Qu’est-ce qu’Expressway Cluster et comment ça marche ?
Options de téléchargement
-
ePub (936.5 KB)
Consulter à l’aide de différentes applications sur iPhone, iPad, Android ou Windows Phone -
Mobi (Kindle) (840.5 KB)
Consulter sur un appareil Kindle ou à l’aide d’une application Kindle sur plusieurs appareils
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Table des matières
Introduction
Ce document décrit comment les clusters Expressway sont conçus pour étendre la résilience et la capacité d’une installation Expressway.
Informations générales
Capacité. Le cluster Expressway peut augmenter la capacité d’un déploiement Expressway d’un facteur maximum de quatre, par rapport à un seul Expressway. Les homologues Expressway dans un cluster partagent l’utilisation de la bande passante ainsi que le routage, la zone, FindMe et d’autres configurations.
Résilience. Le cluster Expressway peut fournir une redondance lorsqu’un Expressway est en mode maintenance, ou au cas où il deviendrait inaccessible en raison d’une panne de réseau ou d’alimentation, ou pour toute autre raison. Les terminaux peuvent s’enregistrer auprès de n’importe quel homologue dans un cluster. Si les points d'extrémité perdent la connexion à leur homologue initial, ils peuvent se réinscrire à un autre dans le cluster.
Spécifications
Un Expressway peut faire partie d’un groupe de six Expressway au maximum. Lorsque vous créez un cluster, vous désignez un homologue comme homologue principal, à partir duquel sa configuration est répliquée vers les autres homologues. Chaque homologue Expressway dans le cluster doit avoir les mêmes capacités de routage, si un Expressway peut router un appel vers une destination, il est supposé que tous les homologues Expressway dans ce cluster peuvent router un appel vers cette destination.
Capacité
Il n'y a aucun gain de capacité après quatre homologues. Ainsi, dans un cluster de six homologues, par exemple, les cinquième et sixième Expressways n’ajoutent pas de capacité d’appel supplémentaire au cluster. La résilience est améliorée avec les homologues supplémentaires, mais pas la capacité.
- Pour les petites machines virtuelles (VM), le cluster est uniquement destiné à la redondance et non à l'évolutivité, et il n'y a aucun gain de capacité du cluster.
- La capacité basée sur une configuration de cluster à 4 homologues est illustrée dans l'image suivante :
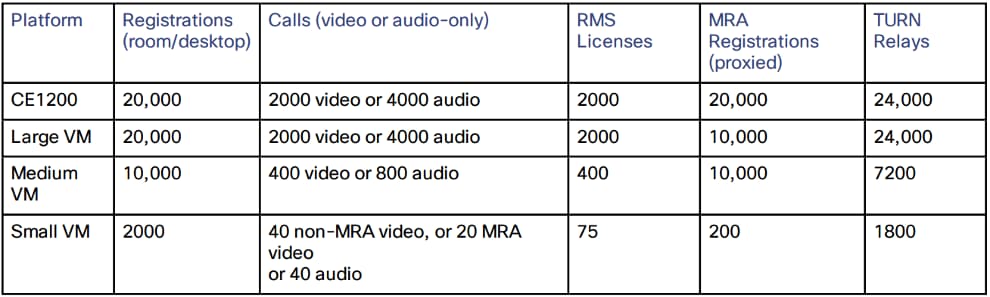
Éléments de page importants

Exigences
- Connaissances de base de Secure Shell (SSH)
- Un cluster doit contenir uniquement un noeud Expressway-C ou uniquement des noeuds Expressway-E.
- Tous les homologues doivent utiliser la même version logicielle.
- Tous les homologues utilisent une plate-forme matérielle, un appareil ou une machine virtuelle (VM), avec des fonctionnalités équivalentes.
- Expressway prend en charge un délai de transmission aller-retour pouvant atteindre 80 ms.
- Le mode H323 est activé sur chaque homologue.
- Tous les homologues ont le même jeu de clés d'option installé, avec les exceptions suivantes :
- Pour Video Control Server (VCS) : Licences d'appel transversal et non transversal
- Pour Expressway : Sessions multimédias
- Pour Expressway : Licences d'enregistrement des systèmes de salle et de bureau
Toutes les autres clés de licence doivent être identiques sur chaque homologue.
- Il ne doit pas y avoir de traduction d'adresses de réseau (NAT) entre les homologues de cluster.
Remarque : Si Expressway-E utilise un seul contrôleur d’interface réseau (NIC), il doit utiliser une adresse IP publique. Si Expressway-E utilise une carte réseau double, l’interface interne doit être utilisée pour créer le cluster.
- L'adresse IP, le service DNS (Domain Name Service) et le protocole NTP (Network Time Protocol) doivent être configurés.
