Introduction
Ce document décrit comment écrire et configurer un filtre afin de détecter et d'agir sur les jeux de caractères basés sur le type de contenu sur l'appareil de sécurité de la messagerie électronique Cisco (ESA). Le document suivant peut être utilisé pour détecter les caractères basés sur une langue étrangère vus dans les messages de spam.
Informations générales
Les administrateurs ESA peuvent recevoir un afflux de messages électroniques contenant des langues étrangères basées sur des caractères qui ne sont pas des messages légitimes pour leur société ou leur(s) domaine(s). Une façon d'aborder l'ESA, nous avons trois options :
-
Écrivez un filtre pour détecter le type de contenu.
-
Écrire un filtre pour référencer un dictionnaire basé sur des caractères dans un filtre.
- Écrivez un filtre à l'aide de la condition Message Language. (Cette option est une nouvelle fonctionnalité pour AsyncOS Email Security 10.0.0-203 et versions ultérieures.)
Comment bloquer les jeux de caractères basés sur le type de contenu
Écrire un filtre pour détecter le type de contenu
La première option consiste pour l'administrateur à écrire et configurer un filtre, puis à l'associer à une stratégie de messagerie, le cas échéant.
Remarque : l'écriture et la configuration de ce filtre en tant que filtre de messages peuvent être coûteuses en ressources pour analyser le corps des e-mails à la recherche des jeux de caractères.
Remarque : il est vivement recommandé de configurer ce filtre en tant que filtre de contenu, car les filtres de contenu se produisent après l'analyse antispam. Toutefois, il est possible de l'écrire et de le configurer en tant que filtre de messages, si nécessaire.
L'exemple suivant prendra en compte un message électronique contenant des caractères russes (cyrilliques) via le jeu de caractères Windows-1251. Écrit en tant que filtre de contenu :
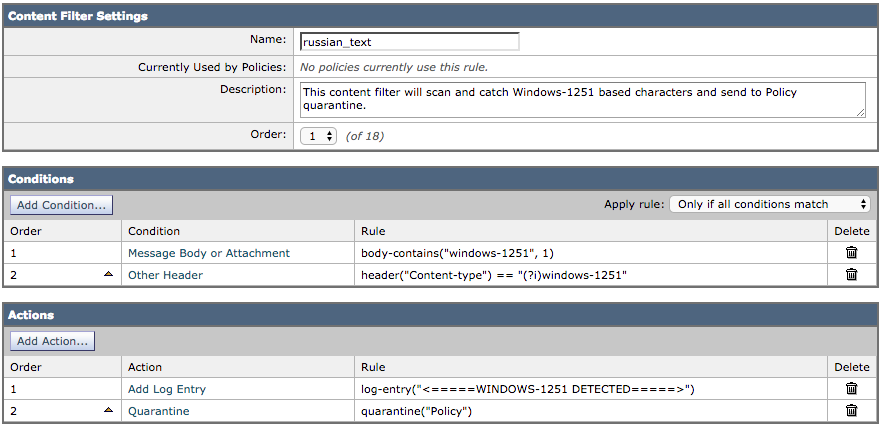
L'e-mail test utilisé contiendra les éléments suivants dans le corps de l'e-mail :
Russian uses а, э, ы, у, o, я, е, ё, ю, и as vowels. You could create a message filter set to "Matches any of the following" that test whether "Body" "contains" "и", "Body" "contains" "ё" and so forth until you covered all of the vowels. Ssince English also uses "a" , "e" , "o", and "y" letters don't test for them. The reason for "Matches any of the following" is to logically OR them - you want the action to take place if any of those letters are found.
Avec le filtre de contenu configuré comme ci-dessus, les journaux de messagerie enregistreraient des données similaires à celles-ci :
Thu Sep 10 14:50:09 2015 Info: Start MID 164993 ICID 266729
Thu Sep 10 14:50:09 2015 Info: MID 164993 ICID 266729 From: <end_user@test.com>
Thu Sep 10 14:50:09 2015 Info: MID 164993 ICID 266729 RID 0 To: <recpient@my_co.com>
Thu Sep 10 14:50:09 2015 Info: MID 164993 using engine: SPF Verdict Cache using cached verdict
Thu Sep 10 14:50:09 2015 Info: MID 164993 Message-ID '<7A961F85-A5F1-413F-87CB-C31D2E5605EC@my_co.com>'
Thu Sep 10 14:50:09 2015 Info: MID 164993 Subject 'russian test'
Thu Sep 10 14:50:09 2015 Info: MID 164993 ready 2302 bytes from <end_user@test.com>
Thu Sep 10 14:50:09 2015 Info: MID 164993 matched all recipients for per-recipient policy DEFAULT in the inbound table
Thu Sep 10 14:50:09 2015 Info: MID 164993 AMP file reputation verdict : CLEAN
Thu Sep 10 14:50:09 2015 Info: MID 164993 using engine: GRAYMAIL negative
Thu Sep 10 14:50:09 2015 Info: MID 164993 Custom Log Entry: <====== WINDOWS-1251 DETECTED ======>
Thu Sep 10 14:50:09 2015 Info: MID 164993 quarantined to "Policy" (content filter:russian_text)
Thu Sep 10 14:50:09 2015 Info: Message finished MID 164993 done
D'autres langues et jeux de caractères peuvent être utilisés. Veuillez consulter la section Références pour plus d'informations.
