Monitoraggio delle prestazioni di iftask e NPU su QvPC-DI
Opzioni per il download
Linguaggio senza pregiudizi
La documentazione per questo prodotto è stata redatta cercando di utilizzare un linguaggio senza pregiudizi. Ai fini di questa documentazione, per linguaggio senza di pregiudizi si intende un linguaggio che non implica discriminazioni basate su età, disabilità, genere, identità razziale, identità etnica, orientamento sessuale, status socioeconomico e intersezionalità. Le eventuali eccezioni possono dipendere dal linguaggio codificato nelle interfacce utente del software del prodotto, dal linguaggio utilizzato nella documentazione RFP o dal linguaggio utilizzato in prodotti di terze parti a cui si fa riferimento. Scopri di più sul modo in cui Cisco utilizza il linguaggio inclusivo.
Informazioni su questa traduzione
Cisco ha tradotto questo documento utilizzando una combinazione di tecnologie automatiche e umane per offrire ai nostri utenti in tutto il mondo contenuti di supporto nella propria lingua. Si noti che anche la migliore traduzione automatica non sarà mai accurata come quella fornita da un traduttore professionista. Cisco Systems, Inc. non si assume alcuna responsabilità per l’accuratezza di queste traduzioni e consiglia di consultare sempre il documento originale in inglese (disponibile al link fornito).
Introduzione
Questo documento descrive come monitorare le prestazioni di iftask / NPU su QvPC-DI.
Vengono inoltre fornite ulteriori informazioni su alcuni concetti chiave di iftask.
Componenti usati
Le informazioni di questo documento si basano su QvPC-DI.
Le informazioni discusse in questo documento fanno riferimento a dispositivi usati in uno specifico ambiente di emulazione. Su tutti i dispositivi menzionati nel documento la configurazione è stata ripristinata ai valori predefiniti. Se la rete è operativa, valutare attentamente eventuali conseguenze derivanti dall'uso dei comandi.
Architettura Iftask
se task è un processo in QvPC-DI. Abilita la funzionalità Data Plane Development Kit (DPDK) sulla scheda virtuale della funzione di servizio (SF) e sulla scheda virtuale della funzione di controllo (CF) per le porte di rete DI e le porte di servizio. Il DPDK è un modo più efficiente per gestire gli input/output negli ambienti virtualizzati.
I driver di dispositivo dei controller di interfaccia di rete (NIC, Network Interface Controller) ad alte prestazioni vengono ora spostati nello spazio utente, evitando costosi switch di contesto (spazio utente/spazio kernel).
I driver vengono eseguiti in modalità non interrompibile nello spazio utente e i thread hanno accesso diretto alle code hardware/ai buffer circolare in questi driver NIC.
La documentazione sull'architettura è disponibile all'indirizzo:
Introduzione a Ultra Services Platform (USP) dal manuale Ultra Gateway Platform System Administration Guide.
Disponibilità per versioni diverse.
In questo diagramma è illustrata l'architettura in dettaglio (per SF):
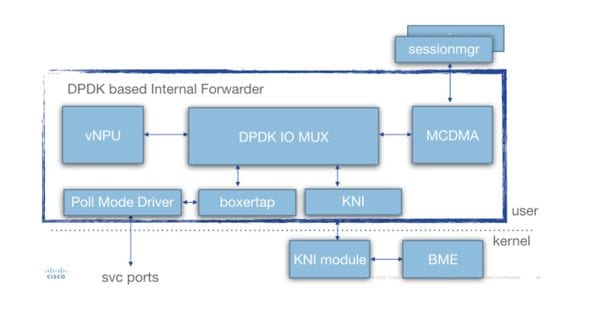
Sono presenti diversi componenti:
Driver modalità sondaggio (PMD): Questa è la funzione che esegue continuamente il polling delle code hardware dalle schede NIC (in caso di SR-IOV) o dai buffer ring del software (in caso di interfacce di tipo virtio/vmxnet). Per questo motivo, il pegging della CPU associata a questi PMD è continuo al 100%.
Durante la distribuzione, i numeri di CPU allocati a iftask e a varie funzioni all'interno di iftask possono essere allocati in modo statico tramite il file param.cfg.
