Guasto di un singolo disco rigido Ultra-M UCS 240M4 - Procedura di sostituzione a caldo - vEPC
Opzioni per il download
Linguaggio senza pregiudizi
La documentazione per questo prodotto è stata redatta cercando di utilizzare un linguaggio senza pregiudizi. Ai fini di questa documentazione, per linguaggio senza di pregiudizi si intende un linguaggio che non implica discriminazioni basate su età, disabilità, genere, identità razziale, identità etnica, orientamento sessuale, status socioeconomico e intersezionalità. Le eventuali eccezioni possono dipendere dal linguaggio codificato nelle interfacce utente del software del prodotto, dal linguaggio utilizzato nella documentazione RFP o dal linguaggio utilizzato in prodotti di terze parti a cui si fa riferimento. Scopri di più sul modo in cui Cisco utilizza il linguaggio inclusivo.
Informazioni su questa traduzione
Cisco ha tradotto questo documento utilizzando una combinazione di tecnologie automatiche e umane per offrire ai nostri utenti in tutto il mondo contenuti di supporto nella propria lingua. Si noti che anche la migliore traduzione automatica non sarà mai accurata come quella fornita da un traduttore professionista. Cisco Systems, Inc. non si assume alcuna responsabilità per l’accuratezza di queste traduzioni e consiglia di consultare sempre il documento originale in inglese (disponibile al link fornito).
Sommario
Introduzione
In questo documento vengono descritti i passaggi necessari per sostituire l'unità disco rigido (HDD) difettosa del server in un'installazione Ultra-M che ospita le funzioni di rete virtuale (VNF) StarOS.
Premesse
Ultra-M è una soluzione di base di pacchetti mobili preconfezionata e convalidata, progettata per semplificare l'installazione di VNF. OpenStack è Virtualized Infrastructure Manager (VIM) per Ultra-M ed è costituito dai seguenti tipi di nodi:
- Calcola
- Disco Object Storage - Compute (OSD - Compute)
- Controller
- Piattaforma OpenStack - Director (OSPD)
L'architettura di alto livello di Ultra-M e i componenti coinvolti sono illustrati in questa immagine:
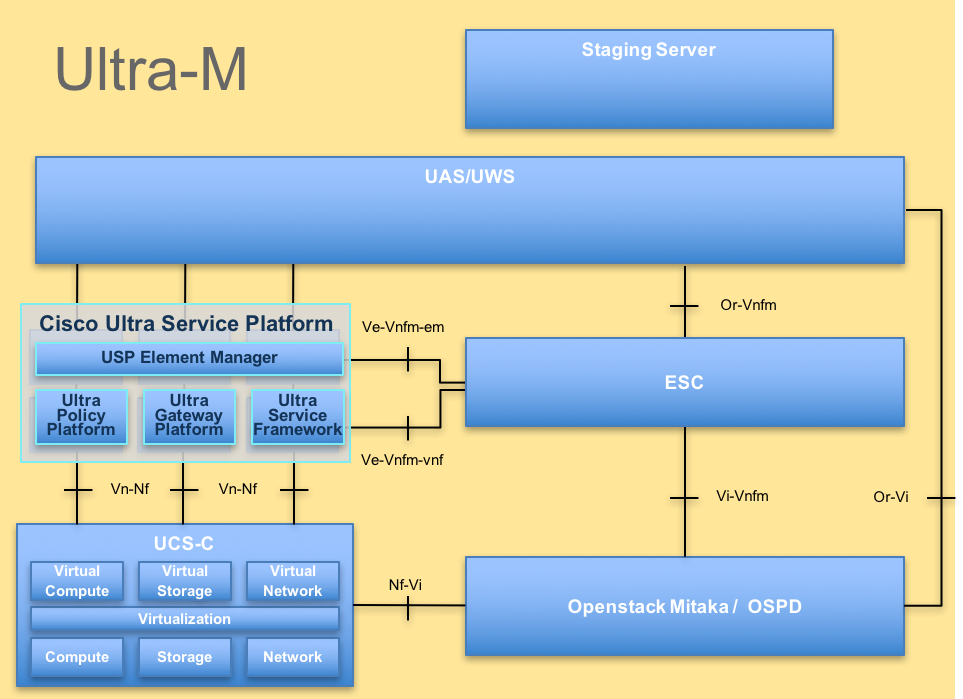 Architettura UltraMQuesto documento è destinato al personale Cisco che ha familiarità con la piattaforma Cisco Ultra-M e descrive in dettaglio i passaggi richiesti da eseguire a livello di OpenStack al momento della sostituzione del server OSPD.
