Hoge beschikbaarheid Herstel in Ultra-M Element Manager Cluster - vEPC
Downloadopties
Inclusief taalgebruik
De documentatie van dit product is waar mogelijk geschreven met inclusief taalgebruik. Inclusief taalgebruik wordt in deze documentatie gedefinieerd als taal die geen discriminatie op basis van leeftijd, handicap, gender, etniciteit, seksuele oriëntatie, sociaaleconomische status of combinaties hiervan weerspiegelt. In deze documentatie kunnen uitzonderingen voorkomen vanwege bewoordingen die in de gebruikersinterfaces van de productsoftware zijn gecodeerd, die op het taalgebruik in de RFP-documentatie zijn gebaseerd of die worden gebruikt in een product van een externe partij waarnaar wordt verwezen. Lees meer over hoe Cisco gebruikmaakt van inclusief taalgebruik.
Over deze vertaling
Cisco heeft dit document vertaald via een combinatie van machine- en menselijke technologie om onze gebruikers wereldwijd ondersteuningscontent te bieden in hun eigen taal. Houd er rekening mee dat zelfs de beste machinevertaling niet net zo nauwkeurig is als die van een professionele vertaler. Cisco Systems, Inc. is niet aansprakelijk voor de nauwkeurigheid van deze vertalingen en raadt aan altijd het oorspronkelijke Engelstalige document (link) te raadplegen.
Inhoud
Inleiding
In dit document worden de stappen beschreven die nodig zijn om de High Availability (HA) in Element Manager (EM)-cluster van een Ultra-M-setup waarin StarOS Virtual Network Functions (VNF’s) wordt gehost, te herstellen.
Achtergrondinformatie
Ultra-M is een voorverpakte en gevalideerde gevirtualiseerde mobiele packet-core-oplossing die ontworpen is om de implementatie van VNF's te vereenvoudigen. Ultra-M oplossing bestaat uit de genoemde Virtual Machine (VM) types:
- Auto-IT
- Automatische implementatie
- Ultra Automation Services (UAS)
- Element Manager (EM)
- Elastische servicescontroller (ESC)
- Controlefunctie (CF)
- Sessiefunctie (SF)
De hoogwaardige architectuur van Ultra-M en de betrokken componenten worden in dit beeld weergegeven:
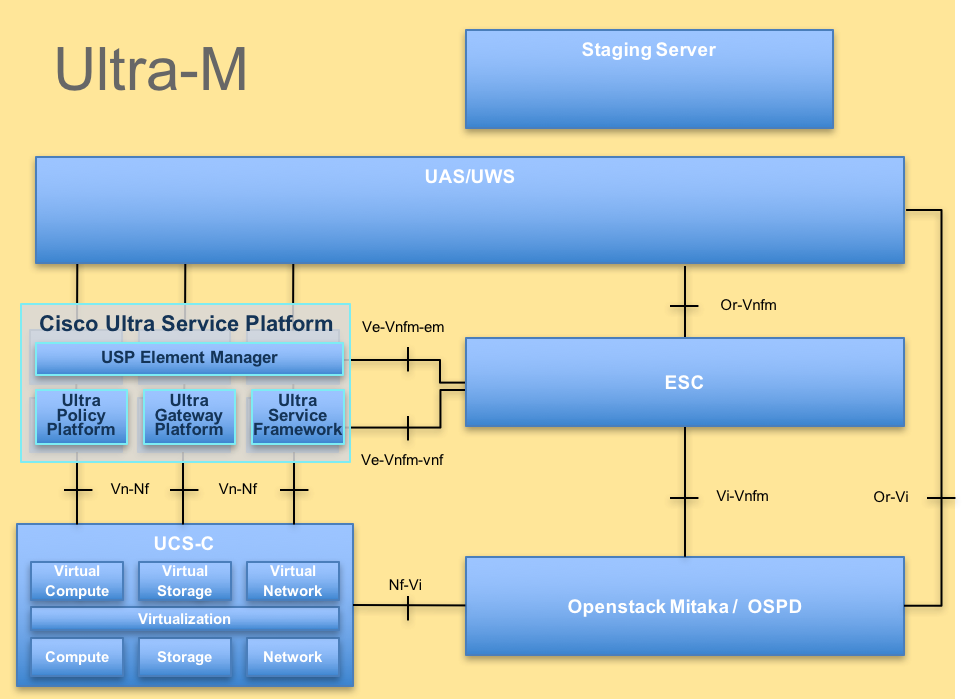 UltraM-architectuur
UltraM-architectuur
Dit document is bedoeld voor het Cisco-personeel dat bekend is met Cisco Ultra-M platform.
