Introduzione
In questo documento vengono descritte le nuove funzionalità della memoria introdotte nei server di generazione M7 e M8 UCS e vengono illustrati i passaggi per comprendere e risolvere i problemi relativi agli errori di memoria
Prerequisiti
Requisiti
Cisco raccomanda la conoscenza dei seguenti argomenti.
- Conoscenze base di UCS.
- Conoscenza di base dell'architettura di memoria.
Componenti usati
Le informazioni fornite in questo documento si basano sulle seguenti versioni software e hardware:
- UCS Family Server M7 e M8
- UCS Manager
- Cisco Integrated Management Controller (CIMC)
- Cisco Intersight Managed Mode (IMM)
Le informazioni discusse in questo documento fanno riferimento a dispositivi usati in uno specifico ambiente di emulazione. Su tutti i dispositivi menzionati nel documento la configurazione è stata ripristinata ai valori predefiniti. Se la rete è operativa, valutare attentamente eventuali conseguenze derivanti dall'uso dei comandi.
Premesse
Panoramica degli errori di memoria
Gli errori di memoria sono tra i tipi di errore più comuni nei server moderni. Gli errori vengono spesso rilevati quando si tenta di leggere una posizione di memoria e il valore letto non corrisponde all'ultimo valore scritto.
Gli errori di memoria possono essere soft o hard. Alcuni errori possono essere corretti, ma più errori soft o hard simultanei su un singolo accesso alla memoria possono non essere corretti.
Funzioni RAS memoria Cisco UCS M7/M8
I server Cisco UCS M7 e M8 dispongono di una serie completa di funzionalità RAS, come descritto di seguito. In questo modo si riduce al minimo l'impatto degli errori di memoria sulle prestazioni e sul tempo di attività del sistema.
ECC a livello di sistema
Tutti i server Cisco UCS M7 utilizzano moduli di memoria con codici ECC in grado di correggere qualsiasi errore limitato a un singolo chip DRAM x4 e di rilevare errori a doppio bit in un massimo di due dispositivi. Questo processo viene ora definito ECC a livello di sistema, come nei server di vecchia generazione
.
Sparing Virtual Lock-Step (VLS) / Adaptive Double Device Data Correction (ADDDC)
ADDDC Sparing è in grado di correggere due errori DRAM consecutivi se risiedono nella stessa regione. Questa funzione tiene traccia degli errori correggibili e mappa dinamicamente i bit in errore copiando i contenuti di riserva (sparing) in una linea cache "buddy". Questo meccanismo può ridurre gli errori correggibili che, se non trattati, potrebbero diventare non correggibili. Questa funzione utilizza il VLS (Virtual Lockstep) per assegnare coppie di contatti della linea di cache all'interno dello stesso canale di memoria a livello di banco DRAM utilizzando il VLS di banco oppure a livello di dispositivo DRAM utilizzando il VLS di rango.
.
ECC on-die
L'ECC on-die è una nuova funzionalità della memoria DDR5. Questa funzionalità è attivata per impostazione predefinita. Tutti gli errori a bit singolo (hard e soft) vengono corretti dalla DRAM prima della trasmissione dei dati all'host. Tuttavia, questi dati corretti non vengono riscritti nella DRAM. La funzione ECS (Error Check and Scrub) è utilizzata per eseguire lo scrub e correggere gli errori a singolo bit presenti in memoria.
ECS (Error Check and Scrub)
L'ECS verifica la presenza di eventuali errori in background pulendo periodicamente (ogni 24 ore) ciascun die di DRAM, correggendoli riscrivendo i dati sull'array e fornendo un conteggio degli errori rilevati durante la pulitura. Questa funzione è attivata per impostazione predefinita.
Post Package Repair (PPR)
La riparazione post-package è una funzione in cui le righe di riserva vengono utilizzate per sostituire una cella o una riga errata in un dispositivo DRAM.
Sono disponibili tre tipi: Soft PPR (riconfigurabile), Hard PPR (permanente) e Runtime PPR.
- I server Cisco UCS M7 con CPU Intel supportano il processore "hard" PPR. Si tratta di una correzione permanente eseguita durante il riavvio in base ai dati di errore raccolti durante il runtime precedente o se si verificano errori di riga durante EMT.
- Le riparazioni si verificano in genere durante i ripristini a caldo/freddo o i cicli CA.
- Sul supporto UCS M8 tutti e tre i tipi di PPR, Hard PPR è abilitato per impostazione predefinita, mentre Runtime PPR è disabilitato.
