Questo elenco comprende gli avvisi preconfigurati di CallManager.
- InizioLimitazioneChiamateElencoBLFSsottoscrizioni
- RichiamaTentativoBloccatoPerCriterio
- ChiamaElaborazioneNodoCpuPegging
- CriticoMotoreCARIDSE
- ErroreMotoreCARIDSE
- ProcessoProgrammazioneCAR non riuscito
- CDRAgentInviaFileNonRiuscito
- CDRFileDeliveryNonRiuscita
- CDRHighWaterMarkExceeded
- CDRMaximumDiskSpaceExceeded
- GialloCodice
- DBChangeNotifyErrore
- ErroreReplicaDBR
- DBReplicationTableOutofSync
- DDRBlockPrevention
- DDRDown
- EMCCFailInClusterLocale
- EMCCFailInRemoteCluster
- ReportQualitàVoceEccessiva
- ImedDistributedCacheInactive
- QuotaIME
- AvvisoQualitàIMP
- IdentificatoriFallbackInsufficienti
- StatoServizioIME
- Credenziali non valide
- BassaFrequenzaHeartbeatServerTFTP
- TracciaChiamataDannosa
- ElencoSupportiEsaurito
- MgcpDChannelOutOfService
- NumeroDiDispositiviRegistratiSuperato
- NumeroDiGatewayRegistratiDiminuiti
- NumeroDiGatewayRegistratiAumentati
- NumeroDiDispositiviMultimedialiRegistratiDiminuiti
- NumeroDiDispositiviMultimedialiRegistratiAumentato
- NumeroDiTelefoniRegistratiEliminati
- RouteListExhausted
- SDLLinkOutOfService
- TCPSetupToIMEF non riuscito
- TLSConnectionToIMEF non riuscito
- ErroreInputUtente
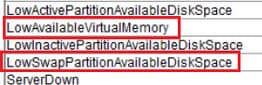
LowAvailableVirtualMemory e LowSwapPartitionAvailableDiskSpace
I server Linux hanno la tendenza a "non cancellare" l'utilizzo della memoria virtuale per un certo periodo di tempo ed è stato rilevato un accumulo e quindi tali allarmi.
Linux funziona in modo leggermente diverso come sistema operativo.
Una volta allocata a un processo, la memoria non verrà recuperata dal processore a meno che altri processi non richiedano una quantità di memoria superiore a quella disponibile.
Ciò causa un'elevata quantità di memoria virtuale.
Una richiesta di aumento della soglia per l'allarme nelle versioni superiori di call manager è stata documentata nel difetto; https://bst.cloudapps.cisco.com/bugsearch/bug/CSCuq75767/?reffering_site=dumpcr
Per le partizioni di swap, questo avviso indica che la partizione di swap non dispone di spazio sufficiente ed è utilizzata in modo intensivo dal sistema. La partizione di swap viene in genere utilizzata per estendere la capacità della RAM fisica quando necessario. In condizioni normali, se la RAM è sufficiente, lo scambio non deve essere utilizzato troppo.
Inoltre, questi possono essere generare avvisi RTMT causati da un accumulo di file temporanei, si consiglia un riavvio del server per cancellare eventuali file temporanei non necessari.
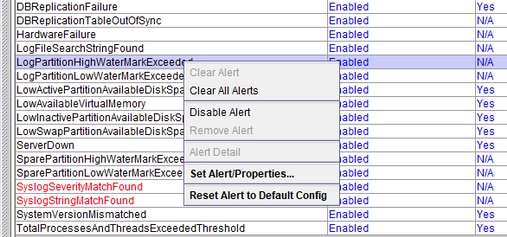
LogPartitionHighWaterMarkExceeded e LogPartitionLowWaterMarkExceeded
Quando si esegue il comando show status nella CLI di un server CUCM, viene visualizzato un valore che specifica la percentuale di spazio libero e occupato della partizione di log nello spazio su disco di CUCM. Questi valori, noti anche come partizione comune, specificano lo spazio occupato dai log/tracce e dai file CDR nel server, che, sebbene innocui, possono causare problemi nella procedura di installazione/aggiornamento a causa della mancanza di spazio nel tempo. Questi avvisi avvisano l'amministratore di cancellare i registri che potrebbero essersi accumulati nel tempo nel cluster/server.
