소개
이 문서에서는 DLP(Data Loss Prevention) 데이터 분류에서 오탐을 줄이기 위해 Data Matching Exclusions를 사용하는 방법을 설명합니다.
개요
Data Matching Exclusions(데이터 일치 제외)를 사용하면 일치하는 특정 데이터를 제외할 수 있으므로 DLP 데이터 분류를 세부적으로 조정하고 오탐을 크게 줄일 수 있습니다. 이 기능은 DLP 검사에서 알려진, 민감하지 않은 데이터 또는 관련되지 않은 일치를 제외하여 더 정확한 데이터 보호를 제공합니다.
데이터 일치 제외가 오탐을 최소화하는 방법
기본 제공 식별자 및 사용자 지정 식별자는 키워드 또는 패턴이 중요하지 않은 데이터와 일치할 때 오탐을 생성할 수 있습니다. 예를 들면 다음과 같습니다.
- 숫자 기반 식별자:
미국 SSN(Social Security Number)과 같은 식별자는 내부 계정 ID와 같은 다른 9자리 번호와 일치할 수 있습니다. 알려진 계정 ID를 제외하면 이러한 오탐이 줄어듭니다.
- 텍스트 기반 식별자:
HIPAA 준수 데이터 분류를 사용하는 의료 고객은 "암 기부 조직"과 같이 환자가 아닌 상황에서 "암"이라는 용어를 탐지할 수 있습니다. 이러한 잘못된 알림을 방지하기 위해 특정 용어를 제외할 수 있습니다.
Data Matching Exclusions를 사용하여 용어 또는 regex 패턴을 지정할 수 있습니다. 이에 대한 일치가 데이터 위반 이벤트를 트리거하지 않도록 합니다. 이를 통해 DLP 알림을 정밀하게 제어할 수 있습니다.
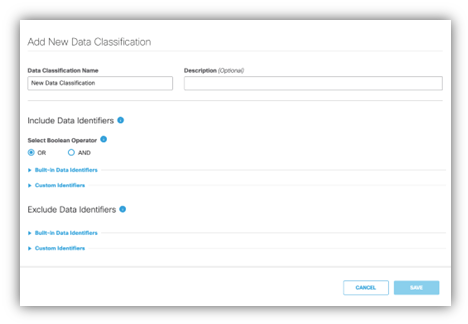
데이터 일치 제외 사용 방법
-
Umbrella 대시보드에서 Data Classification(데이터 분류) 페이지로 이동합니다.
-
Exclude Data Identifier 섹션에서 제외할 사용자 지정 식별자 또는 기본 제공 식별자를 선택합니다.
-
제외할 특정 용어 또는 정규식 패턴을 입력합니다.
- 제외는 전체 문서가 아닌 일치하는 특정 컨텐츠에만 적용됩니다.
- 예를 들어 "암 기증 단체"를 제외할 경우 해당 용어만 위반에서 제외되고 나머지 문서는 계속 검사됩니다.
-
동일한 데이터 식별자가 동일한 분류에 포함되고 제외되는 경우 제외가 우선권을 갖습니다.
관련 리소스
단계별 지침은 Umbrella 설명서를 참조하십시오. 데이터 분류를 생성합니다.
 피드백
피드백