) wordt gehost.
Achtergrondinformatie
Ultra-M is een voorverpakte en gevalideerde gevirtualiseerde mobiele packet-core-oplossing die is ontworpen om de implementatie van VNF's te vereenvoudigen.
Ultra-M oplossing bestaat uit de geciteerde types van Virtuele Machine (VM):
- Auto-IT
- Automatische implementatie
- UAS of AutoVNF
- Element Manager (EM)
- Elastische servicescontroller (ESC)
- Controlefunctie (CF)
- Sessiefunctie (SF)
De hoogwaardige architectuur van Ultra-M en de betrokken componenten worden in dit beeld weergegeven:
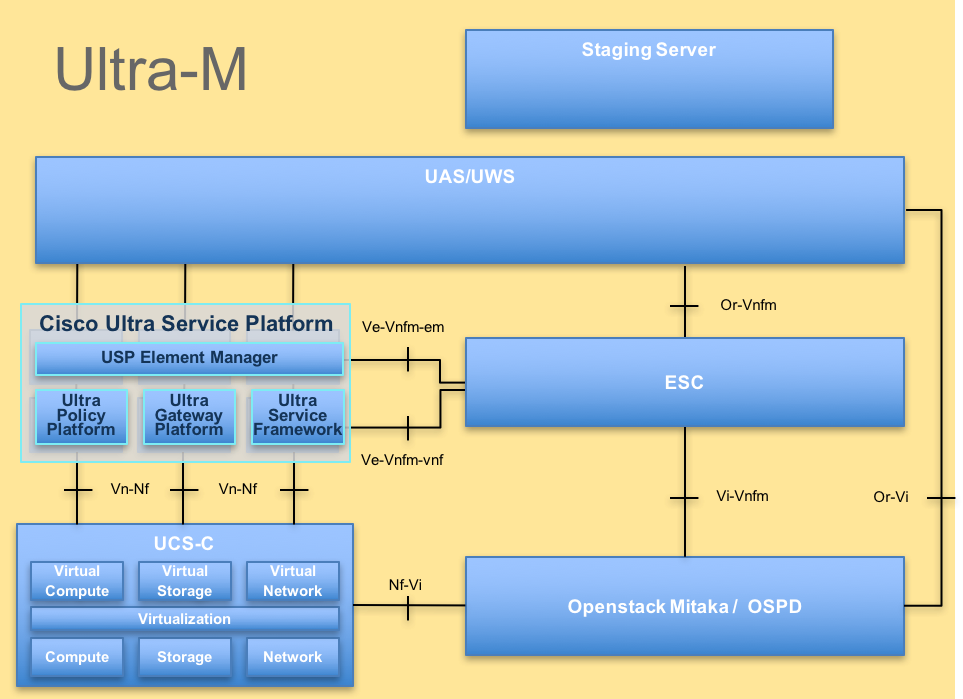 UltraM-architectuur
UltraM-architectuur
Dit document is bedoeld voor het Cisco-personeel dat bekend is met Cisco Ultra-M platform.
Opmerking: Ultra M 5.1.x release wordt overwogen om de procedures in dit document te definiëren.
Afkortingen
| VNF | Virtuele netwerkfunctie |
| CF | Bedieningsfunctie |
| SF | Servicefunctie |
| ESC | Elastic-servicecontroller |
| MOP | Werkwijze |
| OSD | Schijven voor objectopslag |
| HDD | Harde schijf |
| SSD | Solid state drive |
| VIM | Virtual Infrastructure Manager |
| VM | Virtuele machine |
| EM | Element Manager |
| UAS | Ultra-automatiseringsservices |
| UUID | Universele unieke IDentifier |
Werkstroom van de MoP
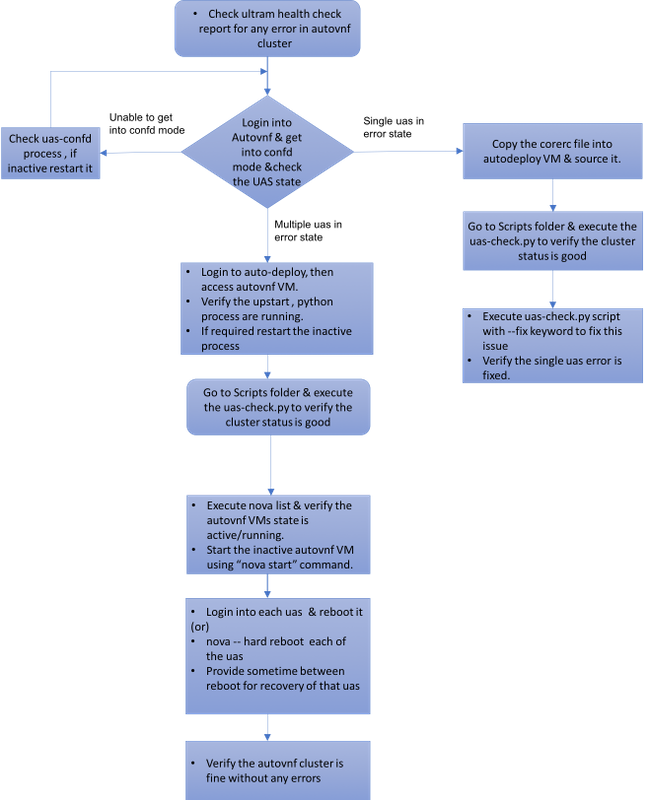
Zaak 1: Terugvordering van één enkele fout in UAS-cluster
Statuscontrole
1. Ultra-M Manager voert de gezondheidscontrole van de Ultra-M-knooppunt uit. Navigeer naar de rapporten /var/log/cisco/ultram-health/directory en begroet voor het UAS-rapport.
