Aislamiento Ultra-M y Reemplazo de Disco Fallido de Ceph/Clúster de Almacenamiento - vEPC
Opciones de descarga
-
ePub (1.2 MB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (742.4 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe los pasos necesarios para aislar y reemplazar el disco OSD del clúster Ceph/Storage alojado en Object Storage Disk (OSD)-Compute en una configuración Ultra-M.
Antecedentes
Ultra-M es una solución de núcleo de paquetes móviles virtualizados validados y empaquetados previamente diseñados para simplificar la implementación de VNF. OpenStack es Virtualized Infrastructure Manager (VIM) para Ultra-M y consta de los siguientes tipos de nodos:
- Informática
- OSD - Informática
- Controlador
- Plataforma OpenStack - Director (OSPD)
La arquitectura de alto nivel de Ultra-M y los componentes implicados se muestran en esta imagen:
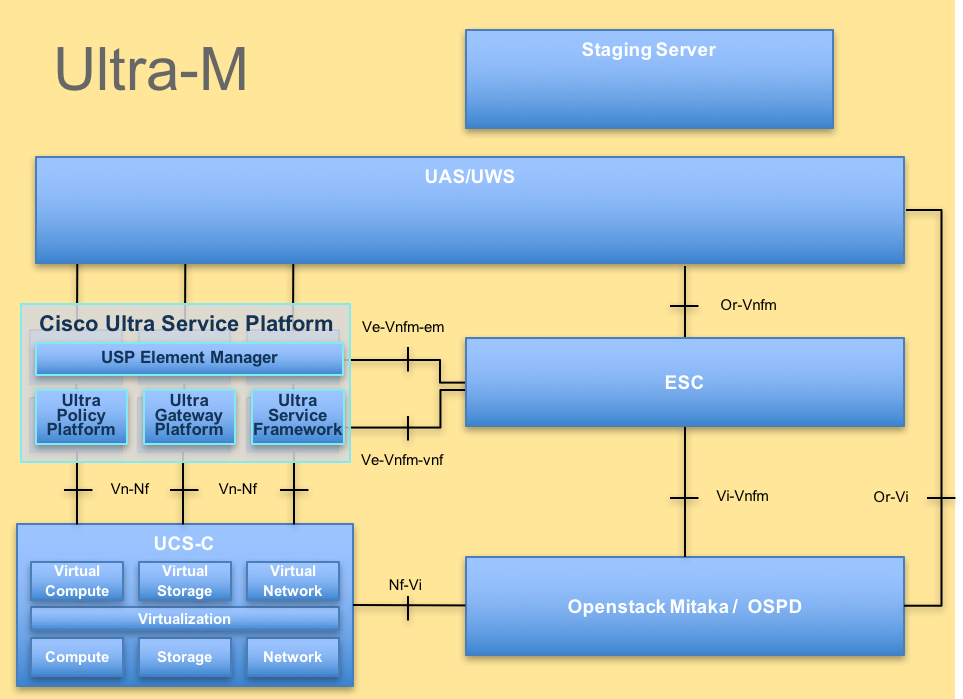 Arquitectura UltraMEste documento está dirigido al personal de Cisco que está familiarizado con la plataforma Ultra-M de Cisco y detalla los pasos necesarios que se deben llevar a cabo en el nivel de OpenStack en el momento de la sustitución del servidor OSPD.
Arquitectura UltraMEste documento está dirigido al personal de Cisco que está familiarizado con la plataforma Ultra-M de Cisco y detalla los pasos necesarios que se deben llevar a cabo en el nivel de OpenStack en el momento de la sustitución del servidor OSPD.
Nota: Se considera la versión Ultra M 5.1.x para definir los procedimientos en este documento.
Abreviaturas
| VNF | Función de red virtual |
| CF | Función de control |
| SF | Función de servicio |
| ESC | Controlador de servicio elástico |
| FREGAR | Método de procedimiento |
| OSD | Discos de almacenamiento de objetos |
| HDD | Disco duro |
| SSD | Unidad de estado sólido |
| VIM | Administrador de infraestructura virtual |
| VM | Máquina virtual |
| EM | Administrador de elementos |
| UAS | Servicios de ultra automatización |
| UUID | Identificador único universal |
Flujo de trabajo del MOP

Comprobaciones de estado previas
1. Utilice el comando Ceph-disk list para comprender la asignación de OSD a Journal e identificar el disco que se va a aislar y reemplazar.
