Een inleiding tot IGRP
Inhoud
Inleiding
Dit document introduceert Interior Gateway Routing Protocol (IGRP). Het heeft twee doelen. De eerste is om een introductie te vormen in de IGRP-technologie, voor degenen die geïnteresseerd zijn in het gebruik, de evaluatie en mogelijk de implementatie ervan. De andere is een bredere blootstelling te geven aan enkele interessante ideeën en concepten die zijn belichaamd in IGRP. Zie IGRP, Cisco IGRP-implementatie en IGRP-opdrachten configureren voor informatie over het configureren van IGRP.
Doelstellingen voor IGRP
Het IGRP-protocol staat een aantal gateways toe om hun routing te coördineren. De doelstellingen zijn:
-
Stabiele routing, zelfs in zeer grote of complexe netwerken. Geen routing loops moeten voorkomen, zelfs als transiënten.
-
Snelle respons op veranderingen in de netwerktopologie.
-
Lage overheadkosten. Dat wil zeggen dat IGRP zelf niet meer bandbreedte zou moeten gebruiken dan wat eigenlijk nodig is voor zijn taak.
-
Verspreiden van verkeer over meerdere parallelle routes wanneer ze ongeveer even gewenst zijn.
-
Rekening houden met foutenpercentages en het niveau van het verkeer op verschillende paden.
De huidige implementatie van IGRP verwerkt routing voor TCP/IP. Het basisontwerp is echter bedoeld om met verschillende protocollen om te kunnen gaan.
Geen enkel middel zal alle routeringsproblemen oplossen. Conventioneel is het routeringsprobleem verdeeld in verschillende stukken. Protocollen zoals IGRP worden "interne gatewayprotocollen" (IGP’s) genoemd. Ze zijn bedoeld voor gebruik binnen één stel netwerken, hetzij onder één beheer, hetzij onder nauw gecoördineerd beheer. Dergelijke netwerken worden aangesloten via "externe gatewayprotocollen" (EGP's). Een IGP is ontworpen om een goede mate van detail over netwerktopologie bij te houden. De prioriteit in het ontwerpen van een IGP wordt geplaatst op het produceren van optimale routes en het reageren snel op veranderingen. Een EGP is bedoeld om één systeem van netwerken te beschermen tegen fouten of opzettelijke verkeerde voorstelling door andere systemen, BGP is zo'n Exterior Gateway Protocol. Bij het ontwerpen van een EGP gaat het in de eerste plaats om stabiliteit en administratieve controles. Vaak is het genoeg voor een EGP om een redelijke route te produceren, in plaats van de optimale route.
IGRP heeft enige gelijkenissen met oudere protocollen zoals het Protocol van de Informatie van Xerox Routing, RIP van Berkeley, en Hello van Dave Mills. Het verschilt van deze protocollen hoofdzakelijk in wordt ontworpen voor grotere en complexere netwerken. Zie de sectie Vergelijking met RIP voor een meer gedetailleerde vergelijking met RIP, die het meest gebruikt van de oudere generatie van protocollen is.
Als deze oudere protocollen, is IGRP een afstands vectorprotocol. In zo een protocol wisselen gateways routinginformatie alleen uit met aangrenzende gateways. Deze routeringsinformatie bevat een samenvatting van informatie over de rest van het netwerk. Wiskundig kan worden aangetoond dat alle gateways samen een optimalisatieprobleem oplossen door wat neerkomt op een gedistribueerd algoritme. Elke gateway hoeft slechts een deel van het probleem op te lossen en hoeft slechts een deel van de totale gegevens te ontvangen.
Het belangrijkste alternatief voor IGRP is Enhanced IGRP (EIGRP) en een klasse van algoritmen die als SPF wordt bedoeld (snelste pad eerst). OSPF gebruikt dit concept. Meer informatie over OSPF vindt u in de OSPF Design Guide. OSPF Deze zijn gebaseerd op een overstromingstechniek, waar elke gateway wordt bijgewerkt over de status van elke interface op elke andere gateway. Elke gateway lost onafhankelijk het optimaliseringsprobleem op vanuit zijn standpunt met behulp van gegevens voor het gehele netwerk. Elke benadering heeft zijn voordelen. In bepaalde omstandigheden kan SPF sneller op veranderingen reageren. Om routing loops te voorkomen, moet IGRP nieuwe gegevens een paar minuten na bepaalde veranderingen negeren. Omdat SPF direct informatie van elke gateway heeft, kan het deze routinglijnen vermijden. Op die manier kan het onmiddellijk op nieuwe informatie reageren. SPF moet echter aanzienlijk meer gegevens verwerken dan IGRP, zowel in interne datastructuren als in berichten tussen gateways.
Het routingprobleem
IGRP is bedoeld voor gebruik in gateways die verscheidene netwerken verbinden. We gaan ervan uit dat de netwerken pakketgebaseerde technologie gebruiken. In feite fungeren de gateways als pakketgateways en switches. Wanneer een systeem dat met één netwerk is verbonden een pakket naar een systeem op een ander netwerk wil verzenden, richt het het pakket naar een gateway. Als de bestemming op één van de netwerken is die met de gateway zijn verbonden, zal de gateway het pakket aan de bestemming door:sturen. Als de bestemming verder weg is, zal de gateway het pakket aan een andere gateway door:sturen die dichter is aan de bestemming. Gateways gebruiken routingtabellen om hen te helpen beslissen wat ze met pakketten moeten doen. Hier is een eenvoudig voorbeeld dat lijst verplettert. (In de voorbeelden worden IP-adressen gebruikt die afkomstig zijn van de Rutgers University. Merk op dat het fundamentele routeringsprobleem voor andere protocollen eveneens gelijkaardig is, maar deze beschrijving zal veronderstellen dat IGRP voor het routing IP. wordt gebruikt)
Afbeelding 1
network gateway interface ------- ------- --------- 128.6.4 none ethernet 0 128.6.5 none ethernet 1 128.6.21 128.6.4.1 ethernet 0 128.121 128.6.5.4 ethernet 1 10 128.6.5.4 ethernet 1
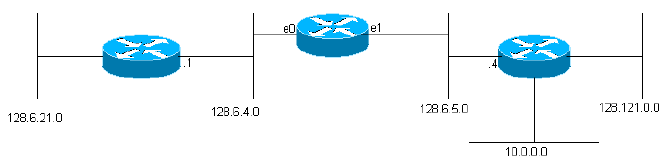
(Feitelijke IGRP-routingtabellen hebben aanvullende informatie voor elke gateway, zoals we zullen zien.) Deze gateway is verbonden met twee Ethernets, genaamd 0 en 1. Ze hebben IP-netwerknummers (eigenlijk subnetnummers) 128.6.4 en 128.6.5 gekregen. Dus pakketten die voor deze specifieke netwerken zijn gericht kunnen rechtstreeks naar de bestemming worden verzonden, eenvoudig door gebruik te maken van de juiste Ethernet-interface. Er zijn twee nabijgelegen gateways, 128.6.4.1 en 128.6.5.4. Pakketten voor andere netwerken dan 128.6.4 en 128.6.5 worden naar een van deze gateways doorgestuurd. De routeringstabel geeft aan welke gateway moet worden gebruikt voor welk netwerk. Bijvoorbeeld, pakketten die aan een gastheer op netwerk 10 worden gericht zouden aan gateway 128.6.5.4 moeten door:sturen. Men hoopt dat deze gateway dichter aan netwerk 10 is, d.w.z. dat de beste weg aan netwerk 10 door deze gateway gaat. Het primaire doel van IGRP is de gateways toe te staan om het verpletteren van lijsten als dit te bouwen en te handhaven.
Samenvatting van IGRP
Zoals hierboven vermeld, is IGRP een protocol dat gateways toestaat om hun routeringstabel op te bouwen door informatie met andere gateways te ruilen. Een gateway begint met vermeldingen voor alle netwerken die er direct mee verbonden zijn. Het krijgt informatie over andere netwerken door het ruilen van routingupdates met aangrenzende gateways. In het eenvoudigste geval, zal de gateway één weg vinden die de beste manier vertegenwoordigt om aan elk netwerk te krijgen. Een pad wordt gekarakteriseerd door de volgende gateway waarnaar pakketten moeten worden verzonden, de netwerkinterface die moet worden gebruikt en metrische informatie. Metrische informatie is een verzameling getallen die karakteriseren hoe goed het pad is. Dit stelt de gateway in staat om paden te vergelijken die hij van verschillende gateways heeft gehoord en te beslissen welke te gebruiken. Er zijn vaak gevallen waarin het verstandig is verkeer tussen twee of meer paden te splitsen. IGRP zal dit doen wanneer twee of meer wegen even goed zijn. De gebruiker kan deze ook configureren om verkeer te splitsen wanneer paden bijna even goed zijn. In dit geval zal meer verkeer langs de weg met betere metriek worden verzonden. De bedoeling is dat verkeer kan worden opgesplitst tussen een lijn van 9600 bps en een 19200 BPS-lijn, en de 19200 lijn zal ongeveer twee keer zoveel verkeer krijgen als de lijn van 9600 BPS.
De metriek die door IGRP worden gebruikt omvatten het volgende:
-
Topologische vertragingstijd
-
Bandbreedte van het smalste bandbreedtesegment van het pad
-
Kanaalbezetting van het pad
-
Betrouwbaarheid van het pad
De topologische vertragingstijd is de hoeveelheid tijd die het zou vergen om aan de bestemming langs die weg te komen, veronderstellend een leeggemaakt netwerk. Natuurlijk is er extra vertraging als het netwerk wordt geladen. De belasting wordt echter berekend aan de hand van de bezettingsgraad van het kanaal, niet door te proberen de werkelijke vertragingen te meten. De padbandbreedte is simpelweg de bandbreedte in bits per seconde van de langzaamste link in het pad. Kanaalbezetting geeft aan hoeveel van die bandbreedte momenteel in gebruik is. Het wordt gemeten en zal veranderen met de belasting. Betrouwbaarheid geeft het huidige foutenpercentage aan. Het is het deel van de pakketten dat onbeschadigd op de bestemming aankomt. Het wordt gemeten.
Hoewel zij niet als deel van metriek worden gebruikt, worden twee extra stukken informatie ermee overgegaan: hoptelling en MTU. De hoptelling is eenvoudig het aantal gateways dat een pakket door zal moeten gaan om aan de bestemming te krijgen. MTU is de maximale pakketgrootte die zonder fragmentatie langs het gehele pad kan worden verzonden. (Dat wil zeggen, het is het minimum van de MTU's van alle netwerken die bij het pad betrokken zijn.)