-
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | XXX | AutoVNF Cluster FAILED : Node: 172.16.180.12, Status: error, Role: NA
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
2. De verwachte status van het UAS-cluster is zoals afgebeeld, waarbij alle drie de UAS’s in leven zijn.
[stack@pod1-ospd ~]# ssh ubuntu@10.1.1.1
password:
ubuntu@autovnf1-uas:~$ ncs_cli -u admin -C
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.12 alive NA
Geen verbinding met Config Server wanneer u probeert verbinding met UAS te maken
1. In bepaalde gevallen kunt u geen verbinding maken met de confd-server.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ confd_cli -u admin -C
Failed to connect to server
2. Controleer de status van het UAS-confd proces.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ sudo initctl status uas-confd
uas-confd stop/waiting
3. Als de confd-server niet werkt, moet u de service opnieuw opstarten.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ sudo initctl start uas-confd
uas-confd start/running, process 7970
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 172.16.180.9 using ssh on autovnf1-uas-0
UAS herstellen van foutstatus
1. In het geval van een storing van een AutoVNF in het cluster, toont het UAS-cluster een van de UAS in de foutstatus .
[stack@pod1-ospd ~]# ssh ubuntu@10.1.1.1
password:
ubuntu@autovnf1-uas:~$ ncs_cli -u admin -C
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.12 alive error
2. Kopieer het corerc bestand (rc bestand van uw VNF) van /home/stack in OSPD-server naar AutoImplementeren en bron het.
3. Controleer de status van uw UAS/AutoVNF met behulp van uas-check.py script. autovnf1 is de naam AutoVNF.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts/uas-check.py auto-vnf autovnf1
2017-11-17 14:52:20,186 - INFO: Check of AutoVNF cluster started
2017-11-17 14:52:22,172 - INFO: Found 2 AutoVNF instance(s), 3 expected
2017-11-17 14:52:22,172 - INFO: Instance 'autovnf1-uas-2' is missing
2017-11-17 14:52:22,172 - INFO: Check completed, AutoVNF cluster has recoverable errors
4. Herstel de UAS met behulp van uas-check.py script en add —fix keyword.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts/uas-check.py auto-vnf autovnf1 --fix
2017-11-17 14:52:27,493 - INFO: Check of AutoVNF cluster started
2017-11-17 14:52:29,215 - INFO: Found 2 AutoVNF instance(s), 3 expected
2017-11-17 14:52:29,215 - INFO: Instance 'autovnf1-uas-2' is missing
2017-11-17 14:52:29,215 - INFO: Check completed, AutoVNF cluster has recoverable errors
2017-11-17 14:52:29,386 - INFO: Creating instance 'autovnf1-uas-2' and attaching volume 'autovnf1-uas-vol-2'
2017-11-17 14:52:47,600 - INFO: Created instance 'autovnf1-uas-2'
5. U zult zien dat de nieuw gemaakte UAS leeft en deel uitmaakt van het cluster.
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.13 alive NA
Geval 2. Alle drie UAS (AutoVNF) zijn in foutenstaat
1. Ultra-M Manager voert de health check van de Ultra-M knooppunt uit.
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | XXX | AutoVNF Cluster FAILED : Node: 172.16.180.12, Status: error, Role: NA,Node: 172.16.180.9, Status: error, Role: NA,Node: 172.16.180.10, Status: error, Role: NA
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
2. Zoals waargenomen in de output, Ultra-M manager meldt dat er een mislukking voor AutoVNF is en het toont aan dat alle drie UAS van de cluster in Foutenstaat zijn.
