Dépannage d'un échec de réplication inter-racks avec le code d'erreur " ; 424-Geo-replication Checksum Mismatch" ;
Options de téléchargement
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Table des matières
Introduction
Ce document décrit diverses méthodes d'investigation pour dépanner la non-concordance de somme de contrôle de géo-réplication entre les racks local et distant.
Conditions préalables
Exigences
Cisco vous recommande de prendre connaissance des rubriques suivantes :
- Redondance géographique dans la fonction de gestion de session (SMF)
- SMF
- Fin de connexion TCP (Transmission Control Protocol)
Composants utilisés
Ce document n'est pas limité à des versions de matériel et de logiciel spécifiques.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. Si votre réseau est en ligne, assurez-vous de bien comprendre l’incidence possible des commandes.
Informations générales
Qu'est-ce que la géo-redondance dans SMF ?
-
SMF prend en charge la redondance géographique (Géo) en mode actif-actif.
-
La configuration GR est également responsable de la réplication des
etcd/cachedonnées vers le rack de secours. -
SMF prend en charge la redondance principale/de secours dans laquelle les données sont répliquées de l'instance principale vers l'instance de secours.
-
Si l'instance principale tombe en panne, l'instance de secours devient l'instance principale et reprend l'opération.
-
Pour atteindre le GR, il est possible de configurer deux paires principale/veille où chaque site traite activement le trafic et la veille agit comme une sauvegarde pour le site distant.
Pod de géo-réplication
-
Le pod de géo-réplication est introduit pour la communication inter-rack/site et pour surveiller le POD/BFD dans le rack
-
Deux instances de GR-POD sont exécutées sur chaque rack/site
-
Deux POD GR fonctionnent en mode actif-veille
-
Les POD GR sont générés sur le noeud Proto/la VM
-
GR POD utilise deux adresses IP virtuelles (VIP)
-
VIP interne pour la communication inter-POD (au sein du rack)
-
VIP externe pour la communication POD GR entre les racks et les sites
-
Les VIP configurés pour GR POD peuvent être actifs sur l'un des noeuds/machines virtuelles Proto
-
Lorsque le POD Active GR redémarre, le VIP est commuté vers un autre noeud/machine virtuelle Proto et le POD de secours GR exécuté sur l'autre noeud/machine virtuelle Proto peut devenir actif
Configuration de référence de pod GR :
smf# show running-config instance instance-id 1 endpoint geo
Thu Oct 20 06:25:25.319 UTC+00:00
instance instance-id 1
endpoint geo
replicas 1
nodes 2
interface geo-internal
vip-ip a.b.c.d vip-port 7001
exit
interface geo-external
vip-ip Y.Y.Y.Y vip-port 7002
exit
exit
exit
Identifier la zone géographique active et la zone géographique de secours
Afin d'identifier la zone géographique active, vous devez vérifier les erreurs ou les événements dans les journaux de la zone géographique.
Pod actif :
user@smf-ims-master-1:~$ kubectl logs georeplication-pod-0 -n smf-smfix1|tail -3
[ERROR] [grcacachepod.go:339] [gr_deferred_sync.application.app] Periodic Sync: Total time taken to sync IPAM cache pod data: 500.563723ms”
[ERROR] [GeoAdminStreamClient.go:276] [gr_pod.geo_admin_client.app] no one waiting for received response for txnID:CP0XXXOKCP0XXX-SMF-IMS-smfix1111163550 of host=geo-admin-pod2
Pod. de secours :
user@cp0xxx-smf-ims-master-1:~$ kubectl logs georeplication-pod-1 -n smf-smfix1|tail -3
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
Fonctionnalités de GR POD
Les modules GR répliquent les données ETCD et Cache Pod sur l'ensemble du site
Pour afficher les détails de la réplication pour les données ETCD et cache-pod, utilisez CLI :
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 1
Thu Oct 20 07:11:52.409 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- -------
1 ETCD 1666249907
IPAM CACHE 1666249907
NRFMgmt CACHE 1666249907
Tenir à jour les rôles des instances locales du site dans ETCD
[ERROR] [gr_pod.gradmin] updateEntryInEtcd: Updating etcd entries for keys : Instance.2, with role as PRIMARY
[ERROR] [gr_pod.gradmin] updateEntryInEtcd: Updating etcd entries for keys : Instance.1, with role as STANDBY
Surveiller l'état du site local (état POD/état BFD)
[cp0xxx-smf-ims/smfix1] smf# show running-config geomonitor podmonitor pods smf-service
Thu Oct 20 07:36:41.280 UTC+00:00
geomonitor podmonitor pods smf-service
retryCount 2
retryInterval 900
retryFailOverInterval 500
failedReplicaPercent 60
Rôles du site
PRIMARY : Le site est prêt et prend activement le trafic pour l'instance donnée.
