QvPC-DI에서 iftask 및 NPU 성능 모니터링
다운로드 옵션
편견 없는 언어
본 제품에 대한 문서 세트는 편견 없는 언어를 사용하기 위해 노력합니다. 본 설명서 세트의 목적상, 편견 없는 언어는 나이, 장애, 성별, 인종 정체성, 민족 정체성, 성적 지향성, 사회 경제적 지위 및 교차성에 기초한 차별을 의미하지 않는 언어로 정의됩니다. 제품 소프트웨어의 사용자 인터페이스에서 하드코딩된 언어, RFP 설명서에 기초한 언어 또는 참조된 서드파티 제품에서 사용하는 언어로 인해 설명서에 예외가 있을 수 있습니다. 시스코에서 어떤 방식으로 포용적인 언어를 사용하고 있는지 자세히 알아보세요.
이 번역에 관하여
Cisco는 전 세계 사용자에게 다양한 언어로 지원 콘텐츠를 제공하기 위해 기계 번역 기술과 수작업 번역을 병행하여 이 문서를 번역했습니다. 아무리 품질이 높은 기계 번역이라도 전문 번역가의 번역 결과물만큼 정확하지는 않습니다. Cisco Systems, Inc.는 이 같은 번역에 대해 어떠한 책임도 지지 않으며 항상 원본 영문 문서(링크 제공됨)를 참조할 것을 권장합니다.
소개
이 문서에서는 QvPC-DI에서 iftask/NPU의 성능을 모니터링하는 방법에 대해 설명합니다.
또한 iftask의 몇 가지 주요 개념에 대한 자세한 정보를 제공합니다.
사용되는 구성 요소
이 문서의 정보는 QvPC-DI를 기반으로 합니다.
이 문서의 정보는 특정 랩 환경의 디바이스를 토대로 작성되었습니다. 이 문서에 사용된 모든 디바이스는 초기화된(기본) 컨피그레이션으로 시작되었습니다. 현재 네트워크가 작동 중인 경우 모든 명령의 잠재적인 영향을 미리 숙지하시기 바랍니다.
Iftask 아키텍처
iftask는 QvPC-DI의 프로세스입니다. DPDK(Data Plane Development Kit) 기능을 DI 네트워크 포트 및 서비스 포트에 대해 SF(Service Function Virtual Card) 및 CF(Control Function Virtual Card)에서 활성화합니다. DPDK는 가상화된 환경에서 입력/출력을 보다 효율적으로 처리할 수 있는 방법입니다.
이제 고성능 NIC(Network Interface Controller)의 디바이스 드라이버가 userspace로 이동되므로 값비싼 컨텍스트 스위치(userspace/kernelspace)가 필요하지 않습니다.
드라이버는 사용자 공간에서 비중단 모드로 실행되며 스레드는 이러한 NIC 드라이버의 HW 큐/링 버퍼에 직접 액세스할 수 있습니다.
아키텍처에 대한 설명서는 다음에서 확인할 수 있습니다.
Ultra Gateway Platform System Administration Guide의 USP(Ultra Services Platform) 소개.
이 다이어그램에는 작업 아키텍처(SF용)가 나와 있습니다.
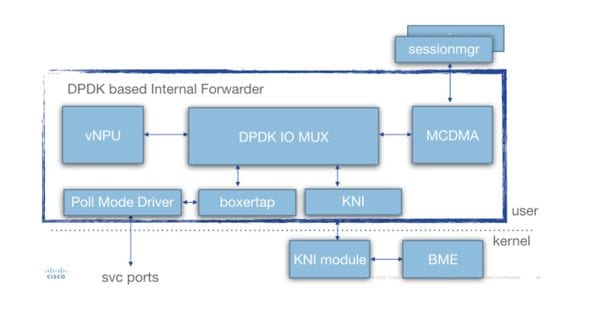
다양한 구성 요소가 있습니다.
PMD(폴링 모드 드라이버): 이는 NIC(SR-IOV의 경우) 또는 SW 링 버퍼(virtio/vmxnet 인터페이스 유형의 경우)에서 HW 큐를 지속적으로 폴링하는 기능입니다. 따라서 이러한 PMD와 연결된 CPU가 100%로 계속 페깅됩니다.
구축 과정에서 iftask에 할당된 CPU의 nr과 iftask 내의 다양한 기능은 param.cfg 파일을 통해 정적으로 할당될 수 있습니다.
