Introducción
Este documento describe los pasos necesarios para reemplazar ambos discos duros defectuosos en el servidor en una configuración Ultra-M que aloja funciones de red virtual (VNF) de StarOS.
Antecedentes
Ultra-M es una solución de núcleo de paquetes móviles virtualizados validados y empaquetados previamente diseñados para simplificar la implementación de VNF. OpenStack es Virtualized Infrastructure Manager (VIM) para Ultra-M y consta de los siguientes tipos de nodos:
- Informática
- Disco de almacenamiento de objetos - Informática (OSD - Informática)
- Controlador
- Plataforma OpenStack - Director (OSPD)
La arquitectura de alto nivel de Ultra-M y los componentes implicados se muestran en esta imagen:
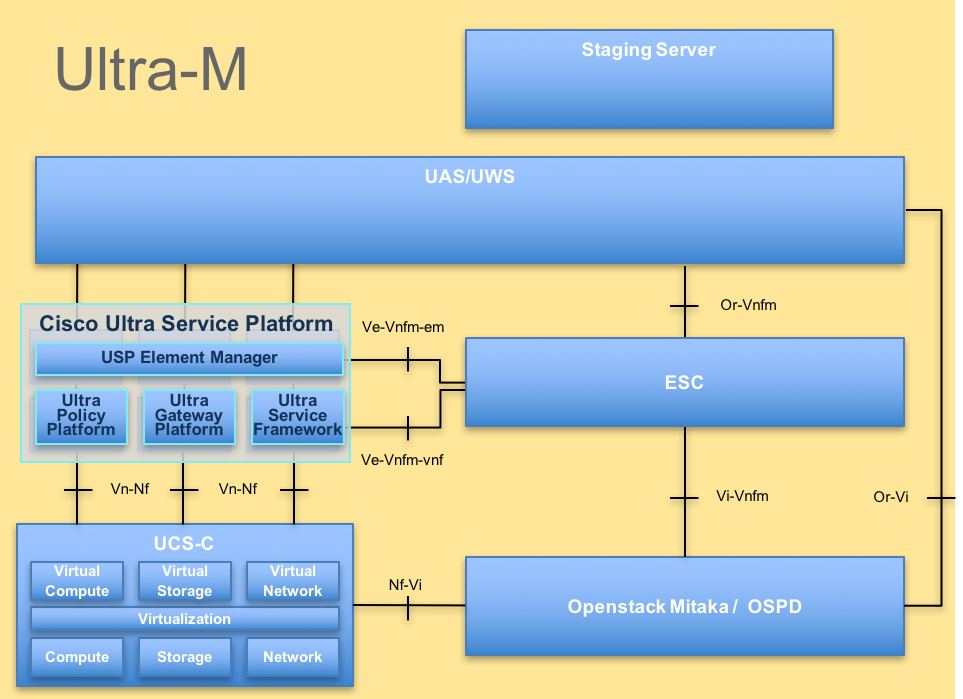 Arquitectura UltraM
Arquitectura UltraM
Este documento está dirigido al personal de Cisco familiarizado con la plataforma Ultra-M de Cisco y detalla los pasos necesarios que deben llevarse a cabo a nivel de OpenStack y StarOS VNF en el momento de la sustitución del servidor controlador.
Nota: Se considera la versión Ultra M 5.1.x para definir los procedimientos en este documento.
Abreviaturas
| VNF |
Función de red virtual |
| CF |
Función de control |
| SF |
Función de servicio |
| ESC |
Controlador de servicio elástico |
| FREGAR |
Método de procedimiento |
| OSD |
Discos de almacenamiento de objetos |
| HDD |
Disco duro |
| SSD |
Unidad de estado sólido |
| VIM |
Administrador de infraestructura virtual |
| VM |
Máquina virtual |
| EM |
Administrador de elementos |
| UAS |
Servicios de ultra automatización |
| UUID |
Identificador único universal |
Fallo en ambas HDD
Cada servidor sin software específico se aprovisionará con dos unidades de disco duro para que actúen como DISCO DE ARRANQUE en la configuración RAID 1. En caso de fallo de un solo disco duro, dado que existe redundancia de nivel RAID 1, el disco duro defectuoso se puede intercambiar en caliente. Sin embargo, cuando ambos discos duros fallan, el servidor estará inactivo y perderá el acceso al servidor. Para restaurar el acceso al servidor y a los servicios, es necesario para sustituir ambos discos duros y añadir el servidor a la pila de nube superpuesta existente.
El procedimiento para reemplazar un componente defectuoso en el servidor UCS C240 M4 puede consultarse en Reemplazo de los componentes del servidor.
En caso de fallo de ambos discos duros, sustituya únicamente estos dos discos duros defectuosos en el mismo servidor UCS 240M4. El procedimiento de actualización del BIOS no es necesario después de reemplazar los discos nuevos.
En la solución Ultra-M basada en OpenStack, el servidor sin software específico UCS 240M4 puede desempeñar una de estas funciones: Compute, OSD-Compute, Controller u OSPD. En estas secciones se mencionan los pasos necesarios para manejar ambos fallos de HDD en cada una de estas funciones de servidor.
Nota: En situaciones en las que ambos discos duros estén en buen estado pero algún otro hardware esté defectuoso en el servidor UCS 240M4, sustituya el UCS 240M4 por el nuevo hardware; sin embargo, vuelva a utilizar los mismos discos duros. En este caso, solo las HDD son defectuosas, por lo que debe volver a utilizar la misma unidad UCS 240M4 y sustituir las HDD defectuosas por otras nuevas.
Fallo de ambos discos duros en el servidor informático
Si se observa un fallo en ambas HDD en UCS 240M4, que actúa como nodo informático, siga el procedimiento de sustitución que se describe en Procedimiento de sustitución del servidor informático.
Fallo de ambas HDD en el servidor controlador
Si se observa un fallo en ambas HDD en UCS 240M4, que actúa como nodo de controlador, siga el procedimiento de sustitución que se describe en la .
Dado que el servidor del controlador que observa la falla de ambos HDD no será accesible a través de Secure Shell (SSH), inicie sesión en otro nodo del controlador para realizar el procedimiento de cierre correcto que se enumera en el link mencionado.
Falla de ambas HDD en OSD-Compute Server
Si se observa el fallo de ambas HDD en UCS 240M4, que actúa como nodo OSD-Compute, siga el procedimiento de sustitución que se describe en la .
En el procedimiento mencionado aquí, el cierre correcto del almacenamiento Ceph no se puede realizar ya que ambos fallos resultan en la indisponibilidad del servidor. Por lo tanto, ignore esos pasos.
Falla de ambas HDD en el servidor OSPD
Si se observa el fallo de ambas HDD en UCS 240M4, que actúa como nodo OSPD de SNMP, siga el procedimiento de sustitución que se describe en la .
En este caso, la copia de seguridad OSPD previamente almacenada es necesaria para la restauración después de la sustitución del disco duro, de lo contrario será como la reimplementación de la pila completa.
 Comentarios
Comentarios