Op basis van de metrische informatie wordt één "samengestelde metriek" berekend voor het pad. De samengestelde metriek combineert het effect van de verschillende metrische componenten in een enkel getal dat de "goedheid" van dat pad weergeeft. Het is de samengestelde metriek die daadwerkelijk wordt gebruikt om te beslissen over het beste pad.
Periodiek zendt elke gateway zijn volledige routeringstabel uit (met enige censuur vanwege de gesplitste horizonregel) naar alle aangrenzende gateways. Wanneer een gateway deze uitzending van een andere gateway krijgt, vergelijkt het de lijst met zijn bestaande lijst. Alle nieuwe bestemmingen en paden worden toegevoegd aan de routertabel van de gateway. Paden in de uitzending worden vergeleken met bestaande paden. Als een nieuw pad beter is, kan het de bestaande vervangen. De informatie in de uitzending wordt ook gebruikt om kanaalbezetting en andere informatie over bestaande paden bij te werken. Deze algemene procedure is vergelijkbaar met de procedure die wordt gebruikt voor alle afstandvectorprotocollen. Het wordt in de wiskundige literatuur het Bellman-Ford-algoritme genoemd. Raadpleeg RFC 1058![]() voor een gedetailleerde ontwikkeling van de basisprocedure waarin RIP, een ouder afstandvectorprotocol, wordt beschreven.
voor een gedetailleerde ontwikkeling van de basisprocedure waarin RIP, een ouder afstandvectorprotocol, wordt beschreven.
In IGRP, wordt het algemene algoritme Bellman-Ford gewijzigd in drie kritieke aspecten. Eerst, in plaats van een eenvoudige metriek, wordt een vector van metriek gebruikt om wegen te karakteriseren. Ten tweede, in plaats van één pad te kiezen met de kleinste metriek, wordt verkeer verdeeld over meerdere paden, waarvan de metriek in een gespecificeerd bereik vallen. Ten derde, worden verscheidene eigenschappen geïntroduceerd om stabiliteit in situaties te verstrekken waar de topologie verandert.
Het beste pad wordt geselecteerd op basis van een samengestelde metriek:
[(K1 / Be) + (K2 * Dc)] r
Waar K1, K2 = constanten, Be = unloaded path bandbreedte x (1-kanaals bezetting), Dc = topologische vertraging, en r = betrouwbaarheid.
Het pad met de kleinste samengestelde metriek wordt het beste pad. Waar er meerdere paden naar dezelfde bestemming zijn, kan de gateway de pakketten via meer dan één pad verzenden. Dit wordt gedaan in overeenstemming met de samengestelde metriek voor elk gegevenspad. Als een pad bijvoorbeeld een samengestelde metriek van 1 heeft en een ander pad een samengestelde metriek van 3, zullen er drie keer zoveel pakketten worden verzonden over het gegevenspad met de samengestelde metriek van 1.
Er zijn twee voordelen aan het gebruiken van een vector van metrische informatie. Het eerste is dat het de mogelijkheid biedt om meerdere soorten diensten te ondersteunen uit dezelfde set gegevens. Het tweede voordeel is verbeterde nauwkeurigheid. Wanneer een enkele metriek wordt gebruikt, wordt deze normaliter behandeld als een vertraging. Elke link in het pad wordt toegevoegd aan de totale metriek. Als er een verbinding met een lage bandbreedte is, wordt het normaal vertegenwoordigd door een grote vertraging. Maar bandbreedte beperkingen cumuleren niet echt de manier waarop vertragingen dat doen. Door bandbreedte als een afzonderlijke component te behandelen, kan het correct worden behandeld. Op dezelfde manier kan de lading worden behandeld door een afzonderlijk kanaalbezettingsnummer.
IGRP verstrekt een systeem om computernetwerken onderling te verbinden die een algemene grafiektopologie met inbegrip van lijnen kunnen stabiel behandelen. Het systeem onderhoudt volledige padmetrieke informatie, dat wil zeggen dat het de padparameters kent van alle andere netwerken waarmee een gateway is verbonden. Het verkeer kan over parallelle paden worden verdeeld en er kunnen meerdere padparameters tegelijkertijd worden berekend over het gehele netwerk.
Vergelijking met het TNO
Deze sectie vergelijkt IGRP met RIP. Deze vergelijking is nuttig omdat RIP wijd voor doeleinden gelijkend op IGRP wordt gebruikt. Dat is echter niet helemaal eerlijk. RIP was niet bedoeld om alle zelfde doelstellingen te ontmoeten zoals IGRP. RIP was bedoeld voor gebruik in kleine netwerken met vrij eenvormige technologie. In dergelijke toepassingen is het over het algemeen adequaat.
Het meest fundamentele verschil tussen IGRP en RIP is de structuur van hun metriek. Helaas is dit geen wijziging die eenvoudigweg kan worden aangepast aan RIP. Het vereist de nieuwe algoritmen en de gegevensstructuren huidig in IGRP.
RIP gebruikt een eenvoudige metriek van de "hoptelling" om het netwerk te beschrijven. In tegenstelling tot IGRP, waar elke weg door een vertraging, bandbreedte, enz. wordt beschreven, in RIP wordt het beschreven door een aantal van 1 tot 15. Normaal wordt dit aantal gebruikt om te vertegenwoordigen hoeveel gateways gaat door de weg alvorens aan de bestemming te krijgen. Dit betekent dat er geen onderscheid wordt gemaakt tussen een langzame serielijn en een Ethernet. In sommige implementaties van RIP, is het mogelijk voor de systeembeheerder om te specificeren dat een bepaalde hop meer dan eens zou moeten worden geteld. Langzame netwerken kunnen door een grote hoptelling worden vertegenwoordigd. Maar omdat het maximum 15 is, kan dit niet veel worden gedaan. Als een Ethernet bijvoorbeeld wordt weergegeven door 1 en een 56Kb-lijn door 3, kunnen er maximaal 5 56Kb-lijnen in een pad zijn of wordt het maximum van 15 overschreden. Om de volledige reeks beschikbare netwerksnelheden te vertegenwoordigen en een groot netwerk mogelijk te maken, suggereren studies die worden uitgevoerd door Cisco dat een 24-bits metriek nodig is. Als de maximale metriek te klein is, krijgt de systeembeheerder een onaangename keuze: of hij kan geen onderscheid maken tussen snelle en langzame routes, of hij kan zijn hele netwerk niet aan zijn limiet aanpassen. In feite zijn een aantal nationale netwerken nu zo groot dat RIP ze niet kan verwerken, zelfs niet als elke hop maar één keer wordt geteld. RIP kan eenvoudig niet voor dergelijke netwerken worden gebruikt.
De voor de hand liggende reactie zou zijn om RIP te wijzigen om een grotere metriek toe te staan. Helaas, dit zal niet werken. Net als alle afstands vectorprotocollen heeft RIP het probleem van "tellen tot oneindigheid". Dit wordt meer in detail beschreven in RFC 1058![]() . Wanneer de topologie verandert, zullen de onechte routes worden geïntroduceerd. De metriek die aan deze onechte routes worden geassocieerd stijgt langzaam tot zij 15 bereiken, op welk punt de routes worden verwijderd. 15 is een klein genoeg maximum dat dit proces vrij snel zal convergeren, ervan uitgaande dat de geactiveerde updates worden gebruikt. Als RIP werd gewijzigd om een metriek met 24 bits toe te staan, zouden de lijnen lang genoeg voor metriek om tot 2**24 worden geteld voortduren. Dit is niet toelaatbaar. IGRP heeft functies die zijn ontworpen om te voorkomen dat ongewenste routes worden geïntroduceerd. Deze worden hieronder besproken in paragraaf 5.2. Het is niet praktisch om complexe netwerken te behandelen zonder dergelijke functies te introduceren of te veranderen in een protocol zoals SFP.
. Wanneer de topologie verandert, zullen de onechte routes worden geïntroduceerd. De metriek die aan deze onechte routes worden geassocieerd stijgt langzaam tot zij 15 bereiken, op welk punt de routes worden verwijderd. 15 is een klein genoeg maximum dat dit proces vrij snel zal convergeren, ervan uitgaande dat de geactiveerde updates worden gebruikt. Als RIP werd gewijzigd om een metriek met 24 bits toe te staan, zouden de lijnen lang genoeg voor metriek om tot 2**24 worden geteld voortduren. Dit is niet toelaatbaar. IGRP heeft functies die zijn ontworpen om te voorkomen dat ongewenste routes worden geïntroduceerd. Deze worden hieronder besproken in paragraaf 5.2. Het is niet praktisch om complexe netwerken te behandelen zonder dergelijke functies te introduceren of te veranderen in een protocol zoals SFP.
IGRP doet een beetje meer dan eenvoudig de waaier van toelaatbare metriek verhoogt. Het herstructureert de metriek om vertraging, bandbreedte, betrouwbaarheid, en lading te beschrijven. Het is mogelijk om dergelijke overwegingen in een enkele metriek zoals RIP’s weer te geven, maar de benadering van IGRP is potentieel nauwkeuriger. Bijvoorbeeld, met één enkele metriek, zullen verscheidene opeenvolgende snelle verbindingen om aan één enkele langzame schijnen gelijkwaardig te zijn. Dit kan het geval zijn bij interactief verkeer, waarbij vertraging de voornaamste zorg is. Voor de overdracht van bulkgegevens is de voornaamste zorg echter de bandbreedte, en het bij elkaar optellen van statistieken is daar niet de juiste aanpak. IGRP behandelt vertraging en bandbreedte afzonderlijk, die vertragingen, maar het nemen van het minimum van de bandbreedte verzamelen. Het is niet gemakkelijk om te zien hoe de gevolgen van betrouwbaarheid en lading in een single-component metriek op te nemen.
Naar mijn mening is één van de grote voordelen van IGRP gemak van configuratie. Het kan direct hoeveelheden vertegenwoordigen die fysieke betekenis hebben. Dit betekent dat het automatisch kan worden ingesteld, op basis van interfacetype, lijnsnelheid, etc. Met een single-component metriek, zal de metriek waarschijnlijk moeten worden "gekookt" om gevolgen van verscheidene verschillende dingen te integreren.
