Dépannage des pannes de chemin de données de matrice ponctuelle de la gamme ASR 9000
Options de téléchargement
-
ePub (611.0 KB)
Consulter à l’aide de différentes applications sur iPhone, iPad, Android ou Windows Phone -
Mobi (Kindle) (617.7 KB)
Consulter sur un appareil Kindle ou à l’aide d’une application Kindle sur plusieurs appareils
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Table des matières
Introduction
Ce document décrit les messages d'échec de chemin de données de structure ponctuelle observés pendant le fonctionnement du routeur de services d'agrégation Cisco (ASR) 9000.
Le message s'affiche au format suivant :
RP/0/RSP0/CPU0:Sep 3 13:49:36.595 UTC: pfm_node_rp[358]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED: Set|online_diag_rsp[241782]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/7/CPU0, 1) (0/7/CPU0, 2) (0/7/CPU0, 3) (0/7/CPU0, 4) (0/7/CPU0, 5)
(0/7/CPU0, 6) (0/7/CPU0, 7)
Ce document est destiné à toute personne souhaitant comprendre le message d'erreur et les actions à entreprendre si le problème est détecté.
Conditions préalables
Exigences
Cisco vous recommande d'avoir une connaissance approfondie des sujets suivants :
- Cartes de ligne ASR 9000
- Cartes de matrice
- Processeurs de routage
- Architecture du châssis
Cependant, ce document n'exige pas que les lecteurs soient familiarisés avec les détails du matériel. Les informations de base nécessaires sont fournies avant que le message d'erreur ne soit expliqué. Ce document décrit l'erreur sur les cartes de ligne Trident et Typhoon. Reportez-vous à la section Comprendre les types de cartes de ligne de la gamme ASR 9000 pour une explication de ces termes.
Composants utilisés
Ce document n'est pas limité à des versions de matériel et de logiciel spécifiques.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. Si votre réseau est en ligne, assurez-vous de bien comprendre l’incidence possible des commandes.
Comment utiliser ce document ?
Considérez ces suggestions sur la façon d'utiliser ce document afin de glaner des détails essentiels et comme guide de référence dans la procédure de dépannage :
- Lorsqu'il n'est pas urgent de déterminer la cause première d'une défaillance du chemin de données de matrice de points, lisez toutes les sections de ce document. Ce document crée l'arrière-plan nécessaire afin d'isoler un composant défectueux lorsqu'une telle erreur se produit.
- Utilisez la section FAQ si vous avez une question spécifique à l'esprit pour laquelle une réponse rapide est nécessaire. Si la question n'est pas incluse dans la section FAQ, alors vérifiez si le document principal répond à la question.
- Utilisez toutes les sections de Analyze Faults sur afin d'isoler le problème à un composant défectueux quand un routeur rencontre une défaillance ou afin de vérifier s'il s'agit d'un problème connu.
Informations générales
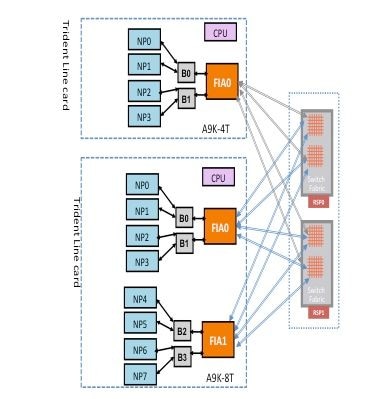
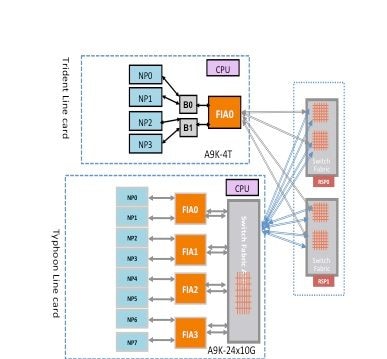
Un paquet peut traverser deux ou trois sauts à travers la matrice de commutation en fonction du type de carte de ligne. Les cartes de ligne de génération Typhoon ajoutent un élément de matrice de commutation supplémentaire, tandis que les cartes de ligne Trident commutent tout le trafic avec la matrice sur la carte processeur de routage uniquement. Ces schémas présentent les éléments de fabric pour ces deux types de cartes de ligne, ainsi que la connectivité de fabric à la carte processeur de routage :
Chemin des paquets de diagnostic Punt Fabric
L'application de diagnostic qui s'exécute sur le processeur de la carte processeur de routage injecte périodiquement des paquets de diagnostic destinés à chaque processeur réseau (NP). Le paquet de diagnostic est rebouclé à l’intérieur du processeur réseau et réinjecté vers le processeur de la carte processeur de routage qui a généré le paquet. Cette vérification périodique de l'état de chaque processeur réseau avec un paquet unique par processeur réseau par l'application de diagnostic sur la carte processeur de routage fournit une alerte pour toute erreur fonctionnelle sur le chemin de données pendant le fonctionnement du routeur. Il est essentiel de noter que l'application de diagnostic sur le processeur de routage actif et le processeur de routage de secours injecte un paquet par NP périodiquement et maintient un nombre de succès ou d'échecs par NP. Lorsqu'un seuil de paquets de diagnostic abandonnés est atteint, l'application génère une erreur.
Vue conceptuelle du chemin de diagnostic
Avant que le document ne décrive le chemin de diagnostic sur les cartes de ligne Trident et Typhoon, cette section fournit un aperçu général du chemin de diagnostic du fabric depuis les cartes processeur de routage actives et de secours vers le processeur réseau sur la carte de ligne.
Chemin des paquets entre la carte processeur de routage active et la carte de ligne
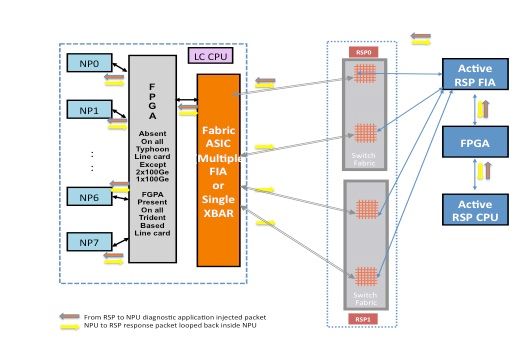
Les paquets de diagnostic injectés depuis le processeur de routage actif dans le fabric vers le NP sont traités comme des paquets de monodiffusion par le fabric de commutation. Avec les paquets de monodiffusion, la matrice de commutation choisit la liaison sortante en fonction de la charge de trafic actuelle de la liaison, ce qui permet de soumettre les paquets de diagnostic à la charge de trafic sur le routeur. Lorsqu'il existe plusieurs liaisons sortantes vers le réseau sans fil, le circuit ASIC de matrice de commutation choisit la liaison actuellement la moins chargée.
Ce schéma décrit le chemin de paquet de diagnostic provenant du processeur de routage actif.
Remarque : la première liaison qui connecte l'ASIC d'interface de fabric (FIA) sur la carte de ligne à la barre transversale (XBAR) sur la carte processeur de routage est choisie tout le temps pour les paquets destinés à la carte réseau. Les paquets de réponse du processeur réseau sont soumis à un algorithme de distribution de charge de liaison (si la carte de ligne est basée sur un typhon). Cela signifie que le paquet de réponse du processeur réseau vers le processeur de routage actif peut choisir n'importe laquelle des liaisons de fabric qui connectent les cartes de ligne à la carte de processeur de routage en fonction de la charge de la liaison de fabric.
Chemin des paquets entre la carte processeur de routage de secours et la carte de ligne
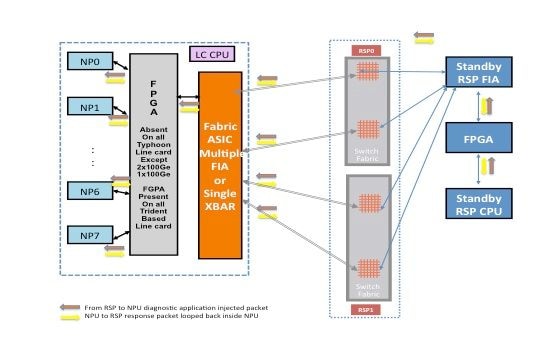
Les paquets de diagnostic injectés depuis le processeur de routage de secours dans le fabric vers le NP sont traités comme des paquets de multidiffusion par le fabric de commutation. Bien qu'il s'agisse d'un paquet multidiffusion, il n'y a aucune réplication à l'intérieur du fabric. Chaque paquet de diagnostic provenant du processeur de routage de secours n’atteint toujours qu’un seul processeur réseau à la fois. Le paquet de réponse du processeur réseau vers le processeur de routage est également un paquet de multidiffusion sur le fabric sans réplication. Par conséquent, l'application de diagnostic sur le processeur de routage de secours reçoit un seul paquet de réponse des NP, paquet par paquet. L'application de diagnostic suit chaque NP du système, car elle injecte un paquet par NP et attend des réponses de chaque NP, paquet par paquet. Avec un paquet multidiffusion, la matrice de commutation choisit la liaison sortante en fonction d'une valeur de champ dans l'en-tête du paquet, ce qui permet d'injecter des paquets de diagnostic sur chaque liaison de matrice entre la carte processeur de routage et la carte de ligne. Le processeur de routage de secours assure le suivi de l'état de santé du processeur réseau sur chaque liaison de fabric qui se connecte entre la carte de processeur de routage et le logement de carte de ligne.