Boxertap: allegare/rimuovere i metadati staros (intestazione MEH) ai pacchetti in base alla loro provenienza (ad esempio: Di (porta/porta di servizio) e dove deve essere inviato (ad esempio: vNPU locale)
IOMUX: Dispone di una libreria BIA con tutte le destinazioni (sessmgr/porte/vNPU/..). Questa funzione sta fondamentalmente instradando i pacchetti in base al loro BIA
vNPU: ricerca/classificazione del flusso. È paragonabile alla NPU dei sistemi basati su hardware (ASR5000/ASR5500).
I flussi in vNPU sono ancora programmati da NPUmgr (che ottiene le sue informazioni da demuxmgr/sessmgr ecc.) nella memoria condivisa accessibile da vNPU.
-Viene inoltre creata un'API in modo che npumgr/sessmgr possa eseguire il polling della vNPU per le statistiche/la configurazione
MCDMA: i pacchetti destinati a sessmgr vengono scritti nell'interfaccia MCDMA (tramite i vari core/thread MCDMA disponibili). Questi pacchetti vengono quindi resi disponibili a sessmgr tramite DMA. Ciò fornisce un reale aumento delle prestazioni, in quanto il kernel è coinvolto solo in modo limitato. Questa condizione viene spiegata più avanti in questo articolo.
MCDMA fornisce anche funzionalità di batch (per gestire molti pacchetti in una singola chiamata di sistema).
KNI: interfaccia per pacchetti che devono essere diretti verso il kernel linux (DI control/ARP/icmp/routing/...)
Flusso Del Pacchetto Iftask
Il diagramma seguente spiega il flusso di un pacchetto del control plane. Esempio: Richiesta creazione sessione GTPv2
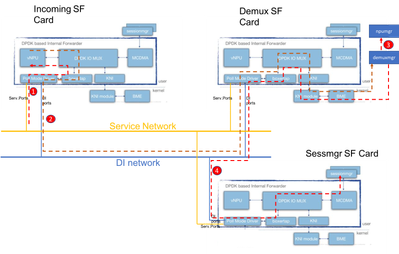
Passaggio 1: Il pacchetto CSR GTPv2 arriverà tramite la porta di servizio su uno dei SF disponibili. Verrà inserito nelle code Rx della scheda NIC dell'interfaccia di servizio e prelevato da uno dei core PMD del processo iftask. Boxertap inserirà l'intestazione MEH e il pacchetto verrà inoltrato tramite IOMux alla vNPU locale per la ricerca del flusso.
Poiché si tratta di una nuova sessione, la vNPU non ha un flusso specifico programmato per questo e dovrà indirizzare il pacchetto alla demuxmgr sulla scheda demux.
Passaggio 2: vNPU modifica l'intestazione MEH (con un nuovo BIA per il processo di demux pertinente). IOMUX sa che deve inviare questo attraverso la rete DI verso la scheda demux. Il processo Iftask sulla scheda Demux gestirà il pacchetto in entrata e IOMux lo indirizzerà al modulo KNI (che è l'interfaccia verso il kernel). Attraverso il kernel finirà infine nel processo demuxmgr (in questo caso egtpinmgr).
Passaggio 3: Demuxmgr eseguirà le relative attività. Selezionare un gestore sessioni e un npumgr programmi con i flussi per i pacchetti GTPv2 successivi
Le vNPU di tutte le schede saranno in grado di accedere alla memoria condivisa utilizzata da npumgr per programmare questi flussi.
Passaggio 4: Il CSR GTPv2 è ora inoltrato al gestore sessioni selezionato. Il suo MEH viene cambiato di nuovo, e inoltrato fuori dalla scheda Demux, sulla rete DI verso la scheda SF di Sessmgr. Il processo IOMUX su tale scheda inoltrerà il pacchetto tramite l'interfaccia MCDMA verso il gestore di sessione selezionato. Da qui in poi, sessmgr gestirà tutto il traffico GTPv2 per questa sessione. Una volta negoziati i TEID GTPU, programmerà i flussi attraverso NPUmgr in modo che i pacchetti GTPU successivi possano passare direttamente dalla scheda SF in ingresso alla scheda SF sessmgr.
vCPU in iftask
Durante la distribuzione, una certa quantità di vCPU (Virtual Central Processing Unit) viene allocata staticamente al processo iftask. Ciò riduce la quantità di core per le applicazioni di spazio utente (sessmgr ecc.), ma migliora notevolmente le prestazioni di I/O.
Questa allocazione viene eseguita tramite il parametro riportato di seguito nel modello param.cfg associato a ciascun file SF/CF durante la distribuzione.