- Runtime PPRpermette di eseguire le riparazioni durante il funzionamento del sistema senza influire sui tempi di attività.
- Se sono attivati sia il processo di replica continua dei dati (PPR), vengono utilizzate tutte le funzioni PPR. Se Hard PPR è disattivato ma Runtime PPR è attivato, il sistema utilizza per impostazione predefinita Soft PPR.
- Il PPR è strettamente collegato agli errori correggibili e ogni errore correggibile genera un record SEL quando il PPR è abilitato.
PMIC (Power Management Integrated Circuit, circuito integrato di gestione dell'alimentazione)
Il modulo PMIC su un modulo DIMM è una caratteristica chiave dei moduli di memoria DDR5. Questa integrazione sposta la funzione di gestione dell'alimentazione dalla scheda madre al modulo di memoria stesso, offrendo diversi vantaggi significativi.
Per la memoria DDR5, è attivata la gestione degli errori PMIC.
- Gli errori PMIC generano record CELL sia durante il runtime che dopo l'avvio.
- Durante l'addestramento della memoria, se viene rilevato un errore PMIC in un canale di memoria, il DIMM interessato viene mappato e il sistema continua ad avviarsi con memoria ridotta
Analisi log
File da archiviare nel supporto tecnico
UCSM_X_TechSupport > sam_techsupportinfo fornisce informazioni su DIMM e array di memoria.
Supporto tecnico per chassis/server
CIMCX_TechSupport\tmp\CICMX_TechSupport.txt -> Informazioni generiche sul supporto tecnico per il server X.
CIMCX_TechSupport\obfl\obfl-log -> I log OBFL forniscono un log continuo sullo stato e l'avvio del server X.
CIMCX_TechSupport\var\log\sel -> SEL log per il server X.
In base alla versione/piattaforma, passare ai file nel pacchetto di supporto tecnico.
RAS -Per la posizione dell'errore CE ECS (Error Check and Scrub)raccolte durante il runtime su ogni scrub
/nv/etc/BIOS/bt/DDR5_CISCO_ECS
AMT Auto viene eseguito all'avvio successivo se si verifica un errore CE e UCE sui DIMM
nv/etc/BIOS/bt/MrcOut.
AMT_TEST_PATTERN:
ADV_MT_SAMSUNG
AMT_RESULT: SUPERATO.
Errore PMIC: /nv/etc/DIMM-PMIC.txt
Il server M8 contiene:-
nv/etc/BIOS/bt >MrcOut
Questi file forniscono informazioni sulla memoria viste a livello di BIOS.
È possibile creare un nuovo riferimento incrociato alle informazioni con le tabelle di report degli stati DIMM.
Esempio dal server AMD:-
nv/etc/BIOS/bt >MrcOut
Contiene:
- Versione del BIOS, data e ora di generazione
- Versioni firmware PSP
- Presenza e stato DIMM (indica che DIMM è presente o meno)
- Dettagli configurazione DIMM.
2025/08/14 13:44:34
BIOS ID : C245M8.4.3.6b.0 Built 04/28/2025 14:15:22
=====================
PSP Firmware Versions
=====================
ABL Version: 100E8012
PSP: 0.29.0.9B
PFMW (SMU): 4.71.126.0
SEV: 1.1.37.28
PHY: 0.1.38.0
MPIO: 1.0.2D.C4
TF MPDMA: 0.47.3.0
PM MPDMA: 0.47.46.0
GMI: AB.1.27.0
RIB: 2.0.8.39
SEC: D.E.90.71
PMU: 0.0.90.4E
EMCR: 0.0.E0.4E
uCode B1: 0xA101154
DIMM Status:
|=======================|
| Memory | DIMM Status |
| Channel | |
|=======================|
| P1_A | 01 |
| P1_B | 01 |
| P1_C | 01 |
| P1_D | 01 |
| P1_E | 01 |
| P1_F | 00 |
| P1_G | 01 |
| P1_H | 01 |
| P1_I | 01 |
| P1_J | 01 |
| P1_K | 01 |
| P1_L | 00 |
| P2_A | 01 |
| P2_B | 01 |
| P2_C | 01 |
| P2_D | 01 |
| P2_E | 01 |
| P2_F | 00 |
| P2_G | 01 |
| P2_H | 01 |
| P2_I | 01 |
| P2_J | 01 |
| P2_K | 01 |
| P2_L | 00 |
|=======================|
DIMM Configuration:
=================================================
MbistTest = Disabled
MbistAggressor = Disabled
MbistPerBitSlaveDieReport = Enabled
DramTempControlledRefreshEn = Disabled
UserTimingMode = Disabled
UserTimingValue = Disabled
MemBusFreqLimit = Disabled
EnablePowerDown = Disabled
DramDoubleRefreshRate = Disabled
PmuTrainMode = 0x0000
EccSymbolSize = 0x0000
UEccRetry = Disabled
IgnoreSpdChecksum = Disabled
EnableBankGroupSwapAlt = Disabled
EnableBankGroupSwap = Disabled
DdrRouteBalancedTee = Disabled
OdtsCmdThrotEn = Disabled
OdtsCmdThrotCyc = Disabled
=================================================
Enhanced Memory Context Restore : APOB_SAVED
2025/08/14 13:44:34
Inventario file MCA in uscita:-
Questo file contiene informazioni sui registri MCA di tutte le banche.
