Inleiding
In dit document wordt beschreven hoe problemen met het gebruik van schijfruimte voor het bestandssysteem /dev/vda3 in RCM kunnen worden opgelost.
Voorwaarden
Vereisten
Cisco raadt u aan kennis te hebben van:
- StarOS Control and User Plane Separation (CUPS) systeemarchitectuur en -beheer.
- Basiscommando's voor Linux/Unix voor controle van bestandssysteem- en schijfgebruik.
Gebruikte componenten
Dit document is niet beperkt tot specifieke software- en hardware-versies.
De informatie in dit document is gebaseerd op de apparaten in een specifieke laboratoriumomgeving. Alle apparaten die in dit document worden beschreven, hadden een opgeschoonde (standaard)configuratie. Als uw netwerk live is, moet u zorgen dat u de potentiële impact van elke opdracht begrijpt.
Overzicht
In Cisco Ultra Packet Core-implementaties met Control and User Plane Separation (CUPS) speelt de Redundancy Control Manager (RCM) een cruciale rol bij de bediening en het beheer van besturingsvliegtuigen. Stabiel gebruik van het bestandssysteem op RCM-knooppunten is belangrijk voor een soepele werking van logboekregistratie, bewaking en abonneesessiebeheer.
Een hoge benutting van schijfruimte op het root-bestandssysteem (/dev/vda3) kan leiden tot systeeminstabiliteit, fouten in logboekschrijvingen of zelfs herstart van de service als deze niet is ingeschakeld. In dit artikel worden de analyse, stappen voor probleemoplossing en preventieve maatregelen beschreven om een hoog schijfgebruik in RCM-knooppunten aan te pakken.
Analyse en observatie
Tijdens de monitoring bleek dat de RCM-node 72% gebruik bereikte op zijn root-bestandssysteem.
Momentopname van schijfgebruik
df -kh
Filesystem Size Used Avail Use% Mounted on
tmpfs 6.3G 9.7M 6.3G 1% /run
/dev/vda3 39G 27G 11G 72% /
tmpfs 32G 4.0K 32G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 488M 48K 452M 1% /var/tmp
/dev/vda1 488M 76K 452M 1% /tmp
Bij nader onderzoek werd vastgesteld dat de logboekbestanden onder /var/log/journal/ aanzienlijk waren gegroeid. Logs gegenereerd tijdens juli alleen al goed voor ~3 GB aan ruimte.
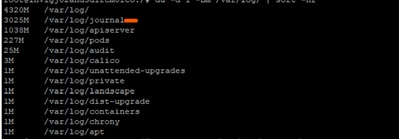
Problemen oplossen
Om het schijfgebruik onder controle te krijgen, zijn de vereiste stappen voor de implementatie van wijzigingen toegepast:
Stap 1: Oude logs opruimen met behulp van journalistiek vacuüm
Bewaar alleen de laatste 2 weken van logs:
sudo journalctl --vacuum-time=2weeks
Of beperk de grootte van het journaal (houd bijvoorbeeld slechts 600 MB bij):
sudo journalctl --vacuum-size=600M
Stap 2: Journaalretentie configureren voor toekomstige preventie
Configuratie journaal bewerken:
vi /etc/systemd/journald.conf
Parameter toevoegen/wijzigen:
MaxRetentionSec=2week
Configuratie toepassen:
sudo systemctl restart systemd-journald
Optionele stap 3: Opstartfout oplossen
Tijdens het opnieuw opstarten van de systeem-journald service in stap 2, kunt u een zorgwekkende fout krijgen:
Error : Failed to allocate directory watch: Too many open files
-
systemd-journald gebruikt inotify om logmappen te bekijken op wijzigingen.
-
Elk horloge of monitor die het instelt, telt mee voor bepaalde kernellimieten.
De huidige limieten die in de problematische RCM zijn gedefinieerd, zijn:
cat /proc/sys/fs/inotify/max_user_watches
501120
cat /proc/sys/fs/inotify/max_user_instances
128
ulimit -n
1024
Uit de verzamelde output:
- Max identificeren horloges: 501120
- Max. aantal instanties melden: 128
Limiet voor bestandsdescriptor openen voor tijdschriften: 1024
Een van de (of alle) grenswaarden voor de output had kunnen raken, wat tot de fout leidde. Dus verzamelden we de huidige gebruikte waarde en vergeleken ze met de verzamelde outputlimiet:
sudo lsof -p $(pidof systemd-journald) | wc -l
65
echo "Root inotify instances: $(sudo find /proc/*/fd -user root -type l -lname 'anon_inode:inotify' 2>/dev/null | wc -l) / $(cat /proc/sys/fs/inotify/max_user_instances)"
Root inotify instances: 126 / 128
Het lijkt erop dat de root al 126 van de 128 toegestane instanties gebruikt. Dat laat tijdschriften met bijna geen ruimte om een nieuwe intify instantie te maken wanneer we opnieuw starten.
Om de fout op te lossen: we kunnen de waarde max_user_instances verhogen en vervolgens de service opnieuw starten:
# Temporarily increase the limit (until next reboot)
echo 256 > /proc/sys/fs/inotify/max_user_instances
sudo systemctl restart systemd-journald
# Temporarily increase the limit (until next reboot)
echo 256 > /proc/sys/fs/inotify/max_user_instances
sudo systemctl restart systemd-journald
Verificatie na wijziging
Na het toepassen van de wijzigingen daalde het schijfgebruik naar 61%, waardoor de node naar de normale bedrijfstoestand werd hersteld.
df -kh
Filesystem Size Used Avail Use% Mounted on
tmpfs 6.3G 9.7M 6.3G 1% /run
/dev/vda3 39G 23G 15G 61% /
tmpfs 32G 4.0K 32G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 488M 48K 452M 1% /var/tmp
/dev/vda1 488M 76K 452M 1% /tmp
Aanbeveling
-
Implementeer dezelfde configuratie voor alle RCM-knooppunten in de implementatie om het schijfgebruik binnen veilige grenzen te houden.
-
Plaats de doel-RCM altijd in de stand-bymodus voordat u de wijzigingen uitvoert om impact op live verkeer te voorkomen.
-
Controleer periodiek het gebruik van /dev/vda3 en de groei van het journaal als onderdeel van proactieve systeemcontroles.
 Feedback
Feedback