- IFTASK_CORES (% di core disponibili da assegnare con iftask)
- (IFTASK_CRYPTO_CORES - (% di core disponibili da assegnare per l'elaborazione crittografica (nel caso di EPDG))
- (IFTASK_MCDMA_CORES - (per ottimizzare ulteriormente il numero di core allocati alla funzionalità MCDMA)
- In un SF, il processo iftask distribuirà internamente i core assegnati in:
- Driver in modalità polling (PMD) vCPU (attività tx/rx/vnpu)
- MCDMA vCPU, trasferimento di pacchetti da iftask a sessmgr e viceversa
- In un CF non sono richieste vCPU MCDMA, poiché i SF non ospitano processi sessmgr.
Il comando 'show cloud hardware iftask' fornisce ulteriori dettagli su questo nella distribuzione di QVPC-DI:
[local]UGP# show cloud hardware iftask Card 1: Total number of cores on VM: 8 Number of cores for PMD only: 0 Number of cores for VNPU only: 0 Number of cores for PMD and VNPU: 2 <-- CF: 2 out of 8 cores are assigned to iftask PMD/VNPU Number of cores for MCDMA: 0 <-- CF: no cores allocated to MCDMA as there is no sessmgr process on CF Number of cores for Crypto: 0 Hugepage size: 2048 kB Total hugepages: 3670016 kB NPUSHM hugepages: 0 kB CPU flags: avx sse sse2 ssse3 sse4_1 sse4_2 Poll CPU's: 1 2 KNI reschedule interval: 5 us ... Card 3: Total number of cores on VM: 8 Number of cores for PMD only: 0 Number of cores for VNPU only: 0 Number of cores for PMD and VNPU: 2 <-- SF: 2 out of 8 core are assigned to iftask PMD/VNPU
Number of cores for MCDMA: 1 <-- SF: 1 out of 8 cores is assigned to iftak MCDMA
Number of cores for Crypto: 0
Hugepage size: 2048 kB
Total hugepages: 4718592 kB
NPUSHM hugepages: 0 kB
CPU flags: avx sse sse2 ssse3 sse4_1 sse4_2
Poll CPU's: 1 2 3
KNI reschedule interval: 5 us
Il comando 'show cloud configuration' fornirà ulteriori dettagli sui parametri utilizzati:
[local]UGP# show cloud configuration Card 1: Config Disk Params: ------------------------- CARDSLOT=1 CPUID=0 CARDTYPE=0x40010100 DI_INTERFACE=BOND:TYPE:ixgbevf-1,TYPE:ixgbevf-2 DI_INTERFACE_VLANID=2111 VNFM_INTERFACE=MAC:fa:16:3e:23:aa:e9 VNFM_PROXY_ADDRS=172.16.180.3,172.16.180.5,172.16.180.6 MGMT_INTERFACE=MAC:fa:16:3e:87:23:9b VNFM_IPV4_ENABLE=true VNFM_IPV4_DHCP_ENABLE=true Local Params: ------------------------- CARDSLOT=1 CARDTYPE=0x40010100 CPUID=0 ... Card 3: Config Disk Params: ------------------------- CARDSLOT=3 CPUID=0 CARDTYPE=0x42030100 DI_INTERFACE=BOND:TYPE:ixgbevf-1,TYPE:ixgbevf-2 SERVICE1_INTERFACE=BOND:TYPE:ixgbevf-3,TYPE:ixgbevf-4 SERVICE2_INTERFACE=BOND:TYPE:ixgbevf-5,TYPE:ixgbevf-6 DI_INTERFACE_VLANID=2111 VNFM_INTERFACE=MAC:fa:16:3e:29:c6:b7 IFTASK_CORES=30 VNFM_IPV4_ENABLE=true VNFM_IPV4_DHCP_ENABLE=true Local Params: ------------------------- CARDSLOT=3 CARDTYPE=0x42010100 CPUID=0
Considerazioni sulla progettazione:
Ci sono diversi fattori che devono essere presi in considerazione quando si allocano vCPU a iftask.
-totale di vCPU disponibili per SF rispetto a vCPU iftask: La configurazione predefinita specifica il 30% delle vCPU associate a iftask tramite il parametro IFTASK_CORES nel file param.cfg. Ma questo può variare a seconda dell'applicazione (MME vs SPGW vs ePDG) —> Da consultare con la progettazione.
-iftask vCPU allocato a PMD e iftask vCPU allocato a MCDMA. Per verificare il bilanciamento, vedere la sezione seguente relativa alle prestazioni dei task.
