소개
이 문서에서는 Cisco RTMT(Real-Time Monitoring Tool) 알림에 대해 설명하고 자주 발생하는 알림의 트러블슈팅 방법을 설명합니다.
사전 요구 사항
요구 사항
Cisco Call Manager 웹 관리에 대한 지식이 있는 것이 좋습니다.
사용되는 구성 요소
이 문서의 정보는 Cisco CallManager Server 11.0을 기반으로 합니다.
이 문서의 정보는 특정 랩 환경의 디바이스를 토대로 작성되었습니다. 이 문서에 사용된 모든 디바이스는 초기화된(기본) 컨피그레이션으로 시작되었습니다. 현재 네트워크가 작동 중인 경우, 모든 명령어의 잠재적인 영향을 미리 숙지하시기 바랍니다.
배경 정보
클라이언트 측 애플리케이션으로 실행되는 RTMT는 시스템 성능, 장치 상태, 장치 검색, CTI(Computer Telephony Integration) 애플리케이션 및 음성 메시징 포트를 모니터링하기 위해 HTTPS 및 TCP를 사용합니다. RTMT는 모니터링 중인 클러스터에 대한 알림을 구성하는 데 사용할 수 있습니다.
시스템은 활성화된 서비스가 위에서 아래로 이동할 때와 같이 미리 정의된 조건이 충족될 때 관리자에게 알리기 위해 알림 메시지를 생성합니다. 시스템에서 알림을 이메일/이메일 페이지로 보낼 수 있습니다.
경고 정의, 설정 및 보기를 지원하는 RTMT에는 미리 구성된 사용자 정의 경고가 포함되어 있습니다. 두 유형 모두에 대해 컨피그레이션 작업을 수행할 수 있지만 사전 구성된 경고는 삭제할 수 없습니다.
RTMT 알림
Unified RTMT는 이미지에 표시된 대로 Alert Central에 사전 구성된 경고와 사용자 지정 경고를 모두 표시합니다.
시스템 드로어의 계층 트리에서 Alert Central 아이콘을 클릭하여 Alert Central에 액세스할 수도 있습니다.
구성
Unified RTMT는 해당 탭 아래에 알림을 구성합니다. System, CallManager, Cisco Unity Connection, Custom을 제공합니다.
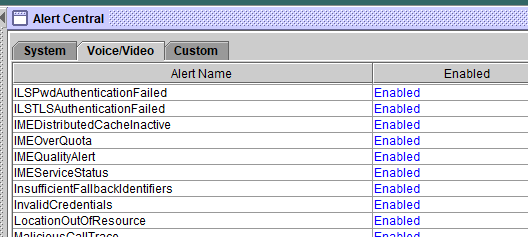
Alert Central에서 사전 구성된 경고 및 사용자 지정 경고를 활성화하거나 비활성화할 수 있습니다. 그러나 미리 구성된 경고는 삭제할 수 없습니다.
RTMT의 경고는 다음과 같이 분류됩니다.
시스템 경고
이 목록은 사전 구성된 시스템 알림으로 구성됩니다.
-
인증 실패
-
CiscoDRF장애
-
CoreDumpFileFound
-
Cpu페깅
-
중요 감사 이벤트 생성됨
-
중요 서비스 중단
-
하드웨어장애
-
LogFileSearchString찾음
-
LogPartitionHighWaterMarkExceeded
-
LogPartitionLowWaterMarkExceeded
-
낮은 활성 파티션 사용 가능 디스크 공간
-
저가용가상메모리
-
낮은 비활성 파티션 사용 가능 디스크 공간
-
LowSwapPartition사용 가능한 디스크 공간
-
ServerDown(CUCM(Unified Communications Manager) 클러스터에 적용됨)
-
SparePartitionHighWaterMarkExceeded
-
SparePartitionLowWaterMarkExceeded
-
SyslogSeverityMatchFound
-
SyslogStringMatchFound
-
SystemVersion불일치
-
TotalProcessesAndThreadExceededThreshold
CallManager 알림
이 목록은 사전 구성된 CallManager 알림으로 구성됩니다.
- BeginThrottlingCallListBLFS등록
- CallAttemptBlockedByPolicy
- 통화 처리노드페깅
- 카드엔진크리티컬
- CSR 장애
- CARSschedulerJobFailed(CARschedulerJobFailed)
- CDRAgentSendFileFailed(CDRAgentSendFile실패)
- CDRFileDeliveryFailed
- CDRHhighWaterMarkExceeded
- CDRMaximumDiskSpaceExceeded
- 코드노랑
- DBCchangeNotifyFailure
- DBR복제실패
- DBR복제 테이블 출력
- DDRBlockPrevention
- DDRD소유
- EMCCF실패로컬클러스터입니다.
