Inleiding
In dit document worden de stappen beschreven voor het oplossen van geheugenfouten op UCS-servers.
Voorwaarden
Vereisten
Cisco raadt kennis van de volgende onderwerpen aan.
- Basiskennis van UCS.
- Basiskennis van geheugenarchitectuur.
Gebruikte componenten
De informatie in dit document is gebaseerd op de volgende software- en hardware-versies:
- Servers M5, M6, M7 en hoger van de UCS-reeks.
- UCS Manager
- Cisco Integrated Management Controller (CIMC)
- Cisco Intersight Managed Mode (IMM)
De informatie in dit document is gebaseerd op de apparaten in een specifieke laboratoriumomgeving. Alle apparaten die in dit document worden beschreven, hadden een opgeschoonde (standaard)configuratie. Als uw netwerk live is, moet u zorgen dat u de potentiële impact van elke opdracht begrijpt.
Achtergrondinformatie
Geheugenfouten
Geheugenfouten worden aangetroffen wanneer een poging wordt gedaan om een geheugenlocatie te lezen. De waarde die uit het geheugen wordt gelezen, komt niet overeen met de waarde die er zou moeten zijn. Deze fouten worden ingedeeld in twee typen:
1. Zachte fouten
Zachte fouten zijn van voorbijgaande aard en worden niet herhaald. Deze zijn tijdelijk en kunnen vaak worden gecorrigeerd door het lezen opnieuw te proberen of de geheugenlocatie te herschrijven.
2. Harde fouten
Permanente fysieke defecten veroorzaken deze. Het herschrijven van de geheugenlocatie en het opnieuw proberen van de leestoegang elimineert geen harde fout. Als gevolg hiervan is deze geheugenfout niet te corrigeren en moet het geheugen worden vervangen als de fout zich blijft herhalen.
Corrigeerbare fouten
Als fouten worden ontdekt en gecorrigeerd, worden ze als corrigeerbaar beschouwd. Dit kan worden bereikt door het lezen opnieuw te proberen of door de juiste geheugeninhoud te berekenen met behulp van Error Correction Code (ECC) -gegevens en de juiste gegevens terug in het geheugen te schrijven. Nadat een fout is gedetecteerd en gecorrigeerd, registreert de Cisco Integrated Management Controller (IMC) de gebeurtenis in het gebeurtenissenlogboek van het systeem.
Typisch, corrigeerbare fouten zijn het gevolg van zachte fouten. Als correcteerbare fouten gedurende een langere periode binnen dezelfde geheugenlocatie blijven bestaan, kan dit wijzen op een potentiële harde fout.
Adaptive Double Device Data Correction (ADDDC)
ADDDC Sparing kan twee opeenvolgende DRAM-fouten corrigeren als ze zich in dezelfde regio bevinden. ADDDC verplaatst gegevens dynamisch van falende bits naar reservegeheugen, waardoor herstelbare fouten niet meer kunnen worden gecorrigeerd. Er is een drempel van corrigeerbare ECC-fouten vereist om het mechanisme te activeren.
ADDDC helpt in sommige scenario's waar corrigeerbare ECC-fouten voorafgaan aan oncorrigeerbare ECC-fouten.
Postpakketreparatie (PPR)
Post Package Repair (PPR) kan defecte geheugengebieden binnen een DIMM permanent herstellen door gebruik te maken van redundante DRAM-rijen. Deze permanente reparatie in het veld zorgt voor snel herstel van harde fouten zonder dat de DIMM hoeft te worden vervangen. Om een reparatie uit te voeren, moet het systeem een ADDDC-gebeurtenis hebben en ten minste één reboot-cyclus doorlopen. Deze herstelactiviteit heeft geen invloed op de prestaties of het totale geheugen dat beschikbaar is voor het besturingssysteem.
PPR en ADDDC zijn standaard ingeschakeld, maar kunnen worden geconfigureerd. PPR vereist dat ook de modus ADDDC Sparing RAS is ingeschakeld. Als de RAS-instelling anders is dan ADDDC Sparing of Platform Default, is PPR niet operationeel. De enige ondersteunde PPR-modus is Hard PPR, wat betekent dat reparaties permanent zijn.