-iftask MCDMA vCPU e vCPU rimanenti per tutte le applicazioni. In genere è consigliabile avere una distribuzione 1/x delle vCPU MCDMA iftask rispetto alle vCPU rimanenti per le applicazioni (sessmgr/aamgr/...).
Esempio:
Totale core 38 disponibili per SF:
-14 assegnato a iftask (6 PMD, 8 MCDMA)
-lasciando 24 assegnati ad altri processi
Ciò significa che è presente 1 MCDMA vCPU per ogni 3 vCPU dell'applicazione.
in questo modo è possibile garantire la parità di carico per ogni vCPU MCDMA.
Monitoraggio delle prestazioni di iftask
Il processo iftask può essere monitorato in diversi modi.
Consolidare l'elenco dei comandi show:
show subscribers data-rate show npumgr dinet utilization pps show npumgr dinet utilization pps show cloud monitor di-network summary show cloud hardware iftask show cloud configuration show iftask stats summary show port utilization table show npu utilization table show npumgr utilization information show processes cpu
Il comando #show cpu info verbose non fornirà informazioni sui core iftask. Saranno sempre elencati con un utilizzo del 100%.
Nell'esempio seguente, i core 1,2,3 sono associati a iftask e sono elencati con un utilizzo del 100%, come previsto.
Card 3, CPU 0:
Status : Standby, Kernel Running, Tasks Running
Load Average : 3.12, 3.12, 3.13 (3.95 max)
Total Memory : 16384M
Kernel Uptime : 4D 21H 56M
Last Reading:
CPU Usage All : 1.9% user, 0.3% sys, 0.0% io, 0.0% irq, 97.8% idle
Core 0 : 5.8% user, 0.2% sys, 0.0% io, 0.0% irq, 94.0% idle
Core 1 : Not Averaged (Poll CPU)
Core 2 : Not Averaged (Poll CPU)
Core 3 : Not Averaged (Poll CPU)
Core 4 : 2.2% user, 0.2% sys, 0.0% io, 0.0% irq, 97.6% idle
Core 5 : 0.8% user, 0.5% sys, 0.0% io, 0.0% irq, 98.7% idle
Core 6 : 0.4% user, 0.5% sys, 0.0% io, 0.0% irq, 99.1% idle
Core 7 : 0.1% user, 0.3% sys, 0.0% io, 0.0% irq, 99.6% idle
Poll CPUs : 3 (1, 2, 3)
Core 1 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Core 2 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Core 3 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Processes / Tasks : 143 processes / 16 tasks
Network mcdmaN : 0.002 kpps rx, 0.001 mbps rx, 0.002 kpps tx, 0.001 mbps tx
File Usage : 1504 open files, 1627405 available
Memory Usage : 7687M 46.9% used
Memory Details:
Static : 330M kernel, 144M image
System : 10M tmp, 0M buffers, 54M kcache, 79M cache
Process/Task : 6963M (120M small, 684M huge, 6158M other)
Other : 104M shared data
Free : 8696M free
Usable : 5810M usable (8696M free, 0M reclaimable, 2885M reserved by tasks)Il comando #show npu usage table fornirà un buon riepilogo dell'utilizzo di ciascun core associato al processo iftask (su ciascuna scheda).
Nota: È importante stabilire se l'utilizzo di alcuni core è notevolmente superiore rispetto ad altri.
[local]UGP# show npu utilization table
-------iftask-------
lcore now 5min 15min
-------- ------ ------ ------
01/0/1 0% 0% 0%
01/0/2 0% 0% 0%
02/0/1 0% 0% 0%
02/0/2 2% 1% 0%
03/0/1 0% 0% 0%
03/0/2 0% 0% 0%
03/0/3 0% 0% 0%
04/0/1 0% 0% 0%
04/0/2 0% 0% 0%
04/0/3 0% 0% 0%
05/0/1 0% 0% 0%
05/0/2 0% 0% 0%
05/0/3 0% 0% 0%Comando #show npumgr usage information (comando nascosto)
Questo comando fornisce ulteriori informazioni su ciascun core iftask e sul consumo di CPU da parte di questi core.
Nota: La CPU dei core PMD viene utilizzata su PortRX, PortTX, KNI e Cipher. La CPU dei core MCDMA viene utilizzata da MCDMA.
Il carico dei core PMD e MCDMA deve essere uniforme.