- EMCCF실패된원격 클러스터
- ExcessiveVoiceQuality 보고서
- IMEDidistributedCacheInactive
- IMEOver할당량
- IMEQualityAlert
- InsufficientFallbackIdentifier(불충분한 폴백 식별자)
- IMES서비스상태
- 유효하지 않은 자격 증명
- 낮은 TFTPServerHeartbeatRate
- 악의적인 통화 추적
- 미디어 목록모두 사용됨
- MgcpDC채널서비스 중단
- 등록된 디바이스 수 초과
- NumberOfRegisteredGatewaysDecreated(등록된 게이트웨이 수 감소)
- 등록된게이트웨이수증가
- 등록된 미디어 장치 수 감소됨
- 등록된 미디어 장치 수Increated
- 등록된 전화 수Dropped
- 경로 목록 소진
- SDLLinkOutOfService
- TCPSetupToIMEF실패
- TLSConnectionToIMEFfailed
- 사용자 입력 실패
LowAvailableVirtualMemory 및 LowSwapPartitionAvailableDiskSpace
Linux 서버는 일정 기간 동안 가상 메모리 사용량을 '확인'하지 못하는 경향이 있으며, 이에 따라 경고가 누적되는 것으로 나타났습니다.
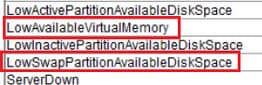
리눅스는 운영 체제로서의 운영방식이 조금 다르다.
일단 메모리가 프로세스에 할당되면 다른 프로세스에서 사용 가능한 메모리보다 많은 메모리를 요청하지 않는 한 프로세서에서 메모리를 회수하지 않습니다.
이로 인해 가상 메모리가 증가합니다.
상위 버전의 call manager에서 경보에 대한 임계값을 늘려야 한다는 요청이 결함에 기록되었습니다. https://bst.cloudapps.cisco.com/bugsearch/bug/CSCuq75767/?reffering_site=dumpcr.
스왑 파티션의 경우 이 알림은 스왑 파티션이 사용 가능한 공간이 부족하고 시스템에서 많이 사용하고 있음을 나타냅니다. 스왑 파티션은 일반적으로 필요한 경우 물리적 RAM 용량을 확장하는 데 사용됩니다. 정상적인 조건에서는 RAM이 충분한 경우 스왑을 너무 많이 사용하지 않아야 합니다.
또한 임시 파일의 빌드업으로 인해 발생하는 RTMT 알림이 발생할 수 있습니다. 불필요한 임시 파일을 지우려면 서버를 재부팅하는 것이 좋습니다.
LogPartitionHighWaterMarkExceeded 및 LogPartitionLowWaterMarkExceeded
CUCM 서버의 CLI에서 show status를 실행하면 CUCM 디스크 공간에서 사용 중인 로깅 파티션과 사용 가능한 로깅 파티션 비율을 지정하는 값이 표시됩니다. 공통 파티션이라고도 하는 이 값은 로그/추적 및 CDR 파일이 서버에 차지하는 공간을 지정합니다. 이 값은 무해하지만 시간이 지남에 따라 공간이 부족하여 설치/업그레이드 절차에서 문제를 일으킬 수 있습니다. 이러한 경고는 클러스터/서버에서 시간이 지남에 누적되었을 수 있는 로그를 삭제하라는 관리자에게 경고의 역할을 합니다.
LogPartitionLowWaterMarkExceeded: 이 경보는 채워진 공간이 경보에 대해 구성된 임계값에 도달할 때 생성됩니다. 이 알림은 디스크 사용량에 대한 사전 검사 표시기의 역할을 합니다.
LogPartitionHighWaterMarkExceeded: 이 알림은 채워진 공간이 알림에 대해 구성된 임계값에 도달할 때 생성됩니다. 경고가 생성되면 서버는 HighWaterMark 임계값보다 작은 공간을 값까지 줄이기 위해 가장 오래된 로그를 자동 삭제하기 시작합니다.
모범 사례는 LogPartitionLowWaterMarkExceeded 알림을 받는 즉시 로그를 수동으로 삭제하는 것입니다.
이를 위한 단계는 다음과 같습니다.