Boxertap: 패킷이 들어오는 위치에 따라 패킷에 staros 메타데이터(MEH 헤더)를 연결/제거(예: Di 포트/서비스 포트) 및 전송 위치(예: 로컬 vNPU)
IOMUX: 모든 대상(sessmgr/ports/vNPU/...)이 있는 BIA 라이브러리가 있습니다. 이 기능은 기본적으로 BIA를 기반으로 패킷을 라우팅하는 것입니다
vNPU: -flow 분류/조회. 이는 HW 기반 시스템의 NPU와 유사합니다(ASR5000/ASR5500).
vNPU의 플로우는 vNPU에서 액세스할 수 있는 공유 메모리에 있는 NPUmgr(demuxmgr/sessmgr 등으로부터 해당 정보를 가져옴)에 의해 계속 프로그래밍됩니다.
- 또한 npumgr/essmgr이 통계/구성을 위해 vNPU를 폴링할 수 있도록 API가 생성됩니다.
MCDMA: sessmgr로 향하는 패킷은 (사용 가능한 다양한 MCDMA 코어/스레드를 통해) MCDMA 인터페이스에 기록됩니다. 그런 다음 이러한 패킷은 DMA를 통해 essmgr에 사용할 수 있게 됩니다. 따라서 커널은 제한된 방식으로만 사용되므로 실질적인 성능 향상이 가능합니다. 이에 대해서는 이 글에서 더 자세히 설명하고 있다.
MCDMA는 또한 일괄 처리 기능(한 시스템 통화에서 많은 패킷을 처리하기 위해)을 제공합니다.
KNI: linux 커널로 이동해야 하는 패킷의 인터페이스(DI 제어/ARP/icmp/라우팅/...)
Iftask 패킷 흐름
아래 다이어그램은 컨트롤 플레인 패킷의 패킷 흐름에 대해 설명합니다. 예: GTPv2 세션 생성 요청
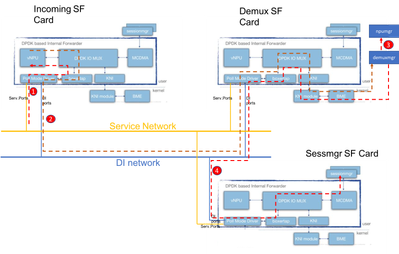
1단계: GTPv2 CSR 패킷은 사용 가능한 SF의 서비스 포트를 통해 들어옵니다. 서비스 인터페이스 NIC의 Rx 대기열에 배치되고 iftask 프로세스의 PMD 코어 중 하나에 의해 선택됩니다. Boxertap이 MEH 헤더를 넣고, 패킷이 흐름 조회를 위해 IOMux를 통해 로컬 vNPU로 전달됩니다.
이 세션은 새 세션이므로 vNPU에는 이에 대해 프로그래밍된 특정 플로우가 없으며, 패킷을 demux 카드의 demux mgr로 라우팅해야 합니다.
2단계: vNPU가 MEH 헤더를 변경합니다(관련 demux 프로세스에 대한 새 BIA 사용). IOMUX는 DI 네트워크를 통해 디먹스 카드를 향해 이 정보를 전송해야 한다는 것을 알고 있습니다. Iftask 프로세스가 Demux 카드의 수신 패킷을 처리하고 IOMux가 이를 KNI 모듈(커널을 향하는 인터페이스)로 라우팅합니다. 커널을 통해 결국에는 demuxmgr 프로세스(이 경우 egtpinmgr)로 끝납니다.
3단계: Demuxmgr에서 작업을 수행합니다. sessmgr을 선택하고 후속 GTPv2 패킷에 대한 흐름과 함께 npumgr을 프로그래밍합니다
모든 카드의 vNPU는 npumgr이 이러한 흐름을 프로그래밍하는 데 사용하는 공유 메모리에 액세스할 수 있습니다.
4단계: 이제 GTPv2 CSR이 선택한 sessmgr로 전달됩니다. MEH가 다시 변경되어 DI 넷에서 Sessmgr SF 카드를 향해 Demux 카드에서 전달됩니다. 해당 카드의 IOMUX 프로세스는 MCDMA 인터페이스를 통해 선택한 세션으로 패킷을 전달합니다. 앞으로 sessmgr은 이 세션의 모든 GTPv2 트래픽을 처리합니다. GTPU TEID가 협상되면 후속 GTPU 패킷이 수신 SF 카드에서 essmgr SF 카드로 직접 이동할 수 있도록 NPUmgr을 통한 흐름을 프로그래밍합니다.
vCPU가 iftask에 있음
구축 과정에서 특정 양의 가상 중앙 처리 장치(vCPU)가 iftask 프로세스에 정적으로 할당됩니다. 따라서 사용자 공간 애플리케이션(sessmgr 등)의 코어 수가 감소하지만 I/O 성능이 크게 향상됩니다.