Le schéma précédent décrit le chemin de paquet de diagnostic provenant du processeur de routage de secours. Notez que, contrairement au cas du processeur de routage actif, toutes les liaisons qui connectent la carte de ligne au XBAR sur le processeur de routage sont exercées. Les paquets de réponse du processeur réseau empruntent la même liaison de fabric que celle utilisée par le paquet dans le processeur de routage vers la direction de la carte de ligne. Ce test garantit que toutes les liaisons qui connectent le processeur de routage de secours à la carte de ligne sont surveillées en continu.
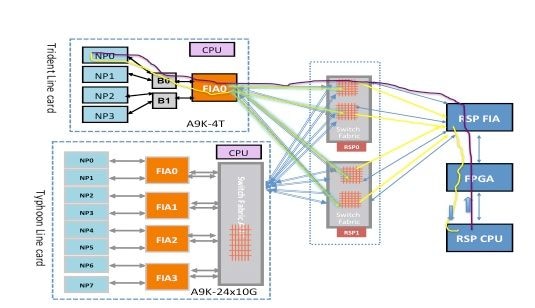
Chemin des paquets de diagnostic Punt Fabric sur la carte de ligne Trident
Ce schéma décrit les paquets de diagnostic provenant du processeur de routage destinés à un processeur réseau qui est rebouclé vers le processeur de routage. Il est important de noter les liaisons de chemin de données et les ASIC qui sont communs à tous les NP, ainsi que les liaisons et les composants qui sont spécifiques à un sous-ensemble de NP. Par exemple, le pont ASIC 0 (B0) est commun à NP0 et NP1, tandis que FIA0 est commun à tous les NP. Du côté du processeur de routage, toutes les liaisons, les circuits ASIC de chemin de données et le FPGA (Field-Programmable Gate Array) sont communs à toutes les cartes de ligne, et donc à tous les processeurs réseau d'un châssis.
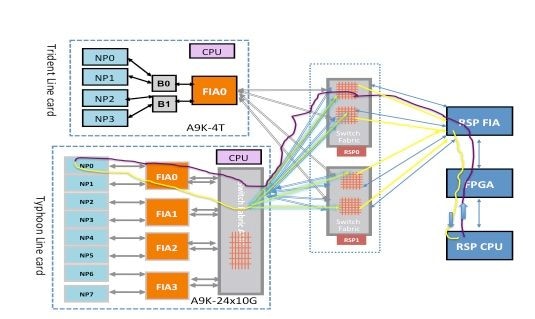
Chemin des paquets de diagnostic Punt Fabric sur la carte de ligne Typhoon
Ce schéma représente des paquets de diagnostic provenant d’une carte de processeur de routage destinés à un processeur réseau qui est rebouclé vers le processeur de routage. Il est important de noter les liaisons de chemin de données et les ASIC qui sont communs à tous les NP, ainsi que les liaisons et les composants qui sont spécifiques à un sous-ensemble de NP. Par exemple, FIA0 est commun à NP0 et NP1. Du côté de la carte processeur de routage, toutes les liaisons, les circuits ASIC de chemin de données et le FGPA sont communs à toutes les cartes de ligne, et donc à tous les processeurs réseau d'un châssis.
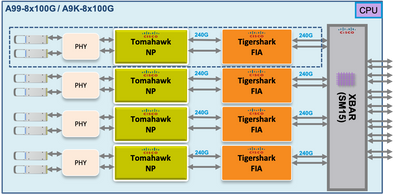
Chemin des paquets de diagnostic de matrice de points sur les cartes de ligne Tomahawk, Lightspeed et LightspeedPlus
Sur les cartes de ligne Tomahawk, il y a une connectivité 1:1 entre la FIA et le NP.
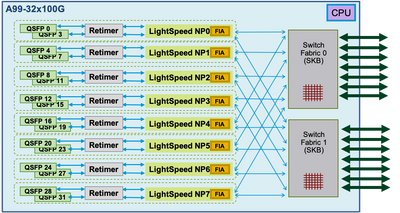
Sur les cartes de ligne Lightspeed et LightspeedPlus, la FIA est intégrée à la puce NP.
Les sections suivantes tentent de décrire le chemin de paquet vers chaque processeur réseau. Ceci est nécessaire afin de comprendre le message d'erreur du chemin de données du fabric punt, et aussi afin de localiser le point de défaillance.
Rapport d'alarme et de panne de diagnostic Punt Fabric
L'échec de l'obtention des réponses d'un processeur réseau dans un routeur ASR 9000 entraîne une alarme. La décision de déclencher une alarme par l'application de diagnostic en ligne qui s'exécute sur le processeur de routage se produit en cas de trois défaillances consécutives. L'application de diagnostic gère une fenêtre d'échec de trois paquets pour chaque NP. Le processeur de routage actif et le processeur de routage de secours diagnostiquent indépendamment et en parallèle. Le processeur de routage actif, le processeur de routage de secours ou les deux cartes de processeur de routage peuvent signaler l'erreur. L’emplacement de la panne et de la perte de paquets déterminent le processeur de routage qui signale l’alarme.
La fréquence par défaut du paquet de diagnostic vers chaque NP est d'un paquet toutes les 60 secondes ou d'un paquet par minute.
Voici le format du message d'alarme :
RP/0/RSP0/CPU0:Sep 3 13:49:36.595 UTC: pfm_node_rp[358]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED: Set|online_diag_rsp[241782]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/7/CPU0, 1) (0/7/CPU0, 2) (0/7/CPU0, 3) (0/7/CPU0, 4) (0/7/CPU0, 5)
(0/7/CPU0, 6) (0/7/CPU0, 7)
Le message indique que le processeur de routage 0/rsp0/cpu0 n'a pas pu atteindre NP 1, 2, 3, 4, 5, 6 et 7 sur la carte de ligne 0/7/cpu0.
Dans la liste des tests de diagnostic en ligne, vous pouvez voir les attributs du test de bouclage de matrice punt avec cette commande :
RP/0/RSP0/CPU0:iox(admin)#show diagnostic content location 0/RSP0/CPU0
RP 0/RSP0/CPU0:
Diagnostics test suite attributes:
M/C/* - Minimal bootup level test / Complete bootup level test / NA
B/O/* - Basic ondemand test / not Ondemand test / NA
P/V/* - Per port test / Per device test / NA
D/N/* - Disruptive test / Non-disruptive test / NA
S/* - Only applicable to standby unit / NA
X/* - Not a health monitoring test / NA
F/* - Fixed monitoring interval test / NA
E/* - Always enabled monitoring test / NA
A/I - Monitoring is active / Monitoring is inactive
Test Interval Thre-
ID Test Name Attributes (day hh:mm:ss.ms shold)
==== ================================== ============ ================= =====
1) PuntFPGAScratchRegister ---------- *B*N****A 000 00:01:00.000 1
2) FIAScratchRegister --------------- *B*N****A 000 00:01:00.000 1
3) ClkCtrlScratchRegister ----------- *B*N****A 000 00:01:00.000 1
4) IntCtrlScratchRegister ----------- *B*N****A 000 00:01:00.000 1
5) CPUCtrlScratchRegister ----------- *B*N****A 000 00:01:00.000 1
6) FabSwitchIdRegister -------------- *B*N****A 000 00:01:00.000 1
7) EccSbeTest ----------------------- *B*N****I 000 00:01:00.000 3
8) SrspStandbyEobcHeartbeat --------- *B*NS***A 000 00:00:05.000 3
9) SrspActiveEobcHeartbeat ---------- *B*NS***A 000 00:00:05.000 3
10) FabricLoopback ------------------- MB*N****A 000 00:01:00.000 3
11) PuntFabricDataPath --------------- *B*N****A 000 00:01:00.000 3
12) FPDimageVerify ------------------- *B*N****I 001 00:00:00.000 1
RP/0/RSP0/CPU0:ios(admin)#
La sortie montre que la fréquence de test PuntFabricDataPath est d'un paquet chaque minute et le seuil d'échec est de trois, ce qui implique que la perte de trois paquets consécutifs n'est pas tolérée et entraîne une alarme. Les attributs de test affichés sont des valeurs par défaut. Pour modifier les valeurs par défaut, saisissez la commande diagnostic monitor interval et diagnostic monitor threshold dans le mode de configuration de l'administration.
Chemin des paquets de diagnostic de carte de ligne basé sur Trident
Échec du diagnostic NP0
Chemin de diagnostic du fabric
Ce schéma décrit le chemin de paquets entre le processeur de routage CPU et la carte de ligne NP0. La liaison qui connecte B0 et NP0 est la seule liaison spécifique à NP0. Tous les autres liens se trouvent sur le chemin commun.
Notez le chemin du paquet du processeur de routage vers NP0. Bien qu'il y ait quatre liaisons à utiliser pour les paquets destinés à NP0 à partir du processeur de routage, la première liaison entre le processeur de routage et le logement de carte de ligne est utilisée pour le paquet à partir du processeur de routage vers la carte de ligne. Le paquet renvoyé par NP0 peut être renvoyé au processeur de routage actif par l’un des deux chemins de liaison de fabric entre le logement de carte de ligne et le processeur de routage actif. Le choix de l’une des deux liaisons à utiliser dépend de la charge de la liaison à ce moment. Le paquet de réponse de NP0 vers le processeur de routage de secours utilise les deux liaisons, mais une liaison à la fois. Le choix de la liaison est basé sur le champ d'en-tête que l'application de diagnostic remplit.