1단계. RTMT를 시작합니다.
2단계. Alert Central을 선택한 다음 다음 작업을 수행합니다.
LogPartitionHighWaterMarkExceeded를 선택하고 해당 값을 기록하고 임계값을 60%로 변경합니다.
LogPartitionLowWaterMarkExceeded를 선택하고 해당 값을 기록하고 임계값을 50%로 변경합니다.
폴링은 5분마다 수행되므로 5~10분 정도 기다렸다가 필요한 디스크 공간을 사용할 수 있는지 확인합니다. 공통 파티션에서 더 많은 디스크 공간을 확보하려면 LogPartitionHighWaterMarkExceeded 및 LogPartitionLowWaterMarkExceeded 스레드 값을 더 낮은 값(예: 30% 및 20%)으로 다시 변경합니다.
15분에서 20분 정도 시간을 두고 일반 칸막이의 공간을 비워라. CLI의 show status 명령을 사용하여 디스크 사용량 감소를 모니터링할 수 있습니다.
그러면 공통 파티션이 다운될 것입니다.
Cpu페깅
CpuPegging 알림은 구성된 임계값을 기반으로 CPU 사용량을 모니터링합니다.
CPU 페깅 경고가 수신되면 가장 높은 CPU를 차지하는 프로세스를 왼쪽 시스템 드로어, 즉 프로세스로 이동하여 사용할 수 있습니다.
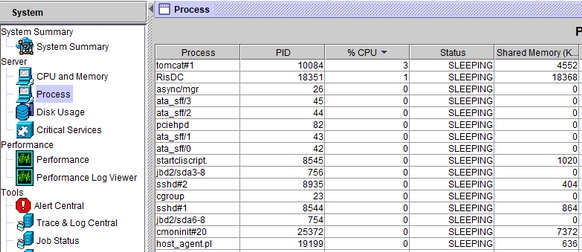
해당 서버의 CLI에서 이러한 출력은 몇 가지 통찰력을 제공합니다.
- 유틸리티 진단 테스트
- 프로세스 로드 cpu 정렬 표시
- 상태 표시
- 유틸리티 핵심 활성 목록
CPU 스파이크가 특정 시간에 발생하는지 무작위로 발생하는지 관찰하는 것이 좋습니다. 무작위로 발생할 경우 필요한 자세한 CUCM 추적과 RisDC 성능 로그를 확인하여 CPU의 스파이크를 유발하는 요소가 무엇인지 확인합니다. 하루 중 특정 시간에 알림이 발생하는 경우 DRS(Disaster Recovery System) 백업, CDR 로드 등과 같은 일부 예약된 작업 때문일 수 있습니다.
또한 어떤 프로세스가 CPU를 가장 많이 차지하는지에 대한 정보를 바탕으로 추가 조사를 위해 특정 로그를 취한다. 예: 범인이 Tomcat인 경우 Tomcat 관련 로그가 필요합니다.
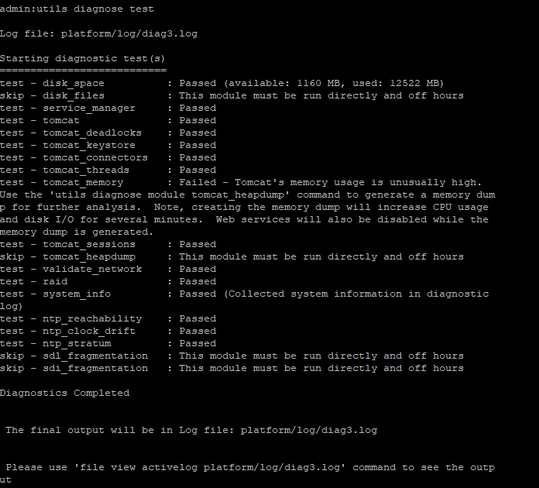
다음을 확인합니다.
구성이 올바르게 작동하는지 확인하려면 이 섹션을 활용하십시오.
여기에 제시된 해결 방법을 수행한 후에도 알림이 해제되지 않거나 알림이 서비스에 즉각적인 영향을 미치는 것으로 보이는 경우, Call Manager 버전, 클러스터의 노드 수, 알림 시간 및 기간, CPU 페깅 시 필요한 프로세스 축소 등에 대한 필요한 세부 정보를 Cisco TAC에 문의하십시오.
문제 해결
현재 이 설정에 사용할 수 있는 특정 문제 해결 정보가 없습니다.
 피드백
피드백