Connexions et ports de cluster
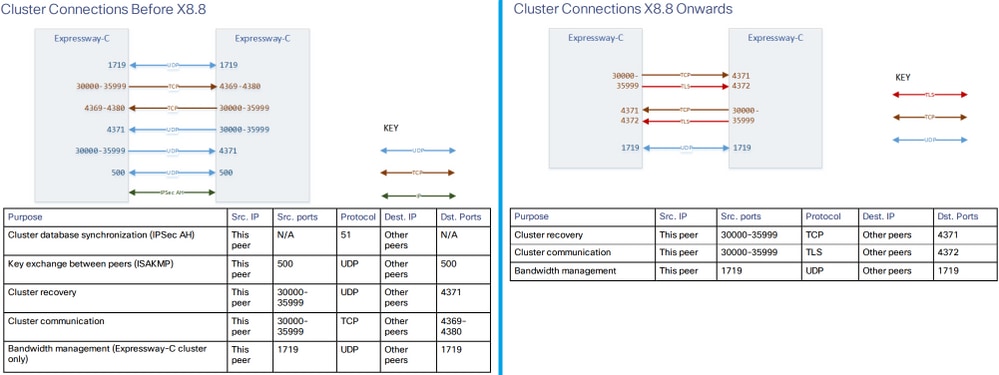
Configurations
Créer un nouveau cluster
- Ouvrez l’interface Web d’Expressway.
- Accédez à System > Clustering.
- Entrez les valeurs suivantes :
Remarque : Vous devez d'abord créer un cluster d'un homologue (principal), puis redémarrer l'homologue principal, avant d'ajouter d'autres homologues. Vous pouvez ajouter d'autres homologues après avoir établi un cluster d'un.
Principal de configuration : 1
Version IP du cluster : Choisissez IPv4 ou IPv6 pour qu'il corresponde au modèle d'adresse réseau.
Options du mode de vérification TLS : Permissive (par défaut) ou Enforce.
Permissive signifie que les homologues ne valident pas leurs certificats respectifs lorsque les connexions TLS (Transport Layer Security) intra-cluster sont établies.
L'application est plus sécurisée, mais nécessite que chaque homologue possède un certificat valide et que l'autorité de certification (CA) soit approuvée par tous les autres homologues.
Adresse homologue 1 : Entrez l’adresse de cet Expressway (l’homologue principal). Si le mode de vérification TLS est défini sur Appliquer, vous devez entrer un nom de domaine complet (FQDN) qui correspond au nom commun du sujet (CN) ou à un autre nom de sujet (SAN) sur le certificat de cet homologue.
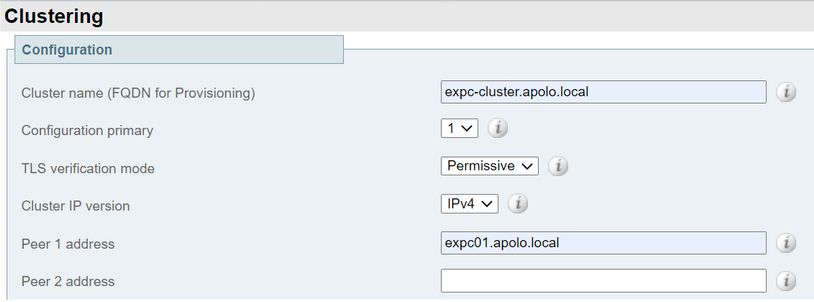
- Sélectionnez Enregistrer.
- Redémarrez le serveur.
- Accédez à Maintenance > Options de redémarrage, puis sélectionnez Redémarrer et confirmez OK.
- Vérifiez que le certificat est valide, comme indiqué dans l'image suivante :
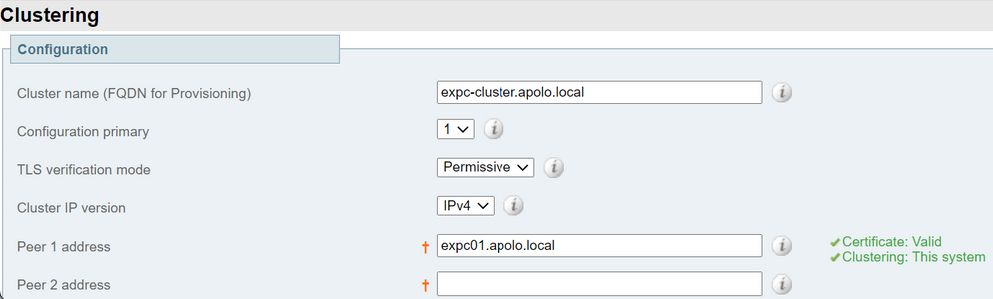
Ajouter des homologues supplémentaires au cluster
Afin d'ajouter un homologue supplémentaire, suivez les étapes suivantes :
- Accédez à System > Clustering sur l’Expressway principal.
- Dans le premier champ vide, entrez l’adresse du nouvel homologue Expressway.
- Sélectionnez Enregistrer.
- L'homologue 1 doit indiquer Ce système. Le nouvel homologue doit indiquer Unknown, puis avec une actualisation doit indiquer Failed parce qu'il n'a pas encore complètement rejoint le cluster.
- Accédez à System > Clustering sur l'un des homologues subordonnés déjà dans le cluster, et modifiez les champs suivants :

- Répétez l'étape précédente pour chacun des homologues subordonnés déjà dans le cluster.
- Sélectionnez Enregistrer.
- L’Expressway déclenche une alarme d’échec de communication de cluster. L'alarme disparaît après le redémarrage requis.
- Redémarrez Expressway.