In caso contrario, potrebbe essere necessaria una certa regolazione (ad esempio, l'allocazione di un numero maggiore o minore di core MDMA).
******** show npumgr utilization information 3/0/0 *******
5-Sec Avg: lcore01| lcore02| lcore03| lcore04| lcore05| lcore06| lcore07| lcore08| lcore09| lcore10| lcore11| lcore12| lcore13| lcore14| lcore15| lcore16|
Idle: 31%| 37%| 32%| 35%| 41%| 48%| 47%| 38%| 57%| 56%| 55%| 56%| 46%| 56%| 54%| 52%|
PortRX: 28%| 26%| 27%| 26%| 0%| 0%| 0%| 0%| 12%| 14%| 11%| 11%| 0%| 0%| 0%| 0%|
PortTX: 5%| 5%| 6%| 5%| 8%| 8%| 8%| 14%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
KniRX: 6%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
Kni: 1%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
McdmaRX: 0%| 0%| 0%| 0%| 34%| 29%| 29%| 32%| 0%| 0%| 0%| 0%| 35%| 28%| 28%| 28%|
Mcdma: 0%| 0%| 0%| 0%| 11%| 7%| 4%| 6%| 0%| 0%| 0%| 0%| 14%| 7%| 7%| 7%|
Vnpu: 28%| 29%| 28%| 32%| 0%| 0%| 0%| 0%| 30%| 28%| 33%| 28%| 0%| 0%| 0%| 0%|
McdmaFlush: 0%| 0%| 0%| 0%| 6%| 8%| 12%| 10%| 0%| 0%| 0%| 0%| 6%| 10%| 11%| 14%|
Cipher: 1%| 2%| 6%| 2%| 0%| 0%| 0%| 0%| 1%| 2%| 1%| 5%| 0%| 0%| 0%| 0%|
rx kbits/sec: 728563| 736103| 647535| 626595| 811362| 698724| 717147| 799281| 617199| 595268| 623670| 633132| 819270| 672732| 790849| 719498|
rx frames/sec: 94409| 95586| 91107| 84997| 109526| 97466| 98557| 107690| 81122| 82076| 86959| 87960| 114114| 96198| 108108| 100259|
tx kbits/sec: 715038| 722181| 634227| 614221| 827124| 712740| 731329| 814782| 605373| 583318| 611001| 620328| 835692| 686575| 806395| 733924|
tx frames/sec: 94310| 95491| 90969| 84896| 109526| 97466| 98557| 107690| 81002| 81986| 86858| 87859| 114114| 96198| 108108| 100259|
5-Min Avg: ...
15-Min Avg: ...ulteriori spiegazioni:
La CPU viene considerata nel modo seguente per un pacchetto in entrata nel processo iftask tramite porta di servizio o porta DI.
La ricerca della Vnpu è la parte che utilizza maggiormente la CPU.
Se dopo la ricerca della Vnpu:
- il pacchetto viene inviato al core MCDMA, il tempo CPU verrà considerato sul McdmaRx del core MCDMA interessato.
-il pacchetto viene inviato a un altro core iftask, il tempo CPU verrà conteggiato in Vnpu
-Il pacchetto viene inviato sullo stesso core di attività, il tempo CPU verrà conteggiato sotto PortRx
-il pacchetto viene inviato sullo stesso core di attività, il tempo CPU verrà considerato sottoKniRx
PortRx include anche un significativo sovraccarico generale per il prelievo dei pacchetti dalle code di ricezione e il loro invio/accodamento dove devono andare
Comandi #show npumgr dinet usage pps, #show npumgr dinet usage bbps e #show port usage table
Forniscono informazioni sul carico sulle porte DI e sulle porte dei servizi.
Le prestazioni effettive dipendono dall'allocazione di NIC/CPU e CPU a iftask.