Architettura UltraMQuesto documento è destinato al personale Cisco che ha familiarità con la piattaforma Cisco Ultra-M e descrive in dettaglio i passaggi richiesti da eseguire a livello di OpenStack al momento della sostituzione del server OSPD.
Nota: Per definire le procedure descritte in questo documento, viene presa in considerazione la release di Ultra M 5.1.x.
Abbreviazioni
| VNF | Funzione di rete virtuale |
| CF | Funzione di controllo |
| SF | Funzione di servizio |
| ESC | Elastic Service Controller |
| MOP | Metodo |
| OSD | Dischi Object Storage |
| HDD | Unità hard disk |
| SSD | Unità a stato solido |
| VIM | Virtual Infrastructure Manager |
| VM | Macchina virtuale |
| EM | Gestione elementi |
| UAS | Ultra Automation Services |
| UUID | Identificatore univoco universale |
Flusso di lavoro del piano di mobilità
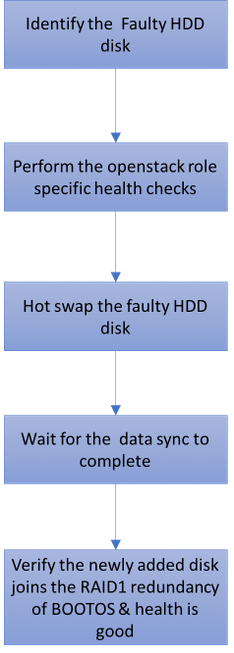
Errore di un singolo disco rigido
1. A ciascun server Baremetal vengono fornite due unità disco rigido che fungono da DISCO DI AVVIO nella configurazione Raid 1. In caso di guasto di un singolo disco rigido, poiché è presente la ridondanza di livello RAID 1, l'unità disco rigido guasta può essere sostituita a caldo.
2. La procedura per sostituire un componente guasto su un server UCS C240 M4 può essere rinviata da: Sostituzione dei componenti server.
3. In caso di guasto di un singolo disco rigido, solo il disco rigido difettoso verrà sostituito a caldo e quindi non sarà necessaria alcuna procedura di aggiornamento del BIOS dopo la sostituzione di nuovi dischi.
4. Dopo aver sostituito i dischi, attendere la sincronizzazione dei dati tra i dischi. Il completamento potrebbe richiedere ore.
5. In una soluzione basata su OpenStack (Ultra-M), il server baremetal UCS 240M4 può assumere uno dei seguenti ruoli: Compute, OSD-Compute, Controller e OSPD. Le procedure richieste per gestire il guasto di un singolo disco rigido in ciascuno di questi ruoli server sono le stesse e in questa sezione vengono descritti i controlli di stato da eseguire prima dell'hot swap del disco.
Errore di un singolo disco rigido sul server di elaborazione
1. Se il guasto delle unità disco rigido viene rilevato in UCS 240M4 che funge da nodo di calcolo, eseguire questi controlli di integrità prima di eseguire finalmente la sostituzione a caldo del disco guasto
2. Identificare le VM in esecuzione su questo server e verificare che lo stato delle funzioni sia buono.
Identificare le VM ospitate nel nodo di calcolo:
Identificare le VM ospitate nel server di elaborazione e verificare che siano attive e in esecuzione. Esistono due possibilità:
1. Il server di elaborazione contiene solo VM SF.
[stack@director ~]$ nova list --field name,host | grep compute-10
| 49ac5f22-469e-4b84-badc-031083db0533 | VNF2-DEPLOYM_s8_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d |
pod1-compute-10.localdomain | ACTIVE|
2. Il server di elaborazione contiene una combinazione CF/ESC/EM/UAS di macchine virtuali.
[stack@director ~]$ nova list --field name,host | grep compute-8
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain | ACTIVE |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c2_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain | ACTIVE |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain | ACTIVE |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain | ACTIVE |
Nota: Nell'output mostrato di seguito, la prima colonna corrisponde all'UUID, la seconda colonna è il nome della VM e la terza colonna è il nome host in cui la VM è presente.