- Après le redémarrage, patientez environ 2 minutes. Il s'agit de la fréquence à laquelle la configuration est copiée à partir du serveur principal.
- Validez l'état de la base de données de cluster.

- Assurez-vous que la configuration est répliquée sur un homologue subordonné.

Appliquer la vérification TLS
Mise en garde : Avant de continuer, vérifiez que vos SAN de certificat contiennent les noms de domaine complets qui figurent dans les champs d'adresse de l'homologue N. Vous devez voir des messages d'état verts pour le clustering et le certificat en regard de chaque champ d'adresse avant de continuer.


- Sur l'homologue principal, définissez le mode de vérification TLS sur Enforce.
Mise en garde : Un avertissement s'affiche si des certificats ne sont pas valides et empêche le cluster de fonctionner correctement en mode de vérification TLS appliquée.
- Le nouveau mode de vérification TLS est répliqué dans toute la grappe.
- Vérifiez que le mode de vérification TLS est maintenant Enforce sur chaque homologue.
- Sélectionnez Save et redémarrez l'homologue principal.
- Une fois que l'homologue principal est de nouveau en ligne, redémarrez chaque homologue un par un.
- Attendez que le cluster se stabilise et vérifiez que l'état Clustering et Certificate est vert pour tous les homologues.

Modifier l'homologue principal
Remarque : Vous pouvez effectuer ce processus même si l'homologue principal actuel n'est pas accessible.
- Sur le nouvel Expressway principal, accédez à System > Clustering.
- Dans le menu déroulant Configuration primary, sélectionnez le numéro d'ID de l'entrée homologue qui indique This system.
- Sélectionnez Enregistrer.
Remarque : Pendant que ce processus est effectué, ignorez toutes les alarmes sur Expressway qui signalent une non-correspondance principale de cluster ou une erreur de réplication de cluster.
- Sur tous les autres homologues Expressway, commencez par l’ancien homologue principal (s’il est toujours accessible).
- Accédez à System > Clustering.
- Dans le menu déroulant Configuration primary, sélectionnez le numéro d’ID de la nouvelle voie express principale.
- Sélectionnez Enregistrer.
- Vérifiez que la modification de la configuration principale a été acceptée, accédez à Système > Clustering et actualisez la page.
- Si un Expressways n’a pas accepté la modification, répétez la même procédure.
- Vérifiez que l'état de la base de données de cluster est Actif.
Modifier le cluster pour utiliser les FQDN
Remarque : Lors de cette procédure, les communications entre homologues sont temporairement affectées, ce qui signifie que des alarmes devraient persister jusqu'à ce que les modifications soient terminées et que le cluster accepte les nouvelles adresses.
- Connectez-vous à tous les homologues du cluster et accédez à System > Clustering.
- Choisissez l'adresse d'homologue qui est modifiée. il est recommandé de commencer par l'adresse Peer 1.
- Sur chaque homologue du cluster, procédez comme suit :
- Remplacez le champ de l'adresse d'homologue choisie de l'adresse IP par son nom de domaine complet.
- Sélectionnez Enregistrer.
- Basculez vers l'homologue identifié par l'adresse d'homologue modifiée que vous avez sélectionnée et redémarrez le serveur.
- Attendez la résolution des alarmes de cluster transitoires.
- Choisissez la prochaine adresse homologue à modifier, puis répétez les étapes 3 à 7.
- Répétez cette procédure jusqu'à ce que vous ayez modifié toutes les adresses d'homologue et redémarré tous les homologues.
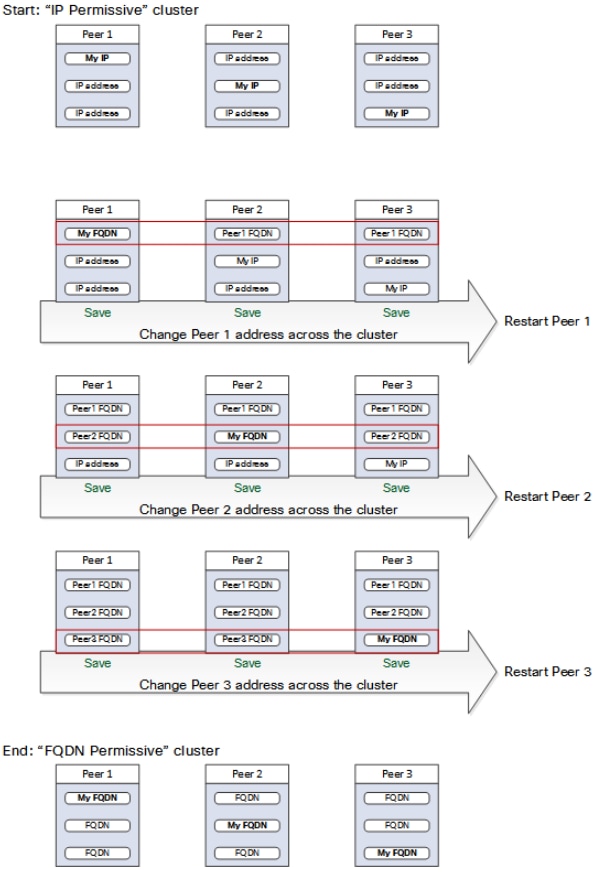
Mappage d’adresses de cluster pour Expressway-E
Pour les déploiements sécurisés comme Mobile and Remote Access (MRA), chaque homologue Expressway-E doit avoir un certificat avec un SAN qui contient son nom de domaine complet public. Le nom de domaine complet est mappé dans le DNS public à l’adresse IP publique de l’Expressway-E.