Controleer de UAS Health met Uas-check.py Script
1. Log in op de Auto-implementatie en controleer of u de AutoVNF UAS kunt gebruiken en de status krijgt.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts$ ./uas-check.py auto-vnf autovnf1 --os-tenant-name core
2017-12-05 11:41:09,834 - INFO: Check of AutoVNF cluster started
2017-12-05 11:41:11,342 - INFO: Found 3 ACTIVE AutoVNF instances
2017-12-05 11:41:11,343 - INFO: Check completed, AutoVNF cluster is fine
2. Van automatisch implementeren, Secure Shell (SSH) naar AutoVNF-knooppunt en overschakelen naar de confd-modus. Controleer de status met Show Uas.
ubuntu@auto-deploy-iso-590-uas-0:~$ ssh ubuntu@172.16.180.9
password:
autovnf1-uas-1#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
----------------------------
172.16.180.9 error NA
172.16.180.10 error NA
172.16.180.12 error NA
3. Aanbevolen wordt om de status te controleren bij alle drie de UAS-knooppunten.
Controleer de status van de VM's op OpenStack-niveau
Controleer de status van de AutoVNF VM's in de nova-lijst. Voer desgewenst nova start uit om de afsluitbare VM te starten.
[stack@pod1-ospd ultram-health]$ nova list | grep autovnf
| 83870eed-b4e9-47b3-976d-cc3eddecf866 | autovnf1-uas-0 | ACTIVE | - | Running | orchestr=172.16.180.12; mgmt=172.16.181.6
| 201d9ce5-538c-42f7-a46c-fc8cdef1eabf | autovnf1-uas-1 | ACTIVE | - | Running | orchestr=172.16.180.10; mgmt=172.16.181.5
| 6c6d25cd-21b6-42b9-87ff-286220faa2ff | autovnf1-uas-2 | ACTIVE | - | Running | orchestr=172.16.180.9; mgmt=172.16.181.13
De weergave van de zoökeeper controleren
1. Controleer de status van de zoökeeper om de modus als leider te verifiëren.
ubuntu@autovnf1-uas-0:/var/log/upstart$ /opt/cisco/usp/packages/zookeeper/current/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/cisco/usp/packages/zookeeper/current/bin/../conf/zoo.cfg
Mode: leader
2. De Zookeeper moet normaal omhoog zijn.
Probleemoplossing voor AutoVNF - Processen en taken
1. Identificeer de reden voor de Foutenstatus van de knooppunten. AutoVNF kan alleen worden uitgevoerd als er een aantal processen actief zijn zoals wordt aangegeven:
AutoVNF
uws-ae
uas-confd
cluster_manager
uas_manager
ubuntu@autovnf1-uas-0:~$ sudo initctl list | grep uas
uas-confd stop/waiting ====> this is not good, the uas-confd process is not running
uas_manager start/running, process 2143
root@autovnf1-uas-1:/home/ubuntu# sudo initctl list
....
uas-confd start/running, process 1780
....
autovnf start/running, process 1908
....
....
uws-ae start/running, process 1909
....
....
cluster_manager start/running, process 1827
....
.....
uas_manager start/running, process 1697
......
......
2. Controleer of deze python-processen actief zijn:
uas_manager.py
cluster_manager.py
usp_autovnf.py
root@autovnf1-uas-1:/home/ubuntu# ps -aef | grep pyth
root 1819 1697 0 Jun13 ? 00:00:50 python /opt/cisco/usp/uas/manager/uas_manager.py
root 1858 1827 0 Jun13 ? 00:09:21 python /opt/cisco/usp/uas/manager/cluster_manager.py
root 1908 1 0 Jun13 ? 00:01:00 python /opt/cisco/usp/uas/autovnf/usp_autovnf.py
root 25662 24750 0 13:16 pts/7 00:00:00 grep --color=auto pyth
3. Start het proces opnieuw op en controleer de status als een van de verwachte processen niet actief is. Als het nog steeds wordt weergegeven in de Foutenstatus, volg dan de procedure in de volgende paragraaf om dit probleem op te lossen.
Repareren voor meervoudig UAS in foutstatus
1. nova —hard reboot <naam van de VM> van OSPD, geef enige tijd voor herstel van deze VM voordat u doorgaat naar de volgende UAS. Doe dit op alle UAS VM's.
of
2.Log in op elk van de UAS en gebruik sudo reboot. Wacht op het herstel en ga dan door naar andere UAS VM's.
Controleer voor transactielogboeken:
/var/log/upstart/autovnf.log
show logs xxx | display xml
Hiermee wordt het probleem opgelost en wordt de UAS hersteld van de foutstatus.
1. Controleer hetzelfde met het gebruik van het ultra_health_check rapport.
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | :-) |
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
Bijgedragen door Cisco-engineers
- Partheban RajagopalCisco geavanceerde services
- Padmaraj RamanoudjamCisco geavanceerde services
 Feedback
FeedbackContact Cisco
- Een ondersteuningscase openen

- (Vereist een Cisco-servicecontract)