Récupération après panne du superviseur Nexus 7000 2/2E Compact Flash
Options de téléchargement
-
ePub (213.7 KB)
Consulter à l’aide de différentes applications sur iPhone, iPad, Android ou Windows Phone -
Mobi (Kindle) (333.2 KB)
Consulter sur un appareil Kindle ou à l’aide d’une application Kindle sur plusieurs appareils
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Contenu
Introduction
Ce document décrit le problème de défaillance du Nexus 7000 Supervisor 2/2E Compact Flash documenté dans le défaut logiciel CSCus2805, tous les scénarios de défaillance possibles et les étapes de récupération.
Avant toute solution de contournement, il est fortement recommandé d'avoir un accès physique au périphérique si une réinstallation physique est requise. Pour certaines mises à niveau de rechargement, l'accès à la console peut être requis et il est toujours recommandé d'effectuer ces contournements avec l'accès à la console au superviseur pour observer le processus de démarrage.
Si l'une des étapes des solutions de contournement échoue, contactez le TAC Cisco pour connaître les autres options de récupération possibles.
Fond
Chaque N7K supervisor 2/2E est équipé de 2 périphériques flash eUSB en configuration RAID1, un principal et un miroir. Ensemble, ils fournissent des référentiels non volatils pour les images de démarrage, la configuration initiale et les données d'application persistantes.
Ce qui peut se produire sur une période de plusieurs mois ou années de service, c'est que l'un de ces périphériques peut être déconnecté du bus USB, ce qui entraîne l'abandon du périphérique de la configuration par le logiciel RAID. Le périphérique peut toujours fonctionner normalement avec 1/2 périphérique. Cependant, lorsque le second périphérique se retire de la baie, le bootflash est remonté en lecture seule, ce qui signifie que vous ne pouvez pas enregistrer la configuration ou les fichiers dans le bootflash, ou permettre au standby de se synchroniser sur le disque actif dans le cas où il est rechargé.
Il n'y a pas d'impact opérationnel sur les systèmes qui fonctionnent dans un état de double panne flash, cependant un rechargement du superviseur affecté est nécessaire pour récupérer de cet état. En outre, toute modification de la configuration en cours ne sera pas prise en compte lors du démarrage et sera perdue en cas de panne de courant.
Symptômes
Ces symptômes ont été observés :
- Échec du diagnostic Compact Flash
switch# show diagnostic result module 5
Current bootup diagnostic level: complete
Module 5: Supervisor module-2 (Standby)
Test results: (. = Pass, F = Fail, I = Incomplete,
U = Untested, A = Abort, E = Error disabled)
1) ASICRegisterCheck-------------> .
2) USB---------------------------> .
3) NVRAM-------------------------> .
4) RealTimeClock-----------------> .
5) PrimaryBootROM----------------> .
6) SecondaryBootROM--------------> .
7) CompactFlash------------------> F <=====
8) ExternalCompactFlash----------> .
9) PwrMgmtBus--------------------> U
10) SpineControlBus---------------> .
11) SystemMgmtBus-----------------> U
12) StatusBus---------------------> U
13) StandbyFabricLoopback---------> .
14) ManagementPortLoopback--------> .
15) EOBCPortLoopback--------------> .
16) OBFL--------------------------> .
- Impossible d'effectuer un 'démarrage de l'exécution de copie'
dcd02.ptfrnyfs# copy running-config startup-config
[########################################] 100%
Configuration update aborted: request was aborted
- eUSB devient en lecture seule ou ne répond plus
switch %MODULE-4-MOD_WARNING: Module 2 (Serial number: JAF1645AHQT) reported warning
due to The compact flash power test failed in device DEV_UNDEF (device error 0x0)
switch %DEVICE_TEST-2-COMPACT_FLASH_FAIL: Module 1 has failed test CompactFlash 20
times on device Compact Flash due to error The compact flash power test failed
- Échecs ISSU, généralement lors de la tentative de basculement vers le superviseur de secours
Diagnostic
Pour diagnostiquer l'état actuel des cartes Compact Flash, vous devez utiliser ces commandes internes. Notez que la commande ne sera pas analysée et qu'elle doit être tapée complètement :
switch# show system internal raid | grep -A 1 "Informations d'état RAID actuelles"
switch# show system fichier interne /proc/mdstat
S'il y a deux superviseurs dans le châssis, vous devrez vérifier l'état du superviseur de secours et déterminer le scénario de défaillance auquel vous êtes confronté. Pour ce faire, faites précéder la commande du mot clé « slot x », où « x » est le numéro de slot du superviseur de secours. Cela vous permet d'exécuter la commande à distance sur le mode veille.
switch# slot 2 show system internal raid | grep -A 1 "Informations d'état RAID actuelles"
switch# slot 2 show system internal file /proc/mdstat
Ces commandes fournissent un grand nombre de statistiques et d'événements RAID, mais vous ne vous intéressez qu'aux informations RAID actuelles.
Dans la ligne "Données RAID du CMOS", vous voulez voir la valeur hexadécimale après 0xa5. Cela indique le nombre de flashs susceptibles de rencontrer un problème.
Exemple :
switch# show system internal raid | grep -A 1 "Current RAID status info"
Current RAID status info:
RAID data from CMOS = 0xa5 0xc3
À partir de cette sortie, vous voulez regarder le numéro à côté de 0xa5 qui est 0xc3. Vous pouvez ensuite utiliser ces touches pour déterminer si la mémoire Compact Flash principale ou secondaire est défectueuse, ou les deux. Le résultat ci-dessus indique 0xc3, ce qui indique que les clignotements compacts principal et secondaire ont échoué.
| 0xf0 | Aucune défaillance signalée |
| 0xe1 | Échec de la mémoire flash principale |
| 0xd2 | Échec de la mémoire flash alternative (ou miroir) |
| 0xc3 | Échec principal et secondaire |
Dans le résultat « /proc/mdstat », assurez-vous que tous les disques sont affichés en tant que « U », ce qui représente « U »p :
switch# slot 2 show system internal file /proc/mdstat
Personalities : [raid1]
md6 : active raid1 sdc6[0] sdb6[1]
77888 blocks [2/1] [_U]
md5 : active raid1 sdc5[0] sdb5[1]
78400 blocks [2/1] [_U]
md4 : active raid1 sdc4[0] sdb4[1]
39424 blocks [2/1] [_U]
md3 : active raid1 sdc3[0] sdb3[1]
1802240 blocks [2/1] [_U]
Dans ce scénario, vous voyez que la mémoire Compact Flash principale n'est pas active [_U]. Une sortie saine affichera tous les blocs en tant que [UU].
Note: Les deux sorties doivent indiquer que le superviseur est sain (0xf0 et [UU]) pour le diagnostiquer. Ainsi, si vous voyez une sortie 0xf0 dans les données CMOS, mais que vous voyez un [_U] dans /proc/mdstat, la boîte n'est pas saine.