Partiële cache line sparing (PCLS)
Er is een foutpreventiemechanisme in de geheugencontroller. Het werkt door het identificeren van defecte kleine delen van gegevens in het geheugen. Deze defecte locaties worden vastgelegd in een speciale directory, samen met back-upgegevens die deze kunnen vervangen. Wanneer het geheugen wordt geopend, als er een fout in die defecte plekken, de controller maakt gebruik van de back-up gegevens uit de directory om ervoor te zorgen dat alles soepel verloopt.
Opmerking: de functies zijn beschikbaar afhankelijk van de CPU-architectuur en de firmwareversie die op de server wordt uitgevoerd. Zorg ervoor dat u in de laatste aanbevolen versie bent om de geheugenfouten beter aan te pakken.
Problemen met RAS oplossen
UCS Manager
Over het algemeen ziet u deze fouten in UCS Manager als een RAS-gebeurtenis.
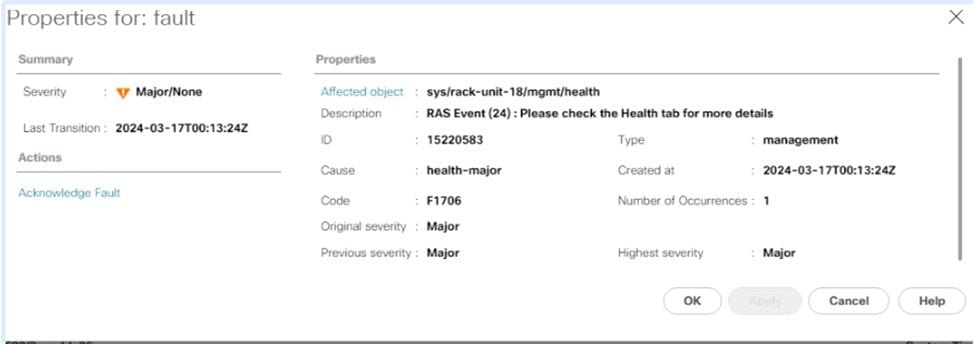
In de gezondheidssamenvatting vindt u meer informatie over de fout, ongeacht of PCLS of PPR is geactiveerd.
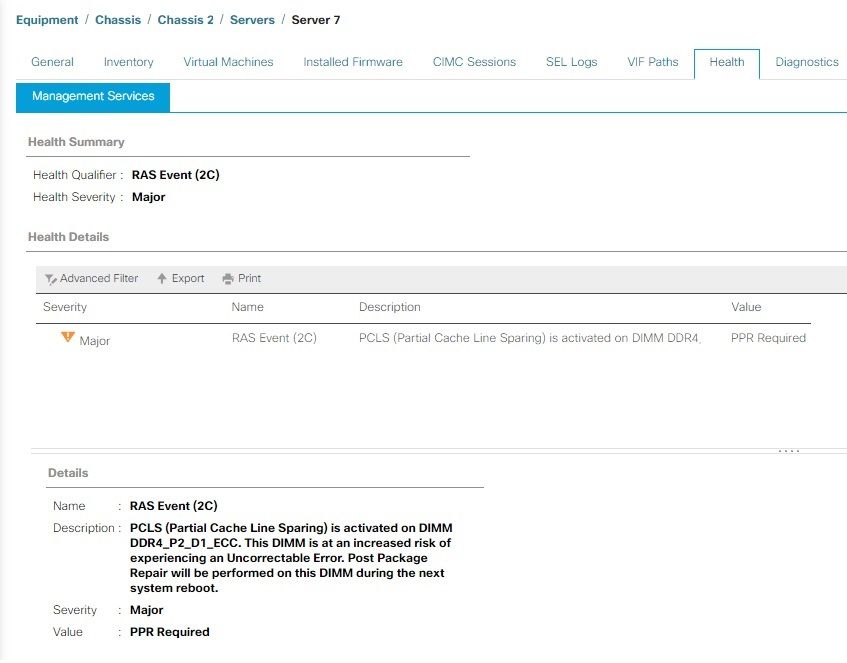
PCLS-voorbeeld
Op M6-servers en nieuwere servers hebt u de mogelijkheid om Partial Cache Line Sparing (PCLS) in te schakelen als een BIOS-optie, wat een mechanisme voor foutpreventie is. De server moet zo snel mogelijk opnieuw worden opgestart, zodat PPR de DIMM kan starten en repareren. Wanneer de server opnieuw is opgestart, controleert u of er voor dezelfde DIMM nog andere fouten in UCS Manager zijn opgetreden.