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph-disk list
/dev/sda :
/dev/sda1 other, iso9660
/dev/sda2 other, xfs, mounted on /
/dev/sdb :
/dev/sdb1 ceph journal, for /dev/sdc1
/dev/sdb3 ceph journal, for /dev/sdd1
/dev/sdb2 ceph journal, for /dev/sde1
/dev/sdb4 ceph journal, for /dev/sdf1
/dev/sdc :
/dev/sdc1 ceph data, active, cluster ceph, osd.1, journal /dev/sdb1
/dev/sdd :
/dev/sdd1 ceph data, active, cluster ceph, osd.7, journal /dev/sdb3
/dev/sde :
/dev/sde1 ceph data, active, cluster ceph, osd.4, journal /dev/sdb2
/dev/sdf :
/dev/sdf1 ceph data, active, cluster ceph, osd.10, journal /dev/sdb4
2. Verifique el estado de Ceph y la asignación del árbol OSD antes de continuar con el aislamiento de disco OSD identificado.
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e709: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v941813: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 11922 GB / 13393 GB avail
704 active+clean
client io 58580 B/s wr, 0 op/s rd, 7 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 0 host pod1-osd-compute-1
-4 4.35999 host pod1-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
Aislamiento y eliminación del disco OSD defectuoso del clúster
1. Inhabilite y detenga el proceso OSD.
[heat-admin@pod1-osd-compute-3 ~]$ sudo systemctl disable ceph-osd@7
[heat-admin@pod1-osd-compute-3 ~]$ sudo systemctl stop ceph-osd@7
2. Marque el OSD.
[heat-admin@pod1-osd-compute-3 ~]$ sudo su
[root@pod1-osd-compute-3 heat-admin]# ceph osd set noout
set noout
[root@pod1-osd-compute-3 heat-admin]# ceph osd set norebalance
set norebalance
[root@pod1-osd-compute-3 heat-admin]# ceph osd out 7
marked out osd.7.
Nota: Espere a que se complete el reequilibrio de datos y a que todos los PG vuelvan a active+clean para evitar problemas.
3. Confirme si el OSD está marcado y espere a que el nuevo equilibrio de Ceph continúe.
[root@pod1-osd-compute-3 heat-admin]# watch -n1 ceph -s
95 active+undersized+degraded+remapped+wait_backfill
28 active+recovery_wait+degraded
2 active+undersized+degraded+remapped+backfilling
1 active+recovering+degraded
2 active+undersized+degraded+remapped+backfilling
1 active+recovering+degraded
2 active+undersized+degraded+remapped+backfilling
67 active+undersized+degraded+remapped+wait_backfill
3 active+undersized+degraded+remapped+backfilling
24 active+undersized+degraded+remapped+wait_backfill
22 active+undersized+degraded+remapped+wait_backfill
1 active+undersized+degraded+remapped+backfilling
8 active+undersized+degraded+remapped+wait_backfill
4. Quite la clave de autenticación para el OSD.
[root@pod1-osd-compute-3 heat-admin]# ceph auth del osd.7
updated
5. Confirme que las claves para OSD.7 no estén listadas.
[root@pod1-osd-compute-3 heat-admin]# ceph auth list
installed auth entries:
osd.0
key: AQCgpB5blV9dNhAAzDN1SVdnuJyTN2f7PAdtFw==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.1
key: AQBdwyBbbuD6IBAAcvG+oQOz5vk62faOqv/CEw==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.10
key: AQCwwyBb7xvHJhAAZKPprXWT7UnvnAXBV9W2rg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.11
key: AQDxpB5b9/rGFRAAkcCEkpSN1YZVDdeW+Bho7w==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.2
key: AQCppB5btekoNBAAACoWpDz0VL9bZfyIygDpBQ==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.3
key: AQC4pB5bBaUlORAAhi3KPzetwvWhYGnerAkAsg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.4
key: AQB1wyBbvMIQLRAAXefFVnZxMX6lVtObQt9KoA==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.5
key: AQDBpB5buKHqOhAAW1Q861qoYqW6fAYHlOxsLg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.6
key: AQDQpB5b1BveFxAAfCLM3tvDUSnYneutyTmaEg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.8
key: AQDZpB5bd4nlGRAAkkzbmGPnEDAWV0dUhrhE6w==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.9
key: AQDopB5bKCZPGBAAfYtp1GLA7QIi/YxJa8O1yw==
caps: [mon] allow profile osd
caps: [osd] allow *
client.admin
key: AQDpmx5bAAAAABAA3hLK8O2tGgaAK+X2Lly5Aw==
caps: [mds] allow *
caps: [mon] allow *
caps: [osd] allow *
client.bootstrap-mds
key: AQBDpB5bjR1GJhAAB6CKKxXulve9WIiC6ZGXgA==
caps: [mon] allow profile bootstrap-mds
client.bootstrap-osd
key: AQDpmx5bAAAAABAA3hLK8O2tGgaAK+X2Lly5Aw==
caps: [mon] allow profile bootstrap-osd
client.bootstrap-rgw
key: AQBDpB5b7OWXHBAAlATmBAOX/QWW+2mLxPqlkQ==
caps: [mon] allow profile bootstrap-rgw
client.openstack
key: AQDpmx5bAAAAABAAULxfs9cYG1wkSVTjrtiaDg==
caps: [mon] allow r
caps: [osd] allow class-read object_prefix rbd_children, allow rwx pool=volumes, allow rwx pool=backups, allow rwx pool=vms, allow rwx pool=images, allow rwx pool=metrics