Scénarios
Pour déterminer le scénario auquel vous êtes confronté, vous devez utiliser les commandes ci-dessus dans la section "Diagnostic" pour établir une corrélation avec une lettre de scénario ci-dessous. À l'aide des colonnes, faites correspondre le nombre de clignotements compacts ayant échoué sur chaque superviseur.
Par exemple, si vous voyez que le code est 0xe1 sur le superviseur actif et 0xd2 sur le serveur de secours, il s'agit de "1 Fail" sur le serveur actif et de "1 Fail" sur le serveur de secours, ce qui correspond à la lettre de scénario "D".
Superviseur unique :
| Lettre Scénario | Superviseur actif | Code de superviseur actif |
| A | 1 Échec | 0xe1 ou 0xd2 |
| B | 2 échecs | 0xc3 |
Deux superviseurs :
| Lettre Scénario | Superviseur actif | supervisor de secours | Code de superviseur actif | Code superviseur de secours |
| C | 0 Échec | 1 Échec | 0xf0 | 0xe1 ou 0xd2 |
| D | 1 Échec | 0 Échec | 0xe1 ou 0xd2 | 0xf0 |
| E | 1 Échec | 1 Échec | 0xe1 ou 0xd2 | 0xe1 ou 0xd2 |
| F | 2 échecs | 0 Échec | 0xc3 | 0xf0 |
| G | 0 Échec | 2 échecs | 0xf0 | 0xc3 |
| H | 2 échecs | 1 Échec | 0xc3 | 0xe1 ou 0xd2 |
| I | 1 Échec | 2 Échec | 0xe1 ou 0xd2 | 0xc3 |
| J | 2 échecs | 2 échecs | 0xc3 | 0xc3 |
Procédure de récupération pour chaque scénario
Scénarios de défaillance de superviseur unique
Scénario A (1 échec sur l'actif)
Scénario de récupération :
1 Échec sur l'actif
Étapes vers la résolution :
1. Charger l'outil de récupération flash pour réparer bootflash. Vous pouvez télécharger l'outil de récupération à partir de CCO sous Utilitaires pour la plate-forme N7000 ou utiliser le lien ci-dessous :
Il est enveloppé dans un fichier compressé tar gz, décompressez-le pour trouver l'outil de récupération .gbin et un fichier readme .pdf. Consultez le fichier readme et chargez l'outil .gbin sur le bootflash du N7K. Bien que cette récupération soit conçue pour ne pas avoir d'impact et puisse être effectuée en direct, le TAC recommande de l'effectuer dans une fenêtre de maintenance en cas de problèmes inattendus. Une fois le fichier sur bootflash, vous pouvez exécuter l'outil de récupération avec :
switch# show system internal file /proc/mdstat \
Personalities : [raid1]
md6 : active raid1 sdd6[2] sdc6[0]
77888 blocks [2/1] [U_] <-- "U_" represents the broken state
resync=DELAYED
md5 : active raid1 sdd5[2] sdc5[0]
78400 blocks [2/1] [U_]
resync=DELAYED
md4 : active raid1 sdd4[2] sdc4[0]
39424 blocks [2/1] [U_]
resync=DELAYED
md3 : active raid1 sdd3[2] sdc3[0]
1802240 blocks [2/1] [U_]
[=>...................] recovery = 8.3% (151360/1802240) finish=2.1min s peed=12613K/sec
unused devices: <none>
switch# show system internal file /proc/mdstat Personalities : [raid1]
md6 :active raid1 sdd6[1] sdc6[0]
77888 blocks [2/2] [UU] <-- "UU" represents the fixed state
md5 :active raid1 sdd5[1] sdc5[0]
78400 blocks [2/2] [UU]
md4 :active raid1 sdd4[1] sdc4[0]
39424 blocks [2/2] [UU]
md3 :active raid1 sdd3[1] sdc3[0]
1802240 blocks [2/2] [UU]
unused devices: <none>
Scénario B (2 échecs sur l'actif)
Scénario de récupération :
2 échecs sur l'actif
Étapes vers la résolution :
Note: Il est souvent observé dans les cas de double panne de mémoire flash, un rechargement logiciel peut ne pas récupérer entièrement le RAID et peut nécessiter l'exécution de l'outil de récupération ou des rechargements ultérieurs pour récupérer. Dans presque tous les cas, il a été résolu par une réinstallation physique du module de supervision. Par conséquent, si l'accès physique au périphérique est possible, après avoir sauvegardé la configuration en externe, vous pouvez tenter une récupération rapide qui a le plus de chances de réussir en réinstallant physiquement le superviseur lorsqu'il est prêt à recharger le périphérique. Cette opération va couper complètement l'alimentation du superviseur et devrait permettre la récupération des deux disques dans le RAID. Passez à l'étape 3 si la récupération de la réinstallation physique n'est que partielle, ou à l'étape 4 si elle échoue complètement car le système ne démarre pas complètement.
Scénarios de défaillance du double superviseur
Scénario C (0 échec en mode actif, 1 échec en mode veille)
Scénario d'échec :
0 Échec sur l'actif
1 Échec en veille
Étapes vers la résolution :
Dans le cas d'une configuration à deux superviseurs, sans défaillance de la mémoire flash sur le système actif et avec une seule défaillance sur le système de secours, une récupération sans impact peut être effectuée.
1. Comme l'outil actif n'a pas de défaillance et que l'outil de secours n'a qu'une seule défaillance, l'outil de récupération rapide peut être chargé sur l'outil actif et exécuté. Une fois l'outil exécuté, il se copie automatiquement dans la baie de secours et tente de resynchroniser la baie. L'outil de récupération peut être téléchargé ici :
Une fois que vous avez téléchargé l'outil, décompressé et téléchargé dans le bootflash de la boîte, vous devrez exécuter la commande suivante pour commencer la récupération :
# load bootflash:n7000-s2-flash-recovery-tool.10.0.2.gbin
L'outil démarre et détecte les disques déconnectés et tente de les resynchroniser avec la matrice RAID.
Vous pouvez vérifier l'état de récupération avec :
# show system internal file /proc/mdstat
Vérifiez que la récupération est en cours. Plusieurs minutes peuvent être nécessaires pour réparer tous les disques à l'état [UU]. Voici un exemple de récupération en cours d'exécution :
switch# show system internal file /proc/mdstat \
Personalities : [raid1]
md6 : active raid1 sdd6[2] sdc6[0]
77888 blocks [2/1] [U_] <-- "U_" represents the broken state
resync=DELAYED
md5 : active raid1 sdd5[2] sdc5[0]
78400 blocks [2/1] [U_]
resync=DELAYED
md4 : active raid1 sdd4[2] sdc4[0]
39424 blocks [2/1] [U_]
resync=DELAYED
md3 : active raid1 sdd3[2] sdc3[0]
1802240 blocks [2/1] [U_]
[=>...................] recovery = 8.3% (151360/1802240) finish=2.1min s peed=12613K/sec
unused devices: <none>
Une fois la récupération terminée, elle doit se présenter comme suit :
switch# show system internal file /proc/mdstat Personalities : [raid1]
md6 :active raid1 sdd6[1] sdc6[0]
77888 blocks [2/2] [UU] <-- "UU" represents the correct state
md5 :active raid1 sdd5[1] sdc5[0]
78400 blocks [2/2] [UU]
md4 :active raid1 sdd4[1] sdc4[0]
39424 blocks [2/2] [UU]
md3 :active raid1 sdd3[1] sdc3[0]
1802240 blocks [2/2] [UU]
unused devices: <none>
Une fois que tous les disques sont dans [UU], la matrice RAID est entièrement sauvegardée avec les deux disques synchronisés.