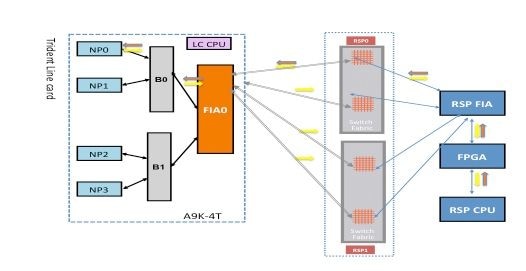
Analyse des défaillances de diagnostic NP0
Scénario de défaillance unique
Si une seule alarme de défaillance du chemin de données de matrice de point PFM (Platform Fault Manager) avec seulement NP0 dans le message de défaillance est détectée, la défaillance se produit uniquement sur le chemin de matrice qui connecte le processeur de routage et la carte de ligne NP0. Il s'agit d'une erreur unique. Si la panne est détectée sur plusieurs NP, reportez-vous à la section Multiple Fault Scenario.
RP/0/RSP0/CPU0:Sep 3 13:49:36.595 UTC: pfm_node_rp[358]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED: Set|online_diag_rsp[241782]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/7/CPU0, 0)
Remarque : cette section du document s'applique à tous les logements de carte de ligne d'un châssis, quel que soit le type de châssis. Par conséquent, cela peut être appliqué à tous les logements de carte de ligne.
Comme illustré dans le schéma de chemin de données précédent, la panne doit se situer à un ou plusieurs des emplacements suivants :
- Liaison reliant NP0 et B0
- Files d'attente B0 internes dirigées vers NP0
- NP0 interne
Scénario de défaillance multiple
Plusieurs pannes NP
Lorsque d'autres pannes sont observées sur NP0 ou que la panne PUNT_FABRIC_DATA_PATH_FAILED est également signalée par d'autres NP sur la même carte de ligne, l'isolation des pannes est effectuée en corrélant toutes les pannes. Par exemple, si l'erreur PUNT_FABRIC_DATA_PATH_FAILED et l'erreur LC_NP_LOOPBACK_FAILED se produisent sur NP0, alors NP a arrêté de traiter les paquets. Référez-vous à la section Chemin de diagnostic de bouclage NP afin de comprendre l'erreur de bouclage. Cela pourrait être une indication précoce d'une défaillance critique à l'intérieur de NP0. Cependant, si une seule des deux défaillances se produit, la défaillance est localisée soit sur le chemin de données de matrice de points, soit sur le CPU de la carte de ligne vers le chemin NP.
Si plusieurs interfaces de réseau sur une carte de ligne présentent un défaut de chemin de données de matrice de points, vous devez remonter le chemin d'arborescence des liaisons de matrice afin d'isoler un composant défectueux. Par exemple, si NP0 et NP1 ont tous deux une défaillance, la défaillance doit être dans B0 ou la liaison qui connecte B0 et FIA0. Il est moins probable que NP0 et NP1 rencontrent une erreur interne critique en même temps. Bien que cela soit moins probable, il est possible que NP0 et NP1 rencontrent une erreur critique due au traitement incorrect d’un type particulier de paquet ou d’un paquet défectueux.
Les deux cartes processeur de routage signalent une défaillance
Si les cartes processeur de routage actives et de secours signalent une défaillance à un ou plusieurs processeurs réseau sur une carte de ligne, vérifiez tous les composants et liaisons communs sur le chemin de données entre les processeurs réseau affectés et les deux cartes processeur de routage.
Échec du diagnostic NP1
Ce schéma décrit le chemin des paquets entre la carte processeur de routage CPU et la carte de ligne NP1. La liaison qui connecte le pont ASIC 0 (B0) et NP1 est la seule liaison spécifique à NP1. Tous les autres liens se trouvent sur le chemin commun.
Notez le chemin du paquet de la carte processeur de routage vers NP1. Bien qu'il y ait quatre liaisons à utiliser pour les paquets destinés à NP0 à partir du processeur de routage, la première liaison entre le processeur de routage et le logement de carte de ligne est utilisée pour le paquet à partir du processeur de routage vers la carte de ligne. Le paquet renvoyé par NP1 peut être renvoyé au processeur de routage actif par l’un des deux chemins de liaison de fabric entre le logement de carte de ligne et le processeur de routage actif. Le choix de l’une des deux liaisons à utiliser dépend de la charge de la liaison à ce moment. Le paquet de réponse de NP1 vers le processeur de routage de secours utilise les deux liaisons, mais une liaison à la fois. Le choix de la liaison est basé sur le champ d'en-tête que l'application de diagnostic remplit.
Chemin de diagnostic du fabric
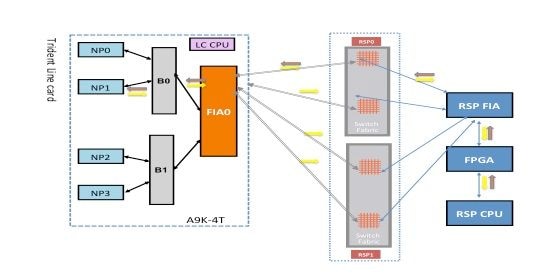
Analyse des défaillances de diagnostic NP1
Reportez-vous à la section Analyse des défaillances de diagnostic NP0, mais appliquez le même raisonnement pour NP1 (au lieu de NP0).
Échec du diagnostic NP2
Ce schéma décrit le chemin des paquets entre la carte processeur de routage CPU et la carte de ligne NP2. La liaison reliant B1 et NP2 est la seule liaison spécifique à NP2. Tous les autres liens se trouvent sur le chemin commun.
Notez le chemin du paquet de la carte processeur de routage vers NP2. Bien qu'il y ait quatre liaisons à utiliser pour les paquets destinés à NP2 à partir du processeur de routage, la première liaison entre le processeur de routage et le logement de carte de ligne est utilisée pour le paquet à partir du processeur de routage vers la carte de ligne. Le paquet renvoyé par NP2 peut être renvoyé au processeur de routage actif par l'un des deux chemins de liaison de fabric entre le logement de carte de ligne et le processeur de routage actif. Le choix de l’une des deux liaisons à utiliser dépend de la charge de la liaison à ce moment. Le paquet de réponse de NP2 vers le processeur de routage de secours utilise les deux liaisons, mais une liaison à la fois. Le choix de la liaison est basé sur le champ d'en-tête que l'application de diagnostic remplit.
Chemin de diagnostic du fabric
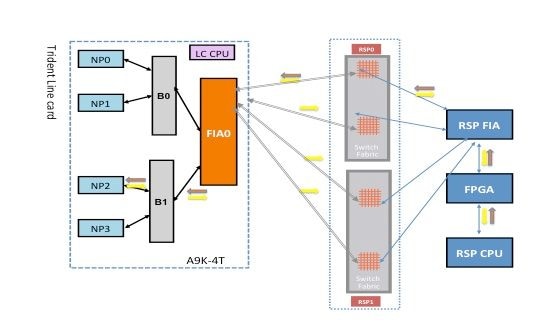
Analyse des défaillances de diagnostic NP2
Reportez-vous à la section Analyse des défaillances de diagnostic NP0, mais appliquez le même raisonnement pour NP2 (au lieu de NP0).
Échec du diagnostic NP3
Ce schéma décrit le chemin des paquets entre la carte processeur de routage CPU et la carte de ligne NP3. La liaison qui connecte le pont ASIC 1 (B1) et NP3 est la seule liaison spécifique à NP3. Tous les autres liens se trouvent sur le chemin commun.
Notez le chemin du paquet de la carte processeur de routage vers NP3. Bien qu'il y ait quatre liaisons à utiliser pour les paquets destinés à NP3 à partir du processeur de routage, la première liaison entre le processeur de routage et le logement de carte de ligne est utilisée pour le paquet à partir du processeur de routage vers la carte de ligne. Le paquet renvoyé par NP3 peut être renvoyé au processeur de routage actif par l’un des deux chemins de liaison de fabric entre le logement de carte de ligne et le processeur de routage actif. Le choix de l’une des deux liaisons à utiliser dépend de la charge de la liaison à ce moment. Le paquet de réponse de NP3 vers le processeur de routage de secours utilise les deux liaisons, mais une liaison à la fois. Le choix de la liaison est basé sur le champ d'en-tête que l'application de diagnostic remplit.
Chemin de diagnostic du fabric
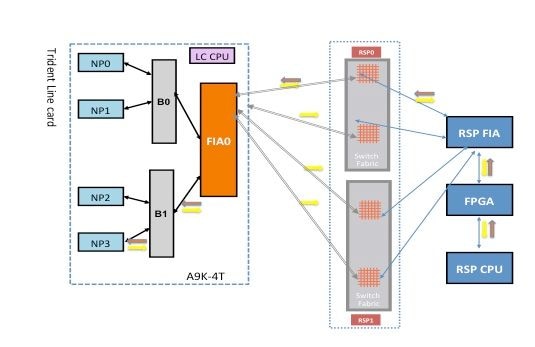
Analyse des défaillances de diagnostic NP3
Reportez-vous à la section Analyse des défaillances de diagnostic NP0, mais appliquez le même raisonnement pour NP3 (au lieu de NP0).
Chemin des paquets de diagnostic de carte de ligne basé sur un typhon
Cette section fournit deux exemples afin d'établir l'arrière-plan pour les paquets de matrice avec des cartes de ligne basées sur Typhoon. Le premier exemple utilise NP1 et le deuxième exemple utilise NP3. La description et l'analyse peuvent être étendues à d'autres cartes de ligne basées sur Typhoon.
Échec du diagnostic du typhon NP1
Le schéma suivant décrit le chemin de paquets entre la carte processeur de routage CPU et la carte de ligne NP1. La liaison qui relie FIA0 et NP1 est la seule liaison spécifique au chemin NP1. Toutes les autres liaisons entre le logement de carte de ligne et le logement de carte de processeur de routage se trouvent sur le chemin commun. Les liaisons qui relient le circuit ASIC XBAR de fabric de la carte de ligne aux interfaces FIA de la carte de ligne sont spécifiques à un sous-ensemble d'interfaces réseau. Par exemple, les deux liaisons entre FIA0 et le fabric local XBAR ASIC sur la carte de ligne sont utilisées pour le trafic vers NP1.