7. Retire el OSD del clúster.
[root@pod1-osd-compute-3 heat-admin]# ceph osd rm 7
removed osd.7
8. Desmonte el disco OSD que necesita ser reemplazado.
[root@pod1-osd-compute-3 heat-admin]# umount /var/lib/ceph/osd/ceph-7
9. Desactive el noscub y el deep.
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset noscrub
unset noscrub
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset nodeep-scrub
unset nodeep-scrub
10. Verifique el estado de Ceph y espere a que health-ok y todos los PG vuelvan a active+clean.
[root@pod1-osd-compute-3 heat-admin]# ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
28 pgs backfill_wait
4 pgs backfilling
5 pgs degraded
5 pgs recovery_wait
83 pgs stuck unclean
recovery 1697/516881 objects degraded (0.328%)
recovery 76428/516881 objects misplaced (14.786%)
noout,norebalance,sortbitwise,require_jewel_osds flag(s) set
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e877: 11 osds: 11 up, 11 in; 193 remapped pgs
flags noout,norebalance,sortbitwise,require_jewel_osds
pgmap v942974: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 10806 GB / 12277 GB avail
1697/516881 objects degraded (0.328%)
76428/516881 objects misplaced (14.786%)
511 active+clean
156 active+remapped
28 active+remapped+wait_backfill
5 active+recovery_wait+degraded+remapped
4 active+remapped+backfilling
client io 331 kB/s wr, 0 op/s rd, 56 op/s wr
Reemplace el disco OSD y cree un nuevo DVD
1. Quite la unidad defectuosa y sustitúyala por una nueva: Guía de instalación y servicio del servidor Cisco UCS C240 M4.
2. Verifique el inicio de sesión en CIMC del OSD-Compute y verifique la ranura donde se reemplaza el OSD y se muestra en buen estado.