2. Si l'outil de récupération rapide ne fonctionne pas, puisque l'actif a les deux disques en service, le serveur de secours doit pouvoir se synchroniser avec succès avec l'actif lors du rechargement.
Par conséquent, dans une fenêtre planifiée, exécutez un « module hors service x » pour le superviseur de secours, il est recommandé d'avoir un accès console au superviseur de secours pour observer le processus de démarrage en cas de problèmes inattendus. Une fois le superviseur hors tension, attendez quelques secondes, puis exécutez la commande « no poweroff module x » pour le mode veille. Patientez jusqu'à ce que le mode veille démarre complètement et passe à l'état « ha-standby ».
Une fois la mise en veille rétablie, vérifiez le RAID avec les commandes « slot x show system internal raid » et « slot x show system internal file /proc/mdstat ».
Si les deux disques ne sont pas entièrement sauvegardés après le rechargement, exécutez à nouveau l'outil de récupération.
3. Si l'outil de rechargement et de récupération échoue, il est recommandé de réinstaller physiquement le module en veille dans la fenêtre pour essayer d'effacer la condition. Si la réinstallation physique échoue, essayez d'exécuter une commande « init system » à partir du mode de démarrage du commutateur en suivant les étapes de récupération de mot de passe pour passer en mode « init system » pendant le démarrage. En cas d'échec, contactez le TAC pour tenter une récupération manuelle.
Scénario D (1 échec en mode actif, 0 échec en mode veille)
Scénario de récupération :
1 Échec sur l'actif
0 Échec en veille
Étapes vers la résolution :
Dans le cas d'une configuration à double superviseur, avec 1 défaillance flash sur le système actif et aucune défaillance sur le système de secours, une récupération sans impact peut être effectuée à l'aide de l'outil de récupération rapide.
1. Comme la mise en veille n'a pas de défaillance et que l'actif n'a qu'une seule défaillance, l'outil de récupération rapide peut être chargé sur l'actif et exécuté. Une fois l'outil exécuté, il se copie automatiquement dans la baie de secours et tente de resynchroniser la baie. L'outil de récupération peut être téléchargé ici :
Une fois que vous avez téléchargé l'outil, décompressé et téléchargé dans le bootflash de l'actif, vous devrez exécuter la commande suivante pour commencer la récupération :
# load bootflash:n7000-s2-flash-recovery-tool.10.0.2.gbin
L'outil démarre et détecte les disques déconnectés et tente de les resynchroniser avec la matrice RAID.
Vous pouvez vérifier l'état de récupération avec :
# show system internal file /proc/mdstat
Vérifiez que la récupération est en cours. Plusieurs minutes peuvent être nécessaires pour réparer tous les disques à l'état [UU]. Voici un exemple de récupération en cours d'exécution :
switch# show system internal file /proc/mdstat \
Personalities : [raid1]
md6 : active raid1 sdd6[2] sdc6[0]
77888 blocks [2/1] [U_] <-- "U_" represents the broken state
resync=DELAYED
md5 : active raid1 sdd5[2] sdc5[0]
78400 blocks [2/1] [U_]
resync=DELAYED
md4 : active raid1 sdd4[2] sdc4[0]
39424 blocks [2/1] [U_]
resync=DELAYED
md3 : active raid1 sdd3[2] sdc3[0]
1802240 blocks [2/1] [U_]
[=>...................] recovery = 8.3% (151360/1802240) finish=2.1min s peed=12613K/sec
unused devices: <none>
Une fois la récupération terminée, elle doit se présenter comme suit :
switch# show system internal file /proc/mdstat Personalities : [raid1]
md6 :active raid1 sdd6[1] sdc6[0]
77888 blocks [2/2] [UU] <-- "UU" represents the correct state
md5 :active raid1 sdd5[1] sdc5[0]
78400 blocks [2/2] [UU]
md4 :active raid1 sdd4[1] sdc4[0]
39424 blocks [2/2] [UU]
md3 :active raid1 sdd3[1] sdc3[0]
1802240 blocks [2/2] [UU]
unused devices: <none>
Une fois que tous les disques sont dans [UU], la matrice RAID est entièrement sauvegardée avec les deux disques synchronisés.
2. Si l'outil de récupération rapide échoue, l'étape suivante consiste à effectuer un « basculement système » pour basculer les modules de supervision dans une fenêtre de maintenance.
Par conséquent, dans une fenêtre planifiée, effectuez un « basculement système », il est recommandé d'avoir un accès console pour observer le processus de démarrage en cas de problèmes inattendus. Patientez jusqu'à ce que le mode veille démarre complètement et passe à l'état « ha-standby ».
Une fois la mise en veille rétablie, vérifiez le RAID avec les commandes « slot x show system internal raid » et « slot x show system internal file /proc/mdstat ».
Si les deux disques ne sont pas entièrement sauvegardés après le rechargement, exécutez à nouveau l'outil de récupération.
3. Si l'outil de rechargement et de récupération échoue, il est recommandé de réinstaller physiquement le module en veille dans la fenêtre pour essayer d'effacer la condition. Si la réinstallation physique échoue, essayez d'exécuter une commande « init system » à partir du mode de démarrage du commutateur en suivant les étapes de récupération de mot de passe pour passer en mode « init system » pendant le démarrage. En cas d'échec, contactez le TAC pour tenter une récupération manuelle.
Scénario E (1 échec en mode actif, 1 échec en mode veille)
Scénario de récupération :
1 Échec sur l'actif
1 Échec en veille
Étapes vers la résolution :
En cas de défaillance d'une seule mémoire flash sur les systèmes actif et de secours, une solution de contournement sans impact peut encore être mise en oeuvre.
1. Aucun superviseur n'étant en lecture seule, la première étape consiste à essayer d'utiliser l'outil de récupération rapide.
L'outil de récupération peut être téléchargé ici :
Une fois que vous avez téléchargé l'outil, décompressé et téléchargé dans le bootflash de l'actif, vous devrez exécuter la commande suivante pour commencer la récupération :
# load bootflash:n7000-s2-flash-recovery-tool.10.0.2.gbin
Il détecte automatiquement les disques déconnectés sur le disque actif et tente de les réparer, se copie automatiquement en veille et détecte et corrige les pannes.