Écrire un filtre pour référencer un dictionnaire basé sur des caractères
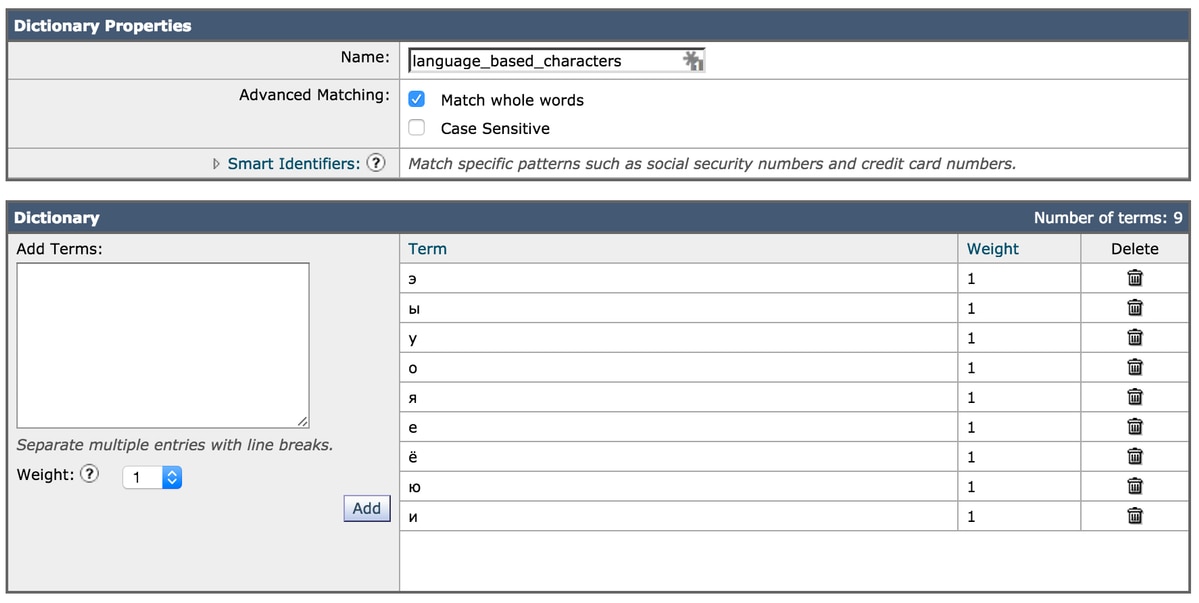
La deuxième option consiste à ajouter la liste des jeux de caractères à un fichier texte de dictionnaire et à y faire référence dans le filtre.