Notez le chemin du paquet de la carte processeur de routage vers NP1. Bien qu'il y ait huit liaisons à utiliser pour les paquets destinés à NP1 à partir de la carte processeur de routage, un seul chemin entre la carte processeur de routage et le logement de carte de ligne est utilisé. Le paquet renvoyé par NP1 peut être renvoyé à la carte processeur de routage par huit chemins de liaison de fabric entre le logement de carte de ligne et le processeur de routage. Chacune de ces huit liaisons est exercée une par une lorsque le paquet de diagnostic est destiné à la carte processeur de routage CPU.
Chemin de diagnostic du fabric
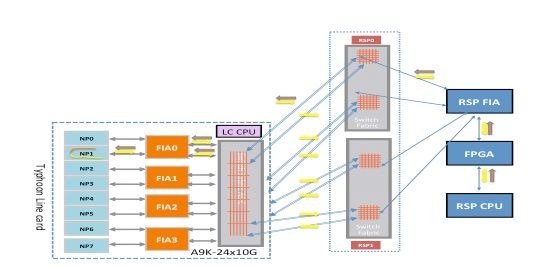
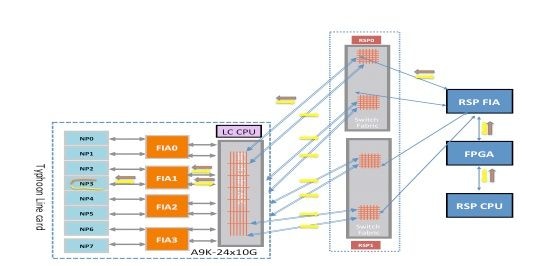
Échec du diagnostic du typhon NP3
Ce schéma décrit le chemin des paquets entre la carte processeur de routage CPU et la carte de ligne NP3. La liaison qui relie FIA1 et NP3 est la seule liaison spécifique au chemin NP3. Toutes les autres liaisons entre le logement de carte de ligne et le logement de carte de processeur de routage se trouvent sur le chemin commun. Les liaisons qui relient le circuit ASIC XBAR de fabric de la carte de ligne aux interfaces FIA de la carte de ligne sont spécifiques à un sous-ensemble d'interfaces réseau. Par exemple, les deux liaisons entre FIA1 et le fabric local XBAR ASIC sur la carte de ligne sont utilisées pour le trafic vers NP3.
Notez le chemin du paquet de la carte processeur de routage vers NP3. Bien qu'il y ait huit liaisons à utiliser pour les paquets destinés à NP3 à partir de la carte processeur de routage, un seul chemin entre la carte processeur de routage et le logement de carte de ligne est utilisé. Le paquet renvoyé par NP1 peut être renvoyé à la carte processeur de routage par huit chemins de liaison de fabric entre le logement de carte de ligne et le processeur de routage. Chacune de ces huit liaisons est exercée une par une lorsque le paquet de diagnostic est destiné à la carte processeur de routage CPU.
Chemin de diagnostic du fabric
Chemin des paquets de diagnostic de carte de ligne Tomahawk
En raison de la connectivité 1:1 entre le FIA et le NP, le seul trafic qui traverse le FIA0 est vers/depuis le NP0.
Chemin des paquets de diagnostic des cartes de ligne basé sur Lightspeed et LightspeedPlus
Comme le FIA est intégré à la puce NP, le seul trafic qui traverse FIA0 est vers/depuis NP0.
Analyser les pannes
Cette section catégorise les pannes en cas de défaillance matérielle et transitoire, et répertorie les étapes utilisées afin d'identifier si une défaillance est une défaillance matérielle ou transitoire. Une fois le type de panne déterminé, le document spécifie les commandes qui peuvent être exécutées sur le routeur afin de comprendre la panne et les actions correctives nécessaires.
Défaillance Passagère
Si un message PFM défini est suivi d'un message PFM clair, une erreur s'est produite et le routeur a corrigé lui-même l'erreur. Des défaillances passagères peuvent se produire en raison des conditions environnementales et des défaillances récupérables dans les composants matériels. Parfois, il peut être difficile d'associer des pannes transitoires à un événement particulier.
Pour plus de clarté, vous trouverez ci-dessous un exemple de défaillance transitoire du fabric :
RP/0/RSP0/CPU0:Feb 5 05:05:44.051 : pfm_node_rp[354]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/2/CPU0, 0)
RP/0/RSP0/CPU0:Feb 5 05:05:46.051 : pfm_node_rp[354]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Clear|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/2/CPU0, 0)
Actions correctives temporaires contre les pannes
L'approche suggérée pour les erreurs transitoires consiste à surveiller uniquement la survenue ultérieure de telles erreurs. Si une panne transitoire se produit plusieurs fois, traitez la panne transitoire comme une panne dure et suivez les recommandations et les étapes pour analyser ces pannes décrites dans la section suivante.
Défaut Dur
Si un message PFM défini n'est pas suivi d'un message PFM clair, cela signifie qu'une erreur s'est produite et que le routeur n'a pas corrigé l'erreur lui-même à l'aide du code de gestion des erreurs, ou que la nature de l'erreur matérielle n'est pas récupérable. Des défaillances matérielles peuvent se produire en raison de conditions environnementales et de défaillances irrécupérables dans les composants matériels. L'approche suggérée pour les défaillances matérielles consiste à utiliser les directives mentionnées dans la section Analyser les défaillances matérielles.
Un exemple de défaillance du fabric dur est répertorié ici pour plus de clarté. Pour cet exemple de message, il n'y a pas de message Clear PFM correspondant.
RP/0/RSP0/CPU0:Feb 5 05:05:44.051 : pfm_node_rp[354]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/2/CPU0, 0)
Mesures correctives pour les défaillances matérielles
Dans un scénario de panne matérielle, collectez toutes les commandes mentionnées dans la section Données à collecter avant la création de la demande de service, et ouvrez une demande de service. En cas d'urgence, après avoir collecté toutes les informations affichées par la commande de dépannage, lancez une carte processeur de routage ou un rechargement de carte de ligne en fonction de l'isolation des pannes. Après le rechargement, si l'erreur n'est pas récupérée, lancez une autorisation de retour de matériel (RMA).
Analyser les défaillances passagères
Complétez ces étapes afin d'analyser les pannes transitoires.
- Saisissez la commande
show logging | inc “PUNT_FABRIC_DATA_PATH"afin de découvrir si l'erreur s'est produite une ou plusieurs fois. - Saisissez la commande
show pfm location allafin de déterminer l'état actuel (SET ou CLEAR). L'erreur est-elle en suspens ou effacée ? Si l'état de l'erreur change entre SET et CLEAR, une ou plusieurs défaillances dans le chemin de données du fabric se produisent de manière répétée et sont corrigées par le logiciel ou le matériel. - Configurez des déroutements SNMP (Simple Network Management Protocol) ou exécutez un script qui collecte
show pfm location allet recherche régulièrement la chaîne d'erreur afin de surveiller l'occurrence future de l'erreur (lorsque le dernier état de l'erreur est CLEAR et qu'aucune nouvelle erreur ne se produit).
Commandes à utiliser
Entrez ces commandes afin d'analyser les pannes transitoires :
show logging | inc “PUNT_FABRIC_DATA_PATH”show pfm location all
Analyser les défaillances matérielles
Si vous affichez les liaisons de chemin de données de fabric sur une carte de ligne sous la forme d'une arborescence (où les détails sont décrits dans la section Informations de fond), vous devez alors déduire, en fonction du point de défaillance, si un ou plusieurs NP sont inaccessibles. Lorsque plusieurs pannes se produisent sur plusieurs processeurs réseau, utilisez les commandes répertoriées dans cette section afin d'analyser les pannes.
Commandes à utiliser
Entrez ces commandes afin d'analyser les pannes matérielles :
show logging | inc “PUNT_FABRIC_DATA_PATH”
La sortie peut contenir un ou plusieurs NP (par exemple : NP2, NP3).show controller fabric fia link-status location
Comme le NP2 et le NP3 (dans la section Défaillance du diagnostic du typhon NP3) reçoivent et envoient des données par le biais d'un seul FIA, il est raisonnable de déduire que la défaillance se situe dans un FIA associé sur le chemin.show controller fabric crossbar link-status instance <0 and 1> location
Si tous les processeurs réseau de la carte de ligne ne sont pas accessibles pour l'application de diagnostic, il est raisonnable de déduire que les liaisons qui connectent le logement de carte de ligne à la carte processeur de routage peuvent présenter une défaillance sur l'un des circuits ASIC qui transfèrent le trafic entre la carte processeur de routage et la carte de ligne.show controller fabric crossbar link-status instance 0 locationshow controller fabric crossbar link-status instance 0 location 0/rsp0/cpu0show controller fabric crossbar link-status instance 1 location 0/rsp0/cpu0show controller fabric crossbar link-status instance 0 location 0/rsp1/cpu0show controller fabric crossbar link-status instance 1 location 0/rsp1/cpu0show controller fabric fia link-status location 0/rsp*/cpu0show controller fabric fia link-status location 0/rsp0/cpu0show controller fabric fia link-status location 0/rsp1/cpu0show controller fabric fia bridge sync-status location 0/rsp*/cpu0show controller fabric fia bridge sync-status location 0/rsp0/cpu0show controller fabric fia bridge sync-status location 0/rsp1/cpu0show tech fabric terminal
Remarque : si tous les processeurs réseau de toutes les cartes de ligne signalent une défaillance, celle-ci se produit très probablement sur la carte processeur de routage (carte processeur de routage active ou carte processeur de routage de secours). Reportez-vous au lien qui connecte le processeur de la carte processeur de routage au FPGA et à la carte processeur de routage FIA dans la section Background Information.