Vous pouvez vérifier l'état de récupération avec :
# show system internal file /proc/mdstat
Vérifiez que la récupération est en cours. Plusieurs minutes peuvent être nécessaires pour réparer tous les disques à l'état [UU]. Voici un exemple de récupération en cours d'exécution :
switch# show system internal file /proc/mdstat \
Personalities : [raid1]
md6 : active raid1 sdd6[2] sdc6[0]
77888 blocks [2/1] [U_] <-- "U_" represents the broken state
resync=DELAYED
md5 : active raid1 sdd5[2] sdc5[0]
78400 blocks [2/1] [U_]
resync=DELAYED
md4 : active raid1 sdd4[2] sdc4[0]
39424 blocks [2/1] [U_]
resync=DELAYED
md3 : active raid1 sdd3[2] sdc3[0]
1802240 blocks [2/1] [U_]
[=>...................] recovery = 8.3% (151360/1802240) finish=2.1min s peed=12613K/sec
unused devices: <none>
Une fois la récupération terminée, elle doit se présenter comme suit :
switch# show system internal file /proc/mdstat Personalities : [raid1]
md6 :active raid1 sdd6[1] sdc6[0]
77888 blocks [2/2] [UU] <-- "UU" represents the correct state
md5 :active raid1 sdd5[1] sdc5[0]
78400 blocks [2/2] [UU]
md4 :active raid1 sdd4[1] sdc4[0]
39424 blocks [2/2] [UU]
md3 :active raid1 sdd3[1] sdc3[0]
1802240 blocks [2/2] [UU]
unused devices: <none>
Une fois que tous les disques sont dans [UU], la matrice RAID est entièrement sauvegardée avec les deux disques synchronisés.
Si les deux superviseurs reprennent l'état [UU], la récupération est terminée. Si la récupération est partielle ou a échoué, passez à l'étape 2.
2. Si l'outil de récupération échoue, identifiez l'état actuel du RAID sur les modules. S'il y a toujours une seule panne de mémoire flash sur les deux, essayez un « basculement système » qui rechargera l'actif actuel et forcera le standby au rôle actif.
Après le rechargement de l'actif précédent dans "ha-standby", vérifiez son état RAID comme il devrait être récupéré pendant le rechargement.
Si le superviseur parvient à récupérer après le basculement, vous pouvez essayer d'exécuter à nouveau l'outil de récupération rapide pour tenter de réparer la défaillance d'un seul disque sur le superviseur actif actuel, ou un autre « basculement système » pour recharger l'actif actuel et forcer le veille actif et actuel précédent qui a été réparé à revenir au rôle actif. Vérifiez que les deux disques du superviseur rechargé ont été réparés à nouveau, réexécutez l'outil de récupération si nécessaire.
3. Si, au cours de ce processus, le basculement ne résout pas le problème RAID, exécutez un « module hors service x » pour le module de secours, puis « no poweroff module x » pour retirer complètement le module et le remettre sous tension.
En cas d'échec de la mise hors service, essayez de réinstaller physiquement le périphérique de secours.
Si, après l'exécution de l'outil de récupération, un superviseur récupère son RAID et que l'autre présente toujours une défaillance, forcez le superviseur avec la défaillance unique à se mettre en veille avec un « basculement système » si nécessaire. Si le superviseur présentant une défaillance unique est
déjà en veille, utilisez un « module x hors service » pour la mise en veille et un « module x sans mise hors tension » pour retirer complètement le module et le remettre sous tension. S'il n'est toujours pas en cours de récupération, essayez de réinstaller physiquement le module. Si une réinstallation ne résout pas le problème,
accédez à l'invite de démarrage du commutateur à l'aide de la procédure de récupération de mot de passe et exécutez une commande « init system » pour réinitialiser le bootflash. Si cela échoue toujours, demandez au TAC de tenter une récupération manuelle.
Note: Si, à un moment donné, le module de secours est bloqué dans un état « mis sous tension » et non « ha-standby », s'il n'est pas en mesure de le faire entièrement avec les étapes ci-dessus, un rechargement du châssis sera nécessaire.
Scénario F (2 échecs sur le mode actif, 0 échec sur le mode veille)
Scénario de récupération :
2 échecs sur l'actif
0 Échec en veille
Étapes vers la résolution :
Avec 2 échecs sur le superviseur actif et 0 sur le superviseur de secours, une restauration sans impact est possible, selon la quantité de configuration en cours ajoutée depuis que le superviseur de secours n'a pas pu synchroniser sa configuration en cours avec le superviseur actif.
La procédure de récupération consiste à copier la configuration en cours du superviseur actif, à basculer vers le superviseur de secours sain, à copier la configuration en cours manquante vers le nouveau superviseur actif, à mettre manuellement en ligne le superviseur actif précédent, puis à exécuter l'outil de récupération.
2. Une fois que la configuration en cours a été copiée à partir du superviseur actif, il est conseillé de la comparer à la configuration de démarrage pour voir ce qui a changé depuis le dernier enregistrement. Ceci peut être vu avec "show startup-configuration". Les différences dépendront bien sûr complètement de l'environnement, mais il est bon de savoir ce qui peut manquer lorsque la veille se met en ligne en tant qu'actif. Il est également conseillé de copier les différences déjà copiées dans un bloc-notes afin de pouvoir les ajouter rapidement au nouveau superviseur actif après le basculement.
3. Une fois les différences évaluées, vous devrez effectuer un basculement de superviseur. Le TAC recommande d'effectuer cette opération pendant une fenêtre de maintenance, car des problèmes imprévus peuvent se produire. La commande permettant d'effectuer le basculement vers le mode de secours est « system switchover ».
4. La commutation doit se produire très rapidement et le nouveau mode veille commence à redémarrer. Pendant ce temps, vous souhaiterez ajouter à nouveau toute configuration manquante à la nouvelle configuration active. Pour ce faire, il suffit de copier la configuration à partir du serveur TFTP (ou de l’emplacement où elle a été précédemment enregistrée) ou d’ajouter manuellement la configuration dans l’interface de ligne de commande. Dans la plupart des cas, les configurations manquantes sont très courtes et l'option CLI sera la plus réalisable.
5. Au bout d'un certain temps, le nouveau superviseur de secours peut revenir en ligne dans un état « ha-standby », mais ce qui se produit normalement, c'est qu'il est bloqué dans un état « powered-up ». L'état peut être visualisé en utilisant la commande "show module" et en se référant à la colonne "Status" à côté du module.
Si le nouveau mode veille est mis sous tension, vous devrez le remettre manuellement en ligne. Pour ce faire, exécutez les commandes suivantes, où « x » est le module de secours bloqué dans un état « mis sous tension » :
(config)# out-of-service module x
(config)# no poweroff module x
6. Une fois que la veille est de nouveau en ligne dans un état « ha-standby », vous devrez alors exécuter l'outil de récupération pour vous assurer que la récupération est terminée. L'outil peut être téléchargé à l'adresse suivante :
Une fois que vous avez téléchargé l'outil, décompressé et téléchargé dans le bootflash de la boîte, vous devrez exécuter la commande suivante pour commencer la récupération :
# load bootflash:n7000-s2-flash-recovery-tool.10.0.2.gbin
L'outil démarre et détecte les disques déconnectés et tente de les resynchroniser avec la matrice RAID.