(Ogni volta che viene rilevato un errore UCE)
--- START OF MCA FILE ---
Timestamp H:M:S 13:44:15 D:M:Y 14:8:2025
--- Note ---
The legacy MCA registers include:
MCA_CTL - Enables error reporting via machine check exception.
MCA_STATUS - Logs information associated with errors.
MCA_ADDR - Logs address information associated with errors. The use of AMD Secure Memory Encryption may change the information logged in the address register.
MCA_MISC0 - Logs miscellaneous information associated with errors.
The MCA Extension registers include:
MCA_CONFIG - Provide configuration capabilities for this MCA bank.
MCA_IPID - Provides information on the block associated with this MCA bank.
MCA_SYND - Logs physical location information associated with a logged error.
MCA_DESTATUS - Logs status information associated with a deferred error.
MCA_DEADDR - Logs address information associated with a deferred error.
MCA_MISC[1:4] - Provides additional threshold counters within an MCA bank.
MCA_TRANSSYND - Logs location information associated with a transparent error.
MCA_TRANSADDR - Logs address information associated with a transparent error.
LS - Load-Store Unit -> Bank 0
IF - Instruction Fetch Unit -> Bank 1
L2 - L2 Cache Unit -> Bank 2
DE - Decode Unit -> Bank 3
Empty/Unused bank -> Bank 4
EX - Execution Unit -> Bank 5
FP - Floating Point Unit -> Bank 6
L3 - L3 Cache Unit -> Bank 7 to 14
MP5 - Microprocessor5 Management Controller -> Bank 15
PB - Parameter Block -> Bank 16
PCS-GMI - GMI Controller -> Bank 17 to 18
KPX-GMI - High Speed Interface Unit(GMI) -> Bank 19 to 20
UMC - Unified Memory Controller -> Bank 21 to 22
CS - Coherent Station -> Bank 23 to 24
NBIO - NorthBridge IO Unit -> Bank 25
PCIE - PCIe Root port -> Bank 26 to 27
PIE - Power Management, Interrupts, Etc -> Bank 28
SMU - System Management Controller Unit -> Bank 29
PCS_XGMI - XGMI Controller -> Bank 30
KPX_SERDES - High Speed Interface Unit(XGMI)-> Bank 31
Empty/Unused bank -> Bank 32 to 63
Total BankNumber = 32
MC Global Capability Value = 120
MC Global Status Value = 0
MC Global Control Value = 0
Number of processor = 64
ProcNum BankNum Socket CCD CCX Core Thread MCA Bank Status MCA Bank Address MCA Configuration MCA IPID MSR VAL MCA SYND MSR VAL MC MISC0 MSR VAL MC MISC1 MSR VAL MC DESTAT MSR VAL MC DEADDR MSR VAL MC SYND1 MSR VAL MC SYND2 MSR VAL
Timestamp H:M:S 13:44:32 D:M:Y 14:8:2025
--- END OF MCA FILE ---
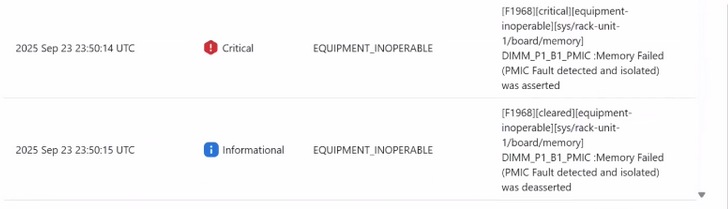
Esempio di errore PMIC nei log di selezione:-
Ogni volta che si verifica un errore PMIC in fase di esecuzione sul DIMM, viene generato il registro SEL come mostrato di seguito e l'host viene spento.