Zoals in de waarschuwing wordt vermeld, is het raadzaam de server zo snel mogelijk opnieuw op te starten, omdat er een risico bestaat dat er een onherstelbare fout optreedt en er daardoor een onverwachte downtime van de server optreedt.
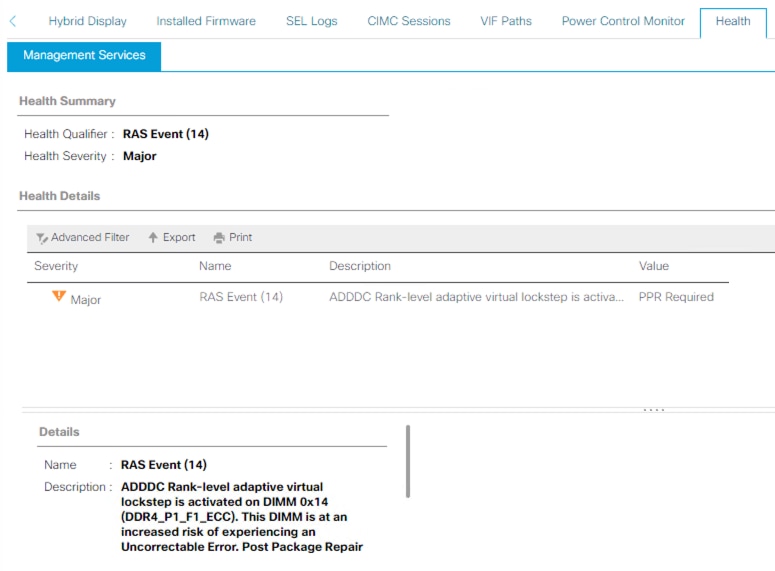
PPR-voorbeeld
De server heeft ADDDC en PPR ingeschakeld en er heeft zich een RAS-gebeurtenis voorgedaan. De fout suggereert dat PPR opnieuw moet worden opgestart om de DIMM te repareren. De server moet zo snel mogelijk opnieuw worden opgestart zodat PPR de DIMM kan starten en repareren.
Wanneer de server opnieuw is opgestart, controleert u of er voor dezelfde DIMM nog andere fouten in UCS Manager zijn opgetreden.
Zoals in de waarschuwing wordt vermeld, is het raadzaam de server zo snel mogelijk opnieuw op te starten, omdat er een risico bestaat dat er een onherstelbare fout optreedt en er daardoor een onverwachte downtime van de server optreedt.
Intersight Managed Mode
De server heeft ADDDC ingeschakeld en er heeft zich een BANK VLS-gebeurtenis voorgedaan, waardoor de fout is ontstaan die u ziet. In dit scenario is de volgende stap het zo snel mogelijk opnieuw opstarten van de server zodat PPR kan worden uitgevoerd.

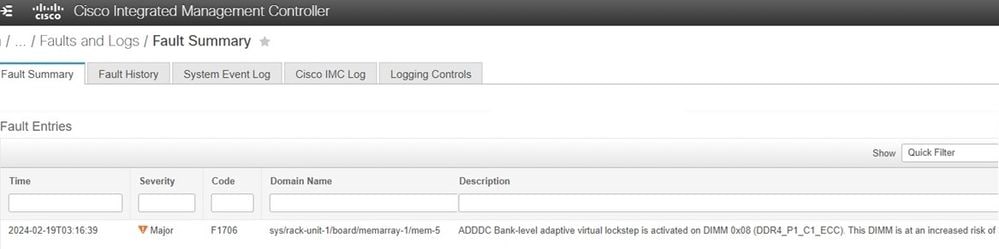
Cisco Integrated Management Controller (CIMC)
De fout wordt weergegeven bij gebruik van de Cisco Integrated Management Controller. Als de server ADDDC heeft en een VLS-gebeurtenis heeft plaatsgevonden, werkt dit zoals is ontworpen om onherstelbare fouten te voorkomen.
