StarOS VNFのCeph停止影響分析
ダウンロード オプション
偏向のない言語
この製品のドキュメントセットは、偏向のない言語を使用するように配慮されています。このドキュメントセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブ ランゲージの取り組みの詳細は、こちらをご覧ください。
翻訳について
シスコは世界中のユーザにそれぞれの言語でサポート コンテンツを提供するために、機械と人による翻訳を組み合わせて、本ドキュメントを翻訳しています。ただし、最高度の機械翻訳であっても、専門家による翻訳のような正確性は確保されません。シスコは、これら翻訳の正確性について法的責任を負いません。原典である英語版(リンクからアクセス可能)もあわせて参照することを推奨します。
内容
概要
このドキュメントでは、Cisco Virtualized Infrastructure Manager(VIM)上で稼働するStarOS VNFが、Cephストレージサービスの障害に影響を受ける方法と、その影響を軽減するために実行できる方法について説明します。これは、Cisco VIMがインフラストラクチャとして使用されているものの、同じ理論を任意のOpenstack環境に適用できることを前提として説明されています。
前提条件
要件
次の項目に関する知識があることが推奨されます。
- Cisco StarOS
- Cisco VIM
- Openstack
- セフ
使用するコンポーネント
このドキュメントの情報は、次のソフトウェアとハードウェアのバージョンに基づいています。
- StarOS:21.16.c9
- Cisco VIM:3.2.2(Openstackキュー)
このドキュメントの情報は、特定のラボ環境にあるデバイスに基づいて作成されました。このドキュメントで使用するすべてのデバイスは、初期(デフォルト)設定の状態から起動しています。本稼働中のネットワークでは、各コマンドによって起こる可能性がある影響を十分確認してください。
省略形
| Cisco VIM | Cisco 仮想インフラストラクチャ マネージャ |
| VNF | 仮想ネットワーク機能 |
| Ceph OSD | Cephオブジェクトストレージデーモン |
| StarOS | Cisco Mobile Packet Coreソリューションのオペレーティングシステム |
Cisco VIMのCeph
この画像は、『Cisco VIM Administrator Guide』から取得したものです。Cisco VIMはストレージバックエンドとしてCephを使用します。
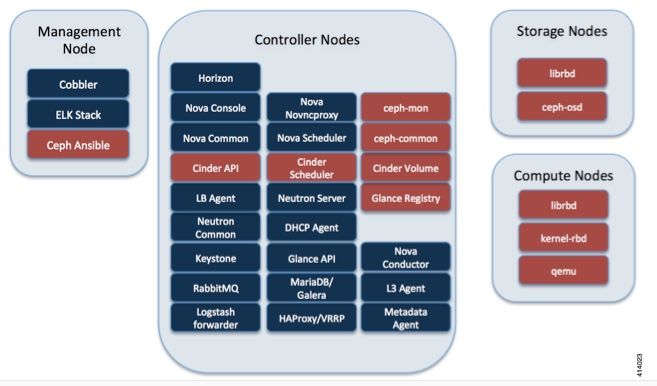
Cephはブロックとオブジェクトストレージの両方をサポートしているため、VMに接続できるVMイメージとボリュームを保存するために使用されます。ストレージバックエンドに依存する複数のOpenStackサービスには、次のものがあります。
- 概要(OpenStackイメージサービス):Cephを使用してイメージを保存します。
- Cinder(OpenStackストレージサービス):Cephを使用して、VMに接続できるボリュームを作成します。
- Nova(OpenStackコンピューティングサービス):Cinderによって作成されたボリュームにCephを使用して接続します。
多くの場合、この例のように、ボリュームはCeph for /flashおよび/hd-raid for StarOS VNFで作成されます。
openstack volume create --image `glance image-list | grep up-image | awk '{print $2}'` --size 16 --type LUKS up1-flash-boot
openstack volume create --size 20 --type LUKS up1-hd-raid
Cephの監視メカニズムの基礎
モニタリングに関するCephドキュメントの説明を次に示します。
各Ceph OSDデーモンは、他のCeph OSDデーモンのハートビートを6秒未満のランダム間隔でチェックします。隣接するCeph OSDデーモンが20秒間の猶予期間内にハートビートを表示しない場合、Ceph OSDデーモンは隣接するCeph OSDデーモンをダウンと見なし、Cephクラスタマップを更新するCephモニタに報告します。デフォルトでは、異なるホストの2つのCeph OSDデーモンは、Ceph Monitorsが報告されたCeph OSDデーモンがダウンしたことを確認する前に、別のCeph OSDデーモンがダウンしていることをCeph Monitorsに報告する必要があります。