Opmerking: Ultra M 5.1.x release wordt overwogen om de procedures in dit document te definiëren.
Afkortingen
| HA | Hoge beschikbaarheid |
| VNF | Virtuele netwerkfunctie |
| CF | Bedieningsfunctie |
| SF | Servicefunctie |
| ESC | Elastic-servicecontroller |
| MOP | Werkwijze |
| OSD | Schijven voor objectopslag |
| HDD | Harde schijf |
| SSD | Solid state drive |
| VIM | Virtual Infrastructure Manager |
| VM | Virtuele machine |
| EM | Element Manager |
| UAS | Ultra-automatiseringsservices |
| UUID | Universele unieke IDentifier |
Werkstroom van de MoP
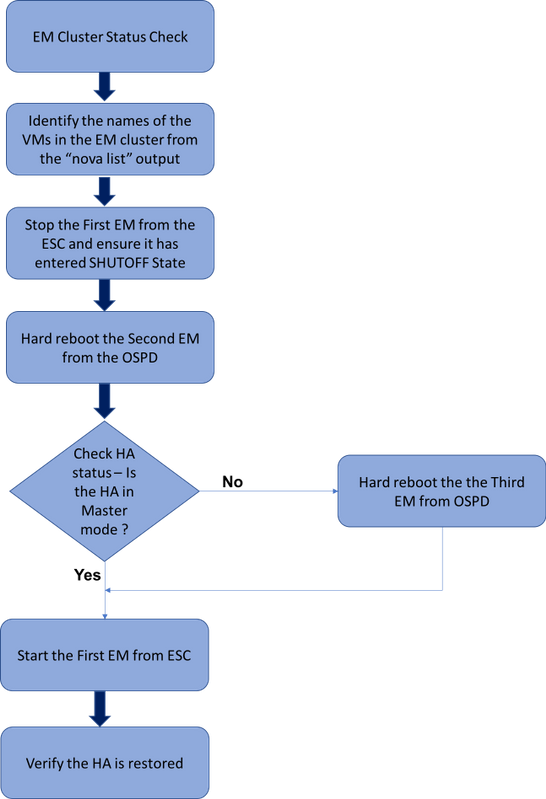 Hoogwaardige workflow van de EM HA-herstelprocedure
Hoogwaardige workflow van de EM HA-herstelprocedure
Clusterstatus controleren
Log in op de actieve EM en controleer de HA status. Er kunnen twee scenario's zijn:
1. HA-modus is geen:
ubuntu@vnfd1deploymentem-0:~$ ncs_cli -u admin -C
admin@scm# show ncs-state ha
ncs-state ha mode none
admin@scm# show ems
%no entries found%
2. EM-cluster heeft slechts één knooppunt (EM-cluster bestaat uit 3 VM's):
ubuntu@vnfd1deploymentem-0:~$ ncs_cli -u admin -C
admin@scm# show ncs-state ha
ncs-state ha mode master
ncs-state ha node-id 2-1528893823
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
----------------------
2 up down down
In beide gevallen kan de HA-status worden hersteld door de stappen die in de volgende paragraaf worden genoemd.
HA-herstelprocedure
Identificeer de VM-namen van EM's die deel uitmaken van het cluster uit de nova-lijst. Er zijn drie VM's die deel uitmaken van een EM-cluster.