Stappen voor probleemoplossing
- Controleer of er geen andere DIMM-fouten aanwezig zijn, bijvoorbeeld Onherstelbare fout.
- Plan een onderhoudsvenster in.
- Plaats een host in de onderhoudsmodus en start de server opnieuw op om te proberen de DIMM permanent te repareren met Post Package Repair (PPR).
Stappen voor opnieuw opstarten via UCSM
Opmerking: u kunt de server ook opnieuw opstarten vanaf het besturingssysteem. In dit voorbeeld wordt de optie Opnieuw opstarten gebruikt vanuit de server-gebruikersinterface.
Navigeer naar de webinterface van UCS Manager.
Bladeserver
Ga naar Apparatuur > Chassis > Server X.
Geïntegreerde server
Navigeer naar Apparatuur > Rackmontages > Server X.
Klik op KVM-console.
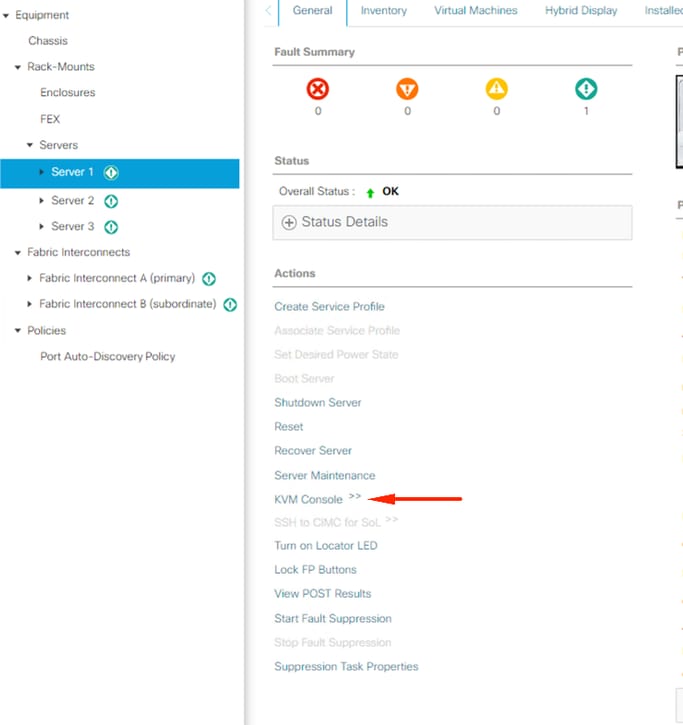
Klik in de KVM-vensters op serveracties, selecteer Reset en klik op OK.
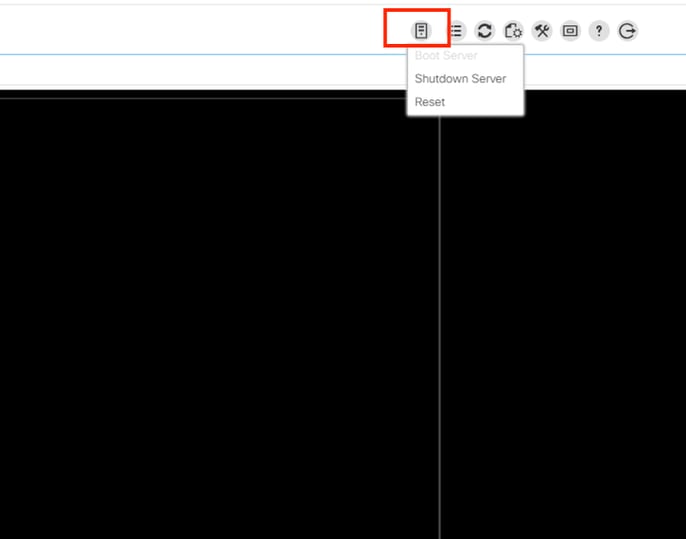
Controleer in de KVM het reboot-proces en zorg ervoor dat het besturingssysteem correct wordt opgestart.