[local]UGP# show npumgr dinet utilization pps
------ Average DINet Port Utilization (in kpps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/0 Virtual Ethernet 0 0 0 0 0 0
2/0 Virtual Ethernet 0 0 0 0 0 0
3/0 Virtual Ethernet 0 0 0 0 0 0
4/0 Virtual Ethernet 0 0 0 0 0 0
5/0 Virtual Ethernet 0 0 0 0 0 0
[local]UGP# show npumgr dinet utilization bps
------ Average DINet Port Utilization (in mbps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/0 Virtual Ethernet 1 1 1 1 1 1
2/0 Virtual Ethernet 1 0 1 0 1 0
3/0 Virtual Ethernet 0 0 0 0 0 0
4/0 Virtual Ethernet 0 0 0 0 0 0
5/0 Virtual Ethernet 0 0 0 0 0 0
[local]UGP# show port utilization table
------ Average Port Utilization (in mbps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/1 Virtual Ethernet 0 0 0 0 0 0
2/1 Virtual Ethernet 0 0 0 0 0 0
3/10 Virtual Ethernet 0 0 0 0 0 0
3/11 Virtual Ethernet 0 0 0 0 0 0
4/10 Virtual Ethernet 0 0 0 0 0 0
4/11 Virtual Ethernet 0 0 0 0 0 0
5/10 Virtual Ethernet 0 0 0 0 0 0
5/11 Virtual Ethernet 0 0 0 0 0 0Comando #show cloud monitor di-network summary
Questo comando esegue il monitoraggio dell'integrità della rete DI. Le carte inviano heartbeat l'una all'altra, e la Perdita viene monitorata. In un sistema sano, non viene segnalata alcuna perdita.
[local]UGP# show cloud monitor di-network summary Card 3 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 4 Good 0.00% 0.00% 5 Good 0.00% 0.00% Card 4 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 3 Good 0.00% 0.00% 5 Good 0.00% 0.00% Card 5 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 3 Good 0.00% 0.00% 4 Good 0.00% 0.00%
Riepilogo statistiche comando #show iftask
Con carichi NPU più elevati, è possibile che il traffico venga interrotto.
Per valutare questa condizione, è possibile eseguire l'output di riepilogo dello stato del comando #show iftask.
Nota: Il valore di DISCARDS può essere diverso da zero. Tutti gli altri contatori dovrebbero idealmente rimanere 0.
[local]VPC# show iftask stats summary Thursday January 18 16:01:29 IST 2018 ----------------------------------------------------------------------------------------------- Counter SF3 SF4 SF5 SF6 SF7 SF8 SF9 SF10 SF11 SF12 ___TOTAL___ ------------------------------------------------------------------------------------------------ svc_rx 32491861127 16545600654 37041906441 37466889835 32762859630 34931554543 38861410897 16025531220 33566817747 32823851780 312518283874 svc_tx 46024774071 14811663244 40316226774 39926898585 40803541378 48718868048 35252698559 1738016438 4249156512 40356388348 312198231957 di_rx 42307187425 14637310721 40072487209 39584697117 41150445596 44534022642 31867253533 1731310419 4401095653 40711142205 300996952520 di_tx 28420090751 16267050562 36423298668 36758561246 32731606974 30366650898 35201117980 16009902791 33536789041 32815316570 298530385481 __ALL_DROPS__ 1932492 252 17742 790473 11228 627018 844812 60402 0 460830 4745249 svc_tx_drops 0 0 0 0 0 0 0 0 0 0 0 di_rx_drops 0 1 0 0 49 113 579 30200 0 4888 35830 di_tx_drops 0 0 0 0 0 0 0 0 0 0 0 sw_rss_enq_drops 0 0 0 0 0 0 0 0 0 0 0 kni_thread_drops 0 0 0 0 0 0 0 0 0 0 0 kni_drops 0 1 0 0 0 0 124 30200 0 0 30325 mcdma_drops 0 0 0 168 80 194535 758500 0 0 11628 964911 mux_deliver_hop_drops 0 0 0 0 0 0 0 0 0 1019 1019 mux_deliver_drops 0 0 0 0 0 0 0 0 0 0 0 mux_xmit_failure_drops 0 3 0 0 0 0 7 2 0 0 12 mc_dma_thread_enq_drops 0 0 0 0 49 113 580 0 0 3457 4199 sw_tx_egress_enq_drops 1904329 0 0 787971 9004 429214 85022 0 0 429810 3645350 cpeth0_drops 0 0 0 0 0 0 0 0 0 0 0 mcdma_summary_drops 28163 247 17742 2334 2046 3043 0 0 0 10028 63603 fragmentation_err 0 0 0 0 0 0 0 0 0 0 0 reassembly_err 0 0 0 0 0 0 0 0 0 0 0 reassembly_ring_enq_err 0 0 0 0 0 0 0 0 0 0 0 __DISCARDS__ 20331090 9051092 23736055 23882896 23807520 24231716 24116576 8944291 22309474 20135799 20135799
SW-RSS e HW-RSS
RSS è una funzione in grado di distribuire il traffico in entrata proveniente da una scheda NIC su più processori DPDK. In genere, la scheda NIC supporta RSS nell'hardware, consentendo la distribuzione del traffico tra più core iftask.