Remarque : Si vous souhaitez simplement mettre en grappe des homologues Cisco Expressway-E et que vous n’avez pas besoin d’une vérification TLS entre eux, vous pouvez former la grappe avec les adresses IP privées des noeuds. Vous n'avez pas besoin du mappage d'adresses de cluster.
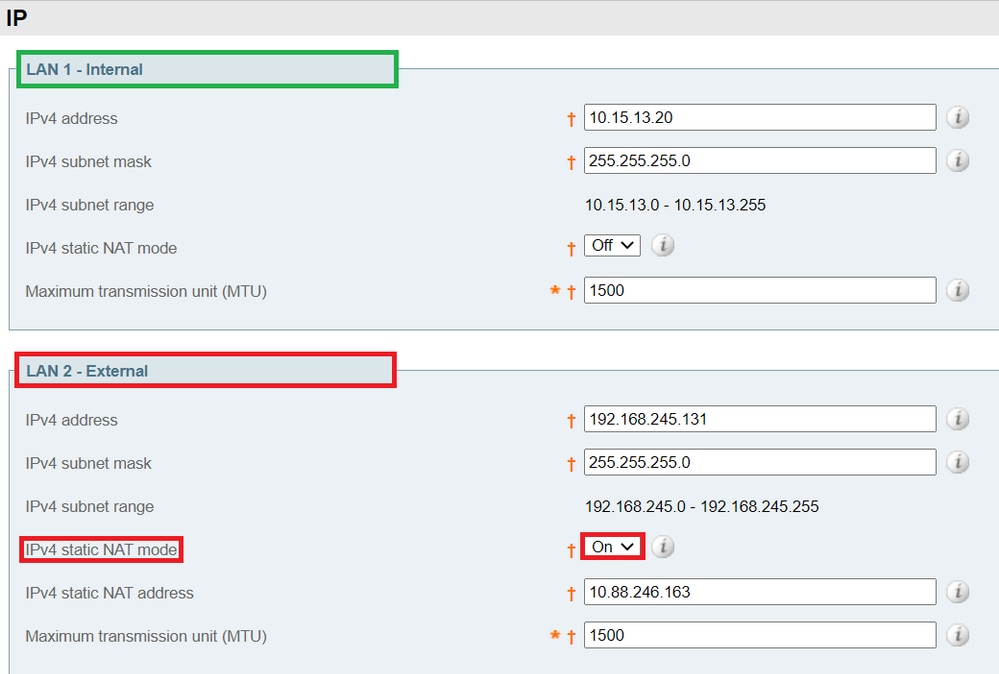
Les mappages d'adresses de cluster sont des paires FQDN:IP qui sont partagées autour du cluster, une paire pour chaque homologue. Les homologues consultent la table de mappage avant d'interroger DNS et, s'ils trouvent une correspondance, ils n'interrogent pas DNS.
Si vous choisissez d'appliquer TLS, les homologues doivent également lire les noms du champ SAN des certificats des autres et vérifier chaque nom par rapport au côté FQDN du mappage.
Il est fortement recommandé d'entrer les mappages sur l'homologue principal. Les mappages d'adresses se répliquent dynamiquement via le cluster. Afin de configurer le mappage d'adresse, suivez la procédure suivante :
- Accédez à System > Clustering sur l'homologue principal, et changez la liste déroulante Cluster address mapping enabled en On (la valeur par défaut est Off). Les champs de mappage d'adresse de cluster s'affichent.
- Modifiez les mappages afin que les noms de domaine complets publics des homologues Expressway-E correspondent aux adresses IP de leurs cartes réseau internes.
- Sélectionnez Enregistrer.

Mise en garde : N'essayez pas d'utiliser le DNS public pour mapper les FQDN publics des homologues à leurs adresses IP privées, cette action peut interrompre la connectivité externe.
Cluster avec une seule carte réseau
Si vous souhaitez que les homologues Expressway-E d’un cluster vérifient leurs identités réciproques à l’aide de certificats, vous pouvez leur permettre d’utiliser DNS pour convertir leurs noms de domaine complets d’homologues de cluster en leurs adresses IP publiques. C’est une façon parfaitement acceptable de former un cluster si les noeuds Expressway-E ont :
- Une seule carte réseau
- Aucune NAT statique configurée
- Adresses IP routables
Dépannage
Qu'est-ce qui déclenche une réinitialisation ?
Si vous effacez tous les champs d’adresse d’homologue de la page de mise en grappe et enregistrez la configuration, Expressway effectue par défaut une réinitialisation d’usine lui-même la prochaine fois que vous faites un redémarrage. Cela signifie que toute la configuration est supprimée, à l'exception de la configuration réseau de base pour l'interface LAN1 (Local Area Network 1), qui inclut toute la configuration effectuée après avoir effacé les champs et le redémarrage suivant.