Échecs passés
Historiquement, 99 % des pannes sont récupérables et, dans la plupart des cas, l'action de récupération déclenchée par le logiciel corrige les pannes. Cependant, dans de très rares cas, des erreurs irrécupérables ne peuvent être corrigées qu'avec la RMA des cartes.
Les sections suivantes identifient certaines erreurs passées rencontrées afin de servir de guide si des erreurs similaires sont observées.
Erreur passagère due à une sursouscription NP
Ces messages s'affichent si l'erreur est due à une sursouscription NP.
RP/0/RP1/CPU0:Jun 26 13:08:28.669 : pfm_node_rp[349]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[200823]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/10/CPU0, 0)
RP/0/RP1/CPU0:Jun 26 13:09:28.692 : pfm_node_rp[349]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Clear|online_diag_rsp[200823]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/10/CPU0,0)
Les pannes transitoires peuvent être plus difficiles à confirmer. Une méthode pour déterminer si un NP est actuellement en sursouscription ou a été en sursouscription dans le passé consiste à rechercher un certain type de chute à l'intérieur du NP et des chutes de queue dans la FIA. Les pertes d'accès direct à la mémoire frontale en entrée (IFDMA) dans le NP se produisent lorsque le NP est surabonné et ne peut pas suivre le trafic entrant. Les pertes de queue FIA se produisent lorsqu'un processeur réseau de sortie active le contrôle de flux (demande à la carte de ligne d'entrée d'envoyer moins de trafic). Dans le scénario de contrôle de flux, la FIA d'entrée a des baisses de queue.
Voici un exemple :
RP/0/RSP0/CPU0:RP/0/RSP0/CPU0:ASR9006-C#show controllers np counters all
Wed Feb 19 13:10:11.848 EST
Node: 0/1/CPU0:
----------------------------------------------------------------
Show global stats counters for NP0, revision v3
Read 93 non-zero NP counters:
Offset Counter FrameValue Rate (pps)
-----------------------------------------------------------------------
22 PARSE_ENET_RECEIVE_CNT 46913080435 118335
23 PARSE_FABRIC_RECEIVE_CNT 40175773071 5
24 PARSE_LOOPBACK_RECEIVE_CNT 5198971143966 0
<SNIP>
Show special stats counters for NP0, revision v3
Offset Counter CounterValue
----------------------------------------------------------------------------
524032 IFDMA discard stats counters 0 8008746088 0 <<<<<
Voici un exemple :
RP/0/RSP0/CPU0:ASR9006-C#show controllers fabric fia drops ingress location 0/1/cPU0
Wed Feb 19 13:37:27.159 EST
********** FIA-0 **********
Category: in_drop-0
DDR Rx FIFO-0 0
DDR Rx FIFO-1 0
Tail Drop-0 0 <<<<<<<
Tail Drop-1 0 <<<<<<<
Tail Drop-2 0 <<<<<<<
Tail Drop-3 0 <<<<<<<
Tail Drop DE-0 0
Tail Drop DE-1 0
Tail Drop DE-2 0
Tail Drop DE-3 0
Hard Drop-0 0
Hard Drop-1 0
Hard Drop-2 0
Hard Drop-3 0
Hard Drop DE-0 0
Hard Drop DE-1 0
Hard Drop DE-2 0
Hard Drop DE-3 0
WRED Drop-0 0
WRED Drop-1 0
WRED Drop-2 0
WRED Drop-3 0
WRED Drop DE-0 0
WRED Drop DE-1 0
WRED Drop DE-2 0
WRED Drop DE-3 0
Mc No Rep 0
Erreur matérielle due à la réinitialisation rapide NP
Lorsque PUNT_FABRIC_DATA_PATH_FAILED se produit, et si la panne est due à la réinitialisation rapide NP, des journaux similaires à ceux répertoriés ici apparaissent pour une carte de ligne basée sur Typhoon. Le mécanisme de surveillance de la santé est disponible sur les cartes de ligne Typhoon, mais pas sur les cartes de ligne Trident.
LC/0/2/CPU0:Aug 26 12:09:15.784 CEST: prm_server_ty[303]:
prm_inject_health_mon_pkt : Error injecting health packet for NP0
status = 0x80001702
LC/0/2/CPU0:Aug 26 12:09:18.798 CEST: prm_server_ty[303]:
prm_inject_health_mon_pkt : Error injecting health packet for NP0
status = 0x80001702
LC/0/2/CPU0:Aug 26 12:09:21.812 CEST: prm_server_ty[303]:
prm_inject_health_mon_pkt : Error injecting health packet for NP0
status = 0x80001702
LC/0/2/CPU0:Aug 26 12:09:24.815 CEST:
prm_server_ty[303]: NP-DIAG health monitoring failure on NP0
LC/0/2/CPU0:Aug 26 12:09:24.815 CEST: pfm_node_lc[291]:
%PLATFORM-NP-0-NP_DIAG : Set|prm_server_ty[172112]|
Network Processor Unit(0x1008000)| NP diagnostics warning on NP0.
LC/0/2/CPU0:Aug 26 12:09:40.492 CEST: prm_server_ty[303]:
Starting fast reset for NP 0 LC/0/2/CPU0:Aug 26 12:09:40.524 CEST:
prm_server_ty[303]: Fast Reset NP0 - successful auto-recovery of NP
Pour les cartes de ligne Trident, ce journal est vu avec une réinitialisation rapide d'un NP :
LC/0/1/CPU0:Mar 29 15:27:43.787 test:
pfm_node_lc[279]: Fast Reset initiated on NP3
Défaillances entre les processeurs de routage RSP440 et les cartes de ligne Typhoon
Cisco a résolu un problème où les liaisons de fabric entre le processeur RSP 440 et les cartes de ligne basées sur le typhon sur le fond de panier sont rarement reformées. Les liaisons de matrice sont réentraînées, car la puissance du signal n'est pas optimale. Ce problème est présent dans les versions de base du logiciel Cisco IOS® XR 4.2.1, 4.2.2, 4.2.3, 4.3.0, 4.3.1 et 4.3.2. Une mise à jour de maintenance logicielle (SMU) pour chacune de ces versions est publiée sur Cisco Connection Online et suivie avec l'ID de bogue Cisco CSCuj10837 et l'ID de bogue Cisco CSCul39674.
Lorsque ce problème se produit sur le routeur, l'un des scénarios suivants peut se produire :
- La liaison s’arrête et s’active. (transitoire)
- La liaison est désactivée en permanence.
ID de bogue Cisco CSCuj10837 - Reformation de fabric entre RSP et LC (direction TX)
Afin de confirmer, collectez les sorties ltrace de LC et des deux RSP (show controller fabric crossbar ltrace location <>) et vérifiez si cette sortie est visible dans les traces RSP :
SMU est déjà disponible
Voici un exemple :
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Oct 1 08:22:58.999 crossbar 0/RSP1/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (1,1,0),(2,1,0),1.
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Oct 1 08:22:58.967 crossbar 0/0/CPU0 t1 init xbar_trigger_link_retrain:
destslot:0 fmlgrp:3 rc:0
Oct 1 08:22:58.967 crossbar 0/0/CPU0 t1 detail xbar_pfm_alarm_callback:
xbar_trigger_link_retrain(): (2,0,7) initiated
Oct 1 08:22:58.969 crossbar 0/0/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (2,1,0),(2,2,0),0.
Le terme direction TX fait référence à la direction du point de vue de l'interface de structure transversale RSP vers une interface de structure transversale sur une carte de ligne basée sur Typhoon.
L'ID de bogue Cisco CSCuj10837 est caractérisé par la détection par la carte de ligne Typhoon d'un problème sur la liaison RX à partir du RSP et l'initiation d'une remise à niveau de liaison. L'un ou l'autre côté (LC ou RSP) peut initier l'événement de recyclage. Dans le cas de l'ID de bogue Cisco CSCuj10837, le LC initie la reformation et peut être détecté par le message init xbar_trigger_link_retrain: dans les traces sur le LC.
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Oct 1 08:22:58.967 crossbar 0/0/CPU0 t1 init xbar_trigger_link_retrain: destslot:
0 fmlgrp:3 rc:0
Lorsque le LC initie le retrain, le RSP signale un rcvd link_retrain dans la sortie de trace.
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Oct 1 08:22:58.999 crossbar 0/RSP1/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (1,1,0),(2,1,0),1.
ID de bogue Cisco CSCul39674 - Reformation de fabric entre RSP et LC (direction RX)
Afin de confirmer, collectez les sorties ltrace de la carte de ligne et des deux RSP (show controller fabric crossbar ltrace location <>) et vérifiez si cette sortie est visible dans les traces RSP :
Voici un exemple :
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Jan 8 17:28:39.215 crossbar 0/0/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (0,1,0),(5,1,1),0.
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Jan 8 17:28:39.207 crossbar 0/RSP1/CPU0 t1 init xbar_trigger_link_retrain:
destslot:4 fmlgrp:3 rc:0
Jan 8 17:28:39.207 crossbar 0/RSP1/CPU0 t1 detail xbar_pfm_alarm_callback:
xbar_trigger_link_retrain(): (5,1,11) initiated
Jan 8 17:28:39.256 crossbar 0/RSP1/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (5,1,1),(0,1,0),0.
Le terme direction RX fait référence à la direction du point de vue de l'interface de structure à barres croisées RSP à partir d'une interface à barres croisées de structure sur une carte de ligne basée sur Typhoon.