Vous pouvez vérifier l'état de récupération avec :
# show system internal file /proc/mdstat
Vérifiez que la récupération est en cours. Plusieurs minutes peuvent être nécessaires pour réparer tous les disques à l'état [UU]. Voici un exemple de récupération en cours d'exécution :
switch# show system internal file /proc/mdstat \
Personalities : [raid1]
md6 : active raid1 sdd6[2] sdc6[0]
77888 blocks [2/1] [U_] <-- "U_" represents the broken state
resync=DELAYED
md5 : active raid1 sdd5[2] sdc5[0]
78400 blocks [2/1] [U_]
resync=DELAYED
md4 : active raid1 sdd4[2] sdc4[0]
39424 blocks [2/1] [U_]
resync=DELAYED
md3 : active raid1 sdd3[2] sdc3[0]
1802240 blocks [2/1] [U_]
[=>...................] recovery = 8.3% (151360/1802240) finish=2.1min s peed=12613K/sec
unused devices: <none>
Une fois la récupération terminée, elle doit se présenter comme suit :
switch# show system internal file /proc/mdstat
Personalities : [raid1]
md6 :active raid1 sdd6[1] sdc6[0]
77888 blocks [2/2] [UU] <-- "UU" represents the correct state
md5 :active raid1 sdd5[1] sdc5[0]
78400 blocks [2/2] [UU]
md4 :active raid1 sdd4[1] sdc4[0]
39424 blocks [2/2] [UU]
md3 :active raid1 sdd3[1] sdc3[0]
1802240 blocks [2/2] [UU]
unused devices: <none>
Une fois que tous les disques sont dans [UU], la matrice RAID est entièrement sauvegardée avec les deux disques synchronisés.
Scénario G (0 échec sur le mode actif, 2 échec sur le mode veille)
0 Échec sur le mode actif, 2 sur le mode veille
Scénario de récupération :
0 Échec sur l'actif
2 défaillances en veille
Étapes vers la résolution :
Avec 0 défaillance sur le superviseur actif et 2 sur le superviseur de secours, une restauration sans impact est possible.
La procédure de récupération consiste à effectuer un rechargement du module de secours.
1. Il est courant de voir dans les superviseurs avec une double panne de mémoire flash qu'un logiciel "reload module x" peut seulement réparer partiellement le RAID ou le faire rester sous tension au redémarrage.
Par conséquent, il est recommandé de réinstaller physiquement le superviseur en cas de double défaillance de la mémoire flash pour retirer complètement le module et le remettre sous tension. Vous pouvez également effectuer les opérations suivantes (x pour le logement de secours #) :
# module hors service x
# aucun module hors tension x
Si vous constatez que la veille reste bloquée à l'état de mise sous tension et qu'elle continue à être mise sous tension après les étapes ci-dessus, cela est probablement dû au rechargement actif de la veille pour ne pas être arrivé à temps.
Cela peut être dû à la tentative de réinitialisation du bootflash/RAID, qui peut prendre jusqu'à 10 minutes, mais qui continue d'être réinitialisé par l'actif avant d'être accompli.
Pour résoudre ce problème, configurez ce qui suit en utilisant « x » pour le numéro de logement de secours bloqué à la mise sous tension :
(config)# system standby manual-boot
(config)# reload module x force-dnld
Ce qui précède fera en sorte que l'actif ne réinitialise pas automatiquement le standby, puis recharge le standby et le force à synchroniser son image de l'actif.
Patientez 10 à 15 minutes pour voir si le mode veille est enfin en mesure d'atteindre l'état « ha-standby ». Une fois qu'il est à l'état de veille, réactivez les redémarrages automatiques de la veille avec :
(config)# system no standby manual-boot
6. Une fois que la veille est de nouveau en ligne dans un état « ha-standby », vous devrez alors exécuter l'outil de récupération pour vous assurer que la récupération est terminée. L'outil peut être téléchargé à l'adresse suivante :
https://software.cisco.com/download/release.html?mdfid=284472710&flowid=&softwareid=282088132&relind=AVAILABLE&rellifecycle=&reltype=latest
Une fois que vous avez téléchargé l'outil, décompressé et téléchargé dans le bootflash de la boîte, vous devrez exécuter la commande suivante pour commencer la récupération :
# load bootflash:n7000-s2-flash-recovery-tool.10.0.2.gbin
L'outil démarre et détecte les disques déconnectés et tente de les resynchroniser avec la matrice RAID.
Vous pouvez vérifier l'état de récupération avec :
# show system internal file /proc/mdstat
Vérifiez que la récupération est en cours. Plusieurs minutes peuvent être nécessaires pour réparer tous les disques à l'état [UU]. Voici un exemple de récupération en cours d'exécution :
switch# show system internal file /proc/mdstat
Personalities : [raid1]
md6 : active raid1 sdd6[2] sdc6[0]
77888 blocks [2/1] [U_] <-- "U_" represents the broken state
resync=DELAYED
md5 : active raid1 sdd5[2] sdc5[0]
78400 blocks [2/1] [U_]
resync=DELAYED
md4 : active raid1 sdd4[2] sdc4[0]
39424 blocks [2/1] [U_]
resync=DELAYED
md3 : active raid1 sdd3[2] sdc3[0]
1802240 blocks [2/1] [U_]
[=>...................] recovery = 8.3% (151360/1802240) finish=2.1min s peed=12613K/sec
unused devices: <none>
Une fois la récupération terminée, elle doit se présenter comme suit :
switch# show system internal file /proc/mdstat Personalities : [raid1]
md6 :active raid1 sdd6[1] sdc6[0]
77888 blocks [2/2] [UU] <-- "UU" represents the correct state
md5 :active raid1 sdd5[1] sdc5[0]
78400 blocks [2/2] [UU]
md4 :active raid1 sdd4[1] sdc4[0]
39424 blocks [2/2] [UU]
md3 :active raid1 sdd3[1] sdc3[0]
1802240 blocks [2/2] [UU]
unused devices: <none>
Une fois que tous les disques sont dans [UU], la matrice RAID est entièrement sauvegardée avec les deux disques synchronisés.
Scénario H (2 échecs sur le mode actif, 1 sur le mode veille)
2 échecs sur le mode actif, 1 sur le mode veille
Scénario de récupération :
2 échecs sur l'actif
1 Échec de la mise en veille
Étapes vers la résolution :
Avec 2 échecs sur le superviseur actif et 1 sur le superviseur de secours, une restauration sans impact est possible, selon la quantité de configuration en cours ajoutée depuis que le superviseur de secours n'a pas pu synchroniser sa configuration en cours avec le superviseur actif.
