Dépannage des problèmes lorsque Element Manager s'exécute en mode autonome
Options de téléchargement
-
ePub (188.5 KB)
Consulter à l’aide de différentes applications sur iPhone, iPad, Android ou Windows Phone -
Mobi (Kindle) (189.0 KB)
Consulter sur un appareil Kindle ou à l’aide d’une application Kindle sur plusieurs appareils
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Contenu
Introduction
Ce document fournit un résumé sur la façon de dépanner les problèmes lorsque le gestionnaire d'éléments s'exécute en mode autonome.
Conditions préalables
Conditions requises
Cisco vous recommande de prendre connaissance des rubriques suivantes :
- StarOs
- Architecture de base Ultra-M
Components Used
Les informations de ce document sont basées sur la version Ultra 5.1.x.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. Si votre réseau est en ligne, assurez-vous de bien comprendre l’incidence possible des commandes.
Informations générales
Ultra-M est une solution de coeur de réseau de paquets mobiles virtualisés prépackagée et validée conçue pour simplifier le déploiement des VNF. OpenStack est le gestionnaire d'infrastructure virtualisée (VIM) pour Ultra-M et comprend les types de noeuds suivants :
- Calcul
- Disque de stockage d'objets - Calcul (OSD - Calcul)
- Contrôleur
- Plate-forme OpenStack - Director (OSPD)
L'architecture de haut niveau d'Ultra-M et les composants impliqués sont représentés dans cette image :
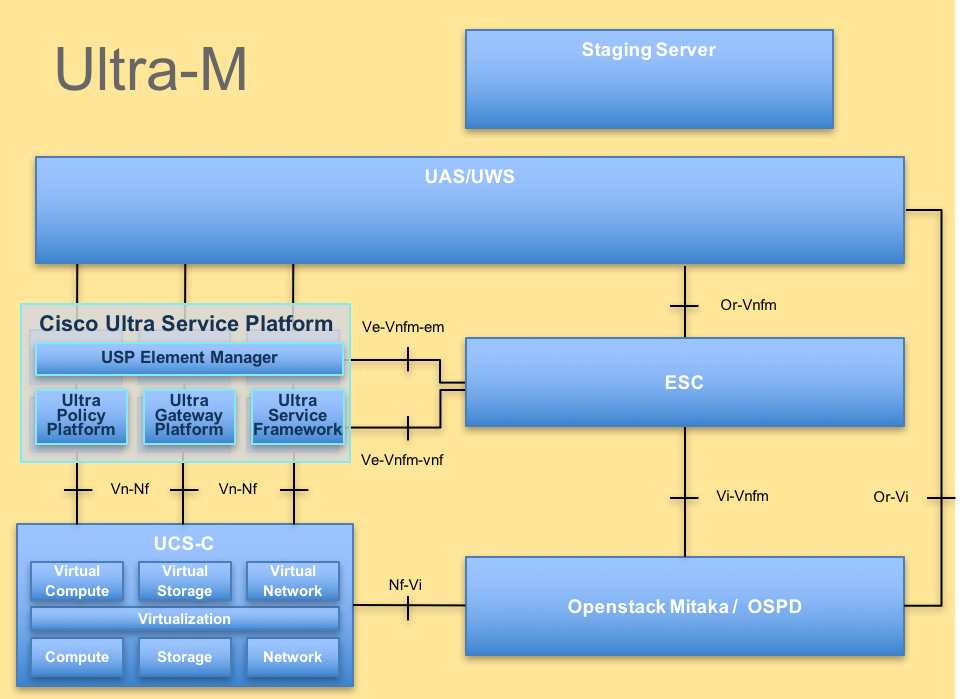 Architecture UltraM
Architecture UltraM
Ce document est destiné au personnel Cisco familier avec la plate-forme Cisco Ultra-M et décrit les étapes à suivre au niveau OpenStack et StarOS VNF au moment du remplacement du serveur du contrôleur.
Abréviations
Ces abréviations sont utilisées dans cet article :
| VNF | Fonction de réseau virtuel |
| EM | Gestionnaire d'éléments |
| VIP | Adresse IP virtuelle |
| CLI | Ligne de commande |
Problème : EM peut se retrouver dans cet état comme il semble dans UltraM Health Manager
EM: 1 is not part of HA-CLUSTER,EM is running in standalone mode
Cela dépend de la version, il peut y avoir 2 ou 3 EM qui s'exécutent sur le système.
Dans le cas où vous avez déployé 3 EM, deux d'entre eux seraient fonctionnels et un troisième simplement pour être en mesure d'avoir le cluster Zookeeper. Cependant, il n'est pas utilisé.
Si l'un des deux EM fonctionnels ne fonctionnait pas ou n'était pas accessible, le EM fonctionnel serait en mode autonome.
Si vous avez déployé 2 modules EM, si l'un d'eux ne fonctionne pas ou n'est pas accessible, le reste du module EM peut être en mode autonome.
Ce document explique comment rechercher si cela se produit et comment récupérer.
Étapes de dépannage et de récupération
Étape 1. Vérifiez l'état des EM.
Connectez-vous au processeur VIP EM et vérifiez que le noeud est dans cet état :
root@em-0:~# ncs_cli -u admin -C
admin connected from 127.0.0.1 using console on em-0
admin@scm# show ems
EM VNFM ID SLA SCM PROXY
3 up down up
admin@scm#
Ainsi, à partir d'ici, vous pouvez voir qu'il n'y a qu'une seule entrée dans SCM - et c'est l'entrée pour notre noeud.