3. Crear una unidad virtual para un nuevo disco duro, debe ser un disco duro fresco sin metadatos.
4. Compruebe que el disco recién agregado está en el estado No confirmado Correcto.
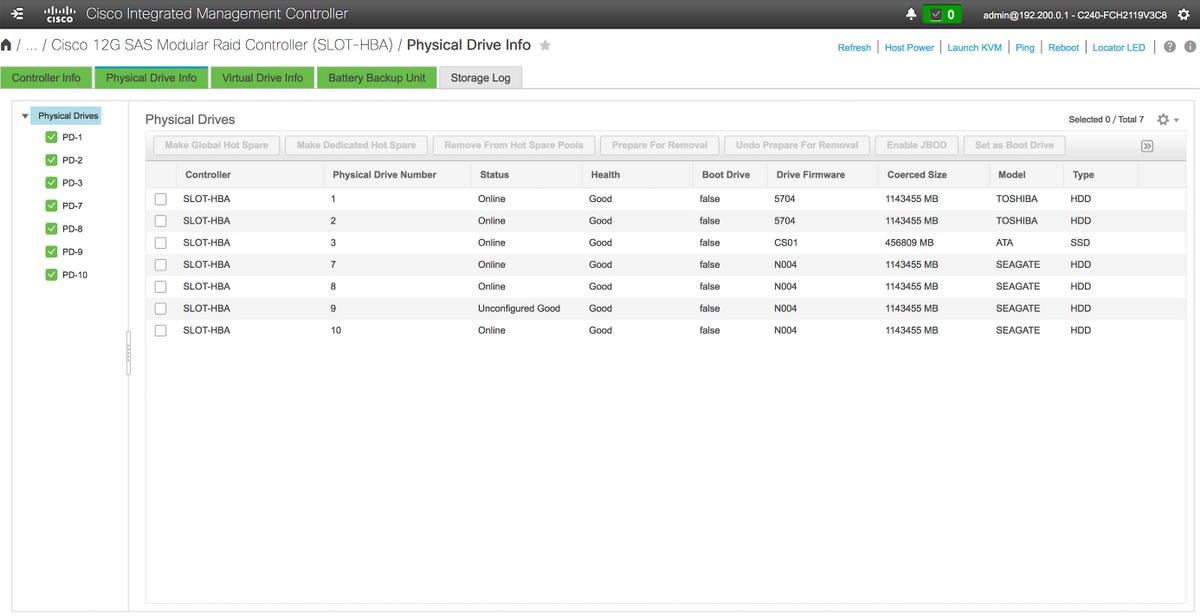 Almacenamiento > Controlador RAID modular Cisco SAS 12G (SLOT-HBA) > Información de la unidad física
Almacenamiento > Controlador RAID modular Cisco SAS 12G (SLOT-HBA) > Información de la unidad física
5. Seleccione la opción Create Virtual Drive from Unused Physical Drives para crear el VD.
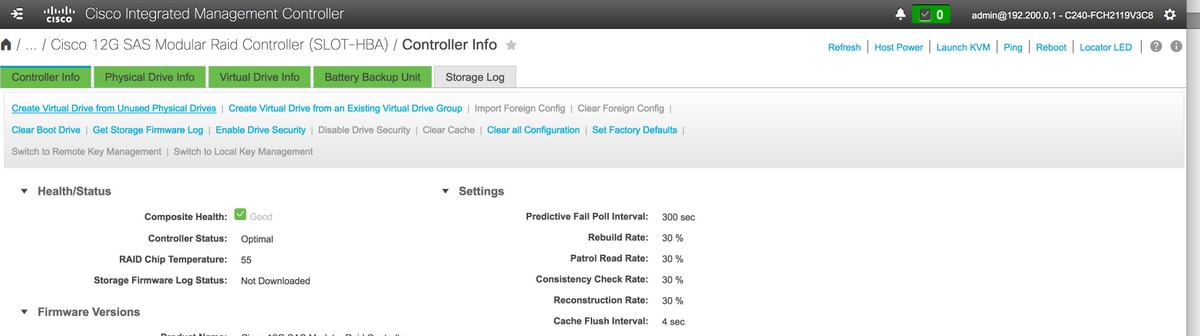 Almacenamiento > Controlador RAID modular SAS 12G de Cisco (SLOT-HBA)
Almacenamiento > Controlador RAID modular SAS 12G de Cisco (SLOT-HBA)
6. Utilice la unidad física 9 para crear un nuevo DVD y nombrarlo como OSD3.