L'ID de bogue Cisco CSCul39674 est caractérisé par la détection par le RSP d'un problème sur la liaison RX à partir de la carte de ligne Typhoon et l'initiation d'une remise à niveau de liaison. L'un ou l'autre côté (LC ou RSP) peut initier l'événement de recyclage. Dans le cas de l'ID de bogue Cisco CSCul39674, le RSP initie la reformation et peut être détecté par le message init xbar_trigger_link_retrain: dans les traces sur le RSP.
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Jan 8 17:28:39.207 crossbar 0/RSP1/CPU0 t1 init xbar_trigger_link_retrain: destslot:4 fmlgrp:
3 rc:0
Lorsque le RSP initie la reformation, le LC signale un événement rcvd link_retrain dans la sortie de trace.
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Jan 8 17:28:39.215 crossbar 0/0/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (0,1,0),(5,1,1),0.
Différences de recyclage de fabric dans les versions 4.3.2 et ultérieures
Un travail important a été effectué afin de réduire le temps nécessaire pour recycler une liaison de fabric dans Cisco IOS XR version 4.3.2 et ultérieure. Le recyclage du fabric se produit désormais en moins d'une seconde et est imperceptible aux flux de trafic. Dans Cisco IOS XR version 4.3.2, seuls ces messages syslog sont visibles lorsqu'une nouvelle formation de la liaison de fabric s'est produite.
%PLATFORM-FABMGR-5-FABRIC_TRANSIENT_FAULT : Fabric backplane crossbar link
underwent link retraining to recover from a transient error: Physical slot 1
Défaillance due au dépassement FIFO ASIC du fabric
Cisco a résolu un problème où l'ASIC de fabric (FIA) pouvait être réinitialisé en raison d'une condition de débordement FIFO (First In First Out) irrécupérable. Le bogue Cisco ayant l'ID CSCul66510 permet de résoudre ce problème. Ce problème n'affecte que les cartes de ligne Trident et n'est rencontré que dans de rares cas avec un encombrement important du chemin d'entrée. Si ce problème se produit, ce message syslog s'affiche avant que la carte de ligne ne soit réinitialisée pour récupérer de l'état.
RP/0/RSP0/CPU0:asr9k-2#show log
LC/0/3/CPU0:Nov 13 03:46:38.860 utc: pfm_node_lc[284]:
%FABRIC-FIA-0-ASIC_FATAL_FAULT Set|fialc[159814]
|Fabric Interface(0x1014000)|Fabric interface asic ASIC1 encountered fatal
fault 0x1b - OC_DF_INT_PROT_ERR_0
LC/0/3/CPU0:Nov 13 03:46:38.863 utc: pfm_node_lc[284]:
%PLATFORM-PFM-0-CARD_RESET_REQ : pfm_dev_sm_perform_recovery_action,
Card reset requested by: Process ID:159814 (fialc), Fault Sev: 0, Target node:
0/3/CPU0, CompId: 0x10, Device Handle: 0x1014000, CondID: 2545, Fault Reason:
Fabric interface asic ASIC1 encountered fatal fault 0x1b - OC_DF_INT_PROT_ERR_0
Défaillance due à l'accumulation d'une file d'attente de sortie virtuelle (VOQ) importante due à l'encombrement du fabric
Cisco a résolu un problème où un encombrement important prolongé pouvait entraîner l'épuisement des ressources du fabric et une perte de trafic. La perte de trafic peut même se produire sur des flux non liés. Ce problème est résolu avec l'ID de bogue Cisco CSCug90300 et est résolu dans Cisco IOS XR version 4.3.2 et ultérieure. Le correctif est également fourni dans Cisco IOS XR version 4.2.3 CSMU#3, ID de bogue Cisco CSCui3805. Ce problème rare peut être rencontré sur les cartes de ligne Trident ou Typhoon.
Commandes pertinentes
Collectez le résultat de ces commandes :
show tech-support fabricshow controller fabric fia bridge flow-control location<=== Obtenir ce résultat pour tous les LCshow controllers fabric fia q-depth location
Voici quelques exemples de résultats :
RP/0/RSP0/CPU0:asr9k-1#show controllers fabric fia q-depth location 0/6/CPU0
Sun Dec 29 23:10:56.307 UTC
********** FIA-0 **********
Category: q_stats_a-0
Voq ddr pri pktcnt
11 0 2 7
********** FIA-0 **********
Category: q_stats_b-0
Voq ddr pri pktcnt
********** FIA-1 **********
Category: q_stats_a-1
Voq ddr pri pktcnt
11 0 0 2491
11 0 2 5701
********** FIA-1 **********
Category: q_stats_b-1
Voq ddr pri pktcnt
RP/0/RSP0/CPU0:asr9k-1#
RP/0/RSP0/CPU0:asr9k-1#show controllers pm location 0/1/CPU0 | in "switch|if"
Sun Dec 29 23:37:05.621 UTC
Ifname(2): TenGigE0_1_0_2, ifh: 0x2000200 : <==Corresponding interface ten 0/1/0/2
iftype 0x1e
switch_fabric_port 0xb <==== VQI 11
parent_ifh 0x0
parent_bundle_ifh 0x80009e0
RP/0/RSP0/CPU0:asr9k-1#
Dans des conditions normales, il est très peu probable de voir une VOQ avec des paquets mis en file d'attente. Cette commande est un instantané rapide en temps réel des files d'attente FIA. Il est courant que cette commande n'affiche aucun paquet mis en file d'attente.
Impact du trafic dû à des erreurs logicielles Bridge/FPGA sur les cartes de ligne Trident
Les erreurs logicielles sont des erreurs non permanentes qui entraînent une désynchronisation de l'ordinateur d'état. Ces paquets sont considérés comme des paquets CRC (Cyclic Redundancy Check), FCS (Frame Check Sequence) ou en erreur sur le côté fabric du processeur réseau ou sur le côté entrée du FIA.
Voici quelques exemples de la façon dont ce problème peut être vu :
RP/0/RSP0/CPU0:asr9k-1#show controllers fabric fia drops ingress location 0/3/CPU0
Fri Dec 6 19:50:42.135 UTC
********** FIA-0 **********
Category: in_drop-0
DDR Rx FIFO-0 0
DDR Rx FIFO-1 32609856 <=== Errors
RP/0/RSP0/CPU0:asr9k-1#show controllers fabric fia errors ingress location 0/3/CPU0
Fri Dec 6 19:50:48.934 UTC
********** FIA-0 **********
Category: in_error-0
DDR Rx CRC-0 0
DDR Rx CRC-1 32616455 <=== Errors
RP/0/RSP1/CPU0:asr9k-1#show controllers fabric fia bridge stats location 0/0/CPU0
Ingress Drop Stats (MC & UC combined)
**************************************
PriorityPacket Error Threshold
Direction Drops Drops
--------------------------------------------------
LP NP-3 to Fabric 0 0
HP NP-3 to Fabric 1750 0
RP/0/RSP1/CPU0:asr9k-1#
RP/0/RSP1/CPU0:asr9k-1#show controllers fabric fia bridge stats location 0/6/CPU0
Sat Jan 4 06:33:41.392 CST
********** FIA-0 **********
Category: bridge_in-0
UcH Fr Np-0 16867506
UcH Fr Np-1 115685
UcH Fr Np-2 104891
UcH Fr Np-3 105103
UcL Fr Np-0 1482833391
UcL Fr Np-1 31852547525
UcL Fr Np-2 3038838776
UcL Fr Np-3 30863851758
McH Fr Np-0 194999
McH Fr Np-1 793098
McH Fr Np-2 345046
McH Fr Np-3 453957
McL Fr Np-0 27567869
McL Fr Np-1 12613863
McL Fr Np-2 663139
McL Fr Np-3 21276923
Hp ErrFrNp-0 0
Hp ErrFrNp-1 0
Hp ErrFrNp-2 0
Hp ErrFrNp-3 0
Lp ErrFrNp-0 0
Lp ErrFrNp-1 0
Lp ErrFrNp-2 0
Lp ErrFrNp-3 0
Hp ThrFrNp-0 0
Hp ThrFrNp-1 0
Hp ThrFrNp-2 0
Hp ThrFrNp-3 0
Lp ThrFrNp-0 0
Lp ThrFrNp-1 0
Lp ThrFrNp-2 0
Lp ThrFrNp-3 0
********** FIA-0 **********
Category: bridge_eg-0
UcH to Np-0 779765
UcH to Np-1 3744578
UcH to Np-2 946908
UcH to Np-3 9764723
UcL to Np-0 1522490680
UcL to Np-1 32717279812
UcL to Np-2 3117563988
UcL to Np-3 29201555584
UcH ErrToNp-0 0
UcH ErrToNp-1 0
UcH ErrToNp-2 129 <==============
UcH ErrToNp-3 0
UcL ErrToNp-0 0
UcL ErrToNp-1 0
UcL ErrToNp-2 90359 <==========
Commandes à collecter pour les erreurs logicielles Bridge/FPGA sur les cartes de ligne Trident
Collectez le résultat de ces commandes :
show tech-support fabricshow tech-support npshow controller fabric fia bridge stats location <>(obtenir plusieurs fois)
Récupération après erreurs logicielles Bridge/FPGA
La méthode de récupération consiste à recharger la carte de ligne concernée.
RP/0/RSP0/CPU0:asr9k-1#hw-module location 0/6/cpu0 reload
Rapport de test de diagnostic en ligne
Les show diagnostic result location
fournit un résumé de tous les tests de diagnostic et échecs en ligne, ainsi que l'horodatage de la dernière fois qu'un test a réussi. L'ID de test de l'échec du chemin de données de matrice de points est 10. Une liste de tous les tests ainsi que la fréquence des paquets de test peuvent être vus avec le show diagnostic content location
erasecat4000_flash:.