Conseil : Si vous devez éviter la réinitialisation d'usine, restaurez les champs d'adresse d'homologue de cluster. Remplacez les adresses homologues d'origine dans le même ordre, puis enregistrez la configuration pour effacer la bannière.
La réinitialisation d'usine est automatiquement déclenchée au redémarrage de l'homologue, afin de supprimer les données sensibles et la configuration du cluster. La réinitialisation efface toute la configuration, à l'exception des informations de base suivantes sur le réseau :
Remarque : Si vous utilisez l'option dual NIC, sachez que toute configuration LAN2 est complètement supprimée par la réinitialisation.
- Adresses IP · Admin, comptes racine et mots de passe
- Clés SSH
- Touches d'option
- Accès HTTPS (Hypertext Transfer Protocol Secure) activé
- Accès SSH activé
Remarque : À partir de la version X12.6, la réinitialisation d'usine supprime le certificat du serveur, la clé privée associée et les paramètres du magasin d'approbations de CA de l'homologue. Dans les versions antérieures du logiciel Expressway, ces paramètres sont conservés.
Échec de réinitialisation industrielle
La réinitialisation en usine peut échouer, cela peut se produire si l’Expressway est une nouvelle installation d’Open Virtualization Appliance (OVA) et n’a pas été mis à niveau.
Afin de résoudre ce problème, veuillez suivre l'une des options suivantes :
- Mettez à niveau tous les noeuds vers la même version logicielle avec le fichier tar.gz. À la fin du processus de mise à niveau, redémarrez le serveur, ce qui déclenche la réinitialisation en usine.
- Téléchargez le fichier tar.gz directement dans le dossier de réinitialisation d'usine avec WinSCP (/mnt/harddisk/factory-reset/). Redémarrez ensuite pour lancer la réinitialisation d'usine ou lancez la réinitialisation d'usine à partir de l'ILC.
Remarque : Veillez à effectuer les sauvegardes appropriées avant une mise à niveau, une modification de certificat ou en cas d'avertissement de réinitialisation en usine.
Séquence de redémarrage
Si un redémarrage du cluster ou d'un homologue est nécessaire, procédez comme suit :
- Redémarrez l'homologue principal et attendez qu'il soit accessible via l'interface Web.
- Validez l'état de réplication de cluster sur le principal et l'état de tous les homologues. Patientez quelques minutes, actualisez occasionnellement les interfaces Web de l'homologue.
- Redémarrez les autres homologues, si nécessaire, un par un. À chaque fois, patientez quelques minutes après son accès et validez son état de réplication.
Remarque : Vous devrez peut-être attendre environ 5 minutes après avoir effectué des modifications de cluster avant que les homologues Expressway signalent un état réussi.
Alarmes et avertissements
Les alarmes des erreurs de cluster sont affichées au format suivant : Erreur de réplication de cluster : (détails) la synchronisation manuelle de la configuration est requise, en voici quelques exemples :
- Erreur de réplication de cluster : une synchronisation manuelle de la configuration est requise.
- Erreur de réplication de cluster : impossible de trouver le fichier de configuration principal ou homologue de ce subordonné, une synchronisation manuelle de la configuration est requise.
- Erreur de réplication de cluster : L'ID principal de la configuration est incohérent. Une synchronisation manuelle de la configuration est requise.
- Erreur de réplication de cluster : Si la configuration de cet homologue est en conflit avec la configuration du principal, une synchronisation manuelle de la configuration est requise.
Si un Expressway subordonné signale l’alarme mentionnée, suivez la procédure suivante :
- Connectez-vous en tant qu'administrateur sur une interface SSH ou CLI.
- Exécutez la commande suivante : xcommand ForceConfigUpdate
Remarque : Veillez à effectuer les sauvegardes appropriées avant une mise à niveau, une modification de certificat ou en cas d'avertissement de réinitialisation en usine.
- Cette commande supprime la configuration Expressway subordonnée et la force à mettre à jour sa configuration à partir de l’Expressway primaire.
Si le problème persiste, il peut être lié à la clé de chiffrement par homologue de cluster. Se produit généralement lorsque les homologues sont mis à niveau dans le mauvais ordre, les homologues subordonnés ne sont pas synchronisés avec le principal. Par conséquent, si xcommand forceconfigupdate ne fonctionne pas, suivez la procédure suivante :
- Connectez-vous à l'homologue principal et vérifiez qu'il est en bon état.
- Assurez-vous que la configuration du cluster indique que cet homologue est le principal.
- Mettez à niveau le principal à nouveau, utilisez le même package que celui que vous avez utilisé à l'origine pour la mise à niveau.
L'alarme de réplication disparaît après la mise à niveau et le redémarrage de l'homologue principal. Cela se produit normalement dans les dix minutes qui suivent le redémarrage, mais peut se produire jusqu'à vingt minutes après le redémarrage.
Alarmes courantes
Configuration de clustering non valide : Le mode H.323 doit être activé. La mise en grappe utilise les communications H.323 entre homologues.
Pour que cette alarme soit effacée, assurez-vous que le mode H.323 est activé, accédez à Configuration > Protocols > H.323.