STANDBY: Le site est en veille, prêt à accepter du trafic, mais n'accepte pas de trafic pour une instance donnée.
STANDBY_ERROR: Le site présente un problème, n'est pas actif et n'est pas prêt à accepter le trafic pour une instance donnée.
FAILOVER_INIT: Le site a commencé à basculer et n'est pas en état de prendre le trafic, temps de mise en mémoire tampon de 2 secondes pour que l'application termine son activité.
FAILOVER_COMPLETE: Le site a terminé le basculement et a tenté d'informer le site homologue du basculement pour l'instance donnée. temps de mémoire tampon de 2 secondes.
FAILBACK_STARTED: Le basculement manuel est déclenché avec un délai à partir du site distant pour une instance donnée.

Remarque : La réplication du cache/ETCD et la réplication CDL se produiraient même dans tous les rôles. Si les liaisons GR sont désactivées/si la pulsation périodique échoue, les déclencheurs GR sont suspendus.
GR-Triggers
CLI pour vérifier les rôles d'instance GR sur le rack
Show role instance id 1
Show role instance id 2
CLI pour réinitialiser le rôle d'erreur de veille en veille
Geo reset-role instance-id <1/2> role standby
Erreur CLI pour passer du rôle de veille à celui de veille
Geo switch-role instance-id <1/2> role standby failback-interval 0
CLI pour passer du rôle de veille au rôle principal
Pour activer ce rôle de commutateur, vous devez déclencher l'interface de ligne de commande à partir du rack dont l'une des instances est principale.
Geo switch-role instance-id <1/2> role standby failback-interval 0
Remarque : Scénario de la journée ensoleillée : Rack1-Instance1-Primary, Instance2-Standby ; Rack2-Instance1-StandBy, Instance2-Primary.
Scénario des jours de pluie : Rack1-Instance 1 et Instance 2-Primary ; Rack2-Instance 1 et Instance 2-StandBy.
Fin de connexion TCP
Le protocole TCP est un protocole orienté connexion, ce qui signifie qu'une connexion est établie et maintenue jusqu'à ce que les programmes d'application à chaque extrémité aient terminé l'échange de messages. Le protocole TCP fonctionne avec le protocole IP (Internet Protocol).
La connexion TCP est également appelée connexion en trois étapes. Lorsqu'une connexion est établie entre la machine client et la machine serveur, le client et le serveur échangent des paquets SYN et ACK avant la transmission des données.
