Introduction
Ce document décrit comment dépanner un problème d'utilisation élevée de l'espace disque pour le système de fichiers /dev/vda3 dans le RCM.
Conditions préalables
Exigences
Cisco vous recommande de connaître les points suivants :
- Architecture et administration du système StarOS Control and User Plane Separation (CUPS).
- Commandes Linux/Unix de base pour la surveillance du système de fichiers et de l'utilisation du disque.
Composants utilisés
Ce document n'est pas limité à des versions de matériel et de logiciel spécifiques.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. Si votre réseau est en ligne, assurez-vous de bien comprendre l’incidence possible des commandes.
Aperçu
Dans les déploiements Cisco Ultra Packet Core avec Control et User Plane Separation (CUPS), le Redundancy Control Manager (RCM) joue un rôle essentiel dans les opérations et la gestion du plan de contrôle. L'utilisation stable du système de fichiers sur les noeuds RCM est importante pour assurer le bon fonctionnement de la journalisation, de la surveillance et de la gestion des sessions des abonnés.
Une utilisation élevée de l'espace disque sur le système de fichiers racine (/dev/vda3) peut entraîner une instabilité du système, des défaillances dans les écritures de journal ou même des redémarrages du service si cette option n'est pas cochée. Cet article présente l'analyse, les étapes de dépannage et les mesures préventives nécessaires pour traiter l'utilisation élevée des disques dans les noeuds du RCM.
Analyse et observation
Lors de la surveillance, il a été constaté que le noeud RCM atteignait 72 % d'utilisation sur son système de fichiers racine.
Snapshot d'utilisation du disque
df -kh
Filesystem Size Used Avail Use% Mounted on
tmpfs 6.3G 9.7M 6.3G 1% /run
/dev/vda3 39G 27G 11G 72% /
tmpfs 32G 4.0K 32G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 488M 48K 452M 1% /var/tmp
/dev/vda1 488M 76K 452M 1% /tmp
Une enquête plus approfondie a permis de constater que les journaux sous /var/log/journal/ avaient augmenté de façon significative. Les journaux générés en juillet représentaient à eux seuls ~3 Go d'espace.
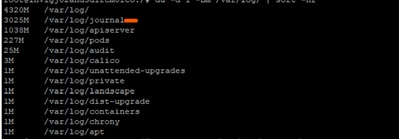
Processus de dépannage
Pour contrôler l'utilisation du disque, les étapes de mise en oeuvre des modifications requises ont été appliquées :
Étape 1 : Nettoyer les anciens journaux en utilisant journalctl Vacuum
Ne conservez que les 2 dernières semaines de journaux :
sudo journalctl --vacuum-time=2weeks
Vous pouvez également limiter la taille du journal (par exemple, ne conserver que 600 Mo) :
sudo journalctl --vacuum-size=600M
Étape 2 : configurez la rétention des journaux pour la prévention future
Modifier la configuration du journal :
vi /etc/systemd/journald.conf
Ajouter/modifier un paramètre :
MaxRetentionSec=2week
Appliquer la configuration :
sudo systemctl restart systemd-journald
Étape 3 facultative : Résoudre erreur de redémarrage
Lors du redémarrage du service systemd-journald à l'étape 2, vous pouvez obtenir une erreur préoccupante :
Error : Failed to allocate directory watch: Too many open files
-
systemd-journald utilise inotify pour surveiller les modifications dans les répertoires de journaux.
-
Chaque montre ou moniteur établit des comptes vers certaines limites du noyau.
Les limites actuelles définies dans le RCM problématique sont les suivantes :
cat /proc/sys/fs/inotify/max_user_watches
501120
cat /proc/sys/fs/inotify/max_user_instances
128
ulimit -n
1024
À partir de la sortie collectée :
- Nombre maximal de montres identifiables : 501120
- Nombre maximal d'instances inotify : 128
Limite de descripteur de fichier ouvert pour le journal : 1024
L'une ou l'autre (ou toutes) des valeurs limites de sortie peut avoir atteint menant à l'erreur. Ainsi, nous avons collecté la valeur utilisée actuelle et les avons comparées à la limite de sortie collectée :
sudo lsof -p $(pidof systemd-journald) | wc -l
65
echo "Root inotify instances: $(sudo find /proc/*/fd -user root -type l -lname 'anon_inode:inotify' 2>/dev/null | wc -l) / $(cat /proc/sys/fs/inotify/max_user_instances)"
Root inotify instances: 126 / 128
Il semble que la racine utilise déjà 126 des 128 instances autorisées inotify. Cela laisse la journalisation avec presque aucun espace pour créer une nouvelle instance inotify quand nous la redémarrons.
Pour résoudre l'erreur : nous pouvons augmenter la valeur max_user_instances et redémarrer le service :
# Temporarily increase the limit (until next reboot)
echo 256 > /proc/sys/fs/inotify/max_user_instances
sudo systemctl restart systemd-journald
# Temporarily increase the limit (until next reboot)
echo 256 > /proc/sys/fs/inotify/max_user_instances
sudo systemctl restart systemd-journald
Vérification post-modification
Après l'application des modifications, l'utilisation du disque a chuté à 61%, restaurant le noeud à l'état de fonctionnement normal.
df -kh
Filesystem Size Used Avail Use% Mounted on
tmpfs 6.3G 9.7M 6.3G 1% /run
/dev/vda3 39G 23G 15G 61% /
tmpfs 32G 4.0K 32G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 488M 48K 452M 1% /var/tmp
/dev/vda1 488M 76K 452M 1% /tmp
Recommandation
-
Mettez en oeuvre la même configuration sur tous les noeuds RCM du déploiement pour maintenir l'utilisation des disques dans des limites sûres.
-
Placez toujours le RCM cible en mode veille avant d'effectuer les modifications pour éviter tout impact sur le trafic en direct.
-
Surveillez régulièrement l'utilisation de /dev/vda3 et la croissance du journal dans le cadre de vérifications proactives de l'état du système.
 Commentaires
Commentaires