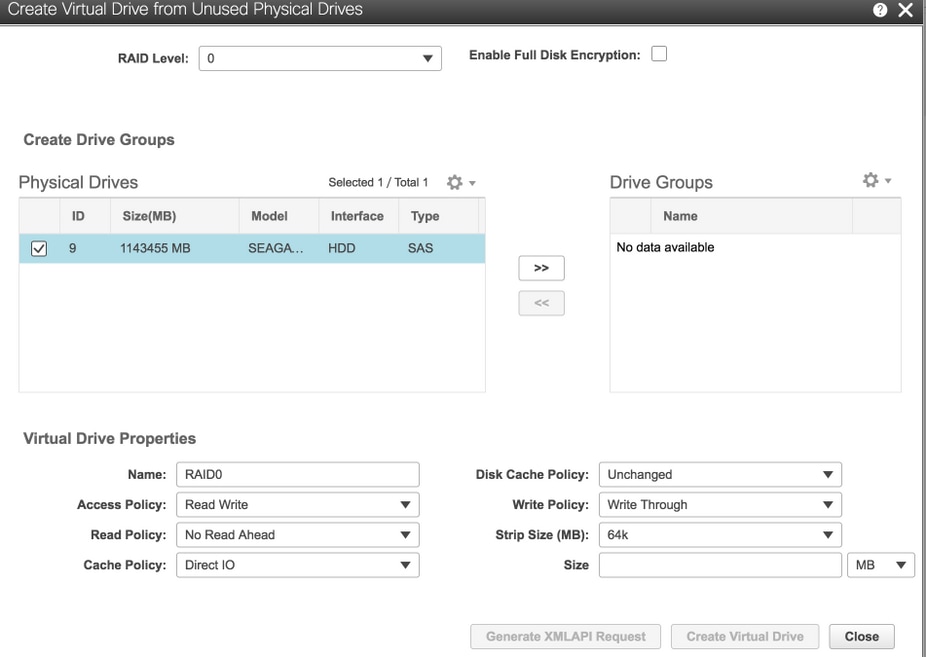 Almacenamiento > Controlador RAID modular SAS de 12 GB de Cisco (SLOT-HBA) > Información del controlador > Crear unidad virtual a partir de unidades físicas no utilizadas
Almacenamiento > Controlador RAID modular SAS de 12 GB de Cisco (SLOT-HBA) > Información del controlador > Crear unidad virtual a partir de unidades físicas no utilizadas
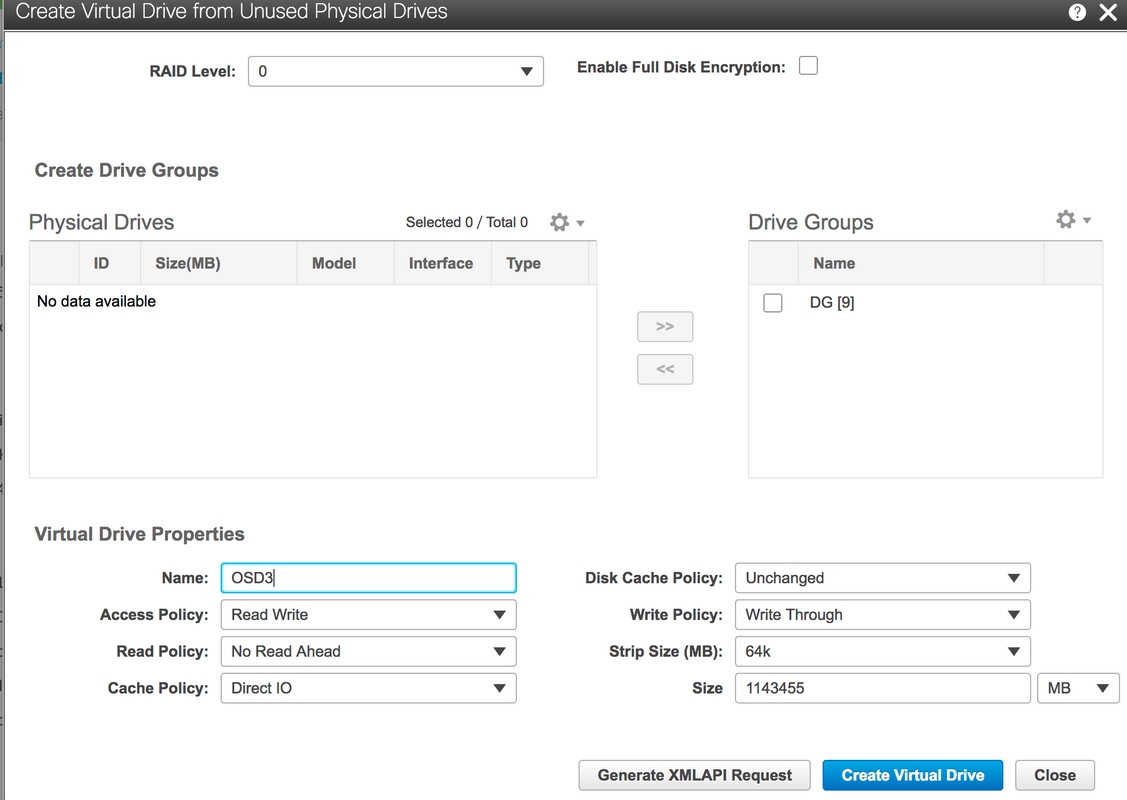 Almacenamiento > Controlador RAID modular SAS de 12 GB de Cisco (SLOT-HBA) > Información del controlador > Crear unidad virtual a partir de unidades físicas no utilizadas
Almacenamiento > Controlador RAID modular SAS de 12 GB de Cisco (SLOT-HBA) > Información del controlador > Crear unidad virtual a partir de unidades físicas no utilizadas