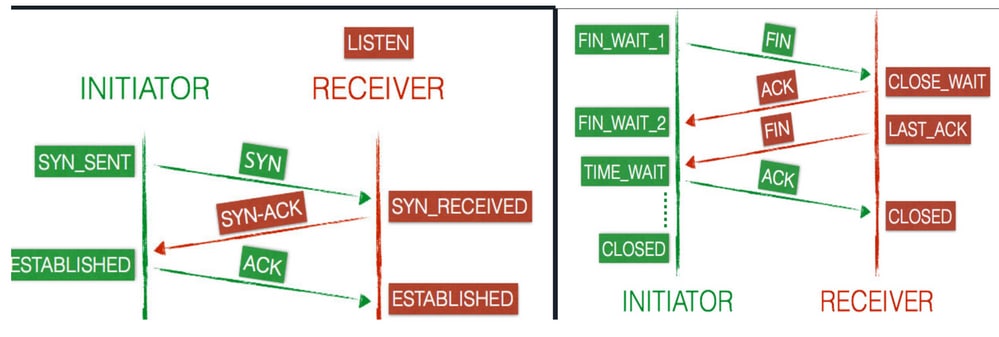 Transmission Control Protocol : état des connexions client et serveur
Transmission Control Protocol : état des connexions client et serveur
Une connexion passe par une série d'états tout au long de sa durée de vie. Les états sont les suivants : LISTEN, SYN-SENT, SYN-RECEIVED, ESTABLISHED, FIN-WAIT-1, FIN-WAIT-2,CLOSE-WAIT,CLOSING, LAST-ACK, TIME-WAITet l'état fictif CLOSED.
- Lorsqu’une nouvelle connexion TCP est ouverte, le client (initiateur) envoie un
SYNpaquet au serveur (récepteur) et met à jour son état enSYN-SENT. - Le serveur envoie alors une
SYN-ACKréponse au client qui change son état de connexion enSYN-RECEIVED.
- Le client répond avec un
ACKmessage et la connexion est marquée comme étant établieESTABLISHEDsur les deux points d'extrémité. Le client et le serveur sont maintenant prêts à transférer des données.
- Le client envoie un
FINpaquet au serveur et met à jour son état enFIN-WAIT-1. - Le serveur reçoit la demande de terminaison du client et répond par un
ACK. Après la réponse, le serveur passe à l'CLOSE-WAITétat suivant. - Dès que le client reçoit la réponse du serveur, il passe à l’
FIN-WAIT-2état . - Le serveur est toujours dans l'
CLOSE-WAITétat et il va indépendamment avec un FIN, qui met à jour l'état enLAST-ACK. - À présent, le client reçoit la demande de terminaison et répond avec un
ACKmessage, ce qui donne unTIME-WAITétat. - Le serveur a maintenant terminé et définit la connexion sur
CLOSEDimmédiatement. - Le client reste dans cet
TIME-WAITétat pendant quatre minutes au maximum, avant que la connexion ne soitCLOSEDétablie.
Problème
Scénario 1. La somme de contrôle de la géo-réplication pour l'ID d'instance 1 présente une incohérence entre le cache IPAM et la somme de contrôle du cache NRFMgmt
l'état de la géo-réplication smfix1/smfix2 a échoué (échec de la réplication inter-rack vers le site distant).
ERREUR : La commande admin a échoué [pod internal-gr-pod-1, URL http://X.X.0.0:15290/commands] avec le code 424, Message fail : non-concordance de la somme de contrôle de réplication.
Le problème a été observé le 23 août à 00:36:19 sous le nom « Inter-rack replication failed ».
From CEE alerts:
Inter_Rack_Replication 9ca45362a049 critical 08-23T00:36:19 System
Inter rack replication to Remote Site failed
Dans cette sortie CLI, vous pouvez voir que l'ID d'instance 1 a une non-concordance de somme de contrôle pour la gestion des adresses IP (IPAM) et le cache NRF.
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 1
Mon Sep 5 08:38:27.762 UTC+00:00
checksum-details
-- --- --------
ID Type Checksum
-- ---- --------
1 ETCD 1662367102
IPAM CACHE 1662367102
NRFMgmtCACHE 1662367102
[cp0xxx-smf-ims/smfix2] smf# show georeplication checksum instance-id 1
Mon Sep 5 08:38:30.767 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- --------
1 ETCD 1662367102
IPAM CACHE 1661214831
NRFMgmtCACHE 1661214831
Scénario 2. La somme de contrôle de la géo-réplication pour l'ID d'instance 2 présente une non-concordance de somme de contrôle ETCD
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 2
Mon Sep 5 08:38:37.852 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- --------
2 ETCD 1661214828
IPAM CACHE 1662367107
NRFMgmtCACHE 1662367107
[cp0xxx-smf-ims/smfix2] smf# show georeplication checksum instance-id 2
Mon Sep 5 08:38:39.118 UTC+00:00
checksum-details
-- ---- -------
ID Type Checksum
-- ---- --------
2 ETCD 1662367107
IPAM CACHE 1662367107
NRFMgmtCACHE 1662367107
Scénario 3. Échec de l’établissement de la connexion TCP avec le site distant
Rack1-smfix1-logs :
À partir des journaux du pod GR, vous pouvez observer que le point de contrôle du pod de cache de mise à jour est arrêté, que la réplication immédiate a échoué et qu'aucun hôte distant n'est disponible.