이 할당은 구축 중에 각 SF/CF와 연결된 param.cfg 템플릿의 아래 매개 변수를 통해 수행됩니다.
- IFTASK_CORES(%의 사용 가능한 코어가 iftask에 할당됨)
- (IFTASK_CRYPTO_CORES - (EPDG의 경우 암호화 처리에 할당할 사용 가능한 코어의 비율)
- (IFTASK_MCDMA_CORES - (MCDMA 기능에 할당된 코어 수에 추가 조정)
- SF에서 iftask 프로세스는 내부적으로 할당된 코어를 다음과 같이 분산합니다.
- PMD(Poll Mode Drivers) vCPU(tx/rx/vnpu 활동 수행)
- MCDMA vCPU, iftask에서 ssmgr 및 back으로 패킷 전송
- CF에서 MCDMA vCPU는 필요하지 않습니다. SF는 sessmgr 프로세스를 호스팅하지 않기 때문입니다.
'show cloud hardware iftask' 명령은 QVPC-DI 구축에서 이에 대한 자세한 정보를 제공합니다.
[local]UGP# show cloud hardware iftask Card 1: Total number of cores on VM: 8 Number of cores for PMD only: 0 Number of cores for VNPU only: 0 Number of cores for PMD and VNPU: 2 <-- CF: 2 out of 8 cores are assigned to iftask PMD/VNPU Number of cores for MCDMA: 0 <-- CF: no cores allocated to MCDMA as there is no sessmgr process on CF Number of cores for Crypto: 0 Hugepage size: 2048 kB Total hugepages: 3670016 kB NPUSHM hugepages: 0 kB CPU flags: avx sse sse2 ssse3 sse4_1 sse4_2 Poll CPU's: 1 2 KNI reschedule interval: 5 us ... Card 3: Total number of cores on VM: 8 Number of cores for PMD only: 0 Number of cores for VNPU only: 0 Number of cores for PMD and VNPU: 2 <-- SF: 2 out of 8 core are assigned to iftask PMD/VNPU
Number of cores for MCDMA: 1 <-- SF: 1 out of 8 cores is assigned to iftak MCDMA
Number of cores for Crypto: 0
Hugepage size: 2048 kB
Total hugepages: 4718592 kB
NPUSHM hugepages: 0 kB
CPU flags: avx sse sse2 ssse3 sse4_1 sse4_2
Poll CPU's: 1 2 3
KNI reschedule interval: 5 us
'show cloud configuration' 명령은 사용된 매개변수에 대한 자세한 정보를 제공합니다.
[local]UGP# show cloud configuration Card 1: Config Disk Params: ------------------------- CARDSLOT=1 CPUID=0 CARDTYPE=0x40010100 DI_INTERFACE=BOND:TYPE:ixgbevf-1,TYPE:ixgbevf-2 DI_INTERFACE_VLANID=2111 VNFM_INTERFACE=MAC:fa:16:3e:23:aa:e9 VNFM_PROXY_ADDRS=172.16.180.3,172.16.180.5,172.16.180.6 MGMT_INTERFACE=MAC:fa:16:3e:87:23:9b VNFM_IPV4_ENABLE=true VNFM_IPV4_DHCP_ENABLE=true Local Params: ------------------------- CARDSLOT=1 CARDTYPE=0x40010100 CPUID=0 ... Card 3: Config Disk Params: ------------------------- CARDSLOT=3 CPUID=0 CARDTYPE=0x42030100 DI_INTERFACE=BOND:TYPE:ixgbevf-1,TYPE:ixgbevf-2 SERVICE1_INTERFACE=BOND:TYPE:ixgbevf-3,TYPE:ixgbevf-4 SERVICE2_INTERFACE=BOND:TYPE:ixgbevf-5,TYPE:ixgbevf-6 DI_INTERFACE_VLANID=2111 VNFM_INTERFACE=MAC:fa:16:3e:29:c6:b7 IFTASK_CORES=30 VNFM_IPV4_ENABLE=true VNFM_IPV4_DHCP_ENABLE=true Local Params: ------------------------- CARDSLOT=3 CARDTYPE=0x42010100 CPUID=0
설계 고려 사항:
iftask에 vCPU를 할당할 때 고려해야 할 여러 가지 요소가 있습니다.
- SF에 사용할 수 있는 총 vCPU 수 vs. iftask vCPU: 기본 구성은 param.cfg 파일의 IFTASK_CORES 매개 변수를 통해 iftask에 연결된 vCPU의 30%를 지정합니다. 그러나 이는 애플리케이션(MME vs SPGW vs ePDG) —> 엔지니어링과 협의할 애플리케이션에 따라 달라질 수 있습니다.