Andere innovaties zijn meer een zaak van algoritmen en datastructuren dan van het routingprotocol. IGRP specificeert bijvoorbeeld algoritmen en gegevensstructuren die het splitsen van verkeer tussen verschillende routes ondersteunen. Het is zeker mogelijk om een implementatie van RIP te ontwerpen die dit doet. Zodra routing echter opnieuw wordt geïmplementeerd, is er geen reden om aan RIP te blijven vasthouden.
Tot nu toe heb ik "generieke IGRP" beschreven, een technologie die routing voor elk netwerkprotocol zou kunnen ondersteunen. In deze sectie is het echter de moeite waard om iets meer te vermelden over de specifieke TCP/IP-implementatie. Dat is de uitvoering die met het RIP zal worden vergeleken.
De updateberichten van RIP bevatten eenvoudig momentopnamen van de routeringstabel. Dat wil zeggen, ze hebben een aantal bestemmingen en metrische waarden, en verder weinig. De IP implementatie van IGRP heeft extra structuur. Eerst wordt het updatebericht geïdentificeerd door een "autonoom systeemnummer." Deze terminologie komt voort uit de Arpanet-traditie en heeft daar een specifieke betekenis. Voor de meeste netwerken betekent dit echter dat u meerdere verschillende routeringssystemen op hetzelfde netwerk kunt gebruiken. Dit is nuttig voor plaatsen waar de netwerken van verscheidene organisaties samenkomen. Elke organisatie kan zijn eigen routing onderhouden. Omdat elke update wordt gelabeld, kunnen gateways worden geconfigureerd om alleen aandacht te besteden aan de juiste. Bepaalde gateways zijn geconfigureerd om updates van verschillende autonome systemen te ontvangen. Zij geven op gecontroleerde wijze informatie door tussen de systemen. Merk op dat dit geen volledige oplossing aan problemen van het verpletteren van veiligheid is. Elke gateway kan worden geconfigureerd om te luisteren naar updates van elk autonoom systeem. Het is echter nog steeds een zeer nuttig hulpmiddel bij het implementeren van routeringsbeleid waar een redelijke mate van vertrouwen tussen de netwerkbeheerders is.
De tweede structurele eigenschap over IGRP update berichten beïnvloedt de manier de standaardroutes door IGRP worden behandeld. De meeste routeringsprotocollen hebben een concept standaardroute. Het is vaak niet praktisch voor het routeren van updates om van elk netwerk in de wereld een lijst te maken. Typisch heeft een reeks gateways gedetailleerde routinginformatie nodig voor netwerken binnen hun organisatie. Al het verkeer voor bestemmingen buiten hun organisatie kan worden verzonden naar een van een paar grensgateways. Die grensgateways kunnen meer volledige informatie hebben. De route naar de beste grensgateway is een "standaardroute". Het is een gebrek in de zin dat het wordt gebruikt om aan om het even welke bestemming te krijgen die niet specifiek vermeld in de interne routeringsupdates is. RIP, en sommige andere routeringsprotocollen, circuleren informatie over de standaardroute alsof het een echt netwerk was. IGRP kiest een andere benadering. In plaats van een enkele nepvermelding voor de standaardroute, maakt IGRP het mogelijk dat echte netwerken worden gemarkeerd als kandidaten voor een standaard. Dit wordt geïmplementeerd door informatie over die netwerken in een speciale buitensectie van het updatebericht te plaatsen. Men kan echter net zo goed denken dat het een beetje aanzet dat met deze netwerken is verbonden. Periodiek scant IGRP alle kandidaat standaardroutes en kiest met de laagste metriek als daadwerkelijke standaardroute.
Mogelijk is deze benadering van defaults iets flexibeler dan de benadering die door de meeste RIP-implementaties wordt gevolgd. Meestal kunnen RIP-gateways worden ingesteld om een standaardroute met een bepaalde gespecificeerde metriek te genereren. Het is de bedoeling dat dit gebeurt bij grensgateways.
Gedetailleerde beschrijving
Deze sectie verstrekt een gedetailleerde beschrijving van IGRP.
Algemene beschrijving
Wanneer een gateway eerst wordt aangezet, wordt zijn routeringstabel geïnitialiseerd. Dit kan worden gedaan door een operator vanaf een console-terminal, of door informatie te lezen uit configuratiebestanden. Een beschrijving van elk netwerk dat met de gateway is verbonden, wordt verstrekt, met inbegrip van de topologische vertraging langs de verbinding (bijvoorbeeld, hoe lang het één enkel beetje duurt om de verbinding over te steken) en de bandbreedte van de verbinding.
Afbeelding 2
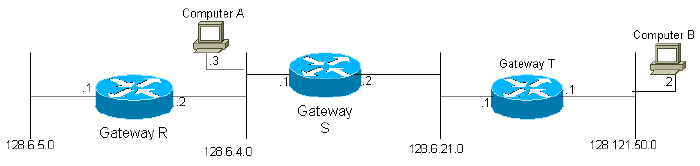
In het bovenstaande diagram wordt gateway S bijvoorbeeld verteld dat hij via de bijbehorende interfaces is verbonden met netwerken 2 en 3. Aldus, aanvankelijk, weet gateway 2 slechts dat het om het even welke bestemmingscomputer in netwerken 2 en 3 kan bereiken. Alle gateways zijn geprogrammeerd om periodiek aan hun naburige gateways de informatie over te brengen die zij met, evenals informatie die van andere gateways is verzameld. Gateway S zou dus updates ontvangen van gateways R en T en leren dat het computers in netwerk 1 via gateway R en computers in netwerk 4 via gateway T kan bereiken. Aangezien gateway S zijn volledige routeringstabel verstuurt, zal gateway T in de volgende cyclus leren dat hij naar netwerk 1 via gateway S kan komen. Het is gemakkelijk om te zien dat informatie over elk netwerk in het systeem uiteindelijk elke gateway in het systeem zal bereiken, op voorwaarde dat het netwerk volledig is aangesloten.
Afbeelding 3
________ Network 1
|
gw A --nw2-- gw C
| / |
| / |
nw3 nw4 nw5
| / |
| / |
gw B gw D
_|_____________|____ Network 6
Elke gateway berekent een samengestelde metriek om de wenselijkheid van de gegevenswegen aan bestemmingscomputers te bepalen. Bijvoorbeeld, in het diagram hierboven, voor een bestemming in Netwerk 6, zou gateway A (gw A) metrische functies voor twee wegen, via gateways B en C berekenen. Merk op dat de wegen eenvoudig door de volgende hop worden bepaald. Er zijn eigenlijk drie mogelijke routes van A naar Network 6:
-
Direct naar B
-
Naar C en vervolgens naar B
-
Naar C en vervolgens naar D
Gateway A hoeft echter niet te kiezen tussen de twee routes waarbij C betrokken is. De routeringstabel in A heeft één enkele ingang die het pad naar C weergeeft. De metriek van de route is de beste manier om van C naar de eindbestemming te komen. Als A een pakket naar C verstuurt, is het aan C om te beslissen of B of D wordt gebruikt.
Vergelijking 1
De samengestelde metrische functie die voor elk gegevenspad wordt berekend, wordt hieronder weergegeven:
[(K1 / Be) + (K2 * Dc)] r
Waar r = fractionele betrouwbaarheid (% van de transmissies die succesvol ontvangen worden bij de volgende hop), Dc = samengestelde vertraging, Be = effectieve bandbreedte: ledige bandbreedte x (1-kanaals bezetting), en K1 en K2 = constanten.
Vergelijking 2
In principe kan de samengestelde vertraging, Dc, als volgt worden bepaald:
Dc = Ds + Dcir + Dt
waarbij Ds = schakelvertraging, Dcir = circuitvertraging (voortplantingsvertraging van 1 bit), en DT = transmissievertraging (geen-belastingsvertraging voor een 1500-bits bericht).
In de praktijk wordt echter voor elk type netwerktechnologie een standaardvertragingscijfer gebruikt. Er zal bijvoorbeeld een standaard vertragingsgetal zijn voor Ethernet en voor seriële lijnen op elke specifieke bitsnelheid.
Hier is een voorbeeld van hoe gateway A’s routeringstabel zou kunnen kijken in het geval van Network 6 diagram hierboven. (Merk op dat de individuele componenten van de metrische vector niet worden getoond, voor eenvoud.)
Routing Table Voorbeeld:
| Netwerk | Interface | Volgende gateway | Metrisch |
|---|---|---|---|
| 1 | NL 1 | None | Direct verbonden |
| 2 | NL 2 | None | Direct verbonden |
| 3 | 3 NL | None | Direct verbonden |
| 4 | NL 2 | C | 1270 |
| 3 NL | B | 1180 | |
| 5 | NL 2 | C | 1270 |
| 3 NL | B | 2130 | |
| 6 | NL 2 | C | 2040 |
| 3 NL | B | 1180 |
Het basisproces van het opbouwen van een routeringstabel door het uitwisselen van informatie met buren wordt beschreven door het Bellman-Ford algoritme. Het algoritme is gebruikt in eerdere protocollen zoals RIP (RFC 1058). Om complexere netwerken te verwerken, voegt IGRP drie functies toe aan het standaard Bellman-Ford-algoritme:
-
In plaats van een eenvoudige metriek, wordt een vector van metriek gebruikt om wegen te karakteriseren. Een enkele samengestelde metriek kan worden berekend van deze vector volgens vergelijking 1, hierboven. Het gebruik van een vector stelt de gateway in staat verschillende soorten diensten aan te passen door verschillende coëfficiënten in vergelijking 1 te gebruiken. Het maakt ook een nauwkeuriger weergave van de kenmerken van het netwerk mogelijk dan een enkele metriek.
-
In plaats van één pad te kiezen met de kleinste metriek, wordt verkeer verdeeld over meerdere paden, waarbij metriek binnen een gespecificeerd bereik vallen. Dit maakt het mogelijk om meerdere routes parallel te gebruiken, waardoor er een grotere effectieve bandbreedte beschikbaar is dan elke route. Een variant V wordt door de netwerkbeheerder ingesteld. Alle paden met minimale samengestelde metrische M worden behouden. Bovendien worden alle paden waarvan de metriek minder is dan V x M behouden. Het verkeer wordt over meerdere paden verdeeld in omgekeerde verhouding tot de samengestelde metriek.