LogPartitionLowWaterMarkExceeded: questo avviso viene generato quando lo spazio pieno raggiunge i valori di soglia configurati per l'avviso. Questo avviso funge da indicatore di pre-controllo per l'utilizzo del disco.
LogPartitionHighWaterMarkExceeded: questo avviso viene generato quando lo spazio pieno raggiunge i valori di soglia configurati per l'avviso. Una volta generato l'avviso, il server inizia a eliminare automaticamente i registri meno recenti in modo da ridurre lo spazio a un valore inferiore alla soglia HighWaterMark.
È buona norma eliminare manualmente i registri non appena viene ricevuto l'avviso LogPartitionLowWaterMarkExceeded.
A tale scopo, eseguire le operazioni seguenti:
Passaggio 1. Avviare RTMT.
Passaggio 2. Selezionare Alert Central, quindi eseguire i task riportati di seguito.
Selezionare LogPartitionHighWaterMarkExceeded, annotarne il valore e modificarne il valore di soglia a 60%.
Selezionare LogPartitionLowWaterMarkExceeded, annotarne il valore e modificarne il valore di soglia a 50%.
Il polling viene eseguito ogni 5 minuti, quindi attendere 5-10 minuti e verificare che lo spazio su disco richiesto sia disponibile. Se si desidera liberare spazio su disco nella partizione comune, modificare nuovamente i valori dei thread LogPartitionHighWaterMarkExceeded e LogPartitionLowWaterMarkExceeded in valori più bassi, ad esempio 30% e 20%.
Concedere 15-20 minuti per liberare lo spazio nella partizione comune. Per monitorare la riduzione dell'utilizzo del disco, usare il comando show status dalla CLI.
Questo farebbe cadere la partizione comune.
Pegging CPU
L'avviso CpuPegging monitora l'utilizzo della CPU in base alla soglia configurata.
Quando viene ricevuto l'avviso di pegging della CPU, il processo che occupa la CPU più alta può essere occupato andando nella Cassetto del sistema a sinistra, ovvero Processo.
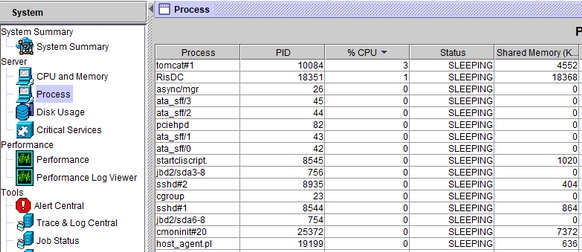
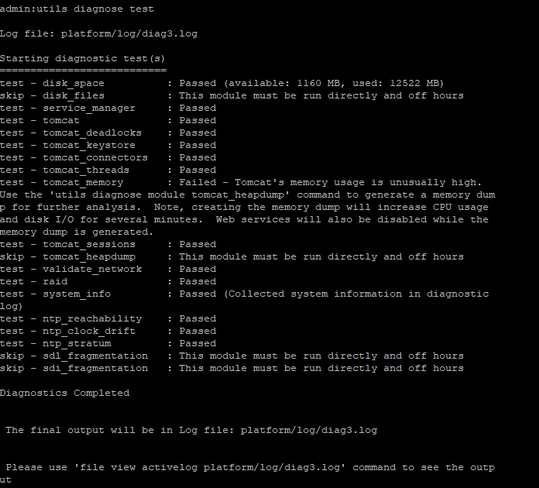
Dalla CLI del server interessato, questi output forniscono informazioni dettagliate.
- utils diagnose test
- mostra cpu carico processo ordinata
- mostra stato
- elenco attivo di base utils
Si consiglia di osservare se il picco della CPU si verifica in un momento specifico o in modo casuale. Se si verifica in modo casuale, le tracce CUCM dettagliate necessarie e i registri delle prestazioni RisDC consentono di verificare che cosa attiva il picco nella CPU. Se gli allarmi si verificano in un momento specifico della giornata, ciò potrebbe essere dovuto ad alcune attività pianificate come il backup del Disaster Recovery System (DRS), il caricamento CDR, ecc.
Inoltre, sulla base delle informazioni su quale processo occupa la maggior parte della CPU, vengono utilizzati log specifici per ulteriori indagini. Ad esempio se il colpevole è Tomcat, sono necessari i log relativi a Tomcat.
 Feedback
Feedback