Exemple d'ajout de caractères au dictionnaire :
Les caractères sont maintenant attribués au dictionnaire et le dictionnaire lui-même est référencé dans les éléments de condition du filtre :
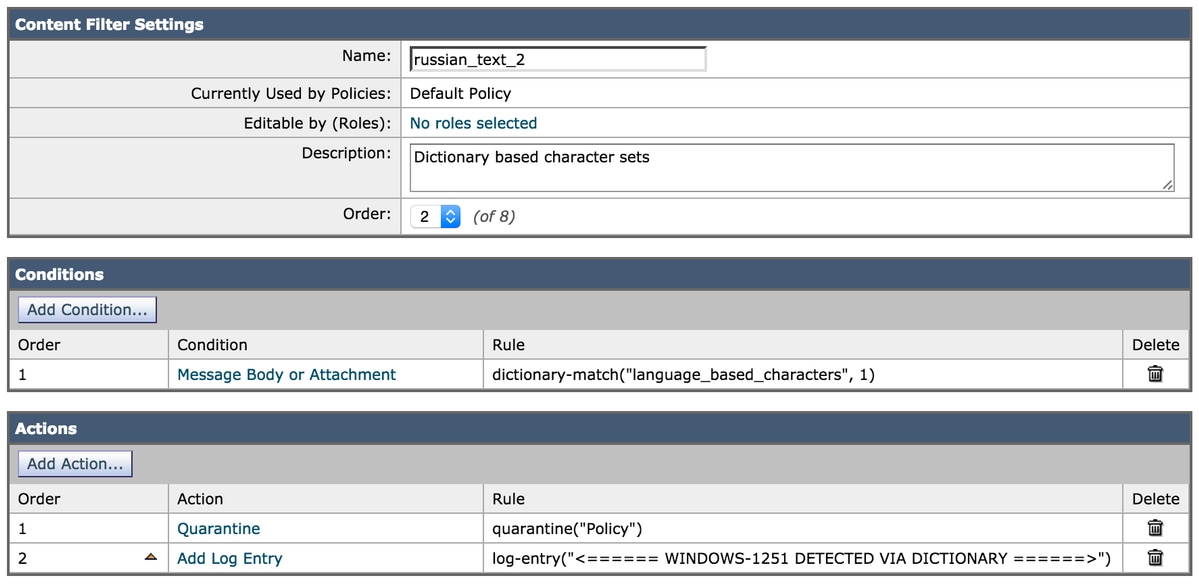
Utilisant le même e-mail test que ci-dessus, il contient les éléments suivants dans le corps de l'e-mail :
Russian uses а, э, ы, у, o, я, е, ё, ю, и as vowels. You could create a message filter set to "Matches any of the following" that test whether "Body" "contains" "и", "Body" "contains" "ё" and so forth until you covered all of the vowels. Ssince English also uses "a" , "e" , "o", and "y" letters don't test for them. The reason for "Matches any of the following" is to logically OR them - you want the action to take place if any of those letters are found.
Avec le filtre de contenu configuré comme ci-dessus à l'aide de la condition de correspondance du dictionnaire, les journaux de messagerie enregistrent des données similaires à celles-ci :
Thu Sep 10 15:26:08 2015 Info: Start MID 164995 ICID 266737
Thu Sep 10 15:26:08 2015 Info: MID 164995 ICID 266737 From: <end_user@test.com>
Thu Sep 10 15:26:08 2015 Info: MID 164995 ICID 266737 RID 0 To: <recpient@my_co.com>
Thu Sep 10 15:26:08 2015 Info: MID 164995 using engine: SPF Verdict Cache using cached verdict
Thu Sep 10 15:26:08 2015 Info: SPF Verdict Cache cache status: hits = 6, misses = 4, expires = 1, adds = 4, seconds saved = 0.50, total seconds = 0.85
Thu Sep 10 15:26:08 2015 Info: MID 164995 Message-ID '<BCC88307-EB91-476E-8732-334E9EE84EC8@my_co.com>'
Thu Sep 10 15:26:08 2015 Info: MID 164995 Subject 'russian test 3'
Thu Sep 10 15:26:08 2015 Info: MID 164995 ready 2316 bytes from <end_user@test.com>
Thu Sep 10 15:26:08 2015 Info: MID 164995 matched all recipients for per-recipient policy DEFAULT in the inbound table
Thu Sep 10 15:26:08 2015 Info: MID 164995 AMP file reputation verdict : CLEAN
Thu Sep 10 15:26:08 2015 Info: MID 164995 using engine: GRAYMAIL negative
Thu Sep 10 15:26:08 2015 Info: MID 164995 Custom Log Entry: <====== WINDOWS-1251 DETECTED VIA DICTIONARY ======>
Thu Sep 10 15:26:08 2015 Info: MID 164995 quarantined to "Policy" (content filter:russian_text_2)
Thu Sep 10 15:26:08 2015 Info: Message finished MID 164995 done
Écrire un filtre de contenu à l'aide de la condition « Langage du message »
La troisième option consiste à utiliser la condition de « langue du message ». L'ESA utilise le moteur de détection de langue intégré pour détecter la langue dans un message. La solution matérielle-logicielle extrait l'objet et le corps du message et le transmet au moteur de détection de langue.
Le moteur de détection de langue détermine la probabilité de chaque langue dans le texte extrait et la renvoie à l'appareil. La solution matérielle-logicielle considère la langue la plus probable comme la langue du message. La solution matérielle-logicielle considère que la langue du message est « indéterminée » dans l'un des scénarios suivants :
- Si la langue détectée n'est pas prise en charge par ESA
- Si la solution matérielle-logicielle ne parvient pas à détecter la langue du message
- Si la taille totale du texte extrait envoyé au moteur de détection de langue est inférieure à 50 octets.
Remarque : cette option est une nouvelle fonctionnalité pour AsyncOS Email Security 10.0.0-203 et versions ultérieures.