7. Habilite IPMI sobre LAN: Admin > Communication Services > Communication Services.
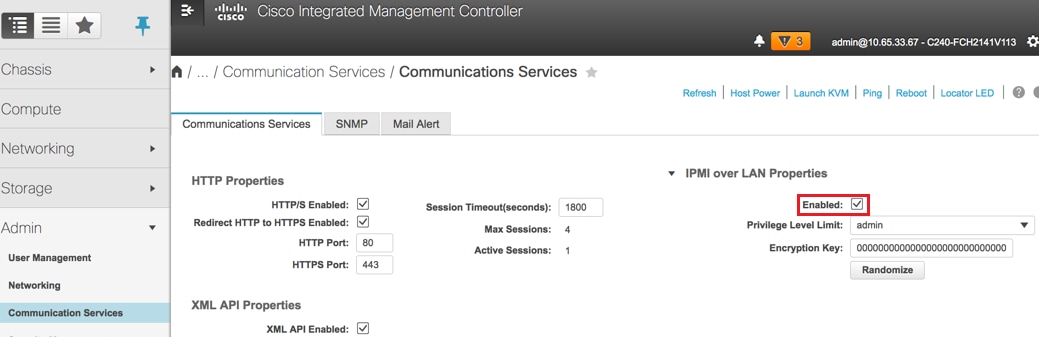 Habilitar IPMI sobre LAN: Admin > Communication Services > Communication Services
Habilitar IPMI sobre LAN: Admin > Communication Services > Communication Services
8. Inhabilite el hyperthreading: Compute > BIOS > Conimage BIOS > Advanced > Processor Configuration.
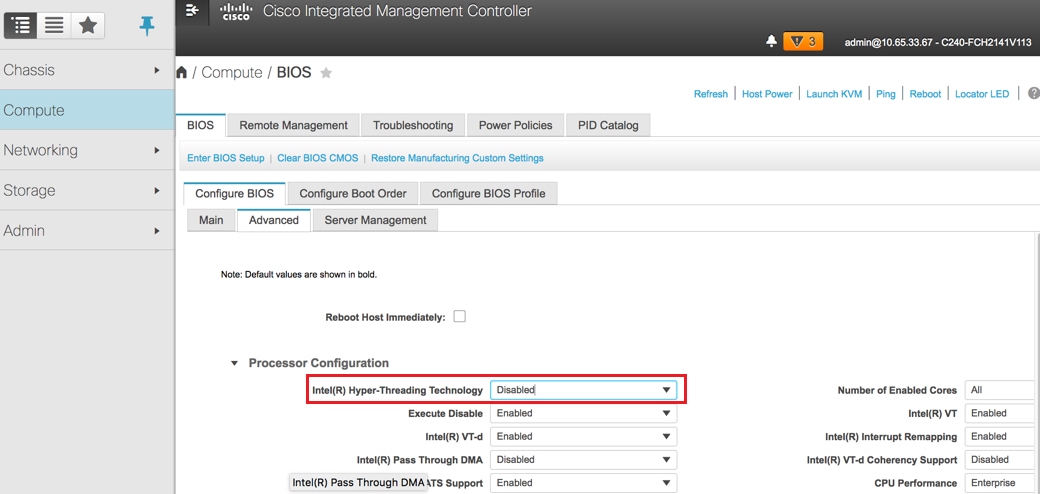 Deshabilitar hiperprocesamiento: Compute > BIOS > Configure BIOS > Advanced > Processor Configuration
Deshabilitar hiperprocesamiento: Compute > BIOS > Configure BIOS > Advanced > Processor Configuration
Nota: La imagen que se muestra aquí y los pasos de configuración mencionados en esta sección hacen referencia a la versión de firmware 3.0(3e) y puede haber ligeras variaciones si trabaja en otras versiones.