-
Er zijn enkele problemen met dit concept van variantie. Het is moeilijk om met strategieën te komen die gebruik maken van variantiewaarden groter dan 1, en niet ook tot pakketten het van een lus voorzien. In Cisco release 8.2 wordt de variantiefunctie niet geïmplementeerd. (Ik weet niet zeker in welke release de functie is verwijderd.) Hierdoor wordt de variantie permanent op 1 ingesteld.
-
Verscheidene eigenschappen worden geïntroduceerd om stabiliteit in situaties te verstrekken waar de topologie verandert. Deze functies zijn bedoeld om routing loops en "tellen naar oneindigheid te voorkomen," die eerdere pogingen om Ford-type algoritmen te gebruiken voor dit type toepassing hebben gekenmerkt. De primaire stabiliteitskenmerken zijn "holddowns", "getriggerde updates", "split horizon" en "vergiftiging". Deze zullen hieronder nader worden besproken.
Verkeersplijting (punt 2) brengt een vrij subtiel gevaar met zich mee. De variantie V is ontworpen om gateways in staat te stellen parallelle paden met verschillende snelheden te gebruiken. Er kan bijvoorbeeld een 9600 BPS-lijn parallel lopen met een 19200 BPS-lijn, voor redundantie. Als variantie V 1 is, wordt alleen het beste pad gebruikt. Dus de 9600 BPS-lijn zal niet worden gebruikt als de 19200 BPS-lijn een redelijke betrouwbaarheid heeft. (Als echter meerdere paden hetzelfde zijn, wordt de lading onderling gedeeld.) Door de variantie te verhogen kunnen we toestaan dat verkeer wordt opgesplitst in de beste route en andere routes die bijna net zo goed zijn. Met voldoende variantie wordt het verkeer over de twee lijnen verdeeld. Het gevaar is dat met een groot genoeg verschil, paden worden toegestaan die niet alleen langzamer zijn, maar in feite "in de verkeerde richting". Er moet dus een extra regel komen om te voorkomen dat er verkeer "stroomopwaarts" wordt verstuurd: Geen verkeer wordt verzonden langs paden waarvan de externe samengestelde metriek (de samengestelde metriek berekend bij de volgende hop) groter is dan de samengestelde metriek berekend bij de gateway. In het algemeen worden systeembeheerders aangemoedigd om de variantie niet boven 1 in te stellen, behalve in specifieke situaties waarin parallelle paden moeten worden gebruikt. In dit geval wordt de variantie zorgvuldig ingesteld om de "juiste" resultaten te leveren.
IGRP is bedoeld om meerdere "typen service" en meerdere protocollen te verwerken. Het type service is een specificatie in een gegevenspakket die de manier waarop paden moeten worden geëvalueerd, wijzigt. Met het TCP/IP-protocol kan het pakket bijvoorbeeld het relatieve belang van hoge bandbreedte, lage vertraging of hoge betrouwbaarheid specificeren. Over het algemeen, zullen de interactieve toepassingen lage vertraging specificeren, terwijl de bulkoverdrachttoepassingen hoge bandbreedte zullen specificeren. Deze voorschriften bepalen de relatieve waarden van K1 en K2 die geschikt zijn voor gebruik in Eq. 1. Elke combinatie van specificaties in het te ondersteunen pakket wordt een "type service" genoemd. Voor elk type dienst moet een reeks parameters K1 en K2 worden gekozen. Er wordt een routeringstabel bijgehouden voor elk type service. Dit gebeurt omdat paden zijn geselecteerd en geordend volgens de samengestelde metriek die wordt gedefinieerd door Eq. 1. Dit is verschillend voor elk type dienst. De informatie van elk van deze routeringstabellen wordt gecombineerd om de routing update berichten te produceren die door de gateways worden uitgewisseld, zoals beschreven in afbeelding 7.
Stabiliteitsfuncties
In deze paragraaf worden holddowns, geactiveerde updates, gesplitste horizon en vergiftiging beschreven. Deze eigenschappen worden ontworpen om gateways te verhinderen verkeerde routes op te nemen. Zoals beschreven in RFC 1058![]() , kan dit gebeuren wanneer een route onbruikbaar wordt als gevolg van een storing in een gateway of een netwerk. In principe detecteren de aangrenzende gateways defecten. Zij verzenden dan het verpletteren van updates die de oude route onbruikbaar tonen. Het is echter mogelijk dat updates bepaalde delen van het netwerk niet bereiken of vertraging oplopen bij het bereiken van bepaalde gateways. Een toegangspoort die nog steeds gelooft dat de oude route goed is, kan die informatie verder verspreiden en zo de mislukte route opnieuw invoeren in het systeem. Uiteindelijk zal deze informatie zich verspreiden door het netwerk en terugkomen naar de gateway die het opnieuw injecteerde. Het resultaat is een cirkelvormige route.
, kan dit gebeuren wanneer een route onbruikbaar wordt als gevolg van een storing in een gateway of een netwerk. In principe detecteren de aangrenzende gateways defecten. Zij verzenden dan het verpletteren van updates die de oude route onbruikbaar tonen. Het is echter mogelijk dat updates bepaalde delen van het netwerk niet bereiken of vertraging oplopen bij het bereiken van bepaalde gateways. Een toegangspoort die nog steeds gelooft dat de oude route goed is, kan die informatie verder verspreiden en zo de mislukte route opnieuw invoeren in het systeem. Uiteindelijk zal deze informatie zich verspreiden door het netwerk en terugkomen naar de gateway die het opnieuw injecteerde. Het resultaat is een cirkelvormige route.
In feite is er sprake van enige overtolligheid tussen de tegenmaatregelen. In beginsel zouden bewaartermijnen en getriggerde updates moeten volstaan om verkeerde routes in de eerste plaats te voorkomen. In de praktijk kunnen verschillende soorten communicatiestoringen echter tot gevolg hebben dat ze onvoldoende zijn. Splitsen horizon en routevergiftiging zijn bedoeld om het routeren van lijnen in elk geval te verhinderen.
Normaal worden er regelmatig nieuwe routingtabellen naar aangrenzende gateways verzonden (elke 90 seconden standaard, hoewel dit kan worden aangepast door de systeembeheerder). Een teweeggebrachte update is een nieuwe routeringstabel die onmiddellijk, in antwoord op één of andere verandering wordt verzonden. De belangrijkste verandering is het verwijderen van een route. Dit kan gebeuren omdat een onderbreking is verlopen (waarschijnlijk is een naburige gateway of lijn gedaald), of omdat een updatebericht van de volgende gateway in de weg aantoont dat de weg niet meer bruikbaar is. Wanneer een gateway G ontdekt dat een route niet meer bruikbaar is, brengt het onmiddellijk een update teweeg. Deze update toont aan dat deze route onbruikbaar is. Overweeg wat gebeurt wanneer deze update de naburige gateways bereikt. Als de route van de buur terug naar G wijst, moet de buur de route verwijderen. Dit zorgt ervoor dat de buurman een update, enz. activeert. Aldus zal een mislukking een golf updateberichten teweegbrengen. Deze golf zal zich door dat gedeelte van het netwerk verspreiden waarin de routes door de ontbroken gateway of het netwerk gingen.
De teweeggebrachte updates zouden volstaan als wij konden waarborgen dat de golf van updates elke aangewezen gateway onmiddellijk bereikte. Er zijn echter twee problemen. Eerst, kunnen de pakketten die het updatebericht bevatten worden gelaten vallen of door één of andere verbinding in het netwerk worden bedorven. Ten tweede, de getriggerde updates gebeuren niet onmiddellijk. Het is mogelijk dat een gateway die nog niet de teweeggebrachte update heeft gekregen een regelmatige update op enkel de verkeerde tijd zal uitgeven, veroorzakend de slechte route om in een buur worden opnieuw opgenomen die reeds de teweeggebrachte update had gekregen. Holddowns zijn ontworpen om deze problemen te omzeilen. De holddown regel zegt dat wanneer een route wordt verwijderd, geen nieuwe route voor de zelfde bestemming voor wat periode zal worden goedgekeurd. Dit geeft de geactiveerde updates tijd om alle andere gateways te bereiken, zodat we er zeker van kunnen zijn dat elke nieuwe routes die we krijgen niet slechts een poort zijn die de oude weer invoegt. De holddown periode moet lang genoeg zijn om voor de golf van teweeggebrachte updates toe te staan om door het netwerk te gaan. Bovendien moet het een paar reguliere uitzendcycli bevatten, om gedropte pakketten te behandelen. Overweeg wat gebeurt als één van de teweeggebrachte updates wordt gelaten vallen of bedorven. De gateway die die update uitgaf zal een andere update bij de volgende regelmatige update uitgeven. Dit zal de golf van teweeggebrachte updates bij buren opnieuw beginnen die de aanvankelijke golf misten.
De combinatie van getriggerde updates en holddowns zou moeten volstaan om van verlopen routes af te komen en te voorkomen dat ze opnieuw worden ingevoerd. Toch zijn sommige extra voorzorgsmaatregelen sowieso de moeite waard. Ze maken zeer verlieslijdende netwerken mogelijk, en netwerken die verdeeld zijn geraakt. De extra voorzorgsmaatregelen die door IGRP worden gevraagd zijn gespleten horizon en routevergiftiging. De gespleten horizon komt voort uit de waarneming dat het nooit zinvol is om een route terug te sturen in de richting waar deze vandaan kwam. Overweeg de volgende situatie:
network 1 network 2
-------------X-----------------X
gateway A gateway B
Gateway A zal B vertellen dat het een route naar netwerk 1 heeft. Wanneer B updates naar A verzendt, is er nooit enige reden voor het om netwerk 1 te noemen. Aangezien A dichter bij 1 is, is er geen reden voor het om te overwegen via B te gaan. De gesplitste horizonregel zegt dat er een afzonderlijk updatebericht moet worden gegenereerd voor elke buur (eigenlijk elk naburig netwerk). De update voor een bepaalde buur moet routes weglaten die naar die buur wijzen. Deze regel voorkomt lusjes tussen aangrenzende gateways. Stel bijvoorbeeld dat de interface van A met netwerk 1 mislukt. Zonder de gespleten horizonregel, zou B A vertellen dat het aan 1 kan krijgen. Aangezien het niet langer een echte route heeft, zou A die route kunnen oppikken. In dit geval zouden A en B beide routes naar 1 hebben. Maar A zou naar B en B naar A wijzen. Natuurlijk moeten getriggerde updates en holddowns voorkomen dat dit gebeurt. Maar omdat er geen reden is om informatie terug te sturen naar waar het vandaan komt, is split horizon toch de moeite waard. Naast zijn rol in het voorkomen van lussen, houdt gesplitste horizon de grootte van update berichten.