-iftask vCPU가 PMD에 할당되고 iftask vCPU가 MCDMA에 할당됩니다. 이것이 균형이 맞는지 확인하려면 아래의 iftask 성능 섹션을 참조하십시오.
-iftask MCDMA vCPU와 모든 애플리케이션의 나머지 vCPU 비교. 일반적으로 애플리케이션에 대한 나머지 vCPU에 대해 iftask MCDMA vCPU의 1/x 분포를 갖는 것이 좋습니다(sessmgr/aaamgr/...).
예:
SF에서 사용할 수 있는 총 코어 38개:
-14 iftask(6PMD, 8CDMA)에 할당
- 다른 프로세스에 24개 할당
즉, 각 3개의 애플리케이션 vCPU에 대해 1개의 MCDMA vCPU가 있습니다.
이는 각 MCDMA vCPU에 대한 동일한 로딩을 보장하는 데 도움이 된다.
iftask 성능 모니터링
iftask 프로세스는 여러 가지 방법으로 모니터링할 수 있습니다.
show 명령 목록 통합:
show subscribers data-rate show npumgr dinet utilization pps show npumgr dinet utilization pps show cloud monitor di-network summary show cloud hardware iftask show cloud configuration show iftask stats summary show port utilization table show npu utilization table show npumgr utilization information show processes cpu
명령 #show cpu info verbose는 iftask 코어에 대한 정보를 제공하지 않습니다. 항상 사용률 100%로 나열됩니다.
아래 예에서 코어 1,2,3은 iftask와 연관되어 있으며 사용률 100%로 나열되어 있으므로 이는 예상된 결과입니다.
Card 3, CPU 0:
Status : Standby, Kernel Running, Tasks Running
Load Average : 3.12, 3.12, 3.13 (3.95 max)
Total Memory : 16384M
Kernel Uptime : 4D 21H 56M
Last Reading:
CPU Usage All : 1.9% user, 0.3% sys, 0.0% io, 0.0% irq, 97.8% idle
Core 0 : 5.8% user, 0.2% sys, 0.0% io, 0.0% irq, 94.0% idle
Core 1 : Not Averaged (Poll CPU)
Core 2 : Not Averaged (Poll CPU)
Core 3 : Not Averaged (Poll CPU)
Core 4 : 2.2% user, 0.2% sys, 0.0% io, 0.0% irq, 97.6% idle
Core 5 : 0.8% user, 0.5% sys, 0.0% io, 0.0% irq, 98.7% idle
Core 6 : 0.4% user, 0.5% sys, 0.0% io, 0.0% irq, 99.1% idle
Core 7 : 0.1% user, 0.3% sys, 0.0% io, 0.0% irq, 99.6% idle
Poll CPUs : 3 (1, 2, 3)
Core 1 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Core 2 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Core 3 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Processes / Tasks : 143 processes / 16 tasks
Network mcdmaN : 0.002 kpps rx, 0.001 mbps rx, 0.002 kpps tx, 0.001 mbps tx
File Usage : 1504 open files, 1627405 available
Memory Usage : 7687M 46.9% used
Memory Details:
Static : 330M kernel, 144M image
System : 10M tmp, 0M buffers, 54M kcache, 79M cache
Process/Task : 6963M (120M small, 684M huge, 6158M other)
Other : 104M shared data
Free : 8696M free
Usable : 5810M usable (8696M free, 0M reclaimable, 2885M reserved by tasks)명령 #show npu 사용률 테이블은 iftask 프로세스(각 카드)와 관련된 각 코어의 사용률을 잘 요약합니다.
참고: 여기서 중요한 것은 일부 코어가 다른 코어보다 일관되게 활용도가 높은지 확인하는 것입니다.
[local]UGP# show npu utilization table
-------iftask-------
lcore now 5min 15min
-------- ------ ------ ------
01/0/1 0% 0% 0%
01/0/2 0% 0% 0%
02/0/1 0% 0% 0%
02/0/2 2% 1% 0%
03/0/1 0% 0% 0%
03/0/2 0% 0% 0%
03/0/3 0% 0% 0%
04/0/1 0% 0% 0%
04/0/2 0% 0% 0%
04/0/3 0% 0% 0%
05/0/1 0% 0% 0%
05/0/2 0% 0% 0%
05/0/3 0% 0% 0%명령 #show npumgr 사용률 정보(숨겨진 명령)
이 명령은 각 iftask core 및 해당 core에서 CPU를 소비하는 요소에 대한 자세한 정보를 제공합니다.
참고: PMD 코어는 PortRX, PortTX, KNI, Cipher에서 CPU를 사용하고 있습니다. MCDMA 코어는 MCDMA에서 CPU를 사용하고 있습니다.