Il processo iftask in Staros ha implementato una versione software di rss che può essere abilitata se:
-nic non supporta HW rss (quindi tutto il traffico tx/rx atterrerà su una singola CPU iftask).
-nic non dispone di un numero sufficiente di code tx/rx (un numero di code inferiore alle CPU tx/rx disponibili assegnate a iftask). In tal caso, il software RSS (completo) consente la corretta distribuzione tra tutti i core di attività disponibili assegnati per rx/tx.
Questa funzione è operativa solo per il traffico in entrata attraverso le porte di servizio. Il traffico di ID non viene preso in considerazione.
Esistono 3 modalità di configurazione:
-no iftask sw-rss - sw-rss disabilitato. Il sistema si basa su RSS HW.
-iftask sw-rss completo - utilizzo di sw rss per tutto il traffico. SW RSS può essere eseguito insieme a HW RSS. Non è necessario disabilitare RSS hardware. Tuttavia, il servizio RSS del software sarà responsabile del bilanciamento effettivo del carico del traffico del servizio nei core iftask.
-iftask sw-rss supplementare - utilizzo di sw rss solo per il traffico non supportato da hw-rss (esempio: traffico MPLS)
Con RSS HW e SW, è importante capire come il traffico viene hashato nei vari processori iftask/dpdk.
RSS HW: l'hashing dipende dall'hardware. Di seguito è riportato un esempio:
[root@host]# ethtool -n enp10s0f1
4 RX rings available
Total 0 rules
[root@host] # ethtool -n enp10s0f0 rx-flow-hash udp4
UDP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA
RSS SW: A partire da Staros 21.6, l'hashing della versione RSS del software si comporta come segue:
1. In case of IPV6
we only support L3( IP src/dst ) based hashing (same as the old behaviour).
2. In case of IPV4
a. For TCP we support IP src/dst + tcp ports src/dst
b. For UDP fragmented - only IP src/dst
c. For UDP non-fragmented not gtpu ( I.e. Port !=2152) ? IP src/dst + udp port src/dst
d. For UDP non-fragmented and gtpu ( I.e. Port ==2152) - IP src/dst + udp port src/dst + gtp tunnel id
e. Any other protocol ? we default back to IP src/dst
Importante: RSS per traffico ID crittografato:
In assenza di SW-RSS (supplementare/completo), potrebbe essere possibile che tutto il traffico DI crittografato venga hashato in un unico Core su iftask.
In questo modo, questo core avrà un utilizzo sempre maggiore rispetto agli altri.
Da CSCvi06080  , a questo punto, è possibile risolvere il problema con questo comando di configurazione:
, a questo punto, è possibile risolvere il problema con questo comando di configurazione:
iftask di-net-encrypt-rss
Dopo l'integrazione di CSCvm41257 , questa opzione verrà impostata come predefinita.
Informazioni più dettagliate su SW RSS:
Lo scopo di sw-rss è quello di bilanciare il carico dei core PMD ed evitare scenari di limitazione del throughput in cui un core PMD si esaurisce quando gli altri dispongono di una notevole capacità disponibile.
Tutti i pacchetti in entrata delle porte di servizio vengono estratti dalla scheda NIC e incapsulati tramite MEH dal core PMD che gestisce la coda Rx in cui arrivano.
A questo punto, se task non sa dove inviare il pacchetto. I pacchetti devono essere elaborati dalla VNPU per determinare la destinazione interna. Praticamente tutti questi pacchetti passano attraverso la ricerca IOC/flusso quando vengono consegnati alla VNPU. Le eccezioni si riferiscono agli scarti per motivi quali vlan non configurata/disabilitata o MAC di destinazione non valido (esiste anche lo scenario di inoltro L3, ma questa situazione è insolita).
Se sw-rss non è configurato, l'elaborazione della ricerca IOC/flusso VNPU viene eseguita sullo stesso core immediatamente dopo l'accesso MEH. Se sw-rss è configurato, i pacchetti vengono accodati a un core per l'elaborazione VNPU basata su un hash. L'operazione di ricerca IOC/flusso VNPU è la singola funzione iftask più costosa; sw-rss consente di bilanciare il carico di lavoro tra tutti i core PMD.