Le résultat du test du chemin de données de matrice de points est similaire à l'exemple suivant :
RP/0/RSP0/CPU0:ios(admin)#show diagnostic result location 0/rsp0/cpu0 test 10 detail
Current bootup diagnostic level for RP 0/RSP0/CPU0: minimal
Test results: (. = Pass, F = Fail, U = Untested)
___________________________________________________________________________
10 ) FabricLoopback ------------------> .
Error code ------------------> 0 (DIAG_SUCCESS)
Total run count -------------> 357
Last test execution time ----> Sat Jan 10 18:55:46 2009
First test failure time -----> n/a
Last test failure time ------> n/a
Last test pass time ---------> Sat Jan 10 18:55:46 2009
Total failure count ---------> 0
Consecutive failure count ---> 0
Améliorations de la récupération automatique
Comme décrit dans l'ID de bogue Cisco CSCuc0493, il y a maintenant un moyen pour que le routeur arrête automatiquement tous les ports qui sont associés aux erreurs PUNT_FABRIC_DATA_PATH déclenchées sur le RP/RSP actif.
La première méthode est suivie via l'ID de bogue Cisco CSCuc04493. Pour la version 4.2.3, ceci est inclus dans l'ID de bogue Cisco CSCui3805. Dans cette version, il est configuré pour arrêter automatiquement tous les ports qui sont associés aux NP qui sont affectés.
Voici un exemple qui montre comment les syslogs apparaîtraient :
RP/0/RSP0/CPU0:Jun 10 16:11:26 BKK: pfm_node_rp[359]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|System
Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP) failed:
(0/1/CPU0, 0)
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINK-3-UPDOWN : Interface
TenGigE0/1/0/0, changed state to Down
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINEPROTO-5-UPDOWN : Line
protocol on Interface TenGigE0/1/0/0, changed state to Down
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINK-3-UPDOWN : Interface
TenGigE0/1/0/1, changed state to Down
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINEPROTO-5-UPDOWN : Line
protocol on Interface TenGigE0/1/0/1, changed state to Down
Le contrôleur indique que la raison de l'arrêt de l'interface est due à DATA_PATH_DOWN. Voici un exemple :
RP/0/RSP0/CPU0:ASR9006-E#show controllers gigabitEthernet 0/0/0/13 internal
Wed Dec 18 02:42:52.221 UTC
Port Number : 13
Port Type : GE
Transport mode : LAN
BIA MAC addr : 6c9c.ed08.3cbd
Oper. MAC addr : 6c9c.ed08.3cbd
Egress MAC addr : 6c9c.ed08.3cbd
Port Available : true
Status polling is : enabled
Status events are : enabled
I/F Handle : 0x04000400
Cfg Link Enabled : tx/rx enabled
H/W Tx Enable : no
UDLF enabled : no
SFP PWR DN Reason : 0x00000000
SFP Capability : 0x00000024
MTU : 1538
H/W Speed : 1 Gbps
H/W Duplex : Full
H/W Loopback Type : None
H/W FlowCtrl type : None
H/W AutoNeg Enable: Off
H/W Link Defects : (0x00080000) DATA_PATH_DOWN <<<<<<<<<<<
Link Up : no
Link Led Status : Link down -- Red
Input good underflow : 0
Input ucast underflow : 0
Output ucast underflow : 0
Input unknown opcode underflow: 0
Pluggable Present : yes
Pluggable Type : 1000BASE-LX
Pluggable Compl. : (Service Un) - Compliant
Pluggable Type Supp.: (Service Un) - Supported
Pluggable PID Supp. : (Service Un) - Supported
Pluggable Scan Flg: false
Dans les versions 4.3.1 et ultérieures, ce comportement doit être activé. Pour ce faire, une nouvelle commande admin-config est utilisée. Comme le comportement par défaut n'est plus d'arrêter les ports, cela doit être configuré manuellement.
RP/0/RSP1/CPU0:ASR9010-A(admin-config)#fault-manager datapath port ?
shutdown Enable auto shutdown
toggle Enable auto toggle port status
Sur Cisco IOS XR 64 bits, la commande de configuration est disponible dans la machine virtuelle XR (et non dans la machine virtuelle Sysadmin) :
RP/0/RSP0/CPU0:CORE-TOP(config)#fault-manager datapath port ?
shutdown Enable auto shutdown
toggle Enable auto toggle port status
L'ID de bogue Cisco CSCui15435 résout les erreurs logicielles qui sont vues sur les cartes de ligne Trident, comme décrit dans la section Impact du trafic dû aux erreurs logicielles Bridge/FPGA sur les cartes de ligne Trident. Cette méthode utilise une méthode de détection différente de la méthode de diagnostic habituelle qui est décrite dans l'ID de bogue Cisco CSCuc0493.
Ce bogue a également introduit une nouvelle commande CLI admin-config :
(admin-config)#fabric fia soft-error-monitor <1|2> location
1 = shutdown the ports
2 = reload the linecard
Default behavior: no action is taken.
Lorsque cette erreur est rencontrée, ce syslog peut être observé :
RP/0/RSP0/CPU0:Apr 30 22:17:11.351 : config[65777]: %MGBL-SYS-5-CONFIG_I : Configured
from console by root
LC/0/2/CPU0:Apr 30 22:18:52.252 : pfm_node_lc[283]:
%PLATFORM-BRIDGE-1-SOFT_ERROR_ALERT_1 : Set|fialc[159814]|NPU
Crossbar Fabric Interface Bridge(0x1024000)|Soft Error Detected on Bridge instance 1
RP/0/RSP0/CPU0:Apr 30 22:21:28.747 : pfm_node_rp[348]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP) failed:
(0/2/CPU0, 2) (0/2/CPU0, 3)
LC/0/2/CPU0:Apr 30 22:21:29.707 : ifmgr[194]: %PKT_INFRA-LINK-3-UPDOWN :
Interface TenGigE0/2/0/2, changed state to Down
LC/0/2/CPU0:Apr 30 22:21:29.707 : ifmgr[194]: %PKT_INFRA-LINEPROTO-5-UPDOWN :
Line protocol on Interface TenGigE0/2/0/2, changed state to Down
RP/0/RSP1/CPU0:Apr 30 22:21:35.086 : pfm_node_rp[348]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED :
Set|online_diag_rsp[237646]|System Punt/Fabric/data Path Test(0x2000004)|failure
threshold is 3, (slot, NP) failed: (0/2/CPU0, 2) (0/2/CPU0, 3)
Lorsque les ports affectés sont arrêtés, la redondance du réseau prend le relais et évite un trou noir du trafic. Afin de récupérer, la carte de ligne doit être rechargée.
Foire aux questions (FAQ)
Q. La carte processeur de routage principale ou de secours envoie-t-elle les messages de test d'activité ou les paquets de diagnostic en ligne à chaque processeur réseau du système ?
R. Oui. Les deux cartes de processeur de routage envoient des paquets de diagnostic en ligne à chaque processeur réseau.
Q. Le chemin est-il le même lorsque la carte processeur de routage 1 (RSP1) est active ?
R. Le chemin de diagnostic est le même pour RSP0 ou RSP1. Le chemin dépend de l'état du RSP. Référez-vous à la section Chemin des paquets de diagnostic de matrice de points de ce document pour plus de détails.
Q. À quelle fréquence les RSP envoient-ils des paquets de diagnostic et combien de paquets de diagnostic doivent être manqués avant le déclenchement d’une alarme ?
R. Chaque RSP envoie indépendamment un paquet de diagnostic à chaque NP une fois par minute. Chaque RSP peut déclencher une alarme si trois paquets de diagnostic ne sont pas acquittés.
Q. Comment déterminez-vous si un NP est ou a été en sursouscription ?
R. Une façon de vérifier si un NP est actuellement en sursouscription ou a été en sursouscription dans le passé est de vérifier pour un certain type de chute à l'intérieur du NP et pour les chutes de queue dans la FIA. Les pertes d'accès direct à la mémoire frontale en entrée (IFDMA) dans le NP se produisent lorsque le NP est surabonné et ne peut pas suivre le trafic entrant. Les pertes de queue FIA se produisent lorsqu'un processeur réseau de sortie active le contrôle de flux (demande à la carte de ligne d'entrée d'envoyer moins de trafic). Dans le scénario de contrôle de flux, la FIA d'entrée a des baisses de queue.
Q. Comment déterminez-vous si un processeur réseau présente une défaillance qui nécessite sa réinitialisation ?
R. Généralement, une panne NP est résolue par une réinitialisation rapide. La raison d'une réinitialisation rapide est affichée dans les journaux.
Q. Est-il possible de réinitialiser manuellement un processeur réseau ?
R. Oui, de la carte de ligne KSH :
run attach 0/[x]/CPU0 #show_np -e [np#] -d fast_reset
Q. Qu'est-ce qui s'affiche si un processeur réseau présente une défaillance matérielle non récupérable ?
R. Vous constatez à la fois une défaillance du chemin de données de matrice punt pour ce NP et une défaillance du test de bouclage NP. Le message d'échec du test de bouclage NP est traité dans la section Annexe de ce document.
Q. Un paquet de diagnostic provenant d’une carte processeur de routage reviendra-t-il à la même carte ?
R. Étant donné que les paquets de diagnostic proviennent des deux cartes de processeur de routage et qu'ils sont suivis sur une base par carte de processeur de routage, un paquet de diagnostic provenant d'une carte de processeur de routage est rebouclé sur la même carte de processeur de routage par le processeur de routage.