PMD 및 MCDMA 코어 모두 상당히 균일한 로드를 가져야 합니다.
그렇지 않으면 일부 튜닝이 필요할 수 있습니다(예: 더 많거나 적은 MDMA 코어 할당).
******** show npumgr utilization information 3/0/0 *******
5-Sec Avg: lcore01| lcore02| lcore03| lcore04| lcore05| lcore06| lcore07| lcore08| lcore09| lcore10| lcore11| lcore12| lcore13| lcore14| lcore15| lcore16|
Idle: 31%| 37%| 32%| 35%| 41%| 48%| 47%| 38%| 57%| 56%| 55%| 56%| 46%| 56%| 54%| 52%|
PortRX: 28%| 26%| 27%| 26%| 0%| 0%| 0%| 0%| 12%| 14%| 11%| 11%| 0%| 0%| 0%| 0%|
PortTX: 5%| 5%| 6%| 5%| 8%| 8%| 8%| 14%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
KniRX: 6%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
Kni: 1%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
McdmaRX: 0%| 0%| 0%| 0%| 34%| 29%| 29%| 32%| 0%| 0%| 0%| 0%| 35%| 28%| 28%| 28%|
Mcdma: 0%| 0%| 0%| 0%| 11%| 7%| 4%| 6%| 0%| 0%| 0%| 0%| 14%| 7%| 7%| 7%|
Vnpu: 28%| 29%| 28%| 32%| 0%| 0%| 0%| 0%| 30%| 28%| 33%| 28%| 0%| 0%| 0%| 0%|
McdmaFlush: 0%| 0%| 0%| 0%| 6%| 8%| 12%| 10%| 0%| 0%| 0%| 0%| 6%| 10%| 11%| 14%|
Cipher: 1%| 2%| 6%| 2%| 0%| 0%| 0%| 0%| 1%| 2%| 1%| 5%| 0%| 0%| 0%| 0%|
rx kbits/sec: 728563| 736103| 647535| 626595| 811362| 698724| 717147| 799281| 617199| 595268| 623670| 633132| 819270| 672732| 790849| 719498|
rx frames/sec: 94409| 95586| 91107| 84997| 109526| 97466| 98557| 107690| 81122| 82076| 86959| 87960| 114114| 96198| 108108| 100259|
tx kbits/sec: 715038| 722181| 634227| 614221| 827124| 712740| 731329| 814782| 605373| 583318| 611001| 620328| 835692| 686575| 806395| 733924|
tx frames/sec: 94310| 95491| 90969| 84896| 109526| 97466| 98557| 107690| 81002| 81986| 86858| 87859| 114114| 96198| 108108| 100259|
5-Min Avg: ...
15-Min Avg: ...자세한 설명:
CPU는 서비스 포트 또는 DI 포트를 통해 iftask 프로세스에 들어오는 패킷에 대해 다음과 같이 설명됩니다.
Vnpu 조회는 CPU가 가장 많이 사용되는 부분입니다.
Vnpu 조회 후:
- 패킷은 MCDMA 코어로 전송되며, CPU 시간은 관련 MCDMA 코어의 McdmaRx에서 고려됩니다.
-패킷이 다른 iftask core로 전송되면 Vnpu에서 CPU 시간을 고려합니다
-패킷이 동일한 작업 코어에 전송되면 PortRx에서 CPU 시간을 고려합니다
-패킷이 동일한 작업 코어로 전송되면 CPU 시간이 KniRx에서 처리됩니다.
PortRx에는 수신 큐에서 패킷을 빼내고 필요한 곳으로 디스패치/큐잉하기 위한 상당한 일반 오버헤드도 포함됩니다
npumgr #show 사용률 pps, #show npumgr dinet 사용률 bps 및 #show 포트 사용률 테이블 명령
DI 포트의 로드 및 서비스 포트에 대한 정보를 제공합니다.
실제 성능은 NIC/CPU 및 iftask에 대한 CPU 할당에 따라 달라집니다.