Stappen voor opnieuw opstarten IMM
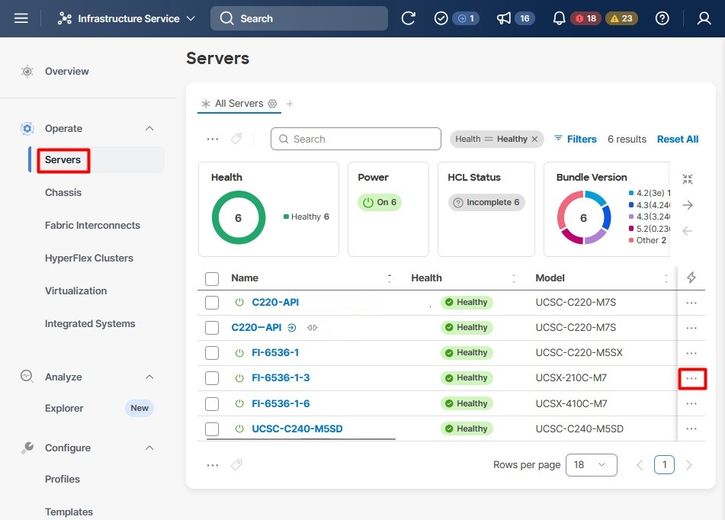
Navigeer naar het tabblad Servers, identificeer de server en klik op het menu Actie (drie punten).
Selecteer vervolgens het menu Aan/uit en vervolgens de optie Energiecyclus.
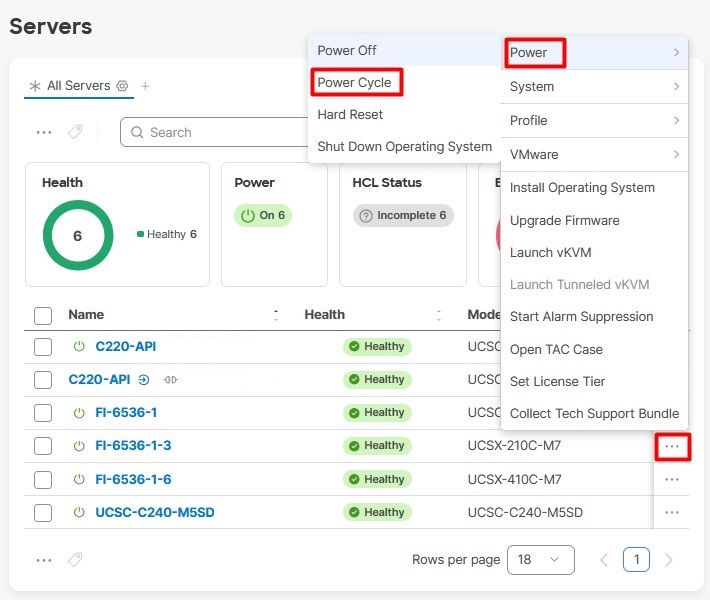
Klik op de knop Energiecyclus om de actie te bevestigen.
Valideer de voortgang onder het menu Verzoeken.
Stappen voor opnieuw opstarten van CIMC
Navigeer naar de optie Vermogen host en selecteer Energiecyclus.
Start de KVM om het reboot-proces te controleren en zorg ervoor dat het besturingssysteem correct wordt opgestart.
Monitor voor nieuwe fouten
Als er na het opnieuw opstarten geen fouten optreden, wat betekent dat er geen andere RAS-gebeurtenis of -fout met betrekking tot de DIMM is, is PPR succesvol en kan de server weer worden gebruikt.