Vuelva a agregar el OSD al clúster
1. Después de reemplazar un nuevo disco, ejecute partprobe para detectar el nuevo dispositivo.
[root@pod1-osd-compute-3 heat-admin]# partprobe
[root@pod1-osd-compute-3 heat-admin]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 278.5G 0 disk
|
-sda1 8:1 0 1M 0 part
-sda2 8:2 0 278.5G 0 part /
sdb 8:16 0 446.1G 0 disk
|
-sdb1 8:17 0 107G 0 part
-sdb2 8:18 0 107G 0 part
-sdb3 8:19 0 107G 0 part
-sdb4 8:20 0 107G 0 part
sdc 8:32 0 1.1T 0 disk
|
-sdc1 8:33 0 1.1T 0 part /var/lib/ceph/osd/ceph-1
sdd 8:48 0 1.1T 0 disk
|
-sdd1 8:49 0 1.1T 0 part
sde 8:64 0 1.1T 0 disk
|
-sde1 8:65 0 1.1T 0 part /var/lib/ceph/osd/ceph-4
sdf 8:80 0 1.1T 0 disk
|
-sdf1 8:81 0 1.1T 0 part /var/lib/ceph/osd/ceph-10
2. Busque un dispositivo que esté disponible en el servidor.
[root@pod1-osd-compute-3 heat-admin]# fdisk -l
Disk /dev/sda: 299.0 GB, 298999349248 bytes, 583983104 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x000b5e87
Device Boot Start End Blocks Id System
/dev/sda1 2048 4095 1024 83 Linux
/dev/sda2 * 4096 583983070 291989487+ 83 Linux
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdb: 479.0 GB, 478998953984 bytes, 935544832 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 224462847 107G unknown ceph journal
2 224462848 448923647 107G unknown ceph journal
3 448923648 673384447 107G unknown ceph journal
4 673384448 897845247 107G unknown ceph journal
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdd: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdc: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sde: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdf: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
[root@pod1-osd-compute-3 heat-admin]#
3. Utilice la lista de discos Ceph para identificar el mapa de partición del disco de asiento.
[root@pod1-osd-compute-3 heat-admin]# ceph-disk list
/dev/sda :
/dev/sda1 other, iso9660
/dev/sda2 other, xfs, mounted on /
/dev/sdb :
/dev/sdb1 ceph journal, for /dev/sdc1
/dev/sdb3 ceph journal
/dev/sdb2 ceph journal, for /dev/sde1
/dev/sdb4 ceph journal, for /dev/sdf1
/dev/sdc :
/dev/sdc1 ceph data, active, cluster ceph, osd.1, journal /dev/sdb1
/dev/sdd :
/dev/sdd1 other, xfs
/dev/sde :
/dev/sde1 ceph data, active, cluster ceph, osd.4, journal /dev/sdb2
/dev/sdf :
/dev/sdf1 ceph data, active, cluster ceph, osd.10, journal /dev/sdb4
Nota: En la lista ceph-disk, el resultado resaltado sde1 es la partición de asiento para sdb2. Verifique la salida de la lista Ceph-disk y asigne la partición de disco de asiento en el comando para la preparación de Ceph. Tan pronto como ejecute el siguiente comando OSD.7 apareció/entró y se iniciará el reequilibrio de datos (relleno/recuperación).
4. Cree el disco Ceph y vuelva a agregarlo al clúster.
[root@pod1-osd-compute-3 heat-admin]# ceph-disk --setuser ceph --setgroup ceph prepare --fs-type xfs /dev/sdd /dev/sdb3
prepare_device: OSD will not be hot-swappable if journal is not the same device as the osd data
Creating new GPT entries.
The operation has completed successfully.
meta-data=/dev/sdd1 isize=2048 agcount=4, agsize=73181055 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=292724219, imaxpct=5
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=142931, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
Warning: The kernel is still using the old partition table.
The new table will be used at the next reboot.
The operation has completed successfully.
#####Hint###
where - sdd is new drive added as OSD
where – sdb3 is journal disk partition number
mapping is sdc1 for sdc, sdd1 for sdd, sde1 for sde
sdf1 for sdf (and so on)
5. Active los discos Ceph y anule los indicadores noscub y nodeep-debug.
[root@pod1-osd-compute-3 heat-admin]# ceph-disk activate-all
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset noout
unset noout
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset norebalance
unset norebalance
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset noscrub
unset noscrub
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset nodeep-scrub
unset nodeep-scrub
6. Espere a que el reequilibrio termine y verifique que la salud del árbol Ceph y OSD esté bien.
[root@pod1-osd-compute-3 heat-admin]# watch -n 3 ceph -s
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e709: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v941813: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 11922 GB / 13393 GB avail
704 active+clean
client io 58580 B/s wr, 0 op/s rd, 7 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
Con la colaboración de ingenieros de Cisco
- Partheeban RajagopalCisco Advanced Services
- Padmaraj RamanoudjamCisco Advanced Services
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)