[local]UGP# show npumgr dinet utilization pps
------ Average DINet Port Utilization (in kpps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/0 Virtual Ethernet 0 0 0 0 0 0
2/0 Virtual Ethernet 0 0 0 0 0 0
3/0 Virtual Ethernet 0 0 0 0 0 0
4/0 Virtual Ethernet 0 0 0 0 0 0
5/0 Virtual Ethernet 0 0 0 0 0 0
[local]UGP# show npumgr dinet utilization bps
------ Average DINet Port Utilization (in mbps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/0 Virtual Ethernet 1 1 1 1 1 1
2/0 Virtual Ethernet 1 0 1 0 1 0
3/0 Virtual Ethernet 0 0 0 0 0 0
4/0 Virtual Ethernet 0 0 0 0 0 0
5/0 Virtual Ethernet 0 0 0 0 0 0
[local]UGP# show port utilization table
------ Average Port Utilization (in mbps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/1 Virtual Ethernet 0 0 0 0 0 0
2/1 Virtual Ethernet 0 0 0 0 0 0
3/10 Virtual Ethernet 0 0 0 0 0 0
3/11 Virtual Ethernet 0 0 0 0 0 0
4/10 Virtual Ethernet 0 0 0 0 0 0
4/11 Virtual Ethernet 0 0 0 0 0 0
5/10 Virtual Ethernet 0 0 0 0 0 0
5/11 Virtual Ethernet 0 0 0 0 0 0명령 #show cloud monitor di-network 요약
이 명령은 DI 네트워크의 상태를 모니터링합니다. 카드가 서로 하트비트를 전송하고 손실이 모니터링됩니다. 건강한 시스템에서는 손실이 보고되지 않습니다.
[local]UGP# show cloud monitor di-network summary Card 3 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 4 Good 0.00% 0.00% 5 Good 0.00% 0.00% Card 4 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 3 Good 0.00% 0.00% 5 Good 0.00% 0.00% Card 5 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 3 Good 0.00% 0.00% 4 Good 0.00% 0.00%
명령 #show iftask stats summary
NPU 로드가 높으면 트래픽이 삭제될 수 있습니다.
이를 평가하기 위해 명령 #show iftask stats summary 출력을 사용할 수 있습니다.
참고: DISCARDS는 0이 아닐 수 있으며 다른 모든 카운터는 0으로 유지하는 것이 좋습니다.
[local]VPC# show iftask stats summary Thursday January 18 16:01:29 IST 2018 ----------------------------------------------------------------------------------------------- Counter SF3 SF4 SF5 SF6 SF7 SF8 SF9 SF10 SF11 SF12 ___TOTAL___ ------------------------------------------------------------------------------------------------ svc_rx 32491861127 16545600654 37041906441 37466889835 32762859630 34931554543 38861410897 16025531220 33566817747 32823851780 312518283874 svc_tx 46024774071 14811663244 40316226774 39926898585 40803541378 48718868048 35252698559 1738016438 4249156512 40356388348 312198231957 di_rx 42307187425 14637310721 40072487209 39584697117 41150445596 44534022642 31867253533 1731310419 4401095653 40711142205 300996952520 di_tx 28420090751 16267050562 36423298668 36758561246 32731606974 30366650898 35201117980 16009902791 33536789041 32815316570 298530385481 __ALL_DROPS__ 1932492 252 17742 790473 11228 627018 844812 60402 0 460830 4745249 svc_tx_drops 0 0 0 0 0 0 0 0 0 0 0 di_rx_drops 0 1 0 0 49 113 579 30200 0 4888 35830 di_tx_drops 0 0 0 0 0 0 0 0 0 0 0 sw_rss_enq_drops 0 0 0 0 0 0 0 0 0 0 0 kni_thread_drops 0 0 0 0 0 0 0 0 0 0 0 kni_drops 0 1 0 0 0 0 124 30200 0 0 30325 mcdma_drops 0 0 0 168 80 194535 758500 0 0 11628 964911 mux_deliver_hop_drops 0 0 0 0 0 0 0 0 0 1019 1019 mux_deliver_drops 0 0 0 0 0 0 0 0 0 0 0 mux_xmit_failure_drops 0 3 0 0 0 0 7 2 0 0 12 mc_dma_thread_enq_drops 0 0 0 0 49 113 580 0 0 3457 4199 sw_tx_egress_enq_drops 1904329 0 0 787971 9004 429214 85022 0 0 429810 3645350 cpeth0_drops 0 0 0 0 0 0 0 0 0 0 0 mcdma_summary_drops 28163 247 17742 2334 2046 3043 0 0 0 10028 63603 fragmentation_err 0 0 0 0 0 0 0 0 0 0 0 reassembly_err 0 0 0 0 0 0 0 0 0 0 0 reassembly_ring_enq_err 0 0 0 0 0 0 0 0 0 0 0 __DISCARDS__ 20331090 9051092 23736055 23882896 23807520 24231716 24116576 8944291 22309474 20135799 20135799
SW-RSS 및 HW-RSS
RSS는 NIC에서 오는 인바운드 트래픽을 여러 DPDK 프로세서에 분산할 수 있는 기능입니다. 일반적으로 NIC는 HW에서 RSS를 지원하므로 여러 iftask core에 트래픽을 분산할 수 있습니다.