Si vous parvenez à vous connecter à l'autre EM, vous pouvez voir quelque chose comme :
root@em-1# ncs_cli -u admin -C admin connected from 127.0.0.1 using
admin connected from 127.0.0.1 using console on em-1
admin@scm# show ems
% No entries found.
Selon le problème rencontré sur le module EM, l'interface de ligne de commande NCS ne peut pas être accessible ou le noeud peut redémarrer.
Étape 2. Vérifiez les journaux dans /var/log/em sur le noeud qui ne rejoint pas le cluster.
Vérifiez les journaux sur le noeud dans l'état du problème. Ainsi, pour l'exemple mentionné, vous naviguerez dans les journaux em-1/var/log/em/zookeeper :
...
2018-02-01 09:52:33,591 [myid:4] - INFO [main:QuorumPeerMain@127] - Starting quorum peer
2018-02-01 09:52:33,619 [myid:4] - INFO [main:NIOServerCnxnFactory@89] - binding to port 0.0.0.0/0.0.0.0:2181
2018-02-01 09:52:33,627 [myid:4] - INFO [main:QuorumPeer@1019] - tickTime set to 3000
2018-02-01 09:52:33,628 [myid:4] - INFO [main:QuorumPeer@1039] - minSessionTimeout set to -1
2018-02-01 09:52:33,628 [myid:4] - INFO [main:QuorumPeer@1050] - maxSessionTimeout set to -1
2018-02-01 09:52:33,628 [myid:4] - INFO [main:QuorumPeer@1065] - initLimit set to 5
2018-02-01 09:52:33,641 [myid:4] - INFO [main:FileSnap@83] - Reading snapshot /var/lib/zookeeper/data/version-2/snapshot.5000000b3
2018-02-01 09:52:33,665 [myid:4] - ERROR [main:QuorumPeer@557] - Unable to load database on disk
java.io.IOException: The current epoch, 5, is older than the last zxid, 25769803777
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:539)
at org.apache.zookeeper.server.quorum.QuorumPeer.start(QuorumPeer.java:500)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.runFromConfig(QuorumPeerMain.java:153)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:111)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:78)
2018-02-01 09:52:33,671 [myid:4] - ERROR [main:QuorumPeerMain@89] - Unexpected exception, exiting abnormally
java.lang.RuntimeException: Unable to run quorum server
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:558)
at org.apache.zookeeper.server.quorum.QuorumPeer.start(QuorumPeer.java:500)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.runFromConfig(QuorumPeerMain.java:153)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:111)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:78)
Caused by: java.io.IOException: The current epoch, 5, is older than the last zxid, 25769803777
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:539)
Étape 3. Vérifiez qu'il existe un snapshot en question.
Accédez à /var/lib/zookeeper/data/version-2 et vérifiez que l'instantané qui est rouge à l'étape 2 est présent.
300000042 log.500000001 snapshot.300000041 snapshot.40000003b
ubuntu@em-1:/var/lib/zookeeper/data/version-2$ ls -la
total 424
drwxrwxr-x 2 zk zk 4096 Jan 30 12:12 .
drwxr-xr-x 3 zk zk 4096 Feb 1 10:33 ..
-rw-rw-r-- 1 zk zk 1 Jan 30 12:12 acceptedEpoch
-rw-rw-r-- 1 zk zk 1 Jan 30 12:09 currentEpoch
-rw-rw-r-- 1 zk zk 1 Jan 30 12:12 currentEpoch.tmp
-rw-rw-r-- 1 zk zk 67108880 Jan 9 20:11 log.300000042
-rw-rw-r-- 1 zk zk 67108880 Jan 30 10:45 log.400000024
-rw-rw-r-- 1 zk zk 67108880 Jan 30 12:09 log.500000001
-rw-rw-r-- 1 zk zk 67108880 Jan 30 12:11 log.5000000b4
-rw-rw-r-- 1 zk zk 69734 Jan 6 05:14 snapshot.300000041
-rw-rw-r-- 1 zk zk 73332 Jan 29 09:21 snapshot.400000023
-rw-rw-r-- 1 zk zk 73877 Jan 30 11:43 snapshot.40000003b
-rw-rw-r-- 1 zk zk 84116 Jan 30 12:09 snapshot.5000000b3 ---> HERE, you see it
ubuntu@em-1:/var/lib/zookeeper/data/version-2$
Étape 4. Étapes de récupération.
1. Activez le mode de débogage pour que EM arrête le redémarrage.
ubuntu@em-1:~$ sudo /opt/cisco/em-scripts/enable_debug_mode.sh
Le redémarrage de la machine virtuelle peut être nécessaire à nouveau (automatiquement, vous n'avez rien à faire)
2. Déplacez les données du zookeeper.
Dans le /var/lib/zookeeper/data, il y a le dossier appelé version-2 qui a l'instantané de la base de données. L'erreur ci-dessus indique l'échec du chargement pour que vous le supprimiez.
ubuntu@em-1:/var/lib/zookeeper/data$ sudo mv version-2 old ubuntu@em-1:/var/lib/zookeeper/data$ ls -la total 20 .... -rw-r--r-- 1 zk zk 2 Feb 1 10:33 myid drwxrwxr-x 2 zk zk 4096 Jan 30 12:12 old --> so you see now old folder and you do not see version-2 -rw-rw-r-- 1 zk zk 4 Feb 1 10:33 zookeeper_server.pid ..
3. Redémarrez le noeud.
sudo reboot
4. Désactivez le mode de débogage.
ubuntu@em-1:~$ sudo /opt/cisco/em-scripts/disable_debug_mode.sh
Ces étapes permettent de rétablir le service sur le problème EM.
Contribution d’experts de Cisco
- Snezana MitrovicCisco TAC Engineer
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)