Introduction
Ce document décrit les différents types d'erreurs de disque, comment les classer et les outils que vous pouvez utiliser pour les identifier.
Conditions préalables
Exigences
Aucune exigence spécifique n'est associée à ce document.
Composants utilisés
Les informations contenues dans ce document sont basées sur les disques durs dans Unified Computing System (UCS).
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. If your network is live, make sure that you understand the potential impact of any command.
Informations générales
Le document décrit également le rôle du contrôleur de disque dur (HDD) et du contrôleur RAID (Redundant Array of Independent Disks) lorsque vous identifiez des erreurs moyennes sur les disques.
Remarque : les erreurs de support sont également appelées erreurs de support
Gérer les erreurs moyennes du disque dur
Quelles sont les causes des erreurs de disque dur ?
La cause la plus fréquente d'erreurs moyennes est une faible amplitude du signal qui se traduit par
- Emplacement de lecture d'adresse de bus logique (LBA) non fiable. Parfois récupérable avec plusieurs tentatives.
- Conditions transitoires, écritures volantes élevées causées par des particules souples.
- Conditions transitoires provoquées par des chocs temporaires, des vibrations ou des événements acoustiques qui entraînent des écritures hors piste.
- Mauvaise fonction de mappage des erreurs dans la fabrication du disque dur, ce qui entraîne un remplissage des emplacements de défaut principaux actuels.
Comment le disque dur détecte-t-il l'erreur de support ?
Étape 1. Le disque dur effectue régulièrement des analyses de support en arrière-plan pour détecter les erreurs.
Étape 2. Le disque dur tente de lire à partir du support et, pour une raison quelconque, ne parvient pas à récupérer les données qui ont été écrites.
Étape 3. Lorsque le disque dur ne parvient pas à récupérer les données écrites, il appelle le code de récupération du disque dur qui tente diverses étapes de récupération d'erreur pour lire correctement les données à partir du support.
Étape 4. Si toutes les étapes de récupération échouent, le lecteur génère une erreur 03/11/0x sur l'hôte et les LBA sont placés sur la liste des défauts en attente.
Comment le contrôleur Raid détecte-t-il les erreurs moyennes ?
- Le contrôleur RAID rencontrera des erreurs moyennes lors des opérations de lecture, de vérification de cohérence, de lecture normale, de reconstruction et de lecture/modification/écriture de la patrouille.
- En fonction de la configuration RAID, le contrôleur peut être en mesure de gérer l'erreur de support signalée par le disque dur et aucune action supplémentaire ne sera requise.
- Dans certains cas, le contrôleur ne pourra pas gérer l'erreur de support et transmettra l'erreur à l'hôte pour gérer l'erreur.
Quand le système d'exploitation détecte-t-il des erreurs moyennes ?
- Si le disque dur signale une erreur moyenne et que le contrôleur RAID ne peut pas gérer la récupération, l'hôte est averti de l'erreur.
- Cette notification n'est plus seulement un message d'avertissement qui informerait le système que l'événement s'est produit. Il s'agit d'une demande d'action du système d'exploitation, car le disque dur et le contrôleur RAID n'ont pas pu récupérer de l'erreur de support.
- Si le système d'exploitation dispose du contexte requis pour résoudre correctement l'erreur de support, elle doit être gérée par le système d'exploitation
- Si les disques sont dans Juste un paquet de disques (JBOD), le système d'exploitation verra des erreurs car elles ne sont pas corrigées par le contrôleur. C'est le cas dans les environnements HyperFlex (HX)/Virtual Storage Area Network (VSAN).
Rôle du disque dur
Défauts croissants (liste G) Niveau de disque dur
Pendant le fonctionnement d'un lecteur, la tête peut tomber sur un secteur dont le niveau de lecture magnétique est affaibli. Les données sont toujours lisibles, mais elles peuvent tomber sous le seuil de préférence pour des niveaux de lecture de secteur satisfaisants. Ce lecteur de disque considérerait ce secteur comme un secteur qui pourrait et pourrait secteur de réserve ces données à un nouvel emplacement disponible dans la liste de réserve de bon connu. Une fois les données déplacées, l'ancienne adresse de secteur est ajoutée à la liste Grown Defects, pour ne plus jamais être utilisée. Ce processus est une erreur de support récupérable. Le lecteur donnera un déclencheur SMART une fois qu'une majorité de ses secteurs de rechange, dont le fonctionnement a été vérifié, seront épuisés.
Rôle du contrôleur RAID
Lecture de patrouille
- Patrol Read est une option définissable par l'utilisateur qui effectue des lectures de lecteur en arrière-plan et mappe toutes les zones défectueuses du lecteur.
- Patrol Read recherche les erreurs de disque physique qui pourraient entraîner une panne de disque. Ces vérifications comprennent habituellement une tentative d'action corrective. La lecture de la patrouille peut être activée ou désactivée avec une activation automatique ou manuelle.
- Une lecture de contrôle vérifie périodiquement tous les secteurs des disques physiques connectés à un contrôleur, qui incluent la zone réservée au système dans les lecteurs configurés en RAID. Patrol Read fonctionne pour tous les niveaux RAID et tous les disques de secours.
- Ce processus démarre uniquement lorsque le contrôleur RAID est inactif pendant une durée définie et qu'aucune autre tâche en arrière-plan n'est active, bien qu'il puisse continuer à s'exécuter en même temps que des processus d'entrée/sortie (E/S) lourds.
- Vous ne pouvez pas effectuer de lectures de contrôle sur des lecteurs configurés dans JBOD.