Échec de la base de données Expressway : Veuillez contacter votre représentant du service d'assistance Cisco.
Afin de dépanner ce type d'alarme, suivez la procédure suivante :
- Prenez un instantané du système et fournissez-le à votre représentant du support technique.
- Supprimez l’Expressway du cluster.
- Restaurez la base de données de cet Expressway à partir d’une sauvegarde effectuée sur cet Expressway précédemment.
- Ajoutez de nouveau l’Expressway au cluster.
Une deuxième méthode est possible si la base de données n'est pas restaurée :
- Prenez un instantané du système et fournissez-le au centre d'assistance technique (TAC).
- Supprimez l’Expressway du cluster.
- Connectez-vous en tant qu'utilisateur racine et exécutez la commande suivante clusterdb_destroy_and_purge_data.sh.
- Restaurez la base de données de cet Expressway à partir d’une sauvegarde effectuée sur cet Expressway précédemment.
- Ajoutez de nouveau l’Expressway au cluster.
Remarque : Veillez à effectuer les sauvegardes appropriées avant une mise à niveau, une modification de certificat ou en cas d'avertissement de réinitialisation en usine.
Mise en garde : clusterdb_destroy_and_purge_data.sh est aussi dangereux qu'il y paraît — utilisez cette option en dernier recours.
Problèmes liés aux clés système
Remarque : Les informations suivantes s'appliquent à partir de la version X14.
Impossible de mettre à jour les alarmes de fichier clé sont déclenchées sur Expressways sur un scénario de noeud unique.
Suivez la procédure suivante pour dépanner ce type d'alarme :
- Connectez-vous en tant qu'administrateur via l'interface de ligne de commande (disponible par défaut sur SSH et via le port série sur les versions matérielles).
- Exécutez la commande suivante : xCommand ForceSystemKeyUpdate.
Impossible de mettre à jour les alarmes de fichier clé sont déclenchées sur Expressways dans un scénario de cluster.
Suivez la procédure suivante pour dépanner ce type d'alarme :
- Connectez-vous au noeud en tant qu'administrateur via l'interface de ligne de commande (disponible par défaut sur SSH et via le port série sur les versions matérielles) lorsque cette alarme n'est pas déclenchée.
- Exécutez la commande suivante : xCommand ForceSystemKeyUpdate.
Détails des journaux
Comme tout autre journal sur Expressway, vous pouvez activer les journaux de diagnostics, avec TCP Dumps.
Dans un état normal, la synchronisation de base de données sur le noeud maître est affichée dans les journaux comme le résultat suivant :
2020-07-21T15:16:50.321-05:00 expc01 replication: UTCTime="2020-07-21 20:16:50,321" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(270)" Detail="Starting synchronisation"
2020-07-21T15:16:50.330-05:00 expc01 replication: UTCTime="2020-07-21 20:16:50,330" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationutils(750)" AlternateIPAddresses="[u'(10.15.13.15 expc01)', u'(10.15.13.16 expc02)']" ConfigurationMasterIndex="0" LocalPeerIndex="0"
2020-07-21T15:16:50.433-05:00 expc01 replication: UTCTime="2020-07-21 20:16:50,433" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(257)" Detail="This peer is the cluster master, local configuration has already been replicated to the other peers"
2020-07-21T15:16:50.437-05:00 expc01 replication: UTCTime="2020-07-21 20:16:50,437" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(336)" Detail="Synchronisation completed successfully"Du point de vue du noeud homologue, il s'affiche comme la sortie suivante :
2020-07-21T15:16:46.900-05:00 expc02 replication: UTCTime="2020-07-21 20:16:46,899" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(270)" Detail="Starting synchronisation"
2020-07-21T15:16:46.908-05:00 expc02 replication: UTCTime="2020-07-21 20:16:46,908" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationutils(750)" AlternateIPAddresses="[u'(10.15.13.15 expc01)', u'(10.15.13.16 expc02)']" ConfigurationMasterIndex="0" LocalPeerIndex="1"
2020-07-21T15:16:46.947-05:00 expc02 replication: UTCTime="2020-07-21 20:16:46,946" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(254)" Detail="This peer is not the cluster master, local configuration is already up to date"
2020-07-21T15:16:46.950-05:00 expc02 replication: UTCTime="2020-07-21 20:16:46,950" Module="developer.replication" Level="INFO" CodeLocation="clusterconfigurationsynchroniser(336)" Detail="Synchronisation completed successfully"Une déconnexion d'homologue est affichée dans la sortie suivante :