2022/08/23 00:34:00.035 [ERROR] [grreplicationclient.go:201] [gr_pod.geo_replication_client_stream.app] HandleImmediateReplication failed: [RPCNoRemoteHostAvailable] No remote host available for this request
2022/08/23 00:34:02.086 [ERROR] [grreplicationclient.go:466] [gr_pod.geo_replication_client_stream.app] Stream disconnected, closing logQueueCounter=0xc0093b08b0
2022/08/23 00:34:04.124 [ERROR] [GeoAdminStreamClient.go:215] [gr_pod.geo_admin_client.app] ADMIN(geo-admin-pod2) : exit outgoing request loop stream closed
2022/08/23 00:34:43.623 [ERROR] [grreplicationclient.go:270] [gr_pod.geo_replication_client_stream.app] Update etcd checkpointing stopped for grinstance: 1
Rack2-smfix2-logs :
À partir des journaux GR Pod, vous pouvez observer une erreur de déconnexion du flux et la différence de somme de contrôle CACHE est plus importante que prévu.
2022/08/23 00:34:06.497 [ERROR] [grreplicationserver.go:62] [gr_pod.geo_replication_server_stream.app] Stream disconnected, closing logQueueCounter=0xc001b85d08
2022/08/23 00:34:06.497 [ERROR] [grreplicationserver.go:314] [gr_pod.geo_replication_server_stream.app] handleCachePodSyncRequests : Stream closed of connection=0xc002ee08f0
2022/08/23 00:34:56.751 [ERROR] [grpodcommands.go:455] [gr_pod.cli_command.app] compareChecksumData: CACHE checksum difference is more then expected, local checksum [1661214831] remote checksum [1661214892]
2022/08/23 00:34:56.678 [ERROR] [etcdAuditReplHandler.go:196] [gr_pod.application.app] SyncETCDData periodic sync : For ETCD [C.GR.1.] key, the remote site data size is: [10833]
2022/08/23 00:36:56.757 [ERROR] [grpodcommands.go:455] [gr_pod.cli_command.app] compareChecksumData: CACHE checksum difference is more then expected, local checksum [1661214831] remote checksum [1661215012]
Scénario 4. Erreur DIMM observée sur le serveur hébergeant le noeud maître
Une erreur ECC est détectée sur le noeud master-1 qui héberge geo-replication-pod-0 en même temps que l'erreur de déconnexion du flux.
CP0XXX-Server9-02# scope sel
CP0XXX-Server9-02 /sel # show entries
Time Severity Description
----------------------- ------------- ----------------------------------------
2022-08-23 00:33:59 UTC Informational "DDR4_P1_E1_ECC: Memory sensor, read 1 correctable ECC errors on CPU1 DIMM E1 was asserted"
2022-08-22 22:59:45 UTC Informational "DDR4_P1_E1_ECC: Memory sensor, read 1 correctable ECC errors on CPU1 DIMM E1 was asserted"
- La communication entre le pod de géo-réplication sur le rack1 et le pod de géo-réplication sur le rack2 est interrompue.
-
Une erreur DIMM se produit sur l'un des noeuds maîtres, ce qui a entraîné l'interruption de la connexion de flux entre les racks 1 et 2.
-
À partir du Rack1 Geo-replication-pod n'a pas pu répliquer ou envoyer de requête au Rack2, il s'affiche avec l'erreur Remote Host not available.