Remarque : l'indexation sémantique latente (LSI) vous recommande de conserver la fréquence de lecture de surveillance et les autres paramètres de lecture de surveillance aux valeurs par défaut pour obtenir les meilleures performances du système. Si vous décidez de modifier les valeurs, enregistrez ici la valeur par défaut d'origine afin de pouvoir les restaurer ultérieurement.
Remarque : Patrol Read ne rend pas compte de sa progression lors de son exécution. L'état de lecture de la surveillance n'est consigné que dans le journal des événements.
Les options de lecture de la patrouille sont comme illustré dans l'image :
 MégaCli, exemples
MégaCli, exemples
Pour afficher des informations sur l'état de lecture de la surveillance et le délai entre les lectures de la surveillance :
# MegaCli64 -AdpPR -Info -aALL
Pour connaître le taux de lecture de la surveillance en cours, exécutez la commande suivante :
# MegaCli64 -AdpGetProp PatrolReadRate -aALL
Pour désactiver la surveillance automatique, procédez comme suit :
# MegaCli64 -AdpPR -Dsbl -aALL
Pour activer la surveillance automatique, procédez comme suit :
#MegaCli64 -AdpPR -EnblAuto -aALL
Pour lancer une patrouille manuelle, lisez la commande scan :
# MegaCli64 -AdpPR -Start -aALL
Pour arrêter une patrouille, lisez le balayage :
# MegaCli64 -AdpPR -Stop -aALL
Contrôle de cohérence
- En RAID, le contrôle de cohérence vérifie l'exactitude des données redondantes dans une matrice. Par exemple, dans un système avec parité, vérifier la cohérence signifie calculer la parité des lecteurs de données et comparer les résultats au contenu du lecteur de parité.
- JBOD ne prend pas en charge le contrôle de cohérence.
- RAID 0 ne prend pas en charge le contrôle de cohérence.
- RAID 1 utilise une comparaison de données et non une parité.
- RAID 6 calcule la parité pour 2 disques de parité et vérifie les deux.
Remarque : il est recommandé d'exécuter une vérification de cohérence au moins une fois par mois.
Les options de gestion du contrôle de cohérence sont les suivantes :
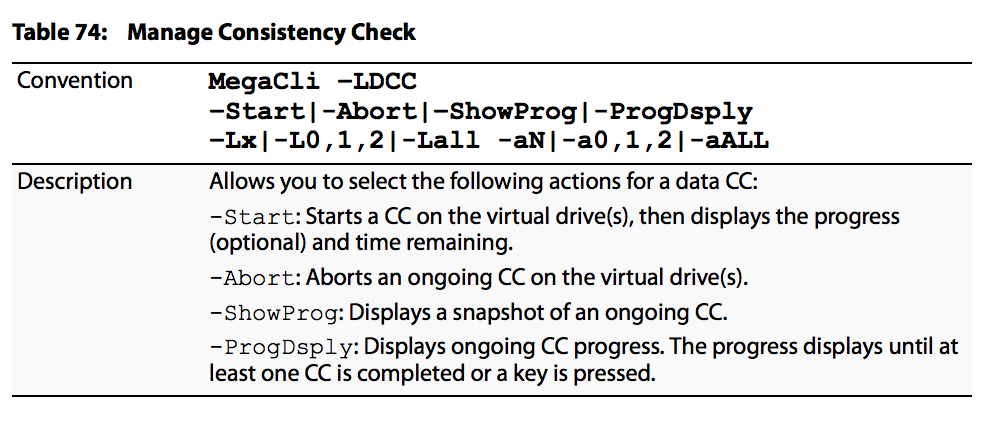
Les options de planification du contrôle de cohérence sont les suivantes :

MégaCli, exemples
Pour voir l'heure de la prochaine vérification de cohérence programmée :
#MegaCli64 -AdpCcSched -Info -aALL
Pour modifier l'heure de vérification de cohérence planifiée :
#MegaCli64 -AdpCCSched -SetSTartTime 20171028 02 -aALL
Pour désactiver la vérification de cohérence :
#MegaCli64 -AdpCcSched -Dsbl -aALL
Conditions dans lesquelles un contrôleur RAID ne peut pas réparer une erreur moyenne
- Dans JBOD
- Le système d'exploitation hôte est responsable des erreurs moyennes.
- Dans RAID 0
- Il n'y a pas de redondance, de sorte que le contrôleur ne peut pas fournir au disque dur les données à écrire sur le LBA.
- Dans RAID 1
- Lorsque le contrôleur ne peut pas dire quelle copie miroir contient les données correctes. Cela se produit uniquement si les deux LBA peuvent être lus, mais que les données ne correspondent pas.
- RAID 5
- S'il y a 2 erreurs ou plus dans la même bande. Plus susceptible de se produire après le lancement de la reconstruction d'une baie. Le lecteur qui est reconstruit est une erreur, et une erreur moyenne sur n'importe quel autre lecteur reconstruit serait la deuxième erreur. Le contrôleur ne serait pas en mesure de reconstruire les données nécessaires pour reconstruire le LBA sur le lecteur de remplacement.
- RAID 6
- S'il y a 3 erreurs ou plus dans la même bande. Survient généralement lors de la reconstruction d'une baie. Le lecteur qui est reconstruit est une erreur, et une erreur moyenne sur deux autres lecteurs pendant que la reconstruction est en cours serait une deuxième et troisième erreurs, ou une erreur moyenne et une deuxième panne de lecteur. Le contrôleur ne serait pas en mesure de reconstruire les données nécessaires pour reconstruire les LBA sur les lecteurs présentant les erreurs.
Informations connexes
 Commentaires
Commentaires