Als zich nieuwe ADDDC-gebeurtenissen voordoen, herhaalt u het reboot-proces dat in de vorige stappen is beschreven om aanvullende permanente reparaties met PPR uit te voeren.
Als er na het opnieuw opstarten een fout optreedt die niet kan worden gecorrigeerd of als er een onbruikbare fout optreedt, geeft de fout aan dat een geheugen moet worden vervangen.
Opmerking: open een kwestie met Cisco TAC om de DIMM te vervangen als u een van deze fouten tegenkomt.
Fout in UCS-beheer: onherstelbaar geheugen
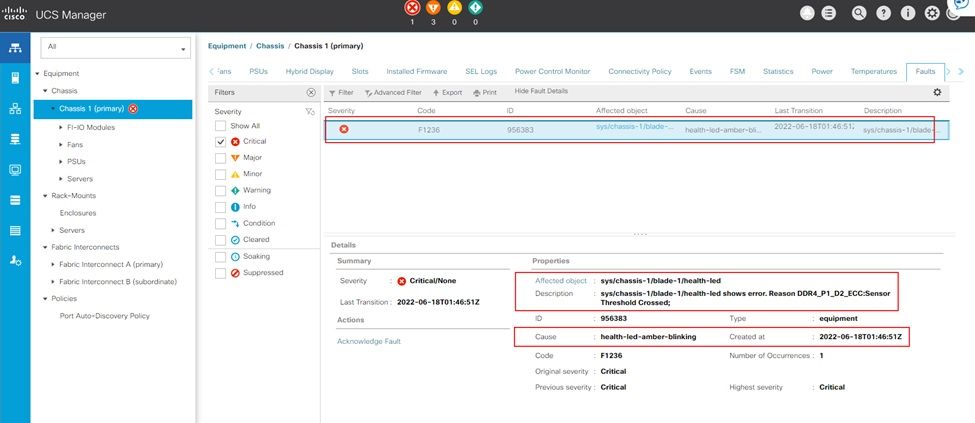
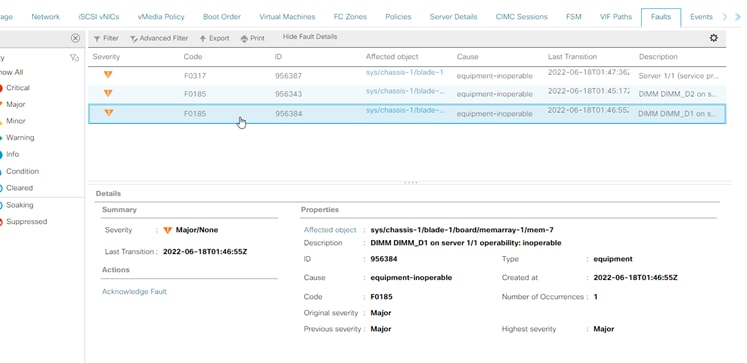
Fout bij oncorrigeerbaar IMM-geheugen
Onherstelbare fout. De fout geeft aan dat de DIMM een onherstelbare fout heeft en moet worden vervangen.

CIMC-fout met onherstelbaar geheugen
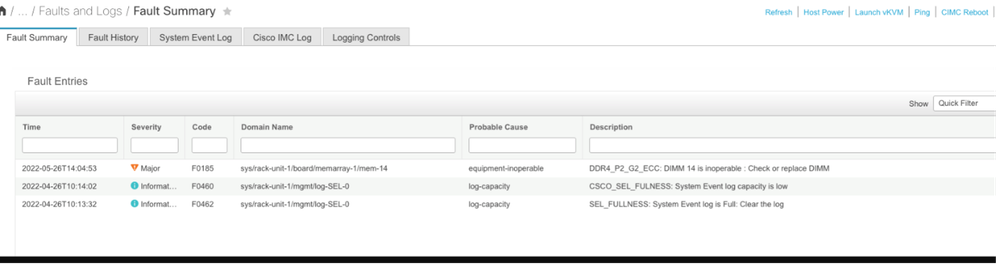
Gerelateerde informatie
 Feedback
Feedback