[stack@director ~]$ nova list | grep vnfd1
| e75ae5ee-2236-4ffd-a0d4-054ec246d506 | vnfd1-deployment_c1_0_13d5f181-0bd3-43e4-be2d-ada02636d870 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.22; DI-INTERNAL2=192.168.2.17; DI-INTERNAL1=192.168.1.14; tmo-autovnf2-uas-management=172.18.181.23 |
| 33c779d2-e271-47af-8ad5-6a982c79ba62 | vnfd1-deployment_c4_0_9dd6e15b-8f72-43e7-94c0-924191d99555 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.13; DI-INTERNAL2=192.168.2.14; DI-INTERNAL1=192.168.1.4; tmo-autovnf2-uas-management=172.18.181.21 |
| 65344d53-de09-4b0b-89a6-85d5cfdb3a55 | vnfd1-deployment_s2_0_b2cbf15a-3107-45c7-8edf-1afc5b787132 | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.4, 192.168.10.9; SERVICE-NETWORK2=192.168.20.17, 192.168.20.6; tmo-autovnf2-uas-orchestration=172.18.180.12; DI-INTERNAL2=192.168.2.6; DI-INTERNAL1=192.168.1.12 |
| e1a6762d-4e84-4a86-a1b1-84772b3368dc | vnfd1-deployment_s3_0_882cf1ed-fe7a-47a7-b833-dd3e284b3038 | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.22, 192.168.10.14; SERVICE-NETWORK2=192.168.20.5, 192.168.20.14; tmo-autovnf2-uas-orchestration=172.18.180.14; DI-INTERNAL2=192.168.2.7; DI-INTERNAL1=192.168.1.5 |
| b283d43c-6e0c-42e8-87d4-a3af15a61a83 | vnfd1-deployment_s5_0_672bbb00-34f2-46e7-a756-52907e1d3b3d | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.21, 192.168.10.24; SERVICE-NETWORK2=192.168.20.21, 192.168.20.24; tmo-autovnf2-uas-orchestration=172.18.180.20; DI-INTERNAL2=192.168.2.13; DI-INTERNAL1=192.168.1.16 |
| 637547ad-094e-4132-8613-b4d8502ec385 | vnfd1-deployment_s6_0_23cc139b-a7ca-45fb-b005-733c98ccc299 | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.13, 192.168.10.19; SERVICE-NETWORK2=192.168.20.9, 192.168.20.22; tmo-autovnf2-uas-orchestration=172.18.180.16; DI-INTERNAL2=192.168.2.19; DI-INTERNAL1=192.168.1.21 |
| 4169438f-6a24-4357-ad39-2a35671d29e1 | vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.6; tmo-autovnf2-uas-management=172.18.181.8 |
| 30431294-c3bb-43e6-9bb3-6b377aefbc3d | vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.7; tmo-autovnf2-uas-management=172.18.181.9 |
| 28ab33d5-7e08-45fe-8a27-dfb68cf50321 | vnfd1-deployment_vnfd1-_0_f63241f3-2516-4fc4-92f3-06e45054dba0 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.3; tmo-autovnf2-uas-management=172.18.181.7 |
Stop een van de EM van het ESC en controleer of het de SHUTOFF-STAAT is binnengegaan.
[admin@vnfm1-esc-0 esc-cli]$ /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli vm-action STOP vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
[admin@vnfm1-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_INERT_STATE</state>
vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
VM_SHUTOFF_STATE
<vm_name>vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>vnfd1-deployment_vnfd1-_0_f63241f3-2516-4fc4-92f3-06e45054dba0</vm_name>
<state>VM_ALIVE_STATE</state>
Wanneer de EM de SHUTOFF-STAAT is binnengegaan, start de andere EM opnieuw op vanuit de OpenStack Platform Director (OSPD).
[stack@director ~]$ nova reboot --hard vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a
Request to reboot server <Server: vnfd2-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a> has been accepted.
Meld u nogmaals aan bij de EM VIP en controleer de HA-status.
ubuntu@vnfd1deploymentem-0:~$ ncs_cli -u admin -C
admin@scm# show ncs-state ha
ncs-state ha mode master
ncs-state ha node-id 2-1528893823
Als de HA in "meester" staat, start de EM die eerder was Shutoff van ESC. Anders, ga verder om volgende EM van OSPD te rebooten en dan de status van Ha opnieuw te controleren.
[admin@vnfm1-esc-0 esc-cli]$ /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli vm-action START vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
[admin@vnfm1-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
VM_ALIVE_STATE
<vm_name>vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>vnfd1-deployment_vnfd1-_0_f63241f3-2516-4fc4-92f3-06e45054dba0</vm_name>
<state>VM_ALIVE_STATE</state>
Nadat u de EM vanaf ESC start, controleer de HA status van EM. Het had hersteld moeten worden.
admin@scm# em-ha-status
ha-status MASTER
admin@scm# show ncs-state ha
ncs-state ha mode master
ncs-state ha node-id 4-1516609103
ncs-state ha connected-slave [ 2-1516609363 ]
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
---------------------
2 up up up
4 up up up
Bijgedragen door Cisco-engineers
- Padmaraj RamanoudjamCisco geavanceerde services
- Partheban RajagopalCisco geavanceerde services
 Feedback
FeedbackContact Cisco
- Een ondersteuningscase openen

- (Vereist een Cisco-servicecontract)