Controlli integrità:
1. Accedere alla VNF di StarOS e identificare la scheda corrispondente alla VM SF o CF. Utilizzare l'UUID della VM SF o CF identificato nella sezione "Identificazione delle VM ospitate nel nodo di calcolo" e identificare la scheda corrispondente all'UUID.
[local]VNF2# show card hardware
Tuesday might 08 16:49:42 UTC 2018
<snip>
Card 8:
Card Type : 4-Port Service Function Virtual Card
CPU Packages : 26 [#0, #1, #2, #3, #4, #5, #6, #7, #8, #9, #10, #11, #12, #13, #14, #15, #16, #17, #18, #19, #20, #21, #22, #23, #24, #25]
CPU Nodes : 2
CPU Cores/Threads : 26
Memory : 98304M (qvpc-di-large)
UUID/Serial Number : 49AC5F22-469E-4B84-BADC-031083DB0533
<snip>
[local]VNF2# show card hardware
Tuesday might 08 16:49:42 UTC 2018
<snip>
Card 2:
Card Type : Control Function Virtual Card
CPU Packages : 8 [#0, #1, #2, #3, #4, #5, #6, #7]
CPU Nodes : 1
CPU Cores/Threads : 8
Memory : 16384M (qvpc-di-large)
UUID/Serial Number : F9C0763A-4A4F-4BBD-AF51-BC7545774BE2
<snip>
2. Verificare lo stato della carta.
[local]VNF2# show card table
Tuesday might 08 16:52:53 UTC 2018
Slot Card Type Oper State SPOF Attach
----------- -------------------------------------- ------------- ---- ------
1: CFC Control Function Virtual Card Active No
2: CFC Control Function Virtual Card Standby -
3: FC 4-Port Service Function Virtual Card Active No
4: FC 4-Port Service Function Virtual Card Active No
5: FC 4-Port Service Function Virtual Card Active No
6: FC 4-Port Service Function Virtual Card Active No
7: FC 4-Port Service Function Virtual Card Active No
8: FC 4-Port Service Function Virtual Card Active No
9: FC 4-Port Service Function Virtual Card Active No
10: FC 4-Port Service Function Virtual Card Standby -
3. Accedere all'ESC ospitato nel nodo Calcola e controllare lo stato.
[admin@VNF2-esc-esc-0 esc-cli]$ escadm status
0 ESC status=0 ESC Master Healthy
4. Accedere all'EM ospitato nel nodo Calcola e controllare lo stato.
ubuntu@vnfd2deploymentem-1:~$ ncs_cli -u admin -C
admin connected from 10.225.247.142 using ssh on vnfd2deploymentem-1
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
---------------------
3 up up up
6 up up up
5. Accedere all'UAS ospitato nel nodo Calcola e controllare lo stato.
ubuntu@autovnf2-uas-1:~$ sudo su
root@autovnf2-uas-1:/home/ubuntu# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on autovnf2-uas-1
autovnf2-uas-1#show uas ha
uas ha-vip 172.18.181.101
autovnf2-uas-1#
autovnf2-uas-1#
autovnf2-uas-1#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.18.181.101
INSTANCE IP STATE ROLE
-----------------------------------
172.18.180.4 alive CONFD-SLAVE
172.18.180.5 alive CONFD-MASTER
172.18.180.8 alive NA
autovnf2-uas-1#show errors
% No entries found.
6. Se i controlli di integrità sono corretti, procedere con la procedura di sostituzione a caldo del disco difettosa e attendere la sincronizzazione dei dati, in quanto occorrono ore per completare la procedura. Fare riferimento alla sezione Sostituzione dei componenti server.
7. Ripetere queste procedure di controllo dello stato per verificare che lo stato di integrità delle VM ospitate nel nodo di calcolo sia ripristinato.
Errore di un singolo disco rigido sul server controller
1. Se il guasto delle unità disco rigido viene rilevato in UCS 240M4 che funge da nodo di controller, seguire i controlli di integrità prima di eseguire la sostituzione a caldo del disco difettoso.
2. Controllare lo stato di Pacemaker sui controller.
3. Accedere a uno dei controller attivi e controllare lo stato del pacemaker. Tutti i servizi devono essere in esecuzione sui controller disponibili e arrestati sul controller guasto.