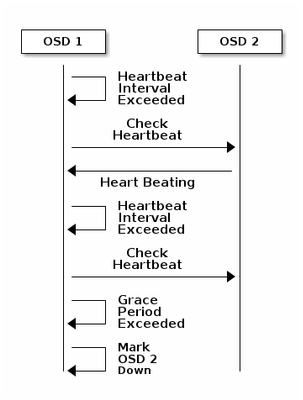
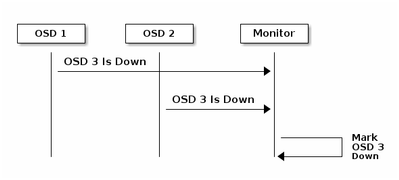
一般的に、OSDのダウンを検出するのに約20秒かかり、このVNFが新しいOSDを使用できるようになってからCephクラスタマップが更新されます。このディスク期間中、I/Oはブロックされます。
StarOS VNFでのブロッキングI/Oの影響
ディスクI/Oが120秒以上ブロックされると、StarOS VNFがリブートします。xfssyncd/md0およびxfs_dbプロセスに関する特定のチェックがあります。これらのプロセスで120秒以上のスタックが検出されると、ディスクI/OおよびStarOSが意図的にリブートします。
StarOSデバッグコンソールログ:
[ 1080.859817] INFO: task xfssyncd/md0:25787 blocked for more than 120 seconds.
[ 1080.862844] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
[ 1080.866184] xfssyncd/md0 D ffff880c036a8290 0 25787 2 0x00000000
[ 1080.869321] ffff880aacf87d30 0000000000000046 0000000100000a9a ffff880a00000000
[ 1080.872665] ffff880aacf87fd8 ffff880c036a8000 ffff880aacf87fd8 ffff880aacf87fd8
[ 1080.876100] ffff880c036a8298 ffff880aacf87fd8 ffff880c0f2f3980 ffff880c036a8000
[ 1080.879443] Call Trace:
[ 1080.880526] [<ffffffff8123d62e>] ? xfs_trans_commit_iclog+0x28e/0x380
[ 1080.883288] [<ffffffff810297c9>] ? default_spin_lock_flags+0x9/0x10
[ 1080.886050] [<ffffffff8157fd7d>] ? _raw_spin_lock_irqsave+0x4d/0x60
[ 1080.888748] [<ffffffff812301b3>] _xfs_log_force_lsn+0x173/0x2f0
[ 1080.891375] [<ffffffff8104bae0>] ? default_wake_function+0x0/0x20
[ 1080.894010] [<ffffffff8123dc15>] _xfs_trans_commit+0x2a5/0x2b0
[ 1080.896588] [<ffffffff8121ff64>] xfs_fs_log_dummy+0x64/0x90
[ 1080.899079] [<ffffffff81253cf1>] xfs_sync_worker+0x81/0x90
[ 1080.901446] [<ffffffff81252871>] xfssyncd+0x141/0x1e0
[ 1080.903670] [<ffffffff81252730>] ? xfssyncd+0x0/0x1e0
[ 1080.905871] [<ffffffff81071d5c>] kthread+0x8c/0xa0
[ 1080.908815] [<ffffffff81003364>] kernel_thread_helper+0x4/0x10
[ 1080.911343] [<ffffffff81580805>] ? restore_args+0x0/0x30
[ 1080.913668] [<ffffffff81071cd0>] ? kthread+0x0/0xa0
[ 1080.915808] [<ffffffff81003360>] ? kernel_thread_helper+0x0/0x10
[ 1080.918411] **** xfssyncd/md0 stuck, resetting card
ただし、120秒のタイマーに限定されません。ディスクI/Oがしばらくブロックされた場合、120秒未満でも、さまざまな理由でVNFがリブートする場合があります。次の出力例は、ディスクI/Oの問題によるリブート、時には継続的なStarOSタスククラッシュなどを示しています。アクティブなディスクI/Oとストレージの問題のタイミングによって異なります。
[ 2153.370758] Hangcheck: hangcheck value past margin!