La procédure de récupération consiste à sauvegarder la configuration en cours à partir du superviseur actif, à basculer vers le superviseur de secours sain, à copier la configuration en cours manquante vers le nouveau superviseur actif, à mettre manuellement en ligne le superviseur actif précédent, puis à exécuter l'outil de récupération.
1. Sauvegardez toute la configuration en cours en externe avec « copy running-config tftp: vdc-all". Notez qu'en cas de défaillance de la double mémoire flash, les modifications de configuration depuis le remontage du système en lecture seule ne sont pas présentes dans la configuration initiale. Vous pouvez consulter « show system internal raid » pour le module affecté afin de déterminer quand le second disque est tombé en panne, c'est-à-dire où le système passe en lecture seule. De là, vous pouvez consulter « show accounting log » pour chaque VDC afin de déterminer quelles modifications ont été apportées depuis la défaillance de la double mémoire flash, de sorte que vous saurez quoi ajouter si la configuration de démarrage persiste lors du rechargement.
Notez qu'il est possible que la configuration initiale soit effacée lors du rechargement d'un superviseur avec une double panne de mémoire flash, ce qui explique pourquoi la configuration doit être sauvegardée en externe.
2. Une fois que la configuration en cours a été copiée à partir du superviseur actif, il est conseillé de la comparer à la configuration de démarrage pour voir ce qui a changé depuis le dernier enregistrement. Ceci peut être vu avec "show startup-configuration". Les différences dépendront bien sûr complètement de l'environnement, mais il est bon de savoir ce qui peut manquer lorsque la veille se met en ligne en tant qu'actif. Il est également conseillé de copier les différences déjà copiées dans un bloc-notes afin de pouvoir les ajouter rapidement au nouveau superviseur actif après le basculement.
3. Une fois les différences évaluées, vous devrez effectuer un basculement de superviseur. Le TAC recommande d'effectuer cette opération pendant une fenêtre de maintenance, car des problèmes imprévus peuvent se produire. La commande permettant d'effectuer le basculement vers le mode veille sera « system switchover ».
4. La commutation doit se produire très rapidement et le nouveau mode veille commence à redémarrer. Pendant ce temps, vous souhaiterez ajouter à nouveau toute configuration manquante à la nouvelle configuration active. Pour ce faire, copiez la configuration à partir du serveur TFTP (ou à partir de l'emplacement où elle a été enregistrée précédemment) ou ajoutez simplement manuellement la configuration dans l'interface de ligne de commande, ne copiez pas directement de tftp vers running-configuration, copiez d'abord vers bootflash, puis vers running-configuration. Dans la plupart des cas, les configurations manquantes sont très courtes et l'option CLI sera la plus réalisable.
5. Au bout d'un certain temps, le nouveau superviseur de secours peut revenir en ligne dans un état « ha-standby », mais ce qui se produit normalement, c'est qu'il est bloqué dans un état « powered-up ». L'état peut être affiché à l'aide de la commande « show module » et en se référant à la colonne « Status » située à côté du module.
Si le nouveau mode veille est mis sous tension, vous devrez le remettre manuellement en ligne. Pour ce faire, exécutez les commandes suivantes, où « x » est le module de secours bloqué dans un état « mis sous tension » :
(config)# module hors service
(config)# no poweroff module x
Si vous constatez que la veille reste bloquée à l'état de mise sous tension et qu'elle continue à être mise sous tension après les étapes ci-dessus, cela est probablement dû au rechargement actif de la veille pour ne pas être arrivé à temps.
Cela peut être dû à la tentative de réinitialisation du bootflash/RAID, qui peut prendre jusqu'à 10 minutes, mais qui continue d'être réinitialisé par l'actif avant d'être accompli.
Pour résoudre ce problème, configurez ce qui suit en utilisant « x » pour le numéro de logement de secours bloqué à la mise sous tension :
(config)# system standby manual-boot
(config)# reload module x force-dnld
Ce qui précède fera en sorte que l'actif ne réinitialise pas automatiquement le standby, puis recharge le standby et le force à synchroniser son image de l'actif.
Patientez 10 à 15 minutes pour voir si le mode veille est enfin en mesure d'atteindre l'état « ha-standby ». Une fois qu'il est à l'état de veille, réactivez les redémarrages automatiques de la veille avec :
(config)# system no standby manual-boot
6. Une fois que la veille est de nouveau en ligne dans un état « ha-standby », vous devrez alors exécuter l'outil de récupération pour vous assurer que la récupération est terminée et pour réparer la défaillance du disque unique sur le disque actif. L'outil peut être téléchargé à l'adresse suivante :
https://software.cisco.com/download/release.html?mdfid=284472710&flowid=&softwareid=282088132&relind=AVAILABLE&rellifecycle=&reltype=latest
Une fois que vous avez téléchargé l'outil, décompressé et téléchargé dans le bootflash de la boîte, vous devrez exécuter la commande suivante pour commencer la récupération :
# load bootflash:n7000-s2-flash-recovery-tool.10.0.2.gbin
L'outil démarre et détecte les disques déconnectés et tente de les resynchroniser avec la matrice RAID.
Vous pouvez vérifier l'état de récupération avec :
# show system internal file /proc/mdstat
Vérifiez que la récupération est en cours. Plusieurs minutes peuvent être nécessaires pour réparer tous les disques à l'état [UU]. Voici un exemple de récupération en cours d'exécution :
switch# show system internal file /proc/mdstat \
Personalities : [raid1]
md6 : active raid1 sdd6[2] sdc6[0]
77888 blocks [2/1] [U_] <-- "U_" represents the broken state
resync=DELAYED
md5 : active raid1 sdd5[2] sdc5[0]
78400 blocks [2/1] [U_]
resync=DELAYED
md4 : active raid1 sdd4[2] sdc4[0]
39424 blocks [2/1] [U_]
resync=DELAYED
md3 : active raid1 sdd3[2] sdc3[0]
1802240 blocks [2/1] [U_]
[=>...................] recovery = 8.3% (151360/1802240) finish=2.1min s peed=12613K/sec
unused devices: <none>
Une fois la récupération terminée, elle doit se présenter comme suit :
switch# show system internal file /proc/mdstat Personalities : [raid1]
md6 :active raid1 sdd6[1] sdc6[0]
77888 blocks [2/2] [UU] <-- "UU" represents the correct state
md5 :active raid1 sdd5[1] sdc5[0]
78400 blocks [2/2] [UU]
md4 :active raid1 sdd4[1] sdc4[0]
39424 blocks [2/2] [UU]
md3 :active raid1 sdd3[1] sdc3[0]
1802240 blocks [2/2] [UU]
unused devices: <none>
Une fois que tous les disques sont dans [UU], la matrice RAID est entièrement sauvegardée avec les deux disques synchronisés.