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-0 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Thu Jun 28 07:53:06 2018 Last change: Wed Jan 17 11:38:00 2018 by root via cibadmin on pod1-controller-0
3 nodes and 22 resources conimaged
Online: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-10.2.2.2 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.120.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
ip-11.120.0.50 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.118.0.48 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-192.200.0.102 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-0 ]
Slaves: [ pod1-controller-1 pod1-controller-2 ]
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-0
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Started pod1-controller-2
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Started pod1-controller-0
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
4. Controllare lo stato di MariaDB nei controller attivi.
[stack@director] nova list | grep control
| 4361358a-922f-49b5-89d4-247a50722f6d | pod1-controller-0 | ACTIVE | - | Running | ctlplane=192.200.0.102 |
| d0f57f27-93a8-414f-b4d8-957de0d785fc | pod1-controller-1 | ACTIVE | - | Running | ctlplane=192.200.0.110 |
[stack@director ~]$ for i in 192.200.0.102 192.200.0.110 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_state_comment'\" ; sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_cluster_size'\""; done
*** 192.200.0.152 ***
Variable_name Value
wsrep_local_state_comment Synced
Variable_name Value
wsrep_cluster_size 2
*** 192.200.0.154 ***
Variable_name Value
wsrep_local_state_comment Synced
Variable_name Value
wsrep_cluster_size 2
5. Verificare che queste righe siano presenti per ciascun controller attivo:
wsrep_local_state_comment: Synced
wsrep_cluster_size: 2
6. Controllare lo stato di Rabbitmq nei controllori attivi.
[heat-admin@pod1-controller-0 ~]$ sudo rabbitmqctl cluster_status
Cluster status of node 'rabbit@pod1-controller-0' ...
[{nodes,[{disc,['rabbit@pod1-controller-0','rabbit@pod1-controller-1',
'rabbit@pod1-controller-2']}]},
{running_nodes,['rabbit@pod1-controller-2',
'rabbit@pod1-controller-1',
'rabbit@pod1-controller-0']},
{cluster_name,<<"rabbit@pod1-controller-0.localdomain">>},
{partitions,[]},
{alarms,[{'rabbit@pod1-controller-2',[]},
{'rabbit@pod1-controller-1',[]},
{'rabbit@pod1-controller-0',[]}]}]
7. Se i controlli di integrità sono corretti, procedere con la procedura di sostituzione a caldo del disco difettosa e attendere la sincronizzazione dei dati, in quanto occorrono ore per completare la procedura. Fare riferimento alla sezione Sostituzione dei componenti server.
8. Ripetere queste procedure di controllo dello stato al fine di confermare il ripristino dello stato di salute del controller.
Errore di un singolo disco rigido su un server di elaborazione OSD
Se il guasto delle unità HDD viene rilevato in UCS 240M4 che funge da nodo OSD-Compute sn, eseguire questi controlli prima di eseguire la sostituzione a caldo del disco guasto.
Identificare le VM ospitate nel nodo di calcolo OSD:
Identificare le VM ospitate nel server di elaborazione. Esistono due possibilità:
1. Il server OSD-Compute contiene una combinazione di VM EM/UAS/Auto-Deploy/Auto-IT.
[stack@director ~]$ nova list --field name,host | grep osd-compute-0
| c6144778-9afd-4946-8453-78c817368f18 | AUTO-DEPLOY-VNF2-uas-0 | pod1-osd-compute-0.localdomain | ACTIVE |
| 2d051522-bce2-4809-8d63-0c0e17f251dc | AUTO-IT-VNF2-uas-0 | pod1-osd-compute-0.localdomain | ACTIVE |
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-osd-compute-0.localdomain | ACTIVE |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-osd-compute-0.localdomain | ACTIVE |
2. Il server di elaborazione contiene una combinazione CF/ESC/EM/UAS di macchine virtuali.
[stack@director ~]$ nova list --field name,host | grep osd-compute-1
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain | ACTIVE |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain | ACTIVE |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain | ACTIVE |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain | ACTIVE |
Nota: Nell'output mostrato di seguito, la prima colonna corrisponde all'UUID, la seconda colonna è il nome della VM e la terza colonna è il nome host in cui la VM è presente.