Splitshorizon zou lijnen tussen aangrenzende gateways moeten verhinderen. Routevergiftiging is bedoeld om grotere loops te doorbreken. De regel is dat wanneer een update de metriek toont voor een bestaande route om voldoende gestegen te zijn, er een lijn is. De route zou moeten worden verwijderd en in holddown worden gezet. Momenteel is de regel dat een route wordt verwijderd als de samengestelde metriek meer dan een factor van 1.1 stijgt. Het is niet veilig voor enkel om het even welke verhoging van samengestelde metriek om verwijdering van de route teweeg te brengen, aangezien de kleine metrische veranderingen wegens veranderingen in kanaalbezetting of betrouwbaarheid kunnen voorkomen. De factor 1,1 is dus gewoon een heuristische factor. De exacte waarde is niet cruciaal. We verwachten dat deze regel alleen nodig is om zeer grote mazen te breken, omdat kleine door getriggerde updates en holddowns zullen worden voorkomen.
Uitschakelen van blokkeringen
Vanaf release 8.2 biedt de code van Cisco een optie om holddowns uit te schakelen. Het nadeel van holddowns is dat ze de adoptie van een nieuwe route vertragen als een oude route mislukt. Met standaardparameters, kan het verscheidene minuten vergen alvorens een router een nieuwe route na een verandering goedkeurt. Om de hierboven uiteengezette redenen is het echter niet veilig om holddowns eenvoudigweg te verwijderen. Het resultaat zou tot oneindigheid worden geteld, zoals beschreven in RFC 1058. We veronderstellen, maar kunnen niet bewijzen, dat met een sterkere versie van routevergiftiging, holddowns niet langer nodig zijn om het tellen tot in het oneindige te stoppen. Het uitschakelen van holddowns maakt deze sterkere vorm van routevergiftiging mogelijk. Merk op dat de gesplitste horizon en de teweeggebrachte updates nog in feite zijn.
De sterkere vorm van routevergiftiging is gebaseerd op een hoptelling. Als de hoptelling voor een weg stijgt, wordt de route verwijderd. Hierdoor verdwijnen vanzelfsprekend nog steeds geldige routes. Als iets elders in het netwerk verandert zodat de weg nu door één meer gateway gaat, zal de hoptelling stijgen. In dit geval is de route nog steeds geldig. Er is echter geen volledig veilige manier om deze case te onderscheiden van het routeren van loops (telling tot oneindig). De veiligste benadering is dus om de route te verwijderen wanneer de hoptelling toeneemt. Als de route nog steeds legitiem is, zal het opnieuw worden geïnstalleerd bij de volgende update, en dat zal een getriggerde update veroorzaken die de route elders in het systeem opnieuw zal installeren.
In het algemeen gebruiken afstandvector algoritmen1 gemakkelijk nieuwe routes. Het probleem is dat oude apparaten volledig uit het systeem worden verwijderd. Dus een regel die overdreven agressief is over het verwijderen van verdachte routes moet veilig zijn.
Details van het updateproces
De reeks processen die in de figuren 4 tot en met 8 worden beschreven, zijn bedoeld voor de verwerking van één netwerkprotocol, bijvoorbeeld TCP/IP, DECnet of het ISO/OSI-protocol. Protocoldetails worden echter alleen voor TCP/IP gegeven. Eén gateway kan gegevens verwerken die meer dan één protocol volgen. Omdat elk protocol verschillende adresseringsstructuren en pakketformaten heeft, zal de computercode die wordt gebruikt om de figuren 4 tot en met 8 uit te voeren over het algemeen verschillend zijn voor elk protocol. Het in figuur 4 beschreven proces zal het meest variëren, zoals beschreven in de gedetailleerde opmerkingen bij figuur 4. De in de figuren 5 tot en met 8 beschreven processen zullen dezelfde algemene structuur hebben. Het primaire verschil tussen protocol en protocol is de indeling van het routing update pakket, dat ontworpen moet worden om compatibel te zijn met een specifiek protocol.
Merk op dat de definitie van een bestemming van protocol tot protocol kan variëren. De hier beschreven methode kan worden gebruikt voor routing naar individuele hosts, naar netwerken of voor complexere hiërarchische adresschema's. Welk type van routing wordt gebruikt, is afhankelijk van de adresseringsstructuur van het protocol. De huidige TCP/IP-implementatie ondersteunt alleen routing naar IP-netwerken. Dus "bestemming" betekent eigenlijk IP-netwerk of subnetnummer. Subnetinformatie wordt alleen bewaard voor verbonden netwerken.
Figuur 4 tot 7 toont pseudo-code voor diverse stukken van het routeringsproces dat door de gateways wordt gebruikt. Bij het begin van het programma worden aanvaardbare protocollen en parameters voor elke interface ingevoerd.
De gateway zal alleen bepaalde protocollen verwerken die worden vermeld. Alle communicatie van een systeem met een protocol dat niet op de lijst staat, wordt genegeerd. De gegevensinvoer is als volgt:
-
Netwerken waarmee de gateway is verbonden.
-
Ongeladen bandbreedte van elk netwerk.
-
Topologische vertraging van elk netwerk.
-
Betrouwbaarheid van elk netwerk.
-
Kanaalbezetting van elk netwerk.
-
MTU van elk netwerk.
De metrische functie voor elk gegevenspad wordt dan berekend volgens vergelijking 1. Merk op dat de eerste drie items redelijk permanent zijn. Zij zijn een functie van de onderliggende netwerktechnologie, en hangen niet van lading af. Ze kunnen worden ingesteld vanuit een configuratiebestand of door directe operator-invoer. Merk op dat IGRP geen gemeten vertraging gebruikt. Zowel de theorie als de ervaring suggereren dat het voor protocollen die gemeten vertraging gebruiken zeer moeilijk is om stabiele routing te handhaven. Er worden twee parameters gemeten: betrouwbaarheid en kanaalbezetting. De betrouwbaarheid is gebaseerd op foutenpercentages die door de hardware of de firmware van de netwerkinterface worden gemeld.
Naast deze ingangen, vereist het routingalgoritme een waarde voor verscheidene routeringsparameters. Dit omvat tijdopnemerwaarden, variantie, en of holddowns worden toegelaten. Dit wordt normaal gesproken aangegeven door een configuratiebestand of een operator-invoer. (Vanaf Cisco release 8.2 is de variantie permanent ingesteld op 1.)
Zodra de initiële informatie is ingevoerd, worden bewerkingen in de gateway geactiveerd door gebeurtenissen, ofwel de aankomst van een gegevenspakket bij een van de netwerkinterfaces, ofwel het verlopen van een timer. De in de figuren 4 tot en met 7 beschreven processen worden als volgt geactiveerd:
-
Wanneer een pakket aankomt, wordt het verwerkt volgens figuur 4. Dit resulteert in het pakket dat wordt verzonden een andere interface, verworpen, of voor verdere verwerking goedgekeurd.
-
Wanneer een pakket door de gateway wordt aanvaard voor verdere verwerking, wordt het geanalyseerd op een protocol-specifieke manier die niet in deze specificatie wordt beschreven. Als het pakket een routing update is, wordt het verwerkt volgens afbeelding 5.
-
Afbeelding 6 toont gebeurtenissen die door een timer zijn geactiveerd. De timer is zo ingesteld dat er eenmaal per seconde een onderbreking wordt gegenereerd. Wanneer de onderbreking voorkomt, wordt het proces dat in figuur 6 wordt getoond uitgevoerd.
-
Afbeelding 7 toont een subroutine van routingupdates. De oproepen tot deze subroutine zijn weergegeven in de figuren 5 en 6.
-
Daarnaast zijn in figuur 8 de details van de in de figuren 5 en 7 bedoelde metrieke berekeningen weergegeven.
Er zijn vier kritieke tijdconstanten die routevoortplanting en expiratie controleren. Deze tijdconstanten kunnen door de systeembeheerder worden ingesteld. Er zijn echter standaardwaarden. Deze tijdconstanten zijn:
-
De tijd-updates van de uitzending worden uitgezonden door alle gateways op alle verbonden interfaces dit vaak. De standaardinstelling is eenmaal in de 90 seconden.
-
Ongeldig tijd-als geen update voor een bepaalde weg binnen deze hoeveelheid tijd is ontvangen, wordt het beschouwd om uit vastgestelde tijd te hebben. Het moet meerdere keren de zendtijd zijn om de mogelijkheid te bieden dat pakketten die een update bevatten door het netwerk kunnen worden laten vallen. De standaardinstelling is 3 maal de uitzendtijd.
-
Houd tijd-wanneer een bestemming onbereikbaar is geworden (of de metriek genoeg is toegenomen om vergiftiging te veroorzaken), gaat de bestemming in "holddown". Gedurende deze status wordt er voor deze tijd geen nieuw pad geaccepteerd voor dezelfde bestemming. De houdtijd geeft aan hoelang deze status moet duren. Het moet een aantal keer de zendtijd zijn. De standaardwaarde is 3 keer de uitzendtijd plus 10 seconden. (Zoals beschreven in de sectie Uitschakelen van holddowns, is het mogelijk om holddowns uit te schakelen.)
-
Spoeltijd-als geen update voor een bepaalde bestemming binnen deze hoeveelheid tijd is ontvangen, wordt de ingang voor het verwijderd uit de routeringstabel. Let op het verschil tussen ongeldige tijd en spoeltijd: Na de ongeldige tijd wordt een pad verzonden en verwijderd. Als er geen resterende paden naar een bestemming zijn, is de bestemming nu onbereikbaar. De database voor de bestemming blijft echter ongewijzigd. Het moet blijven om de ‘holddown' te handhaven. Na de spoeltijd wordt de database-ingang uit de tabel verwijderd. Het zou iets langer moeten zijn dan de ongeldige tijd plus de holddown tijd. De standaardinstelling is 7 maal de uitzendtijd.
Deze cijfers veronderstellen de volgende belangrijke gegevensstructuren. Een afzonderlijke set van deze gegevensstructuren wordt bewaard voor elk protocol dat door de gateway wordt ondersteund. Binnen elk protocol wordt een afzonderlijke set gegevensstructuren bijgehouden voor elk type dienst dat moet worden ondersteund.