[ 2153.396850] ata1.01: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6 frozen
[ 2153.396853] ata1.01: failed command: WRITE DMA EXT
--- skip ---
SYSLINUX 3.53 0x5d037742 EBIOS Copyright (C) 1994-2007 H. Peter Anvin
基本的に、ロングブロッキングI/OはStarOS VNFにとって重要な問題と考えられ、可能な限り最小限に抑える必要があります。
ロングブロッキングI/Oシナリオ
複数のお客様による導入およびラボテストの調査に基づいて、Cephで長いブロッキングI/Oを引き起こす可能性がある2つの主要なシナリオが確認されています。
ラギー・タイマー・メカニズム
OSD間にはハートビートメカニズムがあり、OSDをダウン状態で検出できます。osd_heartbeat_graceの値に基づき(デフォルトでは20秒)、OSDが失敗として検出されます。
また、OSDステータスに揺らぎやフラップが発生すると、graceタイマーが自動的に調整(長くなる)されます。 これにより、osd_heartbeat_graceの値が大きくなる可能性があります。
通常の状況では、ハートビートの猶予は20秒です
2019-01-09 16:58:01.715155 mon.ceph-XXXXX [INF] osd.2 failed (root=default,host=XXXXX) (2 reporters from different host after 20.000047 >= grace 20.000000)
ただし、ストレージノードの複数のネットワークフラップが発生すると、その値が大きくなります。
2019-01-10 16:44:15.140433 mon.ceph-XXXXX [INF] osd.2 failed (root=default,host=XXXXX) (2 reporters from different host after 256.588099 >= grace 255.682576)
上の例では、OSDがダウンしたことを検出するのに256秒かかります。
RAIDカードハードウェア障害
Cephは、RAIDカードのハードウェア障害をタイムリーに検出できない可能性があります。RAIDカードの障害は、一種のOSDのハング状態に終わります。この場合、StarOS VNFをリブートするのに十分な数分でOSDがダウンしたことが検出されます。
RAIDカードがハングすると、一部のCPUコアのWAステータスが100 %になります。
%Cpu20 : 2.6 us, 7.9 sy, 0.0 ni, 0.0 id, 89.4 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu21 : 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu22 : 31.3 us, 5.1 sy, 0.0 ni, 63.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu23 : 0.0 us, 0.0 sy, 0.0 ni, 28.1 id, 71.9 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu24 : 0.0 us, 0.0 sy, 0.0 ni, 0.0 id,100.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu25 : 0.0 us, 0.0 sy, 0.0 ni, 0.0 id,100.0 wa, 0.0 hi, 0.0 si, 0.0 st
また、すべてのCPUコアを徐々に消費し、OSDも徐々にタイムギャップを持ってダウンします。
2019-01-01 17:08:05.267629 mon.ceph-XXXXX [INF] Marking osd.2 out (has been down for 602 seconds)
2019-01-01 17:09:25.296955 mon.ceph-XXXXX [INF] Marking osd.4 out (has been down for 603 seconds)
2019-01-01 17:11:10.351131 mon.ceph-XXXXX [INF] Marking osd.7 out (has been down for 604 seconds)
2019-01-01 17:16:40.426927 mon.ceph-XXXXX [INF] Marking osd.10 out (has been down for 603 seconds)
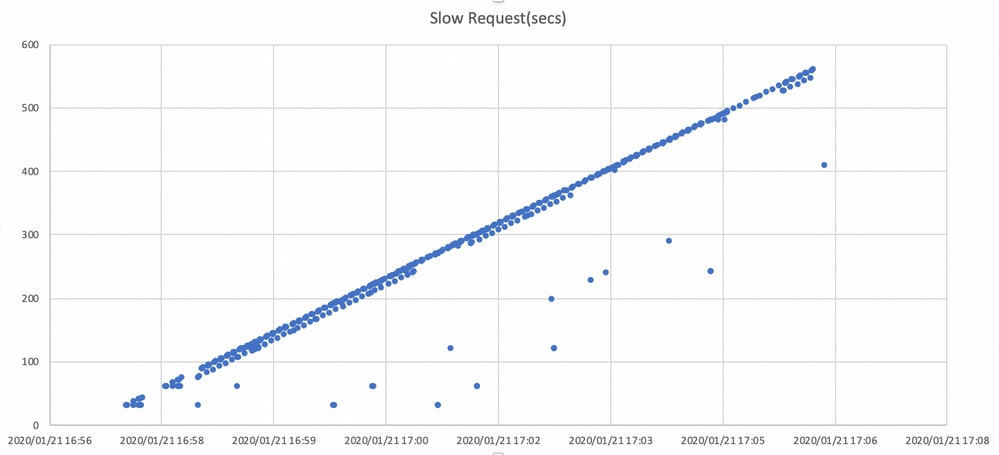
並行して、遅い要求はceph.logで検出されます。
2019-01-01 16:57:26.743372 mon.XXXXX [WRN] Health check failed: 1 slow requests are blocked > 32 sec. Implicated osds 2 (REQUEST_SLOW)
2019-01-01 16:57:35.129229 mon.XXXXX [WRN] Health check update: 3 slow requests are blocked > 32 sec. Implicated osds 2,7,10 (REQUEST_SLOW)