3. Sul server OSD-Compute sono attivi i processi Ceph.
[root@pod1-osd-compute-1 ~]# systemctl list-units *ceph*
UNIT LOAD ACTIVE SUB DESCRIPTION
var-lib-ceph-osd-ceph\x2d11.mount loaded active mounted /var/lib/ceph/osd/ceph-11
var-lib-ceph-osd-ceph\x2d2.mount loaded active mounted /var/lib/ceph/osd/ceph-2
var-lib-ceph-osd-ceph\x2d5.mount loaded active mounted /var/lib/ceph/osd/ceph-5
var-lib-ceph-osd-ceph\x2d8.mount loaded active mounted /var/lib/ceph/osd/ceph-8
ceph-osd@11.service loaded active running Ceph object storage daemon
ceph-osd@2.service loaded active running Ceph object storage daemon
ceph-osd@5.service loaded active running Ceph object storage daemon
ceph-osd@8.service loaded active running Ceph object storage daemon
system-ceph\x2ddisk.slice loaded active active system-ceph\x2ddisk.slice
system-ceph\x2dosd.slice loaded active active system-ceph\x2dosd.slice
ceph-mon.target loaded active active ceph target allowing to start/stop all ceph-mon@.service instances at once
ceph-osd.target loaded active active ceph target allowing to start/stop all ceph-osd@.service instances at once
ceph-radosgw.target loaded active active ceph target allowing to start/stop all ceph-radosgw@.service instances at once
ceph.target loaded active active ceph target allowing to start/stop all ceph*@.service instances at once
4. Verificare che la mappatura dell'OSD (disco rigido) al Journal (SSD) sia corretta.
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph-disk list
/dev/sda :
/dev/sda1 other, iso9660
/dev/sda2 other, xfs, mounted on /
/dev/sdb :
/dev/sdb1 ceph journal, for /dev/sdc1
/dev/sdb3 ceph journal, for /dev/sdd1
/dev/sdb2 ceph journal, for /dev/sde1
/dev/sdb4 ceph journal, for /dev/sdf1
/dev/sdc :
/dev/sdc1 ceph data, active, cluster ceph, osd.1, journal /dev/sdb1
/dev/sdd :
/dev/sdd1 ceph data, active, cluster ceph, osd.7, journal /dev/sdb3
/dev/sde :
/dev/sde1 ceph data, active, cluster ceph, osd.4, journal /dev/sdb2
/dev/sdf :
/dev/sdf1 ceph data, active, cluster ceph, osd.10, journal /dev/sdb4
5. Verificare che lo stato di salute di Ceph e la mappatura dell'albero OSD siano corretti.
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e709: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v941813: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 11922 GB / 13393 GB avail
704 active+clean
client io 58580 B/s wr, 0 op/s rd, 7 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
6. Se i controlli di integrità sono corretti, procedere con la procedura di sostituzione a caldo del disco difettosa e attendere la sincronizzazione dei dati, in quanto occorrono ore per completare la procedura. Fare riferimento alla sezione Sostituzione dei componenti server.
7. Ripetere queste procedure di controllo dello stato per verificare che lo stato delle VM ospitate nel nodo OSD-Compute sia ripristinato.
Errore di un singolo disco rigido sul server OSPD
1. Se il guasto delle unità disco rigido viene rilevato in UCS 240M4 che funge da nodo OSPD, eseguire questi controlli di integrità prima di avviare lo scambio a caldo del disco guasto.
2. Controllare lo stato dello stack OpenStack e l'elenco dei nodi.
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
3. Verificare che tutti i servizi di undercloud siano in stato caricato, attivo e in esecuzione dal nodo OSP-D.
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-ovs-cleanup.service loaded active exited OpenStack Neutron Open vSwitch Cleanup Utility
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
4. Se i controlli di integrità sono corretti, procedere con la procedura di hot swap su disco difettosa e attendere la sincronizzazione dei dati poiché occorrono ore per completare la procedura. Fare riferimento alla sezione Sostituzione dei componenti server.
5. Ripetere queste procedure di controllo dello stato per confermare che lo stato di salute dei nodi OSPD sia ripristinato.
Contributo dei tecnici Cisco
- Partheeban RajagopalCisco Advanced Services
- Padmaraj RamanoudjamCisco Advanced Services
 Feedback
Feedback