Q. L'ID de bogue Cisco CSCuj10837 SMU fournit un correctif pour l'événement retrain de liaison de fabric. Est-ce la cause et la solution de nombreuses pannes de chemin de données de matrice ponctuelle ?
R. Oui, il est nécessaire de charger le SMU de remplacement pour l'ID de bogue Cisco CSCul39674 afin d'éviter les événements de recyclage de la liaison de fabric.
Q. Combien de temps faut-il pour recycler les liaisons de fabric une fois la décision prise ?
R. La décision de se recycler est prise dès qu'une défaillance de liaison est détectée. Avant la version 4.3.2, le recyclage pouvait prendre plusieurs secondes. Après la version 4.3.2, le temps de recyclage a été considérablement amélioré et prend moins d'une seconde.
Q. À quel moment la décision de recycler une liaison de fabric est-elle prise ?
R. Dès que le défaut de liaison est détecté, la décision de se recycler est prise par le pilote ASIC du fabric.
Q. Est-ce uniquement entre le FIA sur une carte de processeur de routage active et le fabric que vous utilisez la première liaison, et ensuite c'est la liaison la moins chargée quand il y a plusieurs liaisons disponibles ?
R. Correct. La première liaison qui se connecte à la première instance XBAR sur le processeur de routage actif est utilisée afin d'injecter le trafic dans le fabric. Le paquet de réponse du processeur réseau peut atteindre la carte processeur de routage active sur n'importe laquelle des liaisons qui se connectent à la carte processeur de routage. Le choix du lien dépend de la charge du lien.
Q. Pendant la nouvelle formation, tous les paquets envoyés sur cette liaison de fabric sont-ils perdus ?
R. Oui, mais avec les améliorations de la version 4.3.2 et des versions ultérieures, le recyclage est pratiquement indétectable. Cependant, dans le code précédent, il pouvait prendre plusieurs secondes pour se recycler, ce qui entraînait la perte de paquets pour cette période.
Q. À quelle fréquence pensez-vous qu'un événement de recyclage de lien de fabric XBAR se produira après la mise à niveau vers une version ou une SMU avec le correctif pour le bogue Cisco ayant l'ID CSCuj10837 ?
R. Même avec le correctif pour l'ID de bogue Cisco CSCuj10837, il est toujours possible de voir des retours à la liaison de fabric en raison de l'ID de bogue Cisco CSCul39674. Mais une fois que vous avez le correctif pour l'ID de bogue Cisco CSCul39674, la reformation de la liaison de fabric sur les liaisons de fond de panier de fabric entre les cartes de ligne basées sur RSP440 et Typhoon ne devrait jamais se produire. Si tel est le cas, envoyez une demande de service au Centre d'assistance technique Cisco (TAC) afin de résoudre le problème.
Q. L'ID de bogue Cisco CSCuj10837 et l'ID de bogue Cisco CSCul39674 affectent-ils le RP sur l'ASR 9922 avec des cartes de ligne basées sur Typhoon ?
A. Oui
Q : Les bogues Cisco CSCuj10837 et CSCul39674 affectent-ils les routeurs ASR-9001 et ASR-9001-S ?
A. Non
Q. Si vous rencontrez la défaillance d'un logement qui n'existe pas avec ce message, « PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP) failed: (8, 0) » dans un châssis à 10 logements, quel logement présente le problème ?
R. Dans les versions précédentes, vous devez tenir compte des mappages physiques et logiques comme indiqué ici. Dans cet exemple, le logement 8 correspond à 0/6/CPU0.
For 9010 (10 slot chassis)
L P
#0 --- #0
#1 --- #1
#2 --- #2
#3 --- #3
RSP0 --- #4
RSP1 --- #5
#4 --- #6
#5 --- #7
#6 --- #8
#7 --- #9
For 9006 (6 slot chassis)
L P
RSP0 --- #0
RSP1 --- #1
#0 --- #2
#1 --- #3
#2 --- #4
#3 --- #5
Données à collecter avant la création de la demande de service
Voici les commandes minimales pour collecter les résultats avant toute action :
show loggingshow pfm location alladmin show diagn result loc 0/rsp0/cpu0 test 8 detailadmin show diagn result loc 0/rsp1/cpu0 test 8 detailadmin show diagn result loc 0/rsp0/cpu0 test 9 detailadmin show diagn result loc 0/rsp1/cpu0 test 9 detailadmin show diagn result loc 0/rsp0/cpu0 test 10 detailadmin show diagn result loc 0/rsp1/cpu0 test 10 detailadmin show diagn result loc 0/rsp0/cpu0 test 11 detailadmin show diagn result loc 0/rsp1/cpu0 test 11 detailshow controller fabric fia link-status locationshow controller fabric fia link-status locationshow controller fabric fia bridge sync-status locationshow controller fabric crossbar link-status instance 0 locationshow controller fabric crossbar link-status instance 0 locationshow controller fabric crossbar link-status instance 1 locationshow controller fabric ltrace crossbar locationshow controller fabric ltrace crossbar locationshow tech fabric locationshow tech fabric locationfile
Commandes de diagnostic utiles
Voici une liste de commandes utiles à des fins de diagnostic :
show diagnostic ondemand settingsshow diagnostic content location < loc >show diagnostic result location < loc > [ test {id|id_list|all} ] [ detail ]show diagnostic statusadmin diagnostic start location < loc > test {id|id_list|test-suite}admin diagnostic stop location < loc >- itérations à la demande de diagnostic admin < nombre d'itérations >
admin diagnostic ondemand action-on-failure {continue failure-count|stop}- admin-config#
[ no ] diagnostic monitor location < loc > test {id | test-name} [disable] - admin-config#
[ no ] diagnostic monitor interval location < loc > test {id | test-name} day hour:minute:second.millisec - admin-config#
[ no ] diagnostic monitor threshold location < loc > test {id | test-name} failure count
Conclusion
La plupart des problèmes liés aux pannes de chemin de données du fabric ponctuel sont résolus à partir de la version 4.3.4 du logiciel Cisco IOS XR. Pour les routeurs affectés par l'ID de bogue Cisco CSCuj10837 et l'ID de bogue Cisco CSCul39674, chargez le SMU de remplacement pour l'ID de bogue Cisco CSCul39674 afin d'éviter les événements de recyclage de la liaison de fabric.
L'équipe de la plate-forme a installé une gestion des pannes à la pointe de la technologie afin que le routeur récupère en quelques sous-secondes en cas de défaillance récupérable d'un chemin de données. Cependant, ce document est recommandé afin de comprendre ce problème, même si aucune faute de ce type n'est observée.
Annexe
Chemin de diagnostic de bouclage NP
L'application de diagnostic qui s'exécute sur le processeur de la carte de ligne effectue un suivi de l'état de chaque processeur réseau avec des vérifications périodiques de l'état de fonctionnement du processeur réseau. Un paquet est injecté à partir du processeur de la carte de ligne à destination du processeur réseau local, lequel processeur réseau doit effectuer une boucle et revenir au processeur de la carte de ligne. Toute perte de ces paquets périodiques est signalée par un message de journal de plate-forme. Voici un exemple d'un tel message :
LC/0/7/CPU0:Aug 18 19:17:26.924 : pfm_node[182]:
%PLATFORM-PFM_DIAGS-2-LC_NP_LOOPBACK_FAILED : Set|online_diag_lc[94283]|
Line card NP loopback Test(0x2000006)|link failure mask is 0x8
Ce message de journal signifie que ce test n'a pas réussi à recevoir le paquet de bouclage de NP3. Le masque d'échec de liaison est 0x8 (le bit 3 est défini), ce qui indique une défaillance entre le processeur de la carte de ligne pour le logement 7 et NP3 sur le logement 7.
Afin d'obtenir plus de détails, collectez le résultat de ces commandes :
admin show diagnostic result location 0//cpu0 test 9 detail show controllers NP counter NP<0-3> location 0//cpu0
Commandes Fabric Debug
Les commandes répertoriées dans cette section s'appliquent à toutes les cartes de ligne Trident ainsi qu'à la carte de ligne 100GE basée sur Typhoon. L'ASIC FPGA Bridge n'est pas présent sur les cartes de ligne basées sur Typhoon (à l'exception des cartes de ligne basées sur Typhoon 100GE). Donc, la show controller fabric fia bridge ne s'appliquent pas aux cartes de ligne basées sur Typhoon, sauf pour les versions 100GE.
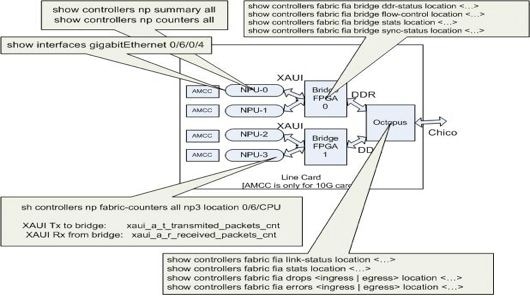
Cette représentation illustrée permet de mapper chaque commande show à l'emplacement du chemin de données. Utilisez ces commandes show afin d'isoler les pertes et les pannes de paquets.
Historique de révision
| Révision | Date de publication | Commentaires |
|---|---|---|
2.0 |
26-Jun-2023
|
Mise à jour de la section des améliorations de la récupération automatique pour l'ID de bogue Cisco CSCuc04493 et mise à jour de la section FAQ. |
1.0 |
29-Oct-2013
|
Première publication |
Contribution d’experts de Cisco
- Mahesh ShirshyadIngénieur TAC Cisco
- David PowersIngénieur TAC Cisco
- Jean-Christophe RodeIngénieur TAC Cisco
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)