Staros의 iftask 프로세스는 다음과 같은 경우 사용 가능한 소프트웨어 버전의 rss를 구현했습니다.
-nic는 HW rss를 지원하지 않으므로 모든 tx/rx 트래픽은 단일 iftask CPU에 상주합니다.
-nic에 충분한 tx/rx 큐가 없습니다(iftask에 할당된 사용 가능한 tx/rx CPU보다 적은 큐). 이 경우 SW-RSS(포괄적)는 rx/tx에 할당된 작업 코어가 있는 경우 사용 가능한 모든 코어에 적절한 배포를 활성화합니다.
이 기능은 서비스 포트를 통해 들어오는 트래픽에만 작동합니다. DI 트래픽은 고려되지 않습니다.
3가지 컨피그레이션 모드가 있습니다.
-no iftask sw-rss - sw-rss disabled. 시스템은 HW RSS를 사용합니다.
-iftask sw-rss 포괄적 - 모든 트래픽에 sw rss 사용 소프트웨어 RSS는 하드웨어 RSS와 함께 실행할 수 있습니다. HW RSS를 비활성화할 필요가 없습니다. 그러나 SW RSS는 iftask 코어에 대한 서비스 트래픽의 실제 로드 밸런싱을 담당합니다.
-iftask sw-rss supplemental - hw-rss에서 지원되지 않는 트래픽에 대해서만 sw rss 사용(예: MPLS 트래픽)
HW와 SW RSS를 모두 사용하면 트래픽이 다양한 iftask/dpdk 프로세서로 해시되는 방식을 이해하는 것이 중요합니다.
하드웨어 RSS: 해싱은 하드웨어에 따라 다릅니다. 다음은 그 예입니다.
[root@host]# ethtool -n enp10s0f1
4 RX rings available
Total 0 rules
[root@host] # ethtool -n enp10s0f0 rx-flow-hash udp4
UDP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA
소프트웨어 RSS: Staros 21.6부터 SW RSS 버전 해싱은 다음과 같이 동작합니다.
1. In case of IPV6
we only support L3( IP src/dst ) based hashing (same as the old behaviour).
2. In case of IPV4
a. For TCP we support IP src/dst + tcp ports src/dst
b. For UDP fragmented - only IP src/dst
c. For UDP non-fragmented not gtpu ( I.e. Port !=2152) ? IP src/dst + udp port src/dst
d. For UDP non-fragmented and gtpu ( I.e. Port ==2152) - IP src/dst + udp port src/dst + gtp tunnel id
e. Any other protocol ? we default back to IP src/dst
중요: 암호화된 DI 트래픽의 RSS:
SW-RSS(보완/포괄적)가 없을 경우 모든 암호화된 DI 트래픽이 iftask의 단일 코어로 해시될 수 있습니다.
이로 인해 이 코어가 다른 코어보다 지속적으로 사용률이 높습니다.
CSCvi 이후06080  이제 이 컨피그레이션 명령으로 이를 완화할 수 있습니다.
이제 이 컨피그레이션 명령으로 이를 완화할 수 있습니다.
iftask di-net-encrypt-rss
CSCvm 통합 41257 , 이 옵션은 기본값으로 설정됩니다.
SW RSS에 대한 자세한 정보:
sw-rss의 목적은 PMD 코어를 로드 밸런싱하고 다른 코어가 상당한 가용 용량을 가지고 있을 때 하나의 PMD 코어가 최대 한계에 도달하는 처리량 제한 시나리오를 피하는 것입니다.
모든 서비스 포트 인그레스 패킷이 NIC에서 제거되고 PMD 코어가 도착한 Rx 대기열을 서비스하는 MEH 캡슐화가 제공됩니다.
이때 작업을 통해 패킷을 전송할 위치를 알 수 없습니다. 내부 대상을 확인하려면 VNPU에서 패킷을 처리해야 합니다. VNPU로 전달될 때 거의 모든 이러한 패킷이 IOC/플로우 조회를 거칩니다. 이 예외는 구성되지 않았거나 비활성화된 vlan 또는 유효하지 않은 대상 MAC(L3 포워딩 시나리오도 있지만, 이는 일반적이지 않음)와 같은 이유로 폐기되는 것과 관련이 있습니다.
sw-rss가 구성되지 않은 경우, VNPU IOC/플로우 조회 처리는 MEH 캡슐화 바로 뒤에 있는 동일한 코어에서 발생합니다. sw-rss가 구성된 경우 패킷은 해시를 기반으로 하는 VNPU 처리를 위해 코어로 대기됩니다. VNPU IOC/플로우 조회 작업은 가장 비용이 많이 드는 단일 iftask 함수입니다. sw-rss를 사용하면 모든 PMD 코어에서 작업 로드의 균형을 맞출 수 있습니다.