Si l'outil de récupération ne récupère pas l'état actuel actif avec une seule défaillance, essayez une autre « commutation système » en vous assurant que votre état actuel de veille est « ha-standby ». En cas d'échec, contactez le TAC Cisco
Scénario I (1 échec en mode actif, 2 échecs en mode veille)
Scénario de récupération :
1 Échec sur l'actif
2 défaillances en veille
Étapes vers la résolution :
Dans un scénario à double superviseur avec 1 défaillance sur le superviseur actif et 2 défaillances sur le superviseur de secours, une reprise sans impact peut être possible, mais dans de nombreux cas un rechargement peut être nécessaire.
Le processus consiste d'abord à sauvegarder toutes les configurations en cours d'exécution, puis à tenter de récupérer la mémoire Compact Flash défaillante sur l'ordinateur actif à l'aide de l'outil de récupération, puis, en cas de succès, vous allez recharger manuellement la mémoire de secours et exécuter à nouveau l'outil de récupération. Si la tentative de récupération initiale ne parvient pas à récupérer la mémoire flash défaillante sur le serveur actif, le TAC doit être engagé pour tenter une récupération manuelle à l'aide du plug-in de débogage.
1. Sauvegardez toute la configuration en cours en externe avec « copy running-config tftp: vdc-all". Vous pouvez également copier la configuration en cours sur une clé USB locale si aucun serveur TFTP n'est configuré dans l'environnement.
2. Une fois la configuration en cours sauvegardée, vous devrez exécuter l'outil de récupération pour tenter une récupération de la mémoire flash défaillante sur le disque actif. L'outil peut être téléchargé à l'adresse suivante :
Une fois que vous avez téléchargé l'outil, décompressé et téléchargé dans le bootflash de la boîte, vous devrez exécuter la commande suivante pour commencer la récupération :
# load bootflash:n7000-s2-flash-recovery-tool.10.0.2.gbin
L'outil démarre et détecte les disques déconnectés et tente de les resynchroniser avec la matrice RAID.
Vous pouvez vérifier l'état de récupération avec :
# show system internal file /proc/mdstat
Vérifiez que la récupération est en cours. Plusieurs minutes peuvent être nécessaires pour réparer tous les disques à l'état [UU]. Voici un exemple de récupération en cours d'exécution :
switch# show system internal file /proc/mdstat \
Personalities : [raid1]
md6 : active raid1 sdd6[2] sdc6[0]
77888 blocks [2/1] [U_] <-- "U_" represents the broken state
resync=DELAYED
md5 : active raid1 sdd5[2] sdc5[0]
78400 blocks [2/1] [U_]
resync=DELAYED
md4 : active raid1 sdd4[2] sdc4[0]
39424 blocks [2/1] [U_]
resync=DELAYED
md3 : active raid1 sdd3[2] sdc3[0]
1802240 blocks [2/1] [U_]
[=>...................] recovery = 8.3% (151360/1802240) finish=2.1min s peed=12613K/sec
unused devices: <none>
Une fois la récupération terminée, elle doit se présenter comme suit :
switch# show system internal file /proc/mdstat
Personalities : [raid1]
md6 :active raid1 sdd6[1] sdc6[0]
77888 blocks [2/2] [UU] <-- "UU" represents the correct state
md5 :active raid1 sdd5[1] sdc5[0]
78400 blocks [2/2] [UU]
md4 :active raid1 sdd4[1] sdc4[0]
39424 blocks [2/2] [UU]
md3 :active raid1 sdd3[1] sdc3[0]
1802240 blocks [2/2] [UU]
unused devices: <none>
Une fois que tous les disques sont dans [UU], la matrice RAID est entièrement sauvegardée avec les deux disques synchronisés.
3. Si, après avoir exécuté l'outil de récupération à l'étape 2, vous n'êtes pas en mesure de récupérer la mémoire Compact Flash défaillante sur le superviseur actif, vous devez contacter le TAC pour tenter une récupération manuelle à l'aide du plug-in de débogage linux.
4. Après avoir vérifié que les deux flashs s'affichent comme "[U]" sur le superviseur actif, vous pouvez redémarrer manuellement le superviseur de secours. Pour ce faire, exécutez les commandes suivantes, où « x » est le module de secours bloqué dans un état « mis sous tension » :
(config)# out-of-service module x
(config)# no poweroff module x
Ceci devrait ramener le superviseur de secours dans un état "ha-standby" (ceci est vérifié en affichant la colonne Status dans la sortie "show module"). Si cela réussit, passez à l'étape 6. Sinon, essayez la procédure décrite à l'étape 5.
5. Si vous constatez que la veille reste bloquée à l'état de mise sous tension et qu'elle continue à être mise sous tension après les étapes ci-dessus, cela est probablement dû au rechargement actif de la veille pour ne pas être arrivé à temps. Cela peut être dû à la tentative de réinitialisation du bootflash/RAID, qui peut prendre jusqu'à 10 minutes, mais qui continue d'être réinitialisé par l'actif avant d'être accompli. Pour résoudre ce problème, configurez ce qui suit en utilisant « x » pour le numéro de logement de secours bloqué à la mise sous tension :
(config)# system standby manual-boot
(config)# reload module x force-dnld
Ce qui précède fera en sorte que l'actif ne réinitialise pas automatiquement le standby, puis recharge le standby et le force à synchroniser son image de l'actif.
Patientez 10 à 15 minutes pour voir si le mode veille est enfin en mesure d'atteindre l'état « ha-standby ». Une fois qu'il est à l'état de veille, réactivez les redémarrages automatiques de la veille avec :
(config)# system no standby manual-boot
6. Une fois que la veille est de nouveau en ligne dans un état « ha-standby », vous devrez alors exécuter l'outil de récupération pour vous assurer que la récupération est terminée. Vous pouvez exécuter le même outil que sur l'actif pour cette étape, aucun téléchargement supplémentaire n'est nécessaire car l'outil de récupération s'exécute sur l'actif et le veille.
Scénario J (2 échecs sur le mode actif, 2 échecs sur le mode veille)
Scénario de récupération :
2 échecs sur l'actif
2 défaillances en veille
Étapes vers la résolution :
Note: Il est souvent observé dans les cas de défaillances de mémoire flash double, un « rechargement » logiciel peut ne pas récupérer entièrement le RAID et peut nécessiter l'exécution de l'outil de récupération ou des rechargements ultérieurs pour récupérer. Dans presque tous les cas, il a été résolu par une réinstallation physique du module de supervision. Par conséquent, si l'accès physique au périphérique est possible, après avoir sauvegardé la configuration en externe, vous pouvez tenter une récupération rapide qui a le plus de chances de réussir en réinstallant physiquement le superviseur lorsqu'il est prêt à recharger le périphérique. Cette opération va couper complètement l'alimentation du superviseur et devrait permettre la récupération des deux disques dans le RAID. Passez à l'étape 3 si la récupération de la réinstallation physique n'est que partielle, ou à l'étape 4 si elle échoue complètement car le système ne démarre pas complètement.