2020-08-12T14:57:43.353-05:00 expc01 UTCTime="2020-08-12 19:57:43,353" Module="developer.clusterdb.cdb" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.159.0>" Detail="Processed mnesia_down event from accessible node" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,353" Module="developer.clusterdb.cdb" Level="ERROR" Node="clusterdb@expc01.apolo.local" PID="<0.159.0>" Detail="Inconsistent Database" Context="from mnesia system - mnesia down" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,354" Module="developer.clusterdb.cdb" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.159.0>" Detail="Connecting database on mnesia running_partitioned_network event" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,354" Module="developer.clusterdb.cdb" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.14215.425>" Detail="Ready to perform node connection transaction" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,354" Module="developer.clusterdb.cdb" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.14215.425>" Detail="Running node connection transaction" Node="clusterdb@expc02.apolo.local"
2020-08-12T14:57:43.354-05:00 expc01 UTCTime="2020-08-12 19:57:43,354" Module="developer.clusterdb.synchronise" Level="WARN" Node="clusterdb@expc01.apolo.local" PID="<0.14215.425>" Detail="Failed connecting to node" Node="clusterdb@expc02.apolo.local" Reason="{ badrpc, { EXIT, { aborted, { noproc, { gen_server, call, [ kernel_safe_sup, { start_child, { dets_sup, { dets_sup, start_link, }, permanent, 1000, supervisor, [ dets_sup ] } }, infinity ] } } } } }"
2020-08-12T14:57:43.524-05:00 expc01 alarm: Level="WARN" Event="Alarm Raised" Id="20006" UUID="0f96695e-d954-4f6f-85c1-2ef1eae6f764" Severity="warning" Detail="Cluster database communication failure: The database is unable to replicate with one or more of the cluster peers" UTCTime="2020-08-12 19:57:43,524"
2020-08-12T14:57:43.771-05:00 expc01 alarm: Level="WARN" Event="Alarm Raised" Id="20004" UUID="3bca6888-f622-11df-93be-07cc953d7b99" Severity="warning" Detail="Cluster communication failure: The system is unable to communicate with one or more of the cluster peers" UTCTime="2020-08-12 19:57:43,771"
2020-08-12T14:57:53.872-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:53,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS SCI SeqNum=52319 Retransmit=True"
2020-08-12T14:57:54.872-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:54,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS LRQ SeqNum=52320 Retransmit=True"
2020-08-12T14:57:56.872-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:56,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS LRQ SeqNum=52320 Retransmit=True"
2020-08-12T14:57:57.871-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:57,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS SCI SeqNum=52319 Retransmit=True"
2020-08-12T14:57:58.871-05:00 expc01 tvcs: Event="External Server Communications Failure" Reason="gatekeeper timed out" Service="NeighbourGatekeeper" Detail="name:10.15.13.16:1719" Level="1" UTCTime="2020-08-12 19:57:58,871"
2020-08-12T14:57:58.871-05:00 expc01 tvcs: UTCTime="2020-08-12 19:57:58,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS LRQ SeqNum=52320 Timeout=True"
2020-08-12T14:57:59.601-05:00 expc01 UTCTime="2020-08-12 19:57:59,601" Module="developer.clusterdb.peernameresolver" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.145.0>" Detail="Triggering forced peer update of peers which failed DNS and queueing next run" Queue-Time-ms="300000"
2020-08-12T14:58:01.871-05:00 expc01 tvcs: UTCTime="2020-08-12 19:58:01,871" Module="network.h323" Level="INFO": Action="Sent" Dst-ip="10.15.13.16" Dst-port="1719" Detail="Sending RAS SCI SeqNum=52319 Timeout=True"
Le passage à l'application TLS sur le noeud maître est montré dans le résultat suivant :
2020-08-12T15:13:24.970-05:00 expc01 UTCTime="2020-08-12 20:13:24,969" Module="developer.cdbtable.cdb.clusterConfiguration" Level="DEBUG" Node="clusterdb@expc01.apolo.local" PID="<0.345.0>" Detail="Inserting into table" TableName="clusterConfiguration"
2020-08-12T15:13:24.976-05:00 expc01 UTCTime="2020-08-12 20:13:24,975" Event="System Configuration Changed" Node="clusterdb@expc01.apolo.local" PID="<0.345.0>" Detail="xconfiguration clusterConfiguration tls_verify - changed from: Permissive to: Enforcing"
2020-08-12T15:13:24.976-05:00 expc01 httpd[15060]: web: Event="System Configuration Changed" Detail="configuration/cluster/tls_verify - changed from: 'Permissive' to: 'Enforcing'" Src-ip="10.15.13.30" Src-port="53155" User="admin" Level="1" UTCTime="2020-08-12 20:13:24"
2020-08-12T15:13:24.979-05:00 expc01 management: UTCTime="2020-08-12 20:13:24,978" Module="developer.management.databasemanager" Level="INFO" CodeLocation="databasemanager(312)" Detail="Cluster configuration change detected"
2020-08-12T15:13:24.980-05:00 expc01 UTCTime="2020-08-12 20:13:24,980" Module="developer.cdbtable.cdb.clusterConfiguration" Level="DEBUG" Node="clusterdb@expc01.apolo.local" PID="<0.345.0>" Detail="Inserting into table" TableName="clusterConfiguration"
2020-08-12T15:13:24.986-05:00 expc01 management: UTCTime="2020-08-12 20:13:24,986" Module="developer.management.databasemanager" Level="INFO" CodeLocation="databasemanager(405)" Detail="TLS Verify change status" Startup="False" New="True"