- 2024-06-11 20:26:36 IST → Attenzione Software di sistema evento: Sensore di memoria, memoria non riuscita (errore PMIC rilevato e isolato) asserito, socket DIMM 1, canale A, CPU 2. asserito

Il DIMM difettoso viene mappato dal BIOS all'accensione successiva dell'host. Vediamo il SEL di seguito

Un errore viene generato come illustrato di seguito.

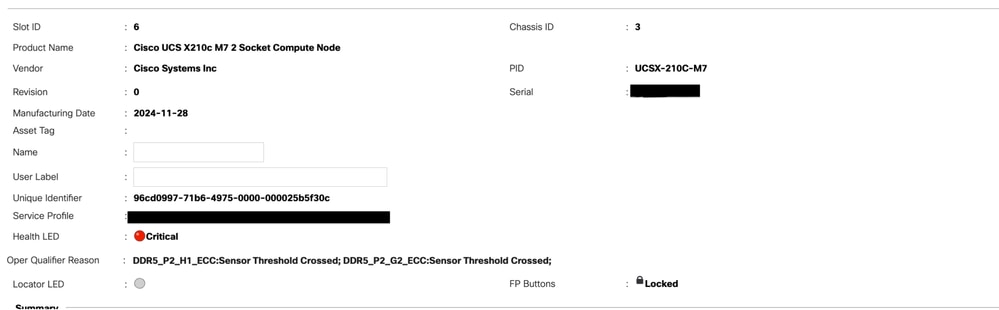
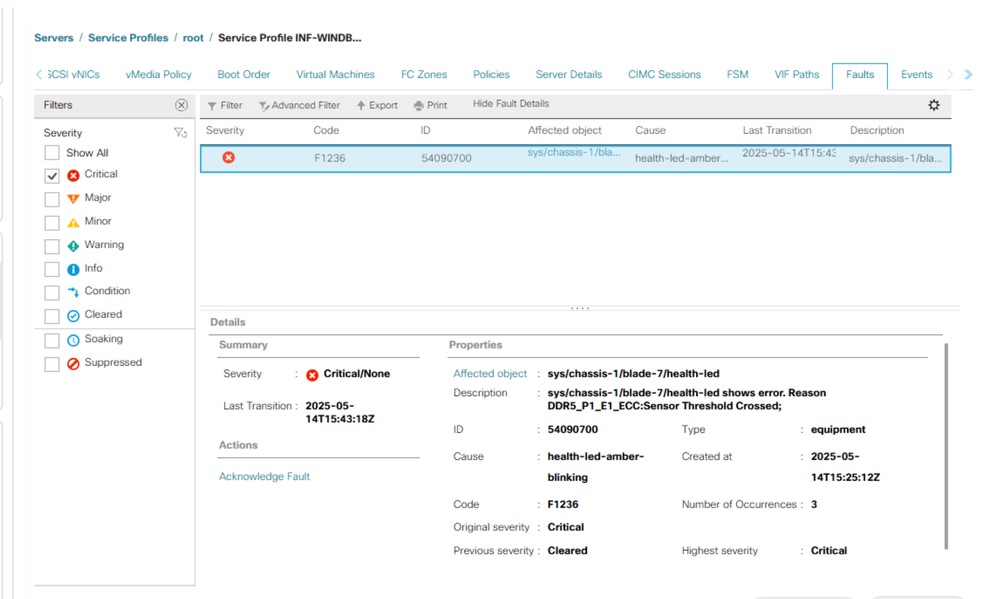
Risoluzione dei problemi relativi agli errori RAS
In genere, questi errori vengono visualizzati in UCS Manager come un evento RAS.
Comandi CLI di UCSM per reimpostare tutti i contatori degli errori di memoria:
Server ambito UCS-A# x/y
UCS-A /chassis/server # reset-all-memory-errors
UCS-A /chassis/server* # commit
Per cancellare i dati SPD:
Spegnere il server
Eseguire quindi i comandi seguenti dalla CLI di UCSM:
UCS-A# connect cimc x/y
UCS-A /chassis/server # reset-all-memory-errors
UCS-A /chassis/server* # commit
Bug degni di nota
1. ID bug Cisco CSCwo62396
2. ID bug Cisco CSCwq3148
3. ID bug Cisco CSCwh73760
 Feedback
Feedback