L'exemple suivant prend en compte un message électronique contenant un jeu de caractères chinois/taïwanais. Écrit en tant que filtre de contenu :
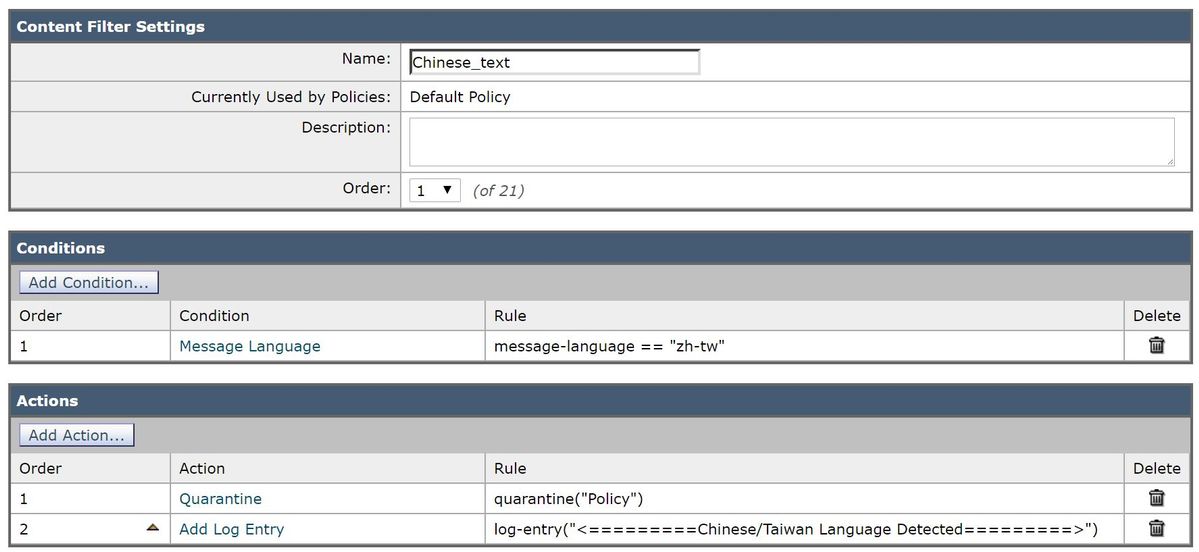
Avec le filtre de contenu configuré comme ci-dessus, les journaux de messagerie enregistreraient des données similaires à celles-ci :
Tue Feb 28 06:53:18 2017 Info: Start MID 481 ICID 27
Tue Feb 28 06:53:18 2017 Info: MID 481 ICID 27 From: <end_user@test.com>
Tue Feb 28 06:53:18 2017 Info: MID 481 ICID 27 RID 0 To: <recipient@my_co.com>
Tue Feb 28 06:53:18 2017 Info: MID 481 Subject 'Chinese text test'
Tue Feb 28 06:53:18 2017 Info: MID 481 ready 1047 bytes from <end_user@test.com>
Tue Feb 28 06:53:18 2017 Info: MID 481 matched all recipients for per-recipient policy DEFAULT in the inbound table
Tue Feb 28 06:53:18 2017 Info: MID 481 interim verdict using engine: CASE spam negative
Tue Feb 28 06:53:18 2017 Info: MID 481 using engine: CASE spam negative
Tue Feb 28 06:53:18 2017 Info: MID 481 interim AV verdict using Sophos CLEAN
Tue Feb 28 06:53:18 2017 Info: MID 481 antivirus negative
Tue Feb 28 06:53:18 2017 Info: MID 481 using engine: GRAYMAIL negative
Tue Feb 28 06:53:18 2017 Info: MID 481 Message language: 'Chinese/Taiwan'
Tue Feb 28 06:53:18 2017 Info: MID 481 Custom Log Entry: <=========Chinese/Taiwan Language Detected=========>
Tue Feb 28 06:53:18 2017 Info: MID 481 Outbreak Filters: verdict negative
Tue Feb 28 06:53:18 2017 Info: MID 481 quarantined to "Policy" (content filter:Chinese_text)
Tue Feb 28 06:53:18 2017 Info: Message finished MID 481 done
Références
- Microsoft fournit des noms de jeux de caractères (nom .NET) dans leur Identificateurs de page de code qui peut être référencé lors de l'écriture et de la configuration des filtres.
Remarque : les pages de code ANSI peuvent être différentes sur différents ordinateurs ou peuvent être modifiées pour un seul ordinateur, ce qui entraîne une corruption des données. Pour des résultats plus cohérents, les applications doivent utiliser Unicode, tel que UTF-8 ou UTF-16, au lieu d'une page de code spécifique.
Informations connexes
 Commentaires
Commentaires