Voor elke bestemming die bij het systeem bekend is, is er een (mogelijk ongeldige) lijst van paden naar de bestemming, een holddown verlooptijd en een laatste update tijd. De laatste updatetijd geeft de laatste keer aan dat een pad voor deze bestemming is opgenomen in een update vanuit een andere gateway. Let op dat er ook updatetijden worden bijgehouden voor elk pad. Wanneer het laatste pad naar een bestemming is verwijderd, wordt de bestemming in holddown gezet, tenzij holddowns uitgeschakeld zijn (Zie de sectie Uitschakelen Holddowns voor meer informatie). De holddown verlooptijd geeft het tijdstip aan waarop de holddown verloopt. Het feit dat het niet nul is, geeft aan dat de bestemming in holddown is. Om berekeningstijd te besparen, is het ook een goed idee om een "beste metriek" voor elke bestemming te houden. Dit is simpelweg het minimum van de samengestelde waarden voor alle paden naar de bestemming.
Voor elke weg aan een bestemming, is er het adres van de volgende hop in de weg, de te gebruiken interface, een vector van metriek die de weg, met inbegrip van topologische vertraging, bandbreedte, betrouwbaarheid, en kanaalbezetting kenmerken. Andere informatie wordt ook geassocieerd met elke weg, met inbegrip van hoptelling, MTU, bron van informatie, de verre samengestelde metriek, en een samengestelde metriek die van deze aantallen volgens vergelijking 1 wordt berekend. Er is ook een laatste updatetijd. De informatiebron geeft aan waar de meest recente update voor dat pad vandaan kwam. In de praktijk is dit hetzelfde als het adres van de volgende hop. De laatste updatetijd is gewoon de tijd waarop de meest recente update voor dit pad is gearriveerd. Het wordt gebruikt om afgesproken paden te verlopen.
Merk op dat een IGRP updatebericht drie gedeelten heeft: interieur, systeem (dat betekent "dit autonome systeem" maar niet interieur), en exterieur. De binnenste sectie is voor routes aan subnets. Niet alle subnetinformatie is opgenomen. Er zijn slechts subnetten van één netwerk opgenomen. Dit is het netwerk dat is gekoppeld aan het adres waarnaar de update wordt verzonden. Normaal gesproken worden updates uitgezonden op elke interface, dus dit is gewoon het netwerk waarop de uitzending wordt verzonden. (Andere gevallen doen zich voor voor reacties op een IGRP-verzoek en wijzen op punt IGRP.) De grote netwerken (bijvoorbeeld, niet-subnets) worden gezet in het systeemgedeelte van het updatebericht tenzij zij specifiek als buitenkant worden gemarkeerd.
Een netwerk zal als buitenkant worden gemarkeerd als het van een andere gateway werd geleerd en de informatie in het buitengedeelte van het updatebericht aankwam. De implementatie van Cisco stelt de systeembeheerder ook in staat om specifieke netwerken als extern te verklaren. Externe routes worden ook wel "kandidaat-default" genoemd. Het zijn routes die naar of door gateways gaan die als geschikt als defaults worden beschouwd, om worden gebruikt wanneer er geen expliciete route aan een bestemming is. Bij Rutgers configureren we bijvoorbeeld de gateway die Rutgers verbindt met ons regionale netwerk, zodat het de route naar de NSFnet backbone markeert als exterieur. De implementatie van Cisco kiest een standaardroute door die buitenroute met de kleinste metriek te kiezen.
In de volgende rubrieken worden bepaalde gedeelten van de figuren 4 tot en met 8 verduidelijkt.
Packet-routing
Figuur 4 beschrijft de totale verwerking van de inputpakketten. Dit wordt eenvoudigweg gebruikt om de terminologie te verduidelijken. Uiteraard is dit geen volledige beschrijving van wat een IP-gateway doet.
Dit proces gebruikt de lijst van ondersteunde protocollen en de informatie over de interfaces die zijn ingevoerd wanneer de gateway wordt geïnitialiseerd. De details van de pakketverwerking hangen van het protocol af dat door het pakket wordt gebruikt. Dit wordt bepaald in Stap A. Stap A is het enige deel van afbeelding 4 dat door alle protocollen wordt gedeeld. Zodra het protocoltype bekend is, wordt de implementatie van figuur 4, geschikt voor het protocoltype, gebruikt. Details van de pakketinhoud worden beschreven in de specificaties van het protocol. De specificaties van een protocol omvatten een procedure om de bestemming van een pakket te bepalen, een procedure om de bestemming met de eigen adressen van de gateway te vergelijken om te bepalen of de gateway zelf de bestemming is, een procedure om te bepalen of een pakket een uitzending is, en een procedure om te bepalen of de bestemming deel uitmaakt van een gespecificeerd netwerk. Deze procedures worden gebruikt in stappen B en C van afbeelding 4. Voor de test in stap D moet u de bestemmingen zoeken die in de routeringstabel worden vermeld. De test is tevreden als er een ingang in de routeringstabel voor de bestemming is, en dat de bestemming met het minstens één bruikbare weg heeft geassocieerd. Houd er rekening mee dat de bestemmings- en padgegevens die in deze en de volgende stap worden gebruikt, afzonderlijk worden bijgehouden voor elk type ondersteunde service. Aldus begint deze stap door het type van de dienst te bepalen dat door het pakket wordt gespecificeerd, en de overeenkomstige reeks gegevensstructuren te selecteren voor deze en volgende stap te gebruiken.
Een pad is bruikbaar voor de stappen D en E als de externe samengestelde metriek minder is dan de samengestelde metriek. Een pad waarvan de externe samengestelde metriek groter is dan de samengestelde metriek is een pad waarvan de volgende hop "verder weg" is van de bestemming, zoals gemeten door de metriek. Dit wordt een "upstream pad" genoemd. Normaal zou je verwachten dat het gebruik van metriek zou voorkomen dat stroomopwaarts paden worden gekozen. Het is gemakkelijk om te zien dat een stroomopwaarts pad nooit de beste kan zijn. Als echter een grote variantie is toegestaan, kunnen andere paden worden gebruikt dan de beste. Sommige daarvan zouden upstream kunnen zijn.
Stap E berekent het te gebruiken pad. Paden waarvan de externe samengestelde metriek niet minder is dan hun samengestelde metriek worden niet in aanmerking genomen. Als meer dan één pad acceptabel is, worden dergelijke paden gebruikt in een gewogen vorm van round-robin afwisseling. De frequentie waarmee een pad wordt gebruikt is omgekeerd evenredig aan de samengestelde metriek.
Ontvangst van Routing Updates
Afbeelding 5 beschrijft de verwerking van een routingupdate die van een naburige gateway wordt ontvangen. Deze actualiseringen bestaan uit een lijst van vermeldingen, die elk informatie voor één enkele bestemming bevatten. Meer dan één ingang voor de zelfde bestemming kan in één enkele routeringsupdate voorkomen, om meerdere types van de dienst aan te passen. Elk van deze gegevens wordt afzonderlijk verwerkt, zoals beschreven in figuur 5. Indien een vermelding in het buitengedeelte van de bijwerking is opgenomen, wordt de buitenvlag voor de bestemming ingesteld indien deze als gevolg van dit proces wordt toegevoegd.
Het gehele proces dat in afbeelding 5 wordt beschreven, moet één keer worden herhaald voor elk type service dat door de gateway wordt ondersteund, met behulp van de set bestemming-/padinformatie die aan dat type service is gekoppeld. Dit wordt getoond in de buitenste lijn in Figuur 5. De volledige routeringsupdate moet eens voor elk type van de dienst worden verwerkt. (Merk op dat de huidige implementatie van IGRP geen meerdere typen service ondersteunt, zodat de buitenste lus niet daadwerkelijk wordt geïmplementeerd.)
Bij stap A worden fundamentele aanvaardbaarheidstests op het pad uitgevoerd. Dit zou redelijke tests voor de bestemming moeten omvatten. Onmogelijke ("Martiaanse") netwerknummers moeten worden afgewezen. (Raadpleeg RFC 1009![]() en RFC 1122
en RFC 1122![]() voor meer informatie.) Updates worden ook verworpen als de bestemming waarnaar ze verwijzen in holddown is, d.w.z. de holddown verlooptijd is niet nul en later dan de huidige tijd.
voor meer informatie.) Updates worden ook verworpen als de bestemming waarnaar ze verwijzen in holddown is, d.w.z. de holddown verlooptijd is niet nul en later dan de huidige tijd.
In Stap B wordt de routeringstabel doorzocht om te zien of deze ingang een pad beschrijft dat al bekend is. Een pad in de routeringstabel wordt gedefinieerd door de bestemming waarmee het is gekoppeld, de volgende hop die als deel van het pad wordt vermeld, de uitvoerinterface die voor het pad moet worden gebruikt en de informatiebron (het adres waar de update vandaan komt, in de praktijk gewoonlijk hetzelfde als de volgende hop). De ingang van het updatepakket beschrijft een weg de waarvan bestemming in de ingang vermeld is, de waarvan outputinterface de interface is die de update binnen kwam, en waarvan de volgende hop en informatiebron het adres van de gateway zijn die de update (de "bron" S) verzond.
In Stap H en Stap T is het updateproces dat in afbeelding 7 is beschreven gepland. Dit proces wordt daadwerkelijk uitgevoerd nadat het gehele proces dat in afbeelding 5 is beschreven, is voltooid. Dat wil zeggen dat het in figuur 7 beschreven updateproces slechts eenmaal zal plaatsvinden, zelfs wanneer het meerdere malen wordt geactiveerd tijdens de verwerking die in afbeelding 5 wordt beschreven. Bovendien moeten voorzorgsmaatregelen worden genomen om te voorkomen dat er te vaak updates worden uitgegeven, als het netwerk snel verandert.
Stap K wordt gedaan als de bestemming die door de huidige ingang in het updatepakket wordt beschreven reeds in de routeringstabel bestaat. K vergelijkt de nieuwe samengestelde metriek die van gegevens in het updatepakket wordt berekend met de beste samengestelde metriek voor de bestemming. Merk op dat de beste samengestelde metriek niet op dit moment opnieuw wordt berekend, dus als het pad dat wordt overwogen al in de routeringstabel staat, kan deze test nieuwe en oude metriek voor hetzelfde pad vergelijken.