-
D'après le résultat de la commande netstat sur les racks 1 et 2 pour le port 7002, le socket du rack 1 est bloqué dans l'état FIN_WAIT1 et le socket du rack 2 est bloqué dans l'état SYN_RECV.
-
Côté serveur, c'est-à-dire sur le rack2, le socket est bloqué dans l'état SYNC_RECV, et la connexion nouvellement créée passe également dans l'état SYNC_RECV et ne peut pas communiquer entre elle.
-
La connexion est dans l'état SYN_RECV parce que le noyau a reçu un paquet SYN pour un port, c'est-à-dire en mode LISTENING, mais l'autre extrémité n'a pas répondu avec ACK.
smfix2-Master-2 a un VIP géo externe (Y.Y.Y.Y:7002) installé, mais l'état de connexion TCP de l'hôte distant (SMFIX1) est bloqué dans l'état SYN_RECV au lieu de l'état ESTABLISHED. a.b.c.d et a.b.c.e sont les adresses IP Master-1 et 2 de smfix1 (Rack1).
user@cp0xxx-smf-ims-master-2:~$ netstat -anp | grep 7002
tcp 0 0 Y.Y.Y.Y:7002 0.0.0.0:* LISTEN -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:35542 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:47046 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:36248 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:42686 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:38248 SYN_RECV -
L'état de la connexion TCP Geo VIP externe sur smfix1 (Rack1) pour l'homologue distant est à l'état FIN-WAIT1 :
user@cp0xxx-smf-ims-master-1:~$ netstat -anp | grep 7002
tcp 0 0 a.b.c.d 0.0.0.0:* LISTEN -
tcp 0 1 a.b.c.d:60866 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:52274 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:59674 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:47926 Y.Y.Y.Y:7002 FIN_WAIT1 -
Solution
Rack1 :
-
Tout d'abord, supprimez le pod Geo de secours, attendez que le pod se rétablisse, puis supprimez le pod Geo actif. Connectez-vous au VIP maître et supprimez le pod GR :
kubectl delete pod-n
Rack2 :
- Tout d'abord, supprimez le pod Geo de secours, attendez que le pod se rétablisse, puis supprimez le pod Geo actif.
-
Vérifiez l'état de la géo-réplication à partir de l'interface de ligne de commande, puis publiez la suppression des modules Geo.
show georeplication-status
- Après la suppression de la zone Geo sur Rack1 et Rack2, vous pouvez voir l'IP externe Geo VIP : Le port TCP passe à l'état ESTABLISHED.
- État de la géo-réplication « Pass ».
- Aucune incohérence de somme de contrôle n'est observée dans l'état de réplication sur les racks.
smfix2 (Rack2) :
user@cp0xxx-smf-ims-master-1:~$ sudo netstat -anp | grep 7002 | grep -v aa
tcp 0 0 Y.Y.Y.Y:7002 0.0.0.0:* LISTEN 36854
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:46402 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 1a.b.c.e:54708 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:55152 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:46530 ESTABLISHED 36854/grpod
tcp 0 0 10.59.0.0:7002 10.59.0.0:46532 ESTABLISHED 36854/grpod
smfix1 (Rack1) :
user@cp0xxx-smf-ims-master-1:~$ sudo netstat -anp | grep 7002 | grep -v aa
tcp 0 0 a.b.c.d 0.0.0.0:* LISTEN 53932/grpod
tcp 0 0 a.b.c.d:46530 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
tcp 0 0 a.b.c.d:46402 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
tcp 0 17 a.b.c.d:46532 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
2. État de la géo-réplication :
[okcp0xx-smf-ims/smfix1] smf# show georeplication-status
result "pass"
[okcp0xx-smf-ims/smfix2] smf# show georeplication-status
result "pass"
Historique de révision
| Révision | Date de publication | Commentaires |
|---|---|---|
1.0 |
05-Dec-2022
|
Première publication |
Contribution d’experts de Cisco
- Manasa G KambiIngénieur TAC Cisco
- Krishna Kishore D VResponsable technique Cisco
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)