2019-01-01 16:57:38.055976 osd.7 osd.7 [WRN] 1 slow requests, 1 included below; oldest blocked for > 30.216236 secs
2019-01-01 16:57:39.048591 osd.2 osd.2 [WRN] 1 slow requests, 1 included below; oldest blocked for > 30.635122 secs
-----skip-----
2019-01-01 17:06:22.124978 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 554.285311 secs
2019-01-01 17:06:25.114453 osd.4 osd.4 [WRN] 19 slow requests, 1 included below; oldest blocked for > 546.221508 secs
2019-01-01 17:06:26.125459 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 558.285789 secs
2019-01-01 17:06:27.125582 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 559.285915 secs
このグラフは、I/O要求がタイムラインでブロックされる時間を示しています。グラフは、ceph.logに低速の要求ログをプロットすることによって作成されます。これは、ブロック時間が時間とともに長くなっていることを示します。
影響を軽減する方法
Cephストレージからローカルディスクに移動
最も簡単に影響を軽減する方法は、Cephストレージからローカルディスクに移動することです。StarOSは/flashと/hd-raidの2つのディスクを使用し、/flashのみをローカルディスクに移動できます。これにより、StarOS VNFはCephの問題に対してより堅牢になります。Cephなどの共有ストレージを使用する場合のマイナス面は、問題が発生すると、その共有ストレージを使用するすべてのVNFに同時に影響が及びます。ローカルディスクを使用することで、ストレージの問題の影響を最小限に抑え、影響を受けるノードでのみ実行できる。また、前のセクションで説明したシナリオはCephのみに適用されるため、ローカルディスクには適用されません。ただし、ローカルディスクの裏面は、StarOSイメージ、設定、コアファイル、課金レコードなどのディスクの内容は、VMの再配置時に保持できません。VNF自動修復メカニズムにも影響を与える可能性があります。
Ceph設定の調整
StarOS VNFの観点からは、上記のブロッキングI/O時間を最小限に抑えるために、次の新しいCephパラメータが推奨されます。
<デフォルト設定>
"mon_osd_adjust_heartbeat_grace": "true",
"osd_client_watch_timeout": "30",
"osd_max_markdown_count": "5",
"osd_heartbeat_grace": "20",
<新しい設定>
"mon_osd_adjust_heartbeat_grace": "false",
"osd_client_watch_timeout": "10",
"osd_max_markdown_count": "1",
"osd_heartbeat_grace": "10",
この構成は次のとおりです。
- 遅れタイマーのメカニズムが無効で、自動調整が行われない
- ハートビートの猶予時間が短縮されます
- OSDはすぐにダウンとしてマークされます(デフォルトでは過去600秒で5回)
新しいパラメータはラボでテストされ、OSDがダウンする検出時間は約10秒未満に短縮されました。当初はデフォルト設定のCephで約30秒でした。
RAIDカードハードウェアの問題の監視
RAIDカードのハードウェアシナリオでは、I/Oがブロックされている間にOSDが断続的に動作する状況が発生するため、問題の性質としてタイムリーに検出することは困難である場合があります。これに対する単一のソリューションはありませんが、RAIDカードの障害に対するサーバハードウェアログや、一部のスクリプトによるceph.logの低速な要求ログを監視し、影響を受けるOSDをプロアクティブにダウンさせるなどのアクションを実行することをお勧めします。
CEPH_OSD_RESEREVED_PCORESチューニング
これは前述のシナリオとは関係ありませんが、I/Oの高負荷が原因でCephのパフォーマンスに問題がある場合は、CEPH_OSD_RESEAVED_PCORESの値を増やすとCeph I/Oのパフォーマンスが向上します。デフォルトでは、Cisco VIM上のCEPH_OSD_RESEAVED_PCORESは2に設定され、増やすことができます。
シスコ エンジニア提供
- Tomonobu OkadaCisco TAC Engineer
- Satoshi KinoshitaCisco TAC Engineer
 フィードバック
フィードバックシスコに問い合わせ
- サポート ケースをオープン

- (シスコ サービス契約が必要です。)