VNPU IOC/플로우 조회에 따라, 패킷은 DINet 전송을 통해 다른 SF로 전송되거나 MCDMA 전송을 통해 로컬 앱으로 대기됩니다(예외도 있지만 이 논의와 관련이 있다고 생각하지 않음).
다른 SF로 전송된 패킷은 DINet Rx 다음에 대상 카드의 적절한 MCDMA 채널로 직접 대기됩니다. 두 번째 VNPU 패스는 필요하지 않습니다.
TX/RX 큐
iftask 로그에서는 다음과 같은 로그를 볼 수 있습니다.
Tue May 7 15:26:48 2019 PID:8188 APP: max rx queues supported 16 ...
Tue May 7 15:26:48 2019 PID:8188 APP: max tx queues supported 8 ...
Tue May 7 15:26:48 2019 PID:8188 APP: hw rx requested 2 ...
Tue May 7 15:26:48 2019 PID:8188 APP: hw tx requested tx 5
이는 실제 하드웨어가 지원하는 rx 및 tx 큐의 지원되는 수와 작업 요청을 수신하는 tx/rx 큐의 수와 관련됩니다.
어떤 iftask 요청이 iftask에 할당된 프로세서 수와 밀접한 관련이 있습니까?
참고: 운전자마다 다릅니다. 일부 쿼리 호스트는 하드코딩되어 있습니다.
hw tx requested count는 dpdk가 사용 중인 코어 수입니다. dpdk에 컨트롤/ipc 스레드가 실행되는 코어가 포함되므로 일반적으로 iftask에 할당된 총 코어보다 1개가 더 많습니다. 이 코어는 boxer와 공유되며 범용 cpu로 예약됩니다(dpdk 컨트롤/ipc 스레드는 많은 cpu를 사용하지 않음).
hw rx 요청 카운트는 일반적으로 PMD 코어의 수입니다.
Iftask는 각 포트에 대해 min(requested, max)을 할당하고 코어에서 배포합니다. 분산 알고리즘이 좀 복잡합니다. 작업 부하를 최대한 균등하게 모든 코어에 분산시키는 것이 목표입니다.
Iftask txbatch
Release 21.9 이후 staros에는 일괄 처리(트래픽 집계)에 중요한 다음과 같은 기본 iftask 컨피그레이션 옵션이 있습니다. 이는 노드가 단일(또는 소수의) 가입자로 테스트 중인 경우 성능에 다소 부정적인 영향을 미칩니다.
# iftask mcdmatxbatch burst size 32 # iftask mcdmatxbatch latency 200 # iftask txbatch burst size 32 # iftask txbatch latency 200
이에 대한 자세한 설명은 별개입니다.
Bulkstats
Bulkstat 계획은 iftask/dinet과 관련된 QPVC-DI 성능을 위해 개발되었다. 이 기능은 성능/로드 관점에서 디넷, 서비스 포트 및 npu 활용도를 모니터링하는 데 유용합니다.
card schema iftask-dinet format EMS,IFTASKDINET,%date%,%time%,%dinet-rxpkts-curr%,%dinet-txpkts-curr%,%dinet-rxpkts-5minave%,%dinet-txpkts-5minave%,%dinet-rxpkts-15minave%,%dinet-txpkts-15minave%,%dinet-txdrops-curr%,%dinet-txdrops-5minave%,%dinet-txdrops-15minave%,%npuutil-now% file 2 port schema iftask-port format EMS,IFTASKPORT,%date%,%time%,%util-rxpkts-curr%,%util-txpkts-curr%,%util-rxpkts-5min%,%util-txpkts-5min%,%util-rxpkts-15min%,%util-txpkts-15min%,%util-txdrops-curr%,%util-txdrops-5min%,%util-txdrops-15min% file 3 card schema npu-util format EMS,NPUUTIL,%date%,%time%,%npuutil-now%,%npuutil-5minave%,%npuutil-15minave%,%npuutil-rxbytes-5secave%,%npuutil-txbytes-5secave%,%npuutil-rxbytes-5minave%,%npuutil-txbytes-5minave%,%npuutil-rxbytes-15minave%,%npuutil-txbytes-15minave%,%npuutil-rxpkts-5secave%,%npuutil-txpkts-5secave%,%npuutil-rxpkts-5minave%,%npuutil-txpkts-5minave%,%npuutil-rxpkts-15minave%,%npuutil-txpkts-15minave%
개정 이력
| 개정 | 게시 날짜 | 의견 |
|---|---|---|
1.0 |
09-Jun-2018
|
최초 릴리스 |
 피드백
피드백