Stap L wordt uitgevoerd voor de paden die slechter zijn dan de bestaande beste samengestelde metriek. Dit omvat zowel nieuwe paden die slechter zijn dan bestaande paden als bestaande paden waarvan de samengestelde metriek is toegenomen. Stap L test of het nieuwe pad acceptabel is. Merk op dat deze test zowel de test implementeert om te bepalen of een nieuw pad goed genoeg is om te houden, als route-vergiftiging. Om aanvaardbaar te zijn, moet de vertragingswaarde niet de speciale waarde zijn die op een onbereikbare bestemming wijst (voor de huidige IP implementatie, alle degenen in een 24 beetjesveld), en de samengestelde metriek (berekend zoals gespecificeerd in Figuur 8) moet aanvaardbaar zijn. Om te bepalen of de samengestelde metriek aanvaardbaar is, vergelijk het met de samengestelde metriek van alle andere wegen aan de bestemming. Laat mij het minimum zijn. Het nieuwe pad is acceptabel als het < V X M is, waarbij V DE VARIANTIE IS DIE IS INGESTELD TOEN DE GATEWAY WERD GEÏNITIALISEERD. ALS V = 1 (WAT ALTIJD WAAR IS VANAF CISCO RELEASE 8.2), IS EEN METRIEK ERGER DAN DE BESTAANDE NIET ACCEPTABEL. ER IS ÉÉN UITZONDERING: ALS HET PAD AL BESTAAT EN HET ENIGE PAD NAAR DE BESTEMMING IS, BLIJFT HET PAD BEHOUDEN ALS DE METRIEK NIET MET MEER DAN 10% IS TOEGENOMEN (OF ALS HOUDINGEN ZIJN UITGESCHAKELD ALS HET HOPAANTAL NIET IS TOEGENOMEN).
Stap V wordt uitgevoerd wanneer de nieuwe informatie voor een pad aangeeft dat de samengestelde metriek wordt verlaagd. De samengestelde metriek van alle paden naar bestemming D worden vergeleken. In deze vergelijking, wordt de nieuwe samengestelde metriek voor P gebruikt, eerder dan die in het verpletteren van lijst verschijnt. De minimale metrische samenstelling M wordt berekend. Vervolgens worden alle paden naar D opnieuw onderzocht. Als de samengestelde metriek voor een pad > M x V, wordt dat pad verwijderd. V is de variantie, ingevoerd toen de gateway werd geïnitialiseerd. (Vanaf Cisco release 8.2 is de variantie permanent ingesteld op 1.)
Periodische verwerking
Het proces dat in figuur 6 wordt beschreven, wordt eenmaal per seconde gestart. Het onderzoekt verschillende timers in de routeringstabel om te zien of een van deze tijden is verlopen. Deze timers worden hierboven beschreven.
Bij Stap U wordt het in figuur 7 beschreven proces geactiveerd.
Stap R en Stap S zijn noodzakelijk omdat de samengestelde metriek die in de routeringstabel worden opgeslagen, van de kanaalbezetting afhangen, die in tijd verandert, gebaseerd op metingen. Periodiek wordt de kanaalbezetting opnieuw berekend, met behulp van een voortschrijdend gemiddelde van gemeten verkeer door de interface. Als de nieuw berekende waarde verschilt van de bestaande, moeten alle samengestelde metriek die een interface bevat worden aangepast. Elke weg die in de routeringstabel wordt getoond wordt onderzocht. Elke pad waarvan de volgende hop interface "I" gebruikt, heeft zijn samengestelde metriek opnieuw berekend. Dit wordt gedaan in overeenstemming met vergelijking 1, met behulp van als kanaalbezetting het maximum van de waarde die is opgeslagen in routingstabel als deel van de metrische weg, en de nieuw berekende kanaalbezetting van de interface.
Updateberichten genereren
Afbeelding 7 beschrijft hoe de gateway updateberichten genereert die naar andere gateways moeten worden verzonden. Er wordt een afzonderlijk bericht gegenereerd voor elke netwerkinterface die aan de gateway is gekoppeld. Dat bericht wordt dan verzonden naar alle andere gateways die door de interface (Stap J) bereikbaar zijn. In het algemeen gebeurt dit door het bericht als een uitzending te verzenden. Als de netwerktechnologie of het protocol uitzendingen niet toestaat, kan het echter nodig zijn het bericht afzonderlijk naar elke gateway te verzenden.
In het algemeen, wordt het bericht opgebouwd door een ingang voor elke bestemming in de routeringstabel, in Stap G toe te voegen. Merk op dat de bestemming/weggegevens verbonden aan elk type van de dienst moeten worden gebruikt. In het slechtste geval wordt een nieuwe vermelding toegevoegd aan de bijwerking voor elke bestemming voor elk type dienst. Alvorens echter een vermelding toe te voegen aan het updatebericht in stap G, worden de reeds toegevoegde vermeldingen gescand. Als de nieuwe vermelding al in het updatebericht staat, wordt deze niet opnieuw toegevoegd. Een nieuwe ingang dupliceert een bestaande wanneer de bestemmingen en de volgende hopgateways het zelfde zijn.
Omwille van eenvoud, laat de pseudocode één ding weg-IGRP updateberichten hebben drie delen: interieur, systeem en exterieur, wat betekent dat er eigenlijk drie loops over bestemmingen zijn. De eerste bevat alleen subnetten van het netwerk waarnaar de update wordt verzonden. De tweede omvat alle grote netwerken (bijvoorbeeld niet-subnetten) die niet als buitenkant zijn gemarkeerd. De derde omvat alle grote netwerken die als buitenkant zijn gemarkeerd.
Stap E implementeert de gesplitste horizontest. In het normale geval, faalt deze test voor routes waarvan de beste weg de zelfde interface uitgaat die de update wordt verzonden. Als de update echter naar een specifieke bestemming wordt verzonden (bijvoorbeeld in antwoord op een IGRP-verzoek van een andere gateway of als onderdeel van "point to point IGRP"), mislukt de gesplitste horizont alleen als het beste pad oorspronkelijk uit die bestemming kwam (de "informatiebron" is hetzelfde als de bestemming) en de uitvoerinterface dezelfde is als die van het verzoek.
Metrische informatie berekenen
Figuur 8 beschrijft hoe de metrische informatie van updateberichten wordt verwerkt die door de gateway worden ontvangen, en hoe het voor updateberichten wordt geproduceerd die door de gateway worden verzonden. Merk op dat de invoer is gebaseerd op één bepaald pad naar de bestemming. Als er meer dan één pad naar de bestemming is, wordt een pad gekozen waarvan de samengestelde metriek minimaal is. Als meer dan één pad de minimale composiet-metriek heeft, wordt een willekeurige bindingsregel gebruikt. (Voor de meeste protocollen is dit gebaseerd op het adres van de volgende hopgateway.)
Afbeelding 4 — Inkomende pakketten verwerken
Data packet arrives using interface I
A Determine protocol used by packet
If protocol is not supported
then discard packet
B If destination address matches any of gateway's addresses
or the broadcast address
then process packet in protocol-specific way
C If destination is on a directly-connected network
then send packet direct to the destination, using
the encapsulation appropriate to the protocol and link type
D If there are no paths to the destination in the routing
table, or all paths are upstream
then send protocol-specific error message and discard the packet
E Choose the next path to use. If there are more than
one, alternate round-robin with frequency proportional
to inverse of composite metric.
Get next hop from path chosen in previous step.
Send packet to next hop, using encapsulation appropriate
to protocol and data link type.
Afbeelding 5: Updates voor inkomende routing verwerken
Routing update arrives from source S
For each type of service supported by gateway
Use routing data associated with this type of service
For each destination D shown in update
A If D is unacceptable or in holddown
then ignore this entry and continue loop with next destination D
B Compute metrics for path P to D via S (see Fig 8)
If destination D is not already in the routing table
then Begin
Add path P to the routing table, setting last
update times for P and D to current time.
H Trigger an update
Set composite metric for D and P to new composite
metric computed in step B.
End
Else begin (dest. D is already in routing table)
K Compare the new composite metric for P with best
existing metric for D.
New > old:
L If D is shown as unreachable in the update,
or holddowns are enabled and
the new composite metric >
(the existing metric for D) * V
[use 1.1 instead of V if V = 1,
as it is as of Cisco release 8.2]
O or holddowns are disabled and
P has a new hop count > old hop count
then Begin
Remove P from routing table if present
If P was the last route to D
then Unless holddowns are disabled
Set holddown time for D to
current time + holddown time
T and Trigger an update
End
else Begin
Compute new best composite metric for D
Put the new metric information into the
entry for P in the routing table
Add path P to the routing table if it
was not present.
Set last update times for P and D to
current time.
End
New <= OLD:
V Set composite metric for D and P to new
composite metric computed in step B.
If any other paths to D are now outside the
variance, remove them.
Put the new metric information into the
entry for P in the routing table
Set last update times for P and D to
current time.
End
End of for
End of for
Afbeelding 6. Periodieke verwerking
Process is activated by regular clock, e.g. once per second
For each path P in the routing table (except directly
connected interfaces)
If current time < P'S LAST UPDATE TIME + INVALID TIME
THEN CONTINUE WITH THE NEXT PATH P
Remove P from routing table
If P was the last route to D
then Set metric for D to inaccessible
Unless holddowns are disabled,
Start holddown timer for D and
Trigger an update
else Recompute the best metric for D
End of for
For each destination D in the routing table
If D's metric is inaccessible
then Begin
Clear all paths to D
If current time >= D's last update time + flush time
then Remove entry for D
End
End of for
For each network interface I attached to the gateway
R Recompute channel occupancy and error rate
S If channel occupancy or error rate has changed,
then recompute metrics
End of for
At intervals of broadcast time
U Trigger update
Afbeelding 7. Update genereren
Process is caused by "trigger update"
For each network interface I attached to the gateway
Create empty update message
For each type of service S supported
Use path/destination data for S
For each destination D
E If any paths to D have a next hop reached through I
then continue with the next destination
If any paths to D with minimal composite metric are
already in the update message
then continue with the next destination
G Create an entry for D in the update message, using
metric information from a path with minimal
composite metric (see Fig. 8)
End of for
End of for
J If there are any entries in the update message
then send it out interface I
End of for
Afbeelding 8 — Details van metrieke berekeningen
Deze sectie beschrijft de procedure om metriek en hoptellingen van een aankomende routingsupdate gegevens te verwerken. De input voor deze functie is de ingang voor een specifieke bestemming in een routingupdate pakket. De output is een vector van metriek die kan worden gebruikt om de samengestelde metriek, en een hoptelling te berekenen. Als dit pad wordt toegevoegd aan de routeringstabel, wordt de gehele vector van metriek ingevoerd in de tabel. De interfaceparameters die in de volgende definities worden gebruikt zijn die die werden geplaatst toen de gateway werd geïnitialiseerd, voor de interface waarop de routingupdate aankwam, behalve dat de kanaalbezetting en de betrouwbaarheid op een bewegend gemiddelde van gemeten verkeer door de interface gebaseerd zijn.