2020-08-12T15:13:25.022-05:00 expc01 UTCTime="2020-08-12 20:13:25,022" Event="System Configuration Changed" Node="clusterdb@expc01.apolo.local" PID="<0.557.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.022-05:00 expc01 UTCTime="2020-08-12 20:13:25,022" Module="developer.clusterdb.peernameresolver" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.145.0>" Detail="Notifying databasemanager (Management Framework)"
2020-08-12T15:13:25.022-05:00 expc01 UTCTime="2020-08-12 20:13:25,022" Module="developer.clusterdb.alternatesmanager" Level="INFO" Node="clusterdb@expc01.apolo.local" PID="<0.142.0>" Detail="alternate peer changed info recieved"
2020-08-12T15:13:25.031-05:00 expc01 UTCTime="2020-08-12 20:13:25,031" Event="System Configuration Changed" Node="clusterdb@expc01.apolo.local" PID="<0.557.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.192-05:00 expc01 management: UTCTime="2020-08-12 20:13:25,192" Module="developer.diagnostics.alarmmanager" Level="INFO" CodeLocation="alarmmanager(173)" Detail="Raising alarm" UUID="e2b8e3d1-b731-4d7d-b606-4682a8f0c2e6" Parameters="null"
2020-08-12T15:13:25.195-05:00 expc01 management: Level="WARN" Event="Alarm Raised" Id="20007" UUID="e2b8e3d1-b731-4d7d-b606-4682a8f0c2e6" Severity="warning" Detail="Restart required: Cluster configuration has been changed, however a restart is required for this to take effect" UTCTime="2020-08-12 20:13:25,194"
Du point de vue du noeud homologue, il est affiché dans la sortie suivante :
2020-08-12T15:13:24.976-05:00 expc02 UTCTime="2020-08-12 20:13:24,976" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.390.0>" Detail="xconfiguration clusterConfiguration tls_verify - changed from: Permissive to: Enforcing"
2020-08-12T15:13:24.979-05:00 expc02 management: UTCTime="2020-08-12 20:13:24,978" Module="developer.management.databasemanager" Level="INFO" CodeLocation="databasemanager(312)" Detail="Cluster configuration change detected"
2020-08-12T15:13:24.982-05:00 expc02 management: UTCTime="2020-08-12 20:13:24,982" Module="developer.management.databasemanager" Level="INFO" CodeLocation="databasemanager(405)" Detail="TLS Verify change status" Startup="False" New="True"
2020-08-12T15:13:25.040-05:00 expc02 UTCTime="2020-08-12 20:13:25,040" Module="developer.clusterdb.peernameresolver" Level="INFO" Node="clusterdb@expc02.apolo.local" PID="<0.136.0>" Detail="Notifying databasemanager (Management Framework)"
2020-08-12T15:13:25.040-05:00 expc02 UTCTime="2020-08-12 20:13:25,040" Module="developer.clusterdb.alternatesmanager" Level="INFO" Node="clusterdb@expc02.apolo.local" PID="<0.143.0>" Detail="alternate peer changed info recieved"
2020-08-12T15:13:25.041-05:00 expc02 UTCTime="2020-08-12 20:13:25,041" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.543.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.042-05:00 expc02 UTCTime="2020-08-12 20:13:25,042" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.543.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.046-05:00 expc02 UTCTime="2020-08-12 20:13:25,046" Module="developer.clusterdb.alternatesmanager" Level="INFO" Node="clusterdb@expc02.apolo.local" PID="<0.143.0>" Detail="alternate peer changed info recieved"
2020-08-12T15:13:25.047-05:00 expc02 UTCTime="2020-08-12 20:13:25,046" Module="developer.clusterdb.peernameresolver" Level="INFO" Node="clusterdb@expc02.apolo.local" PID="<0.136.0>" Detail="Notifying databasemanager (Management Framework)"
2020-08-12T15:13:25.047-05:00 expc02 UTCTime="2020-08-12 20:13:25,047" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.543.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.049-05:00 expc02 UTCTime="2020-08-12 20:13:25,049" Event="System Configuration Changed" Node="clusterdb@expc02.apolo.local" PID="<0.543.0>" Detail="xconfiguration alternatesConfiguration - Changed"
2020-08-12T15:13:25.136-05:00 expc02 management: UTCTime="2020-08-12 20:13:25,136" Module="developer.diagnostics.alarmmanager" Level="INFO" CodeLocation="alarmmanager(173)" Detail="Raising alarm" UUID="e2b8e3d1-b731-4d7d-b606-4682a8f0c2e6" Parameters="null"
2020-08-12T15:13:25.139-05:00 expc02 management: Level="WARN" Event="Alarm Raised" Id="20007" UUID="e2b8e3d1-b731-4d7d-b606-4682a8f0c2e6" Severity="warning" Detail="Restart required: Cluster configuration has been changed, however a restart is required for this to take effect" UTCTime="2020-08-12 20:13:25,139"
Vidéos
Les vidéos suivantes peuvent s'avérer utiles :
Comment créer et ajouter un homologue à un cluster Expressway
Suppression d’un homologue d’un cluster Expressway
Procédure de redémarrage du cluster Expressway
Comment mettre à niveau un clusterGénération de CSR pour MRA/Clustered Expressways
Historique de révision
| Révision | Date de publication | Commentaires |
|---|---|---|
1.0 |
02-Jul-2021
|
Première publication |
Contribution d’experts de Cisco
- Jefferson Madriz
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)