In seguito alla ricerca IOC/flusso della VNPU, il pacchetto viene trasmesso a un altro SF tramite trasmissione DINet o accodato all'app locale tramite trasferimento MCDMA (anche in questo caso, ci sono eccezioni, ma non credo che siano rilevanti per questa discussione).
I pacchetti inviati a un altro SF vengono accodati direttamente al canale MCDMA appropriato sulla scheda di destinazione dopo DINet Rx. Non richiedono un (secondo) passaggio VNPU.
Code TX/RX
Nei log di iftask, è possibile visualizzare log come:
Tue May 7 15:26:48 2019 PID:8188 APP: max rx queues supported 16 ...
Tue May 7 15:26:48 2019 PID:8188 APP: max tx queues supported 8 ...
Tue May 7 15:26:48 2019 PID:8188 APP: hw rx requested 2 ...
Tue May 7 15:26:48 2019 PID:8188 APP: hw tx requested tx 5
Ciò è dovuto al numero supportato di code rx e tx supportate dall'hardware effettivo rispetto al numero di code tx/rx supportate dalle richieste di attività.
Le richieste iftask sono strettamente correlate al numero di processori allocati a iftask.
Nota: Ogni conducente è diverso. Alcuni host di query, altri con hardcoded.
Il conteggio hw tx richiesto indica il numero di core utilizzati da dpdk. Si tratta in genere di uno più dei core totali allocati a iftask perché dpdk include il core su cui viene eseguito il thread di controllo/ipc. Questa base è condivisa con il boxer e programmata come una cpu generica (il thread controllo/ipc dpdk non usa molte cpu).
Il conteggio richiesto di hw rx corrisponde in genere al numero di core PMD.
Iftask alloca il valore minimo (richiesto, massimo) per ciascuna porta e lo distribuisce tra i core. L'algoritmo di distribuzione è un po' complicato. L'obiettivo è distribuire il carico di lavoro il più equamente possibile tra tutti i core.
Iftask txbatch
Dalla release 21.9, staros dispone delle seguenti opzioni di configurazione iftask predefinite che sono importanti per il batch (aggregazione del traffico). Questo ha un impatto negativo sulle prestazioni quando il nodo è sotto test con uno o pochi abbonati.
# iftask mcdmatxbatch burst size 32 # iftask mcdmatxbatch latency 200 # iftask txbatch burst size 32 # iftask txbatch latency 200
Per ulteriori spiegazioni, si veda:
Statistiche
Lo schema Bulkstat è sviluppato per le prestazioni QPVC-DI relative a iftask/dinet. Ciò è utile per monitorare il dinet, le porte di servizio e l'utilizzo della npu dal punto di vista delle prestazioni e del carico:
card schema iftask-dinet format EMS,IFTASKDINET,%date%,%time%,%dinet-rxpkts-curr%,%dinet-txpkts-curr%,%dinet-rxpkts-5minave%,%dinet-txpkts-5minave%,%dinet-rxpkts-15minave%,%dinet-txpkts-15minave%,%dinet-txdrops-curr%,%dinet-txdrops-5minave%,%dinet-txdrops-15minave%,%npuutil-now% file 2 port schema iftask-port format EMS,IFTASKPORT,%date%,%time%,%util-rxpkts-curr%,%util-txpkts-curr%,%util-rxpkts-5min%,%util-txpkts-5min%,%util-rxpkts-15min%,%util-txpkts-15min%,%util-txdrops-curr%,%util-txdrops-5min%,%util-txdrops-15min% file 3 card schema npu-util format EMS,NPUUTIL,%date%,%time%,%npuutil-now%,%npuutil-5minave%,%npuutil-15minave%,%npuutil-rxbytes-5secave%,%npuutil-txbytes-5secave%,%npuutil-rxbytes-5minave%,%npuutil-txbytes-5minave%,%npuutil-rxbytes-15minave%,%npuutil-txbytes-15minave%,%npuutil-rxpkts-5secave%,%npuutil-txpkts-5secave%,%npuutil-rxpkts-5minave%,%npuutil-txpkts-5minave%,%npuutil-rxpkts-15minave%,%npuutil-txpkts-15minave%
Cronologia delle revisioni
| Revisione | Data di pubblicazione | Commenti |
|---|---|---|
1.0 |
09-Jun-2018
|
Versione iniziale |
Contributo dei tecnici Cisco
- Steven Loos
 Feedback
Feedback