-
Vertraging = vertraging van pakket + interface topologische vertraging
-
Bandbreedte = max (bandbreedte vanaf pakket, interfacebandbreedte)
-
Betrouwbaarheid = min (betrouwbaarheid vanaf pakket, interfacebetrouwbaarheid)
-
Kanaalbezetting = max (kanaalbezetting vanaf pakket, bezetting interfacekanaal)
(Max.) wordt gebruikt voor bandbreedte omdat de bandbreedte metriek in omgekeerde vorm wordt opgeslagen. Conceptueel, willen wij de minimumbandbreedte.) Merk op dat de originele kanaalbezetting van het pakket moet worden opgeslagen, omdat het nodig zal zijn om de effectieve kanaalbezetting opnieuw te berekenen wanneer de bezetting van interfacekanalen verandert.
Het volgende maakt geen deel uit van de metrische vector, maar wordt ook als kenmerken van het pad in de routeringstabel gehouden:
-
Hoptelling = hoptelling van pakket.
-
MTU = min (MTU van pakket, interface MTU).
-
Remote composite metric = berekend uit vergelijking 1 met behulp van de metrische waarden uit het pakket. Dat wil zeggen dat de metrische componenten die van het pakket zijn en niet worden bijgewerkt zoals hierboven wordt getoond. Dit moet natuurlijk worden berekend voordat de hierboven genoemde aanpassingen worden uitgevoerd.
-
Samengestelde metriek = berekend uit vergelijking 1 met behulp van de metrische waarden berekend zoals beschreven in dit punt.
Deze rest van deze sectie beschrijft de procedure om metriek en hoptelling voor het verzenden van updates te berekenen.
Deze functie bepaalt de metrische informatie en de hoptelling die in een uitgaand updatepakket moet worden gezet. Het is gebaseerd op een specifiek pad naar een bestemming als er bruikbare paden zijn. Als er geen paden zijn of als de paden allemaal stroomopwaarts zijn, wordt de bestemming "ontoegankelijk" genoemd.
If destination is inaccessible, this is indicated by using a specific
value in the delay field. This value is chosen to be larger
than the largest valid delay. For the IP implementation this is
all ones in a 24-bit field.
If destination is directly reachable through one of the interfaces, use
the delay, bandwidth, reliability, and channel occupancy of the
interface. Set hop count to 0.
Otherwise, use the vector of metrics associated with the path in the
routing table. Add one to the hop count from the path in the
routing table.
Details van de IP-implementatie
In deze sectiesamenvatting worden de pakketformaten beschreven die door Cisco IGRP worden gebruikt. IGRP wordt verzonden via IP-datagrammen met IP-protocol 9 (IGP). Het pakket begint met een header. Het begint onmiddellijk na de IP-header.
unsigned version: 4; /* protocol version number */
unsigned opcode: 4; /* opcode */
uchar edition; /* edition number */
ushort asystem; /* autonomous system number */
ushort ninterior; /* number of subnets in local net */
ushort nsystem; /* number of networks in AS */
ushort nexterior; /* number of networks outside AS */
ushort checksum; /* checksum of IGRP header and data */
Voor updateberichten, volgt de routing informatie onmiddellijk na de header.
Het versienummer is momenteel 1. Pakketten met andere versienummers worden genegeerd.
De opcode kan zijn 1 = update of 2 = verzoek.
Dit geeft het soort bericht aan. Het formaat van de twee berichttypes wordt hieronder gegeven.
Edition is een serienummer dat wordt verhoogd wanneer er een wijziging in de routeringstabel is. (Dit wordt gedaan in die omstandigheden waarin de pseudocode hierboven zegt om een routing update te activeren.) Met het nummer van de editie kunnen gateways vermijden dat updates worden verwerkt die informatie bevatten die ze al hebben gezien. (Dit is momenteel niet geïmplementeerd. Dat wil zeggen, het editie nummer wordt correct gegenereerd, maar het wordt genegeerd bij invoer. Omdat het mogelijk is om pakketten te laten vallen, is het niet duidelijk dat het nummer van de editie voldoende is om dubbele verwerking te voorkomen. Er moet voor worden gezorgd dat alle bij de uitgave behorende pakketten zijn verwerkt.)
Asystem is het autonome systeemnummer. In de implementatie van Cisco kan een gateway deelnemen aan meer dan één autonoom systeem. Elk van deze systemen voert zijn eigen IGRP-protocol uit. Conceptueel, zijn er volledig afzonderlijke routing tabellen voor elk autonoom systeem. Routes die via IGRP van één autonoom systeem aankomen worden verzonden slechts in updates voor dat AS. Dit veld staat de gateway toe om te selecteren welke set van routingtabellen te gebruiken voor de verwerking van dit bericht. Als de gateway een IGRP-bericht ontvangt voor een AS waarvoor het niet is geconfigureerd, wordt het genegeerd. Uiteindelijk maakt de Cisco-implementatie het mogelijk dat informatie van het ene AS naar het andere wordt "gelekt". Ik beschouw dat echter als een administratief instrument en niet als een onderdeel van het protocol.
De binnenzijde, het systeem en de buitenzijde geven het aantal vermeldingen aan in elk van de drie secties van de updateberichten. Deze punten zijn hierboven beschreven. Er is geen andere afbakening tussen de secties. De eerste inwendige elementen worden inwendig beschouwd, de volgende innerlijke elementen als systeemelementen, en de laatste inwendige als uitwendig.
Checksum is een IP-checksum, berekend met behulp van hetzelfde checksum algoritme als een UDP-checksum. De controlesom wordt berekend op de IGRP-header en alle Routing-informatie die erop volgt. Het veld checksum wordt bij het berekenen van de checksum op nul ingesteld. De controlesom bevat de IP-header niet en er is ook geen virtuele header zoals in UDP en TCP.
Verzoeken
Een IGRP-verzoek vraagt de ontvanger om zijn routeringstabel te verzenden. Het verzoekbericht heeft slechts een kop. Alleen de velden versie, opcode en systeem worden gebruikt. Alle andere velden zijn nul. De ontvanger wordt verwacht om een normaal IGRP updatebericht naar de aanvrager te verzenden.
Updates
Een IGRP-updatebericht bevat een kop, onmiddellijk gevolgd door routingberichten. Er zijn evenveel routingvermeldingen opgenomen als die in een datagram van 1500 bytes passen (inclusief IP-header). Bij de huidige structuuraangiften zijn hiervoor maximaal 104 vermeldingen mogelijk. Als meer ingangen nodig zijn, worden verscheidene updateberichten verzonden. Aangezien updateberichten simpelweg worden verwerkt entry by entry, is er geen voordeel aan het gebruik van een enkele gefragmenteerde bericht in plaats van meerdere onafhankelijke berichten.
Hier is de structuur van een routeringsingang:
uchar number[3]; /* 3 significant octets of IP address */
uchar delay[3]; /* delay, in tens of microseconds */
uchar bandwidth[3]; /* bandwidth, in units of 1 Kbit/sec */
uchar mtu[2]; /* MTU, in octets */
uchar reliability; /* percent packets successfully tx/rx */
uchar load; /* percent of channel occupied */
uchar hopcount; /* hop count */
De velden uchar[2] en uchar[3] zijn in normale IP-netwerkvolgorde gewoon 16- en 24-bits binaire gehele getallen.
Number definieert de bestemming die wordt beschreven. Het is een IP-adres. Om ruimte te besparen worden alleen de eerste 3 bytes van het IP-adres gegeven, behalve in het binnengedeelte. In het binnengedeelte worden de laatste 3 bytes gegeven. Voor systeem en buitenroutes zijn geen subnetten mogelijk, dus de byte van de lage orde is altijd nul. Binnenlandse routes zijn altijd subnetten van een bekend netwerk, dus de eerste byte van dat netwerknummer wordt meegeleverd.
Vertraging wordt uitgedrukt in eenheden van 10 microseconden. Dit geeft een bereik van 10 microseconden tot 168 seconden, wat voldoende lijkt. Een vertraging van alle punten geeft aan dat het netwerk onbereikbaar is.
De bandbreedte is een omgekeerde bandbreedte in bits per sec, geschaald met een factor 1,0e10. Het bereik loopt van een 1200 BPS-lijn tot 10 Gbps. (Als de bandbreedte N Kbps is, wordt dus 10000000 / N gebruikt.)
MTU is in bytes.
Betrouwbaarheid wordt gegeven in een fractie van 255, dat wil zeggen 255 is 100%.
De belasting wordt uitgedrukt in een fractie van 255.
Hoptelling is een eenvoudige telling.
Vanwege de ietwat vreemde eenheden die worden gebruikt voor bandbreedte en vertraging, lijken sommige voorbeelden in volgorde. Dit zijn de standaardwaarden die worden gebruikt voor meerdere algemene media.
Delay Bandwidth
--------------- -------------------
Satellite 200,000 (2 sec) 20 (500 Mbit)
Ethernet 100 (1 ms) 1,000
1.544 Mbit 2000 (20 ms) 6,476
64 Kbit 2000 156,250
56 Kbit 2000 178,571
10 Kbit 2000 1,000,000
1 Kbit 2000 10,000,000
Metrische berekeningen
Hier is een beschrijving van de manier waarop de samengestelde metriek in Cisco versie 8.0(3) wordt berekend.
metric = [K1*bandwidth + (K2*bandwidth)/(256 - load) + K3*delay] *
[K5/(reliability + K4)]
If K5 == 0, the reliability term is not included.
The default version of IGRP has K1 == K3 == 1, K2 == K4 == K5 == 0
Gerelateerde informatie
Revisiegeschiedenis
| Revisie | Publicatiedatum | Opmerkingen |
|---|---|---|
1.0 |
04-Sep-2002
|
Eerste vrijgave |
 Feedback
Feedback