Résumé
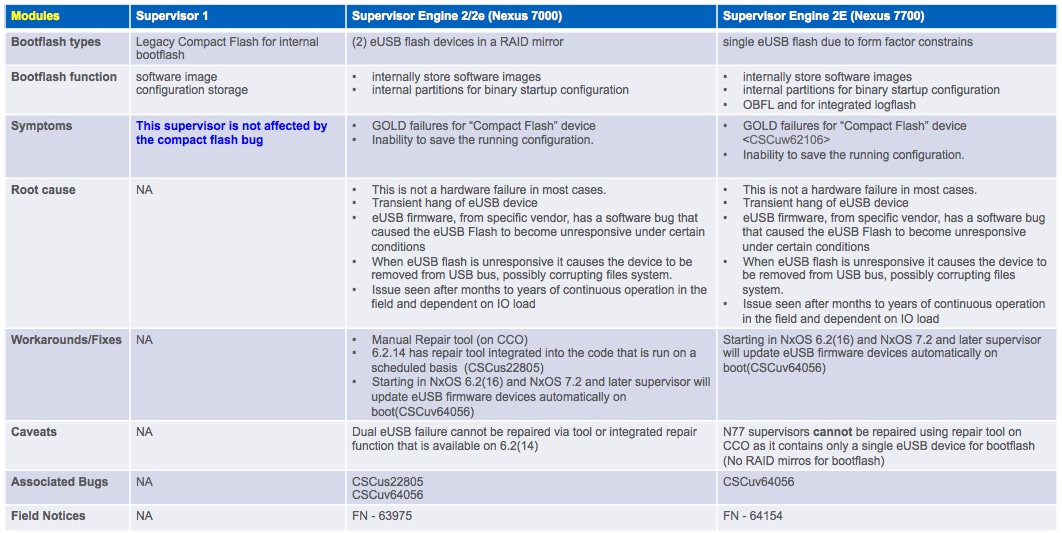
FAQ
Existe-t-il une solution permanente à ce problème ?
Consultez la section Solutions à long terme ci-dessous.
Pourquoi n'est-il pas possible de récupérer un double basculement sur les systèmes actif et en veille en rechargeant le superviseur en veille et en basculant ?
La raison pour laquelle ce n'est pas possible est que pour permettre au superviseur de secours de se trouver dans un état "ha-standby", le superviseur actif doit écrire plusieurs choses dans sa mémoire Compact Flash (informations SNMP, etc.), ce qu'il ne peut pas faire s'il a lui-même une panne de mémoire Flash double.
Que se passe-t-il si l'outil de récupération Flash ne parvient pas à remonter la mémoire Compact Flash ?
Contactez le TAC Cisco pour connaître les options de ce scénario.
Ce bogue affecte-t-il également le Nexus 7700 Sup2E ?
Il existe un défaut distinct pour le N7700 Sup2E - CSCuv64056 . L'outil de récupération ne fonctionne pas pour le N7700.
L'outil de récupération fonctionne-t-il pour les images NPE ?
L'outil de récupération ne fonctionne pas pour les images NPE.
Un ISSU vers une version résolue du code peut-il résoudre ce problème ?
Non. Une ISSU utilise un basculement de superviseur qui peut ne pas fonctionner correctement en raison de la défaillance de la mémoire Compact Flash.
Nous avons réinitialisé la carte concernée. L'état RAID imprime 0xF0, mais les tests GOLD échouent toujours ?
Les bits d'état RAID sont réinitialisés après la réinitialisation de la carte après application de la récupération automatique.
Cependant, toutes les conditions de défaillance ne peuvent pas être récupérées automatiquement.
Si les bits d'état RAID ne sont pas imprimés en tant que [2/2] [U], la récupération est incomplète.
Suivez les étapes de récupération indiquées
La défaillance de la mémoire flash aura-t-elle un impact sur le fonctionnement ?
Non, mais le système peut ne pas redémarrer en cas de panne de courant. Les configurations de démarrage seront également perdues.
Quels sont les éléments recommandés pour un système d'exploitation sain du point de vue du client en termes de surveillance et de récupération ?
Vérifiez l'état du test GOLD compact pour toute défaillance et essayez de récupérer dès que la première partie flash échoue.
Puis-je corriger un échec de la mémoire flash USB défaillante en effectuant une ISSU à partir du code affecté vers la version corrigée ?
ISSU ne réparera pas l'eUSB défaillant. La meilleure option est d'exécuter l'outil de récupération pour une défaillance unique d'eusb sur le sup ou de recharger le sup en cas de défaillance double d'eusb.
Une fois le problème résolu, effectuez la mise à niveau. Le correctif pour CSCus2805 aide à corriger la défaillance d'un seul eUSB UNIQUEMENT et il le fait en analysant le système à intervalles réguliers et tente de réactiver l'eUSB inaccessible ou en lecture seule en utilisant le script.
Il est rare de voir les deux défaillances de la mémoire flash eusb sur le superviseur se produire simultanément, par conséquent cette solution de contournement sera efficace.
Combien de temps faut-il pour que le problème réapparaisse si vous corrigez les échecs de la mémoire flash en utilisant le plug-in ou le rechargement ?
Généralement, il est vu par un temps de disponibilité plus long. Ce chiffre n'est pas exactement quantifié et peut varier d'un an ou plus. En fin de compte, plus le flash eusb est sollicité en termes d'écritures de lecture, plus la probabilité que le système s'exécute dans ce scénario est élevée.
Show system internal raid affiche l'état de la mémoire flash deux fois dans différentes sections. Ces sections ne sont pas non plus cohérentes
La première section indique l'état actuel et la seconde l'état de démarrage.
L'état actuel est ce qui importe et il doit toujours apparaître comme UU.
Solutions à long terme
Ce défaut a une solution de contournement dans 6.2(14), mais le correctif du microprogramme a été ajouté à 6.2(16) et 7.2(x) et plus tard.
Il est conseillé de mettre à niveau vers une version avec le correctif du micrologiciel pour résoudre complètement ce problème.
Si vous ne parvenez pas à mettre à niveau vers une version fixe de NXOS, deux solutions sont possibles.
La solution 1 consiste à exécuter l'outil de récupération rapide de manière proactive chaque semaine à l'aide du planificateur. La configuration suivante du planificateur avec l'outil de récupération rapide dans la mémoire flash de démarrage :
ordonnanceur de fonctions
nom du travail du planificateur Flash_Job
copy bootflash:/n7000-s2-flash-recovery-tool.10.0.2.gbin bootflash:/flash_recovery_tool_copy
chargement de bootflash:/flash_recovery_tool_copy
sortie
nom de planification du planificateur Flash_Recovery
nom du travail Flash_Job
heure hebdomadaire 7
Remarques :
- La récupération rapide doit porter le même nom et figurer dans la mémoire flash de démarrage.
- Le 7 dans la configuration « heure hebdomadaire 7 » représente un jour de la semaine, le samedi dans ce cas.
- La fréquence maximale recommandée par Cisco pour exécuter l'outil de récupération rapide est d'une fois par semaine.
La solution 2 est documentée sur le lien suivant de la note technique
Contribution d’experts de Cisco
- Austin PeacockIngénieur TAC Cisco
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)